企业知识库 RAG 实战:从 PDF 解析到可用系统
企业知识库不能简单理解成"把 PDF 丢进向量库,然后接一个大模型"。在真实项目中,真正麻烦的地方往往不在某一行代码,而在整条链路是否可靠:PDF 能不能解析干净,chunk 切分是否合理,检索能不能找到关键内容,Rerank 会不会带来过高延迟,Prompt 能不能稳定输出,最终答案有没有证据可以追踪。
这节内容围绕"企业知识库实战"展开。前半部分参考 RAG Challenge 冠军方案,看看一个企业年报问答系统是如何设计的;后半部分则把这套思路改造成自己的中文企业知识库,涉及 MinerU 解析、Markdown 切分、kind=string 开放式回答,以及 Streamlit 前端界面。
整套内容最核心的一句话是:
text
RAG 的效果不是靠某一个神奇参数调出来的,而是靠解析、入库、检索、重排、生成和评估整条链路共同决定的。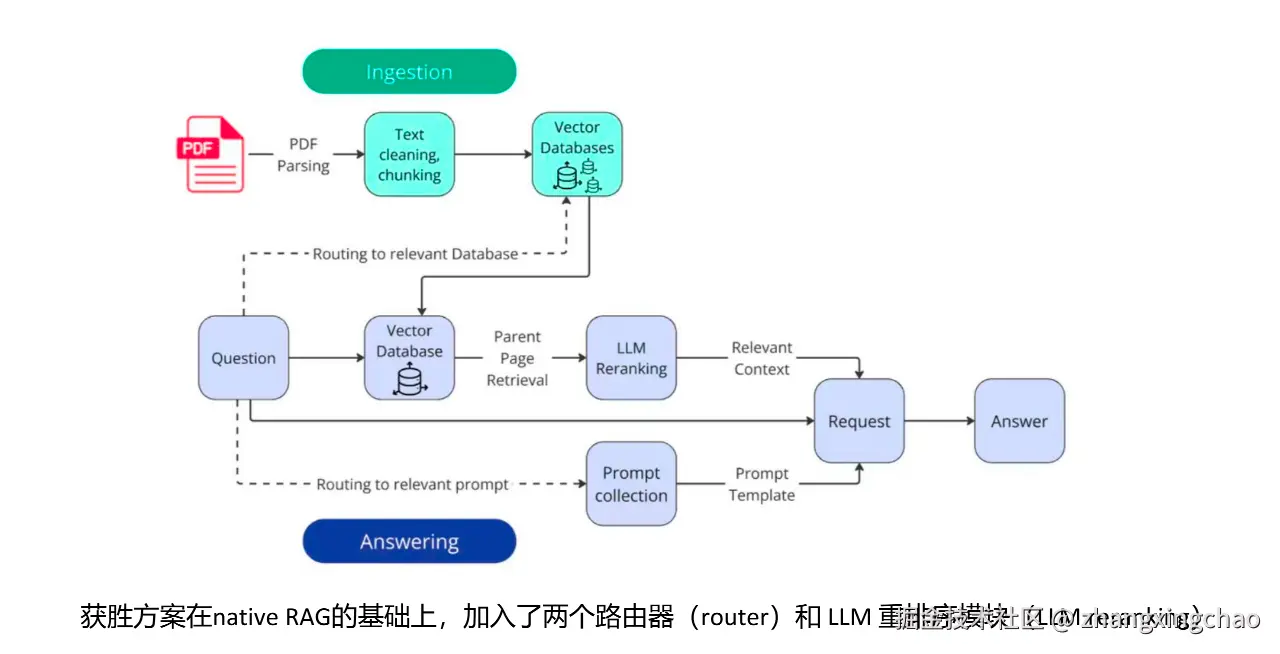
一、先看整体:企业知识库到底解决什么问题
RAG Challenge 的任务是,在比赛当天拿到随机公司的年度报告后,系统需要在有限时间内完成 PDF 解析、数据库构建,并回答随机问题。这些问题通常都有确定答案,比如是或否、公司名称、职位名称、产品名称、营收、门店数量等。同时,答案还需要标注引用页码。
这和普通聊天机器人不一样。普通聊天机器人更看重回答是否自然、流畅,而企业知识库更看重答案是否来自原始资料,是否能追踪到具体文档和页码。如果资料中没有答案,系统应该明确说明不知道,而不是编造内容。另外,输出格式也要稳定,方便程序解析和后续评估。每次调整解析、检索、Prompt 或参数后,也需要能判断效果是否真的提升。
所以,企业知识库的基本流程可以理解为四个阶段:首先是解析,把 PDF 等原始文档转成文本或结构化数据;然后是入库,把解析后的内容切分并保存到检索系统中;接着是检索,根据用户问题找到相关内容;最后是生成答案,由大模型基于检索结果完成回答。
text
Parsing 解析
-> Ingestion 入库
-> Retrieval 检索
-> Answering / Generation 生成答案
在这条链路里,每一步都会影响最终答案。PDF 解析错了,后面的检索就很难正确;检索没有召回关键页面,Prompt 写得再好也没有用;如果召回了大量无关内容,模型就容易被干扰;如果输出格式不稳定,前端展示和评测流程也会跟着出问题。
因此,企业知识库项目不是一个简单的"模型调用项目",而是一个完整的信息处理工程。
二、PDF 解析与表格处理:知识库质量的第一道门槛
企业知识库的第一步是解析文档。表面上看,这只是把 PDF 转成文本,但实际要复杂得多。PDF 里可能包含多栏排版、页眉页脚、图片、公式、表格、脚注、目录、跨页内容,以及一些旋转的大表格。只要解析阶段出错,后面的检索和回答都会受到影响。
材料中提到,作者试过二十多种解析器,包括一些小众解析器、知名解析器、基于机器学习的解析器,以及商业 API。最后选择了 Docling,但并不是直接拿来使用,而是阅读了 Docling 的源码,并重写了一些方法。
这些改造主要包括:解析后生成包含必要元数据的 JSON 文件;利用 JSON 构建 Markdown 文档;尽量把 PDF 中的表格转成 Markdown 或 HTML;对于解析出来的异常文本,再用正则表达式做清洗。

这里有一个很重要的认识:没有任何解析器能够完美还原所有 PDF 细节。尤其是年报、财报、投研报告这类文档,表格多、结构复杂,解析质量直接决定了知识库的上限。
表格处理是另一个典型问题。大型表格中,行标题和列标题可能距离很远,中间隔着大量无关 token。这会带来两个问题:一是向量检索时相关性被稀释;二是 LLM 在理解表格时,可能把指标和数值对应错。
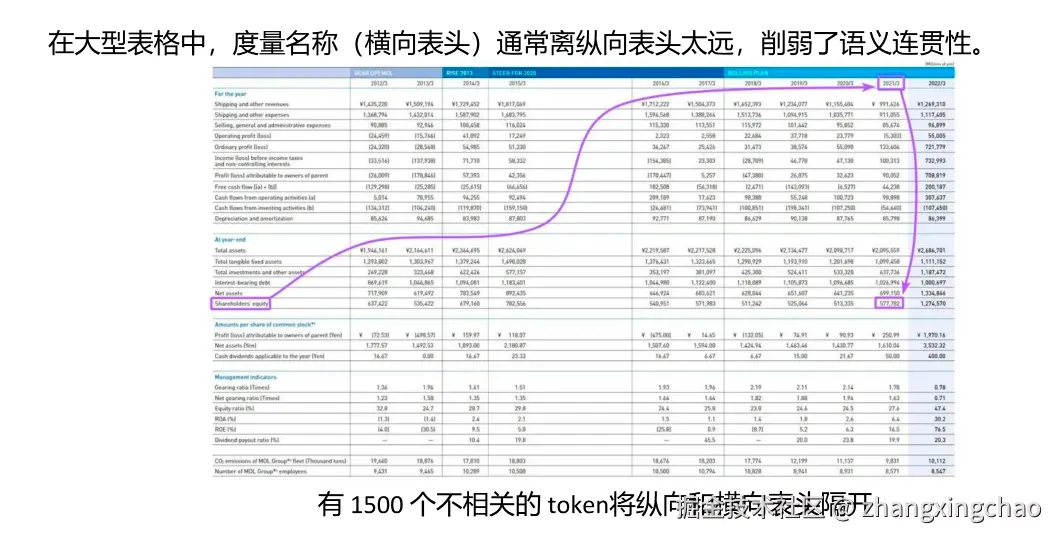
理论上,可以通过表格序列化来解决这个问题。比如 Row-wise Serialization 或 Attribute-Value Pairing,就是把表格转成更适合模型理解的"行式文本"或"属性-值对"。
不过,材料里也提到一个很有价值的结论:作者一开始对表格序列化寄予厚望,但实际测试后发现,它不仅没有提升系统效果,反而略微降低了有效性。所以最终并没有采用表格序列化方案。
这说明 RAG 调优不能只凭直觉。某个方案理论上看起来有用,并不代表它在当前数据、当前任务和当前模型组合下真的有效。最终还是要靠验证集和实验结果说话。
三、入库与检索:chunk 要能召回,也要能回到原文
解析完成后,下一步是把文档放进知识库。这个阶段不是简单保存文本,而是要提前考虑后续如何检索、如何引用,以及如何回到原始页面。
冠军方案没有直接把整页作为一个 chunk,而是先按页处理,再把每一页切成更小的文本块。每个 chunk 都会保存自己的 ID,以及对应的父页面 metadata。检索时,系统先命中小 chunk,再根据 metadata 回到父页面,拿到更完整的上下文。
这个流程大致可以表示为:
text
PDF -> Markdown / JSON
-> 按页处理
-> 每页切成约 300 token 的 chunk
-> 每个 chunk 保存 ID 和 parent page metadata
-> 检索时先命中小 chunk,再回到父页面取完整上下文这样做的原因很直接:小 chunk 更适合检索,完整页面更适合回答。
如果直接用整页做 chunk,页面里可能包含很多无关内容,embedding 相似度会被稀释;但如果 chunk 太小,模型回答时又可能缺少上下文。父页面检索就是在这两者之间做折中:先用小 chunk 定位相关位置,再把对应的完整页面拿回来给模型分析。

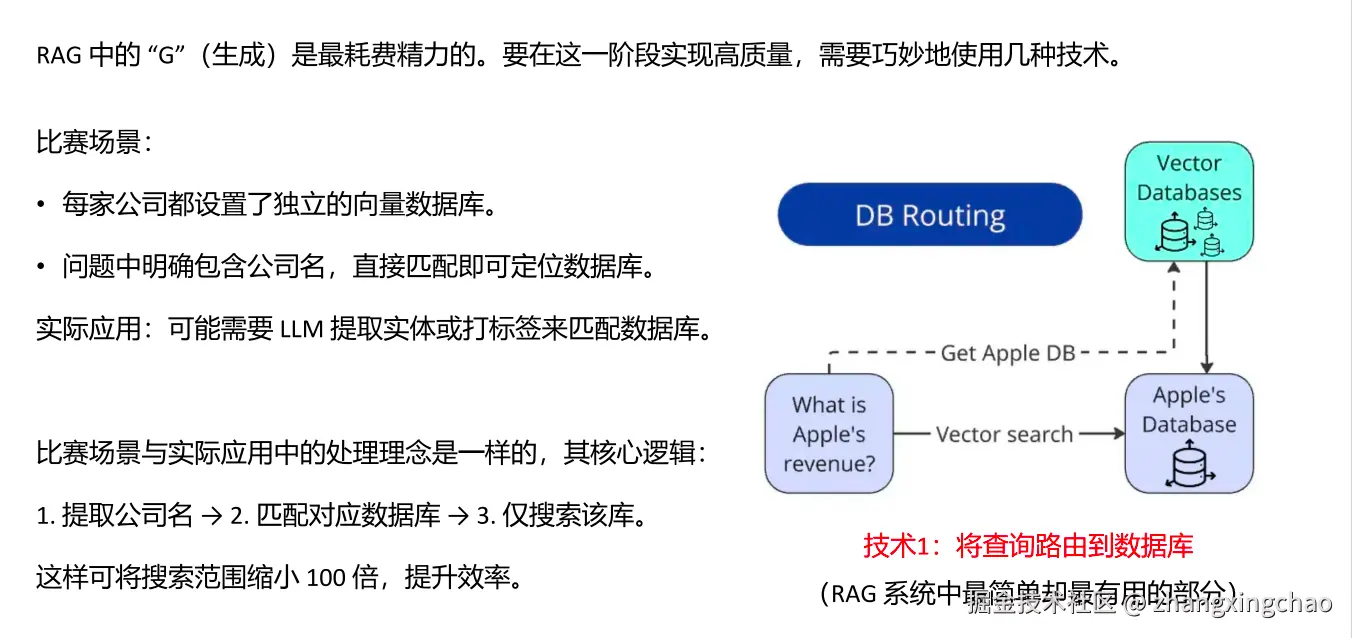
向量库的设计也很关键。材料里提到,如果有 100 家公司的年报,可以为每家公司单独创建一个 Faiss 数据库,也就是一家公司、一份文档、一个 Faiss 数据库。
text
1 个公司 / 1 份文档 / 1 个 Faiss 数据库这样做的好处是结构清晰,也能减少检索范围。用户问某家公司时,系统可以直接进入这家公司的数据库,不需要在所有公司混在一起的向量库中检索。在比赛场景中,问题通常会明确包含公司名,因此可以直接做数据库路由。
检索阶段的核心目标,是把真正相关的内容找出来。基础 RAG 往往只做向量检索 Top N,但实际项目中还可能加入 BM25、Hybrid Search、多路召回、Query Rewrite 等策略。
不过,这里也有一个现实结论:混合搜索理论上很强,但基础实现不一定提升效果,有时反而会降低检索质量。原因可能是多个召回源合并后带来了更多噪声,如果没有好的重排和融合策略,整体效果未必更好。
所以,检索不是越复杂越好,而是要看当前任务到底缺什么。如果是关键词匹配不稳定,可以补 BM25;如果是语义表达不一致,可以补 MultiQuery;如果召回结果太杂,就需要 Rerank。
四、Rerank 和路由:让系统找得更准,但也更贵
向量检索通常负责初步召回,但召回结果并不一定都适合直接交给模型回答。比如系统先召回 30 个 chunk,其中可能只有 5 到 10 个真正有用。这时就需要 Rerank。
材料中使用的是 LLM Reranking。大致流程是,把用户问题和候选文本块一起交给 LLM,让模型判断这个文本块和问题的相关性,并输出 reasoning 和 relevance_score。最后再结合向量得分和 LLM 得分,计算综合相关性。
例如可以设定:
text
vector_weight = 0.3
llm_weight = 0.7也就是说,向量检索先做便宜、快速的初筛,LLM 再做更细粒度的判断。

为什么不直接把所有页面都交给 LLM?原因很简单:成本和速度都不可接受。对于一份上千页的文档,如果每次回答都让 LLM 阅读全部页面,费用和延迟都会很高。更合理的方式是,先用 embedding 快速筛选,再用 LLM rerank 精排,最后只把 Top 页面放进上下文。
text
先用 embedding 快速筛选
-> 再用 LLM rerank 精排
-> 最后只把 Top 页面放进上下文材料里的整合检索器流程可以概括为:用户提出问题后,系统先将问题向量化,然后进行向量检索,召回 Top 30 个相关 chunk。接着根据 chunk metadata 找到对应的父页面并去重,再用 LLM 对这些页面进行重排序,最后返回 Top 10 页面,拼接成回答模型所需的上下文。
text
用户问题
-> 问题向量化
-> 向量检索 Top 30 个相关 chunk
-> 根据 chunk metadata 找到父页面并去重
-> LLM 对页面进行重排序
-> 返回 Top 10 页面
-> 拼接成用于回答的上下文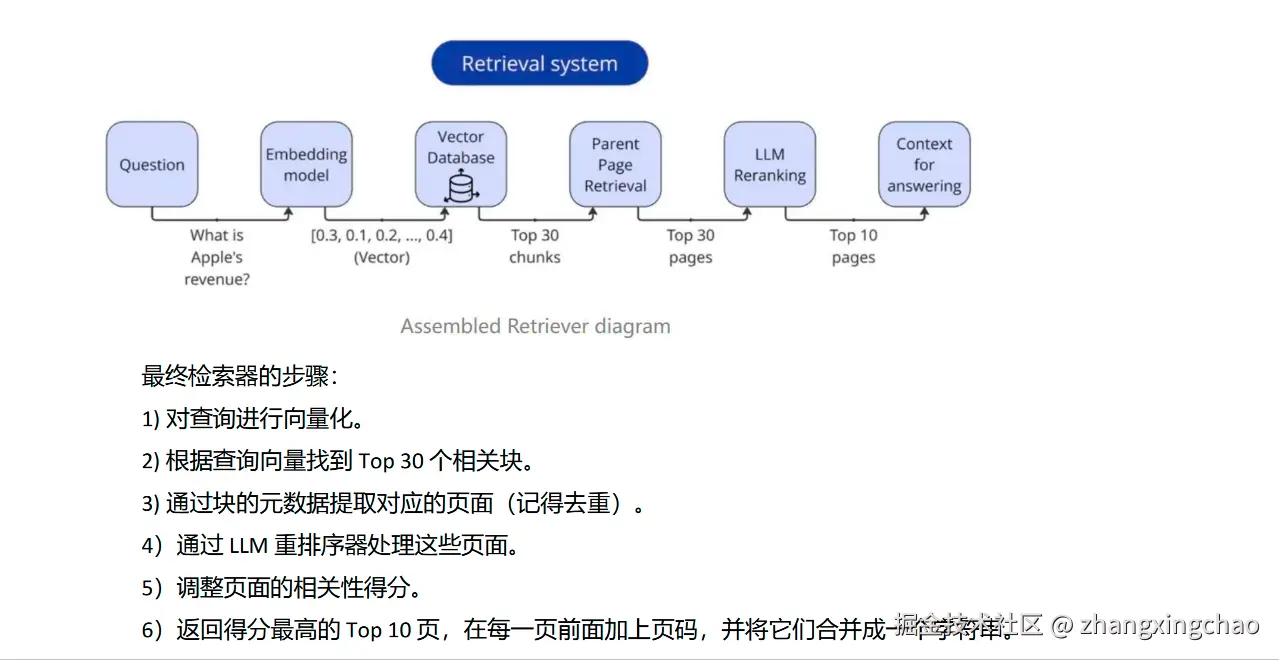
这里也解释了一个课堂里常见的问题:为什么是"先召回 30 个,再返回 10 个"?因为 30 个是初选候选集,10 个是经过 Rerank 后真正给回答模型使用的上下文。初选太少容易漏掉关键内容,初选太多又会增加 Rerank 成本。
除了 Rerank,路由也是冠军方案里的重要部分。路由主要分为两种:数据库路由和 Prompt 路由。
数据库路由解决的是"查哪个库"。比如问题里已经出现了公司名,那么系统就可以直接定位到这家公司的数据库,而不是在所有公司文档中搜索。这能显著缩小检索范围。
Prompt 路由解决的是"用哪个提示词回答"。比赛中每个问题都有明确的答案类型,比如 int、float、bool、str、list[str]。不同类型的答案,对应的约束规则不一样。数值题要处理单位和货币,布尔题要判断某件事是否发生,名称题要精确输出实体名,列表题要避免多余解释。
如果把所有规则都塞进一个 Prompt,模型很容易注意力分散。更好的做法是根据 kind 字段选择不同的 Prompt 模板。
对于比较类问题,还需要复合查询路由。比如用户问"苹果和微软谁的营收更高",系统不应该直接一次性回答,而是先拆成两个子问题。
text
苹果的营收是多少?
微软的营收是多少?分别查询后,再把两个结果放在一起比较。
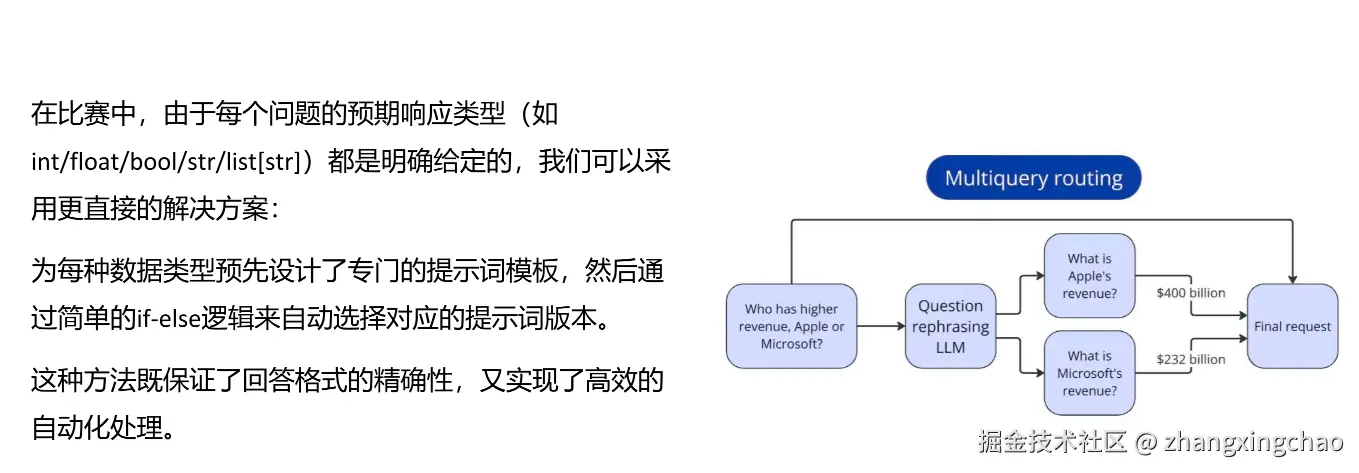
这种方式看起来麻烦,但它把复杂问题拆成了多个简单问题,能明显降低模型出错的概率。
五、Prompt 工程:不是写一句提示词,而是管理一组规则
在这个项目里,Prompt 不是一段简单文字,而是一组工程资产。材料里把提示词集中放在 prompts.py 中,并拆成几个逻辑块:核心系统指令用于告诉模型角色、任务和约束;Pydantic schema 用来规定输出字段和类型;one-shot 或 few-shot 示例用于让模型学习标准回答格式;user prompt 模板则负责动态插入上下文和问题。

这样做的好处是结构清晰,后续也容易维护。比如想修改数值题的规则,就只需要改 NumberPrompt;想支持开放式回答,就新增 StringPrompt;想调整引用页码规则,也可以统一修改 schema 中的字段说明。
材料中提到的几种 Prompt 类型包括:
text
AnswerWithRAGContextBooleanPrompt
AnswerWithRAGContextNumberPrompt
AnswerWithRAGContextNamePrompt
AnswerWithRAGContextNamesPrompt
ComparativeAnswerPrompt它们分别对应不同类型的答案。
text
kind = "boolean" -> AnswerWithRAGContextBooleanPrompt
kind = "number" -> AnswerWithRAGContextNumberPrompt
kind = "name" -> AnswerWithRAGContextNamePrompt
kind = "names" -> AnswerWithRAGContextNamesPrompt这也说明,Prompt 路由本质上就是把一个复杂任务拆成多个规则更少的小任务。模型面对的规则越清晰,输出就越稳定。
CoT 和结构化输出也是这里的重点。材料里提到,简单写一句 "Think step by step" 并不够。特别是较弱模型,可能会出现"虚假推理":先给答案,再倒推理由,甚至编造不存在的依据。所以 CoT 需要和业务规则结合,要明确告诉模型应该如何判断、哪些情况不能推断、什么时候应该返回 N/A。

结构化输出的目的是让模型返回标准 JSON。比如在回答比赛问题时,schema 中通常包含四个字段:
text
step_by_step_analysis:分步推理过程
reasoning_summary:推理摘要
relevant_pages:引用页码
final_answer:最终答案这样做有两个好处。第一,便于调试模型为什么会这样回答;第二,程序可以直接提取 final_answer 和 relevant_pages,不需要再从一大段自然语言里解析答案。
还有一个很重要的点是 Instruction Refinement,也就是指令细化。很多 RAG 系统的效果并不是靠换模型提升的,而是靠不断补充边界规则。
比如用户问"CEO 是谁",业务上是否接受"总裁""董事总经理""Managing Director"这类表达?用户问"股息政策有没有变",如果报告里只提到分红金额变化,但没有提政策变化,应该回答"没有变化",还是"没有信息"?这些问题很难让模型自己稳定处理,需要提前和业务方确认规则,并把规则写进 Prompt。
所以,Prompt 工程更像是在整理业务规则,而不是写几句漂亮的提示词。
六、调参与评估:不要凭感觉改系统
RAG 系统一定要有验证集。材料里提到,作者团队在比赛前用公开的问题生成器创建了 100 个问题的验证集,并手动回答。
这样做有两个价值。第一,可以量化系统效果。每次调整解析、检索、Rerank、Prompt 或参数后,都能判断正确率是否真的提升。第二,可以发现隐藏规则。很多问题表面上很简单,实际却存在不少歧义。只有手动答过,才知道哪些地方需要写进指令。

材料里用 RunConfig 管理各种实验参数,比如:
python
class RunConfig:
use_serialized_tables: bool = False
parent_document_retrieval: bool = False
use_vector_dbs: bool = True
use_bm25_db: bool = False
llm_reranking: bool = False
llm_reranking_sample_size: int = 30
top_n_retrieval: int = 10
parallel_requests: int = 1
full_context: bool = False
answering_model: str = "qwen-turbo-latest"这种配置化方式很适合做实验。比如要验证"表格序列化有没有用",就可以分别跑开启和关闭的版本;要判断 LLM Rerank 是否值得,就可以比较它带来的准确率提升和延迟成本。
这里的关键不是某个参数本身,而是调参方式。每次最好只改有限变量,并且用验证集比较结果。否则就很容易陷入一种误区:感觉某个方案更高级,所以以为它一定更好。
七、改造成自己的中文企业知识库
后半部分的重点,是把 RAG Challenge 的代码改造成自己的中文 RAG 系统。目标是把多份中文投研报告放进 data/stock_data/pdf_reports,然后围绕这些报告提问。例如:
- 中芯国际在晶圆制造行业中的地位如何?
- 半导体行业有哪些关键特性?
- 中芯国际近期营收和利润有什么变化?
- 美国限制政策对中芯国际有什么影响?
- 中芯国际如何应对外部环境变化?

整体改造思路可以分成四步。
第一步,先跑通原项目。
bash
python -m src.pipeline第二步,简化 Markdown 生成。原项目里的 pipeline 比较复杂,可以拆成几个更清楚的步骤:先把 PDF 报告解析成结构化 JSON,再序列化表格,然后把解析后的 JSON 规整为按页 Markdown,最后导出 Markdown 文本。
text
解析 PDF 报告为结构化 JSON
-> 序列化表格
-> 将解析后的 JSON 规整为按页 Markdown
-> 导出 Markdown 文本第三步,用 MinerU 替换原来的 Docling 解析。材料中实现了 pdf_mineru.py,主要逻辑是先调用 MinerU API 创建解析任务,拿到 task_id;然后轮询任务状态;如果任务完成,就下载 zip 并解压。

实际使用时要注意,API Key 不要直接写死在代码里,更推荐用环境变量读取。例如:
python
import os
api_key = os.getenv("MINERU_API_KEY")第四步,改造 text_splitter.py,让它支持直接切分 Markdown。原项目是对 JSON 文件做分块,这里新增了两个函数:
text
split_markdown_reports(...)
split_markdown_file(...)它们的作用是批量读取 Markdown 文件,按行切成 chunk,并保存起止行号、文本内容、公司名、文件名等 metadata。这样后续向量化和检索时,既能找到相关 chunk,也能追踪来源。

接着,还需要支持开放式问题,也就是 kind=string。原项目里已经有 number、boolean、name、names 等类型,但中文投研报告里的问题往往不是只回答一个数字或实体,而是需要输出一段总结性文本。
因此,可以新增:
text
AnswerWithRAGContextStringPrompt这个 Prompt 的 final_answer 是一段字符串,用来回答开放式问题。比如用户问:
text
请简要总结中芯国际 2024 年主营业务的主要内容。这类问题的答案就不应该只是一个数值,而应该是一段基于上下文归纳出来的文本。
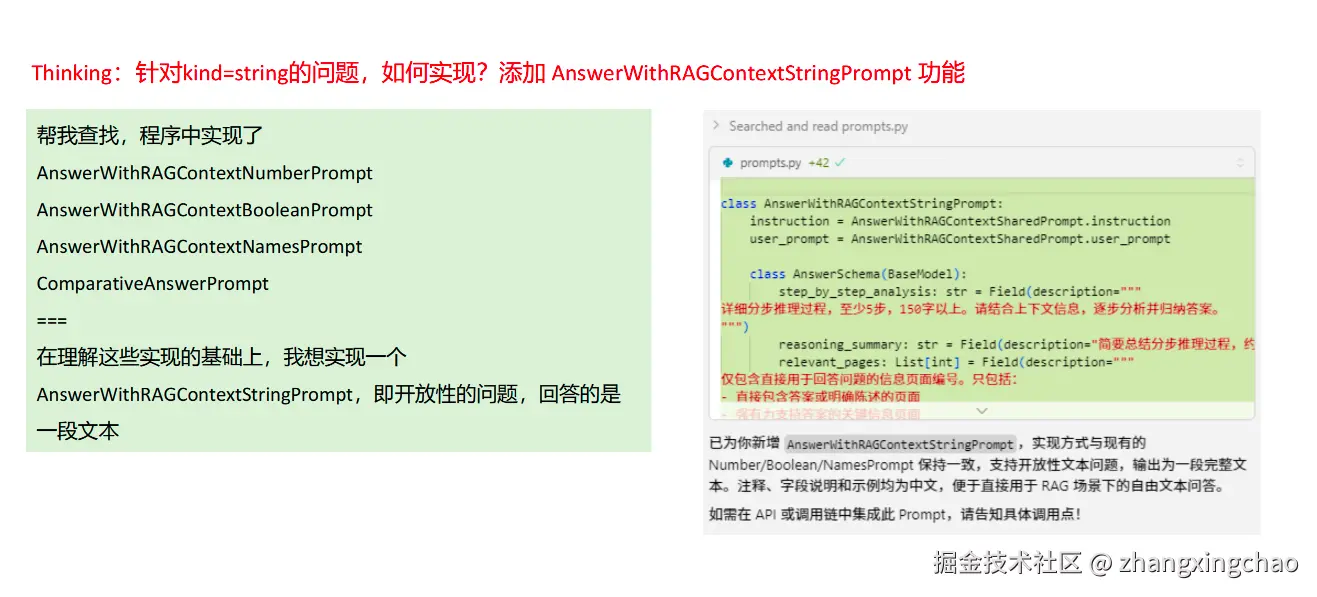
同时,还需要在 api_requests.py 里增加对应逻辑:
python
elif schema == "string":
system_prompt = prompts.AnswerWithRAGContextStringPrompt.system_prompt_with_schema
response_format = prompts.AnswerWithRAGContextStringPrompt.AnswerSchema
user_prompt = prompts.AnswerWithRAGContextStringPrompt.user_prompt这样,当问题类型是 string 时,系统就会走开放式回答的 Prompt。
八、做一个 Streamlit 界面,方便自己调试
最后一步是做一个前端界面。这里不一定要做得很复杂,关键是方便自己测试 RAG 系统。材料里选择了 Streamlit,用户输入一个问题后,后台调用类似 pipeline.process_questions() 或 answer_single_question() 的方法,然后把分步推理、推理摘要、相关页码和最终答案展示出来。
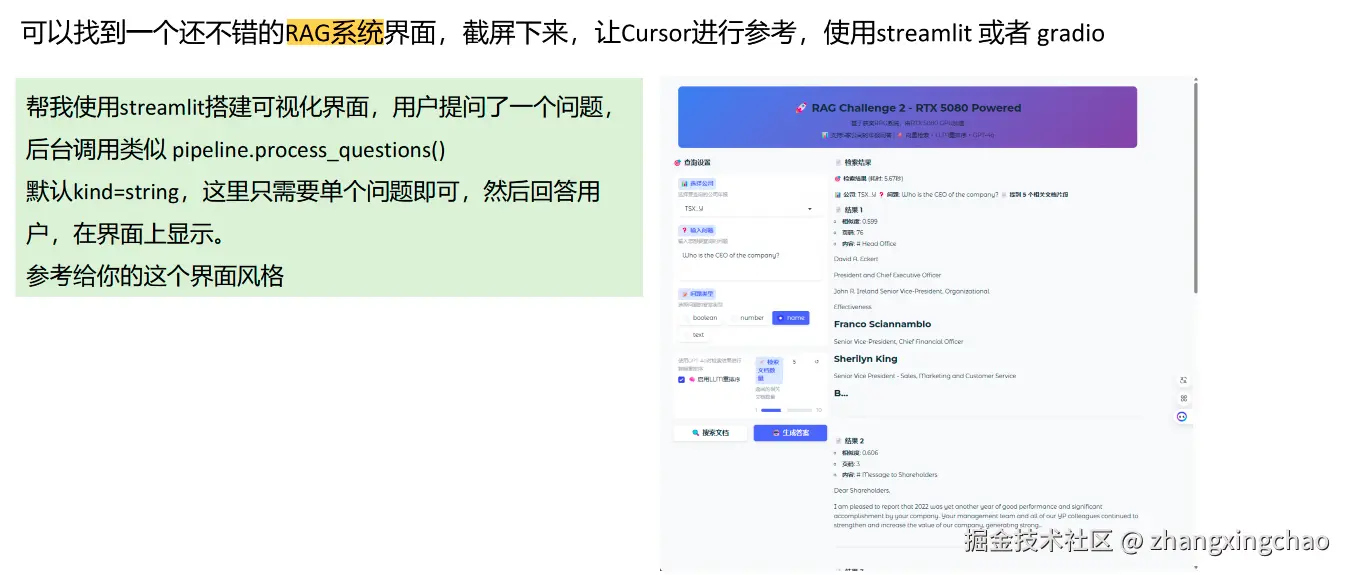
这个界面的价值不是"做得多漂亮",而是让调试更直观。通过界面可以看到检索用了多长时间,Rerank 是否耗时过高,返回的相关页码是否准确,final_answer 是否能被正确解析,以及模型是否回答了没有依据的内容。
材料里也记录了调试过程:一开始界面能跑,但输出结果没有正确解析;后来解析正确了,又发现检索时间过长。这个过程很真实,因为 RAG 项目通常不是一次写完,而是在不断暴露问题、定位问题、再优化中逐步完善。
九、一些落地经验和常见问题
把课程里的代码用到实际工作中,不能只停留在"把老师代码跑一遍"。更合理的方式是,先理解项目流程,再替换成自己的业务数据和业务问题。
可以按这样的顺序推进:
text
1. 先跑通原项目
2. 换成自己的文档
3. 换成自己的解析工具
4. 改 chunk 和 metadata
5. 换 embedding 和 LLM
6. 增加自己的 Prompt 类型
7. 做验证集
8. 用界面辅助调试如果做的是环保行业标准和法律法规知识库,标准和法律可以放在同一个系统里,但 metadata 要区分清楚,比如 doc_type=standard 和 doc_type=law。检索时可以根据问题意图做过滤,也可以让 Agent 或路由模块决定应该查哪一类知识。
如果问"需不需要把文档转成 Q/A 形式",答案是不一定。原始文档仍然应该保留,因为它是证据来源。Q/A 可以作为辅助材料,用来做评测集、问题生成、检索增强或 FAQ,但不应该完全替代原文。
如果是合同审核类需求,已经有多个审核点,每个审核点又有说明,那么确实可以从数据库里读取审核点列表,再用 LangGraph 或类似方式动态生成审核流程。每个审核点可以理解成一个节点,节点负责抽取证据、判断风险、输出结论,最后再汇总成审核报告。
还有一个常见问题是:如果上下文没有超过限制,为什么不把 embedding 召回的结果全部交给 LLM,而要做 Rerank?
原因是,上下文没超限制,并不代表所有内容都应该交给模型。无关内容会干扰模型,尤其是财报、合同、法规这种信息密集的材料。Rerank 的价值不只是压缩 token,而是提高上下文质量。当然,如果候选内容很少、上下文很干净,也可以减少 Rerank,甚至不用 Rerank。
至于 native RAG 多轮对话会不会越来越卡、越来越不准,答案是有可能。因为多轮对话如果不断把历史消息塞进上下文,噪声会越来越多,问题焦点也可能漂移。后续可以通过 query rewrite、history summarization、conversation memory 或 Agentic RAG 来处理。
Rerank 也不一定只能用本地模型。可以使用本地 reranker,比如 bge-reranker;也可以使用在线服务,比如 Jina;还可以直接用 LLM 做 rerank。选择哪种方式,主要取决于效果、成本、速度和部署要求。
对于复杂公式、单位和结构复杂的表格,解析阶段要尽量保留结构。可以使用 MinerU、Docling、OCR、LayoutLM、YOLO 等工具处理版面。入库时也要注意,表格不要被切得太碎,最好让一个表格尽量保留在同一个 chunk 或同一个父页面上下文中。
十、总结
这节内容真正想说明的是,RAG 调优不能只盯着某一个参数。chunk size、top_k、相似度阈值当然重要,但它们只是局部。
更完整的思路应该是:
text
高质量解析
-> 合理入库和 metadata 设计
-> 高效召回
-> Rerank 精排
-> 父页面检索
-> 数据库路由和 Prompt 路由
-> CoT + 结构化输出
-> 指令细化
-> 验证集评估
-> 前端调试和持续优化RAG 系统不是靠某一个"高级组件"就能变好,而是靠每个环节都尽量少出错。解析要可靠,检索要找得到,重排要排得准,Prompt 要把规则说清楚,输出要能被程序解析,引用也要能回到原文。
如果要把它应用到自己的工作里,最实用的路线不是一上来就做复杂 Agent,而是先做一个能跑通的 Native RAG。
text
自己的文档
-> 自己的解析
-> 自己的 chunk
-> 自己的 embedding
-> 自己的问题集
-> 自己的 Prompt
-> 自己的验证集等这条链路稳定后,再逐步加入 MultiQuery、混合检索、Rerank、GraphRAG 或 Agentic RAG。这样做更稳,也更容易定位问题。