
🎈主页传送门**:良木生香**
🔥个人专栏:****《C语言》 《数据结构-初阶》 《程序设计》《鼠鼠的C++学习之路》
🌟人为善,福随未至,祸已远行;人为恶,祸虽未至,福已远离

前言:在上一篇文章中,我们学习了C++的输入输出,缺省参数以及函数重载,这些都是C++入门必备的基础知识,那么在这篇文章中,我们就要来学习剩下C++其他的基础知识,那就是引用、inline、以及nullptr这些知识。
一、引用
1.1、引用的概念和定义
引用不是定义一个新变量,而是给已经存在的变量起一个别名,那么编译器就不会为别名重新开辟空间,它和引用变量共同使用同一块空间。就好比我们把土豆称为马铃薯 ,番茄称为西红柿一样,都是取了一个新的别名,但是东西是同一个东西,所以引用的语法如下:
类型& 别名 = 变量
使用方法如下:
cpp
int a = 10;
int& num = a;这样一来,num就是a的新名字,同时num的值也和a一样,是10。
在这里呢,C++为了避免引用太多的符号,就会复用C语言中的一些符号,在引用中,&的含义是给变量起别名,而不是C语言中的取地址!
1.2、引用的三个特性
1.2.1、引用在定义时必须初始化
在使用引用的时候,一定要先有被引用对象,不能在没有被引用对象的情况下使用引用:
cpp
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& num = a;//这是正确的,因为已经有了被饮用对象a
int& num;//这是错的!因为没有使用被引用对象!!!
return 0;
}说人话就是,不初始化就相当于"有人有一个外号叫小明",但是我们不知道是谁的外号叫小明,如果初始化了,那就相当于"张三的外号叫小明",这样一来,我们就知道小明是张三的外号。
1.2.2、一个变量可以有多个引用
一个变量,可以有一个两个三个别名:
cpp
#include<iostream>
using namespace std;
int main() {
int a = 10;
int& num1 = a;
int& word = a;
int& word2 = word;
cout << &a << endl;
cout << &num1 << endl;
cout << &word << endl;
cout << &word2 << endl;
return 0;
}在这段代码中,num1,word1,word2都是变量a的别名,也就是变量a有多个"外号"。
运行结果如下:
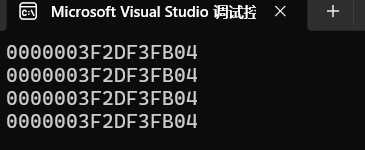
从运行结果就可以看出来,一个变量确实是可以有多个别名的,因为他们的地址都一样。
1.2.3、引用只能引用一个实体
当一个变量被引用而产生了一个新的别名,那么这个别名就只能用在这个变量身上,不能再去引用其他变量:
cpp
#include<iostream>
using namespace std;
int main() {
int b = 10;
int a = 20;
int& num1 = b;
int& num1 = a;//在这里就会报错
return 0;
}当我们运行这段代码,就会出现下面这种错误报告:

这就是告诉我们,num1引用了不止一个变量。用人话来说就是:张三有个外号叫小明,但是李四的外号也叫小明,这就会让朋友们造成困惑,小明到底指的是谁?这就是错误的,所以一个外号只能对应一个人。但一个人可以有多个外号。
小总结:引用必须在定义时就绑定到某个变量,不能 "先定义后绑定"。一个变量可以有多个引用(多个别名),但一个引用只能绑定到一个变量,且绑定后不能再指向其他变量。
1.3、引用的使用
引用的作用主要是用在函数传参和传返回值。C语言的函数传参方式是通过拷贝实参传入形参,当数据量非常大的时候,会让函数栈帧的压力非常大,导致效率降低,尤其是在传入指针的时候,极易出现空指针、野指针的相关问题,安全性差,为了解决这个问题,祖师爷就让引用来解决这类问题。
场景1:
为了更好的了解引用在实际编程中的作用,我们从一个简单的函数入手:
cpp
#include<iostream>
using namespace std;
void Swap(int* x, int* y) {
int temp = *x;
*x = *y;
*y = temp;
}
int main() {
int a = 10;
int b = 20;
cout << a << " " << b << endl;
Swap(&a, &b);
cout << a << " " << b << endl;
}这是一个非常简单的交换函数,程序在运行的时候要先拷贝一份实参在传入形参,然后再通过指针对形参进行解引用,才能完成交换这个动作,这样一来会降低编写的速度和程序运行的效率,但如果使用引用呢?请看VCR:
cpp
#include<iostream>
using namespace std;
void Swap(int& x, int& y) {
int temp = x;
x = y;
y = temp;
}
int main() {
int a = 10;
int b = 20;
cout << a << " " << b << endl;
Swap(a, b);
cout << a << " " << b << endl;
return 0;
}如果使用引用,那么在传参时就可以理解为:
int& x,int& y分别是main函数中a,b的别名,就相当于直接对a和b进行交换,传了别名进去就相当于传了我进去。在语法上就更加好理解,编写代码起来也就更加顺畅。
交换函数只是引用传参中的一个缩影,有没有更加高阶一点的用法呢?有的兄弟,有的。
场景2:
思绪回到我们学习数据结构的时候:在单链表(单项不带头结点不循环链表)中,我们是没有头节点的,就需要不断地使用二级指针将头节点的地址传进去:
cpp
#include<stdio.h>
#include<stdlib.h>
typedef struct ListNode {
struct ListNode* next;
int val;
}ListNode;
void Push_elem_front(ListNode** ppheadNode, int elem) {
//...
}
void Printf_elem(ListNode* pheadNode) {
//...
}
int main(){
ListNode* phead = nullptr;
//...
return 0;
}因为本质上是对头节点进行改变,但是有没有哨兵位,想要对链表进行操作只能是对头节点进行操作,也就是修改头节点指向的地址,想要修改头节点指向的地址,只能通过头节点地址的地址,也就是二级指针进行操作,这样一来会让人理解混乱,不容易编写代码,但是如果我们使用引用呢?请看VCR:
cpp
#include<iostream>
using namespace std;
typedef struct ListNode {
struct ListNode* next;
int val;
}ListNode;
void Push_elem_front(ListNode*& head_of_List, int elem) {
//...
}
void Printf(ListNode* phead, int elem) {
//...
}
int main() {
ListNode* phead = nullptr;
//...
return 0;
}在这段实例里面,尤其是在Push_elem_front()函数中,就是给phead起了个别名,叫做head_of_list,这样一来,就相当于直接将phead的地址直接传入函数中,就不用二级指针进行接收了,更加方便理解。
但是呢,这时候就有同学问了,为什么学校发的书写的是这样的:
cpp
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct ListNode {
struct ListNode* next;
int val;
}ListNode,*pListNode;
void Push_elem_front(pListNode& phead, int elem) {
//...
}
void Print_List(pListNode phead) {
//...
}
int main() {
pListNode phead = nullptr;
//...
return 0;
}为什么课本中只用了一个引用而已呢?为什么之前我们自己写的时候用的是二级指针一级指针?课本中却是一个都没用呢?原因就在这里:
cpp
typedef struct ListNode{
struct ListNode* next;
int val;
}ListNode,*pListNode;这段代码本来应该是这样的:
cpp
typedef struct ListNode ListNode;
typedef struct ListNode* pListNode;将链表节点的地址重命名为pListNode,这样一来,在函数参数中就可以直接对pListNode继续宁引用:pListNode& phead,等价于 ListNode* phead;
上面的两个场景就是引用在函数传参的经典使用场景
那么下面我们来讲讲引用在返回值上的使用:
场景3:
依旧是链表为例。我们在链表中总是要用到查找吧?就是通过指针遍历一次链表,看看哪个节点的值是符合要求的,就返回这个节点的值,我们之前是这么写的:
cpp
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct ListNode {
struct ListNode* next;
int val;
}ListNode;
int getNodeVal(ListNode* phead, int pos) {
ListNode* pcur = phead;
int count = 1;
while (count != pos && pcur!=NULL) {
pcur = pcur->next;
count++;
}
//...
return pcur->val;
}
int main() {
ListNode* phead = nullptr;
int pos = 2;
int num_of_pos = getNodeVal(phead, pos);
cout << num_of_pos << endl;
return 0;
}函数中返回的是pos节点的值,但是想要修改这个节点的值,我就需要将该节点的值的地址返回,通过解引用值的地址才能实现值的修改,但如果是引用的话,查找和修改简直是一举两得,请看VCR:
cpp
int& getNodeVal(ListNode* phead, int pos) {
ListNode* pcur = phead;
int count = 1;
while (count != pos && pcur!=NULL) {
pcur = pcur->next;
count++;
}
//...
return pcur->val;
}
int main() {
ListNode* phead = nullptr;
int pos = 2;
int num_of_pos = getNodeVal(phead, pos);
cout << "修改之前:" << num_of_pos << endl;
getNodeVal(phead, pos) = 200;
num_of_pos = getNodeVal(phead, pos);
cout << "修改之后:" << num_of_pos << endl;
return 0;
}那么在这段代码中,返回的就是节点的值的别名,可以直接通过别名对节点的值直接进行修改,但是有同学又要问了,为什么是getNodeVal(phead,pos) = 200就能实现值的修改呢?因为,这段代码的本质是这样的:
cpp
int& getNodeVal(phead,pos) = pcur->val;
getNodeVal(phead,pos) = 200;如果是这样我就理解了,但为什么函数结束之后还能通过引用找到这个节点的值呢?以为啊,节点是结构体,结构体是存在内存中的堆区,这样的话就算函数结束了这个节点的地址依旧可以被找到
那么上面三个场景就是引用在代码中实际应用中的表现了,这就解决了指针在这方面不够灵活的缺点。但是,下面就有两个问题了:
问题1:引用可以代替指针吗?
答案是不能。因为引用虽然能带来指针带不来的快捷,但是在需要用到修改指向问题的时候,只有指针能用,引用无法修改指向!!!像链表的插入呀,树,节点位置定义等等场景都是要用到指针的
问题2:可以返回临时变量的引用吗?
答案是不能,像下面的例子:
cpp
#include<istream>
using namespace std;
int& Func() {
int temp = 10;
return temp;
}
int main() {
int ret = Func();
return 0;
}这段代码运行起来会有这样一个报错:

也就是说,我们返回了一个临时变量的别名,这时不被允许的,为社么?因为当主函数要调用Func()函数的时候,系统会为Func()函数开辟空间,同时也为temp变量开辟空间,当函数执行完后,系统会回收函数的这部分空间,从物理上来说,temp变量在使用的时候是有位置的,但是系统回收空间后,原本是temp变量的位置现在temp已经不在了,但是那块地还在,算是人去楼空的状态了,这时候主函数在通过别名返回去找temp,就不一定找的到了,所以会报这么一个错误。
1.4、const引用
作用1:防止变量被修改
当我们在编写大程序的时候,希望我们的变量不要被修改,就可以用const引用:
cpp
int a = 10;
const int& num = a;
//num = 100 ,这时错误的,别名不能被修改这时就有同学要问了,const int& 和cost int 有什么区别?请看下面代码就明白了:
cpp
#include<iostream>
using namespace std;
int main() {
int a = 10;
//const int:
const int val = a;
a = 20;
cout << "after a change:" << val << endl;//此时val是不会受到a的影响,只会一直保持最开始的值
const int& num = a;
a = 20;
cout << "after a change:" << num << endl;//此时num会跟着a的改变而改变,因为num是a的别名,与a融为一体了
//val = 10
//num = 10这些都是错误的,因为被const修饰的值不能被修改!!!
return 0;
}还有就是如果原本的变量是const int 呢?那引用就只能用const int& ,
cpp
#include<iostream>
using namespace std;
int main(){
int a = 10;
const int& val = a;//这是对的
int& val2 = a;//这也是对的
const int b = 10;
const int& val1 = b;//这也是对的
//int& val3 = b; 这是错的!!!人家原本的变量都不能被修改,你这个别名怎么敢称为可修改值的?
return 0;
}作用2:效率优化
同样是在编写大程序的时候,如果函数中要传参的对象非常大,像结构体,数组这种,传统的拷贝传值是非常消耗内存的,严重的甚至会导致程序崩溃,但如果这时候用上const引用,问题就就迎刃而解了:
cpp
//C语言:传大的结构体,要拷贝100份(假设),开销极大
typedef struct { int arr[1000]; } BigStruct;
void read(BigStruct s) {}
//C++:只用传别名即可
void read(const BigStruct& s) {} 作用3:隐式类型转换(灵活兼容特性)
我们经常会将浮点数转换为整数,一般情况下我们是这么写的:
cpp
#include<iostream>
using namespace std;
int main(){
double a = 3.14;
//中间其实还有 int temp = (int)a这一步的
const int& b = a;
cout<<a<<endl;//输出3.14不变
cout<<b<<endl;//输出3
return 0;
}
那么以上就是const引用的内容了
1.5、引用和指针的关系
C++中指针和引⽤就像两个性格迥异的亲兄弟,指针是哥哥,引⽤是弟弟,在实践中他们相辅相成,功 能有重叠性,但是各有⾃⼰的特点,互相不可替代。
• 语法概念上引⽤是⼀个变量的取别名不开空间,指针是存储⼀个变量地址,要开空间。
• 引⽤在定义时必须初始化,指针建议初始化,但是语法上不是必须的。
• 引⽤在初始化时引⽤⼀个对象后,就不能再引⽤其他对象;⽽指针可以在不断地改变指向对象。
• 引⽤可以直接访问指向对象,指针需要解引⽤才是访问指向对象。
• sizeof中含义不同,引⽤结果为引⽤类型的⼤⼩,但指针始终是地址空间所占字节个数(32位平下 占4个字节,64位下是8byte)
• 指针很容易出现空指针和野指针的问题,引⽤很少出现,引⽤使⽤起来相对更安全⼀些。
二、inline内联函数
被inline修饰的函数叫做内联函数,编译时C++编译器会再调用的地方直接展开内联函数,并不会额外给函数建立栈帧,由此就提高了程序的编译效率。像这样:
cpp
#include<iostream>
using namespace std;
inline int add(int a, int b) {
return a + b;
}
int main() {
int a = 1, b = 2;
cout << add(a,b) << endl;
return 0;
}在调用反汇编的时候就能看到:

系统是直接将add的结果放到寄存器上面的,减少了add函数额外创建栈帧的开销,但如果没有inline修饰函数,将会是这样的:

会使用call指令跳转到add函数的位置,然后为add函数重新建立栈帧,这就会降低程序运行的效率
但是呢,inline内联函数对于编译器只是一个建议的作用,就是建议编译器将这个函数看成内联函数,但是要不要将其看成内联函数,就取决编译器了,如果这段代码使用递归等会消耗性能的时候,编译器也会将其看成普通的函数进行处理。
那么inline内联函数解决的是C语言的哪些问题呢?是宏。
C语言实现宏函数也会在预处理时将其展开,但是一旦函数复杂,那就很容易出错,且宏不容易调试,所以inline就是为了解决C语言宏的问题。
在一些代码量少但是被频繁使用的函数中,使用inline就能大幅减少时间。假设我现在有10000行带代码和一个20行的函数,要调用100次这段代码,使用内联函数就只用10020行,如果不使用inline函数,那就要用10000+20*100 = 12000行代码编译,性能差距还是非常大的。
小贴士:inline不建议声明和定义分离到两个⽂件,分离会导致链接错误。因为inline被展开,就没有函数地 址,链接时会出现报错。
三、nullptr
我们之前看见的NULL其实是一个宏,在C语言和C++环境下是由不同含义的:
cpp
#ifndef NULL//如果NULl还没有被定义,那就按照下面的方法对其进行定义:
#ifdef __cplusplus//如果是C++环境
#define NULL 0//那就将NULL定义成0
#else//如果是C语言环境
#define NULL ((void *)0)//那就定义成(void*)0,相当于空指针
#endif
#endif由于NULL在不同环境下被定义成不同的意思,所以为了方面编写,祖师爷就发明了nullptr这一个关键字,用来将所有指针类型初始化成空指针,这样就不会因为意思的不同而导致程序出错:
cpp
#include<iostream>
using namespace std;
void f(int x) {
cout << "f(int x)" << endl;
}
void f(int* x) {
cout << "f(int* x)" << endl;
}
int main() {
f(0);
f(nullptr);
f(NULL);
return 0;
}我们平时在初始化指针的时候都是喜欢用NULL,因此在上面这个程序中我们也希望NULL调用的是int*类型的,但是运行结果如下:
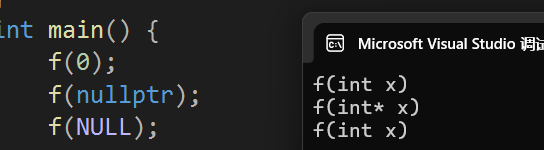
可见NULL在C++环境下调用的是int x类型的,这样就不能用于指针的初始化了,所以用nullptr是最好的方法
nullptr的出现就是为了让指针在定义的时候意义统一。
那么以上就是本次所有的内容了
文章是自己写的哈,有什么描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读~