Agent 协作与编排:核心原语解读
本文讨论的重点不是"什么是单个 Agent",而是多个 Agent 或多个能力单元如何协作、如何被编排、如何在长任务中保持可控。
"Agent 协作与编排"可先理解为:
在一个任务过程中,多个执行单元及其工具能力围绕共享目标进行分工、路由、控制权转移、状态传递、人工审批和结果整合的运行机制。
这里的关键不是 Agent 数量,而是控制权、上下文、状态和责任边界如何移动。
多 Agent 协作的价值在于:
- 专业化:不同角色需要不同指令、工具、模型或策略。
- 上下文隔离:避免一个 Agent 同时携带过多领域知识、工具说明和中间日志。
- 控制权清晰:需要明确谁负责下一步,谁负责最终对用户输出。
- 并行化:多个互不依赖的探索、测试、检索、审查任务可以同时执行。
- 治理边界:高风险工具、外部系统、代码执行或文件修改需要校验或人工审批。
- 可观测性:复杂工作流需要看到模型调用、工具调用、控制权转移和审批轨迹。
多 Agent 的本质不是"更多 Agent",而是把复杂任务切成可管理、可追踪、可恢复的责任单元。
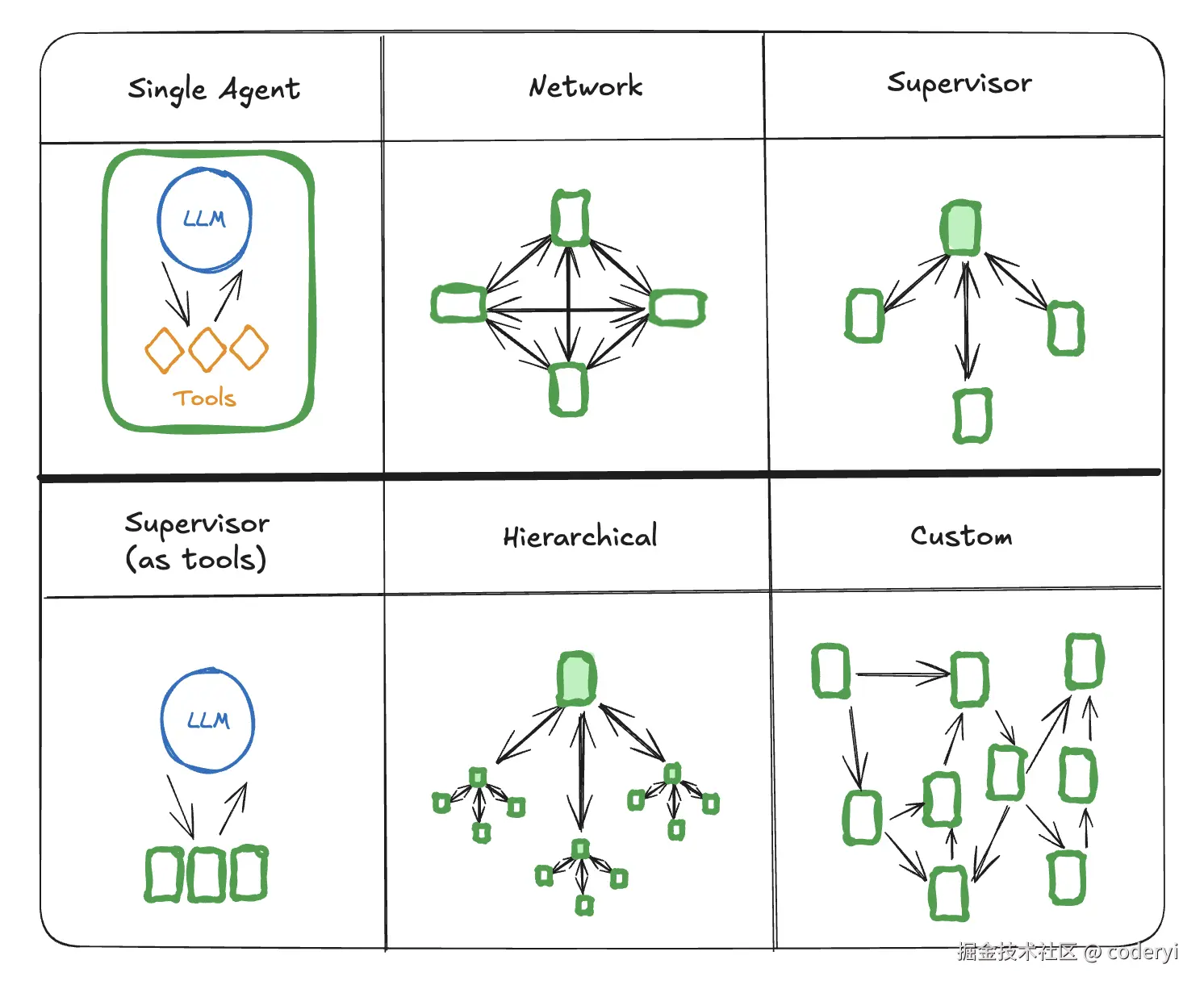 图片来自:LangChain.js 官方文档 Multi-agent。
图片来自:LangChain.js 官方文档 Multi-agent。
run loop:驱动任务推进的运行时循环
run loop 或 agent loop 是 Agent 运行时的基础循环。它负责在每一步判断当前任务是否已经完成,是否需要调用工具、转交给其他执行单元、等待外部输入,或继续推进下一步。
它不是多 Agent 独有的概念。单个 Agent 调工具同样需要 run loop;多 Agent 协作只是在这个循环中加入路由、委托、控制权转移、人工介入和状态恢复等机制。
不同系统可能把它实现为显式循环、图调度器或封装在运行时内部的执行机制,但概念层的含义一致:它是驱动整个工作流前进的底层节拍。
从运行视角看,一个典型的 run loop 通常长这样:
text
读取当前状态
-> 判断是否结束
-> 若未结束,决定下一动作
-> 调用工具
-> 路由到下一个节点 / Agent
-> 暂停,等待人工输入
-> 把结果写回状态
进入下一轮LangGraph 把这件事表示为图中的节点推进,即把显式循环展开成一张可调度、可暂停、可恢复的图。
状态:工作流的可执行事实集合
没有状态,就没有可靠协作。状态至少承担四类职责:
- 保存当前任务进展。
- 承载跨 Agent 传递的信息。
- 记录会话历史或短期上下文。
- 支持暂停、恢复、审计和重放。
这里的状态,指的是工作流当前可执行、可传递、可恢复的事实集合。它通常包括当前任务进度、中间结果、待处理动作、对话上下文、审批信息以及恢复运行所需的元数据。
状态不是简单的"记忆"。记忆偏向长期知识或历史压缩;状态偏向当前工作流的可执行事实。
在 LangGraph 的 persistence 文档里,状态不只是聊天文本的表层内容,而是每一步节点都会读取、更新,并在每个 super-step 被保存为 checkpoint 的运行事实。
状态通常可以概括为下面这类内容的组合:
text
用户当前目标
+ 已完成的子任务
+ 最近一次工具或 Agent 的输出
+ 下一步待执行的责任单元
+ 审批、恢复、重放所需的元数据
= 当前工作流状态路由:决定下一步责任归属的机制
路由回答的是:下一步由谁执行?
常见且能直接落到实现的路由形态包括:
- 代码路由:应用代码根据分类、规则、结构化输出或业务状态决定下一步。
- 模型路由:由模型根据当前上下文选择工具、handoff 或专家 Agent。
- 工作流路由:由预定义的节点、分支、条件或调度规则决定下一个责任单元。
- 并行分发:把多个相互独立的子任务同时交给不同执行单元处理。
- 固定工作流:执行顺序预先确定,只在局部使用模型或条件分支决策。
无论具体实现是规则判断、模型选择还是图调度,路由的本质都一样:在当前状态下决定"下一步由谁负责"。
多 Agent 架构中的 handoff 模式给出的直观图景是:每个 Agent 在本轮结束时,都会做两类决策之一,要么结束,要么把责任交给另一个 Agent;必要时,也可以把责任交还给自己,继续循环。
因此,路由本质上是"责任归属判断",而不是"内容生成本身":
text
当前状态
-> 判断下一责任单元
-> 继续由当前 Agent 处理
-> 交给另一个 Agent
-> 进入固定工作流节点
-> 并行分发给多个子任务
-> 结束handoff:控制权转移机制
handoff 的本质是控制权转移。它不是普通的能力调用,而是把当前任务、当前对话或当前分支的主导责任交给另一个执行单元。
这里至少要区分两种模式:
- 控制权转移:另一个执行单元接管后续处理,并对后续步骤负责。
- 能力调用:协调者仍保留主导权,只把专家当作一个有边界的能力来源。
这个区分非常重要。很多"多 Agent"设计混乱,根源就是没有区分"请专家帮忙"和"把控制权交给专家"。
不同框架未必都用 handoff 这个名字,但只要存在"责任主体发生切换"的机制,就可以在概念上归入控制权转移。
LangGraph 对 handoff 的描述非常具体,至少包含两件事:
- destination:把控制权交给谁。
- payload:交过去时附带哪些信息。
把这个区别拉开之后,很多抽象表述会立刻变清楚:
text
能力调用:协调者 -> 专家 -> 结果回到协调者 -> 协调者继续决定
控制权转移:Agent A -> Agent B -> Agent B 继续决定下一步sub agent:独立上下文中的子任务执行
sub agent 不是统一标准名,更通用的说法是"被委托的专家单元"或"并行工作单元"。它强调的不是上下级关系,而是把某个边界清楚的子任务放到相对独立的上下文里完成。
因此,sub agent 的本质不是"下级",而是:在独立上下文中完成一个边界清楚的任务,再把可消费结果交回协调者。
LangGraph 的多 Agent 文档把这件事讲得很直观:子任务执行单元可以选择共享完整历史,也可以只回传最终结果。
- 共享完整历史:后续单元看到前面所有消息与中间过程,透明,但更消耗上下文。
- 只回传最终结果:各单元保留私有中间过程,只把结论或结构化结果交回,更利于隔离复杂度。
这里的重点在于:它首先是上下文隔离单元,其次才是角色分工单元。
human in the loop 与 interrupt:人工参与与执行中断机制
human in the loop 是 Agent 协作和编排中的核心控制机制。它通常用于高风险或低容错环节,例如文件修改、命令执行、外部系统访问、敏感工具调用或需要用户确认的工作流步骤。
从概念上看,human in the loop 解决的是"哪些步骤不能完全自动决定";interrupt 解决的是"系统如何在那个时刻停下来,并在得到外部输入后从同一执行上下文继续"。
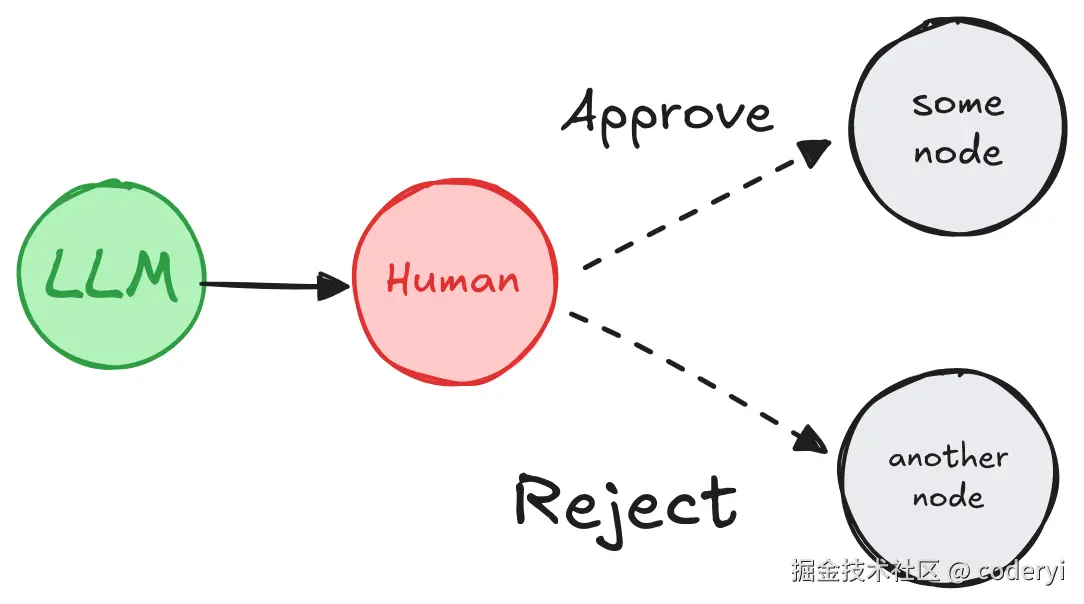
图片来自:LangGraph.js 官方文档 Interrupts。
这里要区分两个层次:
- human in the loop 是通用模式:人类参与审批、编辑、补充信息或否决。
- interrupt 是运行时机制:让工作流暂停并能从同一状态继续。
所以,interrupt 是实现 human in the loop 的关键原语之一,但并非所有框架都用这个名字。
LangGraph 的 review-tool-calls how-to 给出了一个非常直观的经典流程:模型提出动作后,系统不是只有"批准/拒绝"两种选择,而是至少有三种可执行分支。
text
模型提出工具调用
-> interrupt 暂停
-> 人工批准 -> 执行工具
-> 人工修改参数 -> 用修改后的参数执行
-> 人工反馈 -> 回到模型重新决策另一类同样经典的流程是"等待补充信息":Agent 主动停下,向用户索要一个关键输入,拿到之后再从原状态继续。这说明 human in the loop 不只是审批,也包括澄清、纠偏和补全上下文。
checkpoint 与可恢复状态:执行状态的持久化与恢复
checkpoint 更通用的理解,是在关键执行边界保存足够的运行状态,使系统能够暂停、恢复、审计、重放,必要时还可以从中间节点重新分叉执行。
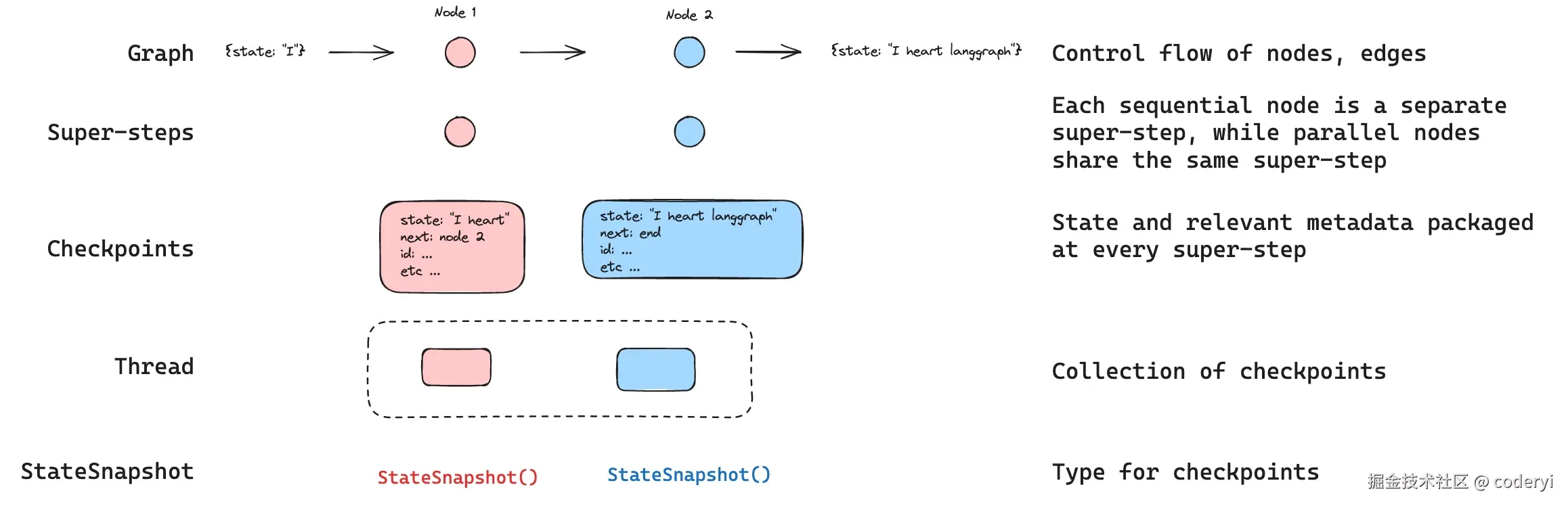
图片来自:LangGraph.js 官方文档 Persistence。
不同系统对这一能力的命名并不统一。有的直接称为 checkpoint,有的把它表达为可恢复状态、运行时持久化或会话级恢复机制。
因此,更稳妥的通用表述是"可恢复状态"或"持久化执行状态":
在关键执行边界保存足够状态,使运行可以暂停、恢复、审计、重放或分叉。
LangGraph 在这一点上的表达很清楚:checkpoint 不是"偶尔保存一下",而是在每个 super-step 保存一份状态快照,并把这些快照挂到某个 thread 下面。
其基本形态可以概括为:
text
thread
├─ checkpoint 0:收到初始输入
├─ checkpoint 1:某个 Agent 完成一步
├─ checkpoint 2:在人工审批前暂停
└─ checkpoint 3:恢复后继续执行因此,从运行机制的角度看,checkpoint 支撑的至少不只是"存档"这一个动作,还包括暂停后恢复、查看历史、从旧状态重放、从旧状态分叉。若按 LangGraph persistence 文档的能力口径,它进一步使 human-in-the-loop、memory、time travel 和 fault-tolerance 成为可能。
tracing 与可观测性:执行过程的记录与观测
复杂 Agent 协作如果不能被观察,就无法调试。tracing 与可观测性解决的是"系统实际做了什么、为什么这样做、在哪一步出了问题"。
trace 的核心价值不在于"日志更多",而在于把责任链看清。从工程观测视角,一个足够有用的执行轨迹通常需要回答下面几个问题:
- 当前处在哪个 thread 或 run。
- 哪个节点、哪个 Agent 在执行。
- 这一轮读了什么状态,写回了什么状态。
- 调用了哪个模型、哪个工具,结果是什么。
- 是否发生了 handoff、interrupt、resume、retry 或 error。
LangGraph 文档把 tracing、debugging 和 LangSmith 集成放在一起说明;在概念层上,这对应的是让多 Agent 系统里的几类关键事实变得可见:谁在做、做了什么、为什么停、交给了谁、最后状态如何变化。
参考资料
- LangGraph.js 官方文档:Overview、Persistence、Interrupts、Multi-agent、Durable execution。docs.langchain.com/oss/javascr...
- OpenAI Agents SDK 官方文档:Agents、Running agents、Orchestration and handoffs、Guardrails and human review、Results and state、Integrations and observability。developers.openai.com/api/docs/gu...
- OpenAI Agents SDK JS 官方文档:Handoffs、Human-in-the-loop、Sessions、Tracing、Agent orchestration。openai.github.io/openai-agen...
- OpenAI Codex 官方文档:Subagents。developers.openai.com/codex/subag...