本文将从实际跑通的案例出发,拆解 Bash + OpenSpec + Claude 这套组合的完整运作逻辑。其中最关键的一环,就是引入Bash loop ------一种让 AI 在无人值守时依然能提交代码、跑测试、更新文档的工作方式。s
昨晚十点,我合上电脑下班回家睡觉。
今早打开终端,git log 一拉------十几条提交排着队,测试全绿,文档跟着更新了,多个需求按设计落了地。
不是有人加班,是我走之前启动的一个脚本------openspec.sh。
我做某业务系统的时候,日常就是和各种数据源、配置表单、校验逻辑、决策流可视化打交道。这类工作有个特点:模式重复但组合多,边界清晰但需求量大。 写第一个需求需要想清楚,写第八个、第十五个就是在重复自己。
这几天我开始尝试让 AI 替我跑这些重复性工作。试了几轮之后发现确实可行,流程也逐渐稳定下来。这篇文章就讲讲我是怎么一步步搞出来的。
起因:Ralph Wiggum 与 ralph.sh
事情得从我刷到的一篇文章说起:Ralph Wiggum: How to Make Claude Code Work While You Sleep with a Bash Loop。
名字来自《辛普森一家》里那个总说"I'm helping!"的小胖子 Ralph Wiggum。作者说,这个 Bash 循环就像他------你不太确定它到底在干嘛,但回头一看,活儿确实干了。
核心思路非常直接:
别搞什么多 Agent 编排、DAG 调度、分阶段状态机。 就一个
while循环 ,反复调用claude -p。 每一轮让 AI 自己找还没干完的任务,写代码,跑测试,提交。 循环跑到所有任务完成、或者到了你设的上限为止。
整个方案只要三个文件: 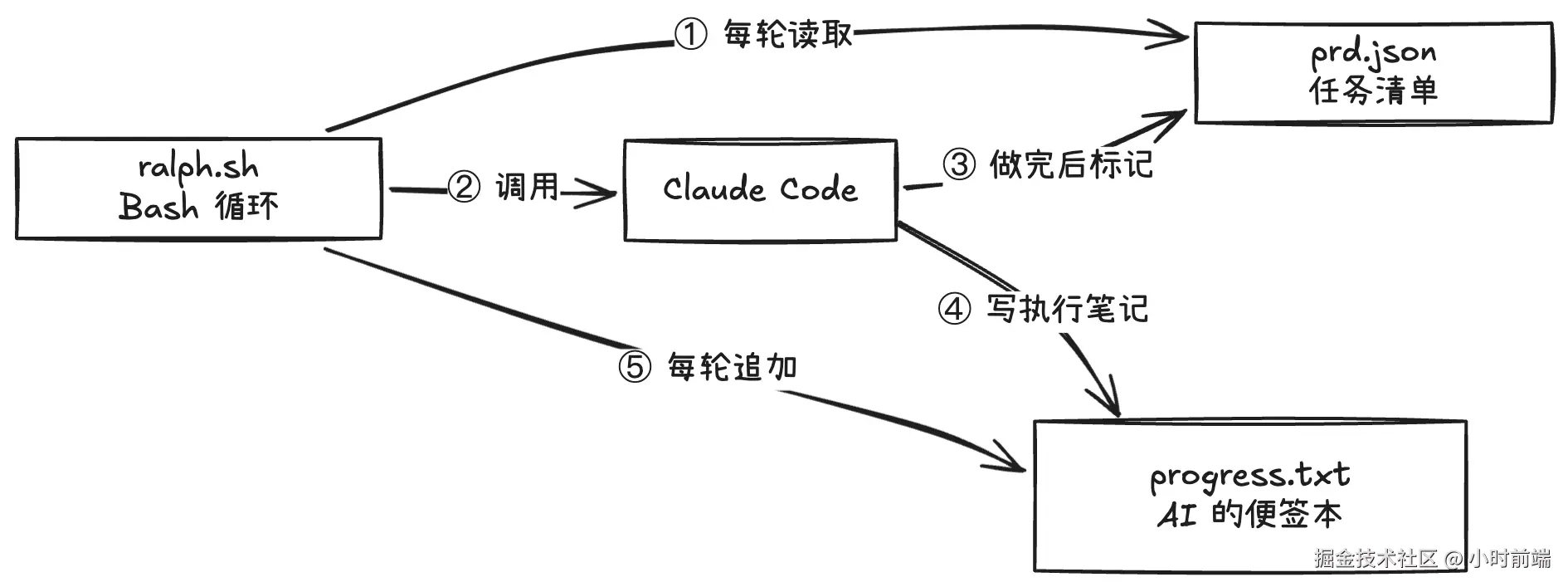
- prd.json --- 需求 + 任务列表,每个任务有个
passes: true/false - progress.txt --- AI 的跨轮次记忆。每轮结束写一笔「做了啥、踩了什么坑」,下一轮开始先读它
- ralph.sh --- 那个
while循环,内部用claude -p把 prompt 传给 Claude Code
看完之后我觉得思路一下打开了:原来不需要搞得那么复杂。
之前我一直觉得让 AI 自动写代码得搞套很重的系统------任务编排、状态管理、失败重试......但其实一个 while 循环就能跑通。关键不在于调度有多精巧,而在于任务描述够不够清楚。
试着跑起来
用 ralph.sh 跑起来。 前提是你已经装了 Claude Code 且能用命令行 claude -p "..."。把项目里的 ralph.sh 打开,里面就是一串固定 prompt:读 prd.json 和 progress.txt,选第一个 passes: false 的任务,实现、跑测试、更新 prd、写 progress、commit,全部做完就输出 RALPH_COMPLETE。脚本每轮执行一次 claude -p,检查输出里有没有 RALPH_COMPLETE,有就退出,没有就 sleep 5 再下一轮。
首先是工具链。 prd.json 里每个任务只有一句话 description,需求一复杂就变得又臭又长。我需要更结构化的方式来写需求------ OpenSpec,可以用提案(proposal)把需求写清楚,AI 按提案执行。
progress.txt 做跨轮次记忆。 这是原版最聪明的设计:每轮结束 AI 往里追加「做了啥、踩了什么坑、下一轮建议」,下一轮先读再干活,不用靠对话历史,Token 也不会随轮次暴涨。
关于 git 提交。 原版 ralph.sh 的 prompt 里让 AI 自己执行 git add . && git commit ...。有的环境里 Claude 不会真执行 shell 命令,那就需要你在脚本里根据「本轮是否改动了文件」自己做一次 commit
于是整个流程就是这样:
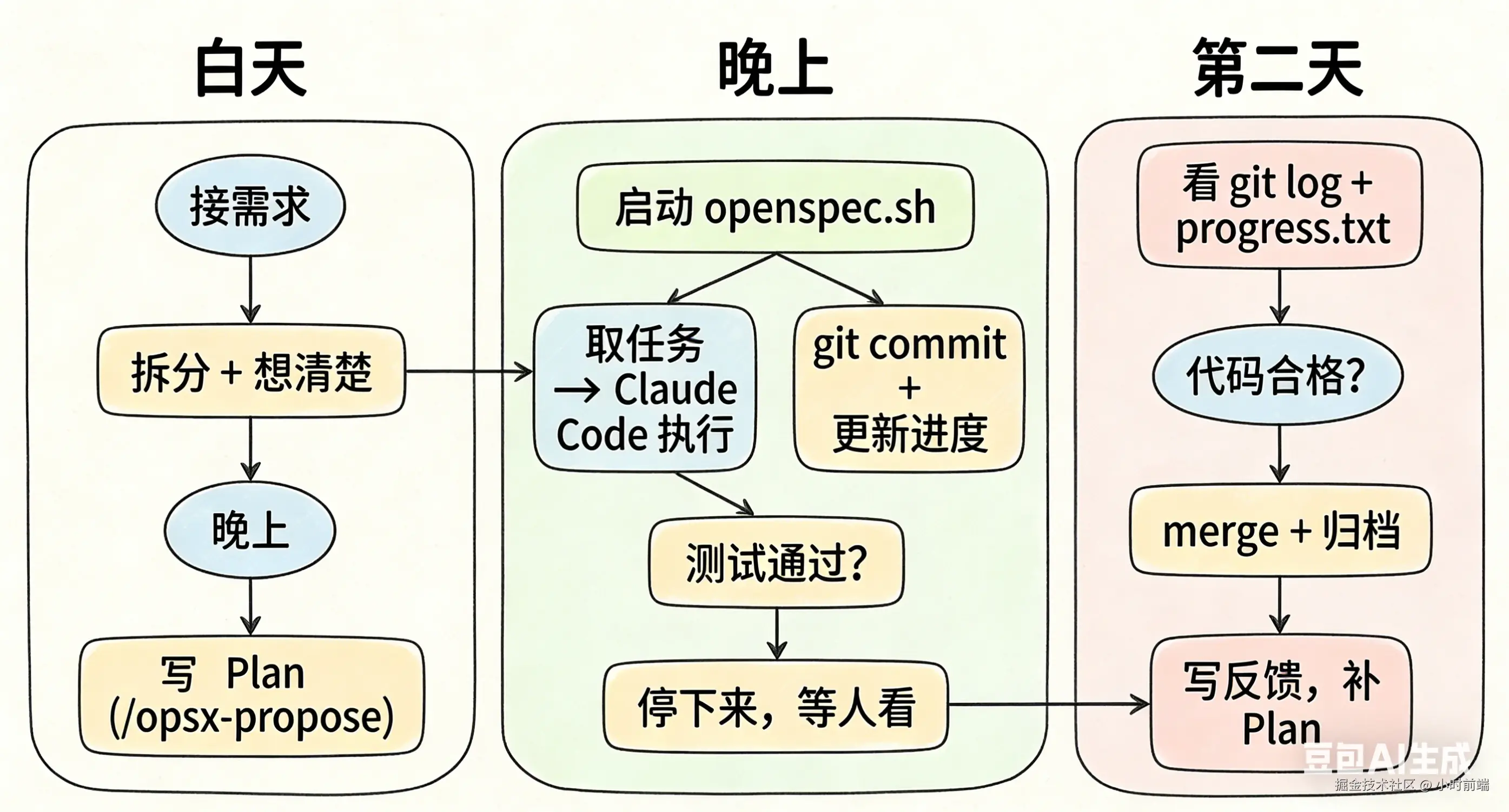 白天想清楚,晚上让 AI 跑,第二天审结果。
白天想清楚,晚上让 AI 跑,第二天审结果。
用 OpenSpec 把 Plan 写厚
具体做法是在 prd.json 里给每个任务加一个 openspecChange 字段,指向一个 OpenSpec 变更目录(完整 prd.json 见[附录 A](#附录 A "#%E9%99%84%E5%BD%95-a-prdjson-%E7%A4%BA%E4%BE%8B"))。AI 拿到任务后,去这个目录下读一整套文件:
bash
openspec/changes/add-frequency-rule/
├── proposal.md # 需求背景、方案设计、影响范围、不能动的部分
├── tasks.md # 可勾选的任务清单
└── specs/ # 本次变更的技术约定(字段校验、接口格式等)白天用 /opsx-propose 和 AI 一起把这几个文件写好。这个过程本身就是在想清楚------很多模糊的地方,是在写 proposal 的时候才暴露出来的。写完之后,晚上的循环脚本用 claude -p "/opsx-apply xxx" 触发执行,AI 会自动读这套文件,而不是靠 prompt 里的一段文字。完整脚本见[附录 B](#附录 B "#%E9%99%84%E5%BD%95-b-openspecsh-%E5%AE%8C%E6%95%B4%E8%84%9A%E6%9C%AC")。
另外两个值得说的设计:
progress.txt 做跨轮次记忆。 这是 Ralph Wiggum 原版最聪明的部分。每轮执行完 AI 往里追加一段笔记------做了什么、遇到什么问题、下一轮建议怎么做。下一轮开始先读它。git log 只记录"改了什么文件",progress.txt 记录的是"为什么这么改"。第二天你翻它就能还原 AI 整晚的决策过程。
归档让规范累积。 变更完成后用 /opsx-archive 归档,过程中产生的新规范会同步到 openspec/specs/。比如第一次跑"代码对比功能"时,specs 里约定了"所有的代码对比功能,采用code-diff组件"。归档后这条规范进了全局。下次跑"类似代码对比"时,AI 自动知道要用同样的组件------不用你再说一遍。跑得越多,AI 的上下文越完整。
跑起来之后,做了哪些优化
刚跑通的那个版本其实挺粗糙的。这几天陆续踩了一些坑,也针对性做了优化。
怎么确认 AI 真的干完了
这是夜间无人值守最核心的问题:你怎么知道 AI 不是「觉得自己做完了」就停了,而是真的做完了?
ralph.sh 的做法 就是 Stop Hook :每轮跑完后在 AI 的输出里查找预定义的「通关密语」RALPH_COMPLETE;没有就继续下一轮,直到出现或达到轮数上限。prompt 里要求 AI:只有当 prd.json 里所有 任务的 passes 都变成 true 后,才在输出里写 RALPH_COMPLETE。如果你不放心「AI 说自己做完」,可以在脚本里加一层校验:检测到 RALPH_COMPLETE 后,用 jq 查一遍 prd.json,确认所有 passes 均为 true 再 exit,否则打 log 并继续循环。
我的做法是两层校验:验收用 OpenSpec 工具先验证任务是否全部完成,通过后再更新 prd.json;完成判定由脚本用数据把关。 在 prompt 里要求 AI:本变更做完后用 OpenSpec 工具(如 openspec status、跑 acceptance)验证该变更已 all_done,通过后再把该 userStory 的 passes 标为 true 并写出通关密语(如 TASK_COMPLETE)。脚本侧不信任「AI 说自己做完了」:只有当输出里出现通关密语且 用 jq 查到 prd.json 里所有 userStory 的 passes 均为 true 时,才认为 PRD 真正完成并退出;否则会提示「Agent 报了完成但 prd 仍有未完成」并继续下一轮。
另外一个经验:给循环设一个硬性上限。 我一般设 50 轮。即使验证逻辑有漏洞导致循环不退出,最多跑 50 轮也会自动停。这是防止"夜间烧钱"的最后一道安全网。
怎么节约 Token 消耗
夜跑最容易被忽视的成本就是 Token。每轮迭代 AI 都要读上下文、生成代码、跑完流程------几十轮下来消耗很可观。
几个有效的优化:
1. 状态外部化,不靠对话历史。 这是 Ralph Wiggum 原版就有的设计------每轮迭代是一次独立调用,AI 通过读 progress.txt 和 prd.json 恢复上下文,而不是把之前几十轮的对话全塞进 prompt。这样每轮的 Token 消耗是恒定的,不会随轮次增长。
2. 任务粒度要小。 一个大任务拆成几个小任务,每个任务的 proposal 更短、specs 更聚焦,AI 每轮需要读的上下文就少。实测下来,三个小变更比一个大变更的总 Token 消耗还少------因为大变更里 AI 经常在一个问题上反复尝试。
3. 高风险任务放前面。 架构决策、核心抽象这类容易出错的活优先跑。如果第 3 轮就翻车了,你只浪费了 3 轮的 Token。反过来,如果把它放在第 30 轮,前面 29 轮的工作可能都白费。
4. 先白天 HITL 调通,晚上再 AFK。 HITL(Human In The Loop)就是你在旁边盯着跑几轮,看 AI 的执行路径对不对、prompt 需不需要调。确认没问题了,再放到夜间无人值守。不要第一次就直接 AFK(Away From Keyboard)------那是在拿 Token 赌运气。
Plan 的质量决定一切
跑了几轮之后最深的体会:夜间跑得好不好,完全取决于白天 Plan 写得好不好。
有一次 proposal 里只写了"参考模块 A 的拖拽组件,实现模块 B 的配置功能",没说清楚模块 B 的细节、不能动模块 A 的拖拽组件。AI 把整个模块 A 的全部功能搬到模块 B 功能中,还顺手改了模块 A 组件的拆分以及逻辑抽象。第二天看 diff 才发现改动范围远超预期。
从那以后总结了几条写 Plan 的规则:
- 写清楚"不能动什么"比"要做什么"更重要。 AI 很擅长发散,但不知道哪些是禁区
- 验收标准必须是可机器验证的。 "性能提升 30%"不行(怎么测?),"编写测试用例,测试通过,pnpm run lint, pnpm run build通过"可以
- 一个变更只做一件事。 proposal 里如果写了"顺便把 XX 也重构一下",AI 真的会顺便重构,然后影响范围不可控
什么活适合夜跑
跑了几轮,初步有了手感:
特别适合的:
- 重构(目标明确、有测试兜底)
- 补测试(覆盖率从 40% 到 80%)
- 补文档(按现有代码生成)
- 依赖升级(升级 + 修 breaking changes)
- 按明确 spec 实现的小功能
- 代码风格统一(批量改命名、格式)
- 框架迁移(Options API → Composition API、Jest → Vitest)
不适合的:
- 需要产品现场拍板的交互设计
- 全新业务逻辑(没有参考,AI 容易偏)
- 成功标准模糊的探索性开发
- 涉及"潜规则"没写进 specs 的改动
实际案例:变量类型功能的一次夜跑
说个具体的。我们某业务系统需要支持多种变量类型加工------类型 A、类型 B、类型 C、类型 D......每种类型逻辑类似(都有基本信息、配置信息、使用信息三个区块),但字段、校验逻辑、联动关系各不相同。
以前的做法:写完第一个类型 A,然后复制粘贴改成第二个(类型 B),再改成第三个(类型 C)......每次都在做「理解上一个 → 改字段 → 改校验 → 调联动 → 改测试」的循环。三天出一个,全部变量类型开发完成要两周多。
用夜跑方案之后,流程变了:
白天我做的事: 先把第一个变量类型(类型 A)完整写好,确认质量没问题。把组件结构、props 接口、校验逻辑、测试模式写进 prd 的 description 或单独 spec 文件;为每种类型在 prd 里写一条任务------写清楚「这种变量有哪些字段、校验逻辑是什么、和类型 A 的差异、和后端接口如何调用」。(若用 OpenSpec,就写成 proposal + tasks + specs。)
晚上 AI 跑的事: prd.json 里排好优先级,./openspec.sh 50 启动。Claude 按 prd 一条条做:读 progress.txt、实现、跑测试、更新 passes、写 progress、commit,直到全部完成或到轮数上限。
第二天我做的事: 审 diff 和 progress.txt。个别细节调一下,merge。
一晚上跑完了 3 个类型的变量组件,包括对应的校验逻辑和测试。手写的话,这个量至少要一两周。
这就是这类前端特别适合这套方案的原因:相似功能多、模式固定、边界清晰。 你只需要把第一个做好、把模式写进 specs,剩下的就是 AI 的强项。
类似的场景还有很多:
- 文件下载&导入 --- 每种类型文件下载和导入不同,但下载和导入工具函数一样,写好 spec 就能批量生成
- 多环境上线校验 --- 已有的校验覆盖不全,把缺失的校验场景列成 tasks,AI 一条一条补
- 决策流可视化节点 --- 多种节点类型(条件节点、动作节点、分支节点......),每种的渲染和交互逻辑用 spec 描述清楚,批量实现
安全兜底
分支隔离。 AI 永远在独立分支上跑,绝不碰 main。万一结果不对,丢掉分支就行,不用回滚。
迭代上限。 前面说了,MAX_ITER 是最后的安全网。
第一次跑会有点不放心。 我中间看了几次 progress.txt。但结果还不错------小变更跑完了,commit message 写得很规范。后面就习惯了。建议第一次先拿一个小任务验证,确认流程没问题再逐步放量。
你也想试?从这里开始
不用一步到位。我也是从一个最小的变更开始验证的。
1. 装 Claude Code --- 确保本机能用 claude -p "hello" 调通(Claude Code 命令行)。
2. 准备三个文件 --- 把 openspec.sh 拷到项目根(或使用文末[附录 B](#附录 B "#%E9%99%84%E5%BD%95-c-ralphsh-%E8%84%9A%E6%9C%AC")),再建好 prd.json(见[附录 A](#附录 A "#%E9%99%84%E5%BD%95-a-prdjson-%E7%A4%BA%E4%BE%8B"))和空的 progress.txt。
3. 先白天手动跑一个变更 --- 在 Claude 里输入 /opsx-propose,写一个小需求(比如"给某个模块补一组单元测试"),和 AI 一起把 proposal 和 tasks 打磨好,再用 /opsx-apply 执行。这一步不上脚本、不夜跑,就是验证 AI 能不能按你的 Plan 正确干完一个活儿。
4. 觉得靠谱了,上夜跑 --- 下班前 ./openspec.sh 50,第二天看 git log 和 progress.txt。
最后
试了几天,最大的感受不是「效率高了」------虽然确实高了------而是我干的事变了。
以前一天:梳理需求 → 某模块的下载与导入优化 → 写代码 → 写校验 → 写测试 → 再来一个需求。 现在一天:梳理需求 → 想清楚需求如何做 → 写 Plan 和 Spec → 审代码 → 做架构决策。
重复性的实现交给 AI 夜跑,我把时间花在"梳理清楚需求,方案如何实现"上面。这反而让整体架构比以前更好了------因为你必须先想清楚方案,才能写出 AI 能跑的 spec。
Ralph Wiggum 那篇文章给了我一个关键的认知:自动化不需要复杂的系统。 一个 while 循环就够了。复杂度应该花在"想清楚要做什么"上面。
Claude-cli + OpenSpec 在这个基础上解决了规模化的问题:当任务不再是一两句话能说清楚的、当规范需要在多个变更之间传递------你需要比 prd.json 更结构化的东西。
但核心还是那个循环。还是那三个文件。还是那个一直在说 "I'm helping!" 的 Ralph。
相关链接:
- Ralph Wiggum: How to Make Claude Code Work While You Sleep with a Bash Loop --- 原文与 ralph.sh 思路来源
- Claude Code --- 命令行
claude -p所需 - OpenSpec 指南
附录
附录 A: prd.json 示例
json
{
"project": "task-manager-frontend",
"version": "1.0.0",
"description": "Frontend for task management application",
"backendAPI": "task-manager-api",
"_workflow": "openspec",
"_openspecNote": "每个 userStory.openspecChange 对应 openspec/changes/ 下的目录名。openspec.sh 会按优先级执行对应 OpenSpec 变更,变更 all_done 后将该 story 的 passes 改为 true。",
"techStack": {
"language": "TypeScript",
"framework": "React",
"buildTool": "Vite",
"stateManagement": "Zustand",
"styling": "Tailwind CSS",
"routing": "React Router",
"httpClient": "Axios",
"formHandling": "React Hook Form",
"validation": "Zod",
"testing": "Vitest + React Testing Library"
},
"userStories": [
{
"id": "FUS001",
"title": "应用布局与关于页",
"description": "标准应用布局(Header、左侧 Sidebar、主内容区、Footer),React Router 接入,首页与关于页路由,关于页展示项目简介、技术栈与使用说明",
"acceptanceCriteria": [
"MainLayout 含 Header、Sidebar、Outlet、Footer,路由 / 与 /about 可用",
"Sidebar 含「首页」「关于」导航,点击切换路由并更新主内容区",
"About 页展示项目名称、简介、技术栈、基本使用说明(静态内容)",
"浏览器刷新后 / 与 /about 路由与内容正确"
],
"priority": 1,
"passes": false,
"openspecChange": "home-layout-sidebar-about"
}
],
"projectStructure": {
"src/": {
"components/": "Reusable UI components",
"pages/": "Page-level components",
"hooks/": "Custom React hooks",
"store/": "State management (Zustand)",
"services/": "API service functions",
"types/": "TypeScript type definitions",
"utils/": "Utility functions",
"styles/": "Global styles and Tailwind config"
}
},
"constraints": [
"Each component must have at least 3 tests",
"Minimum test coverage: 80%",
"No any in TypeScript",
"Responsive design for mobile, tablet, and desktop",
"Atomic commits for each feature",
"每个 OpenSpec 变更完成后原子提交",
"Accessibility compliance (WCAG 2.1 AA)"
],
"setupInstructions": {
"1": "应用布局与关于页"
}
}附录 B: openspec.sh 完整脚本
bash
#!/bin/bash
# openspec.sh - Autonomous Coding Claude-cli 非交互 / 自动化模式)
# Usage: ./openspec.sh [max_iterations]
MAX_ITERATIONS=${1:-50}
ITERATION=0
COMPLETE_SIGNAL="TASK_COMPLETE"
echo "=== Openspec Coding Agent==="
echo "Max iterations: $MAX_ITERATIONS"
echo "Stop signal: $COMPLETE_SIGNAL"
echo ""
while [ $ITERATION -lt $MAX_ITERATIONS ]; do
ITERATION=$((ITERATION + 1))
echo ""
echo "--- Iteration $ITERATION of $MAX_ITERATIONS ---"
echo "Running claude -p (output below)..."
echo ""
# 保存当前 prd 状态,用于迭代后判断是否有"刚完成"的变更并自动提交
PRD_BEFORE=$(mktemp)
if [ -f prd.json ]; then cp prd.json "$PRD_BEFORE"; fi
PROMPT="You are an autonomous coding agent. Read prd.json and progress.txt. Execute OpenSpec changes linked from PRD.
INSTRUCTIONS:
1. In prd.json, pick the first userStory with passes: false (by priority order). Let CHANGE_NAME = that story's \"openspecChange\" (folder under openspec/changes/).
2. Apply that OpenSpec change:
- Run: openspec status --change \"CHANGE_NAME\" --json
- Run: openspec instructions apply --change \"CHANGE_NAME\" --json
- Read all contextFiles from the apply output (e.g. proposal, specs, design, tasks)
- Implement each pending task from the change's tasks file; after each task, mark it complete (- [ ] -> - [x]) in the tasks file. Tasks marked optional (可选) may be skipped and marked complete to proceed.
- If state is blocked or a task is unclear, add notes to progress.txt and do NOT write $COMPLETE_SIGNAL
3. After implementing: run pnpm test:run && pnpm build (or project's equivalent). If they fail, fix before continuing.
4. When the change is all_done (all tasks complete or optional ones skipped): run acceptance (test + build). If acceptance passes: set that userStory's passes to true in prd.json; add notes to progress.txt; commit: git add . && git commit -m 'feat: [openspec] CHANGE_NAME'
5. Only when EVERY userStory in prd.json has passes: true, write exactly: $COMPLETE_SIGNAL (do not write it if any story still has passes: false).
IMPORTANT: One OpenSpec change (one userStory) per iteration. Use openspec CLI; keep commits atomic."
# 实时输出并同时写入临时文件,便于检测完成信号(避免只打印标题后"卡住"的错觉)
RALPH_LOG=$(mktemp)
claude -p "$PROMPT" 2>&1 | tee "$RALPH_LOG"
OUTPUT=$(cat "$RALPH_LOG")
rm -f "$RALPH_LOG"
# 若 Agent 未执行提交,由脚本补做:有未提交变更且本轮有 story 从 passes:false 变为 true 时自动 commit
if command -v jq &>/dev/null && [ -f prd.json ]; then
COMPLETED_CHANGE=""
if [ -f "$PRD_BEFORE" ]; then
for id in $(jq -r '.userStories[]? | .id' prd.json 2>/dev/null); do
passes_now=$(jq -r --arg id "$id" '.userStories[] | select(.id==$id) | .passes' prd.json 2>/dev/null)
change_name=$(jq -r --arg id "$id" '.userStories[] | select(.id==$id) | .openspecChange // ""' prd.json 2>/dev/null)
passes_before=$(jq -r --arg id "$id" '.userStories[] | select(.id==$id) | .passes' "$PRD_BEFORE" 2>/dev/null)
if [ "$passes_now" = "true" ] && [ -n "$change_name" ] && [ "$passes_before" != "true" ]; then
COMPLETED_CHANGE="$change_name"
break
fi
done
fi
if [ -n "$COMPLETED_CHANGE" ] && [ -n "$(git status --porcelain 2>/dev/null)" ]; then
echo ""
echo "=== 自动提交(任务已完成但未 commit)==="
git add .
git commit --no-verify -m "feat: [openspec] $COMPLETED_CHANGE" 2>/dev/null && echo "Committed: feat: [openspec] $COMPLETED_CHANGE" || echo "Commit failed (e.g. hook or git version). Run manually: git commit -m 'feat: [openspec] $COMPLETED_CHANGE'"
fi
fi
rm -f "$PRD_BEFORE"
# Check for completion signal AND verify prd.json (avoid false positive from LLM)
if echo "$OUTPUT" | grep -q "$COMPLETE_SIGNAL"; then
# Verify that all userStories in prd.json have passes: true
if command -v jq &>/dev/null; then
ALL_PASS=$(jq -r '[.userStories[]?.passes] | if length == 0 then "empty" else (all | tostring) end' prd.json 2>/dev/null || echo "error")
if [ "$ALL_PASS" = "true" ]; then
echo ""
echo "=== PRD COMPLETED! ==="
echo "All tasks have been implemented."
exit 0
else
echo ""
echo "=== WARNING: Agent reported $COMPLETE_SIGNAL but prd.json still has unfinished tasks (passes: false). Continuing. ==="
fi
else
# No jq: trust the signal only (original behavior)
echo ""
echo "=== PRD COMPLETED! ==="
echo "All tasks have been implemented."
echo "(Install jq to verify prd.json before accepting completion.)"
exit 0
fi
fi
# Pause between iterations (avoid rate limiting)
sleep 5
done
echo ""
echo "=== Iteration limit reached ==="
echo "Check progress.txt for current status."