本文核心内容是基于上一篇生成的12个数据集文件,使用逻辑回归(Logistic Regression)算法对预处理后的这12个数据集(本文以平均值填充为例)进行分类任务训练与评估,通过网格搜索寻找最优超参数,最终提取模型在测试集上的关键评估指标(召回率、准确率)并保存。
1.数据读取与分割
python
import pandas as pd
from sklearn import metrics#sklearn.metrics:用于计算模型评估指标(如分类报告、准确率、召回率)
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。2.网格搜索优化超参数
python
param_grid = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l2'],
'solver': ['lbfgs'],
'max_iter': [1000, 2000, 3000],
'class_weight': [None, 'balanced'] # 处理样本不均衡
}
#
logreg = LogisticRegression()
grid_search = GridSearchCV(logreg,param_grid,cv=5)# 创建GridSearchCV对象
grid_search.fit(train_data_x,train_data_y)# 在训练集上执行网格搜索
print("Best parameters set found on development set:")#输出最佳参数
print(grid_search.best_params_)3. 构建最优模型
python
LR_result={}#用来保存训练之后的结果
lr = LogisticRegression(C=0.001,max_iter=1000,penalty=None,solver='lbfgs')
lr.fit(train_data_x,train_data_y)4.模型评估与结果提取
python
# '''测试结果[含训练数据集的测试+测试数据集的测试]'''
train_predicted=lr.predict(train_data_x)#训练数据集的预测结果
print('LR的train:\n',metrics.classification_report(train_data_y,train_predicted))
test_predicted=lr.predict(test_data_x)
print('LR的test:\n',metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)
b=a.split()
LR_result['recall_0']=float(b[8])
LR_result['recall_1']=float(b[11])
LR_result['recall_2']=float(b[16])
LR_result['recall_3']=float(b[21])
LR_result['acc']=float(b[25])
print('lr结束')
#lr.predict(...):用训练好的模型对训练集 / 测试集特征做预测,得到预测标签。
metrics.classification_report:生成分类报告,包含精确率(precision)、召回率(recall)、F1 值、支持数,以及整体准确率(accuracy)。
输出训练集的分类报告:看模型在训练集上的表现(是否过拟合)。
输出测试集的分类报告:看模型的泛化能力(核心评估指标)。
指标提取(通过字符串分割):
digits=6:保留 6 位小数,让指标更精确。
a.split():把分类报告的字符串按空格分割成列表,然后通过索引取对应值:
recall_0/1/2/3:类别 0、1、2、3 的召回率(说明是 4 分类任务)。
acc:整体准确率(accuracy)。
把这些指标存入LR_result字典,方便后续对比其他算法。
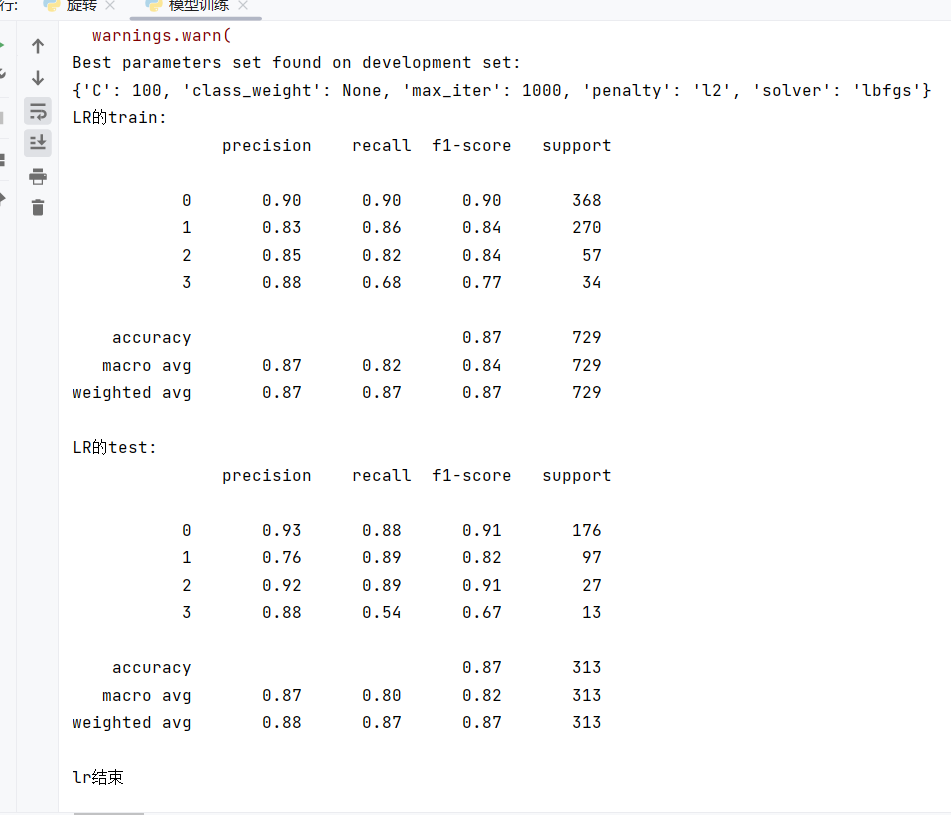
- 最优参数部分(网格搜索结果)
python
Best parameters set found on development set:
{'C': 100, 'class_weight': None, 'max_iter': 1000, 'penalty': 'l2', 'solver': 'lbfgs'}这是网格搜索(GridSearchCV)在 5 折交叉验证后,找到的最优超参数组合:
C=100:正则化强度(值越大,正则化越弱,模型更偏向拟合数据)
penalty='l2':使用 L2 正则化,防止过拟合
solver='lbfgs':优化算法,适合多分类任务
max_iter=1000:最大迭代次数,保证模型收敛
class_weight=None:未对样本不均衡做特殊处理
- 训练集结果(LR 的 train)
这部分是模型在训练数据上的表现,用来判断模型拟合程度:
| 类别 | precision(精确率) | recall(召回率) | f1-score | support(样本数) |
|---|---|---|---|---|
| 0 | 0.90 | 0.90 | 0.90 | 368 |
| 1 | 0.83 | 0.86 | 0.84 | 270 |
| 2 | 0.85 | 0.82 | 0.84 | 57 |
| 3 | 0.88 | 0.68 | 0.77 | 34 |
| accuracy | --- | --- | 0.87 | 729 |
accuracy(准确率):整体预测正确的比例(训练集 87%)
- 测试集结果(LR 的 test)
这部分是模型在从未见过的测试数据上的表现,用来判断泛化能力:
| 类别 | precision(精确率) | recall(召回率) | f1-score | support(样本数) |
|---|---|---|---|---|
| 0 | 0.93 | 0.88 | 0.91 | 176 |
| 1 | 0.76 | 0.89 | 0.82 | 97 |
| 2 | 0.92 | 0.89 | 0.91 | 27 |
| 3 | 0.88 | 0.54 | 0.67 | 13 |
| accuracy | --- | --- | 0.87 | 313 |
测试集准确率和训练集一样(0.87),说明模型没有过拟合,泛化能力稳定