为什么你的 AI Agent 总被网站封杀?六条技术路线,只有一条走对了
你让 AI Agent 自动发个帖、采个数据,结果 Playwright 跑了不到五分钟------账号被封了。
你不甘心,换了 Selenium,加了 stealth 插件,改了 webdriver 标记,甚至用上了指纹浏览器。能撑三天。然后平台升级检测,你又回到原点。
这不是你代码写得差。这是整条技术路线就走错了。
市面上给 AI Agent 加"上网能力"的方案,少说有六种。但大多数人一上来就选了最容易上手但最容易被封的那种,然后在反爬军备竞赛里越陷越深。
这篇文章把六条路线全拆给你看------原理、代价、死穴、适合谁。最后你会发现,最好的反爬方案,是根本不需要反爬。
浏览器自动抓取数据的六条路线
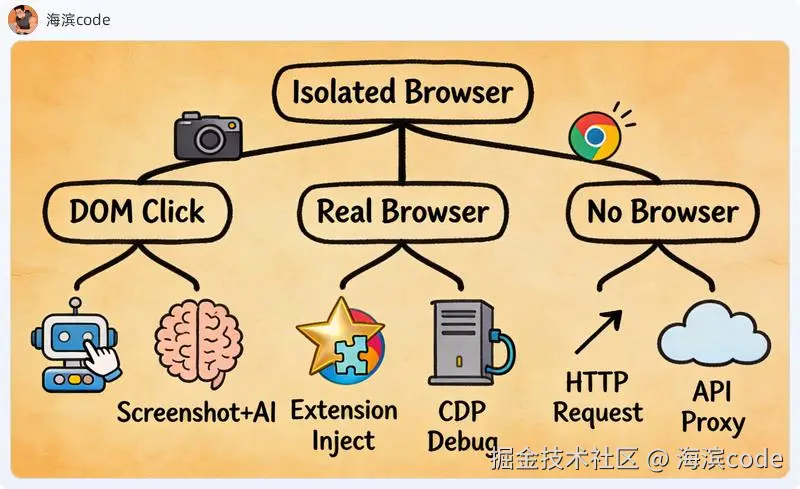
| 路线 | 一句话原理 | 反爬能力 | 速度 | 典型代表 |
|---|---|---|---|---|
| 模拟点击 | 启动独立浏览器,CSS 选择器找元素,模拟鼠标键盘 | ★★☆☆☆ | ★★☆☆☆ | Playwright, Selenium |
| 截图 + AI 视觉 | 截屏发给多模态 AI,AI 判断坐标并操作 | ★★☆☆☆ | ★☆☆☆☆ | Browser Use 类项目 |
| CDP 直连 | Chrome 开调试端口,外部程序通过 WebSocket 控制 | ★★★☆☆ | ★★★☆☆ | Puppeteer 底层协议 |
| Chrome 扩展注入 | 扩展驻留在用户浏览器内,复用真实登录态 | ★★★★★ | ★★★★☆ | 寄生模式方案 |
| 纯 HTTP 请求 | 直接发请求,解析 HTML | ★☆☆☆☆ | ★★★★★ | requests + BeautifulSoup |
| API 代理 | 调第三方代理服务获取数据 | --- | ★★★★☆ | 各种 scraping API |
十五年走了五个弯路
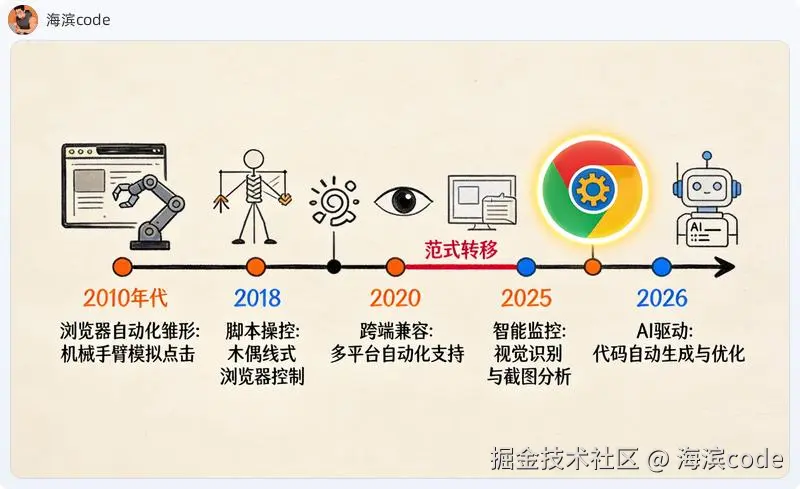
在拆每条路线之前,先看一眼这个领域是怎么走到今天的:
yaml
2010s Selenium 时代------模拟点击是唯一选择
2018 Puppeteer------Chrome CDP 封装,Google 出品
2020 Playwright------跨浏览器 CDP,微软出品
2023 截图+AI 路线兴起------用视觉理解替代 DOM 分析
2024 MCP 协议标准化------浏览器能力接入 LLM 工作流
2025 Chrome 扩展寄生模式成熟------"真实用户"方案落地
2026 AI Agent 自动生成适配器------边际接入成本趋近于零从 Selenium 到 Playwright,本质上是同一条路线在迭代------造一个假浏览器,模拟用户操作。十几年过去了,反爬检测也从"检测一个字段"进化到了"AI 行为分析"。
真正的范式转移发生在 2025 年:有人想明白了,与其造一个假浏览器去骗平台,不如直接把真实的浏览器会话变成 API。
带着这个背景,下面逐条看每条路线的原理和死穴。
路线一:模拟点击------最好上手,也最先被封
这是大多数人的第一选择。Playwright 文档写得好,API 优雅,page.click('#btn') 一行搞定。
但问题出在浏览器本身。
你启动的不是"你的 Chrome",而是一个全新的、干净到可疑的浏览器实例。平台只需要检测三件事:
navigator.webdriver是不是true- 浏览器指纹是不是空白的(没有插件、没有历史、分辨率完美)
- 操作行为是不是机械的(精确到像素的点击、固定间隔的输入)
三条全中,你就是机器人。
说句实在话,stealth 插件能帮你过掉第一条,但第二条和第三条是个无底洞。平台的检测团队也在用 AI,你伪装得越像人,他们检测得越精细。这是一场你注定跑不赢的军备竞赛。
适合 :公开页面抓取、内部测试工具、不需要登录的场景 死穴 :navigator.webdriver=true 一行代码就能识别你
路线二:截图 + AI 视觉------听起来聪明,用起来要命
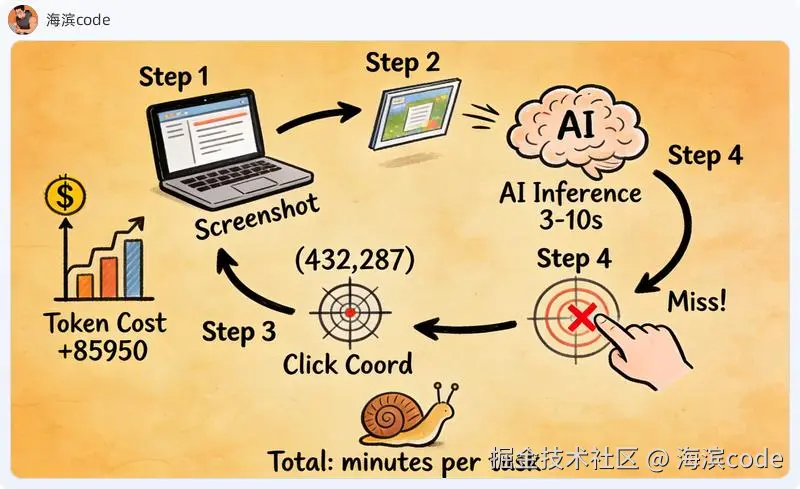
这两年最火的新方向。让 AI "看" 屏幕,自己判断该点哪里。
原理确实漂亮:截屏 → 多模态模型识别 → 输出坐标 → 执行操作 → 再截屏。不需要分析 DOM,不需要写选择器,理论上能操作任何界面。
但你算过账吗?
每一步操作都是一次 AI 推理调用。一个"登录 → 搜索 → 翻页 → 提取"的流程,少说 20 步。每步 3-10 秒的推理时间,加上截图传输,一个完整任务跑下来要好几分钟。如果是 GPT-4o 级别的模型,每步还有几美分的 API 成本。
更要命的是精度问题。AI 说"按钮在坐标 (432, 287)",实际偏了 15 个像素,点到了旁边的链接。在表单填写这种需要精确定位的场景,靠坐标猜测就是在赌运气。
适合 :一次性任务、完全陌生的页面、验证可行性 死穴:100 步操作 = 100 次 API 调用,慢、贵、还不准
路线三:CDP 直连------底层协议,但改变了你的使用习惯
| 维度 | 说明 |
|---|---|
| 原理 | Chrome 启动时带 --remote-debugging-port=9222,外部通过 WebSocket 连接 |
| 控制粒度 | 最细------执行 JS、拦截网络请求、操作 DOM,无抽象层损耗 |
| 核心痛点 | Chrome 必须以调试模式重启,你日常使用的那个 Chrome 要关掉 |
| 反爬表现 | 比模拟点击好一些(连接已有 Chrome 时),但 CDP 连接本身可被检测 |
老实讲,CDP 是 Playwright 和 Puppeteer 的底层发动机。直接用它你能做到最精细的控制------网络拦截、JS 注入、DOM 操作,一个不漏。
但它有个很现实的问题:要求 Chrome 以调试模式启动。
这意味着你日常浏览网页、登录各种账号的那个 Chrome 进程,要么关掉重启带参数,要么你得维护两个 Chrome。对于需要复用登录态的场景,这个操作成本不低。
适合 :开发者工具链、CI/CD 测试、不需要复用日常登录态的场景 死穴:Chrome 必须带调试参数启动,与日常使用习惯冲突
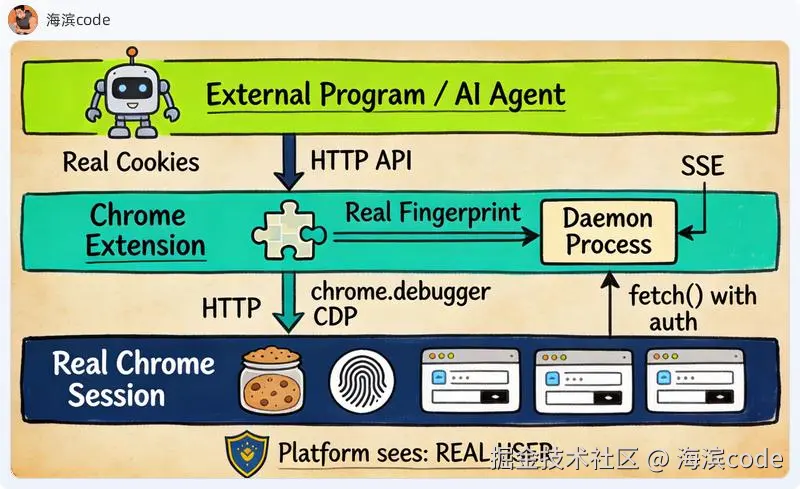
路线四:Chrome 扩展注入------不伪装,因为本来就是真人
前面三条路线有个共同的思路:造一个假浏览器,然后想办法让它看起来像真人。
但换个角度想:你每天打开 Chrome,登录了几十个平台,有完整的 Cookie、浏览历史、插件指纹。为什么不直接把这个真实的浏览器会话变成 API?
Chrome 扩展注入就是这个思路。一个驻留在你浏览器内的扩展,通过 chrome.debugger API 获得 CDP 级别的控制能力,同时能访问所有 Tab 的 Cookie 和页面上下文。
外部程序想操作某个平台?通过中间守护进程把指令传给扩展,扩展在页面内执行 fetch() 请求,直接带上真实的 Cookie 和 CSRF Token。
平台看到的是什么?就是你本人在操作。 因为确实是你的浏览器、你的 Cookie、你的指纹------只不过操作指令来自外部程序。
这里有个关键的分层设计,决定了它能适配多少平台:
| 层级 | 方式 | 说明 |
|---|---|---|
| Tier 1 | 直接带 Cookie 发 fetch() | 最简单,大多数平台适用 |
| Tier 2 | 提取 Bearer/CSRF Token 后注入 | 需要逆向分析请求头 |
| Tier 3 | Webpack 模块注入 / Store 访问 | 调用页面内部未公开的 API |
适合 :需要登录态的重复操作、多平台数据采集、AI Agent 的"手和脚" 死穴:Chrome 必须保持打开状态,无法在无桌面的服务器上运行
这条路线有一个历史门槛:每接入一个新平台,需要逆向分析它的请求结构,写一个专门的适配器。 但 2025-2026 年出现了一个关键变化------AI 能帮你写适配器。给 LLM 一个平台的网络请求抓包,它能分析出认证方式、请求格式、必要的 Header,然后生成适配器代码。人工需要半天到一天的逆向工作,AI 几分钟完成初稿。边际接入成本趋近于零。
路线五和六:纯 HTTP 与 API 代理------能用但局限大
这两条放在一起说,因为它们的逻辑类似:绕过浏览器,直接走网络层。
纯 HTTP 请求适合公开数据、静态页面------速度极快(毫秒级),资源占用几乎为零。但碰到 JS 渲染的 SPA 页面就彻底歇菜,更别提登录态了。
API 代理本质是把脏活交给第三方。你调一个接口,第三方帮你搞定反爬和数据提取。听起来很省事,但你把核心能力交给了别人------第三方挂了你也挂,第三方涨价你只能认。
| 对比 | 纯 HTTP | API 代理 |
|---|---|---|
| 速度 | ★★★★★ 毫秒级 | ★★★★☆ 取决于代理 |
| 成本 | 几乎为零 | 按调用收费 |
| 反爬 | 几乎没有 | 代理帮你处理 |
| 风险 | JS 渲染失效 | 依赖第三方存续 |
适合 :RSS 抓取、公开 API、快速原型 不适合:任何需要登录态或 JS 渲染的场景
反爬的本质:为什么伪装永远跑不赢检测
到这里你应该看出来了:前三条路线的核心思路都是伪装------造一个假浏览器,patch 各种特征,让它看起来像真人。
但反爬检测也在进化。从最早的 navigator.webdriver 检查,到浏览器指纹比对,到行为分析(鼠标轨迹、点击间隔、滚动模式),到现在的 AI 行为识别------检测的维度永远比你能伪装的维度多一个。
| 检测维度 | 模拟点击 | 截图+AI | CDP直连 | 扩展注入 |
|---|---|---|---|---|
| navigator.webdriver | ❌ 暴露 | ❌ 暴露 | ❌ 可能暴露 | ✅ 真实值 |
| 浏览器指纹 | ❌ 空白 | ❌ 空白 | △ 部分真实 | ✅ 完全真实 |
| 行为模式 | ❌ 机械 | ❌ 慢且机械 | ❌ 机械 | ✅ 无 UI 操作 |
| Cookie/登录态 | ❌ 无 | ❌ 无 | △ 需配置 | ✅ 真实登录态 |
第四条路线的思路完全不同:不伪装,因为用的就是真实浏览器。 没有 navigator.webdriver 问题,因为不是自动化启动的;没有指纹问题,因为就是你日常用的那个 Chrome;没有行为模式问题,因为操作走的是内部 API 调用而非 UI 模拟。
最好的反爬方案,是根本没有东西可以被检测。
你该选哪条路线
别急着抄答案,先问自己三个问题:
1. 你的任务需要登录态吗?
- 不需要 → 页面是 JS 渲染的吗?不是就用纯 HTTP,是就用 CDP
- 需要 → 看第二个问题
2. 这个任务是一次性的还是要重复跑?
- 一次性 → 截图 + AI,通用但贵
- 重复跑 → 看第三个问题
3. 你愿意投入多少前期工作?
- 想快速跑通 → 模拟点击(但要接受随时被封的风险)
- 愿意投入一次逆向分析 → Chrome 扩展注入(一次投入,长期稳定)
我的判断:如果你在做 AI Agent 并且需要操作登录态的平台,扩展注入是目前唯一经得起生产环境考验的方案。 模拟点击能快速验证想法,但别指望它能稳定跑。
写在最后
互联网从来不缺数据,缺的是获取数据的正确方式。
我们花了十几年造各种"假浏览器"去骗过网站的检测系统,结果发现最简单的解法一直摆在那里------你每天已经登录了几十个平台,把这些真实的浏览器会话变成可编程的 API,比造一百个假浏览器都管用。
技术的进化往往不是"把旧方案做得更好",而是"换一个完全不同的思路"。
作者:海滨code 10年+码农,曾任某互联网大厂技术专家。常年专注于原生应用和高性能服务器开发、视频传输和处理技术以及AI个人生产力研究。热爱健身,情商为零
公众号:海滨code | 个人主页:haibindev.github.io/,转载请注明作者和出处