在计算机的微观世界里,所有的数字最终都只是一串冷冰冰的、没有感情的 0 和 1。内存里的二进制位本身毫无意义,真正赋予它们灵魂的,是我们定义的"数据类型"。
为什么在 C 语言中,把一个大整数强行塞进小空间后,正数会突然变成负数?为什么看似简单的强制类型转换,常常是底层安全漏洞的罪魁祸首?
以下是 CSAPP 中关于整型数据类型的核心知识点、通俗解释以及实例。
1. 整数数据类型的大小
在 C 语言中,不同的数据类型分配到的字节数(Byte,1 Byte = 8 bits)是不同的,而且这还取决于你的机器字长(32位或64位机器)。
| C 语言数据类型 | 字节数 (32位机器) | 字节数 (64位机器) | 作用与特点 |
|---|---|---|---|
char |
1 | 1 | 通常用来存字符,但本质是8位小整数 |
short |
2 | 2 | 短整型 |
int |
4 | 4 | 最常用的整数类型 |
long |
4 | 8 | 长整型(注意在 64 位机器上变大了) |
int32_t |
4 | 4 | 推荐用法 :精确指定为32位(包含在 <stdint.h> 中) |
核心提示: 为了避免代码在不同机器上跑出不一样的结果,现代 C 语言编程非常推荐使用 int32_t、uint64_t 这种显式标明位数的类型,而不是依赖模糊的 int 或 long。
2. 无符号整数(Unsigned)
无符号整数只能表示非负数(即 的数)。它的编码方式就是最基础的二进制转十进制。
假设我们有一个 位的二进制序列,记作
。
无符号整数的转换公式为:
实例解析(假设我们用 4个 bit 来表示整数,为了方便演示):
我们有一串二进制 1011。
-
第 0 位(最右):
-
第 1 位:
-
第 2 位:
-
第 3 位(最左):
-
总和 :
所以,无符号的 1011 在十进制中就是 11。
3. 有符号整数:补码(Two's Complement)
计算机如何用 0 和 1 表示负数?现代计算机几乎全部使用补码来表示有符号整数。
补码的核心在于:最高位(最左边那一位)变成了"符号位",并且它代表的是一个负权重。
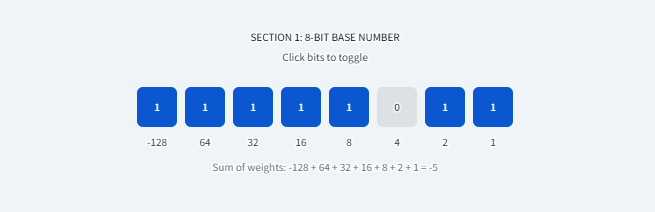
转换公式为:
实例解析(依然使用 4个 bit 的二进制 1011):
-
第 0 位:
-
第 1 位:
-
第 2 位:
-
第 3 位(最高位,负权重):
-
总和 :
所以,同样的二进制 1011,如果按照有符号整数(补码)来解释,它就是十进制的 -5。
思考: 为什么计算机喜欢用补码?因为有了补码,计算机底层的加法器就不需要区分正数和负数了。比如
3 + (-5),在 4 bit 补码下就是0011 + 1011 = 1110,而1110算出来正好是十进制的-2。一套硬件电路直接搞定所有加减法!
4. 有符号与无符号之间的强制类型转换
在 C 语言中,你可以把 int 强制转换成 unsigned int。CSAPP 在这里强调了一个极其重要的反直觉规则:
强制类型转换不会改变底层的二进制位,它只改变了计算机"看待"这串二进制位的方式(即改变了映射规则)。
cpp
short int v = -12345;
unsigned short uv = (unsigned short) v;-
-12345作为 16 位有符号整数,底层的二进制补码是11001111 11000111。 -
当你把它转换成无符号整数
uv时,内存里依然是11001111 11000111。 -
但是按照无符号数的计算方式(最高位的负权重变成了正权重),这串数字现在表示的值变成了 53191。
注意: 当 C 语言在执行包含既有有符号数又有无符号数的运算时,会隐式地将有符号数转换为无符号数,这常常是各种奇葩 Bug 的来源。
5. 扩展与截断
当我们需要把一个较小的数据类型放到一个较大的数据类型中时(比如从 short 转到 int),计算机需要"扩展"位。
-
零扩展(Zero Extension): 用于无符号数。直接在前面补 0。
- 比如:无符号的 4 位
1011(11) 变成 8 位就是00001011(11)。
- 比如:无符号的 4 位
-
符号扩展(Sign Extension): 用于有符号数。把最高位的符号位复制出去。
- 比如:有符号的 4 位
1011(-5),最高位是 1。变成 8 位就是11111011。你可以套用前面的公式算一下,11111011的十进制依然是 -5。这就保证了数值大小不变。
- 比如:有符号的 4 位
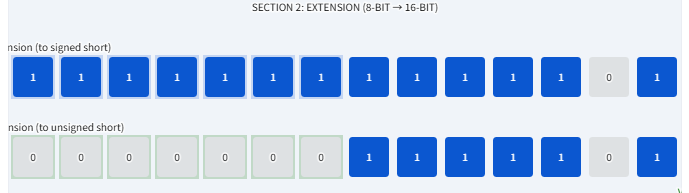
当把大的数据类型转为小的(比如 int 转 short)时,发生的是截断。计算机会直接丢弃多余的高位比特,这可能会改变数值,甚至改变正负号(如果新的最高位刚好变了的话)。
在C语言和底层硬件的交互中,"截断"(Truncation)是一个极易引发潜在Bug的机制。当你试图把一个占用字节数较多的大数据类型(比如 32位的 int)强行塞进一个占用字节数较小的数据类型(比如 16位的 short 或 8位的 char)时,就会发生截断。
CSAPP 对截断的解释非常暴力且直接:无视数值本身的意义,直接像切香肠一样,把多出来的高位(左侧)二进制比特全部砍掉,只保留低位(右侧)的比特。
下面我们分情况详细剖析。
1. 无符号整数的截断:本质是"取模"运算
假设我们将一个 位的无符号数截断为一个
位(
)的无符号数。
-
动作: 丢弃最高的
位。
-
数学意义: 相当于对原来的数值取
-
公式表示:
实例解析:从 8位 截断到 4位
假设我们有一个 8 位的无符号整数,值为十进制的 27。
-
底层二进制:
0001 1011 -
发生截断: 我们要把它存入一个 4 位的类型中。计算机会毫不留情地砍掉左边的 4 位
0001。 -
截断后结果: 剩下低 4 位
1011。 -
重新解释: 无符号的
1011在十进制中是 11。
验证数学公式: 。结果完全吻合。只要数值超出了小类型能表示的范围,它就会像钟表一样"绕回去"。

2. 有符号整数的截断:不仅变大小,还会"变性"
有符号整数(补码)的截断,在位操作上和无符号数一模一样 (同样是砍掉高位),但可怕的是,砍完之后,留下来的最高位会被强行当做新的符号位。这就导致不仅数值的大小会突变,连正负号都可能发生翻转。
- 公式表示:
实例解析:正数突变成负数
假设我们有一个 8 位的有符号整数,值为十进制的 11。
-
底层补码:
0000 1011(因为是正数,最高位是 0) -
发生截断: 将其塞入 4 位的类型中,砍掉左边的 4 位
0000。 -
截断后结果: 剩下低 4 位
1011。 -
重新解释: 现在的最高位变成了 1。在 4 位补码的规则下(最高位权重为
1011的计算过程是 -8 + 0 + 2 + 1 = -5。
结论: 原本的正数 11 ,经过截断后,摇身一变成了负数 -5!
cpp
#include <stdio.h>
int main() {
int big_number = 53191;
// 53191 的 32 位十六进制是 0x0000CFC7
short small_number = (short)big_number;
// short 是 16 位,截断后只保留后四位十六进制,即 0xCFC7
// 0xCFC7 作为有符号的 16 位补码,最高位是 1(负数)
printf("原始的 int: %d\n", big_number);
printf("截断后的 short: %d\n", small_number);
return 0;
}输出结果将会是:
原始的 int: 53191
截断后的 short: -12345
总结
计算机在做截断时是没有"智商"和"安全检查"的,它只负责机械地丢弃多余的比特位。这也是为什么在处理用户输入、网络数据包或者文件解析时,随意将 int 赋值给 char 或 short 常常会引发严重的安全漏洞。
你可能会问:像 Python 或者 JavaScript 这样的高级语言,数字再大也不会截断,为什么 C 语言不行?
-
Python 的做法: 当数字变大时,Python 在底层会自动去内存里寻找一块更大的新空间,把旧数据搬过去,换一个更大的"盒子"。这叫动态类型。
-
C 语言的做法: C 语言是用来写操作系统和底层驱动的,它的第一法则是绝对的执行速度和对内存的绝对控制。
-
如果每次赋值都要去检查"盒子够不够大,不够大就去申请新内存",这会消耗大量的 CPU 时钟周期(额外执行很多指令)。
-
C 语言选择把数据结构写死,直接对应 CPU 的寄存器大小。这样虽然不够安全,但极度高效。
-
既然物理上装不下,那计算机在发生截断时,为什么不干脆直接报错崩溃,或者**把数值锁定在小盒子的最大值(比如封顶在 32767)**呢?
-
为什么不自动报错?
在 C 语言的哲学里有一条铁律:"相信程序员(Trust the programmer)" 。C 语言假设你完全知道自己在干什么。很多时候,程序员是故意利用截断来做事情的!
比如:提取颜色值(RGB)、计算哈希值、或者做密码学里的取模运算。在这些场景下,截断(丢弃高位)正是算法需要的一步。如果编译器每次都报错,这些底层算法就没法写了。
-
为什么不封顶(饱和截断)?
把超出的值直接变成最大值(比如把 50000 变成
short的最大值 32767),这种做法叫"饱和算术"。这在处理音频(比如声音太大直接破音)或图像时很有用。但是,在基础数学逻辑中,直接截断(即取模运算)能保持更好的数学一致性(比如
其实,"截断"本身不是一个动作,而是"强行把大数据放进小空间"所产生的自然物理后果。C 语言为了追求极致的速度,并且为了让程序员能随心所欲地操作内存,选择把这个"危险的权利"直接交给了你。这就好比 C 语言给了你一把极其锋利、没有护手的电锯,切木头很快,但一不小心就会切到手。
正因为如此,现代编程中有很多规范在避免这种错误(比如静态代码检查工具会警告你不要把大类型赋值给小类型)。