2026.3.17
原文说的很详尽,写这么一篇只是为了让自己背的更顺。
1.让代码只输出content?
print(answer.content)
补充:其中,
answer = llm.invoke(prompt.format(question=question, context=docs_content))
该代码先把 question(问题)和 docs_content(上下文 / 参考文档)填充到预设的 prompt(提示词模板)中,再调用大语言模型(llm)处理填充后的提示词,最终将模型返回的结果赋值给 answer 变量。
format 方法会把实际的 question 和 docs_content替换到占位符位置 ,生成最终发给模型的完整提示词。例:若 prompt = "基于{context}回答问题:{question}",question="什么是Python",context="Python是编程语言",格式化后得到:"基于Python是编程语言回答问题:什么是Python"。
llm.invoke(...)
invoke 是 LangChain 框架中统一的模型调用方法,接收格式化后的提示词,向模型发送请求并获取返回结果。
2.修改Langchain代码中`RecursiveCharacterTextSplitter()`的参数`chunk_size`和`chunk_overlap`,观察输出结果有什么变化。
chunk_size=每个块的目标大小
chunk_overlap= 每个块之间重叠?个字符,以缓解语义割裂
未修改前输出结果
修改后的输出结果,其中
chunk_size=5000,
chunk_overlap=500
总结:
一、
- 默认参数(chunk_size=4000, chunk_overlap=200)
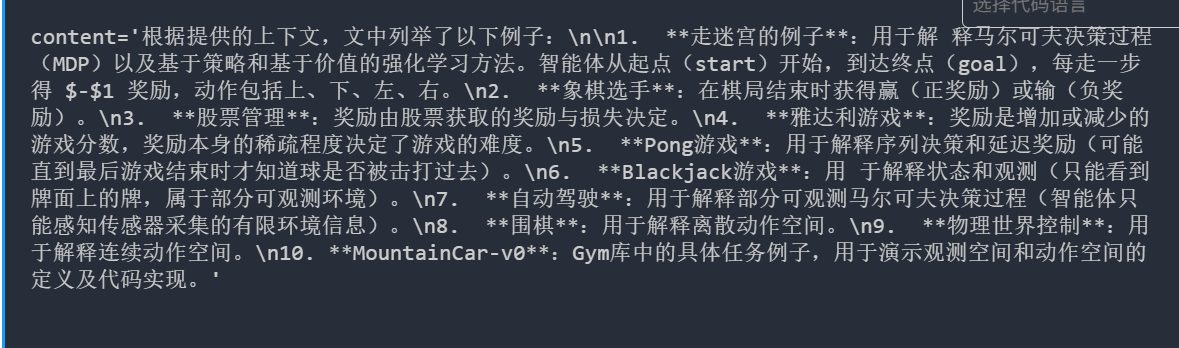
输出:列举了 8 个例子,包括走迷宫、象棋、股票管理、雅达利游戏、Pong游戏、21点、自动驾驶、MountainCar-v0。
特点:覆盖了文章的主要部分,例子比较全面。
- 小参数(chunk_size=1000, chunk_overlap=100)
输出:列举了 3 大类共 10 个例子,包括探索与利用的例子(选择餐馆、做广告、挖油、玩游戏)、强化学习具体应用的例子(DeepMind 走路的智能体、机械臂抓取、OpenAI 的机械臂翻魔方)、Gym 库交互的例子(MountainCar-v0)。
特点:更聚焦于文章的后半部分,特别是探索与利用的例子。
- 大参数(chunk_size=5000, chunk_overlap=500)
输出:列举了 3 大类共 9 个例子,包括自然界与生活领域(羚羊、股票交易)、电子游戏(雅达利的 Pong 游戏、雅达利的 Breakout 游戏)、Gym 库中的具体环境(Taxi-v3、Acrobot、CartPole-v0、MountainCar-v0)。
特点:覆盖了文章的前半部分,特别是自然界和游戏的例子。
二、
-
chunk_size 影响:
- 增大(如从 50→100):文本块数量减少,单个块更长,减少分割次数,但可能包含过多无关内容;
- 减小(如从 50→20):文本块数量剧增,单个块更短,分割更细,但可能导致语义碎片化(比如 "Langchain" 被拆成两半)。
-
chunk_overlap 影响:
- 增大(如从 10→20):相邻块重叠内容更多,上下文连贯性更好,但会重复处理字符,增加冗余;
- 减小(如从 10→0):无重叠,文本块更 "独立",但可能断裂语义(比如 "帮助开发者" 只出现在第一块,第二块直接从 "快速构建" 开始)。
chunk_size决定文本块的长度上限:值越大,块数越少、单块越长;值越小,块数越多、单块越短。chunk_overlap决定文本块的上下文连贯性:值越大,重叠越多、连贯性越好但冗余增加;值越小,重叠越少、冗余降低但可能语义断裂。
这个例子更直观一点
=== 正常参数 (chunk_size=50, chunk_overlap=10) ===
第1块(字符数:50):Langchain是一个强大的大语言模型应用开发框架,它提供了丰富的组件和工具,帮助开发者
第2块(字符数:49):开发者快速构建基于LLM的应用程序。无论是文本处理、链调用还是代理开发,Langchain都能提
第3块(字符数:24):能提供便捷的解决方案。
=== 增大chunk_size (chunk_size=100, chunk_overlap=10) ===
第1块(字符数:99):Langchain是一个强大的大语言模型应用开发框架,它提供了丰富的组件和工具,帮助开发者快速构建基于LLM的应用程序。无论是文本处理、链调用还是代理开发,Langchain都能提
第2块(字符数:24):能提供便捷的解决方案。
=== 减小chunk_size (chunk_size=20, chunk_overlap=10) ===
第1块(字符数:20):Langchain是一个强大的大语言
第2块(字符数:20):大语言模型应用开发框架,它提供了
第3块(字符数:20):它提供了丰富的组件和工具,帮助开
第4块(字符数:20):工具,帮助开发者快速构建基于LLM
第5块(字符数:20):于LLM的应用程序。无论是文本处理
第6块(字符数:20):文本处理、链调用还是代理开发,Lan
第7块(字符数:20):代理开发,Langchain都能提供便捷
第8块(字符数:13):供便捷的解决方案。
=== 增大chunk_overlap (chunk_size=50, chunk_overlap=20) ===
第1块(字符数:50):Langchain是一个强大的大语言模型应用开发框架,它提供了丰富的组件和工具,帮助开发者
第2块(字符数:50):帮助开发者快速构建基于LLM的应用程序。无论是文本处理、链调用还是代理开发,Langchain
第3块(字符数:24):能提供便捷的解决方案。
=== 减小chunk_overlap (chunk_size=50, chunk_overlap=0) ===
第1块(字符数:50):Langchain是一个强大的大语言模型应用开发框架,它提供了丰富的组件和工具,帮助开发者
第2块(字符数:39):快速构建基于LLM的应用程序。无论是文本处理、链调用还是代理开发,Langchain都能提供
第3块(字符数:24):能提供便捷的解决方案。2.数据加载部分
抽取文本->抽取关键信息作为元数据->转换成统一数据结构
Unstructured 库加载并解析一个PDF文件
from unstructured.partition.auto import partition
elements = partition(
filename=pdf_path,
content_type="application/pdf"
)
3.文本分块:直接分,分割号分,语义分,++文档结构分++(←一般组合使用)
总结各个切块的步骤:
-
**直接分块(固定长度分块)**① 设定固定字符 / 词数长度阈值② 从文本开头按阈值逐段硬切割③ 不考虑语义、标点,直接拆分④ 输出分块结果
-
**分割号分块(分隔符分块)**① 定位分隔符(标点、换行、分隔线、特殊符号等)② 以分隔符作为分块边界③ 按边界位置拆分文本④ 清理冗余内容后输出分块
-
语义分块(逻辑分块) ① 识别文本话题、句意、逻辑边界② 按语义完整独立原则划分③ 合并零散短句、拆分过长段落④ 输出语义连贯的分块
-
文档结构分块① 解析文档层级(标题、章节、段落、列表等)② 按结构标签(一级 / 二级标题、正文段)划分③ 遵循文档原有结构边界分块④ 保留结构关系,输出结构化分块
其中语义分块(句子分割 ->上下文感知嵌入 ->计算语义距离 ->识别断点 ->合并成块)中:
langchain_experimental.text_splitter.SemanticChunker 通过 buffer_size 参数(默认为1)来捕捉上下文信息。对于列表中的每一个句子,这种方法会将其与前后各 buffer_size 个句子组合起来,然后对这个临时的、更长的组合文本进行嵌入。
然后计算每对相邻 句子的嵌入向量之间的余弦距离。这个距离值量化了两个句子之间的语义差异------距离越大,表示语义关联越弱,跳跃越明显。
(余弦距离的发现者真伟大。。。)
4.实践:
- 使用
partition_pdf替换当前partition函数并分别尝试用hi_res和ocr_only进行解析,观察输出结果有何变化。
修改前:
解析完成: 5 页, 7956 字符
第一页内容:
进⼊词条 全站搜索检索增强生成
帮助
近期有不法分子冒充百度百科官方人员,以删除词条为由威胁并敲诈相关企业。在此严正声明:百度百科是免费编辑平台,绝不存在收费代编服务,请勿上当受骗!详情 >>
检索增强生成播报 锁定 讨论1 上传视频
⼤模型前沿技术之⼀ 展开2个同名词条
一分钟了解检索增强生成一分钟了解检索增强生成01:2201:22
RAG :当下大模型应用落地的必杀技RAG :当下大模型应用落地的必杀技02:2302:23
查
中国科学院大学计算机科
中国科学院大学计算机科
术学院是 201...
权威合作编辑
⽬录
同义词RAG(⼤模型内化吸收知识的过程)⼀般指检索增强⽣成
本词条由中国科学院大学计算机科学与技术学院、中国科学院计算技术研究所 参与编辑并 审核,经科普中国 · 科学百科认证 。
历史沿革 播报
技术定义 播报
检索增强生成( Retrieval-augmented Generation ),简称 RAG ,是当下热门的大模型 前沿技术之一 [1]。
检索增强生成模型结合了语言模型和信息检索技术。具体来说,当模型需要生成文本或者回答问题时,它会先从一个庞大的
文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性 [2]。