前言
之前对 AI 落地应用特别感兴趣,不想只停留在"聊天"层面,想试试能不能把 AI 变成我的"第二大脑",帮我管理文档、回答问题。于是动手在本地搭建一个完全离线的 AI 知识库。
这个过程踩了不少坑,也收获了很多经验。今天就把我的真实操作流程、遇到的问题和解决方案整理成这篇博客,希望能给同样想入坑的朋友一点参考。
我的设备环境 :Mac OS 15 (M1 芯片),16G 内存 + 256G 硬盘。
核心工具链:Ollama (模型推理) + Gemma 3:4B (对话模型) + Nomic Embed Text (嵌入模型) + Cherry Studio (可视化界面)。
一、实践前先知:为什么要选这套方案?
在开始之前,我做了不少功课。市面上有很多方案(AnythingLLM, Dify, Ragflow 等),但我最终选择了 Ollama + Cherry Studio 的组合,原因很简单:
- 轻量便捷:Ollama 安装简单,命令一行搞定,对新手友好。
- 开源免费:完全本地运行,数据隐私掌握在自己手里,不用担心上传云端。
- 生态丰富:教程多,社区活跃,遇到问题容易找到答案。
- 适合个人:对于我这种单兵作战、主要处理个人文档的场景,这套组合拳性价比最高。
当然,如果你有团队协作或更复杂的工作流需求,Dify 或 Ragflow 可能更适合。但如果你只是想快速拥有一个私人的离线 AI 助手,这样也足够了。
二、我的关键步骤:从下载到跑通
第一步:安装 Ollama
这是整个大厦的地基。
- 操作 :直接去 Ollama 官网 下载对应系统的安装包。我是 Mac,下载后一路下一步即可。
- 验证 :安装完成后,打开终端(Terminal),输入
ollama -v,如果有版本号输出,说明安装成功。
第二步:选择并下载模型(踩坑实录)
这是最关键的一步。模型选大了跑不动,选小了不够聪明。
-
我的配置:M1 芯片,16G 内存。这意味着我不能跑太大的模型(比如 70B),但也没必要跑太小的(比如 1B)。
-
模型选择 :我选择了 Gemma 3 :4B 。
- 理由:Google 出品,基于 Gemini 技术,轻量级但能力不俗。支持 128K 上下文,能处理长文档,而且 4B 的参数量在我的电脑上运行毫无压力。
-
下载命令 :
ollama run gemma3:4b -
⚠️ 踩坑记录 :
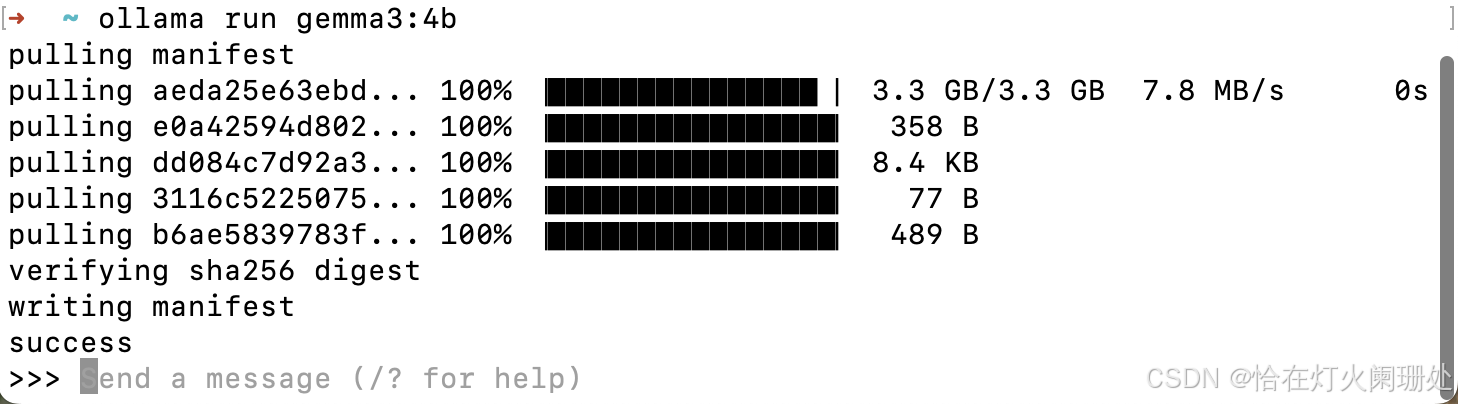
下载过程并不顺利!我第一次执行命令,进度条走了一半报错了;第二次又失败了。
解决方案 :别慌,这通常是网络波动导致的。直接重新执行命令即可!我是失败了两次,第三次终于成功下载并运行了。看到终端里模型开始跟你打招呼,那一刻成就感满满。

第三步:补全"眼睛"------下载嵌入模型(Embedding Model)
这一步是我在后续配置中才发现的重要环节,也是很多新手容易忽略的。
-
什么是嵌入模型?
如果把对话模型(Gemma 3)比作"大脑",负责思考和回答;那么嵌入模型就是"眼睛",负责阅读和理解你的文档,把它们转化成向量存起来。没有它,知识库就是个摆设。 -
如何检查是否已下载?
在终端输入:ollama list查看列表。如果你只看到
gemma3:4b,说明你还没下载嵌入模型。

-
下载推荐模型 :
我选择了nomic-embed-text,因为它体积小(约 274MB)、速度快、中英文支持都不错。ollama pull nomic-embed-text这次下载很顺利,几十秒就搞定了。再次运行
ollama list,确认列表里有了它。
第四步:连接可视化界面------Cherry Studio
虽然可以用命令行聊天,但为了管理知识库和获得更好的体验,我需要一个图形界面。
- 下载 :去 Cherry Studio 官网 下载安装包。
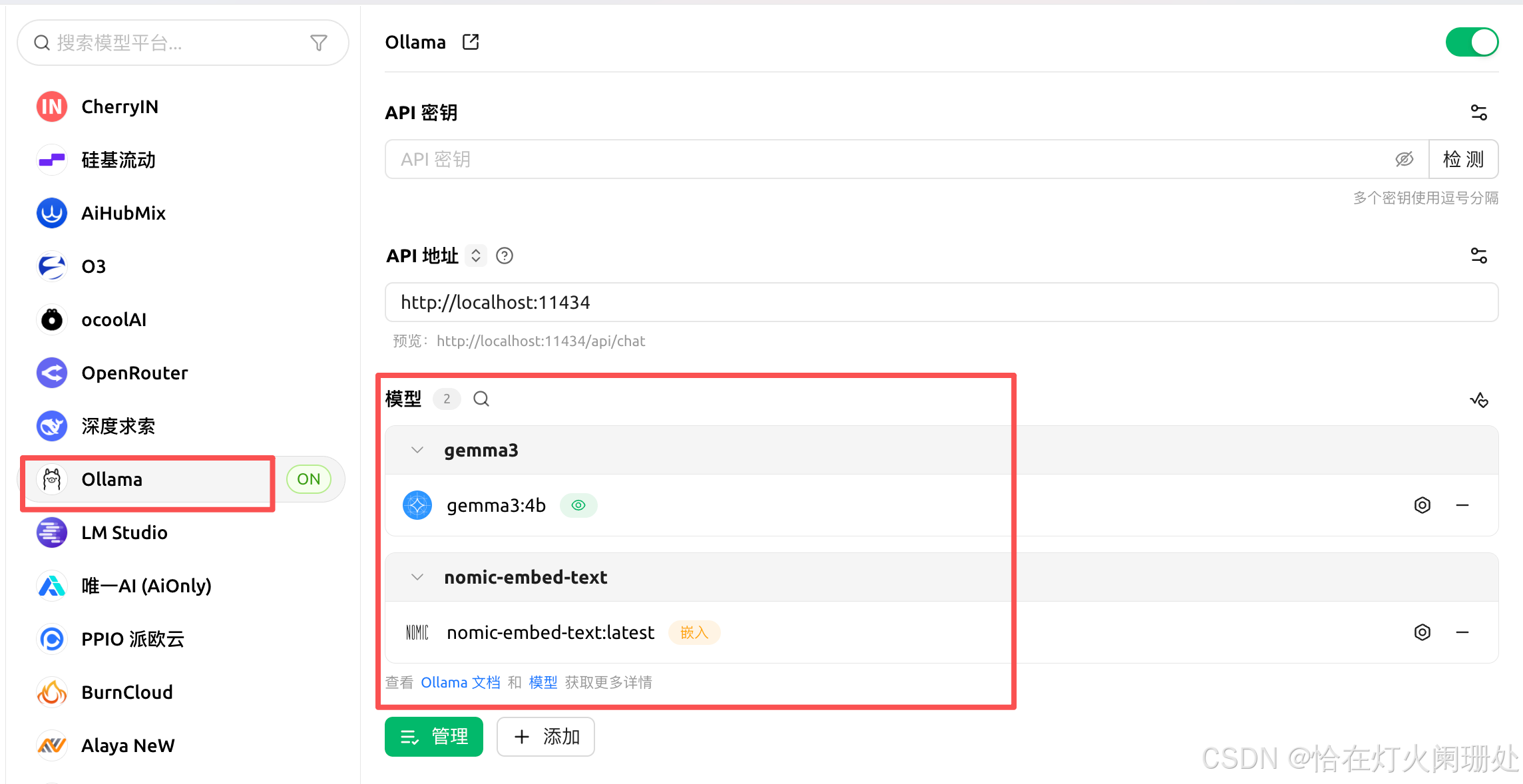
- 配置连接 :
- 打开 Cherry Studio,进入设置(齿轮图标)。
- 找到 模型提供商 -> Ollama。
- 确保接口地址是
http://127.0.0.1:11434(默认通常就是这个)。 - 点击"刷新模型列表",你应该能看到
gemma3:4b和nomic-embed-text。 - 关键点 :在创建知识库时,务必将 嵌入模型 指定为
nomic-embed-text,千万不要选成 Gemma 3!
第五步:创建知识库并测试
一切就绪,开始见证奇迹。
- 新建知识库 :在 Cherry Studio 左侧点击"知识库",新建一个,比如叫"我的离线文档demo"。
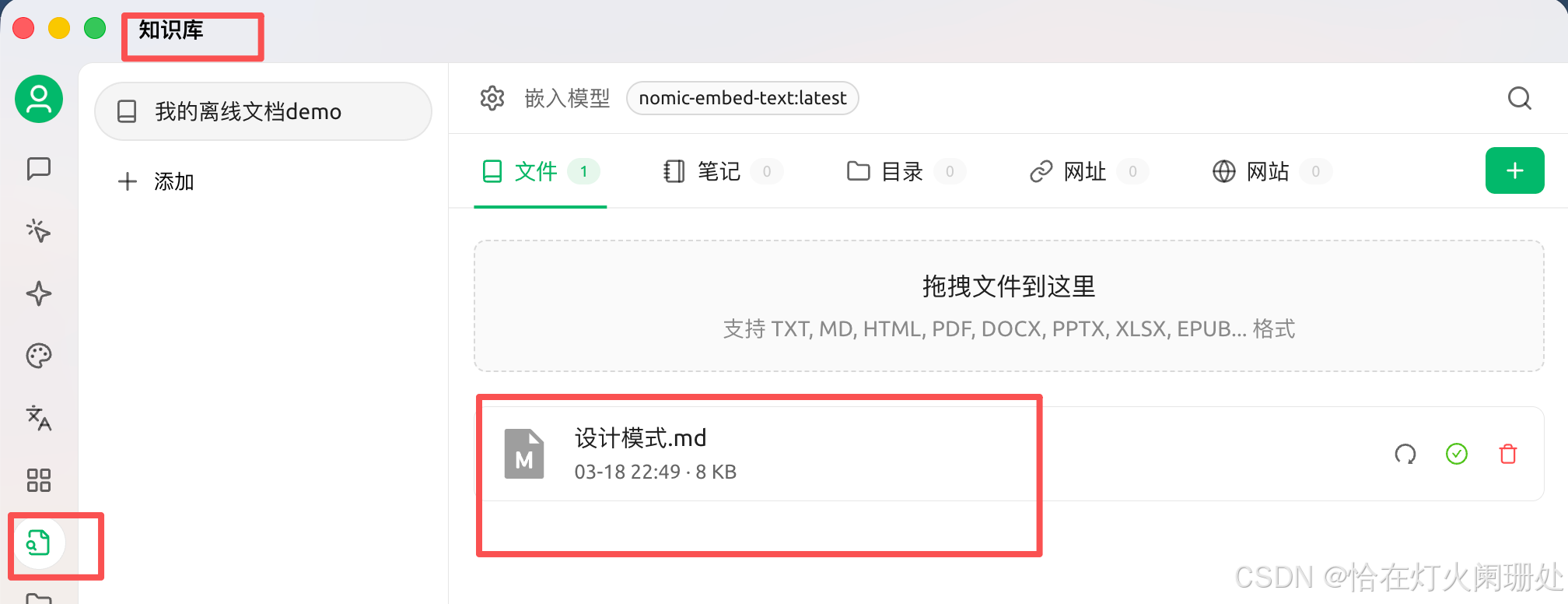
- 上传文档:拖入1个或几个 markdown 或 PDF 或 TXT 文件(我试了网上找的一个技术文档)。
- 索引处理 :系统会自动调用
nomic-embed-text对文档进行切片和向量化。这个过程在 M1 上非常快。 - 关联对话:新建一个对话窗口,在设置里开启"引用知识库",选择刚才创建的库。
- 提问测试 :
- 问:"根据我上传的文档,总结一下核心观点。"
- 问:"文档里提到的那个参数是多少?"
- 如果它能准确回答,并且标注了来源,恭喜你,离线知识库搭建成功!

三、资源占用与性能表现
很多人关心本地部署会不会把电脑卡死。根据我的实际监测:
- 内存占用 :
- Ollama 进程 :运行时大约占用 5.11 GB 内存(包含模型加载和上下文缓存)。
- Cherry Studio :大约占用 583.6 MB。
- 总计:约 5.7 GB。
- 结论:对于 16G 内存的电脑来说,这完全在安全范围内。即使同时开着浏览器和微信,电脑依然流畅。如果是 8G 内存的电脑,可能就需要关闭一些其他软件了。
四、总结与建议
回顾整个过程,其实并没有想象中那么难。核心就在于:选对工具,按部就班,遇到报错别放弃。
给新手的几点建议:
- 网络问题:下载模型失败是常态,多试几次,或者找个网络好的时间段。
- 嵌入模型必装 :一定要记得
ollama pull nomic-embed-text,这是知识库的灵魂。 - 量力而行:根据你的内存选择模型。16G 内存跑 4B-8B 模型最舒服,8G 内存建议跑 3B-4B。
- 数据安全:所有数据都在本地,断网也能用,这才是真正的私有化部署。
现在,我已经拥有了一个完全属于我自己的 AI 知识库。它可以随时帮我查阅资料、总结文档,而且不用担心数据泄露。
如果你也心动了,不妨现在就打开终端,输入第一行命令吧。我们在 AI 落地的路上见!
本文基于个人真实实操记录整理,如有疏漏,欢迎交流指正。