SRP 不能做的本质是:
"把 Unity 的 Camera 组件机制换掉"
比如你不能让 Unity 不再依赖 Camera、完全用你自己的自定义组件直接接管引擎底层相机系统。
所以如果你问的是:
"SRP 能不能定义一套完全脱离 Camera Component 的相机系统?"
通常不行,至少不是按 Unity 这套标准 SRP 用法来做。
SRP 可以做的:
读取 camera.fieldOfView
读取 camera.cullingMask
读取 camera.clearFlags
读取 TryGetCullingParameters
根据不同 camera 走不同渲染逻辑
甚至直接在运行时改 camera.xxx 的值
SRP 不能做的本质是:
"把 Unity 的 Camera 组件机制换掉"
比如你不能让 Unity 不再依赖 Camera、完全用你自己的自定义组件直接接管引擎底层相机系统。
等编译的时候回答问题///
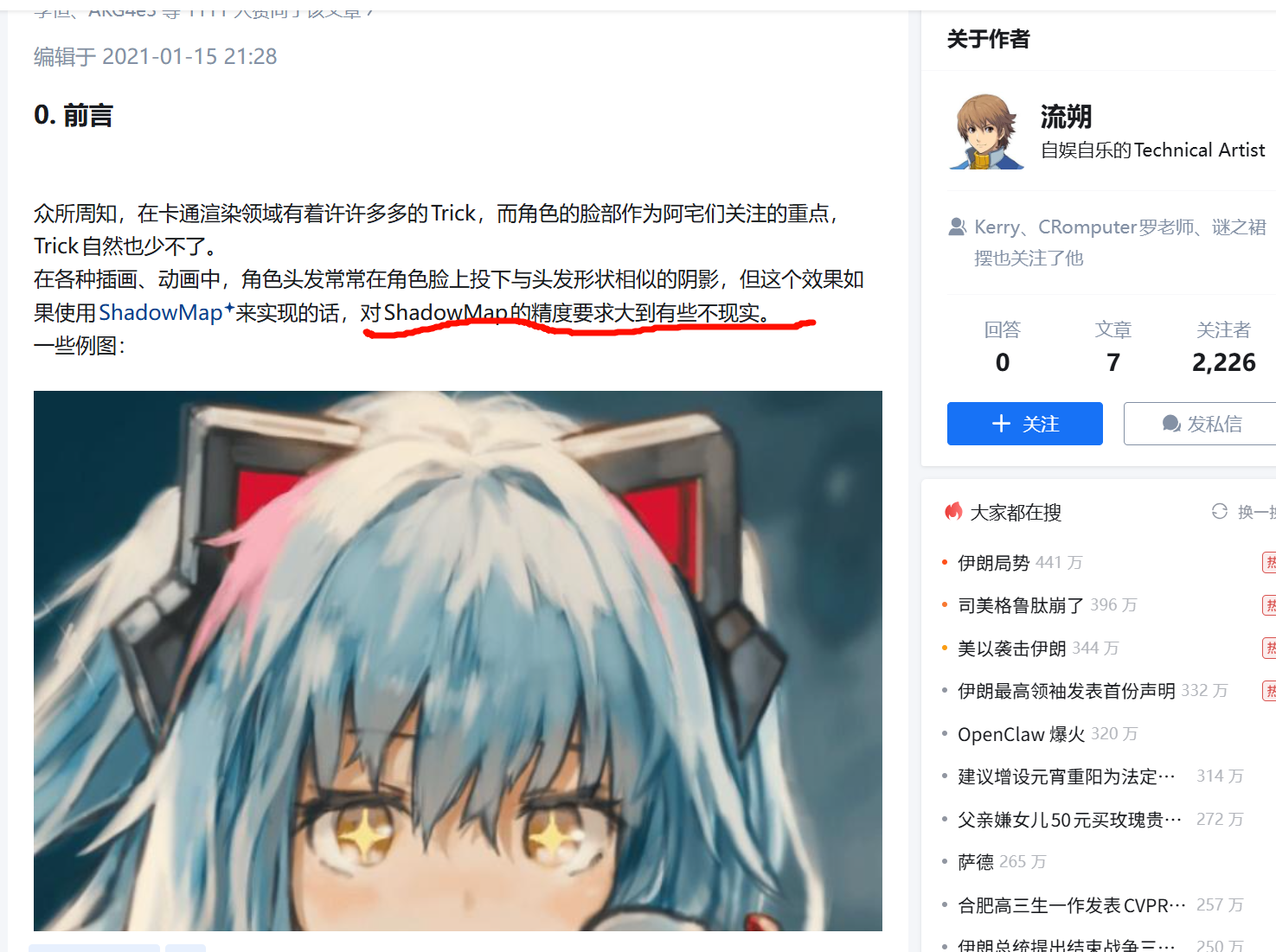
脸部阴影非常小且精细 。
头发在脸上形成的阴影通常是:
-
很细的发丝
-
很小的遮挡
-
非常靠近表面
例如刘海压在额头上那种阴影。
如果用普通 ShadowMap:
-
阴影贴图是从光源投影
-
分辨率固定
-
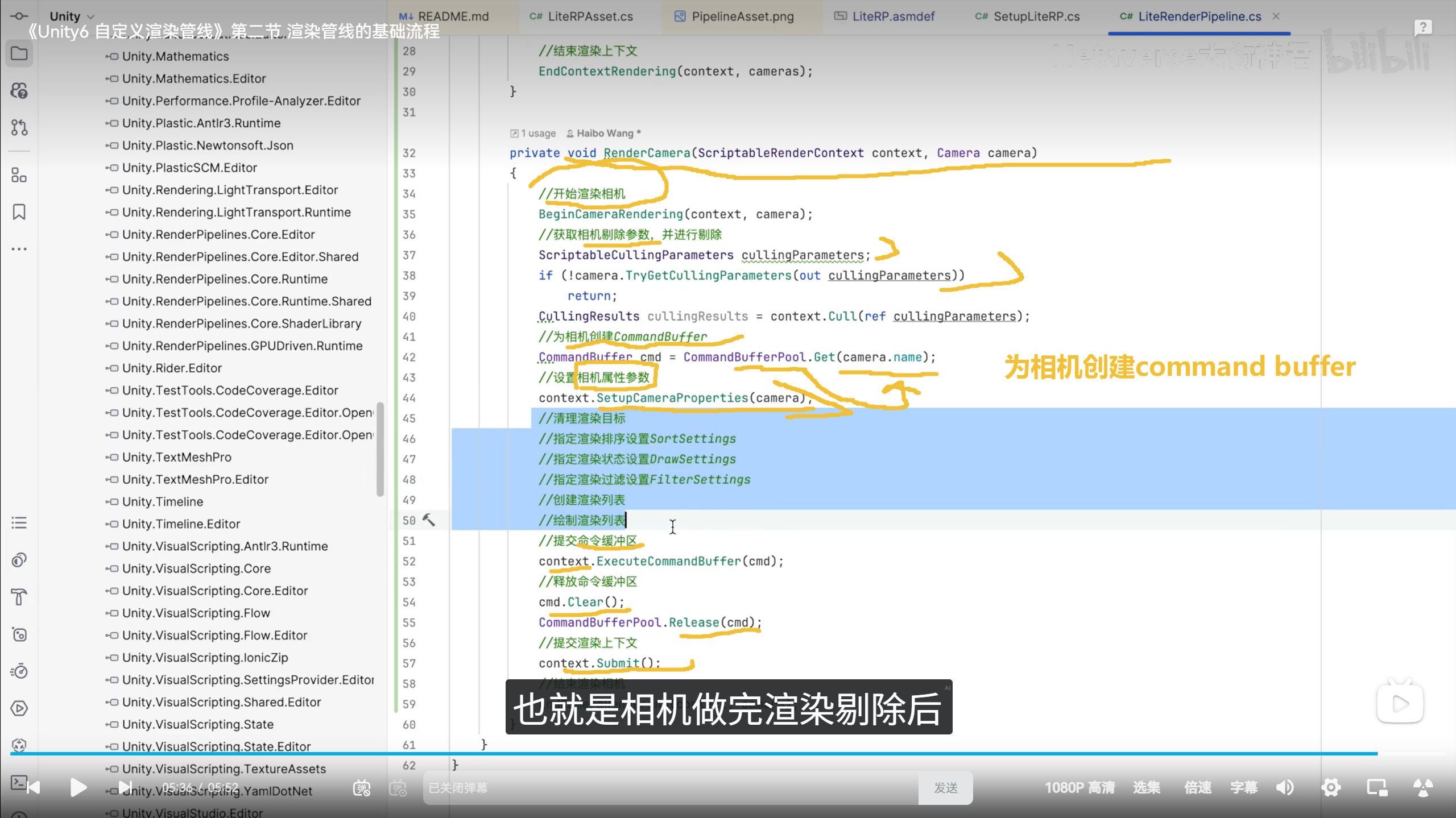
texel 覆盖世界空间面积
结果就是:
头发投到脸上的阴影只占几个 texel。
于是就会出现:
-
阴影锯齿
-
抖动
-
泳动
-
阴影断裂
阴影发生在非常近的距离。
头发和脸的距离可能只有:
1mm ~ 1cm
但 ShadowMap 是在光空间采样:
shadow_depth - receiver_depth
这种情况下:
-
bias 很难调
-
容易 acne
-
或者 peter-panning
尤其头发这种 薄几何体 会更明显。
第三,卡通脸部阴影其实不是物理阴影。
很多动画 / 游戏里,头发投到脸上的阴影是 艺术控制的效果:
例如:
-
阴影形状固定
-
不完全随光变化
-
保持脸型好看
-
防止眼睛被遮住
-
保证表情清晰
如果完全依赖 ShadowMap:
光方向变化 → 阴影完全变化
就会破坏角色表现。
所以很多项目会用 非真实阴影方案。
常见 trick 包括:
1. Ramp Shadow / Face Shadow Texture
在脸上用一张 mask:
dot(N,L) + mask
控制阴影区域。
例如:
脸左侧暗
脸右侧亮
并且和头发位置关联。
引擎很多系统都依赖 Camera
不只是渲染在用 Camera,还有:
SceneView
GameView
剔除
输入射线
Gizmos
后处理挂接
多相机排序
渲染目标
编辑器预览
这些都建立在 Camera 组件体系上。
如果 SRP 能随便替换 Camera,本质上就是允许你重写一大块引擎基础设施,Unity 并没有把权限开放到这一步。
真正需要"彻底替换 Camera 组件模型"的用户非常少。
大多数人只需要:
自定义渲染流程
自定义后处理
自定义 Pass
自定义相机控制逻辑
这些 SRP + 额外脚本已经够了。
Unity 没必要为了少数极深度用户,把整套核心对象系统开放出去。
Camera 在底层替你做的,核心就是两类事:定义"怎么看",以及把这个"看法"接进 Unity 整个引擎系统。
具体可以分成这些。
-
定义观察空间
它帮你维护:
位置和朝向
视锥体
FOV / 正交尺寸
near / far clip
投影矩阵
viewport rect
也就是"从哪里看、看多大范围、按什么投影看"。
-
提供剔除基础
Camera 会把和观察有关的剔除条件组织好,供你通过:
TryGetCullingParameters
拿出来用。
也就是它帮你把"这台相机理论上能看到什么"整理成统一输入。
-
维护渲染目标语义
比如这台相机要画到:
屏幕
RenderTexture
某个目标缓冲
还有深度、排序、叠加关系、多相机输出这些语义,都是 Camera 这层在组织。
-
虽然 SRP 可以不照它默认来做,但 Camera 本身还是维护了:
clear flags
background color
depth
HDR/MSAA 相关选项
stacking/输出优先级相关信息
这些都是"相机级渲染意图"。
-
和引擎其他系统对接

Camera 提供的是一套统一的"观察接口",运行时和编辑器里的很多系统都围绕这套成员工作。
比如同一套东西会被反复使用:
位置和朝向
投影参数
near/far
viewport
clear 相关设置
目标纹理
坐标转换接口
剔除参数来源
这样带来的好处是:
-
语义统一
不管是 Game、Scene、预览窗口,大家谈的都是"相机怎么看"。
-
系统可复用
很多功能不需要为运行时和编辑器各写一套完全不同的观察模型。
-
工具链更稳定
输入、Gizmos、预览、渲染调试都能挂在这套统一接口上。
既然有泛型了,这里为什么要pipeline shader tag?
因为这两者解决的不是同一个问题。
RenderPipelineAsset<BasicRenderPipeline>
是给 C# 类型系统和 Unity 运行时用的
它表达的是:
"这个 asset 会创建哪种 RenderPipeline 类"
而:
private const string RenderPipelineShaderTag = "LightweightPipeline"; public override string renderPipelineShaderTag => RenderPipelineShaderTag;
是给 shader 系统和构建流程用的
它表达的是:
"哪些 shader 认为自己属于这条渲染管线",必须给自己加上这个标签,防止错配,就和urp的shader里写urp tag才可以被加入渲染流程是一样的
大方向是对的,但要再收紧一点表述。
更准确地说:
- RenderPipeline tag 主要是声明"这个 Shader 面向哪条管线"
比如:
Tags { "RenderPipeline" = "LightweightPipeline" }
-
renderPipelineShaderTag 是你的 SRP 在 RenderPipelineAsset 里给出的"当前管线标识"
-
Unity 会拿这两个值做匹配,主要用于:
shader 归属识别
variant stripping
构建时筛选
所以你说的"防止错配"是对的。
但有一点要区分:
它不等于"只有写了这个 tag 才能被加入渲染流程"
真正++决定某个 Pass 会不会被画到的++,是你在渲染代码里用的 ShaderTagId,比如:
++new ShaderTagId++("SRPDefaultUnlit")
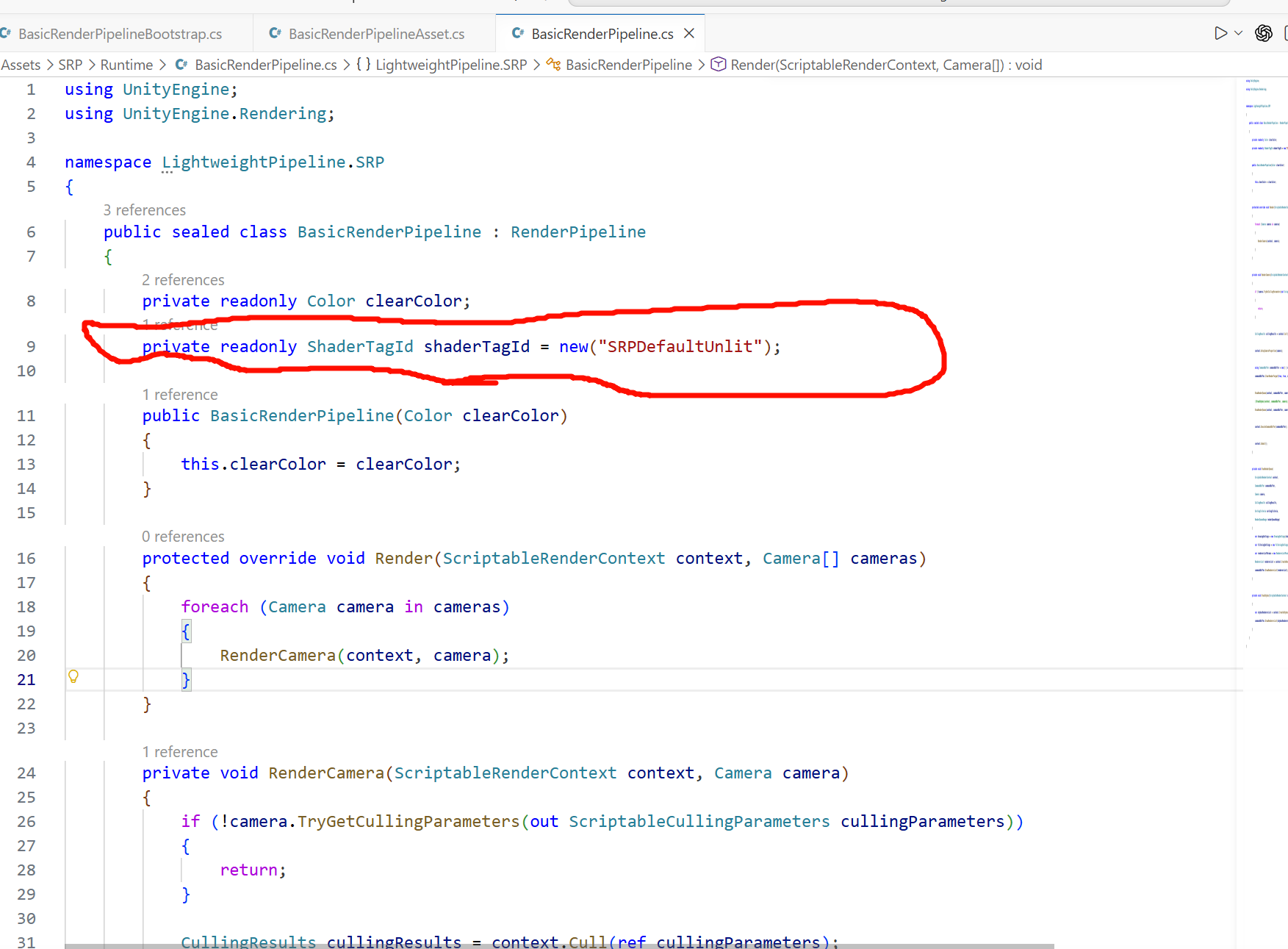
这是"Pass 级别匹配"。
而 RenderPipeline = "LightweightPipeline" 是"Shader 级别归属"。
所以:
泛型解决的是:
代码里的类型绑定
shader tag 解决的是:
shader 资源归属识别
为什么泛型不能代替 shader tag?
因为 shader 不是 C# 泛型对象。
ShaderLab / shader variant stripping / 构建流程不会靠 BasicRenderPipeline 这个 C# 类型名自动推断归属,它们需要一个明确的字符串标识去对齐,例如:
Tags { "RenderPipeline" = "LightweightPipeline" }
Unity 会拿 shader 里的这个字符串,去和 renderPipelineShaderTag 对比。
所以这两层关系是:
RenderPipelineAsset<BasicRenderPipeline>
告诉 Unity 代码层:"你会创建哪个管线类"
renderPipelineShaderTag
告诉 Unity shader 层:"哪些 shader 属于这条管线"
一句话:
泛型管 C# 类型关系,shader tag 管 shader 归属关系,两个都不能互相替代。
写 SRP 时,context 基本就是你和 Unity 渲染后端打交道的主接口之一。

头发投到脸上的阴影只占几个 texel。这个问题是srp可以解决的吗?首先,Camera组件是固定的,context是接渲染后端,阴影的形成,一次性看整个view box 深度,
单独挑出部分物体,渲染更精确的shadowmap?
这个要做,要更了解shadow的流水线
if (pixel 在头发投影区域)
darken
而不是 shadow map。
Hair Shadow Map(单独一张)---这是可以的
只让头发投影到脸:
render hair → small shadow map
apply only to face
这样分辨率集中在脸部。
脸阴影 = 手绘 mask
只根据光方向切换几种版本。
例如:
front light
side light
back light
ShadowMap 适合:
建筑
地面
大物体
远距离
但不太适合:
头发 → 脸
睫毛 → 眼睛
衣领 → 下巴
这种 极小遮挡 + 高艺术要求 的情况。
Tonemap(色调映射)在卡通渲染里的取舍。核心意思是:
标准 ACES Tonemap 对卡通渲染往往"过重",会破坏颜色风格,因此很多卡通项目会降低 ACES 强度,或者直接使用更简单的 Tonemap。
物理亮度、人眼感知与显示设备特性之间的三重矛盾。
RGB数码形式:颜色的数字化编码
计算机中的像素颜色通过RGB三通道数值定义,例如8位系统中每个通道取值范围为0-255(对应0-1的归一化亮度)。这些数值本质是对物理光强的线性采样结果,即数值翻倍理论上代表光强翻倍。但直接使用线性数据会暴露两个问题:
- 存储效率低下:8位精度下,线性编码会将55%的灰度级分配给人眼不敏感的高亮区域,导致暗部细节丢失;
- 显示失真:CRT及现代显示器(如LCD/OLED)的输出亮度与输入电压呈非线性关系(近似亮度=电压^2.2),直接输入线性RGB会使图像整体偏暗。
Gamma校正:非线性补偿的双重作用
Gamma校正通过幂运算对RGB数值进行非线性转换,形成"预补偿-显示补偿"的闭环:
- 预补偿(编码阶段):将线性RGB转换为非线性的sRGB空间,公式为非线性值 = 线性值^(1/2.2)。例如线性亮度0.218经此转换后变为0.5,使8位存储中暗部细节从55级提升至128级,匹配人眼对暗部更敏感的特性(韦伯定律)。
- 显示补偿(解码阶段) :显示器通过自身Gamma曲线(约2.2)将sRGB数值还原为线性亮度,即输出亮度 = sRGB值^2.2。例如存储的0.5经显示器转换后恢复为0.218的物理亮度。
也就是说rgb的颜色定义理论是在硬件显示之上的
所以图片的显示方式才可选择是否srgb
现代显示中的Gamma校正实践
- 硬件实现:显示器驱动芯片(如OLED的DDIC)通过Gamma查找表(LUT)优化转换效率,针对不同亮度等级(如低亮度采用PWM与电流混合驱动)动态调整参数。
- 软件适配:游戏引擎(如Unreal)需在光照计算前将sRGB纹理转换回线性空间,避免光照叠加错误(例如线性空间中0.5+0.5=1.0,而sRGB空间中0.5+0.5会导致过亮)。
- HDR扩展 :高动态范围内容虽使用32位浮点存储线性亮度,但最终仍需通过Tonemapping压缩至sRGB范围后,应用Gamma校正以适配显示设备。
计算的过程就是一直处于"少了符合人眼敏暗"的线性计算,所以最后才额外要^2.2,也就是gamma去压低
因为都是在01之间,所以压低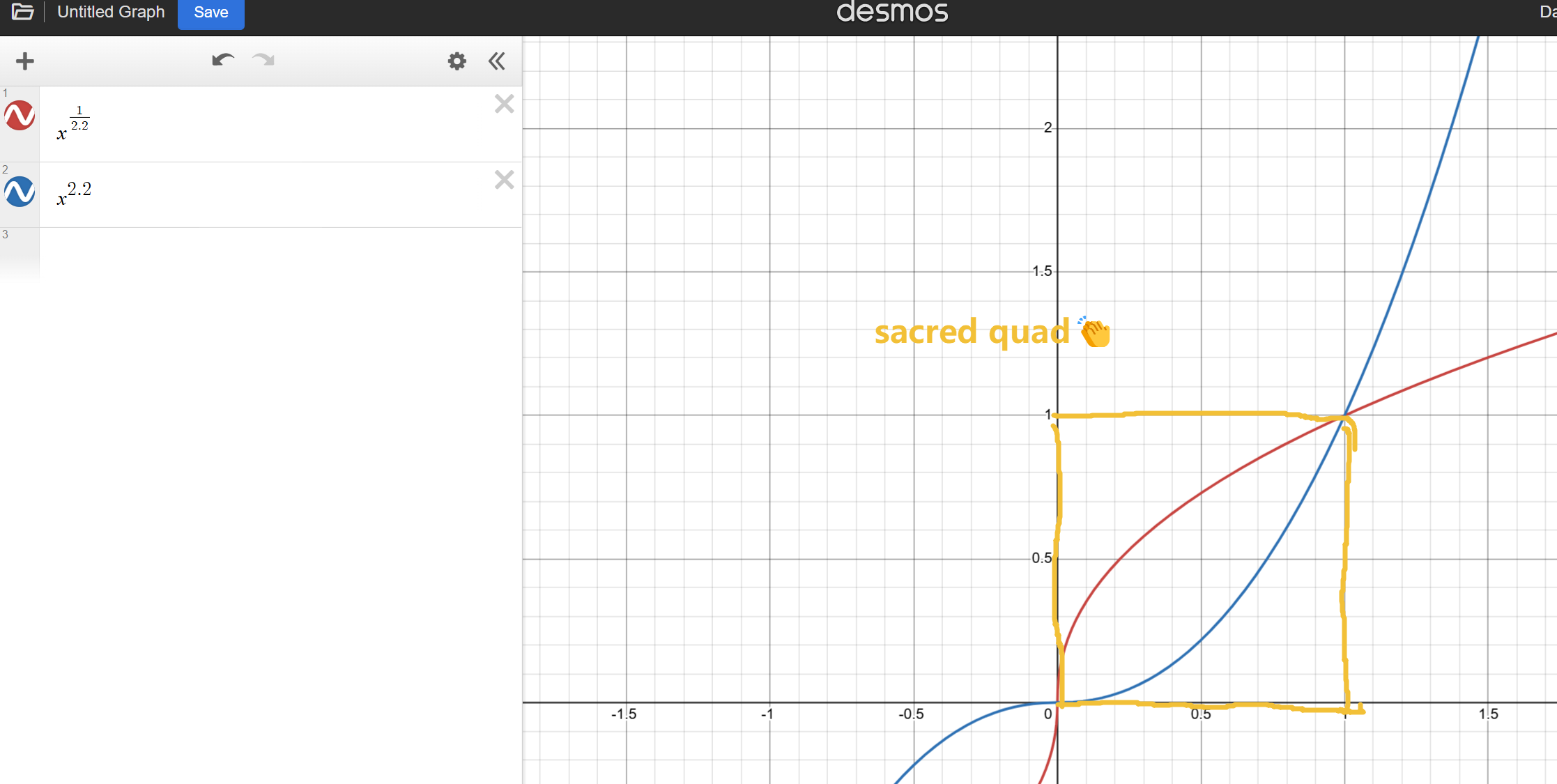
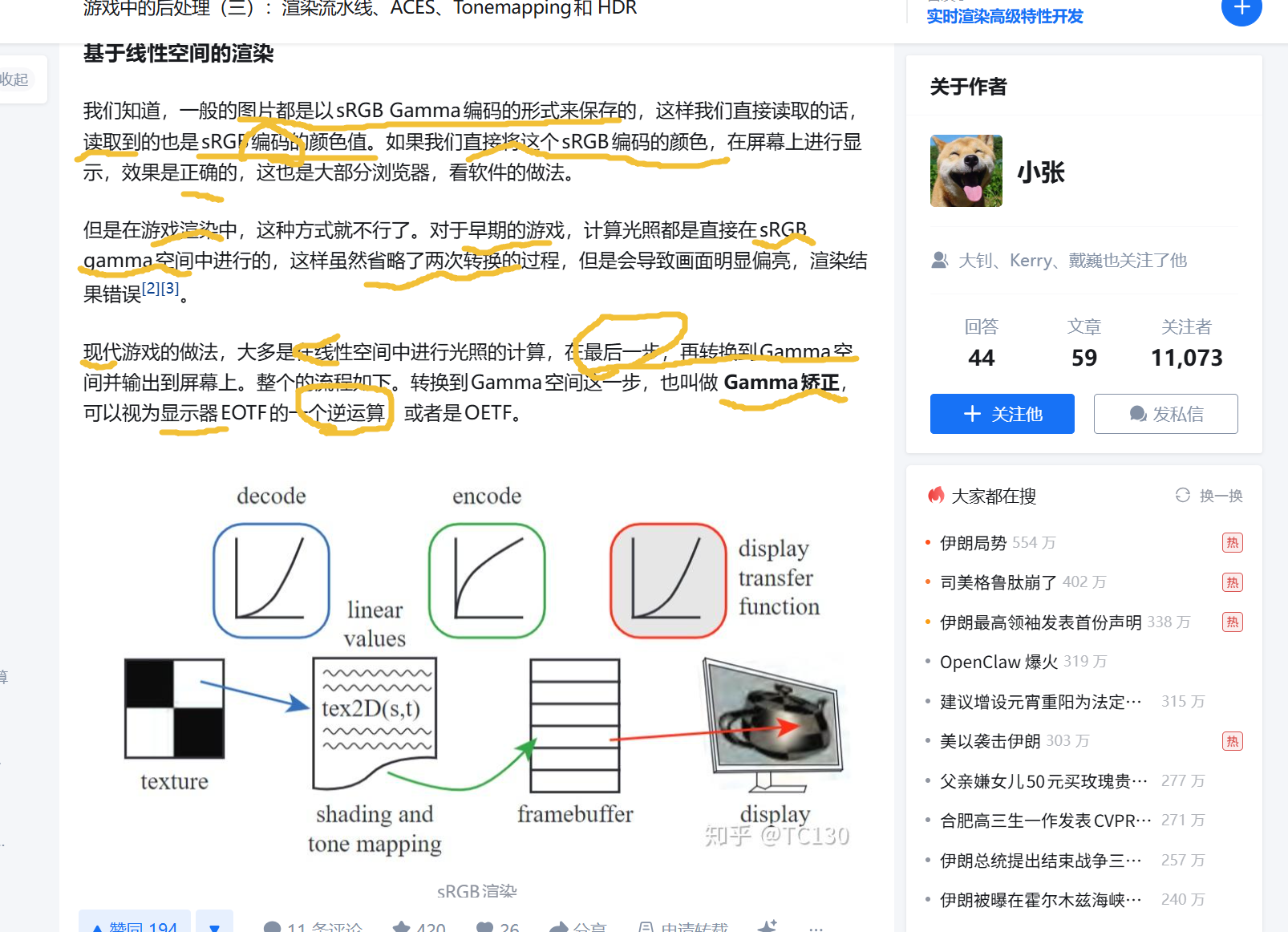

渲染中计算的颜色值叫做 scene-referred 的。把经过 tonemapping 转换后的值叫做 **display-refrerred。**tonemapping 也叫做Display rendering Transform 或者 Output Transform。tonemapping 也叫做Display rendering Transform 或者 Output Transform。

在 CG、影视和游戏开发中,ACES(Academy Color Encoding System)与 Tone Mapping(色调映射)的关系可以概括为:ACES 是一个完整的色彩管理系统,而其核心组成部分之一就是一套标准化的 Tone Mapping 方案。 1, 2
简单来说,ACES 决定了"色彩如何流动",而 Tone Mapping 决定了"高亮度如何被压缩到显示器能显示的范围"。 3, 4
1. 包含关系:ACES 是框架,Tone Mapping 是工具
- ACES:是一个行业标准框架,涵盖了从摄影机输入(IDT)、中间合成(ACEScg)到最终输出(ODT)的全过程。
- Tone Mapping:是 ACES 输出转换(Output Transform)中的一个核心数学步骤。由于渲染出的 HDR 画面亮度极高,远远超过普通显示器(sRGB/Rec.709)的承载能力,必须通过 Tone Mapping 将这些超亮信息"映射"回可显示的范围。 1, 4, 5, 6, 7, 8
2. 功能特点:为什么常用 ACES 做 Tone Mapping?
相比传统的"线性映射"或简单的 Reinhard 映射,ACES 的 Tone Mapping 具有以下特点:
- 胶片感(Filmic Look):ACES 的映射曲线呈 S 形,模拟了胶片的感光特性,能产生更强的对比度和自然的色彩饱和度。
- 高光收敛(Highlight Compression):它能有效防止亮部直接"炸掉"变成纯白。在 ACES 映射下,极亮的颜色会逐渐向白色过渡,并保留一定的细节和色彩倾向。
- 一致性:通过使用 ACES 标准,你在 Blender、Unreal Engine 或 Nuke 中看到的画面效果可以保持高度一致。 8, 9, 10, 11, 12, 13
3. ACES 流程中的关键节点
在 ACES 体系内,Tone Mapping 主要发生在以下两个阶段的组合中:
- RRT (Reference Rendering Transform):这是 ACES 的"灵魂",它将 HDR 场景数据转换为一种理想化的、极宽动态范围的图像,其中包含了基础的 Tone Mapping 曲线。
- ODT (Output Device Transform):针对特定显示器(如你的电脑屏幕)进行最后的适配。 4, 7
- 在 Unreal Engine 中配置 ACES 色彩空间?
- 比较 ACES 与新流行的 AgX Tone Mapping 有什么区别?
5 https://docs.acescentral.com
ACES Tonemap 对真实渲染很好,但对卡通渲染来说往往过重,所以很多卡通项目会降低 ACES 强度或者使用更简单的 Tonemap。
SRP 允许你重写阴影生成策略,所以这个问题可以被"针对性解决",但解决点不在 Camera,而在你怎么为这类遮挡单独建 shadow 数据。主相机只负责最终视图,不负责决定阴影贴图怎么生成。阴影贴图通常是从 光源视角 渲的,不是从主 Camera 渲的。
ScriptableRenderContext 不是"渲染后端"那么简单,它更像 你调度整帧和各类 pass 的入口 。
也就是说,你完全可以在一帧里做:
-
正常主相机渲染
-
普通主光 shadow map
-
再额外插一个"头发→脸部"专用 shadow/depth pass
这正是 SRP 的价值。
你说"一次性看整个 view box 深度",如果指的是常规 shadow map 的话,本质上确实是:
-
先确定光空间下的投影视锥/包围盒
-
再把这一片区域的 caster 渲到 shadow map
问题就在这里:
如果这个光空间覆盖范围太大,而你真正关心的只是脸附近几厘米的区域,那么 texel density 必然不够。
所以"头发投到脸上的阴影只有几个 texel"不是 Camera 的限制,而是 shadow projection / shadow++atlas 分配++ / receiver region 设计不对称。
SRP 可以解决,因为你可以不再用"一张通用阴影图服务所有 receiver"的思路,而改成"针对脸部 receiver,做局部高精度阴影"。
-
普通场景阴影继续走标准主光 shadow map
-
角色脸部额外再走一张"局部专用 shadow map"
SRP 完全可以这么做。你自己在管线里插一个 shadow pass 即可。
主 Camera 固定不妨碍你在 SRP 里创建额外的渲染视图。
完全可以在代码里自己算:
-
view matrix
-
projection matrix
然后用它们去渲一张 RT。
阴影渲染本来就不是非得依赖场景里真的有个 Camera 组件。

两个 depth 值是在同一个投影空间、同一个 (u,v) 位置下定义的,具有可比性。
最实用的一般不是提升 face shadow map 精度,而是"局部 mask + 特殊投影逻辑"的路线。也就是:RT / stencil / 队列控制,这些本质上都是"把作用域和混合关系钉死";而"提高阴影图精度"只是改善真实阴影采样质量,它并不能从根上解决二次元脸部阴影不稳定、边界脏、随镜头抖动、与法线不一致这些问题。
增加一个 RT
这是最强可控方案之一,本质是把"头发对脸的特殊阴影"从主阴影系统里剥出来,单独算。
典型做法是:
先把脸部区域或头发投影信息写进一个局部 RT;
再在 face shader 里读取这个 RT,决定脸上哪里压暗;
或者反过来,把头发沿光方向偏移后渲染到一张 face-space / screen-space mask。
这条路的优点很明确:
-
作用域最好控
你可以只让它影响脸,不污染身体、衣服、场景。
-
风格一致性最好
你可以把阴影做成二值、软阈值、插画化过渡,而不是受真实 shadow map 采样逻辑摆布。
-
容易和脸部 SDF、脸朝向、光照分区联动
这对二次元 NPR 很关键。
-
不依赖主 shadow pipeline
Built-in 里尤其有价值,因为内建阴影链路并不适合做这种风格特化。
缺点也明显:
-
多一个 pass 和 RT 带宽
如果你角色很多,或者移动端 tile memory 紧,这个成本不能忽略。
-
你得自己处理坐标空间和遮挡一致性
比如头发偏移后的 mask 是否和实际刘海几何对齐,镜头侧看时是否穿帮。
-
Built-in 接入会比较"手工"
你问"画质/可控性最强的是不是 RT",通常答案是是的,但不是性价比最高的通用方案。Stencil 更像"限制区域"的工具,不是"生成阴影形状"的工具。
这一点必须分清。很多人把 stencil 当成阴影方案,其实它只能回答"这里能不能画",不能回答"阴影长什么样"。
先标记脸部区域;
再让某个投影 pass 只在脸部 stencil==1 的地方生效。
所以 stencil 通常不是独立方案,而是配套方案。
比如:
头发偏移投影 pass + stencil 限脸
或者
额外 screen-space mask + stencil 裁切
它的优点是:
-
便宜
比单独 RT 更轻。
-
区域约束非常稳定
脸外不画就是不画。
-
Built-in 很容易接
但它解决不了这些核心问题:
-
阴影轮廓从哪里来
-
阴影随头发形状怎么变化
-
光方向变化时投影如何更新
-
阴影边缘怎么风格化
所以 stencil 本身不够。
正确理解是:stencil 是一个"限定器",不是"成像器"。
第三类,改渲染队列
只改渲染队列,通常不够构成完整方案。
渲染队列能改变的本质是:
谁先写深度;
谁后画;
谁能看到谁的结果;
某个 pass 是否能在另一个对象之后做 compositing。
它适合拿来解决的是流程编排,不是阴影算法本身。
比如你可以这样安排:
脸先写 stencil / depth;
头发投影 pass 在其后执行;
最终脸着色时读前面结果。
或者让头发特殊 pass 在普通透明/不透明之间插入。

成立,但通常不建议只依赖材质 Queue;更稳的做法是"URP Renderer Feature / Render Objects 控制执行时机 + 一个专用 pass 利用已有深度"。
也就是说,在 URP 里这个思路仍然是"深度裁剪型投影",不是"必须 stencil/必须 RT",但你最好把它升级成一个显式的 SRP 注入流程,而不是把希望全押在 shader queue 上。
URP 更容易被深度前传和中间纹理行为打断直觉。
比如你用了:
Depth Priming、
Depth Prepass、
MSAA、
Render Pass / Native RenderPass、
Forward+、
或者某些平台上的 depth copy 行为,
这时你以为"前一个物体已经写了深度,后一个 pass 直接 ZTest 就行",但实际是否读到的是同一份深度、是否发生了中间 copy、是否在相同 camera target 上执行,要看 Renderer 配置。
所以在 URP 里,这类方案能不能稳定,不取决于"Queue 概念是否存在",而取决于:
你是不是明确知道这个 pass 在哪一个 RenderPassEvent 上执行;
此时 active depth attachment 是什么;
脸的深度是不是已经进入当前深度缓冲;
偏移头发 pass 是否只做 ZTest LEqual / ZWrite Off;
正常头发是否在它之后继续按常规绘制。
unity-mcp 实际是一个 MCP Server ,它把 Unity Editor 的能力暴露给 AI 客户端。任何 支持 MCP 的 IDE/AI 插件都可以连接它。官方文档明确提到支持:
-
Claude Code
-
Cursor
-
Windsurf
-
VS Code
-
Cline 等 MCP 客户端 GitHub+1
因此 VSCode 作为 MCP client 是可以用的。
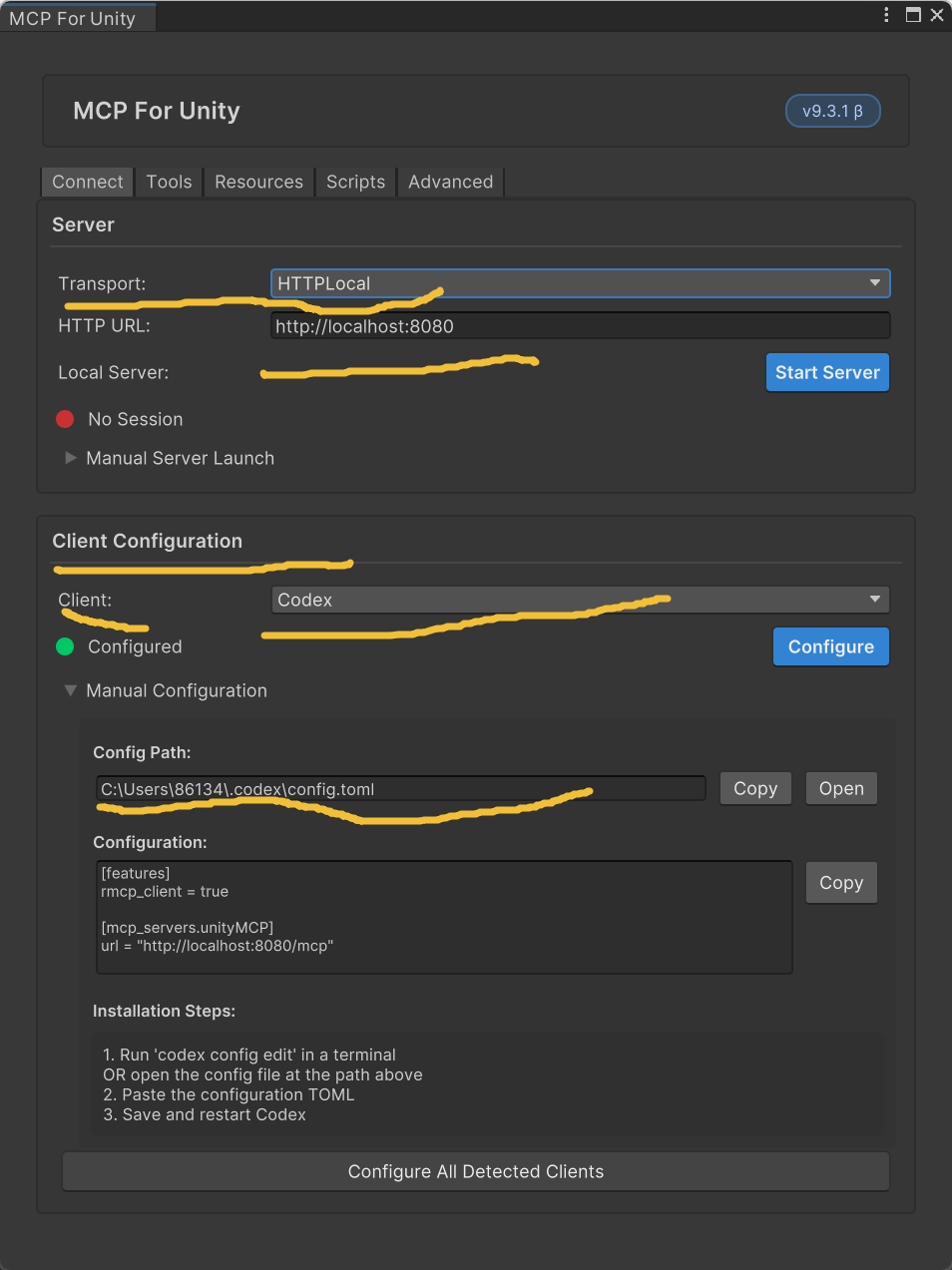
两套认证是分开的:
- Codex CLI -> OpenAI
- 这是 Codex 本身怎么用模型
- 可以是 ChatGPT 账号登录
- 也可以是 OpenAI API key
- Codex CLI -> MCP server
- 这是 Codex 去连外部工具服务器时怎么鉴权
- 跟你是不是用 ChatGPT 账号登录 Codex 没直接关系
- 这里可能不需要认证,也可能需要 X-API-Key、Bearer Token、OAuth 等
你看到的这段:
mcp add --transport http UnityMCP {httpUrl} mcp add --transport http UnityMCP {httpUrl} --header "X-API-Key: {key}"
意思只是:
- 如果 Unity MCP 是本地或无鉴权服务,就直接连
- 如果 Unity MCP 是远端且服务端要求 API key,就在请求头里加 X-API-Key
所以结论是:
- 不是在判断你 Codex 是"账号版"还是"API key 版"
- 而是在判断"这个 MCP 服务本身要不要鉴权"
你当前这个情况就是:
- Codex 自己能正常工作
- 但 unityMCP 这个远端 MCP 服务要求 X-API-Key
- 你 config.toml 里目前只有 url,没有对应认证,所以访问被拒
一般 MCP 不关心你 Codex CLI 是"ChatGPT 账号登录"还是"OpenAI API key 登录"。它通常只关心这几类东西:
- 服务地址
- 例如 url = "http://127.0.0.1:6500/mcp"
- 或者本地启动命令 command + args
- 鉴权信息
- 最常见是 API key
- 也可能是 Bearer token
- 或 OAuth 登录
- 还有很多本地 MCP 根本不需要鉴权
- 少量环境变量
- 比如 PATH、SystemRoot,或者某些服务自己的密钥
- 启动参数
- 如果是 stdio 型 MCP,往往要给启动命令和参数
stdio 指的是操作系统为程序默认提供的三个通道:stdin (标准输入,读入数据)、stdout (标准输出,打印结果)和 stderr(标准错误,输出日志)。

Codex CLI 是账号登录还是 API key 登录,决定的是:
- 你怎么访问 OpenAI 的模型
stdio 还是 HTTP,决定的是:
- Codex 怎么连接某个 MCP server
这是两条独立维度,你可以这样理解:
- 维度 1:Codex -> OpenAI
- ChatGPT 账号登录
- 或 OpenAI API key
- 维度 2:Codex -> MCP server
- stdio
- 或 HTTP/SSE
所以组合上都可以成立:
- 账号登录 + stdio MCP
- 账号登录 + HTTP MCP
- API key 登录 + stdio MCP
- API key 登录 + HTTP MCP
你图里圈的内容说的是 MCP 传输方式本身:
- stdio
- 客户端直接拉起一个本地子进程
- 通过标准输入输出通信
- HTTP/SSE
- 客户端连接一个 URL
- 本地/远端都可以
这跟你 Codex 是不是"API 版本"没关系。
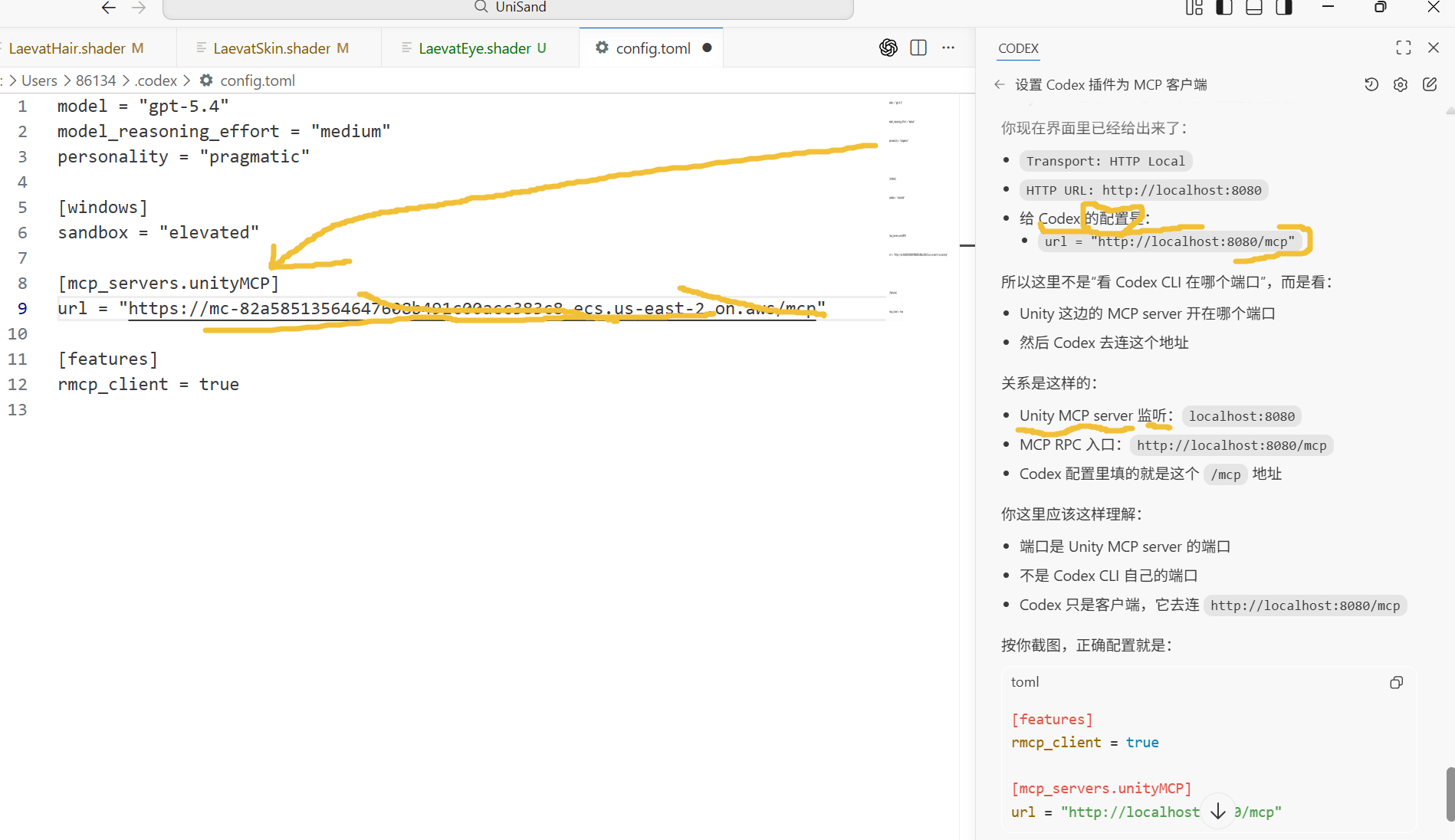
注意两件事:
- Unity 里要先点 Start Server
- 改完 config.toml 后重启 Codex
- uvx
- Python/uv 的运行器,用来临时启动这个 MCP server
- mcp-for-unity
- 要启动的服务程序
- --transport http
- 用 HTTP 而不是 stdio
- --http-url http://localhost:8080
- 监听在本机 8080 端口
- --project-scoped-tools
- 工具作用域限制在当前 Unity 项目
- --pidfile ...
- 记录这个进程的 PID
- --unity-instance-token ...
- 让服务绑定到当前这个 Unity Editor 实例
一句话说完:
- 你点 Start Server 后,Unity 会在你本机开一个 MCP HTTP 服务
- 然后 Codex 通过 http://localhost:8080/mcp 去连它
所以这正好对应你前面 config.toml 里该填的 URL。
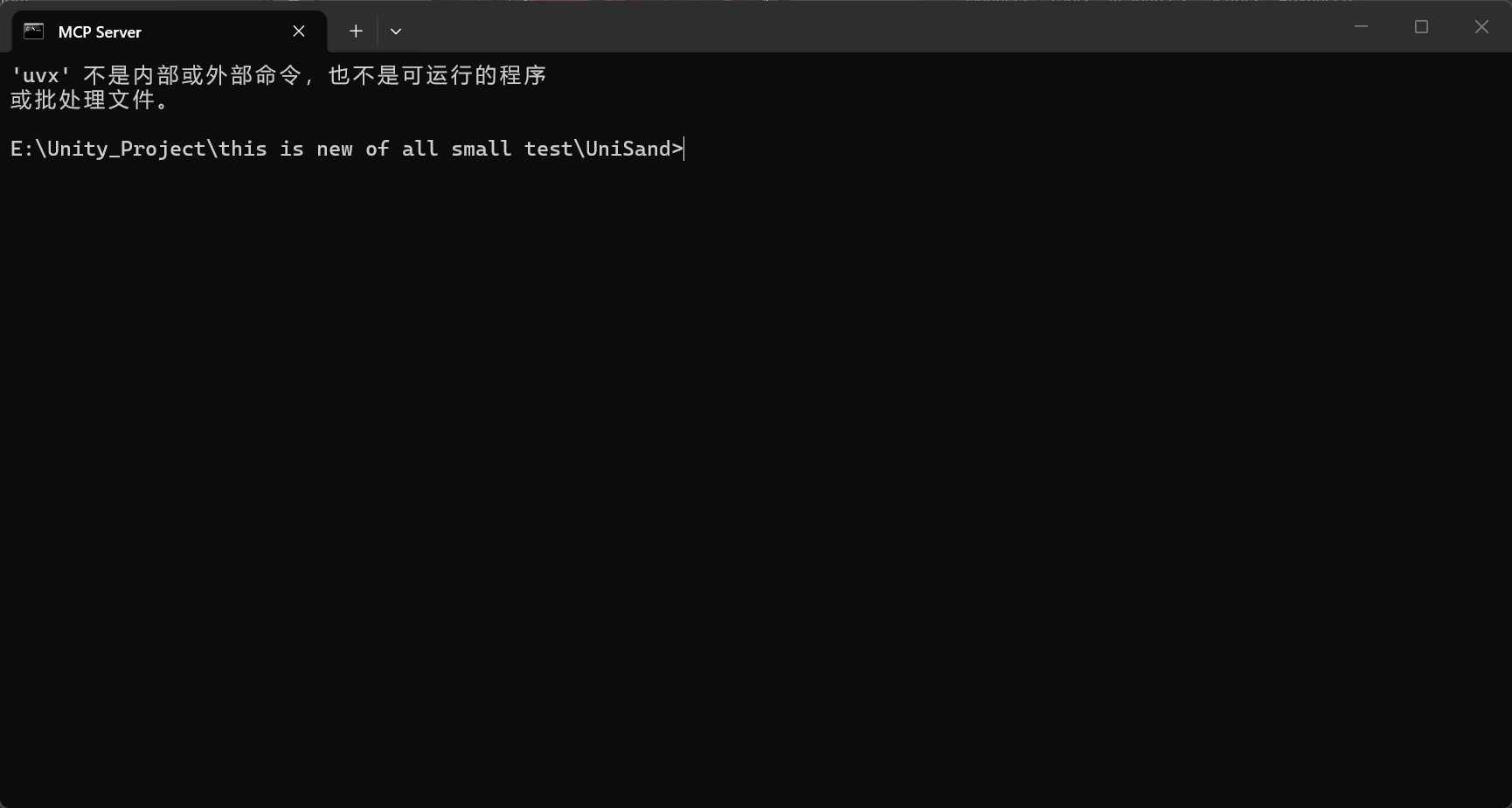 没uv
没uv
https://docs.astral.sh/uv/getting-started/installation/#installation-methods
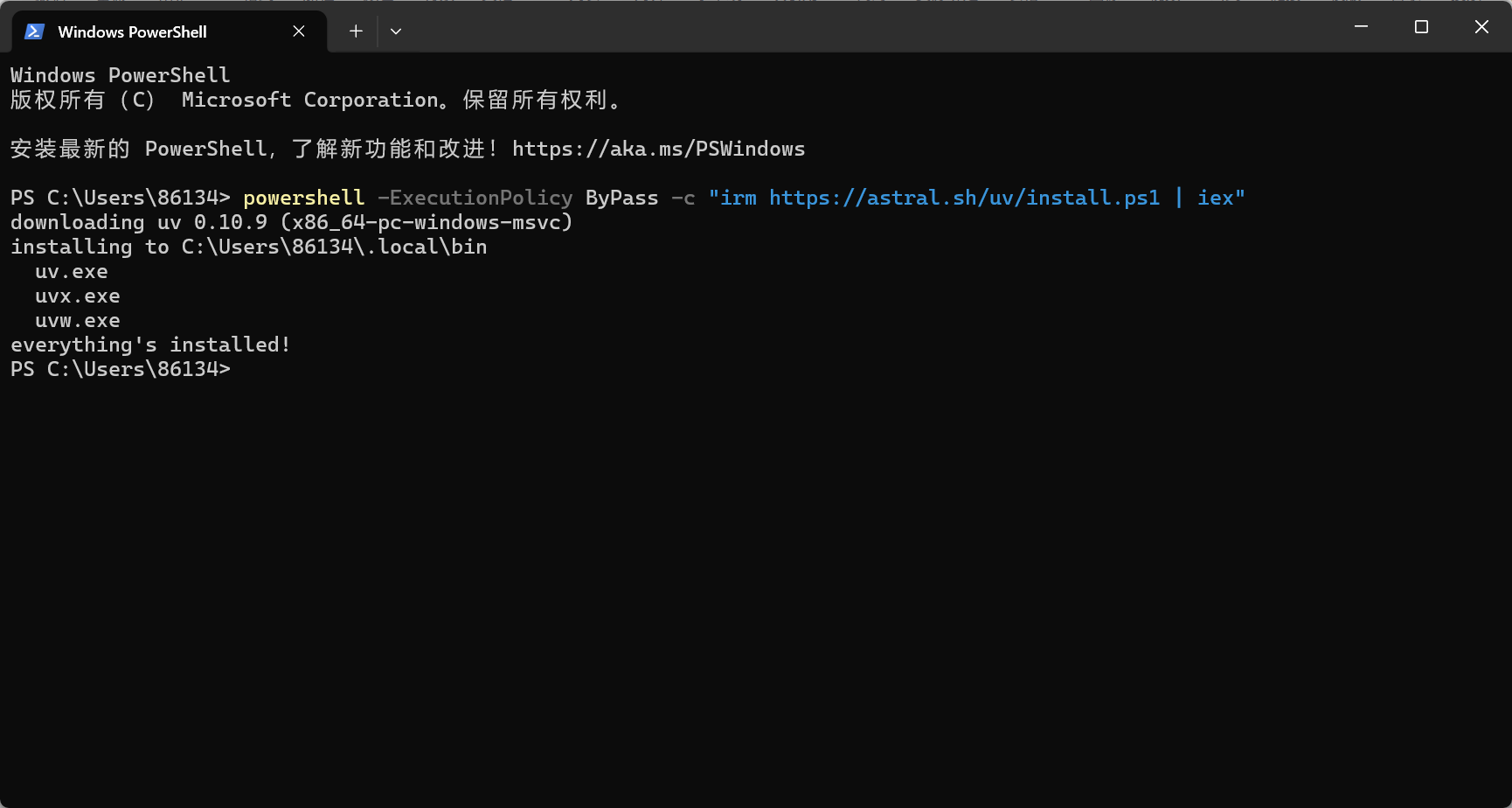
默认就装到你截图里这一行:
C:\Users\86134\.local\bin
具体是:
- C:\Users\86134\.local\bin\uv.exe
- C:\Users\86134\.local\bin\uvx.exe
- C:\Users\86134\.local\bin\uvw.exe
接下来你主要确认两件事:
- 这个目录有没有进 PATH
- 新开一个终端后能不能直接运行:
uv --version uvx --version
如果能直接识别,就可以回 Unity 里继续 Start Server。
如果不能识别,就把这个目录手动加到用户环境变量 Path:
C:\Users\86134\.local\bin
你现在没有看到对话框是正常的,因为
MCP 不是 GUI 工具,它是"给 AI 客户端接工具能力"的后台服务。
tool 和 resource 的区别可以简单理解成:
- tool = 能做事
- resource = 能读信息
在你这个 Unity MCP 里:
tool 是操作接口,通常有参数,会产生动作或执行查询。比如:
- manage_gameobject
- manage_components
- manage_scene
- run_tests
- execute_menu_item
这些属于"让我去做一件事":
- 创建物体
- 改组件
- 运行测试
- 打开场景
- 调 Unity 菜单
resource 是只读上下文,像一个可读取的数据视图。比如:
- mcpforunity://editor/state
- mcpforunity://project/info
- mcpforunity://editor/selection
- mcpforunity://instances
这些属于"让我看看当前状态":
- 编辑器当前状态
- 当前项目信息
- 当前选中了什么
- 当前有哪些 Unity 实例
更具体一点:
- tool
- 像函数 / 命令
- 需要传参数
- 可以修改东西,也可以做动态查询
- 例子:find_gameobjects(search_term="Camera")
- resource
- 像只读地址 / 数据快照
- 通常直接读取
- 不负责修改
- 例子:读取 mcpforunity://editor/state
在使用上的习惯通常是:
- 先用 resource 看上下文
- 再用 tool 执行动作
例如一个典型流程:
- 读 editor/selection
- 确认当前选中了哪个对象
- 调 manage_components
- 给它加 BoxCollider
所以一句话总结:
- resource 偏"看"
- tool 偏"做"
简单来说这确实是有待提升,但确实是看到效果了,vscode
里就能配置,如此方便,之前都没发现