仿 muduo 库 one thread one loop 式并发服务器实现
本项目主要是实现一个高并发的服务器组件,可以简洁快速的完成一个高性能服务器的搭建。并且该组件内部可以提供不同应用层的协议支持,本项目中主要使用 HTTP 协议进行一个搭配。
一、Reactor模型
Reactor 模型是一种高性能网络编程架构,其核心是采用事件驱动与 I/O 多路复用技术实现单线程或少量线程对海量连接的高效管理。将新到来的连接的文件描述符统一注册到多路复用接口(如 epoll)进行监控。主线程通过系统调用(如 epoll_wait)同步等待多个连接上的 I/O 事件就绪,当某一个连接出现可读、可写等请求时,多路复用器返回其就绪的文件描述符以及就绪的事件,由 Reactor 的分发器(Dispatcher)依据其就绪的事件和文件描述符触发对应的回调函数(非阻塞的处理)。
1.1 单 Reactor 单线程
思想: 所有操作都在一个线程中完成。
流程
-
通过主线程的 Reactor 进行事件的监听。
-
触发事件后,进行事件处理。
-
如果是新连接请求,则获取新链接,并添加至多路复用模型中进行事件监控。
-
如果是数据通信,则进行 接收数据、处理数据、发送响应。
-
优缺点
-
所有操作均在同一个线程中完成,思想流程比较简单,不涉及线程通信及资源争抢问题。
-
无法有效的利用 CPU 多核资源,当一个连接处理较慢会影响后续的连接处理以及获取新链接。
适用场景: 适用与客户端数量较少,且处理速度较为快速的场景(如 Redis)。
1.2 单 Reactor 多线程
思想: 获取新链接以及对应事件的I/O处理均在主线程的 Reactor 中完成,而数据的处理则通过线程池去完成。
流程
-
通过主线程的 Reactor 进行事件的监听。
-
触发事件后,进行事件处理。
-
如果是新连接请求,则获取新连接,并添加至多路复用模型进行事件监控。
-
如果数据通信,则接收数据后封装成任务分发给业务线程池进行业务处理。
-
工作线程处理完毕后,将响应交给主线程中的 Reactor 进行数据的响应。
-
优缺点
-
充分利用 CPU 多核资源。
-
单个 Reactor 承担所有事件的监听和I/O的读取与响应,高并发场景下容易造成性能瓶颈;多线程间数据共享和同步复杂。
使用场景: 业务处理耗时的场景。
1.3 多 Reactor 多线程
多 Reactor 多线程又称为主从 Reactor 模型。
结构
-
主 Reactor:主线程,通常只有一个,主要负责监听新连接以及将新链接分发到子 Reactor 中进行监控。
-
子 Reactor:子线程,通常有多个,主要负责进行通信上的监控(只处理I/O),有事件触发,则读取数据将数据分发给业务线程池进行处理。
-
工作线程处理完毕后,将响应交给子 Reactor 线程进行响应。
优点: 重复利用 CPU 多核资源,每个 Reactor 各司其职。
本项目主要实现主从 Reactor 模型服务器,主 Reactor 获取新连接后分发给子 Reactor 进行通信事件监控。而子 Reactor 监控各自的文件描述符的读写事件进行数据读写以及业务处理。
二、功能模块划分
基于以上的理解,我们要实现的是一个带有协议支持的主从 Reactor 模型的高性能服务器,因此整个项目主要划分为两个大模块。
-
server模块:实现基于 Reactor 模型的 TCP 服务器。
-
协议模块:对当前 Reactor 模型服务器提供应用层协议的支持。
2.1 server模块
server 模块就是对所有的连接以及线程进行管理,具体的管理分为三个方面:
-
监听连接管理:对监听连接进行管理。
-
通信连接管理:对通信连接进行管理。
-
超时连接管理:对超时连接进行管理。
基于以上的管理思想,将整个模块进行细致的划分又可以划分为以下多个子模块:
2.1.1 Buffer模块
Buffer模块是一个用户态的缓冲区模块,用于实现通信中用户态的接收和发送缓冲区功能,Buffer模块的意义是:
-
防止接收到的数据不是一个完整的请求,因此对接收的数据进行缓冲。
-
对于响应给客户端的数据,也应该是在套接字可写的情况下才能进行发送,因此对发送的数据进行缓冲。
功能设计
-
向缓冲区中添加数据。
-
从缓冲区中读取数据。
2.1.2 Socket模块
Socket模块主要是对套接字操作进行封装的模块,简化套接字的操作。
功能设计
-
创建套接字。
-
绑定地址信息。
-
开始监听。
-
向服务器发起连接。
-
获取新链接。
-
接收数据。
-
发送数据。
-
关闭套接字。
-
创建一个监听连接。
-
创建一个客户端连接。
2.1.3 Channel模块
Channel模块是对一个描述符的可读、可写、错误等事件进行管理的模块,以及当某个事件就绪之后,对于就绪的文件描述符和事件进行对应的回调处理。
功能设计
-
判断描述符是否可读。
-
判断描述符是否可写。
-
设置描述符的可读事件监控。
-
设置描述符的可写事件监控。
-
解除可读事件监控。
-
解除可写事件监控。
-
解除所有事件监控。
-
当描述符监控的事件就绪之后的处理:
-
处理可读事件就绪后的回调函数
-
处理可写事件就绪后的回调函数
-
处理客户端关闭事件就绪后的回调函数
-
处理错误事件就绪后的回调函数
-
处理任意事件就绪后的回调函数
-
2.1.4 Connection模块
Connection模块是对Buffer模块,Socket模块,Channel模块整体的一个封装模块,实现了对一个 通信套接字的整体管理,对于每一个新链接都会使用 Connection 模块进行管理。
功能设计
-
提供向 Channel 模块提供可读事件就绪后、可写事件就绪后、错误事件就绪后等其他事件就绪后的回调处理函数。
-
关闭连接。
-
发送数据。
-
应用层协议的切换。
-
启动非活跃连接超时释放(避免恶意连接不通信只占用服务器资源)。
-
取消非活跃连接超时释放。
-
回调函数设置,由用户设置的,因为我们组件的设计者并不清楚用户要如何处理事件,因此提供一些回调函数由组件的使用者设置。而当 Acceptor 获取到新连接的文件描述符后,该模块负责创建并初始化一个 Connection 对象,并由 Acceptor 模块设置回调。
-
连接建立完成的回调。
-
连接有新数据接收成功的回调。
-
连接关闭的回调。
-
产生任意事件的回调。
-
2.1.5 Acceptor模块
Acceptor模块主要对 监听的套接字进行管理 的模块。当每获取一个新连接的文件描述符,使用 Connection 对象进行封装,并为 Connection 设置不同的回调函数。
功能设计
- 回调函数的设置,因为 Acceptor 模块负责为 Connection 模块设置事件就绪并读取完毕后的回调函数,而 Acceptor 同样也不是组件的使用者,并不清楚如何处理事件,所以 Acceptor 的回调函数又上层的 TcpServer模块设置。
2.1.6 TimerQuque模块
定时任务模块,让一个任务在指定的时间之后被执行。组件内部,对于非活跃连接希望在 N 秒之后被释放。
功能设计
-
添加定时任务。
-
刷新定时任务。
-
取消定时任务。
2.1.7 Poller模块
Poller模块是对 epoll 进行封装的模块,用于对任意描述符进行IO事件监控的设置,简化对 epoll 的操作(添加、删除、修改)。
功能设计
-
添加事件监控(对于 Channel 模块管理的监听事件,通过 Poller 模块对其进行内核层面的添加、修改以及删除)。
-
修改事件监控。
-
移除事件监控。
2.1.8 EventLoop模块
EventLoop模块可以理解为Reactor模块,这个模块其实就是 one thread one loop 中的 loop,一个 EventLoop 模块对应一个线程。EventLoop 模块主要进行事件监控管理(通信事件、定时事件)的模块。
每一个 Connection 连接,都会绑定一个 EventLoop 模块和线程,对于外界对连接的所有操作,都必须要放到同一个 EventLoop 线程中执行的(防止多个线程操作同一个 Connection 出现线程安全问题)。
功能设计
-
将一个对于连接的操作添加到任务队列中(所有对 Connection 的操作均要在管理它的 EventLoop 线程中执行)。
-
定时任务的添加。
-
定时任务的刷新。
-
定时任务的取消。
2.1.9 TcpServer模块
对于所有子模块的整合模块,用于组件使用者快速简单的搭建高性能服务器的模块。
功能设计
-
对于监听连接的管理(获取一个新连接之后如何处理,由Server模块设置)。
-
对于通信连接的管理(连接产生的某个事件如何处理,由Server模块设置)。
-
对于超时连接的管理(连接非活跃超时是否关闭,由Server模块设置)。
-
对于事件监控的管理(启动多少个线程,有多少个EventLoop,有Server模块设置)。
-
事件回调函数的设置(由组件使用者设置,TcpServer 设置给各个 Conncetion 连接)。
2.2 HTTP模块
HTTP协议模块用于对高并发服务器进行协议支持,基于提供的协议支持能够更方便的完成服务器的搭建。
2.2.1 Util模块
这个模块主要是一个工具模块,提供一些HTTP协议模块所用到的一些工具函数,比如url编码解码以及文件读写等。
2.2.2 HttpRequest模块
HttpRequest模块是HTTP请求数据模块,用于保存HTTP请求数据被解析后的各项请求元素信息。
2.2.3 HttpResponse模块
HttpResponse模块是HTTP响应数据模块,用于业务处理后设置并保存HTTP响应数据的各项元素信息,最终按照HTTP协议响应格式组织并发送给客户端。
2.2.4 HttpContext模块
HttpContext模块是一个HTTP请求接收的上下文模块,主要是为了防⽌在⼀次接收的数据中,不是⼀个完整的HTTP请求,则解析过程并未完成,⽆法进⾏完整的请求处理,需要在下次接收到新数据后继续根据上下⽂进⾏解析,最终得到⼀个HttpRequest请求信息对象,因此在请求数据的接收以及解析部分需要一个上下文来进行控制接收和处理的节奏。
三、server模块实现
3.0 简单日志的设计
cpp
// 日志模块的设计
#define DEBUG 0
#define INFO 1
#define ERROR 2
#define LOG_LEVEL DEBUG
#define LOG(level , format , ...) do { \
if(level < LOG_LEVEL) break; \
time_t tiemstacp = time(nullptr); \
struct tm* time_info = localtime(&tiemstacp); \
char format_time_buffer[1024] = {0}; \
strftime(format_time_buffer , 1023 , "%Y-%m-%d %H:%M:%S" , time_info); \
fprintf(stdout , "[%lx %s:%s:%d] " format "\n" , pthread_self() , format_time_buffer , __FILE__ , __LINE__ , ##__VA_ARGS__); \
} while(0)
#define DEBUG_LOG(format , ...) LOG(DEBUG , format , ##__VA_ARGS__)
#define INFO_LOG(format , ...) LOG(INFO , format , ##__VA_ARGS__)
#define ERROR_LOG(format , ...) LOG(ERROR , format , ##__VA_ARGS__)-
反斜杠
\的作用:宏定义换行连接符,表示下一行是宏定义的延续。 -
do-while(0)的作用:-
将多语句包装成单语句,解决宏展开后的语法问题。
-
允许在宏内部使用
break,实现条件退出。 -
强制调用者加分号,代码风格统一。
-
-
if(level < LOG_LEVEL) break;:如果当前日志级别低于设定的全局日志级别,直接跳出do-while,不执行后续的任何代码。 -
...的作用:定义可变参数,表示可以接受任意数量的参数。 -
__VA_ARGS__:预定义标识符,代表所有的可变参数。 -
##__VA_ARGS__的作用:当可变参数为空时,##会删除前面的逗号,避免编译错误。 -
localtime的基本用法:
c
time_t timestacp = time(nullptr);
struct tm* time_info = localtime(×tacp);
/*
struct tm {
int tm_sec; // 秒 [0-59]
int tm_min; // 分 [0-59]
int tm_hour; // 时 [0-23]
int tm_mday; // 日 [1-31]
int tm_mon; // 月 [0-11](注意:0代表1月)
int tm_year; // 年(从1900年开始计数)
int tm_wday; // 星期 [0-6](0代表周日)
int tm_yday; // 年中的第几天 [0-365]
int tm_isdst; // 夏令时标志
};
*/strftime的基本用法:
c
// 函数原型
size_t strftime(char *s, size_t max, const char *format, const struct tm *tm);
char format_time_buffer[1024] = {0};
strftime(format_time_buffer, 1023, "%Y-%m-%d %H:%M:%S", time_info);3.1 时间轮定时器的设计与实现
时间轮是定时器设计中一种高效管理大量定时任务的数据结构。
核心思想: 将时间分隔成多个 槽(slot),每个槽对应一个时间间隔(比如1秒),所有的槽组成一个环形数组(类似时钟的表盘)。指针(tick)按固定时间间隔移动一个单位,当指针指向某个槽时,执行该槽对应的所有定时任务。
基本结构
-
轮(wheel):一个环形数组,每个元素又是一个数组或链表,存储定时任务。
-
间隔(tick) :每个槽代表的时间长度(如1s)。
tick指针每隔固定时间移动一个单位。
具体的实现思路: 通过 类的析构函数 与 std::shared_ptr。
-
自动执行机制:将一个定时任务放在一个类的析构函数中,则这个定时任务在对象被释放的时候就会自动执行。
-
动态失效机制:使用
shared_ptr管理定时任务对象,当引用计数为0时,对象才真正释放,执行析构函数。
应用示例
-
初始状态:连接建立,创建定时任务对象,设定 30s 后释放。
-
中途操作:第 10s 该连接有通信。
-
创建一个新的基于当前通信连接的定时任务对象,设定基于当前时间 30s 后释放操作,而这个通信连接的定时任务对象又是被
shared_ptr管理起来的。 -
此时两个
shared_ptr指向同一个对象,引用计数 = 2。
-
-
原定时点:第 30s 到达。
- 第一个
shared_ptr释放,引用计数减为1,并不会销毁管理的定时任务对象,也就没有执行析构函数执行对应的定时任务。
- 第一个
-
新定时点:第 40s 到达。
- 第二个
shared_ptr释放,引用计数减为0,销毁对象,执行析构函数,连接关闭。
- 第二个
多级时间轮的扩展
单级时间轮的局限,当一个时间范围很大的时候,那么如果单纯使用一个秒级时间轮,就会造成内存消耗很大的情况。那么我们可以通过将多个单位时间轮分层,形成类似(时、分、秒)的多级时间轮结构。
结构:时级时间轮(24个槽)、分级时间轮(60个槽)、秒级时间轮(60个槽)。
任务添加(以1小时5分30秒后执行为例),将对应的定时任务对象放入时级时间轮的对应位置中,当 时级定时轮的tick指针 走到对应的槽位时,我们此时执行的不是销毁动作,而是 将对应的定时对象放入到分级时间轮的对应位置,同理,当分级时间轮的 tick 指针走到对应的槽位时,我们将对应槽位的所有定时任务对象移动到秒级时间轮的相位置中,直到秒级时间轮的 tick 指针指向对应的槽位时,此时执行的才是真正的销毁动作。
为什么需要时间轮?
在网络编程中,经常需要处理定时任务:比如客户端建立连接,但是不发送数据,空占我们服务器的资源,因此每个连接建立时设置一个超时时间,如果在规定时间内没有收到任何数据,就自动关闭这个连接,释放资源。
-
传统的做法是用最小堆或红黑树管理定时任务,但这些结构在大量定时任务的场景下,插入和删除的时间复杂度是
O(logN)。 -
时间轮算法应运而生,它通过空间换时间的思想,将定时任务的插入、删除、取消都优化到了
O(1)的时间复杂度。
核心的数据结构
TimerTask 定时任务类:设计的巧妙之处 在于,定时任务的执行逻辑放在析构函数中,这意味着只要 TimerTask 对象被销毁,就会自动执行任务。这为时间轮的管理提供了极大便利。
TimerWheel 时间轮管理器。
-
_wheel负责时间调度:决定任务什么时候执行。 -
_tasks负责任务查找:用于刷新、取消等操作。
为什么用 weak_ptr 管理任务?
使用weak_ptr而不是shared_ptr的原因是避免循环引用。
cpp
std::unordered_map<uint64_t, std::weak_ptr<TimerTask>> _tasks;-
_wheel中的shared_ptr持有任务对象,如果_tasks也用shared_ptr,任务永远无法释放 ,因此使用
weak_ptr可以安全的观察任务是否存在,刷新和删除时 ,通过id寻找到weak_ptr使用lock()提升为shared_ptr进行操作。 -
刷新原理: 不删除原有任务,而是在新的时间槽再添加一份相同的任务,原来的任务会在指针到达那个槽位时会清空(其实就是引用计数 - 1),并不会实质的执行定时任务。
-
在对象析构期间,
weak_ptr::lock()会返回空指针,对于weak_ptr谨记检查为空。
timerfd_系列的介绍
timerfd_create 是 Linux 提供的一个非常有用的定时器接口,它将定时器抽象成了一个文件描述符,使得定时器可以融入 I/O 多路复用(如epoll、select)的事件循环中。这正是时间轮实现中,能让定时器和 EventLoop 完美结合的关键。
- 当定时器超时时,timerfd 变为可读。读取 timerfd 会返回一个 uint64_t(8字节) 类型的值,表示自上次读取以来发生的超时次数。
函数原型
cpp
#include <sys/timerfd.h>
// 创建一个新的定时器文件描述符。这个描述符可以像普通文件描述符一样被监听(可读事件),当定时器超时时,描述符变为可读
/*
clockid参数:
CLOCK_REALTIME // 系统实时时间(墙钟时间),会受到手动修改系统时间的影响
CLOCK_MONOTONIC // 系统开机到现在的时间(单调递增),不受修改系统时间影响
flags参数:
0 // 默认行为
返回值:成功返回新的文件描述符,失败返回-1
*/
int timerfd_create(int clockid, int flags);
// 启动或修改定时器的超时时间
/*
struct timespec {
time_t tv_sec; // 秒
long tv_nsec; // 纳秒
};
struct itimerspec {
struct timespec it_interval; // 第一次超时时间后,每次超时的间隔时间
struct timespec it_value; // 定时器的第一次超时时间
};
参数:
fd:timerfd_create返回的文件描述符
flags:0 表示相对时间,TFD_TIMER_ABSTIME 表示绝对时间
new_value:设置新的超时时间
old_value:返回之前的超时设置(可为 nullptr)
*/
int timerfd_settime(int fd, int flags, const struct itimerspec *new_value, struct itimerspec *old_value);
int timerfd_gettime(int fd, struct itimerspec *curr_value);代码实现
cpp
// 时间轮与定时任务的设计
using TimerTaskFun = std::function<void()>;
using ReleaseTaskFun = std::function<void()>;
class TimerTask {
private:
uint64_t _timer_id; // 定时任务id
int _timeout; // 延迟时间
bool _cancel; // 是否执行定时任务
TimerTaskFun _task; // 定时任务
ReleaseTaskFun _release_task; // 删除当前任务在时间轮管理容器中的回调函数
public:
TimerTask(uint64_t timer_id , int timeout , const TimerTaskFun& task)
:_timer_id(timer_id)
,_timeout(timeout)
,_task(task)
,_cancel(true)
{}
// 获取定时任务的延迟时间
int getDelayTime() { return _timeout; }
// 设置删除当前任务在时间轮管理容器中的回调函数
void setReleaseTask(const ReleaseTaskFun& release_task) { _release_task = release_task; }
// 取消定时任务的执行
void cancelTimerTask() { _cancel = false; }
// 析构函数中执行定时任务
~TimerTask() {
if(_cancel) _task();
// 任务执行完毕后,将其从时间轮的哈希表中移除
_release_task();
}
};
class TimerWheel{
private:
int _capacity; // 时间轮的大小
std::vector<std::vector<std::shared_ptr<TimerTask>>> _wheel; // 时间轮
int _tick; // 指针
std::unordered_map<uint64_t , std::weak_ptr<TimerTask>> _tasks; // 管理所有的任务
EventLoop* _loop; // 一个时间轮绑定一个EventLoop
int _timerfd; // 定时器的文件描述符
Channel _timerfd_channel;
static int createTimerfd() {
// CLOCK_MONOTONIC 使用系统开机的相对时间(不受手动修改系统时间的影响)
int timerfd = timerfd_create(CLOCK_MONOTONIC , 0);
if(timerfd < 0) {
ERROR_LOG("create timerfd failed");
abort();
}
INFO_LOG("timewheel create timerfd success: %d" , timerfd);
/*
struct timespec {
time_t tv_sec; // 秒
long tv_nsec; // 纳秒
};
struct itimerspec {
struct timespec it_interval; // 间隔时间(周期性定时)
struct timespec it_value; // 第一次超时时间
};
*/
struct itimerspec itimer;
itimer.it_value.tv_sec = 1; // 第一次超时时间
itimer.it_value.tv_nsec = 0;
itimer.it_interval.tv_sec = 1; // 第一次超时时间后,每次超时的间隔时间
itimer.it_interval.tv_nsec = 0;
timerfd_settime(timerfd , 0 , &itimer , nullptr); // flag: 0表示相对时间
return timerfd;
}
// 读取 timerfd
void readTimerfd() {
uint64_t val = 0;
int res = read(_timerfd , &val , sizeof(val));
if(res < 0) {
ERROR_LOG("read timerfd failed");
abort();
}
}
// 指针向下走一步
void nextTick() {
// tick指针向下走一步,并执行该位置的所有定时任务
_tick = (_tick + 1) % _capacity;
_wheel[_tick].clear();
}
void onTime() {
readTimerfd();
nextTick();
}
// 添加一个定时任务
void addTimerTaskInLoop(uint64_t timer_id , int delay , const TimerTaskFun& task) {
if(hasTimerTask(timer_id)) {
// 若当前定时任务存在,就刷新一下定时任务
return refreshTimerTask(timer_id);
}
// 新增定时任务逻辑
std::shared_ptr<TimerTask> timer_task = std::make_shared<TimerTask>(timer_id , delay , task);
// 设置定时任务执行结束后在时间轮管理容器中删除的回调函数
timer_task->setReleaseTask([& , this](){
std::unordered_map<uint64_t , std::weak_ptr<TimerTask>>::iterator iter = _tasks.find(timer_id);
if(iter != _tasks.end()) {
_tasks.erase(iter);
}
});
int pos = (_tick + delay) % _capacity;
_wheel[pos].push_back(timer_task);
// 将新添加的定时任务管理起来
_tasks[timer_id] = timer_task;
}
// 刷新定时任务
void refreshTimerTaskInLoop(uint64_t timer_id) {
if(hasTimerTask(timer_id)) {
// 定时任务id存在才能刷新定时任务
std::shared_ptr<TimerTask> timer_task = _tasks[timer_id].lock();
int pos = (_tick + timer_task->getDelayTime()) % _capacity;
_wheel[pos].push_back(timer_task);
}
}
// 删除定时任务
void delTimerTaskInLoop(uint64_t timer_id) {
if(hasTimerTask(timer_id)) {
// 这一步很关键!!添加检查
// 在对象析构期间(从析构函数开始执行到结束),weak_ptr::lock() 会返回空指针
// 对于 weak_ptr 时刻谨记检查是否为空
if(_tasks[timer_id].lock())
_tasks[timer_id].lock()->cancelTimerTask();
}
}
public:
TimerWheel(EventLoop* loop)
:_capacity(60)
,_wheel(_capacity)
,_tick(0)
,_loop(loop)
,_timerfd(createTimerfd())
,_timerfd_channel(loop , _timerfd)
{
// 为定时器设置读事件就绪的回调函数
_timerfd_channel.setReadCallback(std::bind(&TimerWheel::onTime , this));
// 设置开启读事件监听 OS每隔一秒向 timefd 中写入数据,timerfd 每隔一秒就会有读事件触发
_timerfd_channel.EnableRead();
}
void addTimerTask(uint64_t timer_id , int delay , const TimerTaskFun& task);
void refreshTimerTask(uint64_t timer_id);
void delTimerTask(uint64_t timer_id);
/*这个接口存在线程安全问题--这个接口实际上不能被外界使用者调用,只能在模块内,在对应的EventLoop线程内执行*/
bool hasTimerTask(uint64_t timer_id) {
std::unordered_map<uint64_t , std::weak_ptr<TimerTask>>::iterator iter = _tasks.find(timer_id);
return iter != _tasks.end(); // 存在返回 true,不存在 false
}
};
// 实现在 EventLoop 类下方
void TimerWheel::addTimerTask(uint64_t timer_id , int delay , const TimerTaskFun& task) {
return _loop->runInLoop(std::bind(&TimerWheel::addTimerTaskInLoop , this , timer_id , delay , task));
}
void TimerWheel::refreshTimerTask(uint64_t timer_id) {
return _loop->runInLoop(std::bind(&TimerWheel::refreshTimerTaskInLoop , this , timer_id));
}
void TimerWheel::delTimerTask(uint64_t timer_id) {
return _loop->runInLoop(std::bind(&TimerWheel::delTimerTaskInLoop , this , timer_id));
} 3.2 Buffer的设计与实现
为什么需要一个这样的缓冲区?
在网络编程中,我们经常遇到这样的情况:从socket读取数据时,可能一次读不完;或者要发送的数据太大,需要分批发。如果每次都重新分配缓冲区,不仅效率低,还容易造成内存碎片。
这个Buffer类的设计就是为了解决这个问题。它基于 环形缓冲区 的思想,通过两个指针来管理读写位置,实现高效的数据缓存。
核心数据结构
类中有三个核心成员:
一个是 vector<char> 类型的_buffer,它是实际存储数据的容器,可以动态扩容。另外两个是uint64_t类型的_rindex和_windex,分别表示读指针和写指针的位置。
读指针指向下一个要读取的数据位置,写指针指向下一个要写入的空闲位置。这两个指针之间的区域就是当前可读的有效数据。
核心思想:延迟拷贝
尽可能复用已有空间,减少扩容和搬移。
基于类中两个下标,我们可以计算出三个重要的空间大小:
头部空闲空间:也就是读指针之前的位置,这部分空间里的数据都已经被读取过了。
可读数据大小:写指针减去读指针的差值,这部分是已经写入但还未读取的有效数据。
尾部空闲空间:缓冲区总大小减去写指针,这部分是从未写入过的空闲区域。
这个Buffer最精妙的设计思想是:不要每次读取数据后都立即移动数据,而是通过移动指针来标记已读区域,等到真正需要空间时才进行数据搬移。
传统的做法是:每次读取数据后,就把后面的所有数据向前拷贝,覆盖掉已读的部分。这样做虽然能保证头部空间一直被释放,但每次读取都要拷贝大量数据,效率很低。
而这里的设计恰恰相反:读取数据时只移动读指针,并不拷贝数据。这样已读的区域就变成了头部空闲空间,但数据还留在原地没有被覆盖。只有等到尾部空间不够用,而头部空闲加上尾部空闲的总空间足够容纳新数据时,才进行一次性的数据搬移。
空间管理策略
当需要写入len字节的数据时,EnsureWriteSpace 函数会根据情况选择三种不同的策略:
第一种情况:如果尾部的空闲空间足够容纳要写入的数据,那么什么都不用做,直接返回。这是最理想的情况,没有任何数据拷贝。
第二种情况:尾部空间不够,但是头部空闲加上尾部空闲的总空间足够。这时候才需要进行一次数据搬移:把当前可读的数据移动到缓冲区的最前面。具体做法是用std::copy把从读指针到写指针之间的数据复制到缓冲区开头,然后把读指针设为0,写指针设为原来可读数据的大小。这样做的优点是虽然进行了一次拷贝,但避免了扩容,而且把所有空闲空间都连续地出现在尾部。
第三种情况:总空闲空间都不够,这时候只能对vector进行扩容,扩容到写指针位置加上需要写入的长度。
代码实现
cpp
// Buffer模块的设计
#define DEFAULT_BUFFER_SIZE 1024
class Buffer{
private:
std::vector<char> _buffer;
uint64_t _rindex;
uint64_t _windex;
public:
Buffer() :_buffer(DEFAULT_BUFFER_SIZE) , _rindex(0) , _windex(0) {}
Buffer(const Buffer& buf) :_buffer(buf._buffer.begin() , buf._buffer.end()) , _rindex(buf._rindex) , _windex(buf._windex) {}
~Buffer() {}
// 返回当前写入位置的起始地址
char* writePosition() { return _buffer.data() + _windex; }
// 返回当前读取位置的起始地址
char* readPosition() { return _buffer.data() + _rindex; }
// 获取尾部空闲空间的大小
uint64_t getTailIdleSize() { return _buffer.size() - _windex; }
// 获取头部空闲空间的大小
uint64_t getHeadIdleSize() { return _rindex; }
// 获取可读空间大小
uint64_t getReadableSize() { return _windex - _rindex; }
// 移动读偏移
void moveReadOffset(uint64_t len) { assert(len <= getReadableSize()); _rindex += len; }
// 移动写偏移
void moveWriteOffset(uint64_t len) { assert(_windex + len <= _buffer.size()); _windex += len; }
// 确保有足够空间写入指定长度数据
void EnsureWriteSpace(uint64_t len) {
if(len <= getTailIdleSize()) {
return;
} else if(len <= getHeadIdleSize() + getTailIdleSize()) {
uint64_t current_readable_size = getReadableSize();
std::copy(readPosition() , writePosition() , _buffer.data());
_rindex = 0;
_windex = current_readable_size;
} else {
// std::cout << "扩容:" << _windex + len << std::endl;
_buffer.resize(_windex + len);
}
}
// 写入数据(不移动写偏移)
void write(const void* data , uint64_t len) {
if(len == 0) return;
EnsureWriteSpace(len);
const char* d = (const char*)data;
std::copy(d , d + len , writePosition());
}
// 写入数据并移动写偏移
void writeAndPush(const void* data , uint64_t len) {
write(data , len);
moveWriteOffset(len);
}
// 写入字符串(不移动写偏移)
void writeString(const std::string& data) {
write(data.c_str() , data.size());
}
// 写入字符串并移动写偏移
void writeStringAndPush(const std::string& data) {
writeString(data);
moveWriteOffset(data.size());
}
// 读取数据到指定缓冲区(不移动读偏移)
void read(void* buf , uint64_t len) {
assert(len <= getReadableSize());
std::copy(readPosition(), readPosition() + len , (char*)buf);
}
// 读取数据到指定缓冲区并移动读偏移
void readAndPop(void *buf , uint64_t len) {
read(buf , len);
moveReadOffset(len);
}
// 读取字符串到stirng中(不移动读偏移)
std::string readAsString(uint64_t len) {
std::string res(len , 0);
read(res.data() , len);
return res;
}
// 读取字符串到string中并移动读偏移
std::string readAsStringAndPop(uint64_t len) {
std::string res = readAsString(len);
moveReadOffset(len);
return res;
}
// 寻找回车换行符
char* findCRLF() {
char* pos = std::find(readPosition() , writePosition() , '\n');
if(pos != writePosition())
return pos;
return nullptr;
}
// 读取一行数据不移动读偏移
std::string getLine() {
char* pos = findCRLF();
if(pos) {
return readAsString(pos + 1 - readPosition()); // 将换行符也读取出来
}
return "";
}
// 读取一行数据并移动读偏移
std::string getLineAndPop() {
std::string res = getLine();
moveReadOffset(res.size());
return res;
}
void clear() { _rindex = _windex = 0; }
};3.3 Socket的设计与实现
这是一个对Linux Socket API进行面向对象封装的C++类。简化了对套接字的操作。
代码实现
cpp
// 套接字模块的设计
#define MAX_BACKLOG 1024
class Socket{
private:
int _sockfd;
public:
Socket() :_sockfd(-1) {}
Socket(int sockfd) :_sockfd(sockfd) {}
~Socket() { close(); }
void close() {
if(_sockfd > 0) {
::close(_sockfd);
_sockfd = -1;
}
}
int fd() { return _sockfd; }
bool create() {
_sockfd = ::socket(AF_INET , SOCK_STREAM , 0);
if(_sockfd < 0) {
ERROR_LOG("listen socket create failed");
return false;
}
INFO_LOG("listen socket create success: %d" , _sockfd);
return true;
}
bool bind(const std::string& ip , uint16_t port) {
struct sockaddr_in addr;
memset(&addr , 0 , sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = inet_addr(ip.c_str());
int res = ::bind(_sockfd , (struct sockaddr*)&(addr) , sizeof(addr));
if(res < 0) {
ERROR_LOG("listen socket bind failed");
return false;
}
INFO_LOG("listen socket bind success: %d" , _sockfd);
return true;
}
bool listen(int backlog = MAX_BACKLOG) {
int res = ::listen(_sockfd , backlog);
if(res < 0) {
ERROR_LOG("listen socket listen failed");
return false;
}
INFO_LOG("listen socket listen success: %d" , _sockfd);
return true;
}
int accept() {
int acceptfd = ::accept(_sockfd , nullptr , nullptr);
if(acceptfd < 0) {
ERROR_LOG("accept failed");
return -1;
}
INFO_LOG("accept success: %d" , acceptfd);
return acceptfd;
}
bool connect(const std::string& ip , uint16_t port) {
struct sockaddr_in addr;
memset(&addr , 0 , sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = inet_addr(ip.c_str());
int res = ::connect(_sockfd , (struct sockaddr*)&(addr) , sizeof(addr));
if(res < 0) {
ERROR_LOG("conncet server failed");
return false;
}
INFO_LOG("conncet server success");
return true;
}
ssize_t recv(void* buf , size_t len , int flags = 0) {
ssize_t res = ::recv(_sockfd , buf , len , flags);
if(res <= 0) {
if(errno == EAGAIN || errno == EINTR) {
return 0; // 这两种错误可以被原谅
}
// 读取错误或对方关闭连接都算错误
ERROR_LOG("sockfd: %d recv failed" , _sockfd);
return -1;
}
return res;
}
ssize_t nonBlockRecv(void* buf , size_t len) {
return recv(buf , len , MSG_DONTWAIT); // MSG_DONTWAIT 表示当前接收为非阻塞
}
ssize_t send(const void* buf , size_t len , int flags = 0) {
ssize_t res = ::send(_sockfd , buf , len , flags);
if(res < 0) {
if(errno == EAGAIN || errno == EINTR) {
return 0; // 不算错误
}
ERROR_LOG("sockfd: %d send failed" , _sockfd);
return -1;
}
return res;
}
ssize_t nonBlockSend(const void* buf , size_t len) {
if(len == 0) return 0;
return send(buf ,len , MSG_DONTWAIT);
}
bool createServer(uint16_t port , const std::string& ip = "0.0.0.0" , int block_flag = false) {
if(!create()) return false;
if(block_flag) setNonBlock();
setReuseAddress();
if(!bind(ip , port)) return false;
if(!listen()) return false;
return true;
}
bool createClient(uint16_t port , const std::string& ip) {
if(!create()) return false;
if(!connect(ip , port)) return false;
return true;
}
bool setNonBlock() {
int flag = fcntl(_sockfd , F_GETFL);
if(flag < 0) {
ERROR_LOG("fcntl failed");
return false;
}
fcntl(_sockfd , F_SETFL , flag | O_NONBLOCK);
return true;
}
void setReuseAddress() {
int opt = 1;
int res = setsockopt(_sockfd , SOL_SOCKET , SO_REUSEADDR , &opt , sizeof(opt));
if(res < 0) {
ERROR_LOG("set reuse address failed");
return;
}
res = setsockopt(_sockfd , SOL_SOCKET , SO_REUSEPORT , &opt , sizeof(opt));
if(res < 0) {
ERROR_LOG("set reuse address failed");
return;
}
}
};3.4 Channel的设计与实现
Channel是Reactor模式中的核心组件,它负责将文件描述符、监听什么事件以及事件发生时的如何处理的回调函数绑定在一起。
设计思想
Channel负责用户层对监听的文件描述符以及就绪事件的管理,Channel 不负责具体的业务逻辑,只负责 分发(调用对应就绪事件的回调函数)。
对于事件监控的开关,每个函数都做了两件事:
-
修改 _events 标志位(用户层)。
-
调用 Update() (更新内核中 epoll 的事件列表)。
Channel 不直接操作 epoll,而是通过 EventLoop 来操作。
事件分发机制 HandlerEvent()
读写事件就绪时使用 if 和 if 的原因是,处理读事件并不会立即释放连接,而是采用一种 延迟释放 的方式,将真正释放连接的函数添加到 EventLoop 的任务队列中,执行流会处理当前所有就绪的 Channel ,调用 Channel 的 HandlerEvent 处理就绪事件。最后执行任务队列中的所有任务(现在才释放当前连接的函数)。
代码实现
cpp
// 用户层对监听和就绪的事件的管理
using event_callback = std::function<void()>;
class Channel{
private:
int _fd;
uint32_t _events; // 监控的事件
uint32_t _revents;// 就绪的事件
// 对应事件就绪后,调用相应的回调函数
event_callback readCallback; // 读事件就绪的回调
event_callback writeCallback; // 写事件就绪的回调
event_callback closeCallback; // 连接挂断后的回调
event_callback errorCallback; // 错误后的回调
event_callback eventCallback; // 任意事件的回调
EventLoop* _loop; // 不同的 Channel 可能属于不同的 EventLoop
public:
Channel(EventLoop* loop , int fd) :_fd(fd) , _events(0) , _revents(0) , _loop(loop) {}
// get/set方法
int fd() { return _fd; }
int events() { return _events; }
int revents() { return _revents; }
void setRevents(uint32_t revents) { _revents = revents; }
// 设置回调方法
void setReadCallback(const event_callback& cb) { readCallback = cb; }
void setWriteCallback(const event_callback& cb) { writeCallback = cb; }
void setErrorCallback(const event_callback& cb) { errorCallback = cb; }
void setCLoseCallback(const event_callback& cb) { closeCallback = cb; }
void setEventCallback(const event_callback& cb) { eventCallback = cb; }
// 查询是否监控了可读与可写事件
bool IsMonitorReadable() { return _events & EPOLLIN; }
bool IsMoinitorWrite() { return _events & EPOLLOUT; }
// 启动或关闭事件监控
void EnableRead() { _events |= EPOLLIN; Update(); }
void EnableWrite() { _events |= EPOLLOUT; Update(); }
void DisableRead() { _events &= ~EPOLLIN; Update(); }
void DisableWrite() { _events &= ~EPOLLOUT; Update(); }
void DisableALl() { _events = 0; Update(); }
// 更新或移除(通过epoll模块对事件进行内核级的更新和移除)
void Remove();
void Update();
// 事件处理函数,根据触发的事件调用相应的回调
void HandlerEvent() {
// EPOLLRDHUP:对方正常关闭连接; EPOLLHUP:连接异常断开(对端异常奔溃)
if(_revents & EPOLLIN || _revents & EPOLLRDHUP || _revents & EPOLLPRI) {
// 刷新连接的活跃度,放在读回调之前是因为可能读错误或连接断开释放连接,在调用任意事件回调就会奔溃
if(eventCallback) eventCallback();
if(readCallback) readCallback(); // 如果调用读回调函数中,造成连接释放,那么后续会造成问题
}
// 有可能释放连接的操作,一次只处理一个
if(_revents & EPOLLOUT) {
if(eventCallback) eventCallback();
if(writeCallback) writeCallback();
} else if(_revents & EPOLLERR) {
if(errorCallback) errorCallback();
} else if(_revents & EPOLLHUP) {
if(closeCallback) closeCallback();
}
}
};
// 更新或移除(通过 EventLoop 中的 epoll模块对事件进行内核级的更新和移除)
void Channel::Remove() { return _loop->removeEvent(this); }
void Channel::Update() { return _loop->updateEvent(this); }3.5 Poller的设计与实现
Poller 是 Reactor 模式的核心引擎,它对 epoll 进行了面向对象的封装,负责内核事件监听和对用户层 Channel 的管理。
设计思想
Channel 负责用户层的事件监听,而 Poller 负责内核层的事件监听。Poller 负责管理所有的 Channel。
这种设计实现了:
-
用户修改 Channel 事件 -> UpdateEevnt -> epoll_ctl 更新内核
-
内核事件就绪 -> epoll_wait 返回 -> 根据 fd 找到 Channel -> 将内核返回的事件标志更新到 Channel 中,然后收集到 active 列表。
Poll方法的步骤
-
等待事件 :调用
epoll_wait阻塞等待事件发生,返回就绪的文件描述符数量。 -
根据 fd 找到 Channel :通过
_channels映射表,将内核返回的fd转换为用户层的Channel对象。 -
设置就绪事件 :将内核返回的事件标志更新到
Channel中,然后收集到active列表。
代码实现
cpp
// 对 epoll 的封装
#define MAX_EPOLL_SIZE 1024
class Poller{
private:
int _epfd;
struct epoll_event _events[MAX_EPOLL_SIZE]; // 就绪的事件队列
std::unordered_map<int , Channel*> _channels; // epoll 管理所有的用户层 Channel,描述符与Channel的映射
// 内部方法,执行实际的 epoll_ctl 操作
void Update(int op, Channel* channel) {
struct epoll_event ev;
memset(&ev , 0 , sizeof(ev));
ev.events = channel->events();
ev.data.fd = channel->fd();
int res = epoll_ctl(_epfd , op , channel->fd() , &ev);
if(res < 0) {
ERROR_LOG("epoll ctl failed");
abort();
}
return;
}
// 判断是否存在 Channel
bool hasChannel(Channel* channel) {
std::unordered_map<int , Channel*>::iterator iter = _channels.find(channel->fd());
return iter != _channels.end(); // 存在返回 true,不存在返回 false
}
public:
Poller() {
_epfd = epoll_create(MAX_EPOLL_SIZE);
if(_epfd < 0) {
ERROR_LOG("epoll create failed");
abort();
}
INFO_LOG("epoll create success: %d" , _epfd);
}
~Poller() {
if(_epfd > 0) {
::close(_epfd);
_epfd = -1;
}
}
// 添加或修改事件监控
void UpdateEvent(Channel* channel) {
if(hasChannel(channel))
return Update(EPOLL_CTL_MOD , channel);
Update(EPOLL_CTL_ADD , channel);
// 添加管理信息
_channels[channel->fd()] = channel;
}
// 移除事件监控
void RemoveEvent(Channel* channel) {
if(hasChannel(channel)) {
// 从内核中移除
Update(EPOLL_CTL_DEL , channel);
// 删除管理信息
_channels.erase(channel->fd());
}
}
// 开启事件监控,返回就绪的Channel列表
void Poll(std::vector<Channel*>* active) {
int readyfds = epoll_wait(_epfd , _events , MAX_EPOLL_SIZE , -1); // -1表示阻塞
if(readyfds < 0) {
if(errno == EINTR) {
// 被信号中断,继续等待
return;
}
ERROR_LOG("epoll wait failed: %s" , strerror(errno));
abort();
}
for(int i = 0; i < readyfds; i++) {
auto iter = _channels.find(_events[i].data.fd);
assert(iter != _channels.end()); // 一定存在,否则管理信息出现问题
// 更新用户层 Channel 的就绪事件
iter->second->setRevents(_events[i].events);
active->push_back(iter->second); // 添加到就绪队列中
}
}
};3.6 EventLoop的设计与实现
EventLoop 是整个 Reactor 模式的核心调度器,它将之前设计的各个模块(Poller、TimerWheel、eventfd)整合在一起,形成一个完整的事件驱动引擎。
EventLoop 主要负责对于事件(监听事件、定时事件等)的管理,同时,EventLoop 还要解决线程间通信的问题,让其他线程可以安全向 EventLoop 所在线程投递任务。
设计思想 :EventLoop是线程绑定的,一个EventLoop只属于一个线程,所有IO操作都在这个线程中执行,避免了锁竞争。
EventLoop的跨线程任务队列设计:
在多线程网络编程中,如何安全高效地跨线程操作连接。
为什么需要跨线程操作?
一、假设一个典型的多线程 TCP 服务器架构:
text
主 EventLoop 线程:接受新连接,将连接分发给各个工作线程
从 EventLoop 线程1:管理一批连接(conn1、conn2、conn3)
从 EventLoop 线程2:管理另一批连接(conn4、conn5、conn6)现在出现了一个场景:从 EventLoop 线程1在处理 conn1时,发现需要关闭 conn4(比如业务逻辑要求)。此时,问题来了,conn4属于线程2,如果线程1直接调用关闭连接,存在线程安全问题。
二、数据竞争与状态不一致
cpp
// 工作线程2的事件循环
void EventLoop::start() {
while(true) {
// 此时正在处理conn4的读事件
channel->HandlerEvent(); // 假设正在执行这里
}
}
// 工作线程1直接关闭
close(conn4.fd); // 突然把fd关了如果工作线程2正在处理conn4的读事件,文件描述符突然被关闭,会导致:
-
正在进行的 read/write 操作失败。
-
Channel 对象状态不一致,工作线程2完全不知道 Channel 已经无效。
-
可能触发各种难以调试的崩溃。
而对连接加锁会导致频繁的锁操作影响并发性能。
EventLoop的解决方案:任务队列
EventLoop的设计思想是:不要直接操作别的线程的连接,而是把操作打包成任务,投递给对方线程去执行。
核心数据结构
cpp
class EventLoop {
std::vector<Functor> _tasks; // 任务队列
std::mutex _mutex; // 保护队列的锁
int _efd; // 唤醒用的eventfd
};当工作线程1需要关闭其他线程所管理的连接时,则可以打包成任务投递给目标线程。
pushInLoop 的实现
cpp
void pushInLoop(const Functor& task) {
{
// 1. 加锁,将任务加入队列
std::unique_lock<std::mutex> lock(_mutex);
_tasks.push_back(task);
}
// 2. 唤醒目标线程
writeEventfd();
}为什么要加锁? 因为任务队列是多线程共享的,工作线程1在添加任务,工作线程2可能在取出任务,必须用锁保护。
为什么要唤醒? 因为工作线程2可能正在阻塞在 epoll_wait 上,如果没有唤醒,这个任务可能等到下一个网络事件到达时才能被执行,造成延迟,这里主要使用线程间的通知机制 eventfd。
线程间通信机制 eventfd
在多线程程序中,其他线程可能需要让EventLoop线程执行一些任务(比如关闭连接、发送数据)。但是EventLoop线程可能正阻塞在epoll_wait上,如何唤醒它?
eventfd就是解决这个问题的:它是一个文件描述符,可以像管道一样用于事件通知,但比管道更轻量。
eventfd的创建
cpp
static int createEventfd() {
int efd = eventfd(0, EFD_CLOEXEC | EFD_NONBLOCK);
// 0:初始计数器值
// EFD_CLOEXEC:执行exec时自动关闭
// EFD_NONBLOCK:非阻塞模式
return efd;
}eventfd的工作机制
cpp
void writeEventfd() {
uint64_t val = 1;
write(_efd, &val, sizeof(val)); // 写入1,计数器+1
}
void readEventfd() {
uint64_t val = 0;
read(_efd, &val, sizeof(val)); // 读取后计数器归零
}-
eventfd内部维护了一个 8 字节的计数器。
-
写入数据会增加计数器。
-
读取会返回计数器值并清零。
-
当计数器 > 0 时,eventfd 变为可读。
任务执行
cpp
void runAllTasks() {
std::vector<Functor> temp;
{
std::unique_lock<std::mutex> lock(_mutex);
_tasks.swap(temp); // 交换而不是直接遍历,减少锁持有时间
}
for(auto& task : temp) task(); // 释放锁后才执行任务
}这个交换操作非常巧妙 :如果直接在锁的保护下遍历执行任务,长时间持锁会阻塞其他线程添加任务,有效的减少锁的持有时间。
主事件循环(执行流)
cpp
void start() {
while(true) {
// 1. 监听事件
std::vector<Channel*> active;
_poll.Poll(&active);
// 2. 处理就绪事件
for(auto& channel : active) {
channel->HandlerEvent();
}
// 3. 执行任务队列中的任务
runAllTasks();
}
}三部曲设计:
-
第一步:Poll监听。 调用 Poll 监听,调用 Poller 获取该 EventLoop 管理的 Channel 中所有就绪的 Channel。
-
第二步:事件分发。 遍历所有就绪的Channel,调用它们的HandlerEvent。每个Channel会根据就绪的事件类型调用对应的回调函数。
-
第三部:任务执行。 执行其他线程投递过来的任务,这些任务可能包括:
- 关闭连接
- 发送数据
- 修改连接状态等
延迟释放
cpp
void Channel::HandlerEvent() {
if(_revents & EPOLLIN) {
if(eventCallback) eventCallback();
if(readCallback) readCallback(); // 这里把连接对象释放了
// 问题:连接对象已经释放,但函数还在继续执行
}
// 如果还有写事件要处理...
if(_revents & EPOLLOUT) {
// 这里的writeCallback可能访问已经释放的对象
if(writeCallback) writeCallback(); // 崩溃!
}
}
// 连接真实的释放操作是 push 到该线程的任务队列中
void Connection::Release() {
_loop->pushInLoop(std::bind(&Connection::ReleaseInLoop, this));
}关键设计:事件处理和任务执行是分离的两个阶段。
完整的执行流:
-
事件发生,epoll_wait返回。
-
遍历处理所有该 EventLoop 所有的就绪事件。
- 整个连接即使在读写错误时,也不会立马被释放,而是在整个事件处理阶段都还活着,所有回调都能正常访问它。等到所有事件都处理完了,才在任务阶段释放。
-
才会执行任务队列中的连接释放操作。
代码实现
cpp
// Reactor 模块 对于事件的管理 epoll、timerfd、eventfd 的就绪事件
using Functor = std::function<void()>;
class EventLoop {
private:
std::thread::id _thread_id; // 一个 eventloop 对应一个线程
int _efd; // 线程间的事件通知机制
Channel _efd_channel;
Poller _poll;
TimerWheel _timer_wheel; // 构造 timerwheel 的时候会使用到 _poll 注意初始化顺序
std::vector<Functor> _tasks; // 任务队列,对于链接的操作都必须在一个 EventLoop 中操作
std::mutex _mutex;
static int createEventfd() {
int efd = eventfd(0 , EFD_CLOEXEC | EFD_NONBLOCK);
if(efd < 0) {
ERROR_LOG("create eventfd failed");
abort();
}
INFO_LOG("eventloop create eventfd success: %d" , efd);
return efd;
}
// 读取 eventfd 的事件通知
void readEventfd() {
uint64_t val = 0;
ssize_t res = read(_efd , &val , sizeof(val));
if(res < 0) {
// EAGAIN表示当前没有数据可读,EINTR表示被信号打断
if(errno == EAGAIN || errno == EINTR) { // 这些错误可以被原谅
return;
}
ERROR_LOG("read eventfd failed");
abort();
}
}
// 写入 eventfd 触发事件通知
void writeEventfd() {
uint64_t val = 1;
ssize_t n = write(_efd , &val , sizeof(val));
if(n < 0) {
if(errno == EAGAIN || errno == EINTR) {
return;
}
ERROR_LOG("write eventfd failed");
abort();
}
}
// 执行任务队列中所有的任务
void runAllTasks() {
// 如果直接加锁执行队列中的所有任务,可能会有些任务执行处理事件过长,导致其他线程添加任务到队列中会造成竞争锁资源的阻塞
// 因此,执行一个 vector 的交换操作,直接释放锁
std::vector<Functor> temp;
{
std::unique_lock<std::mutex> lock(_mutex);
_tasks.swap(temp);
}
for(auto& task : temp) task();
}
public:
EventLoop()
:_thread_id(std::this_thread::get_id())
,_efd(createEventfd())
,_efd_channel(this , _efd)
,_timer_wheel(this)
{
// 为 eventfd 设置读事件就绪的回调函数以及启动读事件回调
_efd_channel.setReadCallback(std::bind(&EventLoop::readEventfd , this));
_efd_channel.EnableRead();
}
// 启动事件循环,处理IO事件和执行任务
void start() {
while(true) {
// 1.监听事件
std::vector<Channel*> active;
_poll.Poll(&active);
// 2.处理就绪事件
for(auto& channel : active) {
// INFO_LOG("%d 事件就绪, 处理该事件" , channel->fd());
channel->HandlerEvent();
}
// 3.执行任务队列中的任务
runAllTasks();
}
}
// 判断当前线程是否是 EventLoop 所属线程
bool isInLoop() { return std::this_thread::get_id() == _thread_id; }
// 断言当前线程是EventLoop所属线程
void assertIsInLoop() { assert(std::this_thread::get_id() == _thread_id); }
// 在当前线程执行任务,如果不是所属线程则添加到任务队列
void runInLoop(const Functor& task) {
if(isInLoop()) return task();
pushInLoop(task);
}
// 添加任务到该线程的任务队列中
void pushInLoop(const Functor& task) {
{
std::unique_lock<std::mutex> lock(_mutex);
_tasks.push_back(task);
}
// 当有任务添加到任务队列中,但是没有事件就绪,导致该 EventLoop 线程阻塞在 epoll_wait 中
// 因此,每当有新任务需要该 EventLoop 线程处理时,就需要写入 eventfd 触发事件通知
writeEventfd();
}
// 更新 Poller 中的事件监听(内核层面的修改)
void updateEvent(Channel* channel) { return _poll.UpdateEvent(channel); }
// 从内核层面移除事件监听
void removeEvent(Channel* channel) { return _poll.RemoveEvent(channel); }
// 添加定时任务
void addTimeTask(uint64_t id, uint32_t delay, const TimerTaskFun& task) { return _timer_wheel.addTimerTask(id , delay , task); }
// 刷新定时任务(延迟其超时时间)
void refreshTimeTask(uint64_t id) { return _timer_wheel.refreshTimerTask(id); }
// 删除定时任务
void delTimeTask(uint64_t id) { return _timer_wheel.delTimerTask(id); }
// 是否存在定时任务
bool hasTimeTask(uint64_t id) { return _timer_wheel.hasTimerTask(id); }
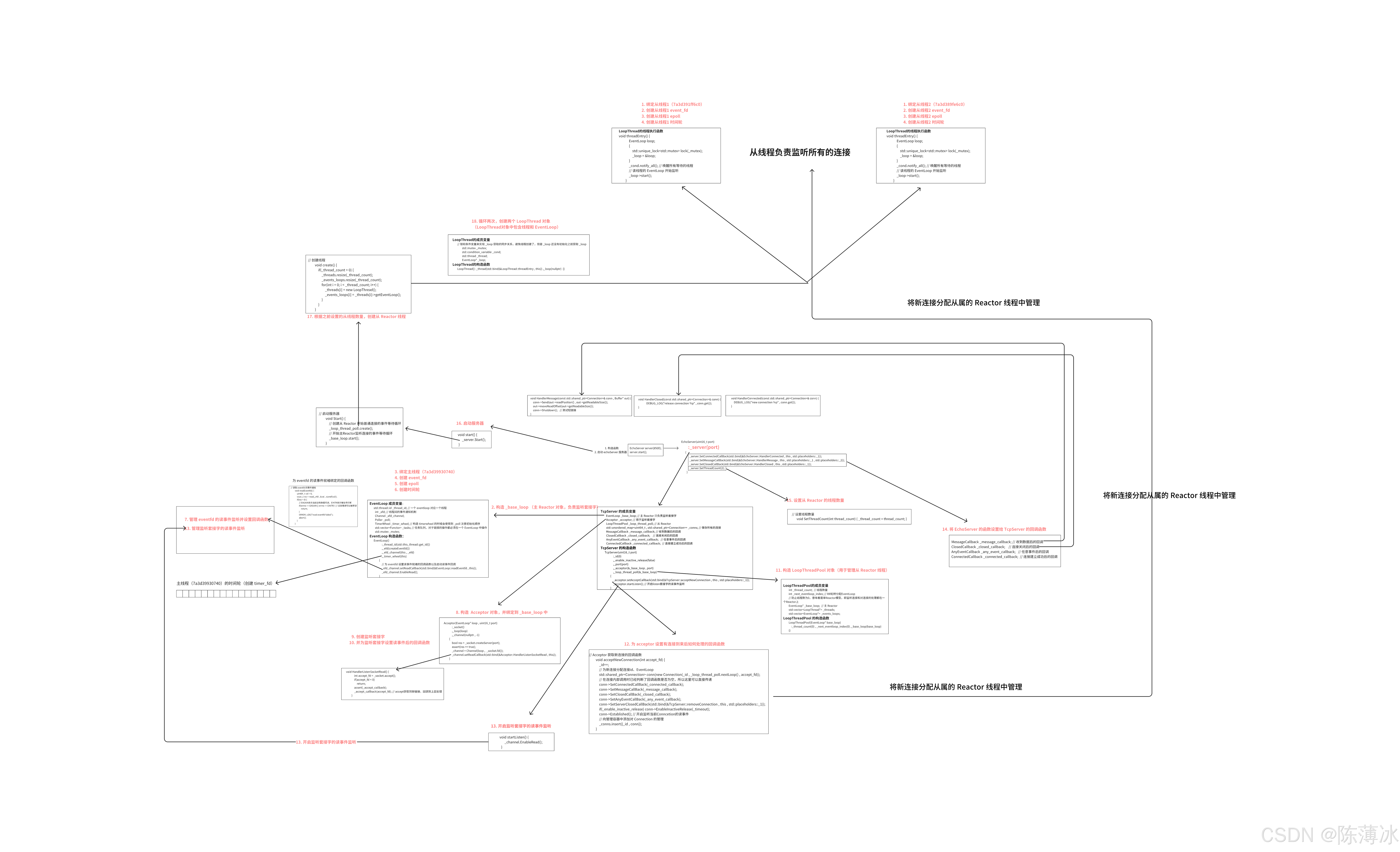
};3.7 LoopThread 和 LoopThreadPoll 的设计与实现
LoopThread 是连接 线程 和 EventLoop 的桥梁,它实现了一个非常重要的模式:one loop per thread。
LoopThread 类主要是解决创建线程和 EventLoop 时的时序问题。
设计思想: 将线程和 EventLoop 绑定在一起,通过同步机制确保 _loop 在完全初始化后才能在外部使用。
getEventLoop 为什么要将 _loop 加锁之后赋值给一个局部变量?
这个设计体现了 锁的最小化持有原则。通过局部变量中转,我们既能保证在锁的保护下安全地读取成员变量,又能让锁在离开作用域时立即释放。这避免了不必要的锁竞争。
代码实现
cpp
// 这是一个将线程和EventLoop关联的类
class LoopThread {
private:
// 锁和条件变量来实现 _loop 获取的同步关系,避免线程创建了,但是 _loop 还没有初始化之前获取 _loop
std::mutex _mutex;
std::condition_variable _cond;
std::thread _thread;
EventLoop* _loop;
void threadEntry() {
EventLoop loop;
{
std::unique_lock<std::mutex> lock(_mutex);
_loop = &loop;
}
_cond.notify_all(); // 唤醒所有等待的线程
// 该线程的 EventLoop 开始监听
_loop->start();
}
public:
LoopThread() :_thread(std::bind(&LoopThread::threadEntry , this)) ,_loop(nullptr) {}
EventLoop* getEventLoop() {
EventLoop* loop = nullptr;
{
std::unique_lock<std::mutex> lock(_mutex);
_cond.wait(lock, [&](){ return _loop != nullptr; }); // wait需要传入 unique_lock
loop = _loop;
}
return loop;
}
};为什么需要 LoopThreadPool?
在单线程Reactor模型中,一个EventLoop既要接受新连接,又要处理所有连接的IO事件。当连接数增多时,这个EventLoop会成为瓶颈。而多线程 Reactor模型的解决方案:
text
主Reactor (base_loop) : 只负责接受新连接
子Reactor1 : 负责一批连接的IO事件
子Reactor2 : 负责一批连接的IO事件
子Reactor3 : 负责一批连接的IO事件
...LoopThreadPool的作用就是管理这些子Reactor线程,并为新连接分配一个合适的EventLoop。
核心数据结构
cpp
int _thread_count; // 线程数量(子Reactor个数)
int _next_eventloop_index; // 轮转分配索引
EventLoop* _base_loop; // 主Reactor(通常由main函数所在线程创建)
std::vector<LoopThread*> _threads; // 线程对象集合
std::vector<EventLoop*> _events_loops; // EventLoop指针集合设计思想: 维护两个并行数组
-
_threads:管理线程生命周期。 -
_events_loops:快速访问 EventLoop (避免通过 LoopThread 间接获取)。
其实单个 _threads 数组也可以实现,getEventLoop() 内部有锁和条件变量等待,虽然初始化后很快,但毕竟有开销。在 nextLoop() 高频调用时,预存_events_loops 可以避免这个开销。
LoopThreadPool 支持两种 Reactor 模式的实现:
-
当线程数量为 0 时 ,所有的 连接操作 和 IO处理 都在 主 Reactor 处理。
-
当线程数量 > 0 时,主 Reactor 只负责 acceptr 新连接,子 Reactor 负责已连接套接字的 IO 事件处理(每个子 Reactor 运行在独立线程中)。
代码实现
cpp
// 这是一个管理 LoopThread 的类
class LoopThreadPool {
private:
int _thread_count; // 线程数量
int _next_eventloop_index; // RR轮转分配EventLoop
// 防止线程数为0,意味着是单Reactor模型,即监听连接和对连接的处理都在一个Reactor上
EventLoop* _base_loop; // 主 Reactor
std::vector<LoopThread*> _threads;
std::vector<EventLoop*> _events_loops;
public:
LoopThreadPool(EventLoop* base_loop)
:_thread_count(0) , _next_eventloop_index(0) ,_base_loop(base_loop)
{}
// 设置线程数量
void SetThreadCount(int thread_count) { _thread_count = thread_count; }
// 创建线程
void create() {
if(_thread_count > 0) {
_threads.resize(_thread_count);
_events_loops.resize(_thread_count);
for(int i = 0; i < _thread_count; i++) {
_threads[i] = new LoopThread();
_events_loops[i] = _threads[i]->getEventLoop();
}
}
}
// RR轮转 返回下一个 EventLoop
EventLoop* nextLoop() {
if(_thread_count == 0)
return _base_loop;
_next_eventloop_index = (_next_eventloop_index + 1) % _thread_count;
return _events_loops[_next_eventloop_index];
}
};3.8 Connection的设计与实现
为什么需要 Connection?
在TCP服务器中,每个客户端连接都需要管理:
-
套接字:用于收发数据的文件描述符。
-
缓冲区:存储待发送和接收的数据。
-
状态:连接当前处于什么阶段。
-
回调:数据到达时通知上层业务。
-
定时器:非活跃连接的超时释放。
Connection类把这些都封装在一起,形成一个完整的连接对象。
为什么需要DISCONNECTING状态?
- 收到关闭请求时,可能还有数据未发完,先进入半关闭状态,等数据发完再真正关闭。
为什么连接需要 std::shared_ptr 管理?
在传统的同步编程中,对象的生命周期很清晰。但是在异步网络编程中,谁拥有连接对象 变得模糊。在 TcpServer 模块中保存每个 Connection 的最后一个引用计数。
代码实现
cpp
// 这是一个对链接管理的类
class Connection;
typedef enum {
DISCONNECTED = 0, // 已断开
DISCONNECTING = 1, // 半关闭
CONNECTING = 2, // 连接中
CONNECTED = 3 // 已建立
} ConnStatus;
class Connection : public std::enable_shared_from_this<Connection> {
private:
uint64_t _conn_id; // 连接的id
ConnStatus _status; // 连接的状态
bool _enable_inactive_release; // 是否开启当前连接的非活跃销毁释放
int _sockfd; // 文件描述符
EventLoop* _loop; // 每个连接绑定一个 EventLoop
Channel _channel; // 对于 _sockfd 的用户层事件管理 channel 依赖 _sockfd 和 _loop 注意构造顺序
Socket _socket; // 对套接字的操作
Buffer _in_buffer; // 用户层输入缓冲区
Buffer _out_buffer; // 用户层输出缓冲区
Any _context; // 协议处理的上下文
// 这四个回调函数是由组件使用者设置的
using MessageCallback = std::function<void(const std::shared_ptr<Connection>& , Buffer*)>;
using ClosedCallback = std::function<void(const std::shared_ptr<Connection>&)>;
using AnyEventCallback = std::function<void(const std::shared_ptr<Connection>&)>;
using ConnectedCallback = std::function<void(const std::shared_ptr<Connection>&)>;
MessageCallback _message_callback; // 收到数据后的回调
ClosedCallback _closed_callback; // 连接关闭后的回调
AnyEventCallback _any_event_callback; // 任意事件后的回调
ConnectedCallback _connected_callback; // 连接建立成功后的回调
ClosedCallback _manager_release; // TcpServer 类将其 Connection 从管理容器中移除的回调
private:
// 处理读事件就绪的回调函数
void HandlerRead() {
char buffer[65536] = {0};
ssize_t res = _socket.nonBlockRecv(buffer , 65535);
if(res < 0) {
// 读取错误,并不会直接释放连接,shutdownInLoop中调用 Release,Release 中会将真正的释放接口 ReleaseInLoop 添加
// 到 _loop 的任务队列中,所以执行流就是会处理完当前所有的 channel->HandleEvent() 才会执行任务队列中的释放任务
// 达到了延迟释放的效果
return ShutdownInLoop();
}
// 读取成功,写入到输入缓冲区
_in_buffer.writeAndPush(buffer , res);
// 若输入缓冲区有数据则调用用户的回调函数处理业务
if(_in_buffer.getReadableSize() > 0)
_message_callback(shared_from_this() , &_in_buffer);
}
// 处理写事件就绪的回调函数
void HandlerWrite() {
ssize_t res = _socket.nonBlockSend(_out_buffer.readPosition() , _out_buffer.getReadableSize());
if(res < 0) {
// 写入错误,检查是否输入缓冲区是否还有数据待处理,调用用户回调函数处理
if(_in_buffer.getReadableSize() > 0)
_message_callback(shared_from_this() , &_in_buffer);
// 释放连接
return Release();
}
// 写入成功后,移动实际的写入位置
_out_buffer.moveReadOffset(res);
// 若写入完毕,则关闭写事件监控
if(_out_buffer.getReadableSize() == 0) {
// 关闭写事件监听
_channel.DisableWrite();
// 若当前连接为半关闭状态,则发送完本次数据,应该释放连接
if(_status == DISCONNECTING)
return Release();
}
}
// 处理挂断事件的回调函数
void HandlerClose() {
_status = DISCONNECTING;
// 一旦连接挂断,套接字则不能写入数据,因此检查一下输入缓冲区是否有待处理数据
if(_in_buffer.getReadableSize() > 0)
_message_callback(shared_from_this() , &_in_buffer);
return Release();
}
// 处理错误事件的回调函数
void HandlerError() {
return HandlerClose();
}
// 处理任意事件的回调函数
void HandlerEvent() {
// 连接为半关闭或关闭状态直接返回
if(_status == DISCONNECTING || _status == DISCONNECTED)
return;
// 刷新定时任务的活跃度
if(_enable_inactive_release) {
_loop->refreshTimeTask(_conn_id);
}
// 调用组件使用者的任意事件回调
if(_any_event_callback)
_any_event_callback(shared_from_this());
}
// 释放连接
void ReleaseInLoop() {
// 1.修改连接状态为关闭状态
_status = DISCONNECTED;
// 2.删除epoll内核中的管理
_channel.Remove();
// 3.关闭文件描述符
_socket.close();
// 4.如果当前定时器队列中还有定时销毁任务,则取消任务
if(_loop->hasTimeTask(_conn_id)) CancelInactiveReleaseInLoop();
// 5.调用使用者的关闭连接回调函数
if(_closed_callback) _closed_callback(shared_from_this());
// 6.调用 TcpServer 类将其 Connection 从管理容器中移除的回调
if(_manager_release) _manager_release(shared_from_this());
}
// 为连接做初始化工作
void EstablishedInLoop() {
assert(_status == CONNECTING);
// 1.修改连接状态为建立完毕状态
_status = CONNECTED;
// 2.开启读事件监控
_channel.EnableRead();
// 3.调用使用者的连接建立完成的回调
if(_connected_callback) _connected_callback(shared_from_this());
}
// 向连接的发送接口
void SendInLoop(Buffer buf) {
if(_status == DISCONNECTED) return;
// 1.写入到输入缓冲区
_out_buffer.writeAndPush(buf.readPosition() , buf.getReadableSize());
// 2.开启写事件监控
if(_channel.IsMoinitorWrite() == false)
_channel.EnableWrite();
}
// 关闭连接,在彻底释放连接前,检查是否还有数据待处理
void ShutdownInLoop() {
// 1.修改连接状态为半关闭状态
_status = DISCONNECTING;
// 2.检查输入缓冲区
if(_in_buffer.getReadableSize() > 0)
_message_callback(shared_from_this() , &_in_buffer);
// 3.检查输入缓冲区
if(_out_buffer.getReadableSize() > 0)
if(_channel.IsMoinitorWrite() == false)
_channel.EnableWrite();
if(_out_buffer.getReadableSize() == 0)
Release();
}
// 启动定时销毁连接任务
void EnableInactiveReleaseInLoop(int sec) {
_enable_inactive_release = true;
// 启动若已存在,则刷新,不存在,则创建
_loop->addTimeTask(_conn_id , sec , std::bind(&Connection::ReleaseInLoop , this));
}
// 取消定时销毁连接任务
void CancelInactiveReleaseInLoop() {
// DEBUG_LOG("CancelInactiveReleaseInLoop");
_enable_inactive_release = false;
if(_loop->hasTimeTask(_conn_id)) {
return _loop->delTimeTask(_conn_id);
}
}
// 更换协议上下文和处理回调函数
void UpgradeInLoop(
const Any& context,
const ConnectedCallback& connected_cb,
const MessageCallback& message_cb,
const ClosedCallback& closed_cb,
const AnyEventCallback& any_event_cb
) {
_context = context;
_message_callback = message_cb;
_closed_callback = closed_cb;
_any_event_callback = any_event_cb;
_connected_callback = connected_cb;
}
public:
Connection(uint64_t id , EventLoop* loop , int fd)
:_conn_id(id)
,_status(CONNECTING)
,_enable_inactive_release(false)
,_sockfd(fd)
,_loop(loop)
,_channel(loop , fd)
,_socket(fd)
{
// 为 channel 设置事件就绪回调
_channel.setReadCallback(std::bind(&Connection::HandlerRead , this));
_channel.setWriteCallback(std::bind(&Connection::HandlerWrite , this));
_channel.setCLoseCallback(std::bind(&Connection::HandlerClose , this));
_channel.setErrorCallback(std::bind(&Connection::HandlerError , this));
_channel.setEventCallback(std::bind(&Connection::HandlerEvent , this));
}
~Connection() { DEBUG_LOG("Release Conncection: %p" , this); }
int Fd() { return _sockfd; }
uint64_t Id() { return _conn_id; }
bool Connected() { return _status == CONNECTED; }
void SetContext(const Any& context) { _context = context; }
Any* GetContext() { return &_context; }
void SetConnectedCallBack(const ConnectedCallback& cb) { _connected_callback = cb; }
void SetMessageCallBack(const MessageCallback& cb) { _message_callback = cb; }
void SetClosedCallBack(const ClosedCallback& cb) { _closed_callback = cb; }
void SetAnyEventCallBack(const AnyEventCallback& cb) { _any_event_callback = cb; }
void SetServerClosedCallBack(const ClosedCallback& cb) { _manager_release = cb; }
void Established() { _loop->runInLoop(std::bind(&Connection::EstablishedInLoop , this)); }
void Send(const char* data , size_t len) {
//外界传入的data,可能是个临时的空间,我们现在只是把发送操作压入了任务池,有可能并没有被立即执行
//因此有可能执行的时候,data指向的空间有可能已经被释放了。
Buffer buf;
buf.writeAndPush(data , len);
_loop->runInLoop(std::bind(&Connection::SendInLoop , this , buf));
}
/****************/
void Release() {
_loop->pushInLoop(std::bind(&Connection::ReleaseInLoop, this));
}
/****************/
void Shutdown() { _loop->runInLoop(std::bind(&Connection::ShutdownInLoop , this)); }
void EnableInactiveRelease(int sec) { _loop->runInLoop(std::bind(&Connection::EnableInactiveReleaseInLoop , this , sec)); }
void CancelInactiveRelease() { _loop->runInLoop(std::bind(&Connection::CancelInactiveReleaseInLoop , this)); }
void Upgrade(
const Any& context,
const ConnectedCallback& connected_cb,
const MessageCallback& message_cb,
const ClosedCallback& closed_cb,
const AnyEventCallback& any_event_cb
) {
// 这个上下文切换的函数应该是立即执行切换的,必须在本线程中调用
_loop->assertIsInLoop();
_loop->runInLoop(std::bind(&Connection::UpgradeInLoop , this , context , connected_cb , message_cb , closed_cb , any_event_cb));
}
};协议上下文 Any 类的实现
cpp
// any类的设计
class Any{
private:
class placeholder{
public:
virtual ~placeholder() {}
virtual const std::type_info& type() = 0;
virtual placeholder* clone() = 0;
};
template<typename T>
class holder : public placeholder{
private:
T _val;
public:
holder(const T& val) :_val(val) {}
// 获取当前 T 的类型
virtual const std::type_info& type() override { return typeid(_val); }
// 克隆一个子类对象由父类指针指向
virtual placeholder* clone() override {
return new holder<T>(_val);
}
T* getVal() { return &_val; }
};
placeholder* _context;
public:
void swap(Any& other) { std::swap(_context , other._context); }
Any() :_context(nullptr) {}
template<typename T>
Any(const T& val) :_context(new holder<T>(val)) {}
Any(const Any& other) :_context(other._context ? other._context->clone() : nullptr) {}
Any& operator=(Any other) {
swap(other);
return *this;
}
template<typename T>
Any& operator=(const T& val) {
Any(val).swap(*this);
return *this;
}
~Any() { delete _context; }
template<typename T>
T* get() {
// 获取的类型必须和保存的类型数据一致
assert(_context);
assert(typeid(T) == _context->type());
return dynamic_cast<holder<T>*>(_context)->getVal(); // dynamic_cast 在模板场景下要求完全匹配,不只是父类指向子类就行
}
};3.9 Acceptor的设计与实现
Acceptor是专门负责接受新连接的类。Acceptor通常运行在主 Reactor 线程中。接收到新连接后通过回调函数通知上层处理新连接。
代码实现
cpp
// 这是一个管理监听套接字的类
using AcceptCallback = std::function<void(int)>;
class Acceptor{
private:
Socket _socket;
EventLoop* _loop;
Channel _channel;
AcceptCallback _accept_callback;
void HandlerListenSocketRead() {
int accept_fd = _socket.accept();
if(accept_fd < 0)
return;
assert(_accept_callback);
_accept_callback(accept_fd); // accept获取到新链接,回调到上层处理
}
public:
Acceptor(EventLoop* loop , uint16_t port)
:_socket()
,_loop(loop)
,_channel(nullptr , -1)
{
bool res = _socket.createServer(port);
assert(res == true);
_channel = Channel(loop , _socket.fd());
_channel.setReadCallback(std::bind(&Acceptor::HandlerListenSocketRead , this));
}
void startListen() {
_channel.EnableRead();
}
void setAcceptCallback(const AcceptCallback& accept_callback) {
_accept_callback = accept_callback;
}
};3.10 主从 Reactor 服务器流程图