
10.2 3D大模型与场景理解
在真实物理世界中,人形机器人所面对的环境本质上是三维的。仅依赖二维视觉信息,难以准确理解空间结构、物体形态与可操作性。随着3D感知技术与大模型的发展,融合点云、网格和几何结构的3D大模型逐渐成为机器人场景理解的重要支撑。本节围绕3D-LLM、点云与文本的跨模态查询,以及3D场景图的构建方法,系统阐述大模型如何赋予机器人对复杂三维环境的高层语义理解能力。
10.2.1 3D-LLM大模型(Point-LLM/Polymath/LASER)
3D-LLM(Three-Dimensional Large Language Model)是指将三维几何感知能力与大语言模型深度融合,使模型不仅能够理解语言和二维图像,还能够直接理解点云、空间结构与物理关系的一类多模态大模型。在人形机器人系统中,3D-LLM 是连接低层三维感知与高层语义推理的重要枢纽,为空间理解、操作决策和任务规划提供语义化的三维认知能力。
- 从三维感知到语言推理的统一建模
传统3D感知算法通常侧重于几何重建和物体识别,难以直接支持高层语义推理。而3D-LLM的核心思想,是将点云等三维数据映射到与语言模型兼容的表示空间,使其能够参与语言驱动的推理过程。
设机器人在时刻t 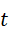 获得的点云数据为P t ={ p i } i=1N
获得的点云数据为P t ={ p i } i=1N 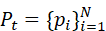 ,其中每个点pi
,其中每个点pi 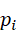 包含空间坐标及相关属性。点云编码器首先将其映射为高层特征表示:
包含空间坐标及相关属性。点云编码器首先将其映射为高层特征表示:
z P = f 3D*(* P t) 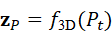
该表示随后通过投影或跨模态对齐模块,与语言模型的语义空间进行融合,从而使三维环境信息能够被语言模型"理解"和利用。
- Point-LLM:面向点云理解的语言增强模型
Point-LLM是3D-LLM中较早、也最具代表性的范式之一,其核心目标是使大语言模型具备点云语义理解能力。该模型通常采用点云编码器(如PointNet、Point Transformer)提取全局或局部特征,并通过对齐机制将其作为"视觉 token"输入语言模型。
在机器人场景中,Point-LLM 使系统能够直接回答基于三维结构的问题,例如:
- "哪个物体是可抓取的?"
- "这个空间是否足够机器人转身?"
这种能力使语言模型不再局限于文本和图像,而是扩展到真实物理空间的语义理解。
- Polymath:多模态统一推理的3D-LLM架构
Polymath代表了3D-LLM向多模态统一建模方向的发展。其设计目标是将点云、图像、语言乃至动作表示统一到一个推理框架中,使模型能够跨模态进行联合推理。
在形式上,可以将Polymath的推理过程抽象为:
h = LLM*(* **z** *P* *,* **z** *I* *,* **z** *T)* 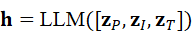
其中,z P 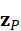 、z I
、z I 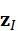 、z T
、z T 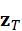 分别表示点云、图像与语言的嵌入表示。
分别表示点云、图像与语言的嵌入表示。
在机器人系统中,这种统一推理能力使模型能够同时考虑几何结构、视觉外观与语言指令,从而更准确地理解复杂场景并生成合理决策。
- LASER:强调空间关系与物理语义的3D理解模型
LASER更关注三维环境中的空间关系、结构约束与物理可行性问题。与侧重语义描述的模型不同,LASER 强调对象之间的拓扑关系和可交互属性,例如支撑关系、可通行性和稳定性。
在机器人任务中,LASER类型的模型常用于下面的场景:
- 判断物体是否可安全放置;
- 推理空间是否可供机器人通过;
- 评估操作动作的物理合理性。
这类模型通常与规划模块深度耦合,为机器人提供更具物理约束的语义理解。
- 3D-LLM在机器人系统中的角色定位
在完整的人形机器人架构中,3D-LLM并不取代底层感知算法,而是位于感知与决策之间的认知层。其主要作用是将原始三维感知结果转化为可被语言模型理解和推理的语义表示,并为任务规划和控制模块提供高层空间知识。
在决策层面,该过程可概括为:
a * = arg max a P(a∣ z P , z T) 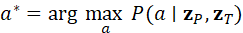
使机器人能够在语言指令约束下,根据三维环境状态选择合适的行动策略。
总之,3D-LLM将三维几何感知与大语言模型深度融合,使机器人能够在真实物理空间中进行语言驱动的理解与推理。Point-LLM、Polymath与LASER分别代表了点云语义理解、多模态统一推理与物理空间建模的不同侧重点,共同构成了大模型时代机器人三维场景理解的重要技术基础。
10.2.2 点云与文本的跨模态查询
点云与文本的跨模态查询,是指机器人能够使用自然语言直接在三维环境中检索目标对象、空间区域或特定场景关系。通过将语言指令映射到三维空间,机器人可以精准定位目标、筛选候选区域,并为后续抓取或导航任务提供直接支持。
- 点云特征编码与表示
在实际场景中,机器人获取的点云数据包含环境的空间结构和物体形态信息,但这些原始点云无法直接用于语义推理。因此,需要通过编码器将点云映射为高维特征表示,使几何信息可以被大模型理解和处理。
设机器人在时刻t 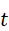 获取的点云数据为:
获取的点云数据为:
P t ={ p i } i=1 N , p i ∈ R3 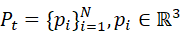
其中,N 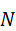 是点数量,每个点 pi
是点数量,每个点 pi 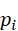 包含空间坐标及可选属性(颜色、反射强度等)。点云编码器 f 3D
包含空间坐标及可选属性(颜色、反射强度等)。点云编码器 f 3D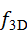 将其映射为高维特征:
将其映射为高维特征:
z P = f 3D*(* P t )∈ RN×d 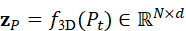
其中,z P 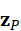 用于保留局部几何和全局空间结构信息,为跨模态对齐和语义推理提供输入。
用于保留局部几何和全局空间结构信息,为跨模态对齐和语义推理提供输入。
- 文本嵌入与语义表示
语言指令是机器人执行任务的核心驱动。自然语言查询需要编码成向量表示,以便与点云特征进行匹配。
给定语言指令T 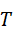 ,文本编码器 f text
,文本编码器 f text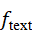 将其映射为语义嵌入:
将其映射为语义嵌入:
z T = f text*(T)∈* Rd 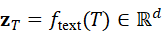
该向量承载目标对象类别、属性以及空间约束等信息,为点云查询提供语义条件。
- 跨模态对齐与相似度计算
要实现语言驱动的点云检索,需要建立点云特征与文本嵌入之间的语义对应。通过在统一嵌入空间计算相似度,模型可以识别点云中与语言描述最匹配的区域。
设第i 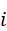 个点云局部特征为v i
个点云局部特征为v i 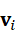 ,文本查询为z T
,文本查询为z T 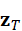 ,相似度计算公式为:
,相似度计算公式为:
s i = v i ⊤z T ∥v i ∥ ∥z T ∥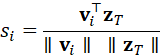
匹配度最高的点云区域可作为目标:
i = arg max i si 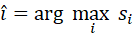
这种机制使机器人能够直接根据语言查询定位目标对象,无需预定义类别标签。
- 多点云区域聚合与任务驱动注意
语言指令可能涉及多个对象或复杂空间关系,如"桌子左侧的红色杯子和蓝色书本"。单个点或区域的匹配不足以完整表示任务目标。
通过语言引导的注意机制,可以对多个局部特征进行加权聚合:
α i = softmax*(* s i ), v * = i α i v i 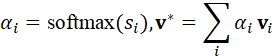
其中,v * 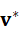 作为任务驱动的聚合表示,可直接用于机器人抓取或导航决策。
作为任务驱动的聚合表示,可直接用于机器人抓取或导航决策。
- 结合几何约束的语义增强
在实际操作中,语言指令通常包含位置或关系约束,例如"杯子在桌子上,靠近右侧边缘"。为了提高匹配精度,需要将几何约束引入跨模态查询:
α i '= α i ⋅ϕ( p i,R) 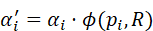
其中,ϕ( p i,R) 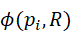 表示点pi
表示点pi 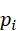 与空间约束R
与空间约束R 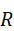 的匹配度。结合几何约束可以使语义查询更精确,同时保证任务的可执行性。
的匹配度。结合几何约束可以使语义查询更精确,同时保证任务的可执行性。
- 闭环执行与动态更新
机器人在执行过程中,环境和目标可能不断变化。点云与文本查询需要以闭环方式运行,以便持续更新目标和调整策略。
对于新时刻的点云Pt+1 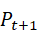 和相同语言指令z T
和相同语言指令z T 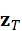 ,更新后的聚合目标为:
,更新后的聚合目标为:
v t+1 * = Query*(* P t+1 , z T) 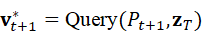
通过这种闭环机制,机器人能够在动态环境中持续追踪目标、应对遮挡或移动,保证任务执行的鲁棒性和稳定性。
总之,点云与文本的跨模态查询实现了语言指令在三维环境中的直接检索和目标定位。通过点云编码、文本嵌入、语义对齐、注意聚合和几何约束增强,机器人能够将语言查询映射为精确的三维感知结果。结合闭环更新,机器人在开放动态环境中可以稳定执行抓取、导航和语义推理任务,从而实现语言驱动的3D感知与操作一体化。
10.2.3 3D场景图的构建与语义增强
3D场景图是将三维环境表示为"节点---关系"结构的高层抽象形式,其中节点表示物体、区域或功能单元,边表示空间关系、功能关系或交互约束。相比原始点云或体素表示,场景图更利于语义推理、任务规划和操作决策。通过语义增强,机器人不仅能够理解几何布局,还能识别功能属性、可操作性和空间可达性,从而实现语言驱动的三维智能感知。
- 节点构建与属性表示
在场景图中,每一个节点通常对应一个可感知的物体或环境区域。节点不仅包含几何信息,还可以嵌入语义属性,如类别、可抓取性或功能。
设场景中检测到的物体集合为 O={ o 1 , o 2 ,..., o M} 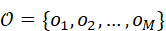 ,每个节点的特征向量由几何特征和语义特征组成:
,每个节点的特征向量由几何特征和语义特征组成:
n i =* **z** *P* *(* *o* *i* *);* **z** *T* *(* *o* *i* *)∈ Rd 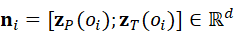
其中,z P ( o i) 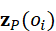 是点云编码器提取的几何特征,z T ( o i)
是点云编码器提取的几何特征,z T ( o i) 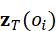 是语言或属性嵌入。节点特征既保留三维信息,又可与语言指令或任务描述对齐。
是语言或属性嵌入。节点特征既保留三维信息,又可与语言指令或任务描述对齐。
- 边关系建模与空间约束
场景图的边表示节点间的空间关系或功能关系,如"在上方""靠近""支撑"。边的表示可以用关系向量或矩阵表示:
e ij =g( n i , n j , R ij) 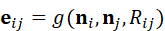
其中,Rij 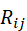 表示几何或语义关系,例如点到点的距离、拓扑关系或功能约束。通过边的建模,机器人可以理解物体之间的相对位置和潜在交互,辅助任务规划和动作推理。
表示几何或语义关系,例如点到点的距离、拓扑关系或功能约束。通过边的建模,机器人可以理解物体之间的相对位置和潜在交互,辅助任务规划和动作推理。
- 语义增强与属性推理
在基础场景图中,每个节点和边主要携带物体的几何信息和空间关系。然而,单纯的几何和拓扑信息对于机器人执行复杂任务仍然不足。例如:机器人要去抓一个杯子,如果只知道杯子的形状和位置,它可能无法判断杯子是否可抓取、是否被占用,或者抓取是否安全。类似地,在导航任务中,仅靠空间位置无法判断路径是否可通行或是否存在优先级冲突。
因此,需要对场景图进行语义增强:将节点和边附加高层语义信息,使机器人不仅"看见"环境,还能"理解"环境的功能和状态,从而更智能地执行任务。语义增强的目标是将场景图从几何结构升级为认知模型,使其具备以下能力:
- 功能属性(Functional Attributes):描述物体或区域的可操作性。例如一个椅子是可坐的,一个杯子是可抓取的,一个门口区域是可通行的。这些功能属性让机器人能够根据任务指令判断哪些对象可以操作。
- 状态信息(State Information):反映物体或区域的动态状态,如设备开/关、桌面占用/空闲、门是否关闭。状态信息帮助机器人在执行任务时选择合适的目标或路径,避免碰撞或重复操作。
- 任务相关约束(Task Constraints):用于辅助规划和执行,例如安全性约束(不能碰掉热水杯)、优先级(先清理障碍再抓取目标)等。这类约束使机器人在复杂任务中可以遵循规则顺序、保证操作安全,并更合理地分配执行资源。
通过语义增强,场景图不仅是静态的三维几何模型,而是具有认知和推理能力的知识结构。机器人能够在场景图中直接推理:判断可操作对象、选择可行路径、安排动作顺序,从而实现更智能、更安全、更高效的任务执行。
语义增强可以通过大模型推理完成,结合语言指令与视觉/点云信息对节点进行属性更新:
n i '= Enhance*(* n i , e ij , z T) 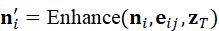
其中,n i '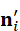 是增强后的节点特征,既保留原始几何,又嵌入语义信息,使机器人能够在场景图上进行高层推理。
是增强后的节点特征,既保留原始几何,又嵌入语义信息,使机器人能够在场景图上进行高层推理。
- 语言驱动的场景图查询与推理
机器人在执行任务时,可将语言指令映射为场景图查询条件。例如,指令"抓取桌子左侧的红色杯子"会触发对场景图的节点与边的检索:
o * = arg max o i ∈O P( o i ∣ n i ', z T) 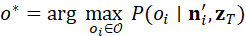
这种语言驱动的场景图推理,使机器人能够在复杂三维环境中定位任务目标,同时考虑空间关系和功能属性,提高任务可执行性。
- 闭环更新与动态环境适应
真实环境是动态的,物体可能移动,空间状态可能变化。场景图需要随时间动态更新:
n i 't 1 = Update*(* n i 't , P t+1 , z T) 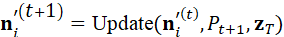
通过闭环更新,机器人可以实时感知环境变化,调整任务目标和操作策略。例如,当目标物体被遮挡或移动时,场景图能够提供最新的节点和边信息,支持机器人重新规划抓取或导航路径。
- 场景图在任务规划中的作用
构建和增强的场景图不仅用于感知,也直接参与任务规划。通过图结构,机器人可以推断操作顺序、空间可达性和潜在冲突。例如,抓取任务需要先移除遮挡物,再定位目标;导航任务需要结合空间约束选择可通行路径。通过结合语言指令、3D感知结果和语义增强的场景图,机器人实现了从语言到感知再到决策的完整闭环。
总而言之,3D场景图的构建与语义增强,是将三维感知数据转化为可推理知识结构的核心方法。通过节点---边结构表示物体与空间关系,结合语义增强和语言驱动查询,机器人可以在复杂、动态的三维环境中实现高层语义理解、目标定位和任务规划。闭环更新确保了系统对环境变化的适应能力,使人形机器人具备真正的场景感知与智能决策能力。