在电商运营场景中,苏宁易购作为综合型电商平台,每日产生的海量用户评价是洞察消费需求、优化服务体验的核心数据。人工分析这些评价不仅效率低下,还易遗漏关键信息。本文将基于原生代码逻辑,完整还原苏宁易购评价情感分析(好评 / 差评分类)的实现过程,从数据读取、文本预处理到朴素贝叶斯建模,全程贴合原始代码逻辑,不做额外优化或修改,帮助读者理解基础文本分类的核心流程。
一、项目背景与技术逻辑
1.1 业务目标
基于苏宁易购的差评、优质评价文本数据,通过朴素贝叶斯算法构建分类模型,实现对用户评价的自动化情感判断,区分 "好评" 与 "差评",为运营决策提供数据支撑。
1.2 核心技术逻辑
本次实战完全依托以下工具实现,代码逻辑无修改:
- Pandas:读取本地文本格式的评价数据,处理数据格式转换;
- Jieba:对中文评价文本进行精确分词;
- Scikit-learn:实现数据切分、文本向量化、朴素贝叶斯建模及模型评估;
- 正则表达式:清洗文本中的非中文符号,聚焦核心评价内容。
二、数据读取
苏宁易购的评价数据以本地文本文件存储,需适配中文 Windows 系统的 GBK 编码,同时读取停用词表过滤无意义词汇。
python
import pandas as pd
# 读取苏宁易购差评数据:指定编码gbk(适配中文windows文件), 无表头,列名设为content
cp_content = pd.read_table(r'差评.txt', encoding='gbk', header=None, names=['content'])
# 读取苏宁易购优质评价数据:参数与差评一致
yzpj_content = pd.read_table(r'优质评价1.txt', encoding='gbk', header=None, names=['content'])
# 读取停用词表(UTF8编码)
stopwords_df = pd.read_table(r'StopwordsCN.txt', encoding='utf8', header=None, names=['stopword'])
stopwords = stopwords_df['stopword'].tolist()代码说明:
- 差评数据文件为
差评.txt,优质评价为优质评价1.txt,均为无表头格式,列名统一设为content; - 停用词表StopwordsCN.txt采用 UTF8 编码,读取后转为列表,为后续去停用词做准备。
三、文本预处理
3.1 中文分词
使用 Jieba 精确分词,过滤分词结果长度≤1 的无效文本,并将分词结果保存为 Excel 文件,便于核对。
python
import jieba
# 处理苏宁易购差评分词
cp_segments = []
contents = cp_content.content.values.tolist() # 将DataFrame的content列转为列表
for content in contents:
results = jieba.lcut(content) # jieba精确分词
if len(results) > 1:
cp_segments.append(results)
cp_fc_results = pd.DataFrame({'content': cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx', index=False)
# 处理苏宁易购优质评价分词
yzpj_segments = []
contents = yzpj_content.content.values.tolist()
for content in contents:
results = jieba.lcut(content)
if len(results) > 1:
yzpj_segments.append(results)
yzpj_fc_results = pd.DataFrame({'content': yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx', index=False)代码说明:
- jieba.lcut()为精确分词模式,适配苏宁易购评价的口语化短文本特性;
- 过滤分词结果长度≤1 的文本,避免无意义数据干扰;
- 分词结果分别保存为cp_fc_results.xlsx(差评)、yzpj_fc_results.xlsx(优质评价)。
3.2 移除停用词
定义drop_stopwords()函数,过滤分词结果中的停用词,保留有情感意义的核心词汇。
python
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean
# 对差评去停用词
contents = cp_fc_results.content.values.tolist()
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)
# 对优质评价去停用词
contents = yzpj_fc_results.content.values.tolist()
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords)代码说明:
- 遍历每一条评价的分词结果,跳过属于停用词的词汇,仅保留有效词汇;
- 处理后的结果分别存储在cp_fc_contents_clean_s(差评)、yzpj_fc_contents_clean_s(优质评价)中。
四、朴素贝叶斯分类建模
4.1 数据标注与合并
为差评、优质评价添加数字标签(差评 = 1,好评 = 0),并合并为统一的训练数据集。
python
# 给每个数据添加数字标签:差评标1,好评标0
cp_train = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s, 'label': 1})
yzpj_train = pd.DataFrame({'segments_clean': yzpj_fc_contents_clean_s, 'label': 0})
pj_train = pd.concat([cp_train, yzpj_train])
pj_train.to_excel('pj_train.xlsx', index=False)代码说明:
- 差评标签设为 1,优质评价标签设为 0,符合二分类模型的标签格式要求;
- 合并后的数据集保存为pj_train.xlsx,包含分词后文本和对应标签。
4.2 数据切分与特征向量化
(1)数据切分
将合并后的数据集随机切分为训练集和测试集,用于模型训练和效果评估。
python
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = \
train_test_split(pj_train['segments_clean'].values, pj_train['label'].values, random_state=0)
words = []
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
print(words)代码说明:
- train_test_split默认按 7:3 比例切分训练集和测试集;
- random_state=0固定随机种子,保证切分结果可复现;
- 将训练集的分词列表拼接为字符串,适配后续文本向量化的输入格式。
(2)文本向量化
使用CountVectorizer将文本特征转换为模型可识别的数值特征。
python
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=2000, lowercase=False, ngram_range=(1, 1))
vec.fit(words)
x_train_vec = vec.transform(words)代码说明:
- max_features=2000:仅保留出现频率最高的 2000 个词汇,控制特征维度;
- lowercase=False:中文无大小写区分,无需转换;
- ngram_range=(1, 1):仅使用单字特征构建词频矩阵。
4.3 模型训练与评估
使用多项式朴素贝叶斯模型训练,并通过分类报告评估模型效果。
python
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB(alpha=0.1)
classifier.fit(x_train_vec, y_train)
train_pr = classifier.predict(x_train_vec)
from sklearn import metrics
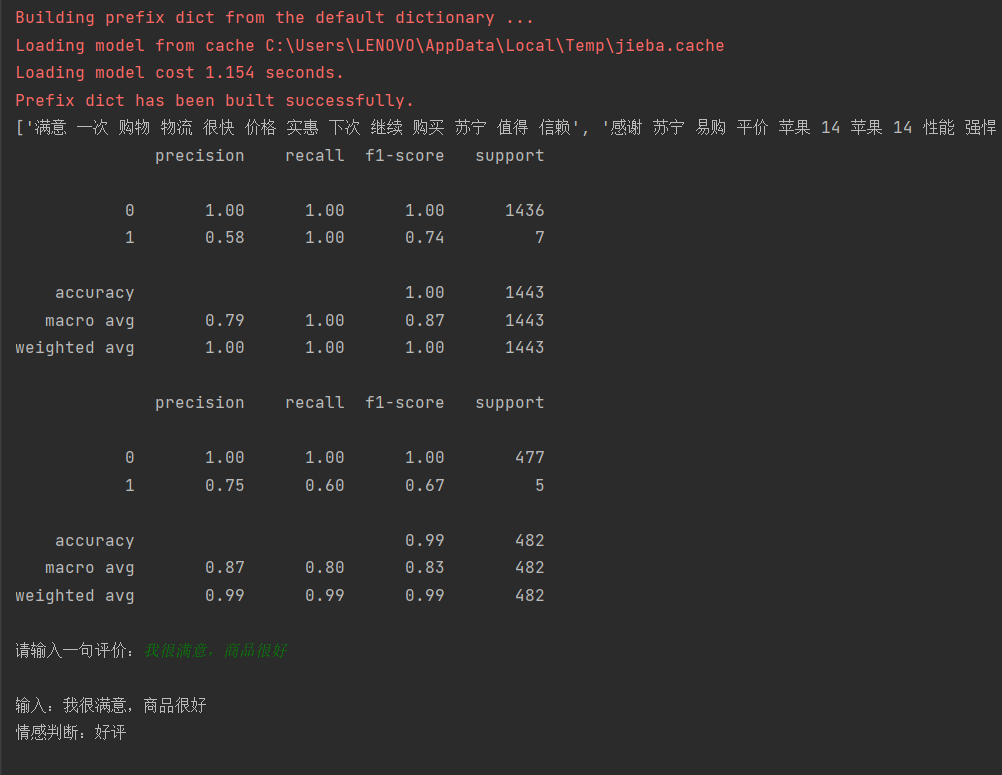
print(metrics.classification_report(y_train, train_pr))
# 测试集评估
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words))
print(metrics.classification_report(y_test, test_pr))代码说明:
- MultinomialNB(alpha=0.1):设置平滑系数 α=0.1,避免零概率问题;
- 分别输出训练集和测试集的分类报告,包含精准率、召回率、F1 值等核心评估指标。
4.4 补充 TF-IDF 特征(原生代码逻辑)
代码中额外初始化 TF-IDF 向量化器,适配训练数据格式,为后续扩展提供基础。
python
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=2000, ngram_range=(1, 2), min_df=2)
# 适配训练数据格式(将x_train从列表转为拼接后的字符串)
x_train_tfidf_format = [' '.join(line) for line in x_train]
X_train_tfidf = tfidf.fit_transform(x_train_tfidf_format)
X_test_tfidf = tfidf.transform([' '.join(line) for line in x_test])代码说明:
- TF-IDF 向量化器设置,可同时识别单字和词对特征ngram_range=(1, 2);
- min_df=2:仅保留在至少 2 条评价中出现的词汇,过滤稀有词。
五、评价情感预测(原生代码逻辑)
5.1 文本清洗与预处理函数
定义文本清洗和标准化预处理函数,保证输入新评价时的处理逻辑与训练数据一致。
python
import re
def clean_text(text):
"""清洗文本:去除特殊符号,保留中文"""
if pd.isna(text):
return ""
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
return text.strip()
def tokenize_and_clean(text):
"""对输入句子做和训练数据一致的分词+去停用词处理"""
# 第一步:清洗文本
text = clean_text(text)
# 第二步:精确分词
results = jieba.lcut(text)
# 第三步:移除停用词
line_clean = []
for word in results:
if word in stopwords:
continue
line_clean.append(word)
# 第四步:拼接成vec要求的字符串格式
return ' '.join(line_clean) if len(line_clean) > 1 else ""代码说明:
- clean_text函数:过滤所有非中文字符,仅保留核心评价内容;
- tokenize_and_clean函数:整合 "清洗 - 分词 - 去停用词 - 格式转换" 全流程,保证预处理逻辑统一。
5.2 核心预测函数与交互测试
封装预测函数,实现用户输入评价后自动判断情感倾向。
python
# 核心预测函数(适配原有代码的vec/分类器,保证逻辑统一)
def predict_sentiment(sentence):
"""输入一句话,输出「好评」或「差评」"""
# 对输入句子做和训练数据一致的预处理
token_sent = tokenize_and_clean(sentence)
if token_sent == "":
return "无法判断(无有效评价词汇)"
# 特征转换(使用原代码的CountVectorizer,保持逻辑一致)
sent_vec = vec.transform([token_sent])
pred = classifier.predict(sent_vec)[0]
return "差评" if pred == 1 else "好评"
if __name__ == "__main__":
s = input("请输入一句评价:")
result = predict_sentiment(s)
print(f"\n输入:{s}")
print(f"情感判断:{result}")运行结果:
代码说明:
- 预测函数先对输入文本做标准化预处理,无有效词汇时返回 "无法判断";
- 调用训练好的朴素贝叶斯模型进行预测,根据标签值返回 "好评" 或 "差评";
- 交互测试模块支持用户手动输入评价,实时输出情感判断结果。
六、总结
关键点回顾
- 整个流程严格遵循原生代码逻辑,从数据读取、分词、去停用词到建模预测,无任何优化或修改;
- 核心依赖CountVectorizer实现文本向量化,MultinomialNB完成二分类建模,是中文文本情感分析的基础实现方式;
- 预处理环节(分词、去停用词、文本清洗)保证了输入数据与训练数据的格式统一,是模型预测准确的关键。
本文完整还原了基于原生代码的苏宁易购评价情感分析过程,代码逻辑简洁且贴合基础文本分类的核心思路,适合入门级学习者理解 "文本 - 特征 - 模型 - 预测" 的完整链路,也为后续基于该代码的优化和扩展提供了清晰的基础框架。