1.线段树
1.引入
有如下问题:
- 有 n(n ≤ 10) 个数, q(1 ≤ 10) 次操作,每次操作为询问区间 l, r 的和。
- 有 n(n ≤ 10) 个数, q(1 ≤ 10) 次操作,操作有两种:
a. 查询区间 l, r 的和;
b. 将第 i 个数修改成 x 。 - 有 n(n ≤ 10) 个数, q(1 ≤ 10) 次操作,操作有两种:
a. 查询区间 l, r 的和;
b. 将区间 l, r 的数全部修改成 x 。 - 有 n(n ≤ 10 ) 个数, q(1 ≤ 10) 次操作,每次操作为区间 l, r 的最大值或者最小值。
这个其实是 RMQ(Range Minimum/Maximum Query) 问题。
以上问题,采用暴力解法显然会超时。接下来,我们学习⼀种树形数据结构 - 线段树:
• 线段树是⼀棵二叉树,常用来维护区间信息;
• 可以在 log \log log 级别的时间复杂度内完成:区间的单点修改,区间修改、区间查询(区间和,区间最大、最小值)等操作。
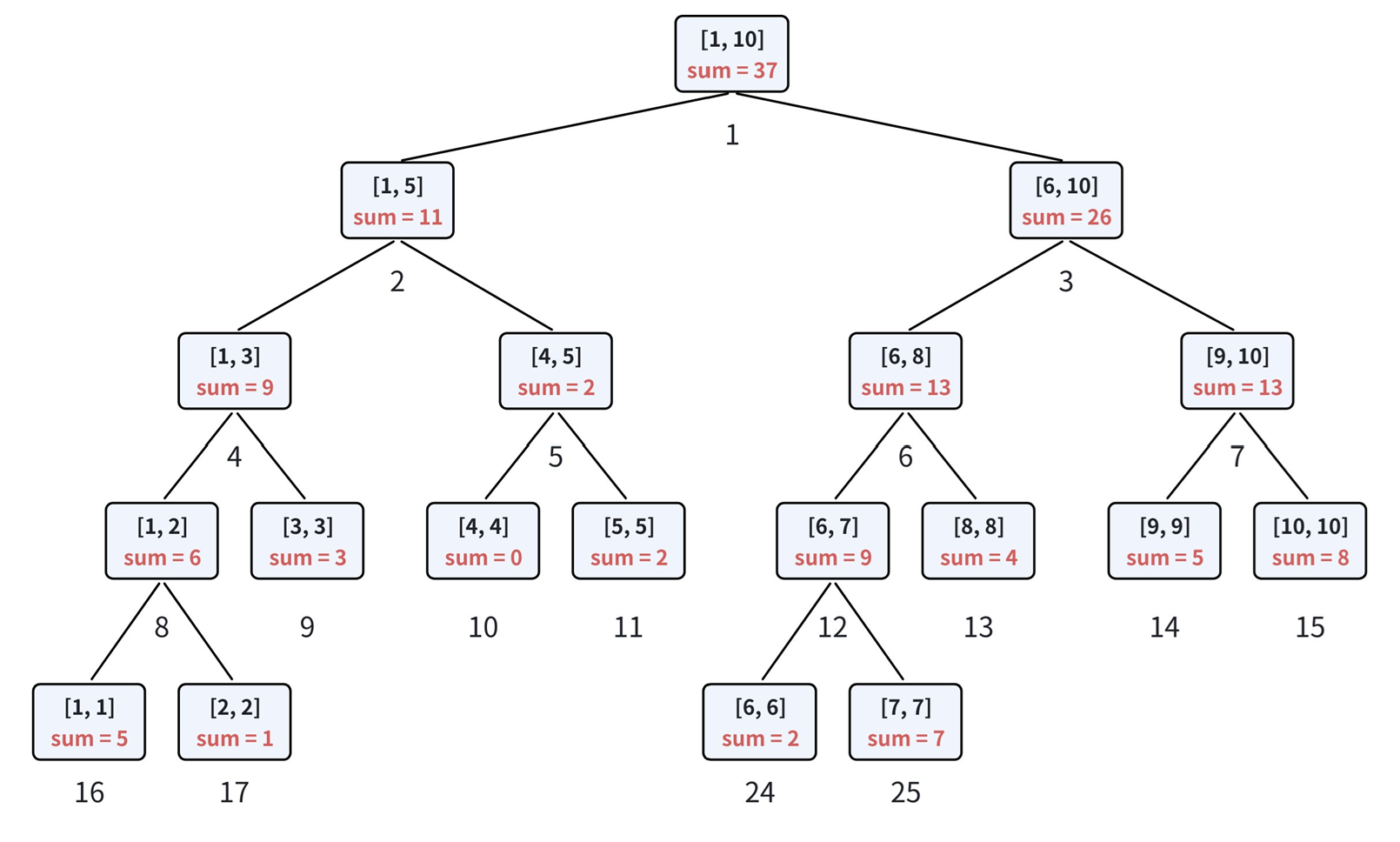
2.构建
根据构建方式,可以得到以下性质:
• 线段树的每个结点都维护⼀个区间的信息;
• 线段树中的根节点维护整个区间的信息,叶子结点维护长度为 1 的区间信息;
• 可以用结构体数组来实现线段树,类似堆的存储方式,也就是⼆叉树的静态存储。此时父节点的编
号为 p 时,左孩子编号为 p × 2 ,右孩子编号为 p × 2 + 1 ;
• 若当前结点维护的区间为 l, r ,那么左右孩子分别维护 l, mid 以及 mid + 1, r 区间的信息;
• 线段树的空间,需要开最大区间的 4 倍。
cpp
#define lc p << 1
#define rc p << 1 | 1
struct node
{
LL sum, l, r;
}tr[N<<2];
void pushup(int p)
{
tr[p].sum = tr[lc].sum + tr[rc].sum;
}
// 建树
void build(int p,int l,int r)// p为节点号
{
tr[p] = { 0,l,r };
if (l == r)
{
tr[p].sum = a[l];
return;
}
int mid = (l + r) >> 1;
build(lc, l, mid);
build(rc, mid+1, r);
// tr[p].sum = tr[lc].sum + tr[rc].sum;
// 左右⼦树构建完成之后,维护 sum 信息
pushup(p);
}时间复杂度: O ( n ) \boldsymbol{O(n)} O(n)
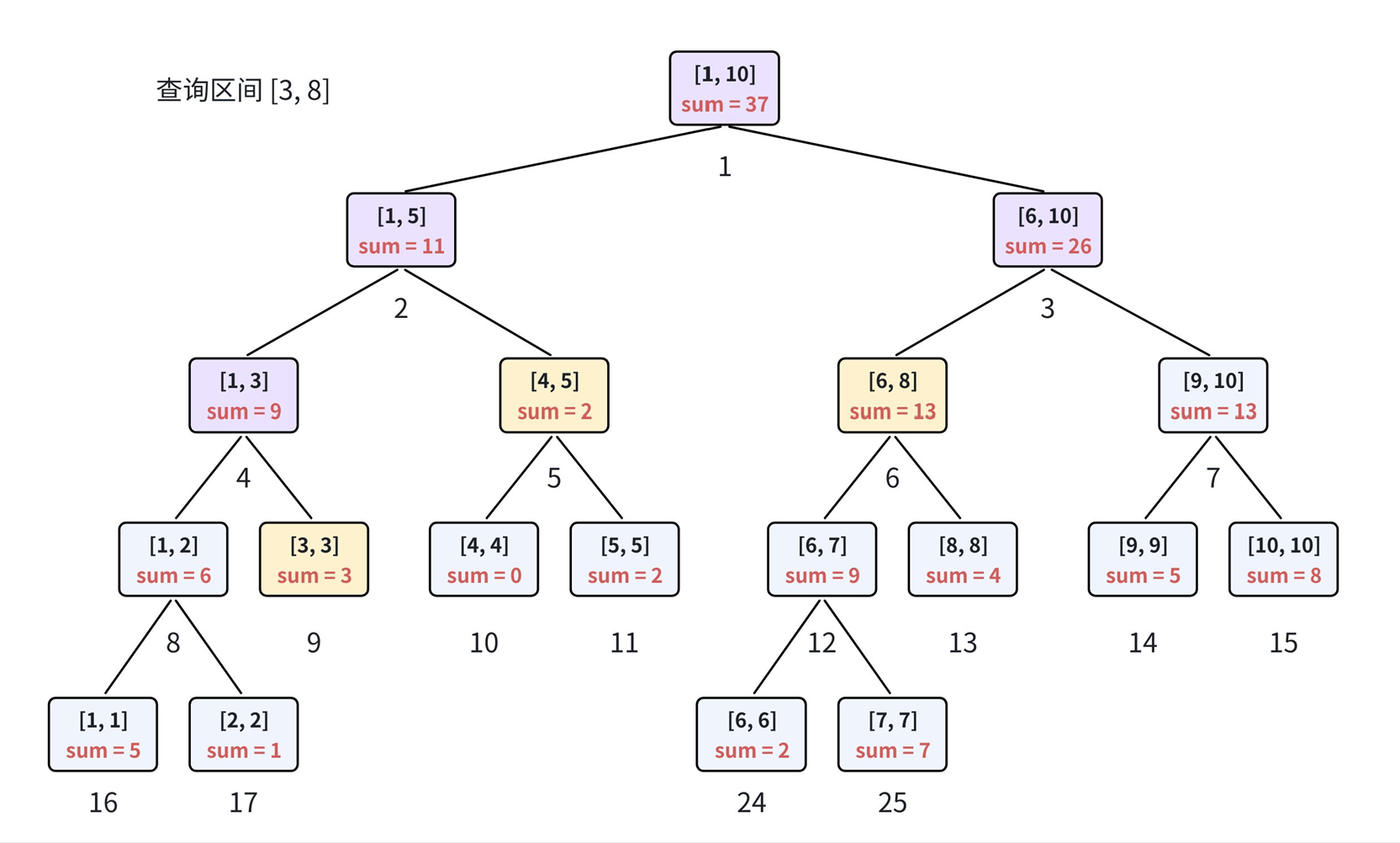
3.区间查询
采用拆分+拼凑思想,在线段树节点中聚合统计结果,执行流程如下:
- 从根节点开始向下递归遍历;
- 若当前节点所管辖区间完全包含在查询区间内,直接返回该节点存储的统计信息;
- 若当前节点左子区间与查询区间存在范围重叠,递归查询左子树;
- 若当前节点右子区间与查询区间存在范围重叠,递归查询右子树。
以数组 a = 5 , 1 , 3 , 0 , 2 , 2 , 7 , 4 , 5 , 8 \boldsymbol{a = 5, 1, 3, 0, 2, 2, 7, 4, 5, 8} a=5,1,3,0,2,2,7,4,5,8 为例,查询区间 3 , 8 \boldsymbol{3,8} 3,8 的区间和,按上述规则完成信息收集与结果合并。
时间复杂度
线段树区间查询仅沿两条分支路径 向下递归,每条路径至多在部分节点处额外访问单个分支节点 ,不会遍历整棵树。
因此区间查询整体时间复杂度为 O ( log n ) \boldsymbol{O(\log n)} O(logn)。
cpp
// 区间查询
LL query(int p, int x, int y)
{
// 查询当前节点包含区间
LL l = tr[p].l, r = tr[p].r;
// 若当前节点被待求区间全包含,直接返回信息
if (x <= l && r <= y)return tr[p].sum;
int sum = 0, mid = (l + r) >> 1;
// 继续向下递推查询子节点信息
if (x <= mid)sum += query(lc, x, y);
if (y > mid)sum += query(rc, x, y);
return sum;
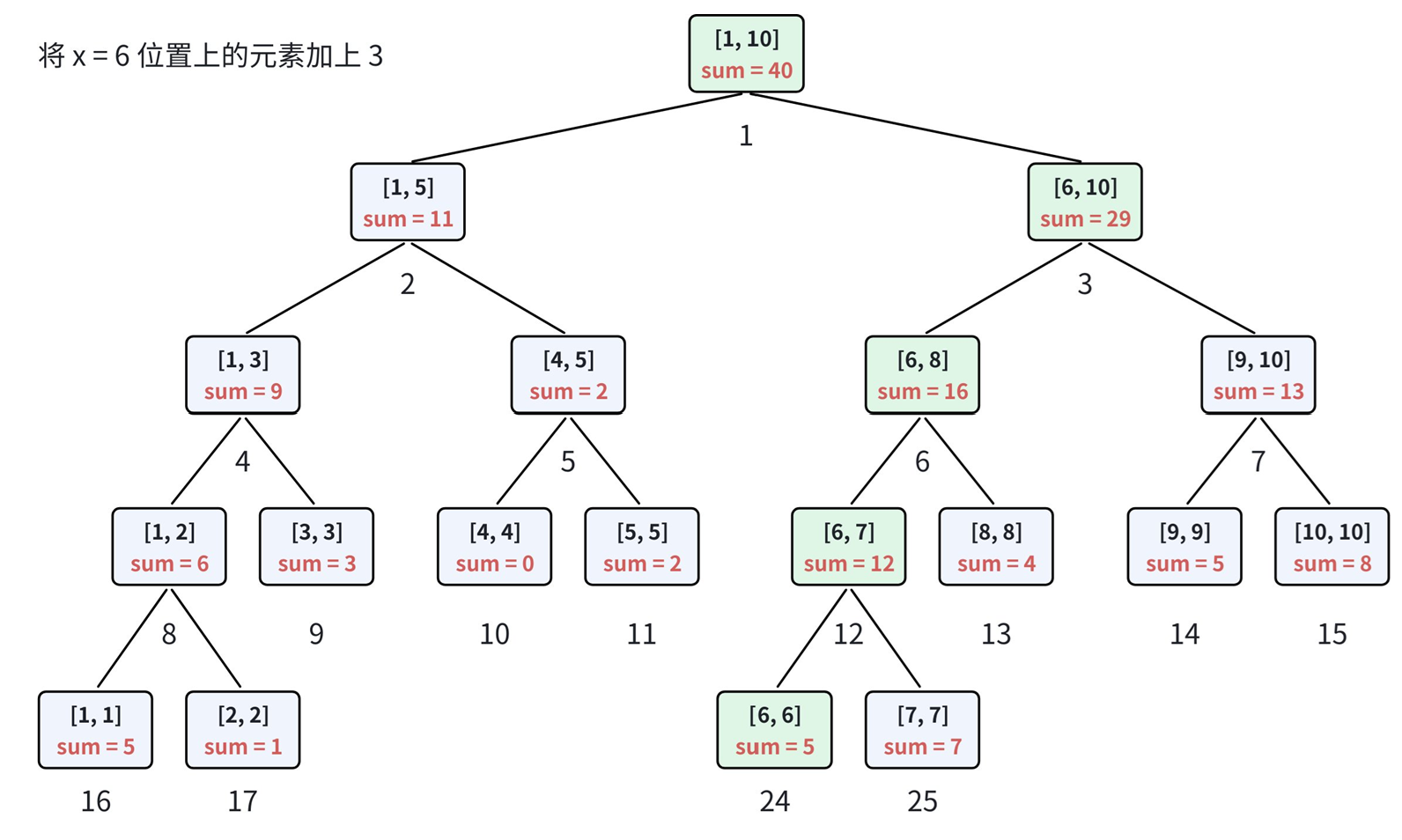
}4.单点修改
例如:将指定位置上的数加上一个数。(如果是对单个位置上的数执行:减去一个数,乘上一个数,除以一个数的操作,都可以转换成加上一个数)
示例:将位置 x = 6 \boldsymbol{x=6} x=6 的元素 增加 3。
具体流程:
- 递归找到目标叶子结点,并更新该结点维护的信息;
- 自底向上回溯 ,更新路径上所有结点的信息 ,保证所有结点维护的值为修改后的最新结果。
cpp
// 单点修改 x为待找的位置
void modify(int p, int x, LL k)
{
int l = tr[p].l, r = tr[p].r;
// 找到目标节点,修改
if (l == x && r == x)
{
tr[p].sum += k;
return;
}
int mid = (l + r) >> 1;
if (x <= mid)modify(lc, x, k);
else modify(rc, x, k);
// 重新整合左右子树信息
pushup(p);
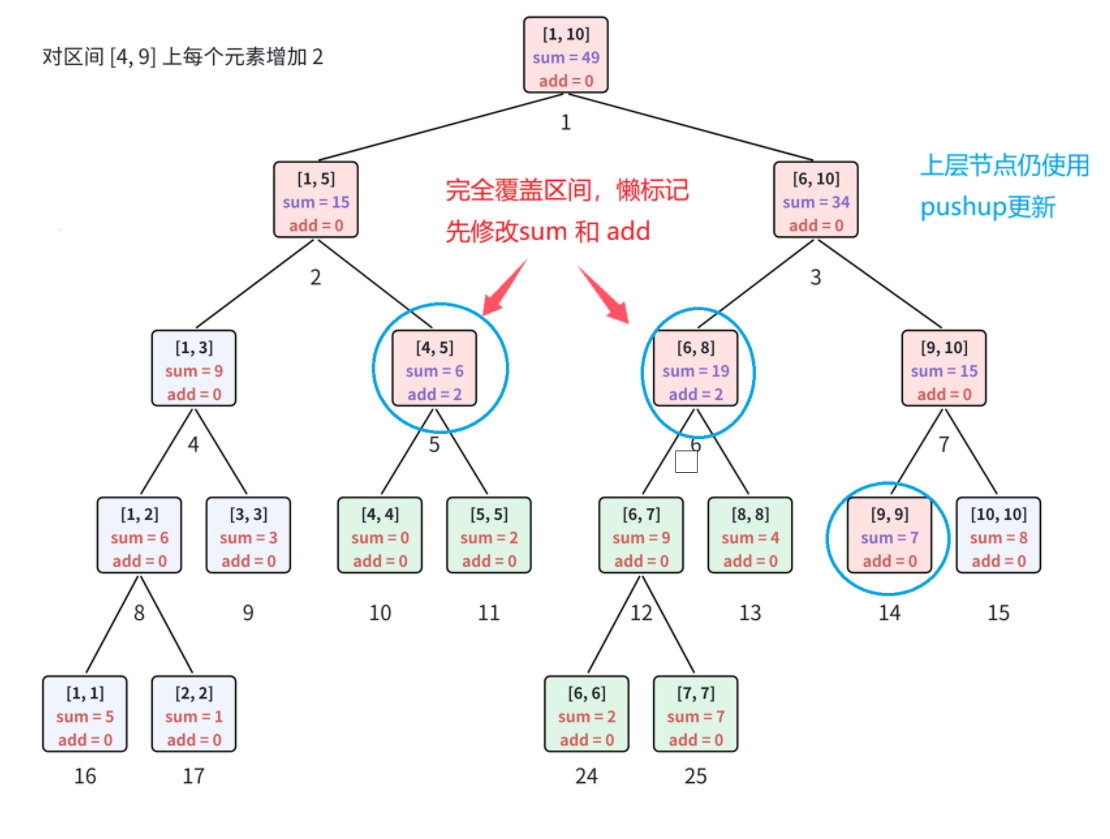
}5. 区间修改(懒标记)
例如:对区间 4 , 9 4,9 4,9 内每个元素统一增加数值。
若采用单点修改方式,逐个修改区间内所有元素,时间复杂度为 O ( n ) O(n) O(n),效率极低。
思路优化:
若当前结点所管辖区间 l , r l,r l,r,能被修改区间 x , y x,y x,y 完全覆盖 ,就可以在 O ( 1 ) O(1) O(1) 时间内直接更新该区间统计信息,无需递归修改左右子节点 ,延迟处理子节点更新操作(在以后查询/修改时向下更新)。
基于该思想,在线段树每个结点中额外增设懒标记,实现延迟更新:
- 当当前结点管辖区间被操作区间完全覆盖时,终止递归;直接更新当前区间数据,不向下遍历子节点,同时给当前结点打上区间修改懒标记。
- 后续再次执行查询、区间修改操作,访问到带懒标记的结点时,再将懒标记向下下放传递,更新左右子节点数据并清空当前结点标记。
通过懒标记延迟更新策略,将区间修改的时间复杂度由 O ( n ) O(n) O(n) 压缩至 O ( log n ) O(\log n) O(logn),与区间查询时间复杂度持平。
下面进行一次区间修改懒标记 和 一次查询向下更新标记、懒标记的示例
以数组 a = 5 , 1 , 3 , 0 , 2 , 2 , 7 , 4 , 5 , 8 \boldsymbol{a = 5, 1, 3, 0, 2, 2, 7, 4, 5, 8} a=5,1,3,0,2,2,7,4,5,8 为例:
对指定区间内每个元素统一增加值,线段树对应信息维护方式如下。
若执行查询操作:查询区间 5 , 7 5,7 5,7 内所有元素的和,对应信息维护规则如下。
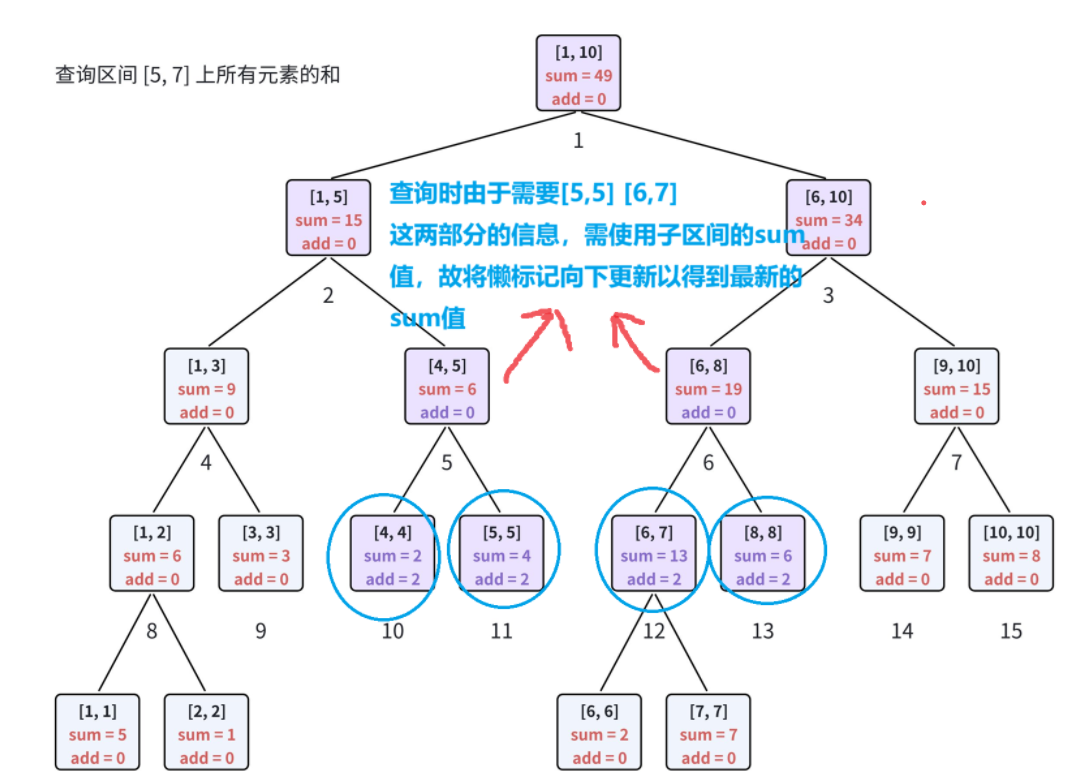
进行区间查询、区间修改时,递归遍历到对应区间,遵循以下规则:
-
当前结点管辖区间 l , r l,r l,r 完全被操作区间 x , y x,y x,y 包含
a. 直接利用区间长度更新区间统计值,无需继续向下递归;
b. 给当前结点打上懒标记,延迟更新子节点,处理完成后直接向上返回。
-
当前结点管辖区间 l , r l,r l,r 仅部分落在操作区间 x , y x,y x,y 内
a. 先执行
pushdown,将当前结点的懒标记向下下发,更新左右子节点数据;b. 按照操作区间范围,分别递归遍历左、右子区间;
c. 左右子区间递归处理完毕后,执行
pushup,更新维护当前结点的区间汇总信息。
4.树形dp
【树形 dp】
树形 dp,即在树上进行的 dp。由于树是通过递归定义的数据结构,因此树形 dp ⼀般都是在递归中进行。
【树形 dp 解决问题的方式】
对于某个问题,如果用树形 dp 解决,方式是很固定的。在用递归遍历这棵树时:
- 从某个结点向上回溯时,当前这棵子树 已经全部遍历完毕,因此就可以给根节点返回⼀个信息;
- 根节点把所有子树遍历完毕之后,整合所有信息,然后向上返回。
⼀句话总结:树形 dp 就是在递归的过程中,根节点拿到所有孩子提供的信息,整合之后向上返回。
在实现树形 dp 的时候,我们⼀般不把信息当成递归的返回值,而是创建⼀个数组存储要返回的信息。因为较为复杂的树形 dp 是要整合很多信息的。
cpp
// 状态表示法
void dfs(int x)
{
f[x] = 1;
for (auto y : edges[x])
{
dfs(y);
f[x] = max(f[x], f[y] + 1);
}
}
// 状态表示法
void dfs(int i)
{
// 到最底,返回0
if (i > n)return ;
int ret = 0;
// 找所有子树最深值
for (auto& e : edges[i])
{
if (!f[e])dfs(e);
ret = max(ret, f[e]);
}
// 加上自己的深度
f[i] = ret + 1;
return ;
}
// 返回值dp法
int dfs(int i)
{
// 到最底,返回0
if (i > n)return 0;
int ret = 0;
// 找所有子树最深值
for (auto& e : edges[i])
{
ret = max(ret, dfs(e));
}
// 加上自己的深度
return ret + 1;
}【树形 dp 分析方式】
在树形 dp 中,我们⼀般思考两个问题,在递归到某⼀个子树的时候:
- 根结点需要子结点提供哪些信息?
- 根结点如何整理子结点提供的信息,并向上返回。
其中:
• 根结点向上返回的信息以及子结点提供的信息是同⼀种信息,就是状态表示 ;
• 根节点整理信息的方式就是状态转移方程 ;
• 递归进入该结点的时候可以初始化,
• dfs 的过程就是填表顺序。(后序遍历)
• 根节点存储的信息,⼀般就是最终结果。
4.1NC6 二叉树中的最大路径和
使用树形dp,res求每颗子树的最大路径和(过根),子树返回的是以我为根单链的最大路径
cpp
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
/**
* @param root TreeNode类
* @return int整型
*/
int res = -0x3f3f3f3f;
int dfs(TreeNode* root)
{
// 到底了
if (root == nullptr)return 0;
// 求左右单链最长值
int l = max(dfs(root->left),0);// 负值会减少路径和
int r = max(dfs(root->right),0);// 负值会减少路径和
// root->val+l+r为当前子树最大路径和(必过根)
res = max(res,root->val+l+r);// 为负值就不加
// 返回子树单链
return max(l, r) + root->val;
}
int maxPathSum(TreeNode* root) {
// write code here
dfs(root);
return res;
}
};17.kmp
-
【子串】
选取字符串中连续的一段字符。
-
【前缀】
从字符串首端开始 ,到任意某个位置结束的子串。
字符串长度为
i的前缀,对应区间:1, i -
【真前缀】
属于前缀,但不包含整个字符串本身。
-
【后缀】
从字符串任意某个位置开始 ,到字符串末尾 的子串。
字符串长度为
n、长度为i的后缀,对应区间:n−i+1 , n -
【真后缀】
属于后缀,但不包含整个字符串本身。
-
真公共前后缀(Border)
字符串 s s s 的真公共前后缀 (也叫 b o r d e r \boldsymbol{border} border):
设子串 t t t,满足:
- t t t 是 s s s 的真前缀
- t t t 是 s s s 的真后缀
则 t t t 为字符串 s s s 的真公共前后缀。
-
最长真公共前后缀( π \boldsymbol{\pi} π)
一个字符串中,长度最大 的真公共前后缀,其长度记作 π \boldsymbol{\pi} π。
示例:
字符串: a a b a a b a \boldsymbol{aabaaba} aabaaba
- 所有真公共前后缀: a \boldsymbol{a} a、 a a b a \boldsymbol{aaba} aaba
- 最长真公共前后缀长度: π = 4 \boldsymbol{\pi = 4} π=4
1.2 前缀函数
前缀函数 :对字符串的每一个前缀子串,依次求解其最长真公共前后缀的长度( π \boldsymbol{\pi} π 值)。
以字符串 aabaab 为例:
前缀函数数组中每一位,代表对应固定长度前缀的最长 border 长度,也就是该前缀的最长真公共前后缀长度。
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 前缀子串 | a |
aa |
aab |
aaba |
aabaa |
aabaab |
| π \pi π | 0 | 1 | 0 | 1 | 2 | 3 |
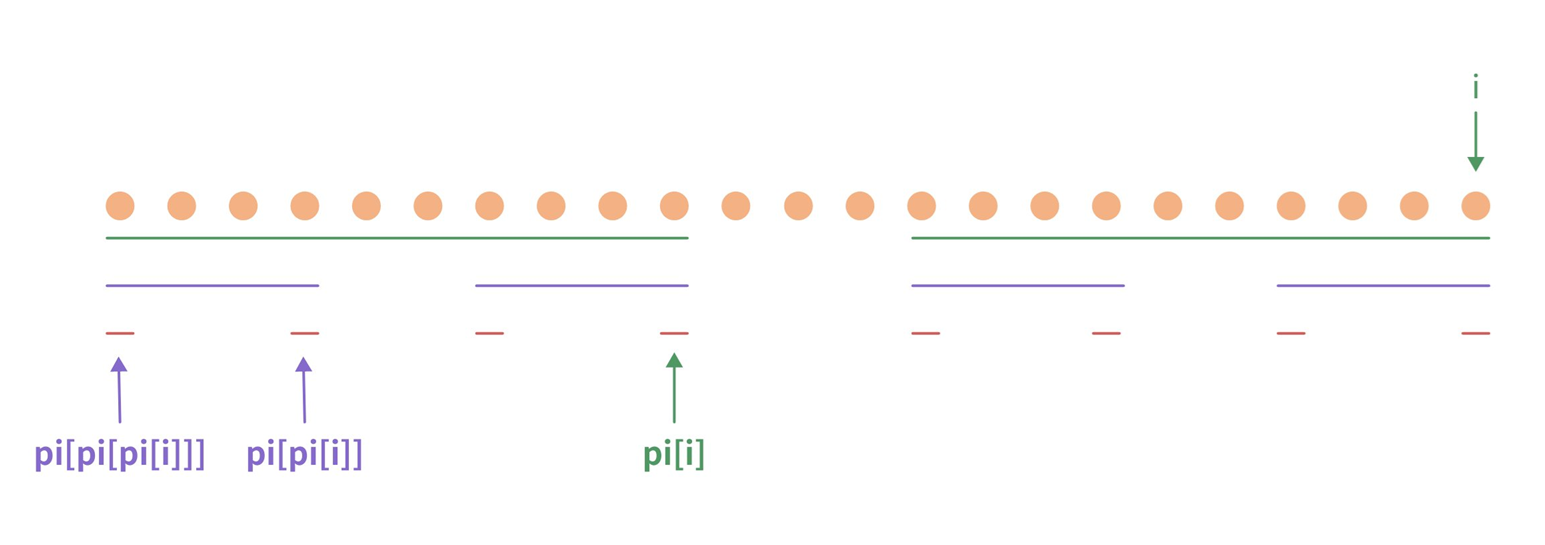
【小用途】
- 可从大到小枚举字符串 s s s 某个前缀的所有 border。
在求出字符串 s s s 的前缀函数表后,可借助该表,从大到小遍历得到某个前缀的全部 border。
核心原理:border 具有传递性
字符串 border 的 border,仍然是该字符串的 border。
1.3 计算前缀函数
前缀函数定义
π i \boldsymbol{\pii} πi 表示:字符串 s s s 长度 为 i i i 的前缀,对应的最长 border 长度(最长真公共前后缀长度)(包含i位置字符)。
以字符串 a a b a a b \boldsymbol{aabaab} aabaab 为例:
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 前缀子串 | a | aa | aab | aaba | aabaa | aabaab |
| π \boldsymbol{\pi} π | 0 | 1 | 0 | 1 | 2 | 3 |
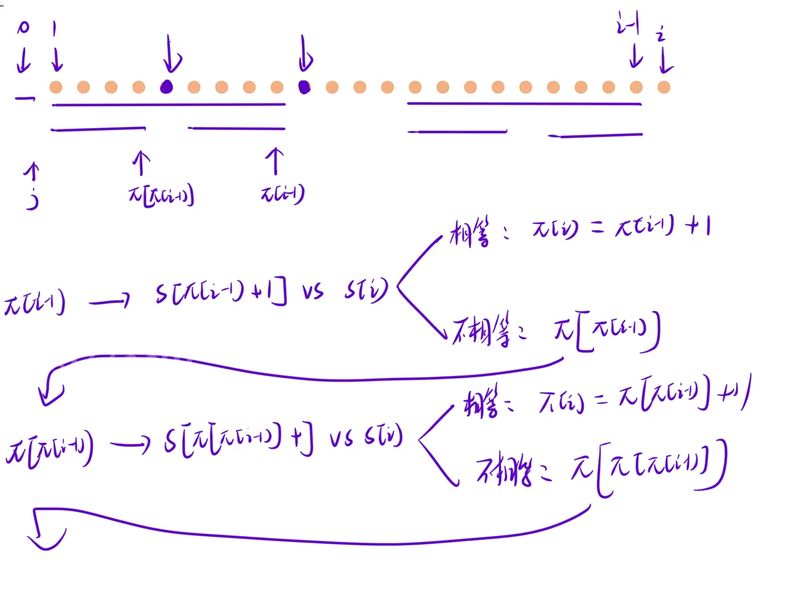
前缀函数计算原理
计算前缀函数包含动态规划思想,通过状态转移逐步推导。
-
状态表示
π i \boldsymbol{\pii} πi:字符串 s s s 长度为 i i i 的前缀的最长 border 长度。 -
状态转移逻辑
- 长度为 i i i 的前缀,其候选边界,可由长度为 i − 1 i-1 i−1 的前缀的 border 推导;
- 从大到小枚举 i − 1 i-1 i−1 前缀的所有 border;
-
依次比对当前 border 的下一个字符与 s i si si:
- 若字符相等:该长度即为 π i \boldsymbol{\pii} πi;
- 若字符不相等:继续向前寻找更小 border,直至遍历完毕。
前缀函数(π数组)标准代码实现
cpp
时间复杂度分析
模拟算法执行过程可得: i i i 指针只会向后递增; j j j 指针单次最多后移一位 (此时i也向后移动,所以 i − j i-j i−j不会变小),不匹配时仅向前回跳,不会重复无效遍历。
整体所有指针操作至多遍历字符串两遍,
因此前缀函数算法时间复杂度为 O ( n ) \boldsymbol{O(n)} O(n)。
2. 周期和循环节
【周期】
- 对于字符串 s s s 和正整数 p p p,若对 1 ≤ i ≤ ∣ s ∣ − p 1 \le i \le |s|-p 1≤i≤∣s∣−p 均满足 s i = s i + p si = si+p si=si+p,则称 p p p 为字符串 s s s 的一个周期。
示例 :字符串 abbabba 的周期有 3 , 6 , 7 3, 6, 7 3,6,7。
【循环节】
- 若字符串 s s s 的周期 p p p 满足 p ∣ ∣ s ∣ \boldsymbol{p \mid |s|} p∣∣s∣( p p p 整除字符串长度),则称 p p p 为 s s s 的一个循环节。
示例 :
字符串 abbabba 的循环节为 7 7 7;
字符串 abbabbabb 的循环节为 3 , 9 3, 9 3,9。
特殊情况 : p = ∣ s ∣ p=|s| p=∣s∣ 既是 s s s 的周期,也是循环节。
【性质】
设字符串 s s s 的长度为 n n n,则:
字符串 s s s 有长度为 p p p 的 border ⟺ n − p \iff n-p ⟺n−p 是字符串 s s s 的周期。
证明直观,画图即可验证。
因此,字符串的周期性等价于 border 的性质,求周期等价于求字符串的 border。
字符串最小的周期 = n - 字符串最长的border
如何求所有的周期?
前缀函数------> 从小到大枚举所有border