检索增强生成技术RAG
作为一名前端开发人员,在AI席卷的这几年,越来越能明显的感觉到AI在代码生成方面,有着日新月异的变话,AI技术也是层出不穷,隔段时间就会出来新的技术,本次来了解一下AI层面常用到的一个技术 RAG,尝试来寻找一些可以在工作中有帮助的思路方向
什么是RAG?
1.1 基本概念
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索技术与生成式大语言模型(LLM)相结合的人工智能框架。它通过从外部知识库中检索相关信息,并将其作为上下文输入给LLM,从而显著提升模型在知识密集型任务中的表现。
1.2 RAG的核心价值
1.2.1 LLM的不足
使用大模型时,对于一些不在模型训练数据中的信息,模型回答是无法作出精准判断的,即使回答了,可能也是错误的结论,也就是常说的"幻觉",当模型用于外部一些通用场景的时候,还可以使用其他技术让模型在外网自主搜索内容进行生成总结,但是在内网环境,或者信息存在壁垒的场景,比如,面向公司内部研发的机器人,这个问题会严重影响用户的体验
总结LLM的不足
- LLM是基于"预训练"的的数据进行训练,对于新的数据,LLM是无法参考回答的
- LLM无法基于非公开的数据进行参考回答
- 对于LLM不知道的数据,在回答的时候通常会"胡说八道",也就是"幻觉"
面对这类问题,需要对模型进行额外的信息穿透,主要有两种方式
- 微调:就是在预训练的模型上,使用特定的数据,专业的领域的知识,进行进一步训练,让模型在特定领域的表现更好
- RAG:从外部知识库检索一些相关的信息提供给LLM,让他可以获取一些专业知识喂到上下文,私有数据进行回答
1.2.2 微调 VS RAG
举个例子
比如拿一本从来没看过的书
微调会把这本书的知识嵌入到模型内部中,模型会深入理解相应的知识点以及图谱关系等
而RAG相当于给你一本书做参考资料,进行"开卷回答",回答的质量决定参考片段与问题本身的关键度
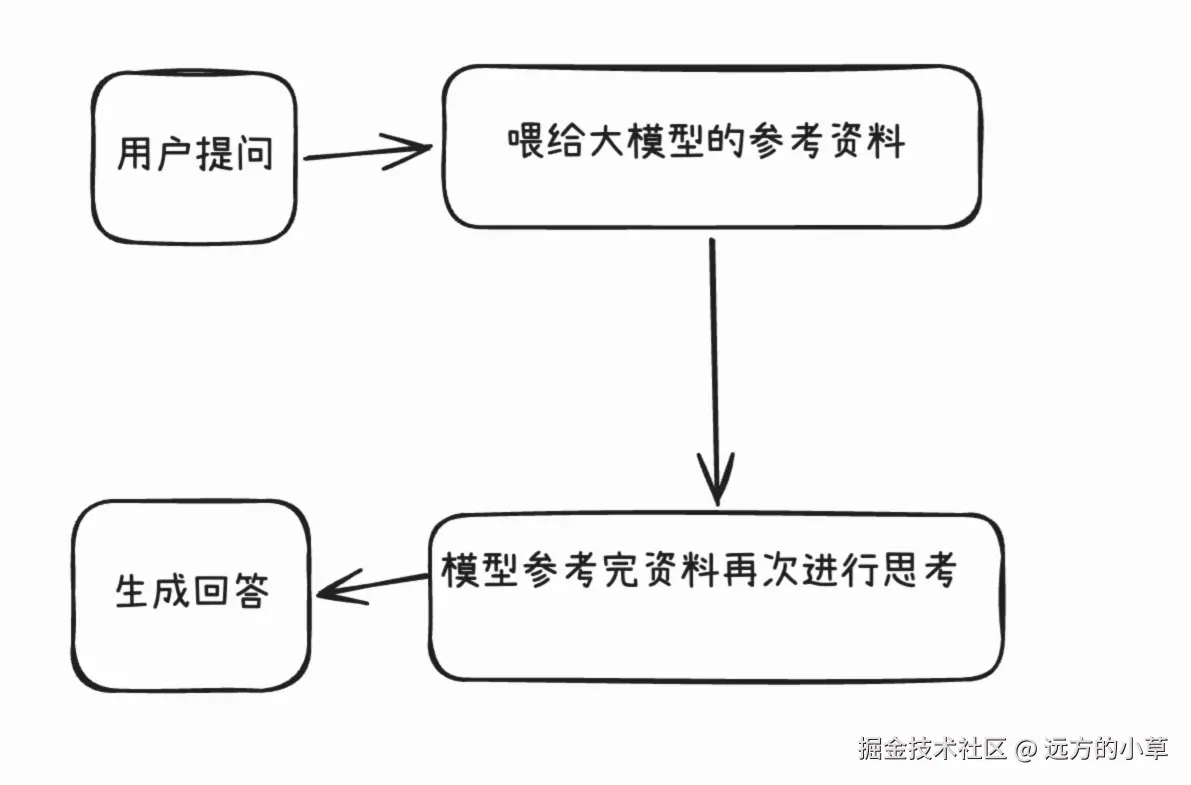
由于微调是内化知识到大模型,所以最终效果是最好的,
但是微调需要有过高的成本投入
- 时间和人力成本比较高:需要对大量的数据进行清洗标注训练,
- 经济成本较高:训练需要较高的算力,
- 实现难度比较高:需要专业的AI知识
相比之下上面三个微调的缺点,就是RAG的优点,对于一些中小企业来说,RAG或许是更好的选择
RAG的应用场景
RAG 的应用范围非常广泛,以下是一些典型场景
- 智能客服:在企业客服系统中,RAG 可以根据用户问题从产品手册或 FAQ 中检索相关信息,并生成自然语言回答。
- 知识库问答:在内部知识管理系统中,RAG 可以帮助员工快速查找文档并生成总结或答案。
- 法律与合规:在法律咨询场景中,RAG 可以检索最新的法规和案例,生成符合事实的建议。
- ......
这些场景通常需要处理大量的外部知识,而 RAG 的动态检索能力使其成为理想的选择。
工作流程
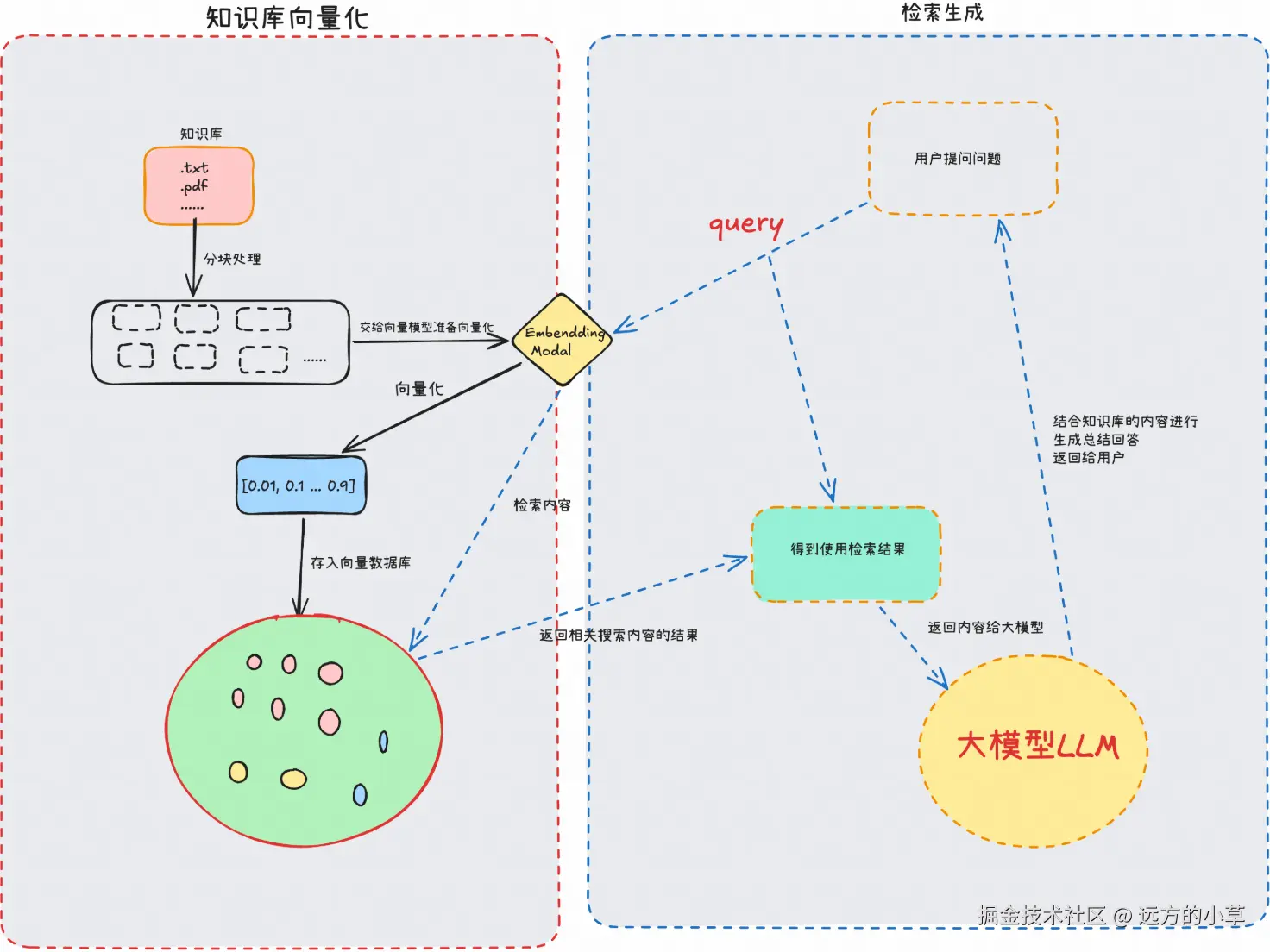
知识库(Knowledge Base)
知识库是RAG的数据源,包含了可检索的信息,可以的形式是
- 文本文档:比如txt,pdf
- 数据库
- 网页内容
- 企业数据:比如产品手册
检索模块(Retriever)
检索器根据用户提问的问题从知识库从查找相关的内容,通常有两种检索技术
- 基于关键词的检索:比如ES,使用关键字匹配查找相关文档
- 基于语义的检索:使用嵌入模型(Embedding Model)将查询内容和文档转换为向量,通过向量相似度进行查找相关的文档
嵌入模型(Embedding Model)
用于将查询内容和文档转换为高维度的向量,这些向量捕捉了文本的语义信息,使得相似的文本在向量空间中更接近
向量数据库(Vector Database)
用于存储和查询文档的向量表示
向量检索技术
向量(Vector)
向量就是同时拥有数值和方向的量
在 RAG里,向量指的是用一串数字表示文本(或图片等)的数学表示。
每一个向量维度代表一个语义,语义相近的文本,对应的向量在空间中会靠得更近。
比如
- 二维向量:0.1,0.2,可以理解为一个有x轴和y轴的平面直角坐标系
- 高维向量:0.02,0.05,...0.03,以此类推,维度越高,在语义检索中精度就越高
文本向量化(Embedding)
向量化是将非数值数据(如文本、图像或音频)转换为数字向量(一组有序的数字)的过程。
在 RAG 系统中,我们主要关注文本的向量化,即将一段文字(单词、句子或文档)转换为一个高维向量(通常是数百到数千维的数字数组)
类比:你在一家图书馆工作图书馆里有成千上万本书,你需要一种方法快速判断两本书是否内容相似,一种简单的办法是为每本书创建一个"特征清单",比如:
- 包含多少科技词汇?
- 包含多少历史事件?
- 情感是积极还是消极?
如果我们用数字表示这些特征(例如 2, 5, 0.1),每本书就变成了一个向量。通过比较这些向量,我们可以判断两本书的相似性。向量化就是为文本创建这样的"特征清单",但它由计算机自动生成,包含更复杂的语义信息。
为什么需要文本向量化
计算机无法直接理解文本,因为它们处理的是数字。向量化将文本转换为计算机可以处理的数字格式,同时保留文本的语义信息
当我们在检索的时候,可以通过语义相似度比较
打个比方
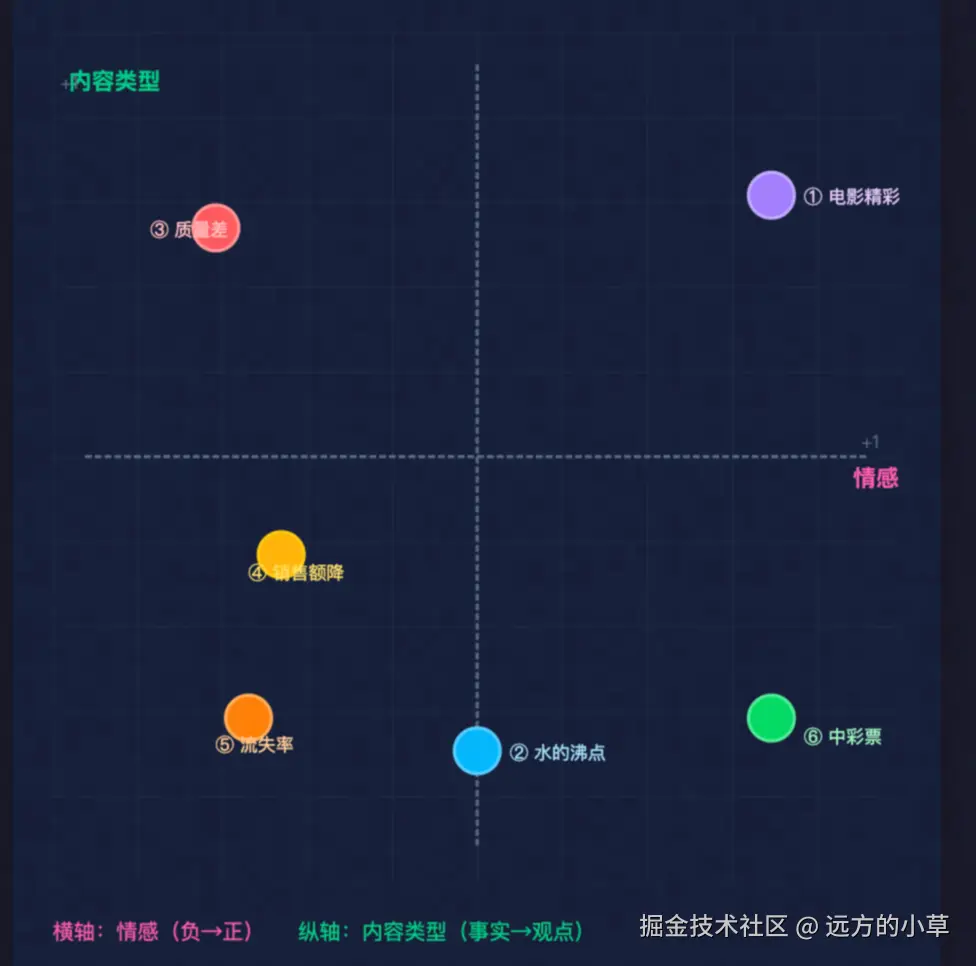
从上图可以看到,相似的文本会被聚集,比如销售额降低(虚拟向量 0.2, 0.3 ... )和流失率增加 0.3, 0.4 ... 在情感方面都偏向负面,且都是事实观点,他们在向量空间里的夹角,相比于中彩票 0.9, 0.02... (情感正向,基于事实)和 质量差 0.1,0.7...(情感负面,基于主观意见)要小很多。
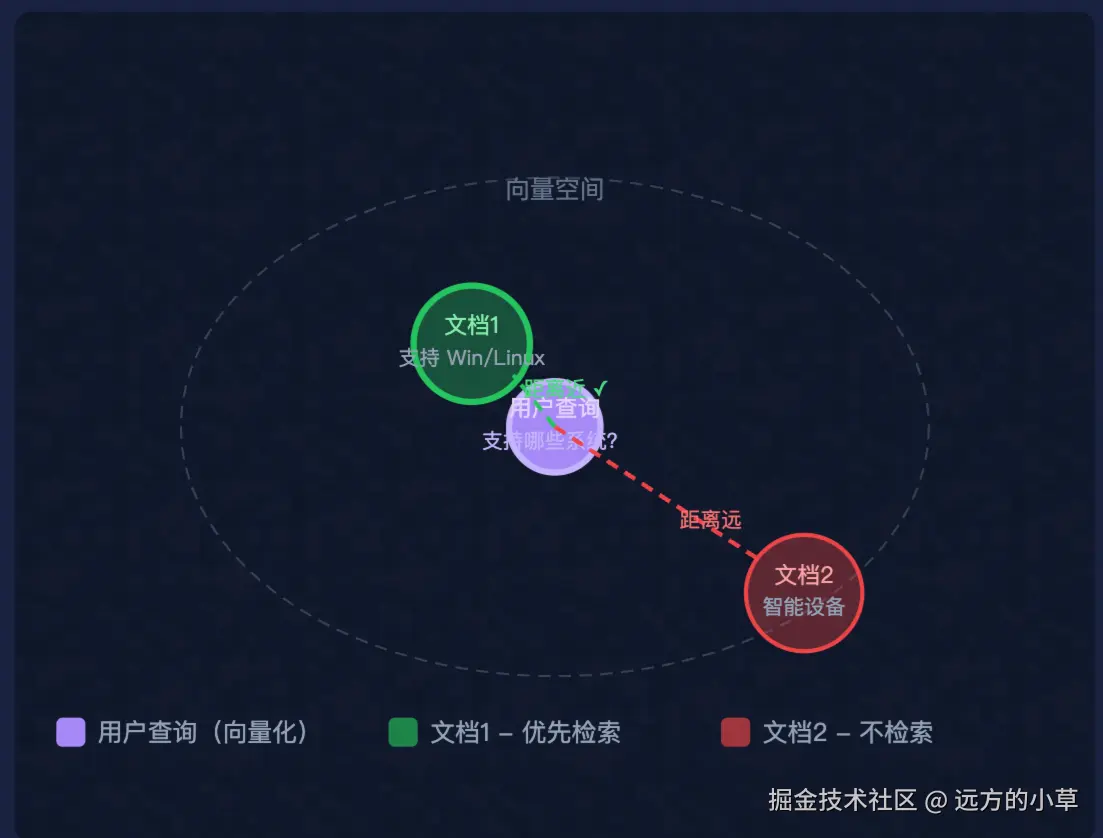
假设知识库中有以下文档:
- 文档 1:"产品支持 Windows 和 Linux。"
- 文档 2:"本产品是一款智能设备。"
用户查询:"产品支持哪些系统?"。与文档1(系统支持哪些系统)语义接近、距离近,与文档2(智能设备)语义无关、距离远 → RAG 优先检索文档1。
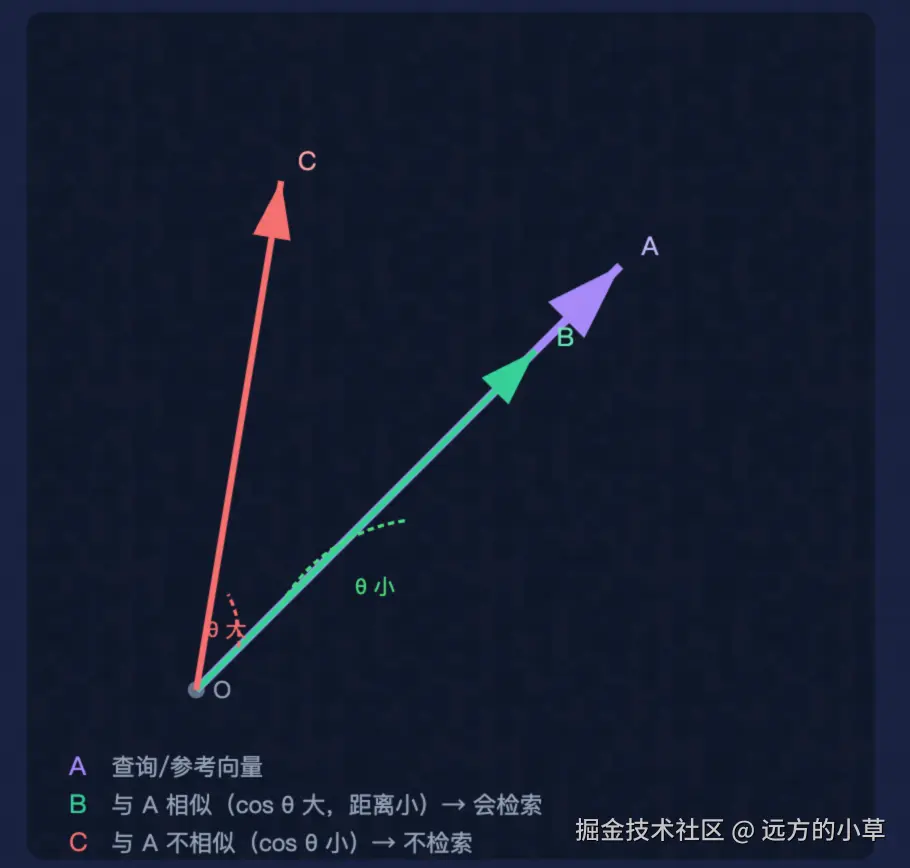
余弦相似度
在RAG检索中,常用余弦相似度算法来匹配语义相似的文本
余弦相似度算法看"方向和夹角"
Top-K
在RAG系统中,检索匹配到相似的结果,需要吧相关的内容返回给大模型,会同时匹配到好几条结果
Top-K = 只保留分数最高的 K 个,把这 K 个文档块交给大模型生成答案。
例如 Top-5:只取相似度排前 5 的 5 条文档,不再用第 6、7、8... 条。
简易RAG项目(用于更好理解RAG)
流程示意图

为了方便,让AI生成相应的代码
arduino
帮我生成一个RAG的简易项目,包括加载.txt文本内容,文本检索,文本转向量,使用qwen3-max大模型,chroma向量数据库,text-embendding-v4向量模型, 框架是 langchain,.txt文本你也帮我生成,主要用于学习RAG代码
python
"""
RAG 简易 Demo(LangChain + Chroma + text-embedding-v4 + qwen3-max)
学习要点:
- 加载 .txt 文档(TextLoader)
- 文本切分(RecursiveCharacterTextSplitter)
- 文本转向量(DashScope text-embedding-v4)
- Chroma 向量库持久化
- 检索 + RAG 生成(qwen3-max)
运行前准备:
1) 安装依赖:pip install -r requirements.txt
2) 配置环境变量:export DASHSCOPE_API_KEY="你的key"
用法:
python index.py --build # 构建索引(先运行一次)
python index.py --ask "你的问题" # 提问
"""
import os
import argparse
from pathlib import Path
from typing import List, Tuple
from dotenv import load_dotenv
load_dotenv()
# -----------------------------
# 配置
# -----------------------------
CHAT_MODEL = "qwen3-max"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
API_KEY = os.getenv("DASHSCOPE_API_KEY")
EMBEDDING_MODEL = "text-embedding-v4"
DATA_DIR = Path(__file__).resolve().parent / "data"
CHROMA_DIR = Path(__file__).resolve().parent / "chroma_db"
CHUNK_SIZE = 800
CHUNK_OVERLAP = 150
TOP_K = 4
USE_MMR = True
# -----------------------------
# 依赖导入
# -----------------------------
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
# -----------------------------
# 工具函数
# -----------------------------
def require_api_key() -> None:
if not API_KEY or not API_KEY.strip():
raise RuntimeError(
"未检测到 DASHSCOPE_API_KEY。请先在终端执行:export DASHSCOPE_API_KEY='你的key'"
)
def load_documents(data_dir: Path) -> List[Document]:
"""从 data_dir 加载所有 .txt 文档。"""
if not data_dir.exists():
raise RuntimeError(f"未找到文档目录:{str(data_dir)}。请创建 data/ 并放入 .txt 文件。")
docs: List[Document] = []
for path in data_dir.rglob("*.txt"):
if not path.is_file():
continue
try:
loader = TextLoader(str(path), encoding="utf-8")
docs.extend(loader.load())
except Exception as e:
print(f"[加载失败] {path.name}: {e}")
for d in docs:
if "source" not in d.metadata:
d.metadata["source"] = d.metadata.get("file_path") or d.metadata.get("path") or "unknown"
return docs
def split_documents(docs: List[Document]) -> List[Document]:
"""将文档切分为 chunks。"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
)
chunks = splitter.split_documents(docs)
for i, c in enumerate(chunks):
c.metadata["chunk_id"] = i
src = c.metadata.get("source", "")
c.metadata["source_name"] = Path(src).name if src else "unknown"
return chunks
def make_embeddings() -> DashScopeEmbeddings:
"""创建 DashScope text-embedding-v4 客户端。"""
return DashScopeEmbeddings(
model=EMBEDDING_MODEL,
dashscope_api_key=API_KEY,
)
def build_and_save_index(chunks: List[Document]) -> None:
"""构建 Chroma 向量库并持久化到 chroma_db/。"""
embeddings = make_embeddings()
CHROMA_DIR.mkdir(parents=True, exist_ok=True)
Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=str(CHROMA_DIR),
)
print(f"[完成] 已保存 Chroma 索引到:{str(CHROMA_DIR)}")
def load_vectorstore() -> Chroma:
"""从 chroma_db/ 加载 Chroma 向量库。"""
embeddings = make_embeddings()
if not CHROMA_DIR.exists():
raise RuntimeError(
f"未找到索引目录:{str(CHROMA_DIR)}。请先运行:python index.py --build"
)
return Chroma(
persist_directory=str(CHROMA_DIR),
embedding_function=embeddings,
)
def make_retriever(vectorstore: Chroma):
"""从向量库创建 retriever。"""
if USE_MMR:
return vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": TOP_K, "fetch_k": max(20, TOP_K * 5)},
)
return vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": TOP_K},
)
def format_context(docs: List[Document]) -> Tuple[str, str]:
"""将检索到的 chunks 格式化为上下文与引用清单。"""
blocks: List[str] = []
cites: List[str] = []
for d in docs:
source = d.metadata.get("source_name", "unknown")
chunk_id = d.metadata.get("chunk_id", "?")
cite = f"{source}#chunk{chunk_id}"
cites.append(cite)
blocks.append(f"[{cite}]\n{d.page_content}")
context_text = "\n\n".join(blocks)
citations_text = "\n".join(f"- {c}" for c in cites)
return context_text, citations_text
def answer_with_rag(query: str) -> None:
"""RAG 主流程:加载索引 -> 检索 -> 生成答案 -> 打印引用。"""
require_api_key()
vectorstore = load_vectorstore()
retriever = make_retriever(vectorstore)
docs = retriever.invoke(query)
context, citations = format_context(docs)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个基于资料回答问题的助手。\n"
"规则:\n"
"1) 只能使用【给定上下文】回答,不要编造。\n"
"2) 如果上下文不足以回答,请直接回答:不知道,并说明缺少哪类信息。\n"
"3) 回答后必须给出引用:用 [source] 的形式列出你用到的片段来源,例如:[xxx.txt#chunk0]。\n"
"4) 用中文回答,尽量简洁、条理清晰。\n",
),
(
"human",
"【给定上下文】\n"
"{context}\n\n"
"【问题】\n"
"{question}\n",
),
]
)
llm = ChatOpenAI(
model=CHAT_MODEL,
temperature=0.2,
api_key=API_KEY,
base_url=BASE_URL,
)
msg = prompt.invoke({"context": context, "question": query})
resp = llm.stream(msg)
print("\n==================== 答案 ====================")
for chunk in resp:
print(chunk.content, end="", flush=True)
print("\n==================== 检索命中(引用清单) ====================")
print(citations if citations.strip() else "(无命中)")
def build_index() -> None:
"""构建索引:加载 data/*.txt -> 切分 -> Chroma 向量化并持久化。"""
require_api_key()
docs = load_documents(DATA_DIR)
if not docs:
raise RuntimeError("没有加载到任何文档。请检查 data/ 目录下是否有 .txt 文件。")
print(f"[加载] 原始文档数:{len(docs)}")
chunks = split_documents(docs)
print(f"[切分] chunks 数:{len(chunks)} (chunk_size={CHUNK_SIZE}, overlap={CHUNK_OVERLAP})")
build_and_save_index(chunks)
def quick_eval() -> None:
"""用几条样例问题做快速自检。"""
questions = [
"什么是 RAG?",
"chunk_size 和 chunk_overlap 分别是什么?",
"Embedding 在 RAG 里起什么作用?",
]
for q in questions:
print("\n\n#############################################")
print("Q:", q)
answer_with_rag(q)
def main() -> None:
parser = argparse.ArgumentParser()
parser.add_argument("--build", action="store_true", help="构建向量索引(先运行一次)")
parser.add_argument("--ask", type=str, default="", help="对本地知识库提问")
args = parser.parse_args()
if args.build:
build_index()
return
if args.ask.strip():
answer_with_rag(args.ask.strip())
return
print("用法:")
print(" python index.py --build")
print(' python index.py --ask "你的问题"')
if __name__ == "__main__":
main()
shell
langchain>=0.3.0
langchain-openai>=0.2.0
langchain-community>=0.3.0
langchain-text-splitters>=0.3.0
langchain-core>=0.3.0
langchain-chroma>=0.1.0
chromadb>=0.4.0
dashscope>=1.20.0
python-dotenv>=1.0.0
arduino
Embedding 与文本切块(Chunk)简介
在 RAG 中,长文档通常会被切成较小的片段,这些片段称为 chunk(文本块)。切块的目的是让检索更精准:每个 chunk 对应一个向量,用户提问时用问题的向量去匹配最相似的若干 chunk,而不是整篇文档。切块时有两个常用参数:chunk_size 表示每个块的大致长度(如按字符数或 token 数),chunk_overlap 表示相邻块之间的重叠长度。overlap 可以避免把一句完整的话从中间切断,让跨块边界的语义也能被检索到。chunk_size 越大,单块上下文越完整,但检索粒度越粗;越小则检索越细,但可能割裂语义,需要根据实际文档和问题类型做权衡。
文本转向量依靠的是 Embedding 模型。Embedding 模型把一段文本映射成一个固定维度的数值向量,语义相近的文本在向量空间中距离更近。这样我们就可以用"向量相似度"(如余弦相似度)来检索与问题最相关的文档块。常见的做法是:用同一个 Embedding 模型分别对文档 chunk 和用户问题进行编码,得到文档向量和查询向量,再在向量数据库(如 Chroma、FAISS)中进行相似度检索,取 top-k 个最相关的 chunk 作为 RAG 的上下文。
arduino
RAG 简介:检索增强生成
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索与大语言模型生成的技术。其核心思想是:在回答用户问题之前,先从外部知识库中检索出与问题相关的文档片段,再把这些片段作为上下文交给大模型,让模型基于"给定资料"来生成答案,而不是仅依赖模型自身记忆。
RAG 的典型流程包括三步:第一步是检索(Retrieval),根据用户问题在向量库或全文索引中查找最相关的文档块;第二步是把检索到的内容拼成一段上下文;第三步是生成(Generation),将"上下文 + 用户问题"一起输入大模型,由模型生成回答。这样既能利用大模型的理解与生成能力,又能保证答案有据可依,减少幻觉。
RAG 适用于知识问答、客服、内部文档助手等场景。当你的知识经常更新、或不想把全部知识都写进模型时,用 RAG 把文档存进向量库,按需检索再生成,是常见且有效的做法。项目结构
bash
├── index.py # 主入口:构建索引 + RAG 问答
├── data/ # 存放 .txt 文档
│ ├── rag_intro.txt # 示例1:RAG 概念与流程
│ └── embedding_chunk.txt # 示例2:Embedding 与 Chunk 简介
├── chroma_db/ # Chroma 持久化目录(运行 --build 后生成)
├── requirements.txt # 依赖列表(可选)
└── README.md # 运行说明(可选)运行
首次运行build会生成向量数据库,用于提问时候的检索
提问"什么是 RAG?"
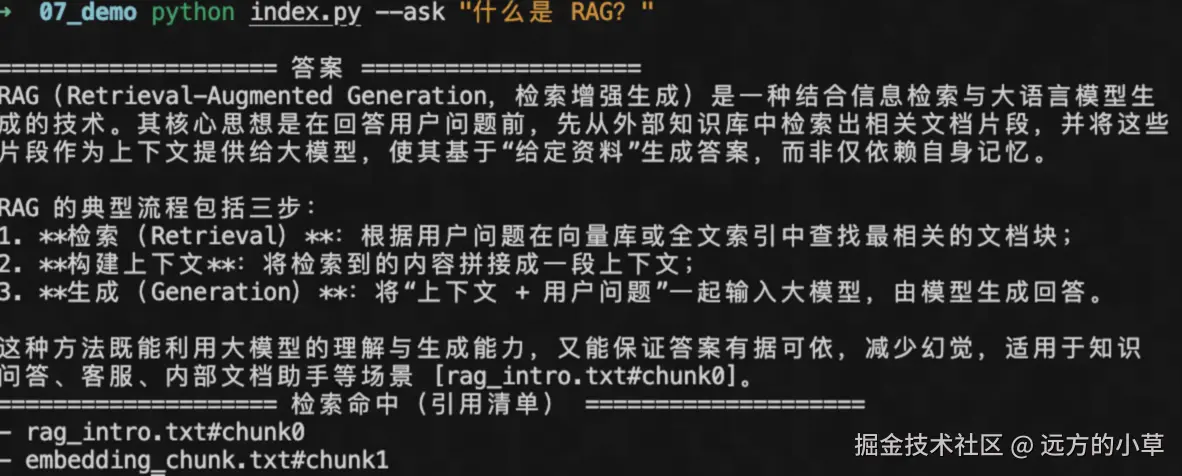
检索到响应的txt的内容了
提问"什么是 LLM?"
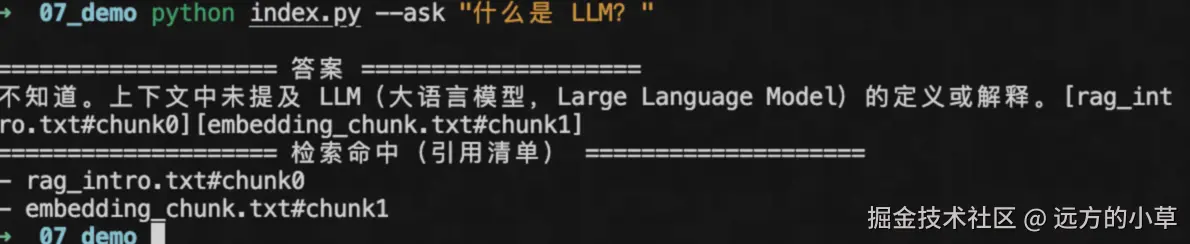
没检索到
参考资料: