
接下来我们要学习一个新知识点 ------ 工作流的常见模式。其实大家对工作流已经不陌生了,通过之前的多个案例,我们已经知道工作流的核心思路:先明确需求,再拆分出所需的各个节点,最后用边将这些节点串联起来,这就是编写工作流的基本套路。
工作流模式是预先定义好的执行路径,就像工厂的流水线一样,每个步骤都有明确的输入输出和顺序。根据不同的需求场景,从而定制出工作流常见的用法选项。
当这类套路积累多了,行业内的开发者会将其总结归纳,形成通用的 "模式",本章我们就来详细了解这些常见模式。需要强调的是,本章内容并不复杂,代码难度甚至低于之前的案例,核心是理解每种模式的作用和适用场景。
首先要明确,我们所说的 "工作流常见模式" 并非某个特定框架(比如 LangGraph)专属,而是通用的设计思路 ------ 除了 LangGraph,Java 中的 Spring AI、阿里巴巴相关框架等支持工作流的工具,都遵循这些模式。我们只是以 LangGraph 为载体进行编码实现,这些模式的核心逻辑适用于所有工作流开发框架。
提示链模式(Prompt Chaining)
概念
第一个要介绍的模式是提示链模式 ,它就像一条流水线,核心特点是前一个节点的输出作为后一个节点的输入。
这就跟进行内容创作时,需要 大纲 → 初稿 → 润色 → 最终稿,且每个步骤的输出需要传输给下一个步骤,才能确保内容质量逐步提升。
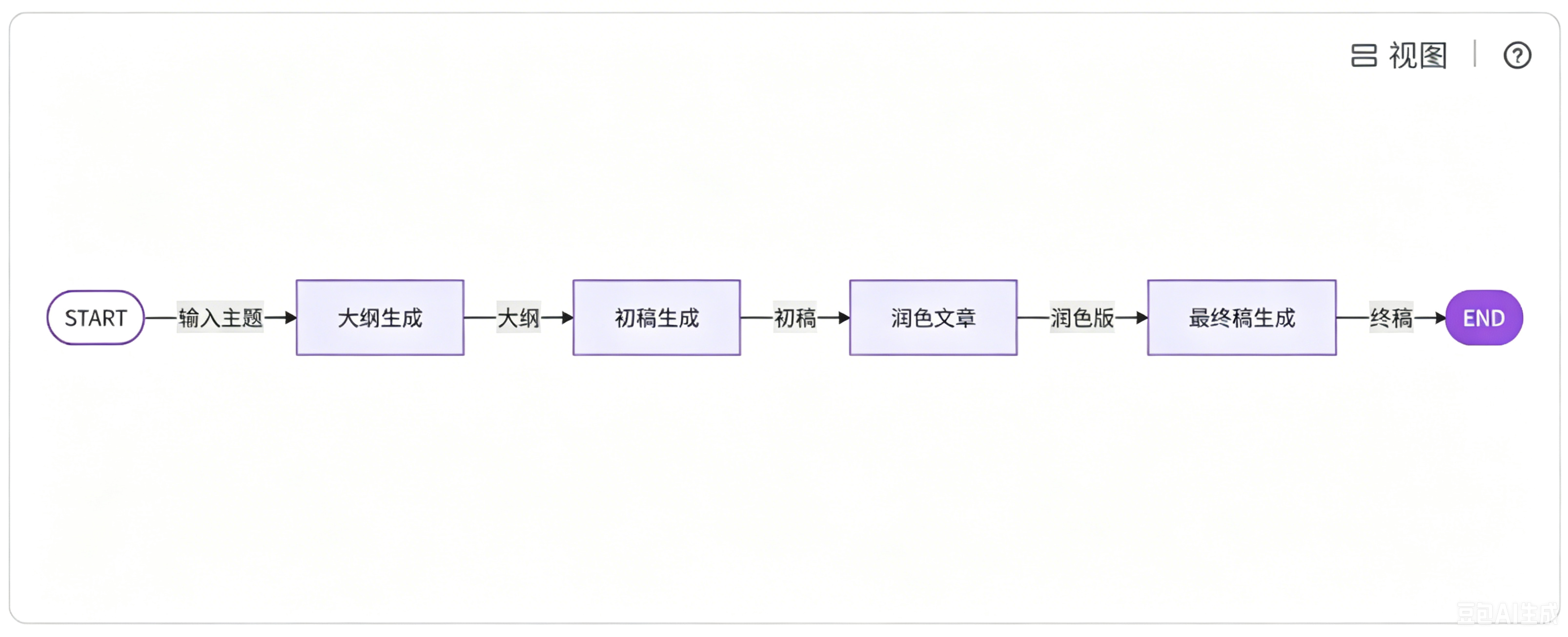
以 AI 文章生成系统为例:如果直接给大模型一个主题,让它一次性生成终稿,效果往往不够理想;但如果将任务拆分成多个子任务,效果会更稳定、质量更高。具体来说,可拆分为四个节点:
-
第一个节点接收 "主题" 输入,输出 "文章大纲";
-
第二个节点以 "大纲" 为输入,生成 "文章初稿";
-
第三个节点基于 "初稿" 进行 "内容润色";
-
第四个节点根据 "润色后的内容" 生成最终的 "文章终稿"。
这种拆分思路的优势在于,每个节点专注于单一子任务,任务颗粒度越细,最终产出的结果越可控、越优质,这也是提示链模式的核心价值。
接下来我们用 LangGraph 实现这个 AI 文章生成系统,具体步骤如下:
第一步,定义状态类。我们需要三种状态:
-
一是
InputState,用于接收用户输入的 "主题(topic)"; -
二是
OutputState,用于存储最终的 "文章终稿(final_content)"; -
三是
ProcessState,作为中间状态,存储流程中的 "大纲(outline)""初稿(draft)""润色版(polished_content)",方便节点间传递数据。
第二步,实现四个核心节点。每个节点的逻辑类似,仅提示词和处理目标不同:
-
节点 1(大纲生成) :接收
InputState中的主题,通过提示词 "根据主题生成包含两个核心标题的文章大纲,仅返回大纲" 调用大模型,将结果更新到ProcessState的outline字段; -
节点 2(初稿生成) :接收
ProcessState中的主题和大纲,通过提示词 "根据主题和大纲生成文章初稿,每个标题下最多三句话,仅返回初稿" 调用大模型,更新ProcessState的draft字段; -
节点 3(内容润色) :接收
ProcessState中的主题和初稿,通过提示词 "根据主题和初稿润色文章,保持内容简洁,仅返回润色结果" 调用大模型,更新ProcessState的polished_content字段; -
节点 4(终稿生成) :接收
ProcessState中的主题、大纲和润色版内容,通过提示词 "整合主题、大纲和润色内容,生成完整文章终稿" 调用大模型,将结果更新到OutputState的final_content字段。
第三步,构建工作流图。在 LangGraph 中,先将四个节点添加到图中,再定义边的连接关系:起始节点指向节点 1,节点 1 指向节点 2,节点 2 指向节点 3,节点 3 指向节点 4,形成一条线性链条。 同时设置输入验证(仅接收InputState)和输出过滤(仅返回OutputState中的final_content),确保流程规范。
最后,测试工作流。输入主题 "人工智能的未来发展",执行工作流后,会依次打印 "大纲生成中""初稿生成中""润色中""终稿生成中" 的日志,最终输出整合后的文章终稿。从执行结果可以看到,大纲仅包含两个核心标题,初稿每个标题下不超过三句话,润色后的内容简洁流畅,终稿逻辑完整,完全符合我们预设的需求。
总的来说,提示链模式的核心是 "线性流水线式的节点串联",通过拆分大任务为多个子任务,让每个节点专注于单一职责,从而提升结果的稳定性和质量。这种模式在内容生成、数据处理等需要分步推进的场景中非常常用,也是工作流开发中最基础、最核心的模式之一。
模式实践
我们可以创建一个内容创作场景的工作流,包含 大纲 → 初稿 → 润色 → 最终稿。节点即可设计为:
generate_outline节点:只负责大纲生成generate_draft节点:只负责初稿写作polish_content节点:只负责内容润色finalize_content节点:只负责最终整合
且可以使用定义输入输出的方式,如下所示:
python
# 1. 定义输入模式 - 只包含用户输入
class InputState(TypedDict):
topic: str # 用户输入的主题
# 2. 定义输出模式 - 只包含最终结果
class OutputState(TypedDict):
final_content: str # 最终的内容
# 3. 定义完整状态模式(内部使用)
class OverallState(InputState, OutputState):
outline: str # 第一步:生成的大纲
draft: str # 第二步:生成的初稿
polished_draft: str # 第三步:润色后的稿件完整代码示例如下:
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
model = init_chat_model("gpt-4o-mini")
# 1. 定义输入模式 - 只包含用户输入
class InputState(TypedDict):
topic: str # 用户输入的主题
# 2. 定义输出模式 - 只包含最终结果
class OutputState(TypedDict):
final_content: str # 最终的内容
# 3. 定义完整状态模式(内部使用)
class OverallState(InputState, OutputState):
outline: str # 第一步:生成的大纲
draft: str # 第二步:生成的初稿
polished_draft: str # 第三步:润色后的稿件
# 第一步:生成大纲
PROMPT_1 = (
"根据主题生成文章大纲。\n"
"主题: {topic}\n"
"要求: "
"1.只需两个最核心标题"
"2.不用进行说明,只返回最终大纲"
)
def generate_outline(state: InputState):
"""根据主题生成内容大纲"""
print("*" * 50)
print(f"内容大纲生成中...\n")
prompt = PROMPT_1.format(topic=state['topic'])
outline = model.invoke([HumanMessage(content=prompt)]).content
print(f"大纲已生成: \n{outline}\n")
return {
"outline": outline,
"topic": state["topic"]
}
# 第二步:基于大纲生成初稿
PROMPT_2 = (
"根据以下内容生成文章完整初稿。\n"
"主题: {topic}\n"
"大纲: "
"{outline}\n"
"要求: "
"1.每个标题下,最多使用三句话的内容即可"
"2.不用进行说明,只返回最终结果"
)
def generate_draft(state: OverallState):
"""根据大纲生成完整初稿"""
print("*" * 50)
print(f"生成初稿中...\n")
prompt = PROMPT_2.format(topic=state['topic'],outline=state['outline'])
draft = model.invoke([HumanMessage(content=prompt)]).content
print(f"初稿已生成: \n{draft}\n")
return {"draft": draft}
# 第三步:润色稿件
PROMPT_3 = (
"根据文章初稿进行润色。\n"
"主题: {topic}\n"
"初稿: "
"{draft}\n"
"要求: "
"1.润色后,文章不能太长"
)
def polish_content(state: OverallState):
"""对初稿进行润色优化"""
print("*" * 50)
print(f"文章润色中...\n")
prompt = PROMPT_3.format(topic=state['topic'],draft=state['draft'])
polished = model.invoke([HumanMessage(content=prompt)]).content
print(f"润色完成,内容如下: \n{polished}\n")
return {"polished_draft": polished}
# 第四步:生成最终稿
PROMPT_4 = (
"根据润色版文章,生成文章终稿。\n"
"主题: {topic}\n"
"大纲: "
"{outline}\n"
"润色版文章: "
"{polished_draft}\n"
)
def finalize_content(state: OverallState):
"""生成最终版本的内容"""
prompt = PROMPT_4.format(topic=state['topic'],outline=state['outline'],polished_draft=state['polished_draft'])
final_content = model.invoke([HumanMessage(content=prompt)]).content
return {"final_content": final_content}
# 构建工作流
builder = StateGraph(
OverallState,
input_schema=InputState,
output_schema=OutputState
)
# 添加节点
builder.add_node(generate_outline) # 节点1: 生成大纲
builder.add_node(generate_draft) # 节点2: 生成初稿
builder.add_node(polish_content) # 节点3: 润色稿件
builder.add_node(finalize_content) # 节点4: 生成最终稿
# 连接节点(直线流程)
builder.add_edge(START, "generate_outline") # 开始 → 生成大纲
builder.add_edge("generate_outline", "generate_draft") # 大纲 → 初稿
builder.add_edge("generate_draft", "polish_content") # 初稿 → 润色
builder.add_edge("polish_content", "finalize_content") # 润色 → 最终稿
builder.add_edge("finalize_content", END) # 最终稿 → 结束
# 编译工作流
chain = builder.compile()
# 使用工作流
print("=" * 50)
result = chain.invoke({"topic": "人工智能的未来发展"})
print("最终创作结果:")
print("=" * 50)
print(result["final_content"])
print("=" * 50)运行后,每个节点都有详细的日志输出(调试):
python
**************************************************
内容大纲生成中...
大纲已生成:
人工智能的未来发展
# 1. 技术趋势与创新方向
## 1.1 自然语言处理的进步
### 1.2 机器学习与深度学习的演变
### 1.3 强人工智能的可能性
# 2. 应用领域与社会影响
## 2.1 医疗行业的变革
### 2.2 自动化与就业市场的关系
### 2.3 伦理与监管的挑战
**************************************************
生成初稿中...
初稿已生成: 已省略
(内容较多,已省略)
**************************************************
文章润色中...
润色完成,内容如下:
(内容较多,已省略)
==================================================
最终创作结果:
(内容较多,已省略)
==================================================并行化模式(Parallelization)
概念
接下来我们学习工作流的第二种常见模式 ------并行化模式 。所谓并行化,核心是指多个任务可以同时进行处理,以此提升整体效率。需要重点注意 的是,并行执行的多个任务完成后,必须通过一个专门的节点进行结果汇总,否则后续流程无法推进,汇总步骤是并行化模式中不可或缺的关键环节。
并行执行的任务之间必须相互独立,不能有数据依赖。
这是并行化模式的前置条件,比汇总节点更根本------如果任务之间有依赖,它们根本就不能并行。
并行化是指多个任务同时进行,提高效率,最终汇总结果。在多角度处理同一问题时,常用该模式。
为了更好地理解,我们以 "智能电动自行车产品分析" 为场景展开说明:在研发一款智能电动自行车前,需要完成三项核心分析 ------ 市场分析、竞品分析和技术分析。这三项分析完全可以并行推进:
-
市场分析聚焦电动自行车行业的市场现状、用户需求(比如用户关注续航里程、车身重量、防盗能力,对骑行社交有新需求);
-
竞品分析针对其他品牌电动自行车的优劣势(比如传统品牌车型智能化不足,我们的产品需提升智能化水平);
-
技术分析则评估研发过程中的技术难题(比如材料选型、GPS 防盗功能实现、与相关 APP 的集成等)。
如果安排三个人分别负责这三项分析,能大幅缩短整体调研时间,待所有分析完成后,再由专人汇总结果,形成最终的产品报告 ------ 这就是并行化模式的典型应用场景。
最终汇总分析结果。而并行分析不仅省时,还能提升决策质量。
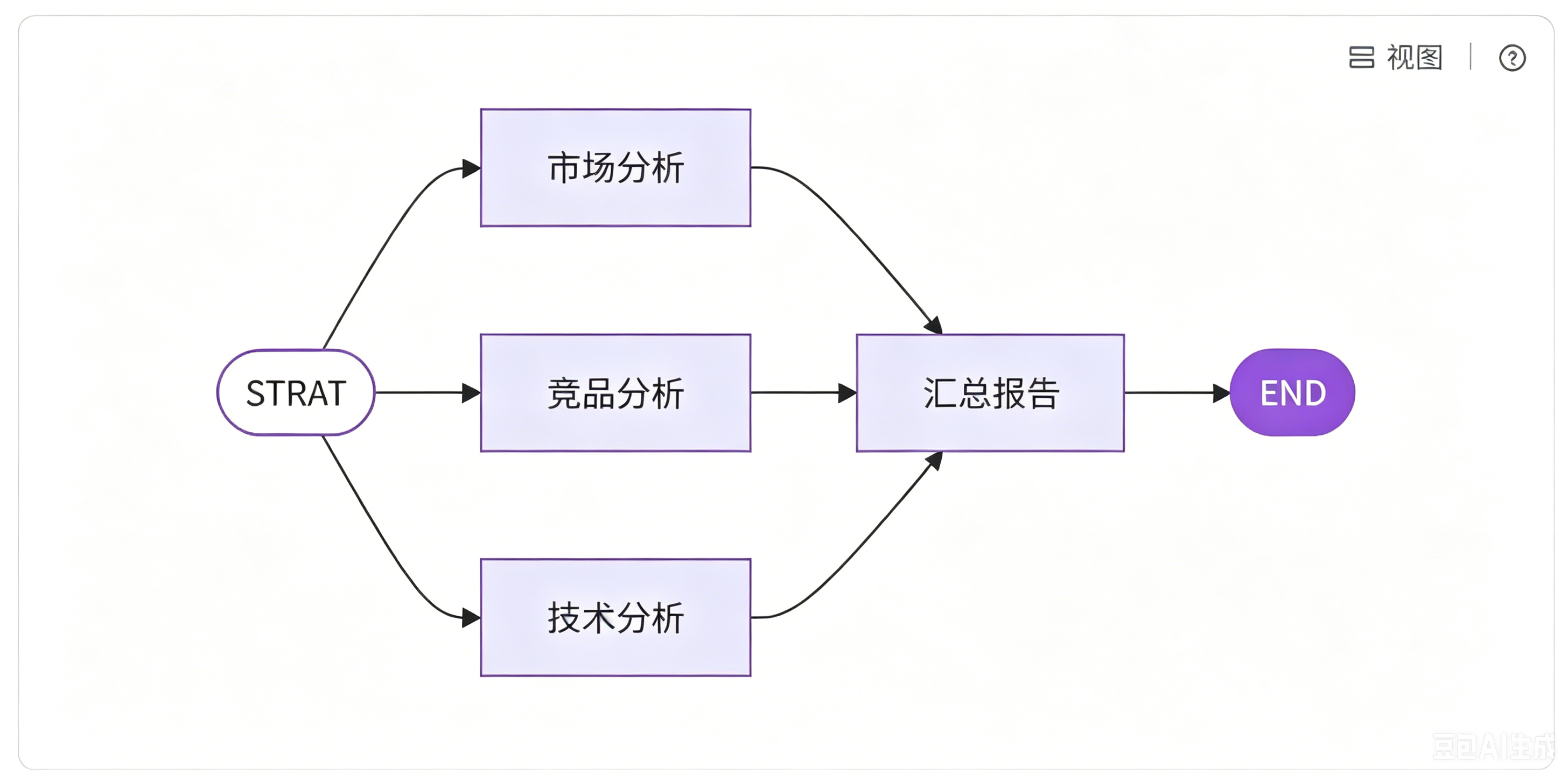
模式实践
在 LangGraph 中,并行化模式的实现核心在于 "边的配置" ,通过设置固定边让起始节点同时指向多个并行节点,再让所有并行节点统一指向汇总节点,最终由汇总节点指向结束节点。下面我们通过代码具体实现这一流程:
第一步,定义状态类。状态需包含输入的 "分析主题(比如'城市通勤智能电动车')",以及三个并行任务的结果(市场分析结果、竞品分析结果、技术分析结果),最后还要包含汇总后的 "产品报告",确保各节点间的数据传递顺畅。
第二步,实现四个核心节点。前三个为并行任务节点,最后一个为汇总节点:
- 市场分析节点(market_analysis):输出市场分析结果,比如用户对续航、重量、防盗的需求及骑行社交的潜在需求;
- 竞品分析节点(competitor_analysis):输出竞品分析结果,比如传统品牌智能化不足的痛点;
- 技术分析节点(technology_analysis):输出技术分析结果,比如需要攻克的材料、功能集成等技术难题;
- 汇总报告节点(summary_report) :接收前三个节点的分析结果,通过字符串拼接等方式整合为一份完整的产品报告,更新到状态的 "产品报告" 字段中。
第三步,构建并行化工作流图。首先将四个节点添加到图中,然后配置边的连接关系:
-
起始节点(start)同时指向市场分析、竞品分析、技术分析三个节点(实现并行执行);
-
接着让这三个并行节点都指向汇总报告节点(实现结果汇总);
-
最后让汇总报告节点指向结束节点(end)。
为了验证图的正确性,还可以通过 LangGraph 的可视化功能生成 Mermaid 代码,在在线编辑器中绘制流程图,直观确认并行关系和汇总逻辑是否符合预期。
第四步,测试工作流。输入分析主题 "城市通勤智能电动车",执行工作流后,三个并行节点会同时处理任务,完成后将结果传递给汇总节点,最终输出整合了市场、竞品、技术三大维度的产品分析报告。
并行化模式的核心优势是 "提升效率",适用于多个任务相互独立、无依赖关系(即解耦)的场景 ------ 比如市场分析、竞品分析、技术分析之间无需传递数据,仅需最终汇总结果。如果任务之间存在依赖(比如 A 任务的输出是 B 任务的输入),则更适合使用前一种提示链模式。这种模式在多维度调研、多模块数据处理等场景中应用广泛,是工作流开发中提升效率的重要手段。
实现一个工作流,可以并行执行三个维度的分析,最后整合成全面的产品研发建议,为智能电动自行车项目提供决策支持。完整代码示例:
python
from typing import TypedDict
from langgraph.constants import START, END
from langgraph.graph import StateGraph
class AnalysisState(TypedDict):
concept: str # 概念
market: str # 市场分析
competitor: str # 竞品分析
tech: str # 技术分析
report: str # 汇总报告
# 三个并行分析任务
def market_task(state: AnalysisState):
"""市场分析"""
return {"market": "用户关注续航、重量、防盗,对骑行社交有兴趣..."}
def competitor_task(state: AnalysisState):
"""竞品分析"""
return {"competitor": "传统品牌智能化不足,互联网品牌续航和售后差..."}
def tech_task(state: AnalysisState):
"""技术分析"""
return {"tech": "轻量化电池车身、GPS防盗、社交App集成..."}
# 汇总结果
def combine_results(state: AnalysisState):
"""生成最终报告"""
report = f"产品分析报告\n\n"
report += f"市场分析: \n{state['market']}\n\n"
report += f"竞品分析: \n{state['competitor']}\n\n"
report += f"技术分析: \n{state['tech']}\n\n"
report += "建议: 聚焦续航、防盗、社交功能的平衡发展"
return {"report": report}
# 构建工作流
builder = StateGraph(AnalysisState)
builder.add_node("market", market_task)
builder.add_node("competitor", competitor_task)
builder.add_node("tech", tech_task)
builder.add_node("combine", combine_results)
# 并行执行三个分析
builder.add_edge(START, "market")
builder.add_edge(START, "competitor")
builder.add_edge(START, "tech")
# 汇总结果
builder.add_edge("market", "combine")
builder.add_edge("competitor", "combine")
builder.add_edge("tech", "combine")
builder.add_edge("combine", END)
workflow = builder.compile()
# 使用
result = workflow.invoke({"concept": "城市通勤智能电动自行车"})
print(result["report"])
bash
产品分析报告
市场分析:
用户关注续航、重量、防盗,对骑行社交有兴趣...
竞品分析:
传统品牌智能化不足,互联网品牌续航和售后差...
技术分析:
轻量化电池车身、GPS防盗、社交App集成...
建议: 聚焦续航、防盗、社交功能的平衡发展路由模式(Routing)
概念
接下来我们学习第三种工作流模式 ------路由模式 ,它也被称作智能分流模式,我们在之前的实战案例中已经多次使用过这种模式。
路由模式的核心定义十分简单:它能够依据用户输入的内容、流程运行产生的状态数据,自动判定并分流执行不同的业务分支,选择对应的处理逻辑执行,本质上和我们之前学习的条件边用法高度契合。
我们先用生活化的例子理解路由模式,最典型的就是日常使用的智能客服热线。拨通客服电话后,系统会根据用户的选择进行分流,按数字按键对应不同服务通道,查询话费、咨询业务、转接人工服务各自走独立流程。放到线上智能客服系统中也是同理,平台会自动识别用户提问的内容,把售前咨询类问题分流到售前处理流程,售后报修类问题分流到售后处理流程,技术故障类问题分流到技术答疑流程,不同类型的问题进入专属链路完成处理,这就是路由模式最直观的应用。
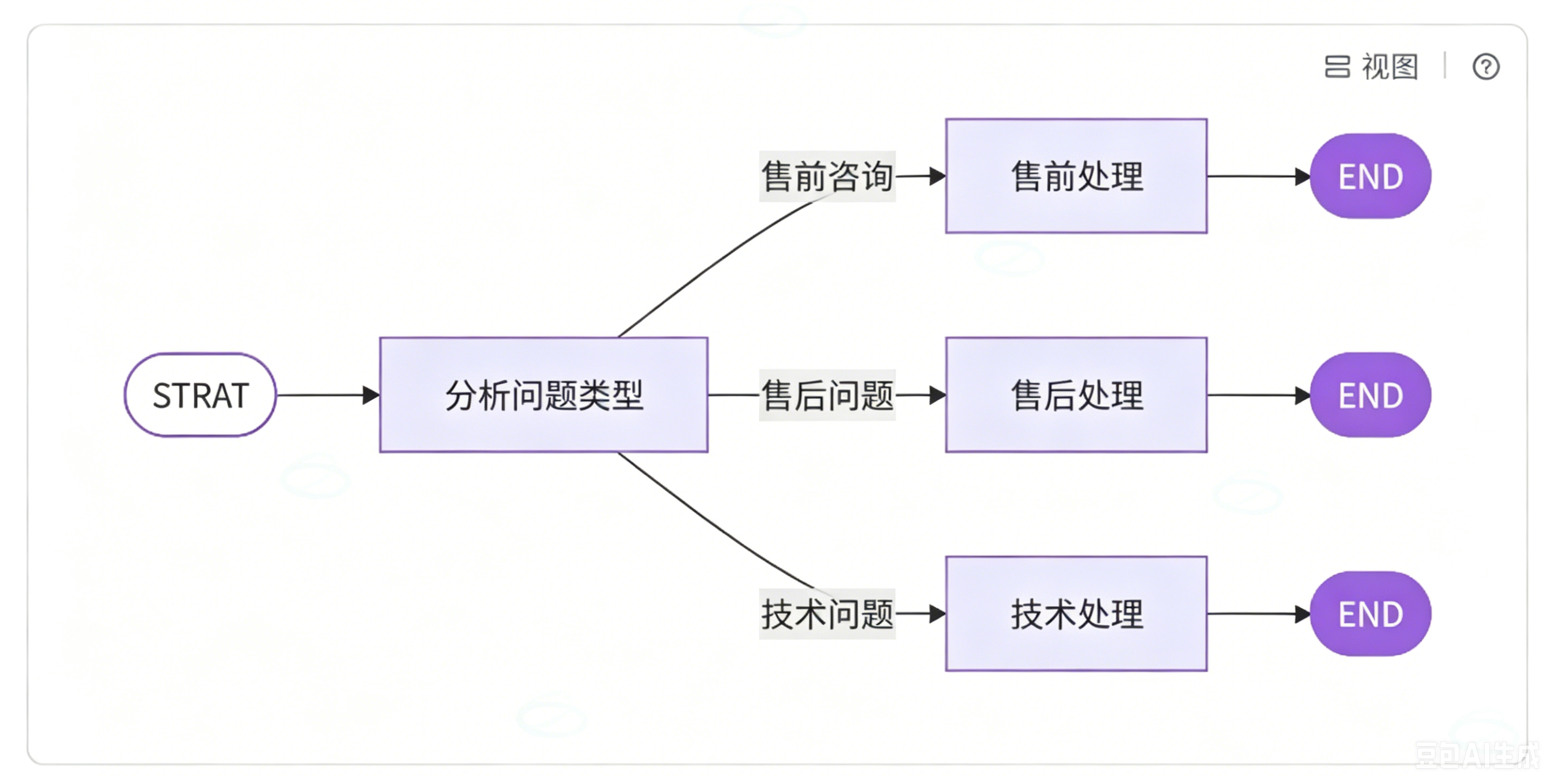
路由模式也被称为 "智能分流",根据输入内容决定执行哪个分支。最典型案例就是智能客服系统,可以用户问题自动分类处理,如下所示:
回顾我们之前写过的实战案例,其实早就接触并使用过路由智能分流逻辑。
第一个场景 是智能搜索系统,流程中会判定用户问题是否需要调用搜索工具:需要调用工具就进入工具执行节点,不需要则直接结束流程,整个判断分流依靠识别消息内的指定标识完成,这就是典型的路由分流。
第二个场景是 RAG 检索问答系统,这套系统里用到了两处路由逻辑:
-
第一处依旧是判断是否需要调取检索工具,按需分流;
-
第二处是检索完成后,校验检索出来的文档内容是否符合答题需求,文档合格就直接进入生成答案节点,文档不合格就进入重写问题节点,重新优化提问再进行检索。而文档合格与否的判定方式,就是借助大模型结构化输出 实现的,我们限定大模型只能输出
yes或者no两种结果,再依托条件边读取这个结果,以此决定后续走向哪一条流程分支,这和我们现在要讲解的路由模式实现思路完全一致。
清楚过往案例的用法后,我们再来学习全新的智能客服路由案例,理解起来就会轻松很多。这套智能客服工作流的整体流程十分清晰:流程启动后,首先进入问题类型分析节点,把用户提出的问题交给大模型,依靠大模型完成问题分类;我们同样采用结构化输出的方式,限制大模型最终只输出三类结果,分别对应售前咨询、售后咨询、技术问题,以此生成路由决策标识。
拿到明确的分类决策之后,我们通过条件边读取该决策状态,自动匹配对应的执行节点:判定为售前问题,就进入售前业务处理节点;判定为售后问题,进入售后问题处理节点;判定为技术问题,进入技术故障答疑节点。这三类处理节点相互独立、互不干扰,各自完成对应业务逻辑后,统一走向流程结束节点,每条业务分支都是完全解耦的独立流程。
模式实践
接下来我们梳理这套路由模式代码的完整编写思路。
第一步是定义全局状态类,状态中需要包含三类核心数据:
- 第一类是用户输入的原始提问内容;
- 第二类是流程流转的核心依据,也就是大模型生成的路由决策标识;
- 第三类是各个分支处理完成后最终输出的回复结果,依靠这三类状态数据,就能完成全流程的数据传递与逻辑判断。
第二步是编写四大核心功能节点。
第一个为路由决策分析节点,在该节点中初始化大模型,绑定固定格式的结构化输出,传入用户问题让模型自动分类,最终产出明确的问题类型决策,更新到全局状态当中。剩下三个分别是售前处理节点、售后处理节点、技术问题处理节点,这三个节点逻辑简洁,只需要匹配对应业务场景,生成标准化回复内容,把最终结果更新至输出状态即可,无需额外复杂逻辑。
第三步搭建工作流流程图,配置节点与流向关系。
首先将所有节点统一添加至工作流中,再配置基础固定边:流程起始节点固定指向问题分析决策节点,三个业务处理节点全部固定指向流程结束节点。最关键的一步就是配置条件路由边 ,我们单独编写路由判断函数,函数读取状态里的决策标识,通过判断语句匹配不同节点名称,以此实现从决策节点自动分流到三大业务处理节点的效果。我们也可以设置默认分流方向,规避模型识别异常的情况,保障流程稳定运行。
第四步完成流程调用与测试,我们直接传入不同类型的用户问题,测试路由分流是否准确。
输入产品价格、产品功能相关提问,系统会判定为售前咨询;输入商品质量问题、退货物流相关提问,会判定为售后咨询;输入软件报错、功能故障相关提问,则会精准归类为技术问题。
在实际测试过程中我们会发现,偶尔会出现分类判定偏差的情况,比如部分偏向售后政策咨询的问题,会被模型划分到售前类别里,出现这类问题的核心原因是提示词撰写不够细致严谨,我们只需要优化分类判断的提示词,明确界定每一类问题的判定标准,就能大幅提升路由分类的精准度。
最后我们总结一下路由模式的核心要点。路由模式的本质就是依靠状态判定 + 条件边实现流程智能分流,既可以单独拆分出专门的决策节点完成分类判断,让流程逻辑层次更清晰;也可以直接在条件边中调用大模型完成判定,精简整体代码结构,两种写法都能实现路由效果,大家可以根据开发习惯和项目场景自由选择。
它和我们之前学过的两种模式有着明确区分:提示链模式是线性串行执行,任务之间存在先后依赖;并行化模式是多任务同步执行,任务之间相互独立无需交互;而路由模式是分支选择执行,依靠条件判定走不同业务链路,三种模式各司其职,能够满足绝大多数 AI 工作流的开发场景。
所以现在要实现一个智能客服系统,根据用户问题自动分类,达到精准匹配处理能力。核心设计在于条件路由机制:
- 动态路径选择:可以基于 LLM 分析结果动态决定执行路径(结构化返回)
- 分支隔离:不同类型的问题由专用处理器处理
关键代码如下:
python
# 定义路由决策的数据结构
class Route(BaseModel):
step: Literal["pre_sale", "after_sale", "technical"] = Field(
description="根据用户问题类型决定路由到售前、售后还是技术处理"
)
# 路由决策节点
def model_call_router(state: State):
"""分析用户输入,决定问题类型"""
model = init_chat_model("gpt-4o-mini")
decision = model.with_structured_output(Route).invoke(state["input"])
return {"decision": decision.step}节点即可设计为:
model_call_router节点:路由决策节点,根据用户问题,由 LLM 通过结构化返回进行智能决策。pre_sale_handler节点:处理售前咨询after_sale_handler节点:处理售后问题technical_handler节点:处理技术问题
完整代码如下所示:
python
from langchain.chat_models import init_chat_model
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from typing_extensions import Literal, TypedDict
from pydantic import BaseModel, Field
class State(TypedDict):
input: str # 用户输入
decision: str # 路由决策
output: str # 最终输出
# 定义路由决策的数据结构
class Route(BaseModel):
step: Literal["pre_sale", "after_sale", "technical"] = Field(
description="根据用户问题类型决定路由到售前、售后还是技术处理"
)
# 路由决策节点
def model_call_router(state: State):
"""分析用户输入,决定问题类型"""
model = init_chat_model("gpt-4o-mini")
decision = model.with_structured_output(Route).invoke(state["input"])
return {"decision": decision.step}
# 三个不同的处理节点
def pre_sale_handler(state: State):
"""处理售前咨询"""
return {"output": "售前咨询已处理,处理内容......"}
def after_sale_handler(state: State):
"""处理售后问题"""
return {"output": "售后问题已处理,处理内容......"}
def technical_handler(state: State):
"""处理技术问题"""
return {"output": "技术问题已处理,处理内容......"}
# 路由函数 - 根据决策返回下一个节点
def route_decision(state: State):
if state["decision"] == "pre_sale":
return "pre_sale_handler" # 去售前处理节点
elif state["decision"] == "after_sale":
return "after_sale_handler" # 去售后处理节点
elif state["decision"] == "technical":
return "technical_handler" # 去技术处理节点
# 构建路由工作流
router_builder = StateGraph(State)
# 添加处理节点
router_builder.add_node(pre_sale_handler)
router_builder.add_node(after_sale_handler)
router_builder.add_node(technical_handler)
router_builder.add_node(model_call_router)
# 先经过路由决策
router_builder.add_edge(START, "model_call_router")
# 条件边:根据路由结果选择分支
router_builder.add_conditional_edges(
"model_call_router",
route_decision,
["pre_sale_handler", "after_sale_handler", "technical_handler"]
)
# 所有分支最终都结束
router_builder.add_edge("pre_sale_handler", END)
router_builder.add_edge("after_sale_handler", END)
router_builder.add_edge("technical_handler", END)
router_workflow = router_builder.compile()
# 测试
test_cases = [
"我想了解一下你们产品的价格和功能", # 售前咨询
"我购买的产品有质量问题,需要退货", # 售后问题
"这个软件安装后无法正常运行,报错代码0x80070005", # 技术问题
"请问你们的售后服务政策是什么", # 售后问题
"我的订单已经发货但还没收到", # 售前咨询
"如何配置数据库连接参数" # 技术问题
]
for test_case in test_cases:
print("*" * 50)
print(f"用户问题: {test_case}")
result = router_workflow.invoke({"input": test_case})
print(result["output"])运行结果:
python
**************************************************
用户问题: 我想了解一下你们产品的价格和功能
售前咨询已处理,处理内容......
**************************************************
用户问题: 我购买的产品有质量问题,需要退货
售后问题已处理,处理内容......
**************************************************
用户问题: 这个软件安装后无法正常运行,报错代码0x80070005
技术问题已处理,处理内容......
**************************************************
用户问题: 请问你们的售后服务政策是什么
售后问题已处理,处理内容......
**************************************************
用户问题: 我的订单已经发货但还没收到
售前咨询已处理,处理内容......
**************************************************
用户问题: 如何配置数据库连接参数
技术问题已处理,处理内容......
**************************************************