一、Spring中new 去哪了?
日常敲代码的时候,我们习惯了在一个类里打上 @Autowired 或者 @Resource,然后就理所当然地调用这个对象的方法。不知道你有没有停下来想过一个问题:在原生的 Java 世界里,想要一个对象,唯一的合法途径就是 new 出来。那 Spring 里的 new 去哪了?为什么它消灭了我们在业务代码里手动 new 对象的权利?
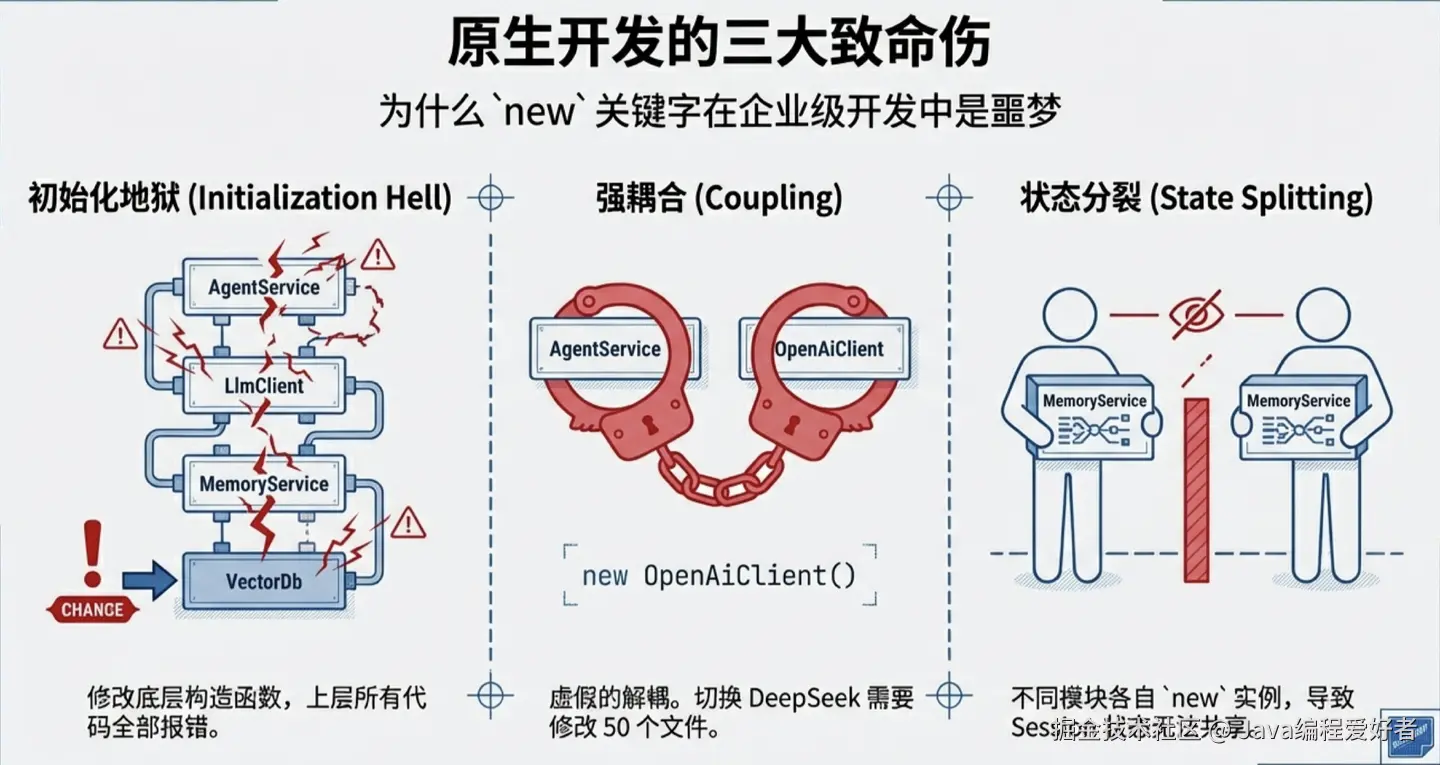
1.1 原生开发的问题
假设你要写一个"Agent 调度引擎",核心是 AgentService。它要能正常工作,必须依赖两个组件:负责调大模型的 LlmClient,以及负责提供上下文记忆的 MemoryService。而这个 MemoryService 底层又必须连着一个向量数据库 VectorDatabase 来做持久化。
如果不按 Spring 的套路,我们回归最原始的 Java 写法,在代码里手动 new,会发生什么?
- 令人绝望的初始化顺序
你想在入口处创建一个 AgentService,代码写出来大概是这样的:
ini
// 必须从最底层的依赖开始,逆向 new 上去
VectorDatabase vectorDb = new MilvusDatabase("localhost", 19530);
MemoryService memoryService = new MemoryService(vectorDb);
LlmClient llmClient = new OpenAiClient("sk-xxxx...");
// 底层零件全备齐了,最后才能拼装出最终的服务
AgentService agentService = new AgentService(llmClient, memoryService);看起来似乎还能接受?但这仅仅是 4 个类。真实的系统里,一个核心 Service 背后可能牵扯几十上百个类的依赖网。只要最底层的 VectorDatabase 的构造函数加了一个鉴权参数,整条调用链上所有手动 new 它的上层代码全部报错,你必须顺藤摸瓜挨个修改,而且完全是无意义的活儿,同时你还要考虑到是当前IDE发展的很好,在Spring还没出来的那个时候,你这样改个代码,怎么找全都是个问题。
- 替换实现的崩溃
老板今天看新闻说 DeepSeek 便宜又好用,我们要支持国产让你把 OpenAI 换掉。这时候,有兄弟可能会拍说了:"这算什么灾难?Java开发的基本功是面向接口编程。我在 AgentService里写 LlmClient llmClient = new OpenAiClient();,左边声明的是接口,这不就解耦了吗?"
错!这只是一种虚假的解耦。 接口确实解决了"多态调用"的问题,但它根本没有解决"对象创建权"的问题。只要你的代码里出现了 new OpenAiClient() 这个确切的类名,你的 AgentService 就被这个具体实现死死绑架了。当你要换成 DeepSeekClient 时,你依然得捏着鼻子打开 AgentService.java 的源码,去修改那行 new 的代码。如果系统里有 50 个地方用到了大模型,你就得改 50 个地方。真正优雅的解耦,是 AgentService 压根不需要知道具体的实现类是谁,只要别人给我一个符合标准的接口就行。
- 运行时状态分裂
这是很多新手最容易忽视,也是实际工作中最致命的一点。
假设 MemoryService 里缓存了一些当前会话的运行时状态。你在 AgentService 里手动 new 了一个 MemoryService,跑着跑着,系统里的另一个模块 ChatHistoryController 也需要查阅记忆,它也顺手 new 了一个 MemoryService。
想想看会发生什么?这两个模块在内存里拿到的根本不是同一个对象。AgentService 往自己那个实例里存的数据,ChatHistoryController 在它自己的实例里根本查不到。在 A 处修改了状态,B 处浑然不知,这种BUG 排查起来能让人怀疑人生。
1.2 解决方案
看完这一地鸡毛,你会发现,让业务类自己去管理对象的创建、依赖顺序和生命周期,是一个极其繁琐,且不符合效率的事情。开发者的精力应该集中到业务的实现,而不是被这些琐碎的事情绊住,
我们需要一个 容器来帮我们管理这些东西。我们和这个容器达成一个协议:
以后代码里再也不许随便 new 了。所有的对象实例,在系统启动的时候,由容器按照配置统一创建好,并且默认只创建一份(单例,解决上面的状态分裂问题) ,存放在容器里面。
谁需要用,只要声明一下(比如加上 @Autowired),容器就会自动把组装好的成品按需塞给你。
在这个机制下,那些不再是散落在代码各处、被随意 new 出来的"野孩子",而是被统一收编、具有标准生命周期、被严格管控的对象,我们就给它起个名字------Bean。
现在我们搞清楚我们为什么要交出 new 的权利。明白了 Bean 存在的原因,接下来,我们就来看看Spring的容器是怎么一步步发展成今天这个样子的。
二、Spring 的演进
既然决定了要把 new 对象的权力交出去,那接下来的问题就是:IoC 容器怎么知道我想要什么对象?又要怎么把它们组装起来?
为了回答这个问题,Spring 走过了三个极其折腾,但也极其顺理成章的阶段。这三个阶段的主线实际只有一个:不断将那些重复性的工作交给框架解决,把开发者的精力彻底释放到业务逻辑上。
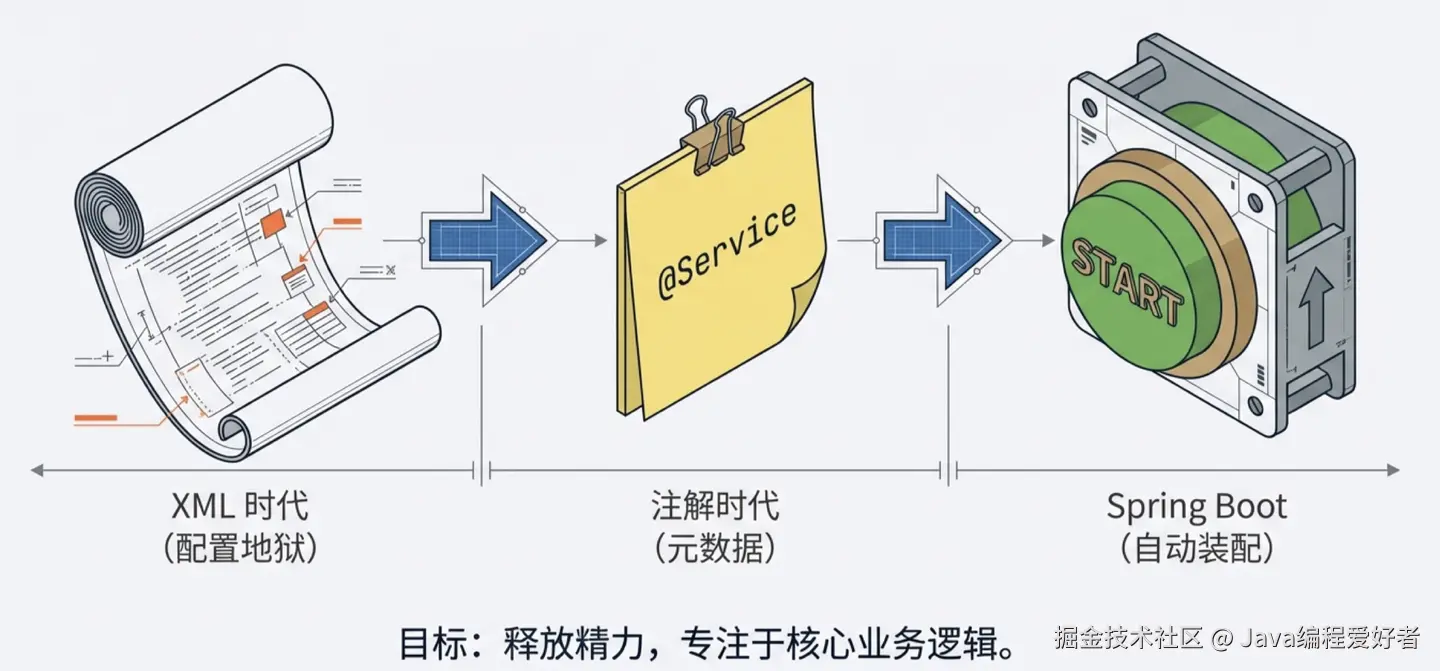
2.1 XML 时代:权力的交接与伪需求的破灭
最早的时候,Spring 的思路很直白:既然不想在 Java 代码里写死依赖,那我们就在外面建一个统一的文件。早期的开发者需要写一份 XML 文件,在里面用 <bean> 标签一行行地告诉容器:给我造一个 AgentService,它的 llmClient 属性对应的是下面那个叫 openAiClient 的 <bean>。
当时这套方法有一个极具迷惑性的卖点:"修改依赖不需要改 Java 代码,改改 XML 就不需要重新编译了!"
技术上这句话是成立的:改外部配置确实不需要重新编译 class。
但在真实的工程实践中,这其实是个伪需求。试想一下,如果你要把底层数据库从 Oracle 换成 MySQL,这种核心变更必然要经过完整的代码提交、CI/CD 构建和全量回归测试。既然无论如何都要重新打包走发布流程,改 XML 和改 Java 代码有什么本质区别?
随着系统变大,XML 动辄几千行,找个依赖关系能在文件里翻瞎眼。为了消灭代码里的强耦合,当年那批程序员掉进了另一个名为"配置地狱"的坑。于是Spring进入了下一个阶段。
2.2 注解时代:元数据与反射的天作之和
痛定思痛,Spring 发现:既然是我自己写的类,干嘛非得到 XML 里再抄一遍名字?并且这个东西鬼一样的长,比如一个简单的类的全限定类名长这样:<bean class="com.yourcompany.ai.agent.core.service.impl.AgentServiceImpl">这东西不仅写起来恶心,更致命的是,一旦你在 IDE 里重构代码、挪动了包的位置,如果不小心漏改了 XML,编译期完全不报错,系统一启动直接崩溃。
很巧啊很巧,Java 5 引入了一个划时代的语言级新特性:注解(Annotation) 。
这里要澄清一个误区:注解并不是 Spring 发明的魔法(其他语言也有类似概念,比如 C# 的 Attribute 或 Python 的装饰器)。Java 官方最初加这个特性,可不是专门为了给 Spring 用的。在那之前,如果你想给一段代码附加一些说明信息(也就是元数据 Metadata,比如告诉框架这个方法是个测试用例,或者这个方法需要开启事务),你只能靠写外部 XML,或者极其别扭的命名约定(比如 JUnit 3 规定测试方法必须以 test 开头)。
Java 引入注解,本质上是为了让代码具备自我描述的能力。它允许你直接把标签贴在源码上,让数据和代码物理绑定在一起。
Spring 敏锐地抓住了这个特性。
它是如何应用的?你在 AgentServiceImpl 类头上贴个 @Service,在属性上贴个 @Autowired。注意,注解本身没有任何执行能力,它真的只是一张静静贴在那里的便利贴。
但这张便利贴,完美解决了 XML 的包名痛点: Spring 容器启动时,会去扫描你指定的包目录。当它看到类头上贴着 @Service 时,它不仅标记 了这个类需要被管理,更重要的是,因为这个注解是直接贴在类文件上的,Spring 可以直接通过底层 API 获取到这个类的完整包名和结构! 拿到包名后,底层的反射机制(Reflection)就可以直接在内存里把这个类动态实例化出来,并放入容器的缓存里。
你再也不用手写那串长长的 com.yourcompany... 了。包名随便改,类随便挪,只要注解还在,容器就能利用反射就能把它造出来。代码与配置真正合二为一,开发效率直接起飞。
2.3 Spring Boot 时代:约定优于配置
发展到这,程序员老哥们还觉得不够简单,每次搭新项目,你依然要手动配一大堆基础设施:扫哪些包、配事务管理器、写各种样板式的配置类。
这时候Spring Boot 横空出世,祭出了约定优于配置的杀手锏。
拿数据库连接来说:在以前,你引入了 MySQL 驱动,还得在代码里一步一步地 new 一个 DataSource,配置连接池,再配置 JdbcTemplate。
而在 Spring Boot 中,你只要在 pom.xml 里引入了数据库相关的 starter 和驱动包。容器在启动时一看:"哎?你引入了 MySQL 驱动,那我就默认你肯定需要连接池,我直接在底层默默帮你把 HikariDataSource 和 JdbcTemplate 这些 Bean 全造好扔进容器里。"你只需要在配置文件里填个账号密码就能直接用。
从 XML 的笨重,到注解的灵活,再到 Boot 的全自动装配,Spring 所有的演进都只为了一件事:让那些和核心业务无关的技术底座(对象的创建、依赖、环境装配)彻底隐形。 只有把开发者的心智负担降到最低,我们才能把全部精力倾注到真正的业务逻辑上。
三、IoC 源码梳理
在正式开始梳理源码之前,三水儿想先讲两句看源码的心法。
很多人学 Spring 源码,一上来就去死记硬背 createBeanInstance、populateBean 这些长串的英文名,过两个月忘得一干二净。为什么?因为你是从结果倒推。
我觉得看源码应该是"带着痛点找解法":假设现在框架由你来写,你会怎么做?遇到了什么死局?你是怎么打补丁的?
今天,我们就假装自己是 Spring 的早期开发者,试着从零开始,一行行把刚才那个 AgentService(依赖 MemoryService)给装配出来。
3.1 V1.0 时代:不就是一个大 Map 吗?
要接管所有的对象,通过一个key获取到它,不就是建一个全局的缓存吗?
系统启动时,我扫一遍代码,只要看到 @Service,我就用反射把它 new 出来,然后丢进一个 Map 里。以后谁要用,直接从 Map 里拿。
typescript
// V1.0 极简版容器
private Map<String, Object> singletonObjects = new ConcurrentHashMap<>();
public Object getBean(String beanName) {
if (!singletonObjects.containsKey(beanName)) {
// 利用反射 new 一个对象
Object bean = Class.forName(className).newInstance();
singletonObjects.put(beanName, bean);
}
return singletonObjects.get(beanName);
}这就是 Spring 源码里一级缓存(singletonObjects 单例池) 的雏形。
看起来是不超简单?别急,继续往下看。
3.2 V2.0 时代:递归组装与 populateBean 的诞生
V1.0 存在的最大的 BUG 在于,它造出来的是个没用的对象。对象有属性、有依赖,不注入就全是 null,一调用就 NPE。
例如:当容器去 new AgentService() 时,它发现里面有个标注了 @Autowired 的 MemoryService 字段。如果你只是简单地 new,这个字段永远是 null,一调程序就报空指针。
于是,我们又给 getBean 方法加了一道核心工序:属性填充(populateBean) 。
typescript
// V2.0 增加了依赖注入的代码
public Object getBean(String beanName) {
// 1. 实例化(造空壳)
Object bean = instantiateBean(beanName);
// 2. 属性填充(塞依赖)
populateBean(beanName, bean);
// 3. 放入单例池
singletonObjects.put(beanName, bean);
return bean;
}
private void populateBean(String beanName, Object bean) {
// 发现 AgentService 需要 MemoryService
// 转身再去调 getBean 去容器里要 MemoryService!
Object dependency = getBean("memoryService");
// 拿到了,反射塞进去
field.set(bean, dependency);
}仔细看 populateBean 里的那句 getBean("memoryService"),这其实是一个完美的递归调用。A 缺 B,就暂停造 A 去造 B;B 造好了塞给 A,A 继续造。
到这里,Spring 已经能处理绝大多数的普通业务逻辑了。
3.3 V3.0 时代:循环依赖
随着业务越来越复杂,又一个bug诞生了。
假设现在 MemoryService 在更新完记忆后,需要调用 AgentService 的状态上报方法。也就是说,MemoryService 里也 @Autowired 了一个 AgentService。
我们拿着 V2.0 的代码走一遍:
- 容器调用
getBean("agentService"),造出 A 的空壳。 - A 开始
populateBean,发现缺 B,调用getBean("memoryService")。 - 容器造出 B 的空壳。
- B 开始
populateBean,发现缺 A,调用getBean("agentService")。 - A 还没造完(还没放进单例池 Map 里),于是容器又去造 A 的空壳...
乓击嘎巴碎!StackOverflowError。我们发现了大名鼎鼎的循环依赖。
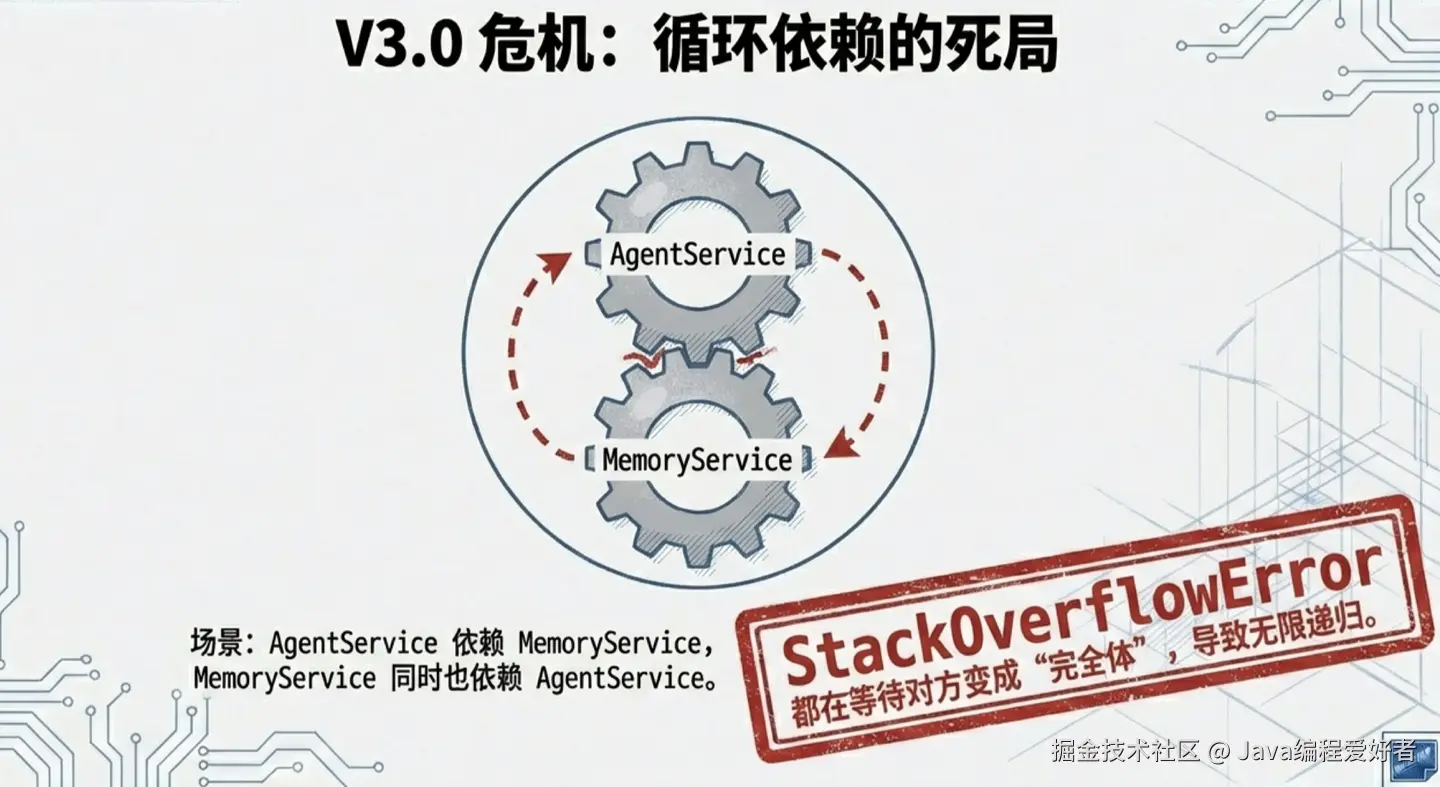
3.4 V4.0 时代:引入半成品缓存
怎么打破这个死循环?Spring 的开发者展现出了极高的工程智慧:既然死锁是因为大家都在等对方变成"完全体",那我就先把"半成品"交出去!
这就好比我们在造两台互相依赖的机器。机器 A 需要连接机器 B 的信号,机器 B 也需要接入机器 A 的底盘。 如果按死理,A 必须等 B 完全造好才能动工,B 也必须等 A 完全造好,那就永远卡死了。
Spring 的解法是:别死等,我先把机器 A 的"空铁壳子"(仅仅是在 JVM 堆里分配了内存地址,但里面的属性全是 null)推过去,你先把这个空壳子用螺丝固定在机器 B 上(B 完成了对 A 早期引用的注入)。
等你机器 B 全部组装好、变成完全体之后,我再回过头来,把机器 A 内部需要的零件(其他属性)一个个塞进刚才那个空铁壳子里。
注意,这里有一个 Java 原生机制:引用传递。 因为 Java 传递的是对象的内存地址,所以 B 当初拿走的那个空壳子,和我后来填满零件的壳子,物理上是同一个东西!只要我这边把 A 的属性一填完,B 肚子里那个原本空荡荡的 A,瞬间就变成了拥有全部属性的完全体。
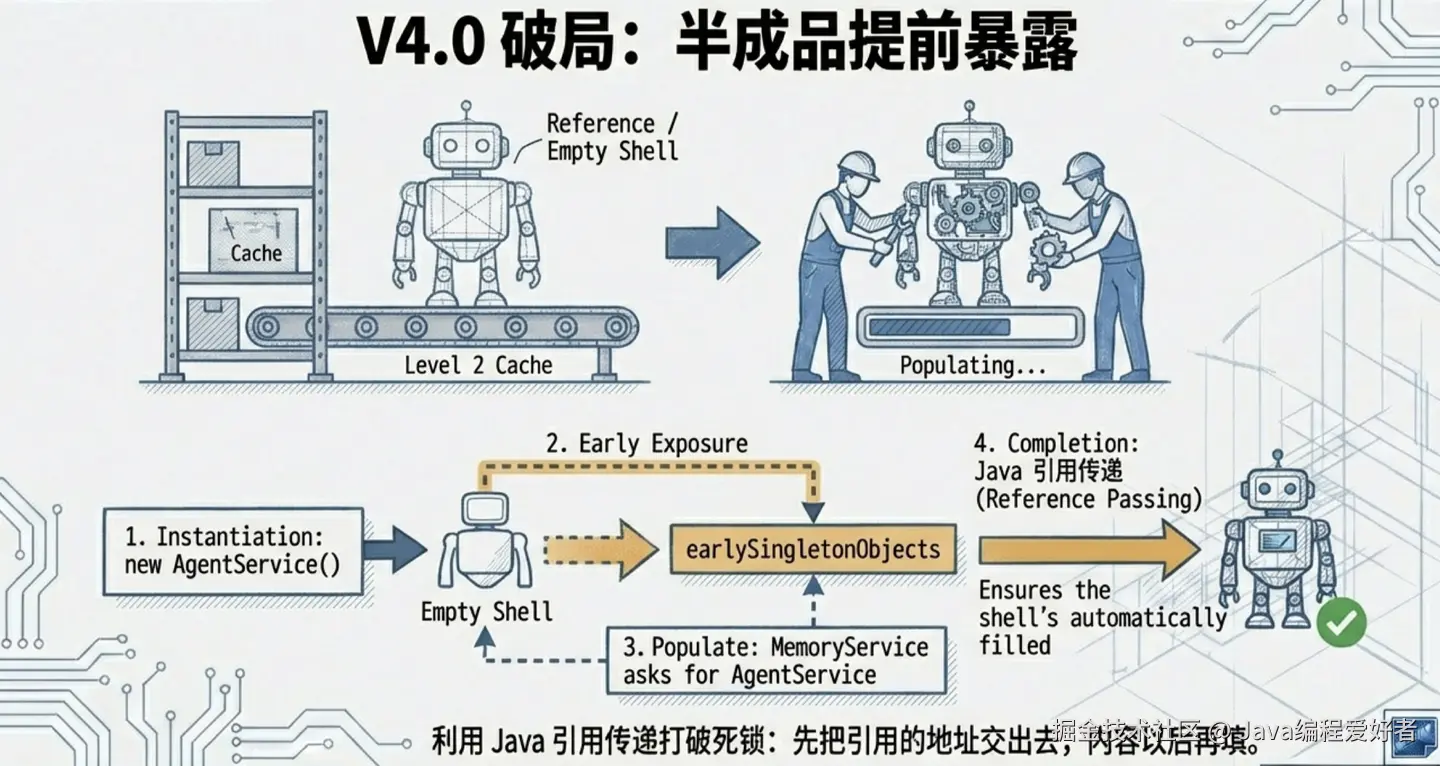
为了实现这个操作,Spring 在一级缓存之外,又加了一个 Map:二级缓存(earlySingletonObjects,专门存早期半成品的引用) 。
我们来看一下一个简单的示例代码:
typescript
// 一级缓存:存放完全体 Bean(日常 getBean 都是从这里拿)
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:存放早期暴露的半成品 Bean(空铁壳子,专门用来破死锁)
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);接着,我们来到 Bean 诞生的核心流水线 doCreateBean 方法:
scss
protected Object doCreateBean(String beanName) {
// 1. 实例化:反射造出一个空铁壳子
Object bean = createBeanInstance(beanName);
// 【破局的灵魂一步】:提前暴露!
// 刚 new 出来,啥属性都没填,直接强行塞进二级缓存!
// 相当于向全系统大喊:我的内存地址已经在这了,谁急用谁先拿去占个位!
earlySingletonObjects.put(beanName, bean);
// 2. 属性填充:开始依赖注入(这里会触发去拿 MemoryService,从而引发递归)
populateBean(beanName, bean);
// 3. 初始化:精加工(执行 @PostConstruct 等)
bean = initializeBean(beanName, bean);
// 4. 收尾:成为完全体后,从二级缓存移除,正式放入一级缓存
earlySingletonObjects.remove(beanName);
singletonObjects.put(beanName, bean);
return bean;
}最后,配合上寻找 Bean 的 getSingleton 方法,循环依赖被彻底打通:
kotlin
public Object getSingleton(String beanName) {
// 先去一级缓存找完全体
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级没有,且发现这个 Bean 正在别的地方创建中(说明发生循环依赖了!)
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 【救命稻草】:去二级缓存拿半成品(空铁壳子)!
singletonObject = this.earlySingletonObjects.get(beanName);
}
return singletonObject;
}现在整个Bean的初始化流程已经基本确立了:
- 实例化(Instantiation) :造出
AgentService的空铁壳子后,立刻把它扔进二级缓存! - 属性填充(populateBean) :A 发现缺 B,去造 B。B 发现缺 A,去缓存里找。
-
一级缓存?没有。
-
二级缓存?找到了 A 的空铁壳子!
- B 毫不犹豫地拿着 A 的空壳引用,塞进自己的肚子里。B 填充完毕,成为完全体,扔进一级缓存。
- 回到 A 的流程,A 从一级缓存里拿到了完全体的 B,塞进自己肚子里。A 也成为完全体,从二级缓存移出,正式放入一级缓存。
重要边界(面试必问)
这套提前暴露机制,默认只解决
单例 + setter/字段注入
-
构造器注入循环依赖:对象都没实例化出来,没法提前暴露
-
prototype 循环依赖:默认也不支持,通常直接报错
3.5 三级缓存:为 AOP 留的后门与下一场的伏笔
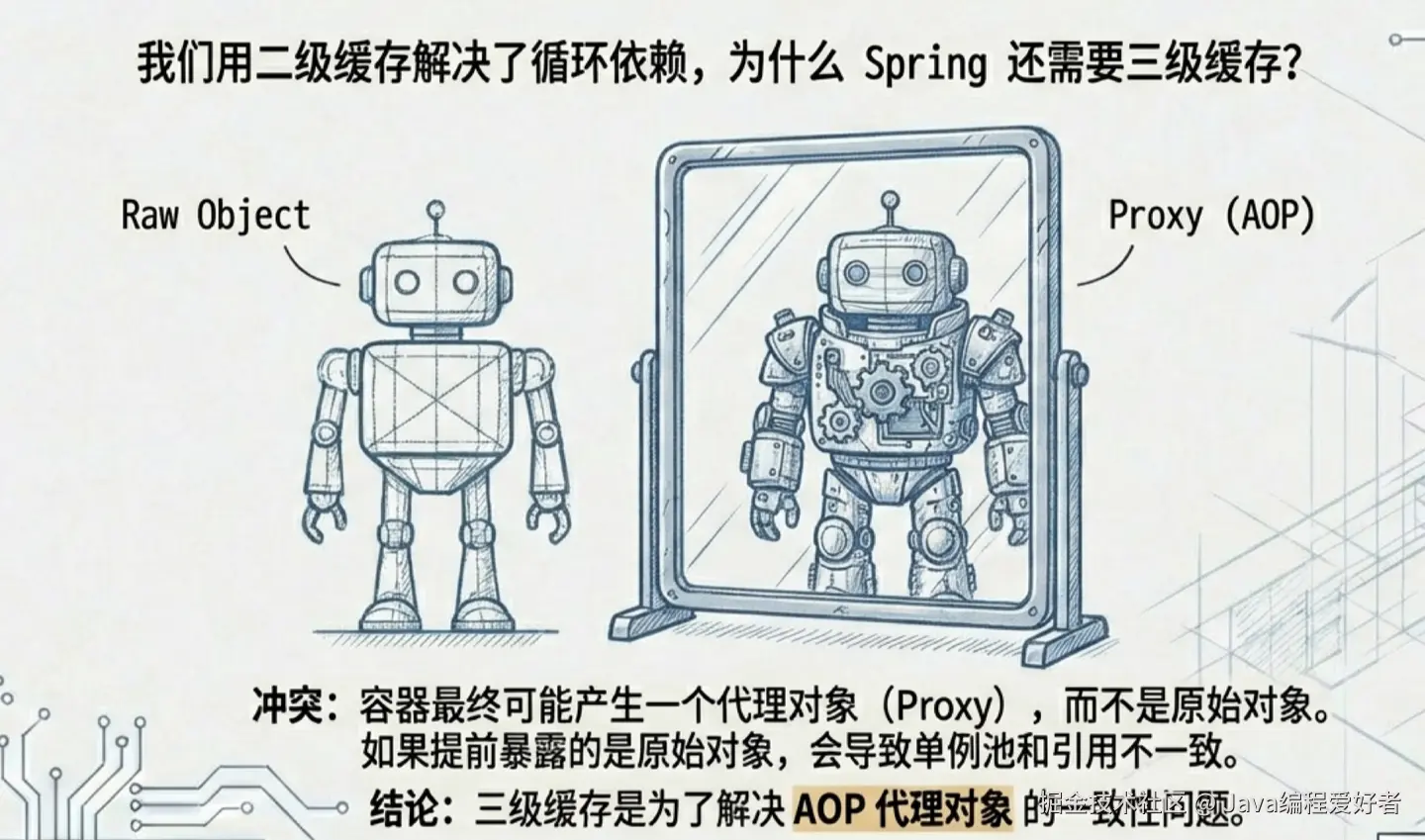
到这里,依赖注入其实已经彻底跑通了。但肯定有兄弟要掀桌子了:"不对啊,我背的八股文里明明说 Spring 是三级缓存啊!怎么被你吃了一级?"
放心,没少。这第三级缓存,是为了解决另一个问题才被迫引入的,AOP 代理导致的"早期引用一致性"。
回到刚才的流水线,Spring 在把对象正式扔进一级缓存之前,其实还偷偷加了最后一道工序:initializeBean()(初始化)。
为什么要加这步?因为我们需要对 Bean 进行再加工,比如执行带有 @PostConstruct 注解的方法。 但更致命的是,Spring 在这里埋下了一个极其深远的伏笔:如果你的 AgentService 头上加了 @Transactional(事务)或者其他切面注解,Spring 就会在这个最后关头,把你原本老老实实造出来的原始 Bean 给扣下,利用 CGLIB 凭空捏造一个代理对象,最终扔进一级缓存的,其实是这个替身!
问题来了:
如果最终给出去的是替身,那前面二级缓存里提前暴露出去的"空铁壳子"是不是就给错了?别人肚子里装的是原始对象,单例池里却是代理对象------单例语义被破坏。
所以需要三级缓存:它不是再放一份对象,而是放 "生成早期引用的能力" (通常表现为 ObjectFactory 之类)。当发生循环依赖又可能需要代理时,容器可以通过这层能力拿到"正确的早期引用"(可能已被增强),避免出现"早期注入原始对象,最终对外是代理对象"的不一致。
这个细节留到下一篇 AOP 专场再细盘------但你现在至少知道:三级缓存不是为了凑数,是被 AOP 逼出来的。
回过头来看看这条演进之路,你再去看源码里那些又臭又长的方法名,是不是不再觉得像天书了,反而像是在看一部系统架构的进化史? 所有的复杂底层设计,从来不是哪位大神拍脑袋想出来炫技的,全都是被真实的工程痛点一步步改进出来的。
同样,那些曾经让我们痛苦不堪、只能死记硬背的面试题,其实也是从这些痛点里演化出来的。