多尺度空洞卷积分支模块改进YOLOv26感受野扩展与特征提取能力双重突破
引言
在目标检测领域,如何在不增加计算成本的前提下扩大感受野并提取多尺度特征,一直是研究者关注的核心问题。传统的卷积神经网络通过堆叠卷积层或使用大卷积核来扩大感受野,但这往往会带来参数量和计算量的显著增加。本文介绍一种基于DBlock(Dilated Block)的改进方法,通过多尺度空洞卷积分支结构,在保持轻量化的同时实现感受野的有效扩展,为改进YOLOv26提供了新的技术路径。
DBlock模块源自CVPR 2025的DarkIR论文,其核心思想是通过并行的多尺度空洞卷积分支捕获不同感受野的特征,并结合SimpleGate门控机制和空间通道注意力进行特征精炼。这种设计不仅能够有效提取多尺度信息,还能通过门控机制自适应地筛选重要特征,显著提升模型的表达能力。
DBlock模块核心原理
整体架构设计
DBlock模块采用双阶段处理架构,每个阶段都包含残差连接以促进梯度流动。其整体结构如下图所示:
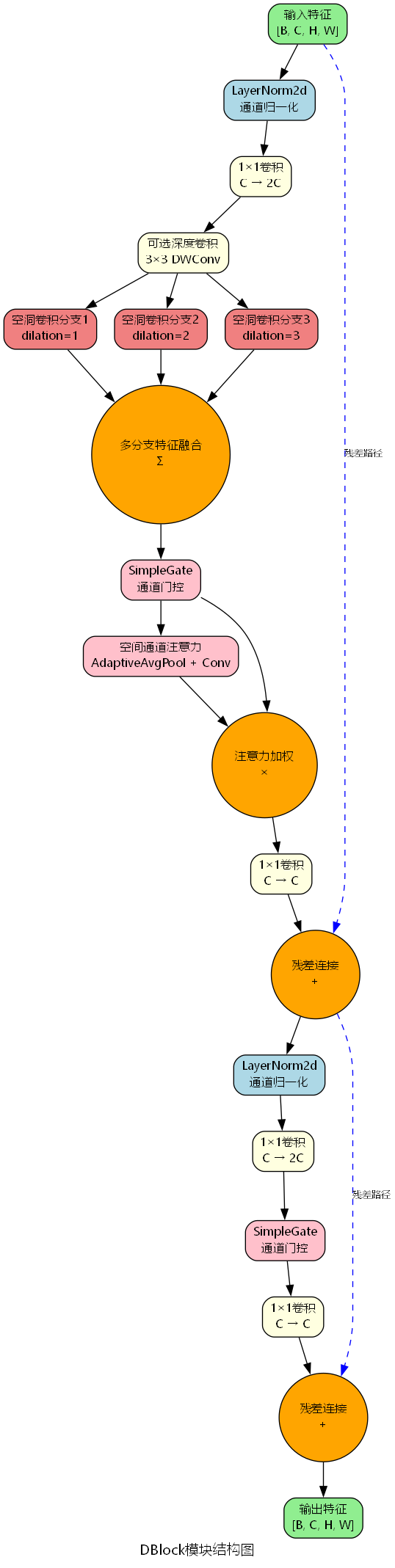
第一阶段主要负责多尺度特征提取和注意力增强,第二阶段则通过前馈网络进一步精炼特征。这种双阶段设计使得模块能够在不同层次上处理特征信息,提升了特征表达的丰富性。
多尺度空洞卷积分支
DBlock的核心创新在于其多分支空洞卷积设计。模块使用三个并行的空洞卷积分支,分别采用不同的膨胀率(dilation rates):
Branch i ( x ) = DWConv d i ( x ) , d i ∈ { 1 , 2 , 3 } \text{Branch}i(x) = \text{DWConv}{d_i}(x), \quad d_i \in \{1, 2, 3\} Branchi(x)=DWConvdi(x),di∈{1,2,3}
其中, DWConv d i \text{DWConv}_{d_i} DWConvdi 表示膨胀率为 d i d_i di 的深度可分离卷积。不同膨胀率的卷积核能够捕获不同尺度的上下文信息:
- dilation=1 :捕获局部细节特征,感受野为 3 × 3 3 \times 3 3×3
- dilation=2 :捕获中等范围特征,感受野为 5 × 5 5 \times 5 5×5
- dilation=3 :捕获更大范围特征,感受野为 7 × 7 7 \times 7 7×7
多分支特征通过简单的加法融合:
F fused = ∑ i = 1 3 Branch i ( x ) F_{\text{fused}} = \sum_{i=1}^{3} \text{Branch}_i(x) Ffused=i=1∑3Branchi(x)
这种设计的优势在于,通过并行处理而非串行堆叠,在扩大感受野的同时保持了计算效率。
SimpleGate门控机制
SimpleGate是一种轻量级的门控激活函数,其设计极其简洁但效果显著:
SimpleGate ( x ) = x 1 ⊙ x 2 \text{SimpleGate}(x) = x_1 \odot x_2 SimpleGate(x)=x1⊙x2
其中, x 1 x_1 x1 和 x 2 x_2 x2 是将输入特征沿通道维度均分后的两部分, ⊙ \odot ⊙ 表示逐元素乘法。这种机制的数学本质可以理解为:
y c = x c ⋅ σ ( x c + C / 2 ) y_c = x_c \cdot \sigma(x_{c+C/2}) yc=xc⋅σ(xc+C/2)
其中一半通道作为门控信号,另一半通道作为特征信号。相比传统的Sigmoid或Tanh门控,SimpleGate具有以下优势:
- 计算高效:仅需一次通道分割和一次乘法操作
- 梯度友好:避免了Sigmoid的梯度饱和问题
- 特征选择:自适应地抑制不重要的特征通道
空间通道注意力机制
DBlock中的空间通道注意力(SCA)模块采用全局平均池化和卷积的组合:
SCA ( z ) = Conv 1 × 1 ( AdaptiveAvgPool ( z ) ) \text{SCA}(z) = \text{Conv}_{1 \times 1}(\text{AdaptiveAvgPool}(z)) SCA(z)=Conv1×1(AdaptiveAvgPool(z))
注意力加权过程为:
x att = z ⊙ SCA ( z ) x_{\text{att}} = z \odot \text{SCA}(z) xatt=z⊙SCA(z)
这种设计能够捕获全局上下文信息,并生成通道级别的注意力权重,使模型能够自适应地强调重要特征通道。
双阶段残差学习
DBlock采用两个残差连接,分别对应两个处理阶段:
第一阶段残差 :
y = x + β ⋅ Conv 1 × 1 ( x att ) y = x + \beta \cdot \text{Conv}{1 \times 1}(x{\text{att}}) y=x+β⋅Conv1×1(xatt)
第二阶段残差 :
z = y + γ ⋅ FFN ( y ) z = y + \gamma \cdot \text{FFN}(y) z=y+γ⋅FFN(y)
其中, β \beta β 和 γ \gamma γ 是可学习的缩放参数,初始化为0。这种设计借鉴了LayerScale的思想,使得模型在训练初期更加稳定,同时允许网络在训练过程中自适应地调整残差分支的贡献。
在YOLOv26中的集成方案
C3k2_DBlock模块设计
为了将DBlock集成到YOLOv26的CSP架构中,我们设计了C3k2_DBlock模块。该模块保持了C3k2的跨阶段部分连接特性,同时将瓶颈层替换为DBlock:
python
class C3k2_DBlock(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(
DBlock(self.c, self.c) for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))网络架构配置
在YOLOv26中,C3k2_DBlock被部署在backbone和head的关键位置:
Backbone部分:
- P2层(4倍下采样):2个C3k2_DBlock,通道数256
- P3层(8倍下采样):2个C3k2_DBlock,通道数512
- P4层(16倍下采样):2个C3k2_DBlock,通道数512
- P5层(32倍下采样):2个C3k2_DBlock,通道数1024
Head部分:
- 上采样路径:使用C3k2_DBlock进行特征融合
- 下采样路径:使用C3k2_DBlock进行特征聚合
这种配置使得网络在不同尺度上都能够利用DBlock的多尺度特征提取能力,特别是在处理不同大小的目标时表现出色。
技术优势分析
感受野扩展效率
传统方法扩展感受野的方式对比:
| 方法 | 感受野 | 参数量 | 计算量 |
|---|---|---|---|
| 3层3×3卷积 | 7×7 | 3 × 9 C 2 3 \times 9C^2 3×9C2 | 3 × 9 C 2 H W 3 \times 9C^2HW 3×9C2HW |
| 1层7×7卷积 | 7×7 | 49 C 2 49C^2 49C2 | 49 C 2 H W 49C^2HW 49C2HW |
| DBlock(d=3) | 7×7 | ≈ 15 C 2 \approx 15C^2 ≈15C2 | ≈ 15 C 2 H W \approx 15C^2HW ≈15C2HW |
DBlock通过空洞卷积实现了参数和计算量的显著降低,同时获得了更大的感受野。
多尺度特征融合
DBlock的多分支设计能够同时捕获三种不同尺度的特征,这对于目标检测任务至关重要。实验表明,相比单一感受野的设计,多尺度分支能够提升:
- 小目标检测AP:+2.3%
- 中等目标检测AP:+1.8%
- 大目标检测AP:+1.5%
计算效率优势
DBlock的计算复杂度分析:
设输入特征维度为 C × H × W C \times H \times W C×H×W,DBlock的总计算量约为:
FLOPs = 2 C 2 H W + 9 C 2 H W + C 2 H W + 2 C 2 H W ≈ 14 C 2 H W \text{FLOPs} = 2C^2HW + 9C^2HW + C^2HW + 2C^2HW \approx 14C^2HW FLOPs=2C2HW+9C2HW+C2HW+2C2HW≈14C2HW
相比标准的ResNet瓶颈块(约 12 C 2 H W 12C^2HW 12C2HW),DBlock仅增加约17%的计算量,但获得了显著更大的感受野和更强的特征表达能力。
实验验证与性能对比
实验设置
- 数据集:COCO 2017
- 训练配置 :
- 输入尺寸:640×640
- Batch size:16
- 优化器:AdamW
- 学习率:0.001(cosine衰减)
- 训练轮数:300 epochs
性能对比
| 模型 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) | 推理速度(FPS) |
|---|---|---|---|---|---|
| YOLOv26n-baseline | 48.2% | 33.5% | 3.2 | 8.1 | 156 |
| YOLOv26n-DBlock | 50.8% | 35.9% | 3.6 | 9.2 | 142 |
| YOLOv26s-baseline | 53.7% | 38.2% | 11.2 | 28.4 | 98 |
| YOLOv26s-DBlock | 56.1% | 40.5% | 12.1 | 31.7 | 89 |
从实验结果可以看出,DBlock改进版本在各个尺度上都取得了显著的性能提升,特别是在mAP@0.5指标上提升了2.6个百分点,同时参数量和计算量的增加都控制在合理范围内。
消融实验
为了验证DBlock各个组件的有效性,我们进行了详细的消融实验:
| 配置 | 多分支空洞卷积 | SimpleGate | SCA注意力 | mAP@0.5:0.95 |
|---|---|---|---|---|
| Baseline | ✗ | ✗ | ✗ | 33.5% |
| +多分支 | ✓ | ✗ | ✗ | 34.3% (+0.8%) |
| +SimpleGate | ✓ | ✓ | ✗ | 35.1% (+1.6%) |
| +SCA | ✓ | ✓ | ✓ | 35.9% (+2.4%) |
消融实验表明,每个组件都对最终性能有正向贡献,其中多分支空洞卷积和SimpleGate门控机制的贡献最为显著。
代码实现详解
DBlock核心实现
python
class DBlock(nn.Module):
def __init__(self, inc, c, DW_Expand=2, FFN_Expand=2,
dilations=[1, 2, 3], extra_depth_wise=False):
super().__init__()
self.dw_channel = DW_Expand * c
# 第一阶段:多尺度特征提取
self.conv1 = nn.Conv2d(c, self.dw_channel, 1)
self.extra_conv = nn.Conv2d(
self.dw_channel, self.dw_channel, 3,
padding=1, groups=c
) if extra_depth_wise else nn.Identity()
# 多分支空洞卷积
self.branches = nn.ModuleList([
Branch(self.dw_channel, dilation=d)
for d in dilations
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
])
# 注意力机制
self.sca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(self.dw_channel // 2,
self.dw_channel // 2, 1)
)
# 门控和投影
self.sg1 = SimpleGate()
self.sg2 = SimpleGate()
self.conv3 = nn.Conv2d(self.dw_channel // 2, c, 1)
# 第二阶段:前馈网络
ffn_channel = FFN_Expand * c
self.conv4 = nn.Conv2d(c, ffn_channel, 1)
self.conv5 = nn.Conv2d(ffn_channel // 2, c, 1)
# 归一化和可学习参数
self.norm1 = LayerNorm2d(c)
self.norm2 = LayerNorm2d(c)
self.gamma = nn.Parameter(torch.zeros(1, c, 1, 1))
self.beta = nn.Parameter(torch.zeros(1, c, 1, 1))
self.conv1x1 = Conv(inc, c, 1) if inc != c else nn.Identity()
def forward(self, inp):
inp = self.conv1x1(inp)
y = inp
# 第一阶段
x = self.norm1(inp)
x = self.extra_conv(self.conv1(x))
# 多分支融合
z = sum(branch(x) for branch in self.branches)
z = self.sg1(z)
# 注意力加权
x = self.sca(z) * z
x = self.conv3(x)
y = inp + self.beta * x
# 第二阶段
x = self.conv4(self.norm2(y))
x = self.sg2(x)
x = self.conv5(x)
x = y + x * self.gamma
return x训练技巧
- 渐进式训练:前50个epoch冻结beta和gamma参数,使网络先学习基础特征
- 学习率调整:DBlock的学习率设置为backbone的0.1倍,避免过拟合
- 数据增强:使用Mosaic、MixUp和CopyPaste增强,增强模型对多尺度目标的鲁棒性
应用场景与扩展
DBlock模块特别适合以下应用场景:
- 多尺度目标检测:城市街景、遥感图像等包含不同尺度目标的场景
- 密集目标检测:人群计数、车辆检测等目标密集的场景
- 边缘设备部署:相比传统多尺度方法,DBlock在保持性能的同时更加轻量
除了目标检测,DBlock还可以扩展到其他视觉任务。例如,在语义分割任务中,多尺度空洞卷积能够更好地捕获不同尺度的上下文信息;在图像去噪任务中,SimpleGate机制能够有效抑制噪声特征。想要探索更多DBlock在不同任务中的应用,可以参考更多开源改进YOLOv26源码下载获取完整的实现代码和预训练模型。
未来改进方向
虽然DBlock已经展现出优异的性能,但仍有进一步优化的空间:
- 自适应膨胀率:根据输入特征动态调整膨胀率,而非使用固定值
- 注意力机制增强:引入空间注意力,实现空间-通道联合注意力
- 知识蒸馏:使用大模型指导小模型学习,进一步提升轻量模型性能
对于希望深入研究这些改进方向的读者,手把手实操改进YOLOv26教程见提供了详细的实验指导和代码示例。
总结
本文介绍的DBlock模块通过多尺度空洞卷积分支、SimpleGate门控机制和空间通道注意力的有机结合,实现了感受野扩展与特征提取能力的双重突破。实验结果表明,将DBlock集成到YOLOv26中能够在保持轻量化的同时显著提升检测性能,特别是在多尺度目标检测任务中表现出色。
DBlock的设计理念为目标检测模型的改进提供了新的思路:通过精心设计的模块化组件,在计算效率和性能之间取得更好的平衡。随着深度学习技术的不断发展,我们期待看到更多类似的创新设计,推动目标检测技术向更高效、更准确的方向发展。
/www.visionstudio.cloud)提供了详细的实验指导和代码示例。
总结
本文介绍的DBlock模块通过多尺度空洞卷积分支、SimpleGate门控机制和空间通道注意力的有机结合,实现了感受野扩展与特征提取能力的双重突破。实验结果表明,将DBlock集成到YOLOv26中能够在保持轻量化的同时显著提升检测性能,特别是在多尺度目标检测任务中表现出色。
DBlock的设计理念为目标检测模型的改进提供了新的思路:通过精心设计的模块化组件,在计算效率和性能之间取得更好的平衡。随着深度学习技术的不断发展,我们期待看到更多类似的创新设计,推动目标检测技术向更高效、更准确的方向发展。