DestinyLinker/MingLi-Bench:评估中国传统占卜大语言模型的基准------八字(八字)和紫微斗数(紫微斗数)。
MingLi-Bench 项目部署实录:基于 EPGF 架构的工程化实践
一、项目简介
MingLi-Bench 是一个专门用于评测大语言模型(LLM)在中国传统命理学领域能力的基准测试框架。项目数据源自 2022--2025 年"全球算命师大赛",共收录 160 道标准化选择题,覆盖婚姻、事业、家庭、健康、财运、学业、性格等 12 个人生维度。通过向模型输入命例信息并比对标准答案,可量化评估各模型在八字(Bazi)与紫微斗数(Ziwei Doushu)推理上的真实水平。
- 项目地址:https://github.com/DestinyLinker/MingLi-Bench
- 数据规模:160 题,4 个年度(2022--2025)
- 评测方式:精确匹配(Exact Match)
- 特色功能 :支持
--cot链式推理与--astro预计算命盘注入
二、部署环境
在开始之前,先介绍一下本文使用的环境管理思路------EPGF(Engineering Python Governance Framework)。
【EPGF 白皮书】路径治理驱动的多版本 Python 架构------ Windows 环境治理与 AI 教学开发体系
一次搭好、终身不乱Windows Python 环境治理(EPGF)系列总览 / 阅读路线图 目录
Python 多版本环境治理理念驱动的系统架构设计------三维治理、四级隔离、五项自治 原则(路径治理升级修订 V 2.0 版)
传统做法的问题
大多数人管理多个 Python 版本的方式是:去官网下载 Python 3.10、3.11、3.12......分别安装到系统里,然后不停地修改环境变量或借助工具来回切换;还为了适应新兴的管理工具,不断安装 uv、poetry、hatch、pipenv、pipx、nox、tox 等现代工具。时间一长,系统里堆满了各种 Python 和各种全局工具的安装目录,环境变量一团乱麻,出问题根本不知道从哪查起。
EPGF 的解法
EPGF 的第一个核心原则是:系统里只装一个 Anaconda,不单独安装任何 Python 版本。 所有 Python 版本都以 Conda 虚拟环境的形式存在:
conda create -n py310 python=3.10
conda create -n py311 python=3.11
conda create -n py312 python=3.12
conda create -n py313 python=3.13配置好环境变量后,在系统任意位置、任意终端里,一条命令即可切换 Python 版本:
conda activate py312 # 切换到 Python 3.12
conda activate py310 # 切换到 Python 3.10工具与 Python 版本绑定
EPGF 的第二个核心原则是:不在系统全局安装 uv、poetry 等工具 ,而是在每个 py3xx 环境里分别统一安装一遍:
conda activate py312
pip install uv poetry hatch pipenv virtualenv pipx nox tox poetry-plugin-shell工具的可执行文件统一落在对应环境的 Scripts/ 目录下(如 D:\A\envs\py312\Scripts\),跟着 Python 版本走,互不干扰。
项目级解耦:.venv 跟随项目
日常开发不在 Conda 环境里直接写代码,而是在项目目录下创建专属的 .venv:
conda activate py312 # 借用 py312 作为父级解释器
python -m venv --copies .venv # 物理复制,而非符号链接
conda deactivate # 借完即断,.venv 从此独立.venv 一旦创建完成,就与 Conda 父级彻底解耦------即使卸载 Anaconda,项目照常运行。
终极一招:工具也装进 .venv
如果项目用到了 uv、poetry 等现代工具,EPGF 会在项目的 .venv 里再装一遍:
.venv\Scripts\pip install uv poetry这样项目调用的是自己 .venv 里的工具,而不是父级 Conda 环境里的,彻底解决了这类工具"默认全局操作、依赖父级、行为难以预测"的老大难问题。
整体架构一览
系统层 ── 只有 Anaconda,不装任何独立 Python
│
Conda 具名环境 ── py310 / py311 / py312 / py313 ...(各版本 + 工具套件)
│
项目 .venv ── 继承父级解释器后立即解耦,工具按需在 .venv 内再装一遍层层隔离,步步可解耦,这便是 EPGF 的核心理念:"继承而不依赖,封装而解耦"。
| 项目 | 配置 |
|---|---|
| 操作系统 | Windows 10/11(x64) |
| 终端 | Visual Studio 2022 Developer Command Prompt v17.12.20 + Clink v1.9.23 |
| .venv 环境 | Python 3.12 (来自 EPGF 架构) |
| 虚拟环境 | 项目级 .venv(--copies 物理复制模式) |
| 包管理 | pip 26.1.1 |
三、部署实录
步骤 1:进入项目目录
cd K:\PythonProjects5\MingLi-Bench步骤 2:激活 Conda 父环境
conda activate py312步骤 3:创建项目级虚拟环境
python -m venv --copies .venv--copies 在 Windows 下创建解释器的物理副本而非符号链接,避免路径污染和跨环境依赖风险。
步骤 4:激活项目虚拟环境
.venv\Scripts\Activate终端前缀变为 (.venv) (py312) K:\PythonProjects5\MingLi-Bench,项目级环境已激活。
步骤 5:解耦 Conda 父环境
conda deactivate终端前缀变为 (.venv) K:\PythonProjects5\MingLi-Bench,.venv 正式独立。
步骤 6:安装项目依赖
pip install -r requirements.txt安装过程顺利,主要依赖包括:
openai(2.37.0) --- OpenAI API 客户端anthropic(0.103.0) --- Anthropic Claude 客户端google-generativeai(0.8.6) --- Google Gemini 客户端requests(2.34.2)、tqdm、python-dotenv等基础库
依赖解析过程中,pip 对 grpcio-status 进行了多版本兼容性回溯检查,最终锁定 grpcio-status-1.71.2,耗时稍长但无报错。
步骤 7:升级 pip(可选但推荐)
python.exe -m pip install --upgrade pip
# 25.0.1 → 26.1.1步骤 8:配置环境变量
cp .env.example .env.env 已自动加入 .gitignore。根据实际评测需求填写对应平台的 API Key:
【笔记】suna部署之获取 OpenRouter API key
【笔记】Suna 部署之获取 OpenAI API key
# OpenRouter(推荐,单 Key 评测多模型)
OPENROUTER_API_KEY=sk-or-...
OPENROUTER_BASE_URL=https://openrouter.ai/api/v1
# 原生平台(按需填写)
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...
GOOGLE_API_KEY=...
DEEPSEEK_API_KEY=sk-...
DOUBAO_API_KEY=...
DOUBAO_BASE_URL=https://ark.cn-beijing.volces.com/api/v3
DOUBAO_ENDPOINT_ID=ep-...
# 默认参数
TIMEOUT=60
MAX_WORKERS=5
MAX_TOKENS=8192
TEMPERATURE=0.0四、踩坑与解决
坑点:Windows 终端不支持 Shell 行内注释
现象:执行带中文注释的命令时报错:
python -m mingli_bench.cli --list-models # 查看受支持的模型列表
# 报错:cli.py: error: unrecognized arguments: # 查看受支持的模型列表原因 :Windows CMD/PowerShell 不会将 # 识别为注释符,而是将其及之后的内容整体作为参数传递给 argparse。
解决:去掉行尾注释,或另起一行写说明:
python -m mingli_bench.cli --list-models
python -m mingli_bench.cli --stats五、部署验证
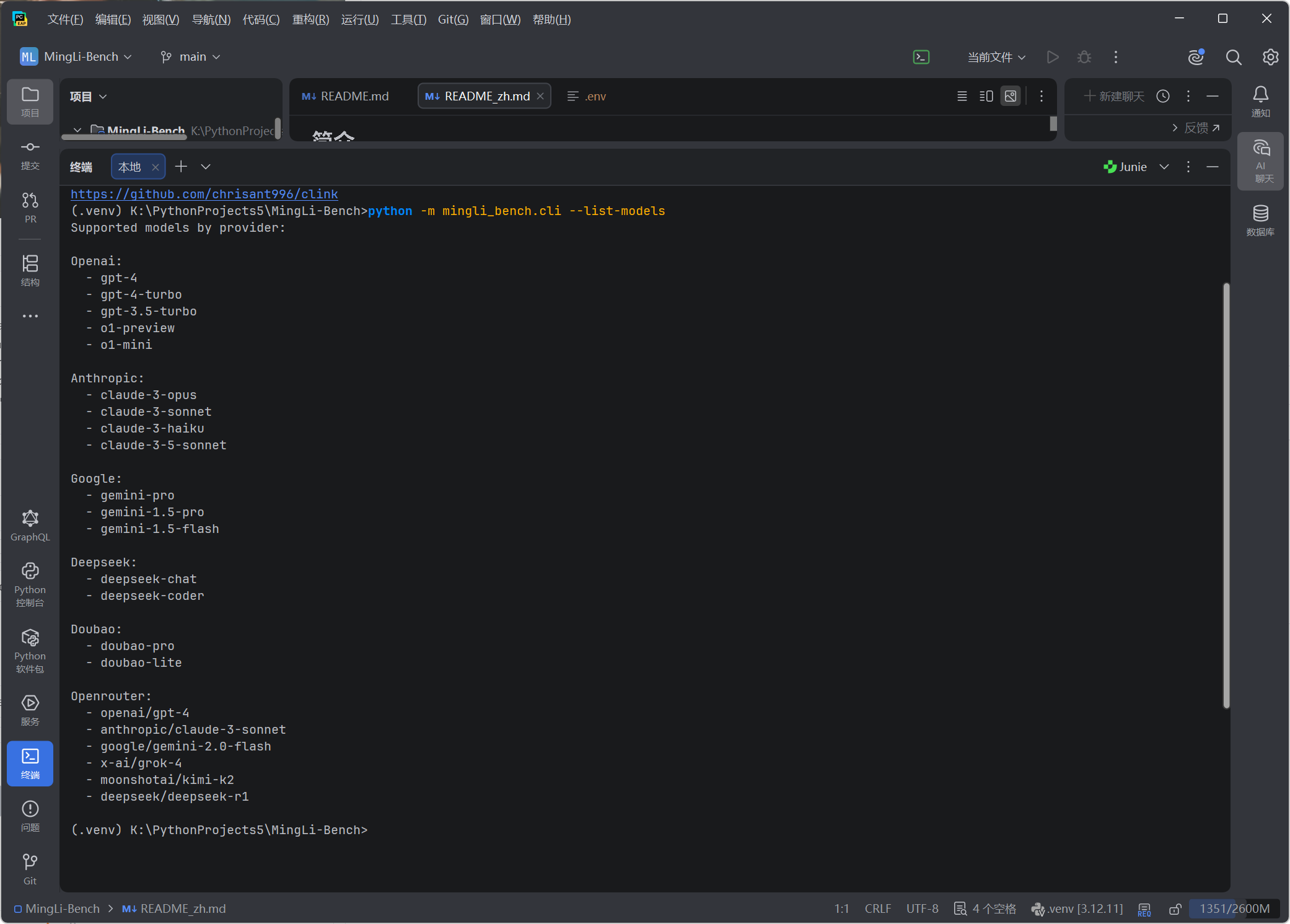
验证 1:查看支持的模型列表
python -m mingli_bench.cli --list-models输出结果涵盖 6 大平台 20+ 模型:
- OpenAI:gpt-4, gpt-4-turbo, gpt-3.5-turbo, o1-preview, o1-mini
- Anthropic:claude-3-opus, claude-3-sonnet, claude-3-haiku, claude-3-5-sonnet
- Google:gemini-pro, gemini-1.5-pro, gemini-1.5-flash
- DeepSeek:deepseek-chat, deepseek-coder
- Doubao:doubao-pro, doubao-lite
- OpenRouter:openai/gpt-4, anthropic/claude-3-sonnet, google/gemini-2.0-flash, x-ai/grok-4, moonshotai/kimi-k2, deepseek/deepseek-r1
验证 2:查看数据集统计
python -m mingli_bench.cli --stats输出摘要:
Dataset Statistics:
Name: FortuneTellingBench
Version: unknown
Available Years: 2022, 2023, 2024, 2025
Total Questions: 160
Categories:
- 婚姻: 44 题(占比最高,27.5%)
- 事业: 25 题
- 家庭: 22 题
- 健康: 17 题
- 性格: 14 题
- 财运: 13 题
- 学业: 11 题
- 子女: 6 题
- 外貌: 3 题
- 运势: 2 题
- 灾劫: 2 题
- 官非: 1 题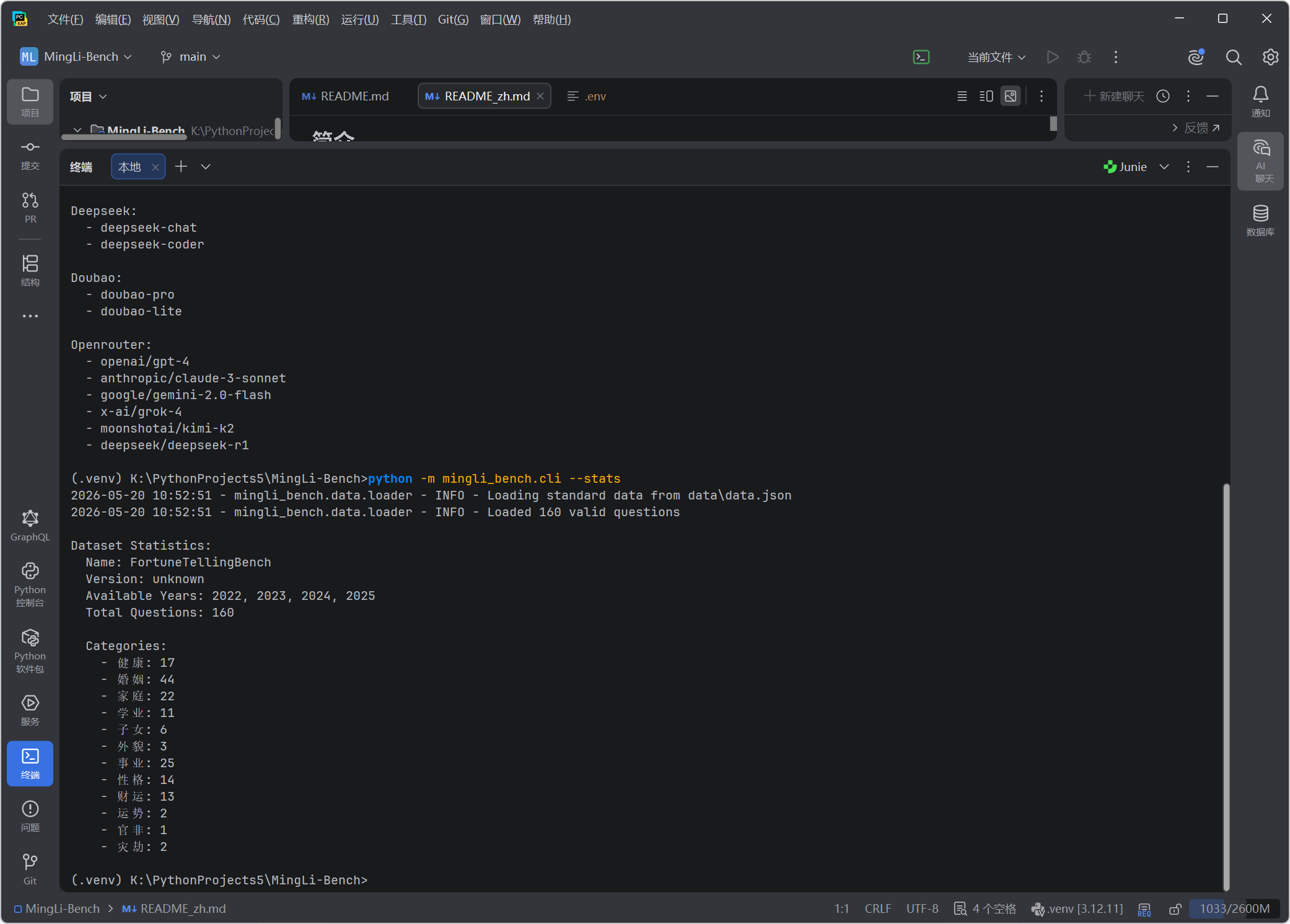
六、使用指南
推荐参数组合
官方强烈建议始终携带 --cot 和 --astro:
--cot(Chain-of-Thought):在 Prompt 前注入链式推理指令,给模型留出逐步分析命盘的空间--astro:从data/fortune_api_results.json注入预计算的八字/紫微斗数排盘结果,避免模型因"排盘错误"而失分,从而纯粹评测推理能力
评测示例
方式一:OpenRouter 路由(单 Key 评测多模型,推荐)
# 评测 Kimi K2
python -m mingli_bench.cli --model moonshotai/kimi-k2 --year 2025 --cot --astro --max-workers 8
# 评测 DeepSeek-R1
python -m mingli_bench.cli --model deepseek/deepseek-r1 --year 2025 --cot --astro
# 评测 GPT-4o
python -m mingli_bench.cli --model openai/gpt-4o --year 2025 --cot --astro方式二:原生平台直调
# DeepSeek 官方 API
python -m mingli_bench.cli --platform deepseek --model deepseek-chat --year 2025 --cot --astro
# 豆包 / 火山引擎
python -m mingli_bench.cli --platform doubao --model doubao-pro --year 2025 --cot --astro --max-workers 8输出产物
每次运行默认在 logs/ 目录生成三份产物:
| 文件 | 说明 |
|---|---|
<model>_results.json |
逐题预测、得分与聚合统计 |
<model>_summary.txt |
核心指标摘要(准确率、分类表现等) |
<model>_responses/ |
每道题的模型原始回复文本 |
七、总结
本次 MingLi-Bench 部署在 EPGF 架构指导下完成,环境从 Conda 具名环境继承、创建后即解耦,实现项目自包含。部署过程整体顺畅,唯一需要注意的坑点是 Windows 终端不支持 # 行内注释。
部署状态:✅ 成功 。下一步只需在 .env 中填入 API Key,即可对 Kimi、GPT-4o、Claude、DeepSeek 等主流模型展开一场别开生面的"算命能力"横评。