什么是 RAG
RAG 全称为 Retrieval Augmented Generation,翻译为检索增强生成。其核心工作原理包含两个步骤:
- 检索:从资料库中检索相关内容
- 生成:基于检索到的内容生成答案
RAG 是目前最常用的 AI 问答方案之一,广泛应用于企业知识助手和智能客服系统。
RAG 解决的核心问题
传统方案的局限性
直接将完整文档发送给大模型(如 GPT-4O、DeepSeek 等)会遇到以下问题:
- 上下文窗口限制:每个模型只能处理一定量的信息,超过上下文窗口大小会导致"读了后面忘了前面"
- 推理成本过高:输入内容越多,成本越高
- 推理速度慢:输入内容过多会严重影响模型响应速度
RAG 的解决方案
RAG 通过以下方式解决上述问题:
- 将文档切分为多个片段
- 根据用户问题检索相关片段(如从上百页文档中找出 3 个相关片段)
- 仅将相关片段和用户问题发送给大模型
RAG 完整流程架构
RAG 流程分为两个主要部分:
数据准备部分(用户提问前)
- 分片(Chunking)
- 索引(Indexing)
回答部分(用户提问后)
- 召回(Retrieval)
- 重排(Reranking)
- 生成(Generation)
核心技术概念详解
向量(Vector)
向量是数学概念,代表有大小和方向的量,可用数组表示:
- 一维向量:
[1]、[-3] - 二维向量:
[2, 1]、[-1, 2] - 三维向量:
[1, 2, 3]
RAG 中使用的向量维度通常较大(几百到几千维),维度越大包含的信息越丰富。
Embedding
Embedding 是将文本转换为向量的过程。核心特点:
- 语义相近的文本对应的向量也相近
- 通过专门的
embedding模型完成(非 GPT-4O 等通用模型)
示例:
"马克喜欢吃水果" → 向量 [1, 2]
"马克爱吃水果" → 向量 [1, 1]
"天气真好" → 向量 [-3, -1]前两个句子向量相近,说明语义相关;第三个句子向量距离较远,说明语义不相关。
模型选择 :可参考 MTEB 排行榜评选最优 embedding 模型。
向量数据库
向量数据库专门用于存储和查询向量,具备以下特点:
- 为向量存储做了优化
- 提供向量相似度计算功能
- 存储内容包括原始文本和对应向量
典型数据结构:
| 原始文本 | 向量 |
|---|---|
| 马克喜欢吃水果 | 1, 2 |
| 天气真好 | -3, -1 |
五个核心环节详解
1. 分片(Chunking)
将完整文档切分为多个片段,常见方式:
- 按字数分片(如 1000 字一个片段)
- 按段落分片
- 按章节分片
- 按页码分片
2. 索引(Indexing)
索引流程包含两个步骤:
- 通过
embedding模型将每个片段文本转换为向量 - 将片段文本和对应向量存储到向量数据库
3. 召回(Retrieval)
召回是搜索与用户问题相关片段的过程:
- 用户问题发送给
embedding模型转换为向量 - 向量数据库计算向量相似度
- 返回最相关的 N 个片段(通常 10 个)
向量相似度计算方法
余弦相似度:
- 计算两个向量夹角的 cosine 值
- 夹角越小,相似度越高
欧氏距离:
- 计算两个向量间的直线距离
- 距离越小,相似度越高
点积:
- 考虑向量方向和长度
- 值越大,相似度越高
- 方向一致时为正值,相反时为负值,垂直时为 0
4. 重排(Reranking)
从召回的 10 个片段中精选出 3 个最相关的片段。
召回 vs 重排对比
| 特性 | 召回阶段 | 重排阶段 |
|---|---|---|
| 计算方法 | 向量相似度 | Cross-Encoder 模型 |
| 成本 | 低 | 高 |
| 耗时 | 短 | 长 |
| 准确率 | 低 | 高 |
| 适用场景 | 初步筛选 | 精挑细选 |
类比:召回像简历筛选(快速粗选),重排像面试环节(仔细精选)。
5. 生成(Generation)
将用户问题和重排后的 3 个相关片段一起发送给大模型,生成最终答案。
完整流程演示
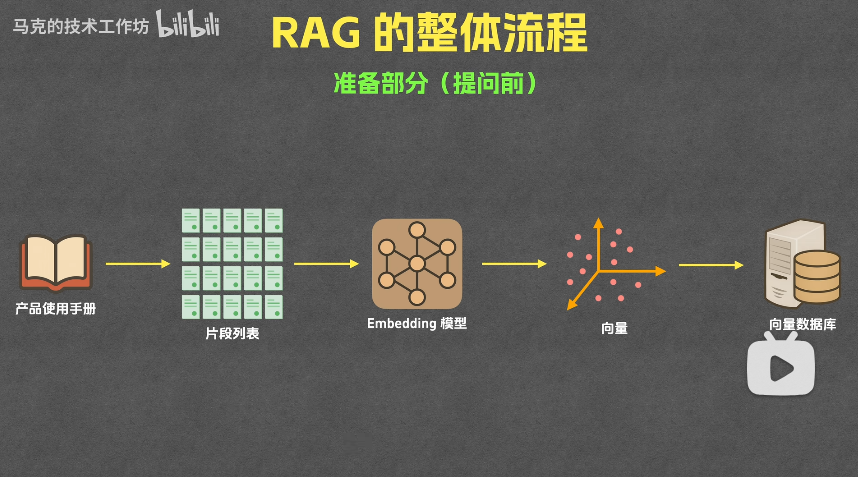
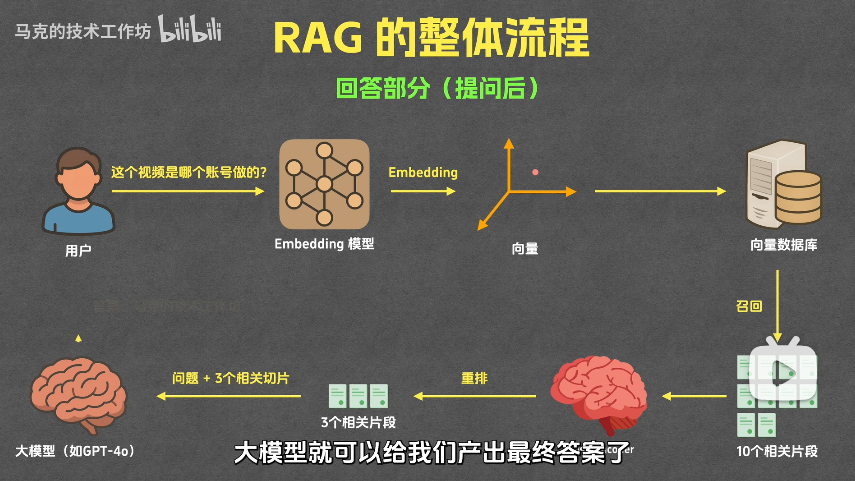
提问前的准备流程
原始文档
分片处理
Embedding模型
向量数据库
- 对相关资料进行分片
- 将所有片段发送给
embedding模型生成向量 - 将向量和原始文本存入向量数据库
用户提问后的处理流程
用户问题
Embedding模型
向量数据库查询
召回10个片段
Cross-Encoder重排
精选3个片段
大模型生成答案
- 用户问题通过
embedding模型转换为向量 - 向量数据库查找 10 个最相似片段
Cross-Encoder模型重排,选出 3 个最相关片段- 将 3 个片段和用户问题发送给大模型
- 大模型生成最终答案
技术要点总结
- 核心原理:先检索相关内容,再基于内容生成答案
- 关键技术:向量化表示、相似度计算、分阶段筛选
- 性能优化:通过召回+重排的两阶段设计平衡效率和准确性
- 应用场景:企业知识库、智能客服、文档问答系统
RAG 技术通过将复杂的文档检索问题转化为向量空间中的相似度计算问题,实现了高效准确的知识检索和问答生成。
参考来源:RAG 工作机制详解------一个高质量知识库背后的技术全流程