一、分布式容错的本质:故障是常态,容错是核心能力
分布式系统的核心矛盾,是业务对高可用的极致要求 与分布式环境天然的不可靠性之间的矛盾。Sun公司提出的分布式系统8大谬误,道破了所有分布式故障的根源:我们默认网络可靠、延迟为零、带宽无限、拓扑固定,但现实中,网络抖动、机器宕机、依赖服务超时、资源耗尽、数据不一致等故障,是分布式系统的常态,而非例外。
分布式容错的核心目标,是在故障发生时,将故障锁定在最小范围内,避免雪崩扩散,保障核心业务的持续可用,最终实现系统的"自愈能力"。一套完整的分布式容错体系,必须覆盖故障检测、故障隔离、故障恢复三大核心环节,三者形成闭环,缺一不可。
二、故障检测:容错体系的前置前提
故障检测是容错的第一道关口------无法精准识别故障,后续的隔离、恢复便无从谈起。故障检测的核心挑战,是在漏判 (故障未被识别,流量持续打入故障节点)和误判(正常节点被判定为故障,引发不必要的流量摘除、主从切换)之间找到最优平衡。
2.1 故障的分级定义与检测维度
我们需要建立多层级的故障检测体系,覆盖从底层资源到上层业务的全维度,避免单一检测维度的盲区:
- 资源级故障:CPU使用率持续飙高、内存/磁盘耗尽、网络IO阻塞、线程池队列满、JVM Full GC STW超时等系统资源异常,这类故障会直接导致业务处理能力下降甚至丧失。
- 进程级故障:应用进程崩溃、JVM退出、进程死锁/活锁,此时TCP连接可能仍存活,但业务已完全无法处理。
- 实例级故障:服务实例无法响应健康检查请求、实例注册信息从注册中心摘除,实例整体不可用。
- 接口级故障:具体业务接口的异常率、超时率、响应时间超过阈值,实例整体存活,但部分业务能力丧失,这是最细粒度也是最容易被忽略的故障场景。
2.2 核心检测机制的底层逻辑与易混淆点区分
2.2.1 TCP Keepalive vs 应用层心跳
这是生产环境最常见的认知误区,二者的核心能力边界完全不同:
- TCP Keepalive:传输层的保活机制,默认2小时发送一次探测包,仅能验证TCP连接的网络链路是否通畅,无法感知应用层的状态。比如应用进程发生死锁,TCP连接仍处于ESTABLISHED状态,但业务已完全无法处理请求,此时TCP Keepalive会判定连接正常,出现严重的漏判。
- 应用层心跳:业务层面的存活探测,客户端与服务端通过约定的心跳接口,周期性交换业务层的存活状态、负载信息。它不仅能验证网络连通性,还能验证应用进程、业务线程池、核心依赖的健康状态,是分布式系统故障检测的核心基础。
2.2.2 固定超时检测 vs 自适应故障检测
固定超时检测是最简单的检测方式:超过预设时间未收到心跳响应,即判定节点故障。但分布式网络存在天然的抖动,固定超时无法适配动态的网络环境:超时设置过短,会引发大量误判;超时设置过长,会导致故障发现不及时,扩大业务影响。
自适应故障检测的行业标准方案,是Phi Accrual Failure Detector ,已在Akka、Cassandra、Gossip协议等主流分布式组件中大规模落地。其核心逻辑是:基于历史心跳的延迟分布,计算出phi值------代表节点故障的置信度,phi值越高,节点故障的概率越大。例如phi=5时,节点故障的概率为99.999%,此时即可判定节点故障。
该算法完全自适应网络环境的变化,网络抖动时,会自动调整故障判定的阈值,从根本上解决了固定超时的误判与漏判问题。
2.3 故障检测生产级实现
2.3.1 项目基础依赖配置
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam.demo</groupId>
<artifactId>distributed-fault-tolerance-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>distributed-fault-tolerance-demo</name>
<properties>
<java.version>17</java.version>
<resilience4j.version>2.2.0</resilience4j.version>
<mybatis-plus.version>3.5.6</mybatis-plus.version>
<fastjson2.version>2.0.52</fastjson2.version>
<guava.version>33.1.0-jre</guava.version>
<lombok.version>1.18.30</lombok.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot3</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>2.3.2 全维度健康检测接口实现
kotlin
package com.jam.demo.controller;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.jam.demo.entity.IdempotentRecord;
import com.jam.demo.mapper.IdempotentRecordMapper;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
/**
* 服务健康检测控制器
*
* @author ken
*/
@Slf4j
@RestController
@RequestMapping("/health")
@Tag(name = "健康检测接口", description = "全维度服务健康状态检测")
public class HealthCheckController {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private IdempotentRecordMapper idempotentRecordMapper;
/**
* 实例级基础健康检测
*
* @return 服务基础状态
*/
@GetMapping("/base")
@Operation(summary = "基础健康检测", description = "验证服务实例基础存活状态")
public Map<String, Object> baseHealth() {
return Map.of("status", "UP", "timestamp", System.currentTimeMillis());
}
/**
* 全维度深度健康检测
* 覆盖核心依赖:数据库、缓存、核心业务表
*
* @return 全维度健康状态
*/
@GetMapping("/deep")
@Operation(summary = "深度健康检测", description = "验证服务核心依赖与业务能力健康状态")
public Map<String, Object> deepHealth() {
long startTime = System.currentTimeMillis();
Map<String, Object> result = Maps.newHashMap();
result.put("baseStatus", "UP");
result.put("timestamp", startTime);
try {
// 数据库连通性检测
jdbcTemplate.queryForObject("SELECT 1", Integer.class);
result.put("dbStatus", "UP");
// 核心业务表可用性检测
List<IdempotentRecord> records = idempotentRecordMapper.selectList(
Wrappers.lambdaQuery(IdempotentRecord.class).last("LIMIT 1")
);
result.put("bizTableStatus", "UP");
// 缓存连通性检测
String redisKey = "health:check:ping";
stringRedisTemplate.opsForValue().set(redisKey, "pong");
String redisValue = stringRedisTemplate.opsForValue().get(redisKey);
if (StringUtils.hasText(redisValue) && "pong".equals(redisValue)) {
result.put("redisStatus", "UP");
} else {
result.put("redisStatus", "DOWN");
result.put("status", "DOWN");
}
// 整体状态判定
if (!result.containsValue("DOWN")) {
result.put("status", "UP");
}
} catch (Exception e) {
log.error("深度健康检测失败", e);
result.put("status", "DOWN");
result.put("errorMsg", e.getMessage());
}
result.put("checkCost", System.currentTimeMillis() - startTime);
return result;
}
}2.3.3 Phi Accrual自适应故障检测器实现
ini
package com.jam.demo.detector;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.CollectionUtils;
import java.util.LinkedList;
import java.util.List;
/**
* Phi Accrual自适应故障检测器
* 基于历史心跳延迟分布,自适应判定节点故障状态
*
* @author ken
*/
@Slf4j
public class PhiAccrualFailureDetector {
private static final int MAX_SAMPLE_SIZE = 1000;
private static final double PHI_THRESHOLD = 5.0;
private static final long MIN_STANDARD_DEVIATION_MILLIS = 10L;
private final LinkedList<Long> heartbeatIntervals = new LinkedList<>();
private long lastHeartbeatTime = 0L;
private double meanInterval = 0L;
private double variance = 0L;
/**
* 接收心跳,更新统计数据
*
* @param heartbeatTime 心跳时间戳
*/
public synchronized void heartbeat(long heartbeatTime) {
if (lastHeartbeatTime > 0) {
long interval = heartbeatTime - lastHeartbeatTime;
addIntervalSample(interval);
recalculateStatistics();
}
this.lastHeartbeatTime = heartbeatTime;
}
/**
* 计算当前phi值,判定节点是否故障
*
* @param currentTime 当前时间戳
* @return true-节点故障,false-节点正常
*/
public synchronized boolean isFailure(long currentTime) {
if (lastHeartbeatTime == 0) {
return false;
}
long elapsedTime = currentTime - lastHeartbeatTime;
double phi = calculatePhi(elapsedTime);
return phi >= PHI_THRESHOLD;
}
/**
* 添加心跳间隔样本
*
* @param interval 心跳间隔毫秒数
*/
private void addIntervalSample(long interval) {
if (heartbeatIntervals.size() >= MAX_SAMPLE_SIZE) {
heartbeatIntervals.removeFirst();
}
heartbeatIntervals.add(interval);
}
/**
* 重新计算均值与方差
*/
private void recalculateStatistics() {
if (CollectionUtils.isEmpty(heartbeatIntervals)) {
meanInterval = 0;
variance = 0;
return;
}
// 计算均值
double sum = 0;
for (Long interval : heartbeatIntervals) {
sum += interval;
}
this.meanInterval = sum / heartbeatIntervals.size();
// 计算方差
double varianceSum = 0;
for (Long interval : heartbeatIntervals) {
double diff = interval - meanInterval;
varianceSum += diff * diff;
}
this.variance = varianceSum / heartbeatIntervals.size();
}
/**
* 计算phi值
* phi = -log10(存活概率)
*
* @param elapsedTime 距离上次心跳的时间
* @return phi值
*/
private double calculatePhi(long elapsedTime) {
double standardDeviation = Math.max(Math.sqrt(variance), MIN_STANDARD_DEVIATION_MILLIS);
double normalizedDiff = (elapsedTime - meanInterval) / standardDeviation;
double survivalProbability = calculateNormalDistributionCDF(normalizedDiff);
return -Math.log10(survivalProbability);
}
/**
* 计算正态分布累积分布函数
* 使用Hastings近似算法
*
* @param x 标准化变量
* @return 累积概率
*/
private double calculateNormalDistributionCDF(double x) {
if (x < 0) {
return 1 - calculateNormalDistributionCDF(-x);
}
double t = 1.0 / (1.0 + 0.2316419 * x);
double b1 = 0.319381530;
double b2 = -0.356563782;
double b3 = 1.781477937;
double b4 = -1.821255978;
double b5 = 1.330274429;
double probability = 1.0 - Math.exp(-x * x / 2.0) * t
* (b1 + t * (b2 + t * (b3 + t * (b4 + t * b5)))) / Math.sqrt(2 * Math.PI);
return Math.max(probability, 1e-15);
}
}三、故障隔离:防止雪崩的核心防线
故障隔离是容错体系的核心,其底层逻辑来自《Release It!》提出的舱壁模式:如同邮轮的水密舱,将系统的资源与业务域划分为独立的故障域,单个故障域的故障只会耗尽自身的资源,不会扩散到整个系统,从根本上避免分布式雪崩。
3.1 故障隔离的核心维度
- 资源隔离:为不同的业务、依赖服务分配独立的资源池(线程池、连接池、内存),避免单个依赖故障耗尽整个服务的资源。
- 业务隔离:核心业务与非核心业务拆分,使用独立的集群、数据库实例,非核心业务故障不会影响核心交易链路。
- 部署隔离:服务实例跨机房、跨可用区部署,单个机房/可用区故障不会导致服务整体不可用。
- 数据隔离:核心数据与非核心数据分库分表存储,避免单表故障影响整个数据库的可用性。
3.2 核心隔离模式的底层逻辑与区分
3.2.1 线程池隔离 vs 信号量隔离
这是服务间调用最常用的两种隔离模式,二者的适用场景与能力边界完全不同,必须根据业务场景精准选型:
| 特性 | 线程池隔离 | 信号量隔离 |
|---|---|---|
| 隔离方式 | 为每个依赖分配独立的线程池,业务线程与执行线程分离 | 为每个依赖分配独立的信号量计数器,与业务线程共用同一线程 |
| 线程切换 | 存在线程上下文切换,有固定性能开销 | 无线程切换,性能开销极低 |
| 超时控制 | 原生支持独立的超时时间配置,可主动中断超时请求 | 无原生超时控制,仅能依赖调用方的超时机制 |
| 异步支持 | 原生支持异步调用 | 不支持异步调用 |
| 适用场景 | 外部服务依赖、IO密集型调用、需要精准超时控制的场景 | 内部服务依赖、CPU密集型调用、高并发低延迟的核心链路 |
3.2.2 隔离 vs 熔断:易混淆点明确区分
很多开发者会将隔离与熔断混为一谈,二者是互补但完全不同的容错机制:
- 隔离是事前静态防御:在架构设计阶段,通过划分资源池、拆分故障域,提前限制每个依赖的资源上限,从根源上避免故障扩散,是主动的、预防性的设计。
- 熔断是事后动态止损:当依赖的故障指标(异常率、超时率)达到预设阈值时,主动切断对该依赖的流量调用,避免故障持续放大,是被动的、补救性的控制。
生产环境中,二者必须结合使用:隔离是基础,熔断是隔离的补充,形成完整的故障防护体系。
3.2.3 熔断模式的状态机原理
熔断模式的核心是状态机流转,包含三个核心状态,完整的流转流程如下:
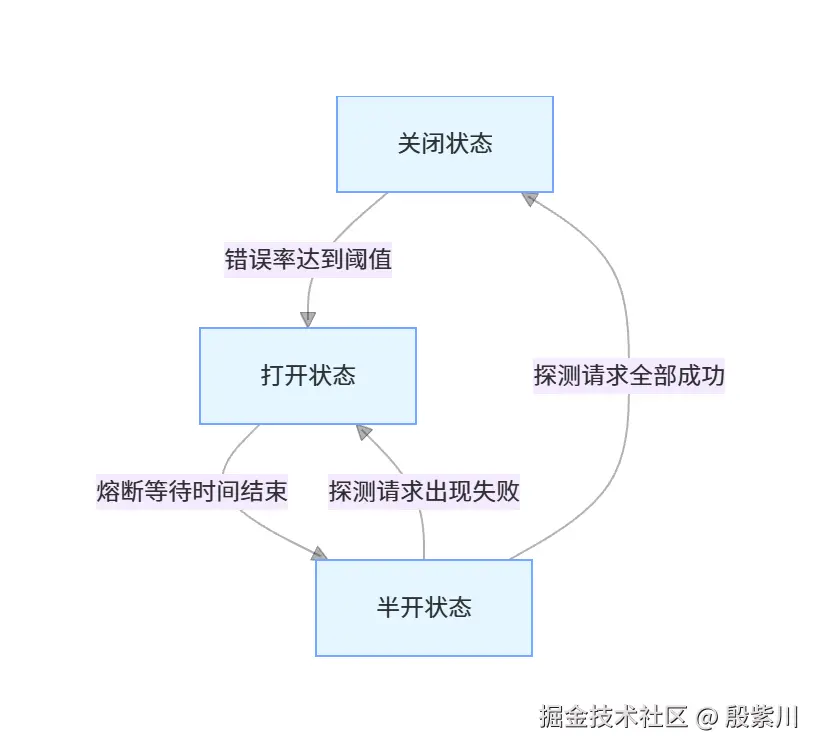
- 关闭状态:流量正常调用,熔断器持续统计请求指标,未达到阈值时保持关闭。
- 打开状态:错误率达到阈值,熔断器打开,直接拒绝所有请求,执行降级逻辑。
- 半开状态:熔断等待时间结束后,熔断器进入半开状态,放行少量探测请求,验证依赖服务是否恢复。若探测请求全部成功,切换回关闭状态;若出现失败,重新切换回打开状态。
3.3 故障隔离生产级实现
3.3.1 Resilience4j隔离与熔断配置
arduino
resilience4j:
bulkhead:
configs:
default:
max-concurrent-calls: 50
max-wait-duration: 10ms
instances:
payment-service:
base-config: default
max-concurrent-calls: 30
user-service:
base-config: default
max-concurrent-calls: 100
thread-pool-bulkhead:
configs:
default:
core-thread-pool-size: 10
max-thread-pool-size: 20
queue-capacity: 50
keep-alive-duration: 1000ms
instances:
third-party-pay:
core-thread-pool-size: 5
max-thread-pool-size: 10
queue-capacity: 20
circuitbreaker:
configs:
default:
sliding-window-size: 100
sliding-window-type: COUNT_BASED
failure-rate-threshold: 50
minimum-number-of-calls: 10
wait-duration-in-open-state: 5000ms
permitted-number-of-calls-in-half-open-state: 5
record-exceptions:
- java.lang.Exception
instances:
payment-service:
base-config: default
failure-rate-threshold: 30
wait-duration-in-open-state: 3000ms
retry:
configs:
default:
max-retry-attempts: 3
wait-duration: 500ms
enable-exponential-backoff: true
exponential-backoff-multiplier: 2
retry-exceptions:
- java.net.SocketTimeoutException
- java.net.ConnectException
instances:
user-service:
base-config: default
max-retry-attempts: 23.3.2 线程池隔离与熔断业务实现
kotlin
package com.jam.demo.service;
import com.jam.demo.entity.PaymentRequest;
import com.jam.demo.entity.PaymentResult;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import io.github.resilience4j.retry.annotation.Retry;
import io.github.resilience4j.threadpoolbulkhead.annotation.ThreadPoolBulkhead;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.concurrent.CompletableFuture;
/**
* 支付服务-故障隔离与熔断实现
*
* @author ken
*/
@Slf4j
@Service
public class PaymentService {
/**
* 第三方支付调用
* 整合线程池隔离、熔断、重试机制
*
* @param request 支付请求参数
* @return 支付结果异步回调
*/
@ThreadPoolBulkhead(name = "third-party-pay")
@CircuitBreaker(name = "payment-service", fallbackMethod = "paymentFallback")
@Retry(name = "payment-service")
public CompletableFuture<PaymentResult> doPayment(PaymentRequest request) {
log.info("开始处理支付请求,订单号:{}", request.getOrderNo());
// 第三方支付接口调用逻辑
PaymentResult result = callThirdPartyPay(request);
return CompletableFuture.completedFuture(result);
}
/**
* 支付失败降级方法
*
* @param request 支付请求参数
* @param e 异常信息
* @return 降级支付结果
*/
private CompletableFuture<PaymentResult> paymentFallback(PaymentRequest request, Exception e) {
log.error("支付服务触发降级,订单号:{},异常信息:", request.getOrderNo(), e);
PaymentResult fallbackResult = new PaymentResult();
fallbackResult.setOrderNo(request.getOrderNo());
fallbackResult.setSuccess(false);
fallbackResult.setMessage("支付通道暂时不可用,请稍后重试");
return CompletableFuture.completedFuture(fallbackResult);
}
/**
* 第三方支付接口调用
*
* @param request 支付请求
* @return 支付结果
*/
private PaymentResult callThirdPartyPay(PaymentRequest request) {
// 第三方支付接口调用实现
PaymentResult result = new PaymentResult();
result.setOrderNo(request.getOrderNo());
result.setSuccess(true);
result.setMessage("支付成功");
result.setPayNo("PAY" + System.currentTimeMillis());
return result;
}
}3.3.3 信号量隔离业务实现
kotlin
package com.jam.demo.service;
import com.jam.demo.entity.UserInfo;
import io.github.resilience4j.bulkhead.annotation.Bulkhead;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* 用户服务-信号量隔离实现
*
* @author ken
*/
@Slf4j
@Service
public class UserService {
/**
* 查询用户信息
* 采用信号量隔离,适配高并发低延迟的内部调用场景
*
* @param userId 用户ID
* @return 用户信息
*/
@Bulkhead(name = "user-service", fallbackMethod = "userInfoFallback")
public UserInfo getUserInfo(Long userId) {
log.info("查询用户信息,用户ID:{}", userId);
// 用户信息查询逻辑
UserInfo userInfo = new UserInfo();
userInfo.setUserId(userId);
userInfo.setUserName("testUser");
userInfo.setUserPhone("13800138000");
return userInfo;
}
/**
* 用户信息查询降级方法
*
* @param userId 用户ID
* @param e 异常信息
* @return 降级用户信息
*/
private UserInfo userInfoFallback(Long userId, Exception e) {
log.error("用户服务触发降级,用户ID:{},异常信息:", userId, e);
UserInfo fallbackUser = new UserInfo();
fallbackUser.setUserId(userId);
fallbackUser.setUserName("未知用户");
return fallbackUser;
}
}四、故障恢复:容错体系的闭环能力
故障恢复是容错体系的最后一环,核心目标是让系统在无人干预的情况下,自动从故障中恢复,回到正常的服务状态,形成完整的容错闭环。故障恢复的核心前提是无状态设计:无状态的服务实例可以随时重启、扩缩容,不会丢失业务数据,是自动恢复的基础。
4.1 故障恢复的核心模式
4.1.1 自动重试:瞬时故障的最优解决方案
自动重试针对网络抖动、超时等瞬时故障,通过重新发起调用恢复业务正常执行,是成本最低、最常用的恢复手段。但重试必须遵循严格的规范,否则会引发重试风暴,彻底打崩下游服务,造成更大范围的故障。
重试的核心规范:
- 仅针对瞬时故障重试:仅对超时、网络异常等可恢复的故障重试,参数错误、权限不足等业务异常重试无效,绝对不能重试。
- 必须保证幂等性:所有可重试的接口,必须实现严格的幂等性,避免重试导致数据重复、资损等问题。
- 必须设置退避策略:采用固定间隔、指数退避等退避策略,避免重试请求集中爆发,引发重试风暴。
- 必须设置上限:严格限制最大重试次数、最大重试总时长,避免无限重试。
4.1.2 幂等设计:重试与重复请求的基础保障
幂等性的核心定义:同一个请求,执行一次与执行多次的业务结果完全一致。它是所有分布式系统的基础能力,不仅是重试的前提,也是重复提交、异步消息、分布式事务的核心保障。
生产环境主流的幂等实现方案,按适用场景可分为:
- 唯一索引:数据库层面的终极幂等保障,通过业务唯一键(如订单号、请求流水号)建立唯一索引,重复插入会触发唯一键冲突,避免数据重复。
- 幂等表:专门的幂等记录表,记录请求的唯一标识,业务执行前先查询记录是否存在,存在则直接返回结果,不存在则执行业务,执行完成后插入幂等记录。
- 乐观锁 :基于版本号机制,通过
UPDATE table SET xxx=xxx, version=version+1 WHERE id=? AND version=?实现,仅当版本号匹配时更新成功,避免并发更新导致的数据不一致。 - 状态机约束:基于业务状态流转,比如订单只有待支付状态才能执行支付操作,已支付的订单无法再次支付,通过业务状态的不可逆性实现幂等。
4.1.3 其他核心恢复模式
- 数据回滚:针对持久化数据的故障,通过本地事务回滚、Saga补偿事务,恢复数据的一致性。
- 主从切换:针对有状态的中间件(数据库、缓存、消息队列),主节点故障时,自动切换到从节点,保障服务持续可用。
- 流量调度:故障实例被摘除后,负载均衡自动将流量调度到健康实例;单机房故障时,自动将流量切换到同城备用机房。
- 自愈扩缩容:基于监控指标,实例故障时自动重启、重建;负载过高时自动扩容实例,负载过低时自动缩容,实现资源的动态适配。
4.2 故障恢复生产级实现
4.2.1 幂等表MySQL建表语句
sql
CREATE TABLE `idempotent_record` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`request_id` varchar(64) NOT NULL COMMENT '请求唯一标识',
`biz_type` varchar(32) NOT NULL COMMENT '业务类型',
`biz_data` json DEFAULT NULL COMMENT '业务执行结果',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`expire_time` datetime NOT NULL COMMENT '过期时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_request_biz` (`request_id`,`biz_type`),
KEY `idx_expire_time` (`expire_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='幂等记录表';4.2.2 幂等处理核心实现
typescript
package com.jam.demo.service;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.jam.demo.entity.IdempotentRecord;
import com.jam.demo.mapper.IdempotentRecordMapper;
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallback;
import org.springframework.transaction.support.TransactionTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.time.LocalDateTime;
import java.util.function.Supplier;
/**
* 幂等处理服务
*
* @author ken
*/
@Slf4j
@Service
public class IdempotentService {
@Autowired
private IdempotentRecordMapper idempotentRecordMapper;
@Autowired
private TransactionTemplate transactionTemplate;
/**
* 幂等执行业务逻辑
*
* @param requestId 请求唯一标识
* @param bizType 业务类型
* @param expireTime 幂等记录过期时间
* @param bizSupplier 业务执行逻辑
* @return 业务执行结果
*/
public <T> T executeWithIdempotent(String requestId, String bizType, LocalDateTime expireTime, Supplier<T> bizSupplier) {
if (!StringUtils.hasText(requestId) || !StringUtils.hasText(bizType)) {
throw new IllegalArgumentException("请求唯一标识与业务类型不能为空");
}
if (ObjectUtils.isEmpty(expireTime)) {
throw new IllegalArgumentException("幂等记录过期时间不能为空");
}
// 1. 查询幂等记录是否存在
IdempotentRecord existRecord = idempotentRecordMapper.selectOne(
Wrappers.lambdaQuery(IdempotentRecord.class)
.eq(IdempotentRecord::getRequestId, requestId)
.eq(IdempotentRecord::getBizType, bizType)
);
if (!ObjectUtils.isEmpty(existRecord)) {
log.info("请求已处理,直接返回结果,requestId:{},bizType:{}", requestId, bizType);
return JSON.parseObject(existRecord.getBizData(), Object.class);
}
// 2. 编程式事务执行幂等记录插入与业务逻辑
return transactionTemplate.execute(new TransactionCallback<T>() {
@Override
public T doInTransaction(TransactionStatus status) {
try {
// 插入幂等记录,利用唯一索引防重
IdempotentRecord newRecord = new IdempotentRecord();
newRecord.setRequestId(requestId);
newRecord.setBizType(bizType);
newRecord.setExpireTime(expireTime);
idempotentRecordMapper.insert(newRecord);
// 执行业务逻辑
T result = bizSupplier.get();
// 更新业务执行结果
newRecord.setBizData(JSON.toJSONString(result));
idempotentRecordMapper.updateById(newRecord);
return result;
} catch (Exception e) {
status.setRollbackOnly();
// 唯一键冲突,说明并发请求已处理,查询已存在的记录返回
if (e.getMessage().contains("Duplicate entry") && e.getMessage().contains("uk_request_biz")) {
IdempotentRecord concurrentRecord = idempotentRecordMapper.selectOne(
Wrappers.lambdaQuery(IdempotentRecord.class)
.eq(IdempotentRecord::getRequestId, requestId)
.eq(IdempotentRecord::getBizType, bizType)
);
if (!ObjectUtils.isEmpty(concurrentRecord)) {
return JSON.parseObject(concurrentRecord.getBizData(), Object.class);
}
}
log.error("幂等业务执行失败,requestId:{},bizType:{}", requestId, bizType, e);
throw new RuntimeException("业务执行失败", e);
}
}
});
}
}4.2.3 带幂等保障的重试业务实现
less
package com.jam.demo.controller;
import com.jam.demo.entity.OrderRequest;
import com.jam.demo.entity.OrderResult;
import com.jam.demo.service.IdempotentService;
import com.jam.demo.service.OrderService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.time.LocalDateTime;
/**
* 订单控制器-带幂等保障的重试实现
*
* @author ken
*/
@Slf4j
@RestController
@RequestMapping("/order")
@Tag(name = "订单接口", description = "带幂等保障的订单业务处理")
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private IdempotentService idempotentService;
/**
* 创建订单接口
* 基于幂等表实现严格幂等,支持重试
*
* @param requestId 请求唯一标识
* @param request 订单创建请求
* @return 订单创建结果
*/
@PostMapping("/create")
@Operation(summary = "创建订单", description = "带幂等保障的订单创建接口,支持重试")
public OrderResult createOrder(
@Parameter(description = "请求唯一标识", required = true) @RequestHeader("Request-Id") String requestId,
@RequestBody OrderRequest request) {
log.info("收到订单创建请求,requestId:{},订单号:{}", requestId, request.getOrderNo());
// 幂等执行订单创建逻辑,幂等记录24小时后过期
return idempotentService.executeWithIdempotent(
requestId,
"ORDER_CREATE",
LocalDateTime.now().plusHours(24),
() -> orderService.createOrder(request)
);
}
}五、分布式容错全链路架构设计
一套完整的分布式容错体系,必须覆盖从流量入口到数据存储的全链路,形成事前预防、事中检测、事后止损、自动恢复的完整闭环。全链路容错架构如下:

全链路容错的核心设计原则:
- 分层容错:每一层都具备独立的容错能力,不会将故障传递到下一层。
- 故障域最小化:将故障锁定在最小的范围内,避免跨层、跨服务扩散。
- 端到端的可观测:全链路的故障指标、调用链路、日志都可观测,为故障检测、定位、恢复提供数据支撑。
- 默认降级:所有非核心依赖都必须设置降级逻辑,故障发生时,优先保障核心业务可用。
六、生产级最佳实践与踩坑指南
6.1 故障检测最佳实践
- 必须采用多层级检测结合的方案,资源级+进程级+实例级+接口级,避免单一检测维度的盲区。
- 应用层心跳必须与业务逻辑复用同一个线程池,否则无法检测到线程池满的故障,出现心跳正常但业务完全不可用的情况。
- 故障判定必须设置连续失败次数,不能单次失败就判定为故障,避免网络抖动导致的误判。
- 深度健康检查必须覆盖核心依赖,不能仅返回200状态码,必须验证数据库、缓存、核心业务表的可用性。
6.2 故障隔离最佳实践
- 核心业务与非核心业务必须彻底隔离,使用独立的线程池、集群、数据库实例,非核心业务故障绝对不能影响核心交易链路。
- 强依赖与弱依赖必须明确区分,弱依赖必须设置降级逻辑,故障时直接跳过,不影响主流程。
- 线程池隔离的参数必须基于压测结果设置,不能拍脑袋,队列长度不宜过长,避免请求排队时间超过业务超时时间。
- 熔断阈值必须基于线上真实数据设置,同时设置最小请求数,避免少量请求就触发误熔断。
6.3 故障恢复最佳实践
- 所有可重试的接口,必须实现幂等性,没有例外。
- 重试必须设置退避策略、最大重试次数、最大重试时长,绝对不能使用无退避的无限重试。
- 所有故障场景都必须设置回退降级策略,优先返回托底数据,而不是直接抛出异常给用户。
- 故障恢复后必须设置验证机制,比如熔断的半开状态,先放行少量流量验证服务恢复情况,正常后再全量放开,避免二次故障。
6.4 高频踩坑避坑指南
- 坑1:用TCP Keepalive替代应用层心跳,导致应用进程死锁,TCP连接正常但业务完全不可用,流量持续打入引发雪崩。
- 坑2:非幂等接口设置重试,导致重复下单、重复支付等资损问题。
- 坑3:线程池队列设置过长,请求排队时间远超业务超时时间,即使线程池正常,业务也全部超时失败。
- 坑4:无退避策略的重试,引发重试风暴,下游故障时,重试流量将下游服务彻底打崩,故障范围扩大。
- 坑5:健康检查接口无核心依赖验证,实例被判定为健康,但数据库已宕机,业务请求全部失败。
- 坑6:熔断阈值设置过低,少量瞬时错误就触发熔断,导致服务不必要的不可用。
- 坑7:无状态设计不到位,实例重启后数据丢失,无法正常恢复,只能人工介入处理。
七、总结
分布式容错不是一个单点的技术组件,而是一套体系化的架构设计思想。它的核心不是让系统不出故障,而是承认故障是分布式系统的常态,通过全链路的检测、隔离、恢复机制,让系统在故障发生时,能够从容应对,将影响降到最低,保障核心业务的持续可用。
真正的高可用分布式系统,是把容错能力刻进架构的骨子里,而不是靠事后的人工救火。从架构设计的第一天起,就假设每一个依赖都会故障,每一个节点都会宕机,每一次网络调用都会超时,基于这个前提,设计出完整的容错闭环,这才是分布式高可用的核心本质。