前面我们了解了 Kafka 的数据是如何存储的,今天我们来学习 Kafka 中另外一个重要的概念:副本。
写在前面
我们已经知道了数据在写入 Kafka 时,会先把数据写入到 Page Cache,之后再异步刷盘。不知道你有没有注意到一个问题,如果在数据刷盘之前 Broker 断电会发生什么,数据会不会丢失?带着这个问题,我们一起进入今天的主题。
什么是副本
我们知道 Kafka 有 Topic 的概念,Topic 下又分成多个分区,而副本则是在分区层级下定义的。一个分区可以有一个或多个副本,每个副本都需要保存相同的消息序列。
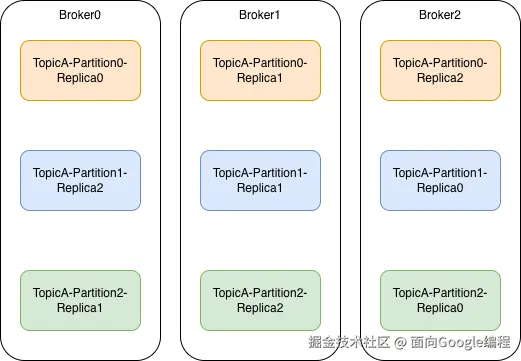
在生产环境中,通常需要部署多台 Broker,并把同一个分区下的副本部署到不同的 Broker 中,以此来保证单机问题不会影响集群整体的稳定性。
ISR 机制
既然多个副本之间要保持相同的消息序列,那么怎么才能保证数据一致呢?在 Kafka 中,副本分为 Leader 副本和 Follower 副本。只有 Leader 副本对外提供服务,也就是 Producer 和 Consumer 都是与 Leader 副本交互。Follower 副本只是一味的异步从 Leader 副本拉取消息,然后写入到自己的日志中。
这里就会存在一个问题,如果 Follower 副本本身出现问题,或者 Follower 副本与 Leader 副本之间的网络出现问题,那么就会出现 Follower 的数据写入进度落后于 Leader 的情况。在什么情况下才算是 Follower 与 Leader 进度同步呢?
为了解决这个问题,Kafka 引入了 ISR 机制。ISR 是 In-Sync Replicas 的缩写,它表示一个副本的集合,在这个集合中的数据都被认为是与 Leader 同步的副本,Leader 副本本身也在 ISR 副本集合中。那么副本进入 ISR 集合的标准是什么呢?
首先我们知道了 Leader 副本一定在 ISR 集合中,Follower 副本需要与 Leader 副本保持同步才能进入 ISR 集合。这个"同步"的判定标准取决于配置参数 replica.lag.time.max.ms,在最新版本的 Kafka 中这个参数的默认值是 30 秒,也就是说如果一个 Follower 在 30 秒内没有向 Leader 发送同步请求,或者没有同步到 Leader 节点的 Log End Offset,那么它就会被踢出 ISR 集合。如果后面这个副本慢慢追上了进度,那么它还会被加进 ISR 集合。
默认情况下,如果当前 Leader 挂掉,Kafka 只能从 ISR 集合中选举出新的 Leader。大概的选举流程为:
- 参与选举:Follower 副本"提名"自己为新的 Leader。
- 提名协调:由 Zookeeper 或者 KRaft 完成,指定一个提名者为新的 Leader。
- 提名通知:通知所有副本,将新的 Leader ID 下发。
- 选举完成:客户端请求会路由到新的 Leader,所有客户端可以继续进行读写操作。
如何保证数据不丢
了解了 ISR 机制之后,我们再来讨论最开始提到的问题,Broker 挂掉之后,数据会不会丢失。如果 Broker 上有 Leader 副本,就会触发选举,我们一定是希望新的 Leader 是和旧 Leader 的数据完全同步的,这样的话新的 Leader 的 PageCache 或者磁盘中就会有旧 Leader 未刷盘的这部分数据。
那如何才能保证 ISR 副本集合中有与旧 Leader 数据一致的副本呢?关键点在于两个配置:
acks=all 和 min.insync.replicas >= 2,即必须所有 ISR 副本确认同步完成才算写入成功,ISR 副本数必须大于等于 2(不满足的话数据会无法写入)。
总结
本文我们了解了 Kafka 的副本机制,多副本可以为 Kafka 集群提供了高可用能力。为了保证数据不丢,我们需要进行如下配置: acks=all 和 min.insync.replicas >= 2,保证 ISR 副本与 Leader 副本数据同步。
最后再留一个 hook,在介绍 ISR 准入条件时,我们提到其中一个判断条件是 Follower 要同步到 Leader 的 Log End Offset。你知道这个 Log End Offset 是什么吗?