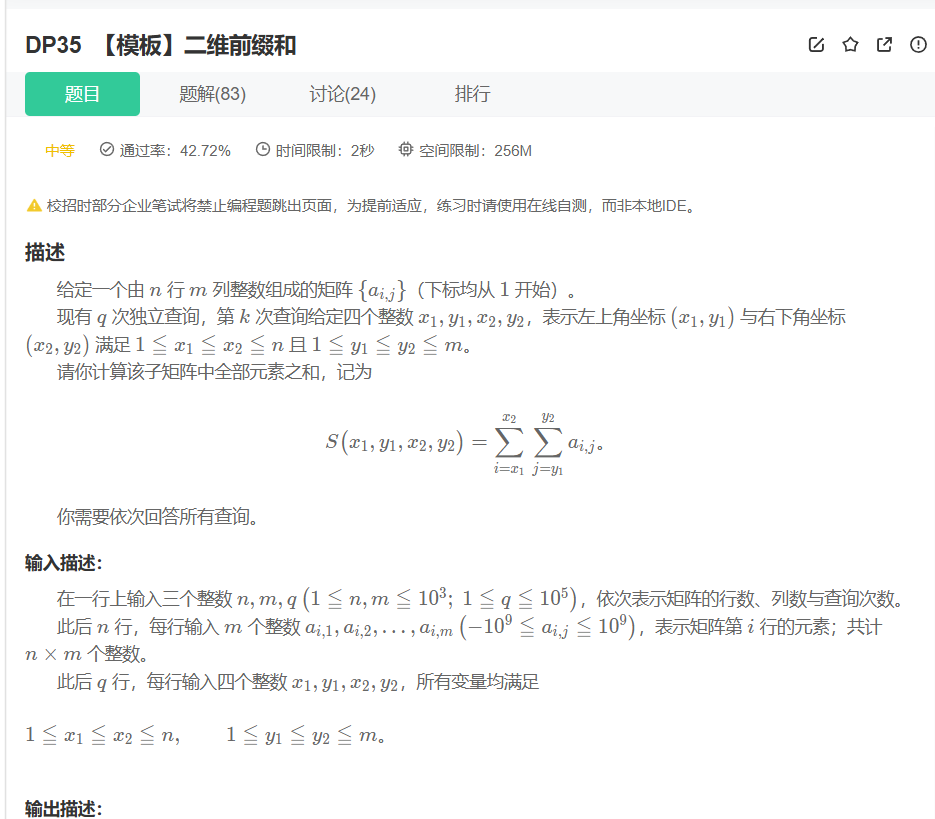
 有点难
有点难
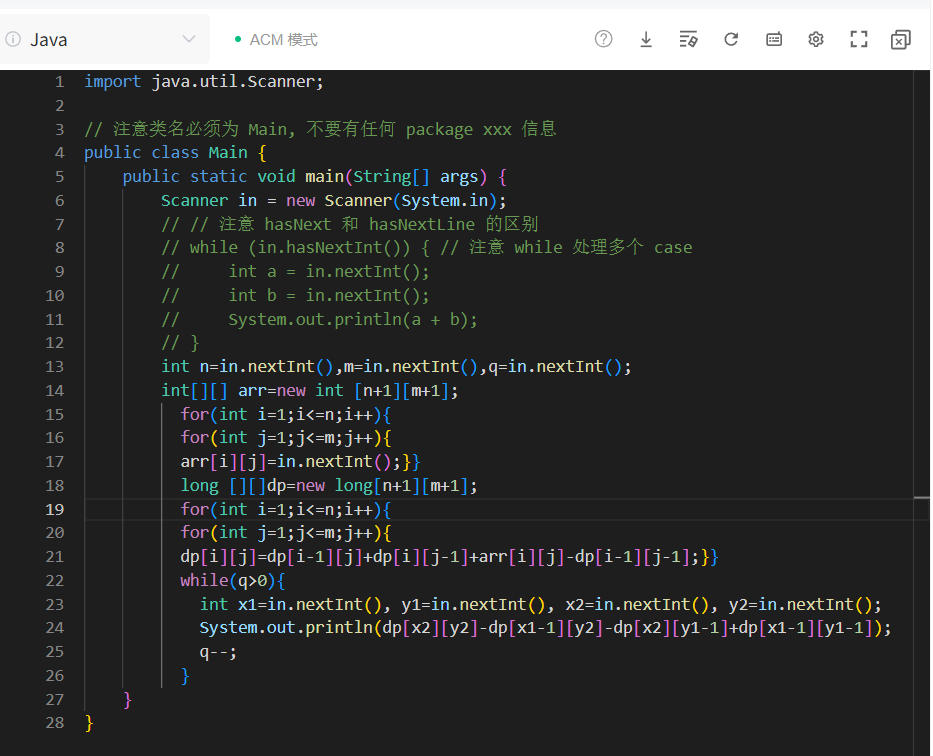
这份笔记详细记录了二维前缀和 的原理推导,这是算法竞赛和面试中非常经典的技巧。它主要用于解决**"快速计算矩阵(二维数组)中某子矩阵的元素和"**的问题。
1. 核心思想:降维打击
一维数组求区间和,我们用一维前缀和。
二维数组(矩阵)求子矩阵和,自然升级为二维前缀和。
-
暴力法:每次查询都遍历子矩阵,复杂度 O(m×n)。
-
前缀和法 :通过空间换时间,预处理出
dp数组,使得单次查询复杂度降为 O(1)。
2. 推导过程解析(看图说话)
(1) 定义:dpij是什么?
笔记中明确定义:dpij表示从 (1,1)到 (i,j)这个矩形区域内所有元素的和。
也就是以左上角为原点,右下角为 (i,j)的子矩阵的总和。
(2) 状态转移方程(最难理解的一步)
笔记中画了一个 2×2的小矩阵,标记为 A、B、C、D,这是推导的关键:
-
目标 :求右下角的块 D。
-
已知:
-
dpi−1j:包含了 A、B 的大矩形和。
-
dpij−1:包含了 A、C 的大矩形和。
-
arrij:就是 D 的值。
-
dpi−1j−1:包含了 A 的矩形和(多加了一次,需要减掉)。
-
推导逻辑:
如果我们把上面两个大矩形加起来(dpi−1j+dpij−1),中间的 A 区域被加了两次。
所以,我们需要减去一次 A(即 dpi−1j−1),再加上当前格子的右下角 D(即 arrij)。
得出公式:
dp[i][j]=dp[i−1][j]+dp[i][j−1]+arr[i][j]−dp[i−1][j−1](注:这个公式的前提是输入数组 arr的下标也从 1 开始,且 dp[0][x]和 dp[x][0]都为 0)
3. 查询逻辑(容斥原理)
笔记下半部分画了一个大方框套小方框的图,用来解释如何查询任意子矩阵 (x1,y1)到 (x2,y2)的和。
类比一维前缀和(suml...r=dpr−dpl−1),二维查询就是"大盒子减小盒子加重叠":
Sum=dp[x2][y2]−dp[x1−1][y2]−dp[x2][y1−1]+dp[x1−1][y1−1]-
dpx2y2:包含目标区域的超大矩形总面积。
-
减去左边多余列 (dpx1−1y2) 和 上边多余行 (dpx2y1−1)。
-
加上左上角多减的一次 (dpx1−1y1−1)。
4. 代码实现(Java 版)
结合笔记中的逻辑,以下是标准的 Java 实现代码:
public class TwoDPrefixSum {
public static void main(String[] args) {
// 假设输入数据如下(下标从1开始,补0方便计算)
// 3 4 表示 3行 4列
int[][] arr = {
{0, 0, 0, 0, 0}, // 第0行填充0,作为哨兵节点
{0, 1, 2, 3, 4}, // 第1行数据
{0, 5, 6, 7, 8}, // 第2行数据
{0, 9, 10, 11, 12} // 第3行数据
};
int m = 3, n = 4;
long[][] dp = new long[m + 1][n + 1];
// 1. 预处理(构建 dp 数组)
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 套用笔记中的公式
dp[i][j] = dp[i-1][j] + dp[i][j-1] + arr[i][j] - dp[i-1][j-1];
}
}
// 2. 查询示例:求 (2,2) 到 (3,3) 的子矩阵和
int x1 = 2, y1 = 2;
int x2 = 3, y2 = 3;
long result = dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1];
System.out.println("子矩阵和为: " + result); // 预期结果:6+7+10+11 = 34
}
}5. 总结与避坑指南
-
下标统一 :笔记左侧问"为什么下标从1开始?",这是因为这样可以完美避开数组越界,并且让
dp[0][...]和dp[...][0]自然变为 0,简化计算。 -
数据类型 :笔记中特意将
dp数组声明为long类型。这是因为矩阵求和很容易发生整数溢出 ,如果输入数据是int且矩阵很大,求和结果可能会超过int的最大值,必须使用long。 -
复杂度:
-
预处理:O(m×n)
-
单次查询:O(1)
-