快速了解部分
基础信息(英文):
1.题目: MotuBrain: An Advanced World Action Model for Robot Control
2.时间: 2026.05
3.机构: 生数科技
4.3个英文关键词: World Action Model (WAM), VLA, Diffusion
1句话通俗总结本文干了什么事情
本文提出了一种名为 MotuBrain 的机器人控制模型,它通过一个统一的 Diffusion 模型同时预测"世界画面"和"机器人动作",让机器人既能看懂世界,又能精准执行复杂任务。
研究痛点:现有研究不足 / 要解决的具体问题
现有 VLA 模型虽然能理解语言和视觉,但缺乏对物理世界动态的深层理解,导致控制精度差;而现有的"世界模型+动作"两阶段方法(先预测画面再推算动作)存在误差累积的问题,且效率低下。
核心方法:关键技术、模型或研究设计(简要)
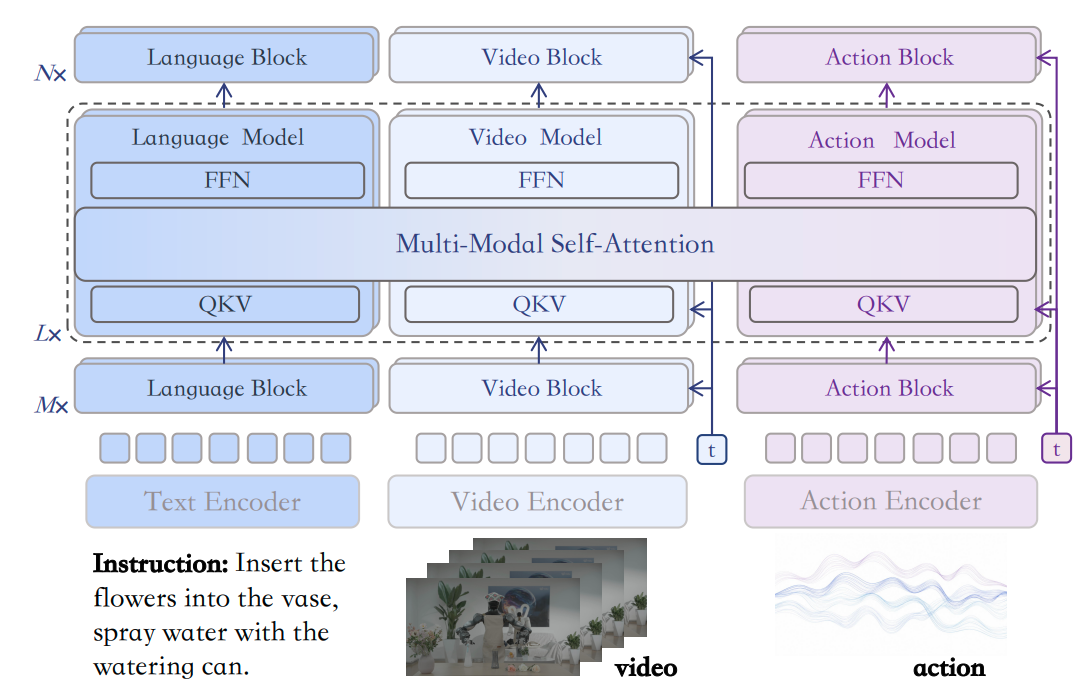
采用 World Action Model (WAM) 范式,使用 UniDiffuser 和 3路 Mixture-of-Transformers 架构,将视频画面和机器人动作放在同一个模型中联合预测(Joint Prediction),并配合一系列推理加速技术(如 V2A attention, FP8 量化)。
深入了解部分
作者想要表达什么
作者认为,真正的机器人智能不应仅仅是模仿行为(如 VLA 那样),而应该建立一个统一的"世界动作模型"。通过在大规模异构数据上联合训练视觉预测和动作生成,模型可以同时具备强大的物理世界理解能力和精准的动作控制能力,且这种能力可以迁移到不同的机器人本体上。
相比前人创新在哪里
- 统一联合预测:不同于之前的"两阶段法"(先生成视频再反推动作),MotuBrain 在一个模型里同时预测视频和动作,避免了误差累积。
- 架构设计:引入了独立的文本流(Text Stream)来增强语义理解,并使用了 V2A (Video-to-Action) attention 机制,允许在推理时只生成动作而不生成视频,大幅提高速度。
- 多视角与通用性:支持任意数量的摄像头视角,并使用统一的动作表示(Relative EEF),使其能轻松迁移到不同构型的机器人(如不同的人形机器人)上。
解决方法/算法的通俗解释
想象给机器人装上了一个"预演大脑"。当给定指令时,这个大脑不是直接乱动,而是在内部快速模拟"如果我这样做,下一秒画面会变成什么样",并同时规划出"我该怎么做动作"。因为画面预测(World Model)和动作规划(Action)是同一个大脑在思考,所以它们非常协调,不会出现"想做的和看到的对不上"的情况。
解决方法的具体做法
- 模型架构:基于 UniDiffuser,构建了包含 Video、Action、Text 三个数据流的 MoT (Mixture-of-Transformers)。
- 训练数据金字塔:从互联网视频(大规模视觉先验) -> 第一人称视频(接近机器人视角) -> 异构机器人数据(不同机器人的动作) -> 特定机器人数据(最终部署的机器人数据)。
- 推理加速:使用了 FP8 量化、DiT Caching(利用时间冗余跳过计算)、V2A 推理模式(冻结视频流,只跑动作流)以及实时的 Chunked 闭合回路执行(减少延迟带来的抖动)。
基于前人的哪些方法
- UniDiffuser:用于联合建模视频和动作两个模态。
- Vidu:作为视频生成的预训练基础模型(Base Model)。
- LingBot-VA:借鉴了其 noisy-conditioning 策略来增强鲁棒性。
- DreamZero:借鉴了其 DiT Caching 策略和 Action Chunk Smoothing。
实验设置、数据、评估方式、结论
- 实验设置:在 RoboTwin 2.0(50个双臂操作任务)和 WorldArena(世界模型评测基准)上进行评估,并在真实的人形机器人上进行了少样本(50-100条轨迹)部署测试。
- 数据:使用了互联网视频、第一人称视频、以及多机器人平台的异构数据。
- 评估方式 :
- RoboTwin 2.0:计算任务成功率(Success Rate)。
- WorldArena:计算 EWMScore(包含视觉质量、运动质量、物理遵循等16个指标)。
- 结论:MotuBrain 在 RoboTwin 上达到了 95.8% (Clean) 和 96.1% (Randomized) 的成功率,优于现有的 VLA 和世界模型基线;在 WorldArena 上取得了最高的 EWMScore (63.77),证明其预测的画面既真实又符合物理规律。
提到的同类工作
- VLA (Vision-Language-Action) Models:如 RT-2, Octo, π0 等,作为主要对比基线。
- World Models:如 JEPA-VLA, LingBot-VA 等。
- Video Generation Models:如 Veo, Wan 等,用于对比世界模型的视觉生成能力。
和本文相关性最高的3个文献
- Motus 5 (2025)
- LingBot-VA 24 (2Up)
- DreamZero 36 (2026)
我的
- WAM模型,结构和Motus很像。
- 亮点在于推理很快,V2A Attention让其不用生成视频(推理时),以及cache加速。引入了 3D RoPE,可以适应任意多视角。
- 把robotwin刷的很高。
- 还没开源。