目录
[C语言 文件IO](#C语言 文件IO)
[Linux 文件IO](#Linux 文件IO)
[struct file](#struct file)
[struct files_struct](#struct files_struct)
[文件描述符 fd](#文件描述符 fd)
C语言 文件IO
在正式讲解Linux中是如何对文件进行IO前,我们先简单回顾以下C语言中,是如何进行文件的IO的。
fopen
**fopen用于打开文件,包含在头文件<stdio.h>**中,函数原型如下:
FILE* fopen(const char *pathname, const char *mode);pathname:打开文件路径,可以是绝对路径或相对路径mode:打开文件的模式
打开文件的最常用模式为:
"r":只读,若文件不存在则报错
"w":只写,若文件不存在则创建,打开时清空文件原有内容
"a":只写,若文件不存在则创建,打开时从文件末尾追加
该函数会返回一个**FILE*** 的指针,C语言中,通过操作这个**FILE***来控制文件的IO。
当我们打开文件时,每个被使⽤的⽂件都在内存中开辟了⼀个相应的⽂件信息区,⽤来存放⽂件的相关信息。
这些信息是保存在⼀个结构体变量中的。该结构体类型是由系统声明的,取名**FILE**。我们可以通过操纵这个FILE类型的结构体,来操控文件。
大部分情况下,我们可以得到一个指向该结构体的指针FILE*,即文件指针,后续通过文件指针来操控文件。
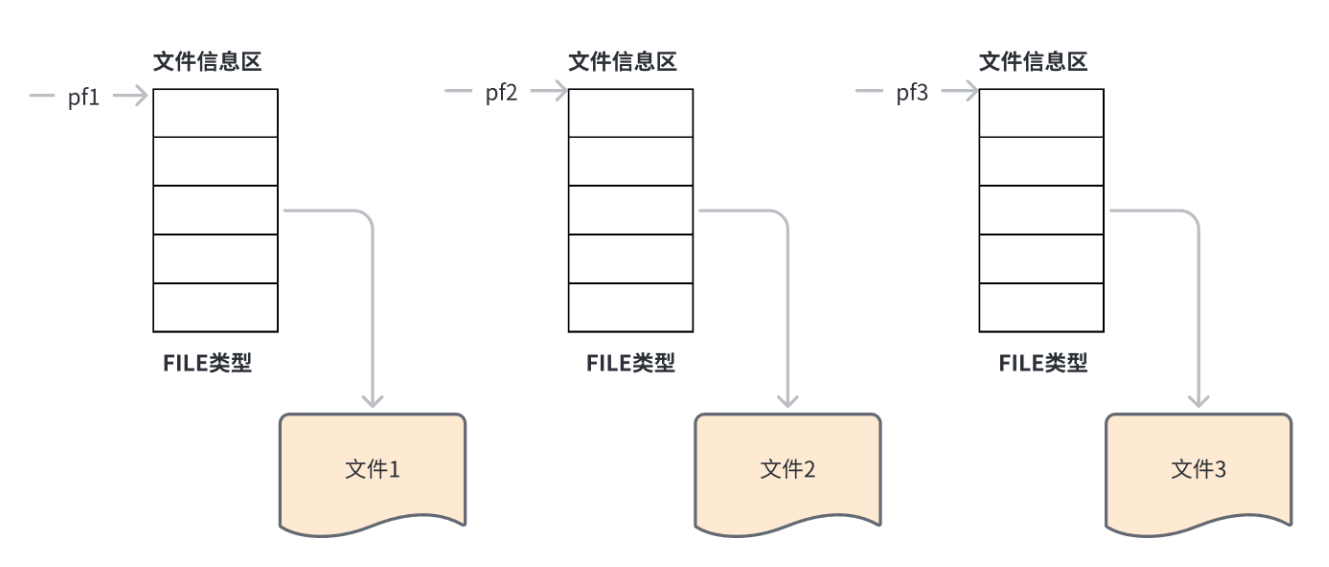
上图中,三个指针**pf1,pf2,pf3**,它们都指向了一个FILE类型的文件信息区。而每个文件信息区都存储着一个文件的信息,后续就通过这三个指针来操控这三个文件。
C语⾔程序在启动的时候,默认打开了3个流:
stdin- 标准输⼊流,在⼤多数的环境中从键盘输⼊。
stdout- 标准输出流,⼤多数的环境中输出⾄显⽰器界⾯。
stderr- 标准错误流,⼤多数环境中输出到显⽰器界⾯。
这三个流也是通过文件指针来操作的。
以上是从C语言的视角来看文件,接下来从操作系统的角度来看文件。
Linux 文件IO
在C语言中,所有文件都通过文件指针**FILE*来操控,而在Linux中,所有IO操作都围绕文件描述符fd**。
open接口
open用于打开文件,需要头文件<sys/types.h>、<sys/stat.h>、<fcntl.h>,函数原型如下:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
open会返回一个int类型的值,这个值就是文件描述符fd,后续通过**fd**操控对应文件。
该接口有两个版本,先说只有两个参数的接口:
pathname:打开文件的路径flags:打开文件的模式
这个模式和**fopen**的相似,比如控制读、写、追加等,以下选项:
| 选项 | 功能 |
|---|---|
O_RDONLY |
以只读方式打开 |
O_WRONLY |
以只写方式打开 |
O_RDWR |
以读写方式打开 |
O_CREAT |
若打开时不存在,则创建文件 |
假设用以下代码打开一个不存在的文件:
int fd = open("log.txt", O_WRONLY);如果使用C语言的**fopen,以w形式打开,遇到一个不存在的文件log.txt,则会默认创建该文件。但是对于open接口,以O_RDONLY**形式打开一个文件,如果文件不存在,就什么也不干。
如果想要打开文件同时创建文件,则需要加上**O_CREAT,open**接口是以位图的形式传参的,把所需的选项进行按位或即可。
在test.c中执行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT);
return 0;
}其中**O_WRONLY | O_CREAT**的意思就是:以只读方式打开文件,如果文件不存在就创建。

运行,/test.c后,当前目录就出现了文件**log.txt了,但是它的权限值是乱码-rwsr-x---**,如果你删掉该文件后再次运行代码,你会发现下一次的权限值和上次还不一样。
当**
open**没有传入第三个参数时,生成文件的权限值是随机的
此时就需要三个参数的**open**接口:
int open(const char *pathname, int flags, mode_t mode);其中**mode用于控制文件的初始权限,最终权限还要经过umask**过滤
在test.c中执行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
umask(0000);
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
return 0;
}先通过umask(0000)将当前的**umask变成0000,随后open的第三个参数传入0666,也就是log.txt的初始权限。由于umask变成0000,不会影响初始权限,最终log.txt的权限就是0666,也就是rw-rw-rw-**。

最终**log.txt的权限为rw-rw-rw-,因此open**的第三个参数,是用于控制文件的初始权限的。
close接口
close用于关闭文件,需要头文件<unistd.h>,函数原型如下:
int close(int fd);直接传入对应文件的**fd**即可。
write接口
write用于向文件写入,需要头文件<unistd.h>,函数原型如下:
ssize_t write(int fd, const void *buf, size_t count);
fd:被写入文件的**fd**buf:指向被写入的字符串count:写入字符的个数
示例:
在test.exe中执行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
const char* str = "Hello\n World!\n";
write(fd, str, 6);
close(fd);
return 0;
}以上代码中,向log.txt写入了一个字符串str,write的第三个参数为6,只写入了六个字符Hello\n,输出结果:
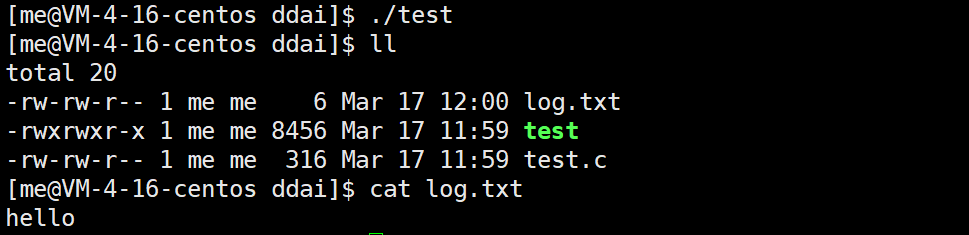
可以看到,log.txt的内容确实是Hello。
在保留原先的**Hello**的情况下,我们再写入以下内容:
const char* str = "123";
write(fd, str, 3);这次只写入三个字符,看看输出结果:
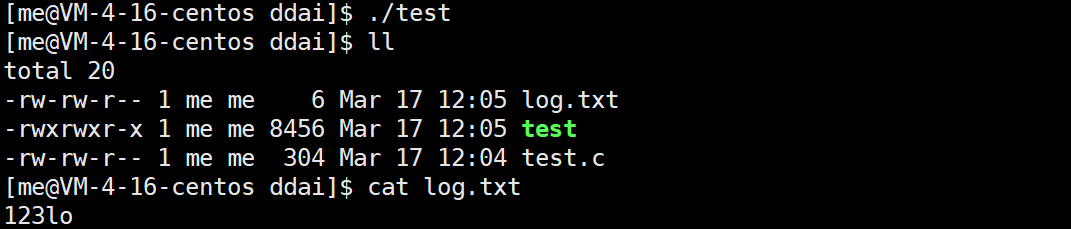
最终**log.txt的内容变成了123lo**,这是为什么?
以**
O_WRONLY**模式对文件进行写入时,不会先把文件内容清空,而是直接从头开始覆盖
因此新写入的**123把原先hello**的头三个字符覆盖掉了,但是后面的字符没有被覆盖也没有被清空。
对于一个文件重复写入,有两种解决方案,对应两个**open**的选项:
| 选项 | 功能 |
|---|---|
O_TRUNC |
打开时清空文件内容 |
O_APPEND |
以追加的形式写入 |
同样以位图的形式传入,直接按位或到第三个参数中即可,这样就可以得到两种常用组合:
O_WRONLY | O_CREAT | O_TRUNC:以只读形式打开,如果文件不存在就创建,打开时清空文件所有内容O_WRONLY | O_CREAT | O_APPEND:以只读形式打开,如果文件不存在就创建,打开时从文件的结尾开始追加
不知道你看到这个描述,有没有一点点熟悉?
没错,**O_WRONLY | O_CREAT | O_TRUNC模式打开,就是fopen的以"w"形式打开;O_WRONLY | O_CREAT | O_APPEND就是fopen的以"a"形式打开。由于fopen是用户操作接口,而open是系统调用接口,其实fopen就是对open**的封装。
read接口
read用于读取文件,需要头文件<unistd.h>,函数原型如下:
ssize_t read(int fd, void* buf, size_t count);fd:目标文件的文件描述符**fd**buf:将文件内容读取到**buf**指向的空间中count:最多读取**count**个字节的内容
返回值:
< 0:读取发送错误
= 0:读取到文件末尾
> 0:读取成功,返回读取到的字符个数
示例:
在test.exe中执行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int fd = open("log.txt", O_RDONLY);
char buffer[1024];
ssize_t ret1 = read(fd, buffer, 1024);
printf("ret1 = %ld\n", ret1);
printf("%s", buffer);
ssize_t ret2 = read(fd, buffer, 1024);
printf("ret2 = %ld\n", ret2);
close(fd);
return 0;
}log.txt的内容为字符串123lo,一开始通过**open以只读形式打开文件后,先通过read(fd, buffer, 1024)把内容存储到数组buffer中,并把返回值交给ret1。随后输出ret1和buffer**。
读取完**log.txt后,再读取了一次read(fd, buffer, 1024),这次读取的结果交给ret2,并输出ret2**。
输出结果:

第一次**read返回值为6**,也就是字符串**123lo中有13个字符,随后buffer中也正常输出了123lo。而第二次read**,由于上一次读取时已经遇到文件末尾了,所以本次读取返回0。
内存文件管理
struct file
想要打开一个文件,文件是要从磁盘中提取的,要访问硬件设备,而访问硬件设备是操作系统才有的权力,因此访问文件毫无疑问是要经过操作系统的。在操作系统中,会使用一个叫做file的结构体来描述一个被打开的文件,并把这个文件的数据从磁盘加载到内存中。
当一个文件被打开加载到内存中,就可以称这个文件是一个**内存文件,本博客现在讨论的就是被打开的文件,或者说内存文件**是如何进行管理的。
在**Linux 2.6.10内核中,struct file**如下:
struct file {
struct list_head f_list;
struct dentry *f_dentry;
struct vfsmount *f_vfsmnt;
struct file_operations *f_op;
atomic_t f_count;
unsigned int f_flags;
mode_t f_mode;
int f_error;
loff_t f_pos;
struct fown_struct f_owner;
unsigned int f_uid, f_gid;
struct file_ra_state f_ra;
unsigned long f_version;
void *f_security;
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
spinlock_t f_ep_lock;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
};**struct file**是一个非常重要的数据结构,它表示一个打开的文件,并且提供了访问和操作文件的接口。
我提取出几个重要的成员,做一个简化模型:
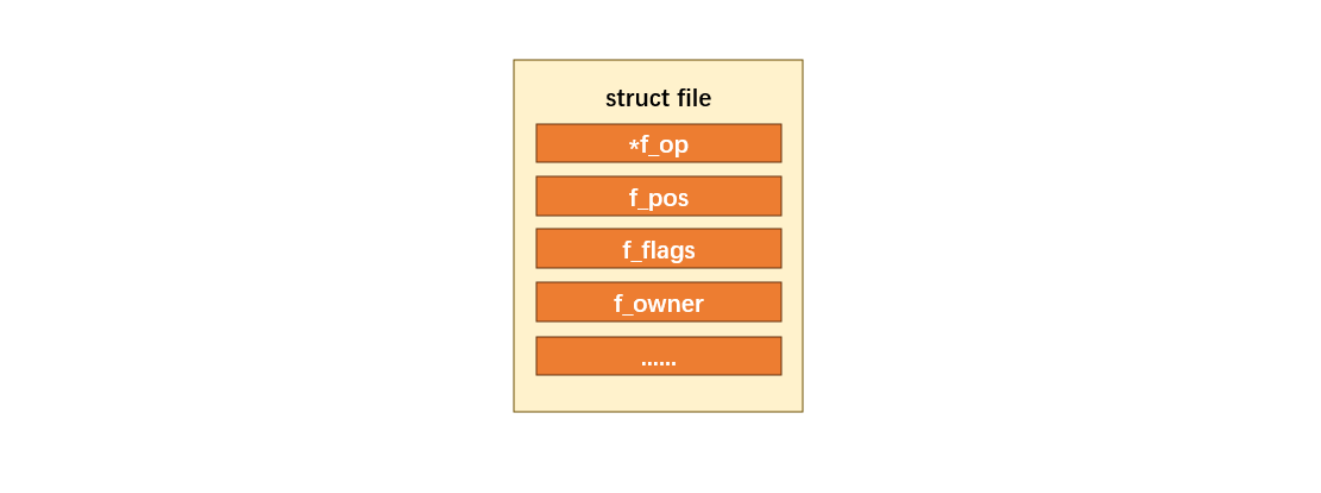
其中这些重要成员的功能如下:
loff_t f_pos
这个成员保存了文件当前的读写位置。许多文件操作函数都会根据这个位置来读写数据。
unsigned int f_flags:
这个成员保存了打开文件时设置的标志,如 O_RDONLY, O_WRONLY, O_APPEND 等。这些标志决定了对文件的访问权限和行为。
struct fown_struct f_owner
这个成员保存了文件所有者的信息,包括进程 ID 和用户 ID。它用于实现文件的所有权和权限检查。
struct file_operations *f_op
这个成员指向一个**struct file_operations** 类型的结构体,它定义了各种文件操作函数,如 read(), write(), open(), release() 等。这些函数由文件系统或驱动程序实现,用于处理对文件的各种操作。
在**Linux中,一切皆文件,不论是显示器,键盘,磁盘,内存,一切软硬件都是通过文件来控制的,因此每个文件的写入与读取方式很有可能不同,但是我们又要用read,write这样的接口来对文件统一的读写。于是在struct file中,用一个f_op成员指向一个结构体struct file_operations**,在对应结构体内部,存放着指向各种函数指针。
在**Linux 2.6.10内核中,struct file_operations**如下:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_write) (struct kiocb *, const char __user *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*sendfile) (struct file *, loff_t *, size_t, read_actor_t, void *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*dir_notify)(struct file *filp, unsigned long arg);
int (*flock) (struct file *, int, struct file_lock *);
};在以上结构体的成员中,可以找到几个熟悉的身影:read,write,open,它们都是函数指针。我们在对文件进行IO操作的时候,其实都是到了**struct file**中,找到这里的函数指针,通过函数的地址来调用各自实现的函数。这样每个硬件厂商实现自己的读写接口,上层只需要以统一的形式调用即可。
struct files_struct
刚刚的结构体**struct file是用于描述具体的被打开的文件的,而操作系统想要对所有被打开的文件进行统一的管理,就需要再把所有的struct file组织起来,这个组织struct file的结构体,就是struct files_struct** 。
在**Linux 2.6.10内核中,struct files_struct**如下:
struct files_struct {
atomic_t count;
spinlock_t file_lock; /* Protects all the below members. Nests inside tsk->alloc_lock */
int max_fds;
int max_fdset;
int next_fd;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};其中最重要的成员,就是最后一个成员**fd_array,该成员是一个数组,指向的成员类型为struct file*,也就是指向struct file**的指针。
视图如下:
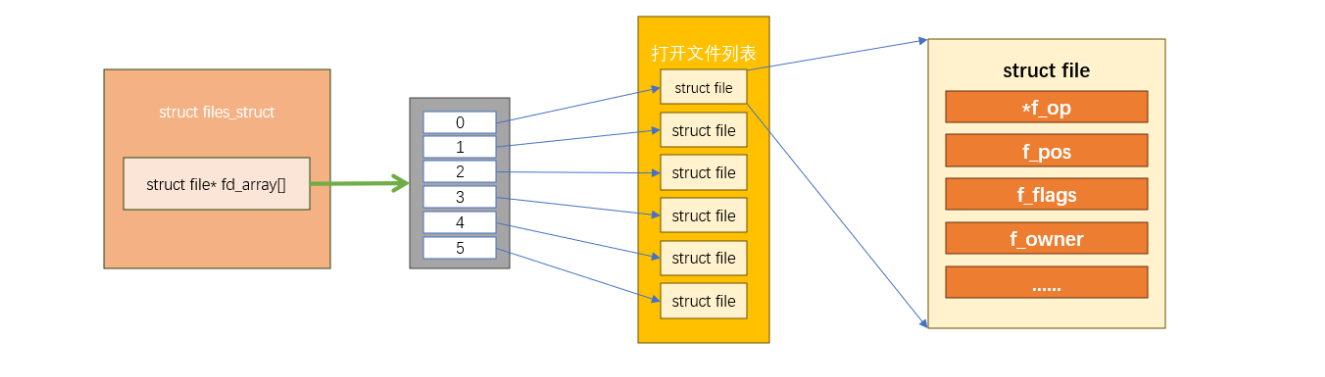
fd_array就是灰色的数组,每个数组的元素都是一个指向struct file的指针,struct file对应一个打开的文件。操作系统有一个全局的struct files_struct,用于统一管理所有进程打开的文件。
每个进程也要打开多个文件,那么每个进程又要如何管理自己打开的文件呢?
每个进程也要通过**
struct files_struct来管理多个struct file**
在进程**PCB即task_struct**中,有这样一个成员:
/* open file information */
struct files_struct *files;也就是说,每个进程也要维护一个struct files_struct,来控制自己打开的文件。
当一个文件被打开,大致视图如下:
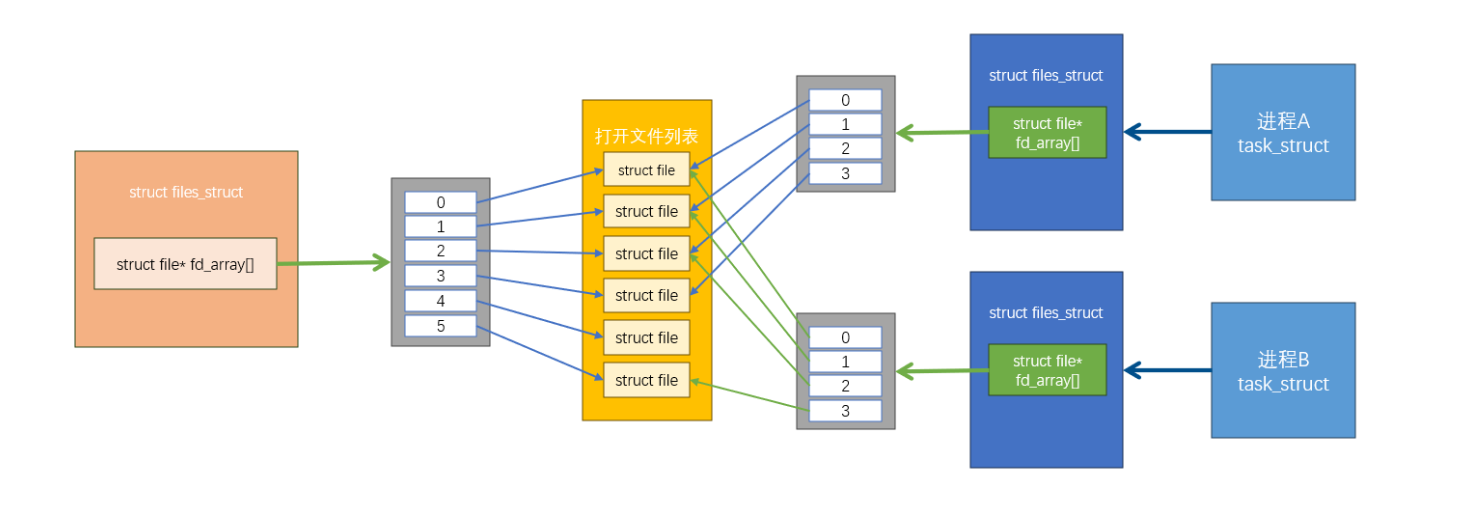
左侧是被操作系统全局管理的**struct files_struct,整个系统中所有被打开的文件都要被这个结构体管理。而右侧是每个进程自己打开维护的struct files_struct**,分别管理自己打开的文件。
我在图片中也标识了,当多个进程打开同一个文件,那么它们的fd_array里面的元素,会指向同一个**struct file**。
文件描述符 fd
那么我在此先抛出结论:
文件描述符**
fd,就是fd_array**的数组下标
现在我们创建一大批文件,然后看看它们的fd的值。
在**test.c**中执行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
int fd1 = open("log1.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd2 = open("log2.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd3 = open("log3.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd4 = open("log4.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd5 = open("log5.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fd1 = %d\n", fd1);
printf("fd2 = %d\n", fd2);
printf("fd3 = %d\n", fd3);
printf("fd4 = %d\n", fd4);
printf("fd5 = %d\n", fd5);
return 0;
}输出结果:
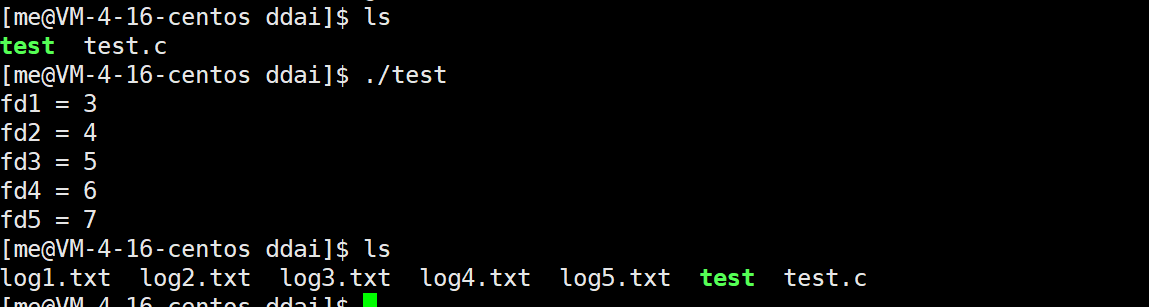
执行**./test后,确实多出了五个文件,但是其fd是3 4 5 6 7这样从3开始依次排列的,为什么要这样干?数组下标从0开始,那么编号0 1 2的fd**去哪里了?
还记得在C语言中,会为我们默认打开三个流**stdin,stdout,stderr吗?这三个流也是向文件输入输出,默认打开三个流stdin,stdout,stderr的时候,0 1 2为编号的fd**就已经被占用了!
C语言中,文件流是以**FILE的形式被管理的,毫无疑问FILE是对Linux文件系统的封装,FILE内部一定存储了fd,否则无法通过fd来访问特定的文件。其中FILE的_fileno成员,就是fd**。
来看看**stdin,stdout,stderr的_fileno**:
#include <stdio.h>
int main()
{
int fd1 = stdin->_fileno;
int fd2 = stdout->_fileno;
int fd3 = stderr->_fileno;
printf("stdin->_fileno = %d\n", fd1);
printf("stdout->_fileno = %d\n", fd2);
printf("stderr->_fileno = %d\n", fd3);
return 0;
}输出结果:

这就很好的证明了**stdin,stdout,stderr占用了0 1 2为编号的fd**。
缓冲区
也许你听说过很多次缓冲区,但是对它依然感到陌生,其实缓冲区的概念很好理解:
缓冲区本质上就是一块内存区域
fwrite等C语言的文件IO接口,都在底层封装了系统调用接口write等,如果用户高频调用fwrite,那么也就会相应地调用write等系统调用接口。
于是C语言的设计者认为,反正最后数据都要被到内存中,这个过程需要通过**write等系统调用接口,我们能不能把调用fwrite写入的数据先保留下来,等到一定的量之后,再通过一次write**,把之前所有的数据一次性写入?
于是缓冲区应运而生,这个缓冲区叫做**用户级缓冲区,用户调用的所有C语言文件IO接口,都会先写到缓冲区中,然后等到一定条件,在通过一次系统调用,把之前所有缓冲区的数据写入到操作系统中,这个一次性写入过程叫做刷新缓冲区**。
要注意的是,操作系统也有自己的缓冲区,但是这个是操作系统自己管理的内核缓冲区,其决定了wirte等系统调用接口写入的数据,何时写入到内存中,但不是该博客讨论的范围,后续讨论的缓冲区都是用户级缓冲区。
用户级缓冲区的刷新策略有以下三种:
- 无缓冲:不进行缓冲,直接输出
- 行缓冲:向显示器写入时,**
'\n'**会强制刷新缓冲区,也就是一行一行刷新缓冲区- 全缓冲:向普通文件写入时,一般缓冲区被写满才会刷新
当然,程序结束,或者用户调用**flush**函数,也会强制刷新缓冲区。
那么缓冲区在哪里呢?
缓冲区被结构体**
FILE**管理
由于每个文件的FILE是独立的,因此每个文件的缓冲区也是独立的!
我用一段申请的代码来证明缓冲区的存在:
先在**test.c**中运行以下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>
int main()
{
const char* s1 = "hello write!\n";
write(stdout->_fileno, s1, strlen(s1));
const char* s2 = "hello printf!";
printf("%s", s2);
printf("\n");
return 0;
}这串代码分别通过系统调用接口**write** 和用户操作接口**printf向stdout**写入数据,也就是向显示器写入数据。
输出结果:

**write和printf**都输出了一条语句,这符合预期,接下来我修改一下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>
int main()
{
const char* s1 = "hello write!\n";
write(stdout->_fileno, s1, strlen(s1));
const char* s2 = "hello printf!";
printf("%s", s2);
fork();
printf("\n");
return 0;
}在**write和printf输出完后,在printf("\n");之前,使用fork**创建了一个子进程,现在输出结果如下:

奇怪的现象出现了,printf("%s", s2);明明在fork之前就已经完成了,为什么会输出两次?
在printf("%s", s2);中,我特地没有换行,因为向显示器输出时,换行会刷新缓冲区,而当前缓冲区还没有被刷新。于是**hello printf!**被保留在了缓冲区。
当子进程被创建时,会继承父进程的数据和代码,stdin的FILE指向的缓冲区,也会被继承。当父子进程分别指向printf("\n");时,刷新各自的缓冲区,于是分别输出了一句**hello printf!**。
可以得出的是,在C语言层面确实存在一个用户级缓冲区,这个缓冲区可以被继承。