每个分区都有副本,这个副本是在创建主题的时候指定的。
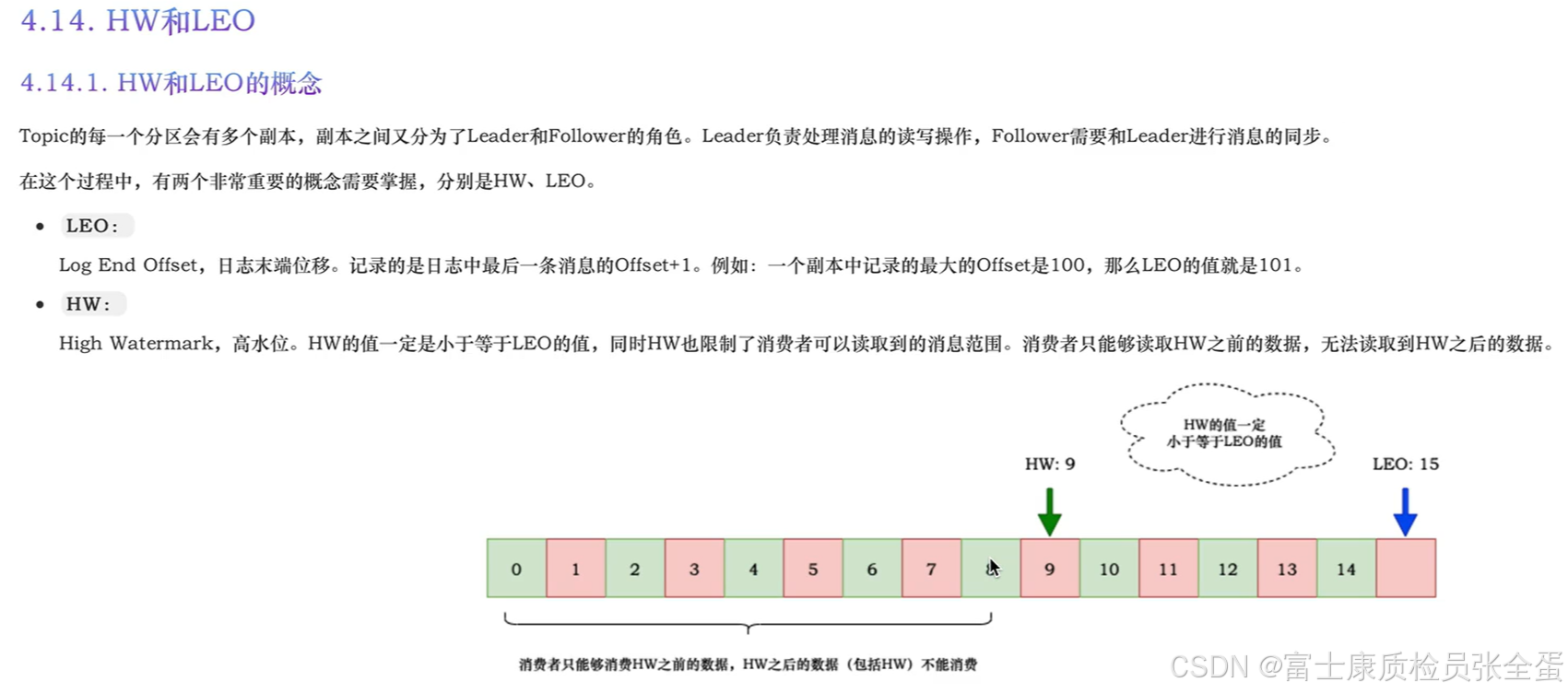
HW限制了消费者可以读取到的数据范围,比如图中hw是9,那么消费者只能读取hw 9之前的数据,也就是只能读取到0-8的数据,至于HW之后的数据,这些数据还没有同步完成。所以这些数据对于消费者来说现在是看不到的,读取不到的,这就是HW的概念。
leo和hw在副本之间进行消息同步的时候他们扮演了什么样的角色?有什么样的作用?也就是在数据同步的时候工作流程是什么?
follower向leader同步数据,那得告诉leader现在的leo是多少,换句话说也就是应该从什么位置返回数据,不可能将分区的所有数据都返回给follower,太多了,网络传输起来不方便,而且收到之后还得截取。
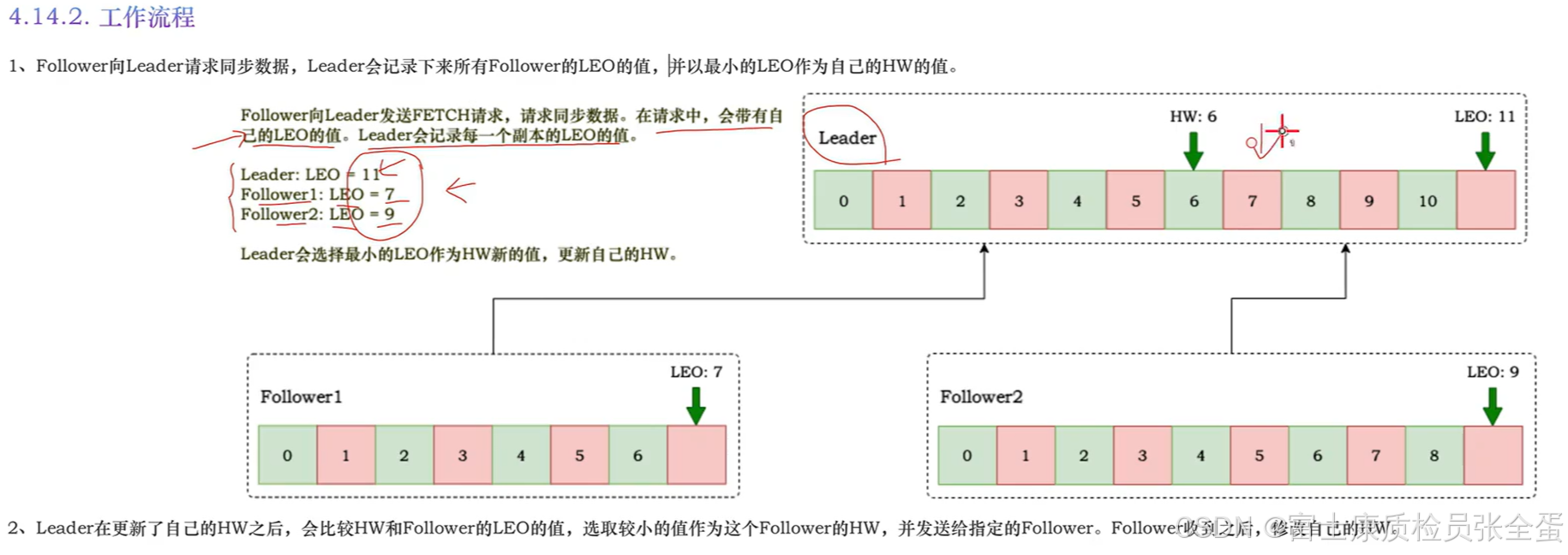
follower1向leader请求数据会告诉leader我的leo是7,那么leader就会找到7以及之后的数据返回。同样follower是leo是9,在请求leader的时候也会告诉leader leo是9。于是leader就会将9之后的数据返回给follower2。所以follower在向leader请求数据同步请求的时候会带上自己leo的值。
带上leo的值leader是可以记录下来的,那么leader会找到follower中leo的最小值,这个最小值就可以作为新的hw的值了。因为leader发现副本中的值已经同步过来了,也就是这条消息在所有的副本中都是存在的,那么消费者就看可以读取这样一条消息了。
leader在更新了自己的HW之后,也就是7,然后告诉其他副本让其将自己的HW更新为7。比如对于follower2来说,他的leo是9,于是leader结合了自己的HW告诉follower2可以将自己HW更新为7。对于所有的副本来说都可以将自己的HW更新为7。
也就是follower和leader之间进行数据同步的时候,它会维护两个这样的变量,应该是HW,另外一个是leo。
为什么要维护这两个变量?因为是要维护异常的情况的。
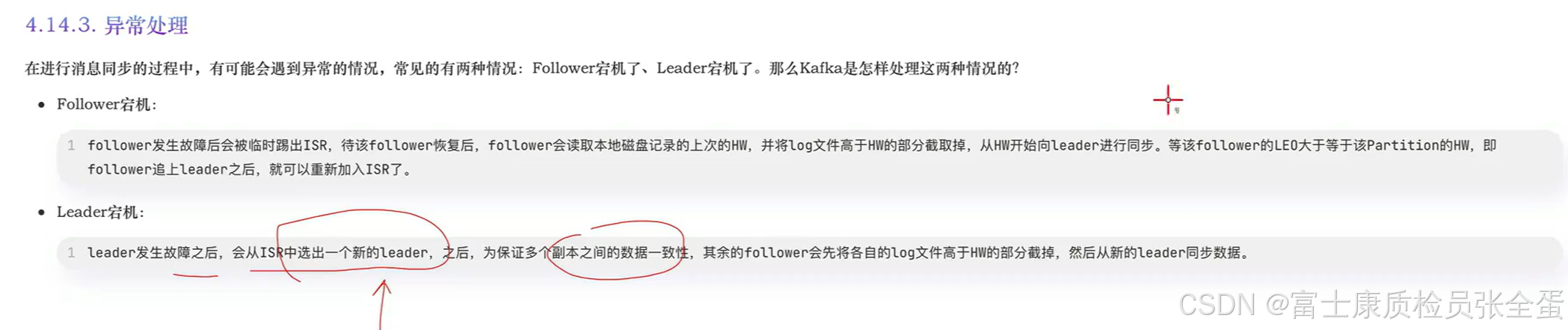
有了leo和hw这两个概念,kafka就可以在副本之间完成消息的同步操作。