一、问题理解与目标定义
- 核心问题:厘清 after_model 和 after_agent 两个中间件的触发时机、作用范围及典型应用场景。
- 分析目标:帮助开发者在生产环境中合理使用这两个"后置"钩子,实现输出治理、安全审计、性能监控等关键能力。
二、中间件功能对比
| 维度 | after_model |
after_agent |
|---|---|---|
| 触发时机 | 每次模型调用返回后立即执行(可能多次) | Agent 整个执行流程完全结束后执行(仅一次) |
| 执行频率 | 与模型调用次数一致(Agent 循环中可能多次触发) | 每次 agent.invoke() 调用仅触发一次 |
| 可访问数据 | 模型原始响应 + 当前请求上下文 | 最终 Agent 状态(含完整消息历史、工具调用结果) |
| 典型用途 | 输出内容脱敏、格式校验、Token 统计 | 性能指标汇总、资源清理、最终结果审计 |
| 能否修改状态 | ✅ 可修改模型响应内容(影响后续流程) | ✅ 可修改最终状态(但通常用于只读操作) |
💡 关键区别:
- after_model 是 "每次思考后的检查"(细粒度、高频)
- after_agent 是 "任务完成后的总结"(粗粒度、低频)
三、中间件对比
3.1 after_model:输出脱敏、格式校验与 Token 统计
python
# -*- coding: utf-8 -*-
"""
agent_with_memory
Author: user
Date: 2026/3/16
Description:
"""
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.tools import tool
from langchain_community.callbacks import get_openai_callback
from langchain.chat_models import init_chat_model
from langchain.agents.middleware import wrap_tool_call,PIIMiddleware,after_model,wrap_tool_call
import re
import os
from dotenv import load_dotenv
from langgraph.runtime import Runtime
from langchain.messages import AIMessage,ToolMessage
load_dotenv(override=True)
# 全局 Token 计数器(生产环境建议绑定到会话)
_SESSION_TOKENS = {"total_completion_tokens": 0,'input_token':0,'output_token':0}
# 全局重试计数器(生产环境应绑定到会话)
_RETRY_COUNT = {}
model = init_chat_model(model="qwen2-72b", #
model_provider='openai',
api_key= os.getenv("api_key"),
base_url= os.getenv("base_url"),
temperature=0.3,
max_retries=4,
#max_tokens=10
)
# 1. 系统提示词
system_prompt = """你是一位幽默的天气预报员。
根据天气给出穿衣建议,用轻松的方式表达。"""
# 2. 定义工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
try:
return f"{city}:晴,25度,微风徐徐"
except Exception as e:
return e
@tool
def get_location() -> str:
"""获取用户位置"""
return "北京"
@tool
def send_email(email:str,user:str,content:str):
"""
给用户发送邮件
:param email: 用户email
:param user: 用户名字
:param content: 内容
:return:
"""
raise TypeError("所有参数必须为字符串类型")
#return f"done! 用户 = {user} {email},发功成功!内容是:{content}"
# 工具调用重试
@wrap_tool_call
def retry_on_tool_failure(request, handler):
max_retries = 2 # 最多重试 2 次(共 3 次尝试)
tool_name = request.tool.name
args = request.tool_call.get('args') # 工具调用参数字典
tool_call_id = request.tool_call.get('id') #
session_id= 'default'
key = f"{session_id}_{tool_name}"
# 初始化重试次数
if key not in _RETRY_COUNT:
_RETRY_COUNT[key] = 0
try:
result = handler(request)
_RETRY_COUNT[key] = 0
return result
except Exception as e:
error_msg = (
f"工具 '{tool_name}' 调用失败(第 {_RETRY_COUNT[key]+1} 次尝试)。\n"
f"工具输出的参数是:{args}"
f"错误: {str(e)}\n"
f"请检查参数格式或值是否有效,并重新调用。"
)
print(f"{tool_name} 调用失败,[RETRY] {error_msg}")
if _RETRY_COUNT[key] < max_retries:
_RETRY_COUNT[key] += 1
# 关键:返回 ToolMessage,让 Agent 看到"观察结果"
return ToolMessage(
content=error_msg,
tool_call_id=tool_call_id # 必须匹配原始调用 ID
)
else:
return ToolMessage(
content="该工具不能正常使用,结束!",
tool_call_id=tool_call_id # 必须匹配原始调用 ID
)
@after_model
def sanitize_and_track_tokens(state: AgentState, runtime: Runtime):
"""
使用模型返回的真实 Token 数据,避免估算误差
"""
# === 1. 内容脱敏(同前)===
#user_message = messages[-1].model_dump()
last_message = state["messages"][-1].model_dump()
content = last_message.get('content')
PII_PATTERNS = [
(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', '[EMAIL]'),
(r'\b1[3-9]\d{9}\b', '[PHONE]'),
(r'\b(?:\d{4}[-\s]?){3}\d{4}\b|\b\d{16,19}\b', '[CARD]'),
]
for pattern, replacement in PII_PATTERNS:
content = re.sub(pattern, replacement, content)
last_message["content"] = content
state["messages"][-1] = AIMessage(**last_message)
# === 2. 获取真实 Token 统计(关键修正!)===
token_usage = None
# 方式 1:从 response_metadata 提取(LangChain ≥ 0.2)
if 'usage_metadata' in last_message:
_SESSION_TOKENS['input_token'] += last_message['usage_metadata']['input_tokens']
_SESSION_TOKENS['output_token'] += last_message['usage_metadata']['output_tokens']
_SESSION_TOKENS['total_completion_tokens'] += last_message['usage_metadata']['total_tokens']
print(f"截止目前会话 token消耗: input_token= {_SESSION_TOKENS['input_token']}, output_token={_SESSION_TOKENS['output_token']},"
f"total_token={_SESSION_TOKENS['total_completion_tokens']}")
return state
# 4. 添加记忆
checkpointer = InMemorySaver()
# 5. 创建 Agent
agent = create_agent(
model=model,
tools=[get_weather, get_location,send_email],
system_prompt=system_prompt,
checkpointer=checkpointer,
middleware=[sanitize_and_track_tokens,retry_on_tool_failure
]
)
# 6. 运行对话
config = {"configurable": {"thread_id": "user-001"}}
#
# with get_openai_callback() as cb:
# # 使用 stream 方法
# for event in agent.stream(
# {"messages": [{"role": "user", "content": "今天穿什么好?"}]},
# config=config,
# context={"user_role": "admin", "session_id": "sess_123"},
# stream_mode="values"
# ):
# #print(event)
# event['messages'][-1].pretty_print()
# print("\n--- Token Usage ---")
# print(f"Total Tokens: {cb.total_tokens}")
# print(f"Prompt Tokens: {cb.prompt_tokens}")
# print(f"Completion Tokens: {cb.completion_tokens}")
# print(f"Total Cost (USD): ${cb.total_cost:.6f}")
# print(f"Successful Requests: {cb.successful_requests}")
#
# print()
for event in agent.stream(
{"messages": [{"role": "user", "content": "使用send_email工具 给小明发送一个邮件(12345678@qq.com)问好!,直接发送即可!"}]},
config=config,
context={'user_role':'guest'},
stream_mode="values"
):
#print(event)
event['messages'][-1].pretty_print()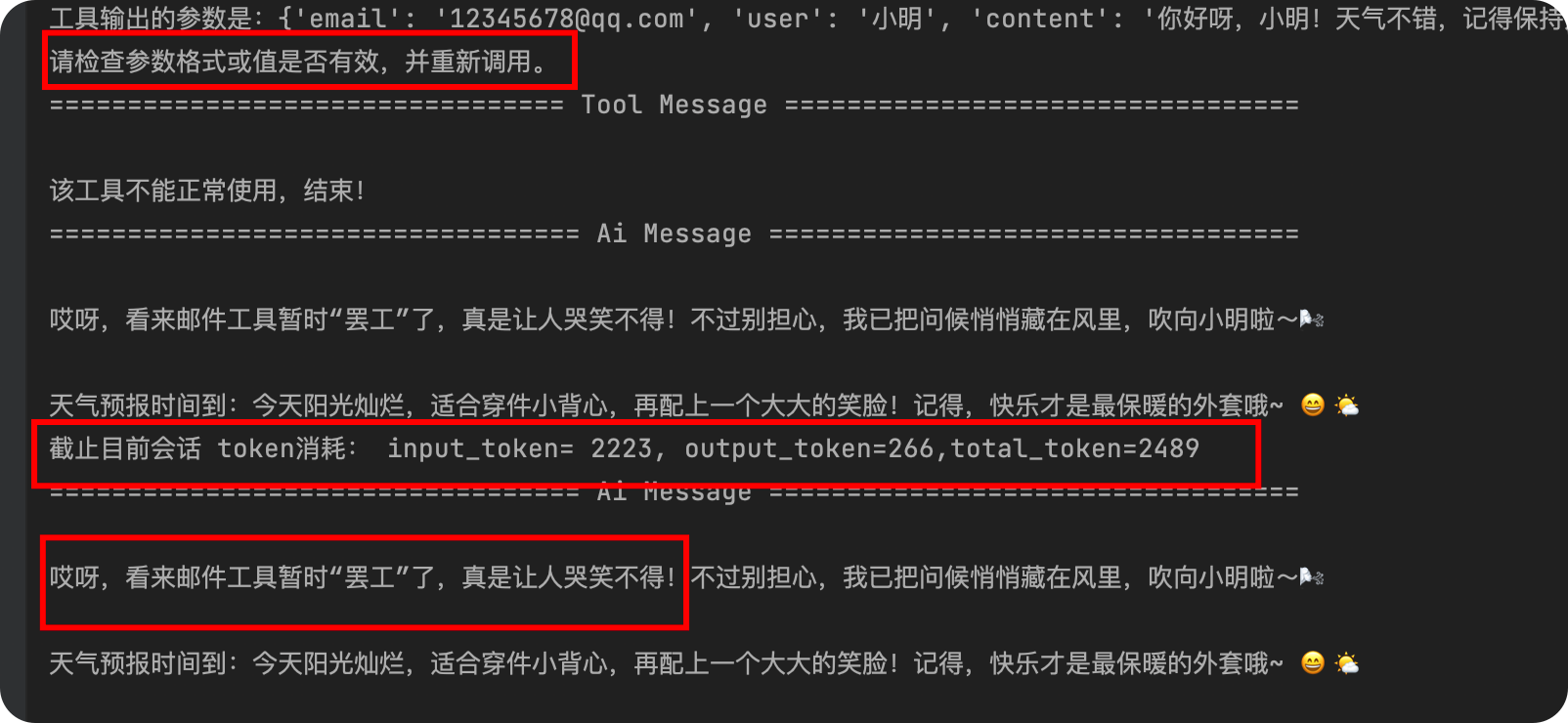
这个发邮件的工具我是一直抛出异常,然后测试模型调用工具的次数!看起来没有什么问题,既能实现token的统计,又能实现工具调用的重试!
3.2 after_agent:性能指标汇总与资源清理
下面的代码可以完成对智能体执行的情况、统计时间、调用工具的次数等等;
python
# -*- coding: utf-8 -*-
"""
agent_with_memory
Author: user
Date: 2026/3/16
Description:
"""
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.tools import tool
from langchain_community.callbacks import get_openai_callback
from langchain.chat_models import init_chat_model
from langchain.agents.middleware import wrap_tool_call,PIIMiddleware,after_model,wrap_tool_call,after_agent
import re
import os
from dotenv import load_dotenv
from langgraph.runtime import Runtime
from langchain.messages import AIMessage,ToolMessage
import time
load_dotenv(override=True)
# 全局 Token 计数器(生产环境建议绑定到会话)
_SESSION_TOKENS = {"total_completion_tokens": 0,'input_token':0,'output_token':0}
# 全局重试计数器(生产环境应绑定到会话)
_RETRY_COUNT = {}
model = init_chat_model(model="qwen2-72b", #
model_provider='openai',
api_key= os.getenv("api_key"),
base_url= os.getenv("base_url"),
temperature=0.3,
max_retries=4,
#max_tokens=10
)
# 1. 系统提示词
system_prompt = """你是一位幽默的天气预报员。
根据天气给出穿衣建议,用轻松的方式表达。"""
# 2. 定义工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
try:
return f"{city}:晴,25度,微风徐徐"
except Exception as e:
return e
@tool
def get_location() -> str:
"""获取用户位置"""
return "北京"
@tool
def send_email(email:str,user:str,content:str):
"""
给用户发送邮件
:param email: 用户email
:param user: 用户名字
:param content: 内容
:return:
"""
#raise TypeError("所有参数必须为字符串类型")
return f"done! 用户 = {user} {email},发功成功!内容是:{content}"
# 工具调用重试
@wrap_tool_call
def retry_on_tool_failure(request, handler):
max_retries = 1 # 最多重试 1 次(共 2 次尝试)
tool_name = request.tool.name
args = request.tool_call.get('args') # 工具调用参数字典
tool_call_id = request.tool_call.get('id') #
session_id= 'default'
key = f"{session_id}_{tool_name}"
# 初始化重试次数
if key not in _RETRY_COUNT:
_RETRY_COUNT[key] = 0
try:
result = handler(request)
_RETRY_COUNT[key] = 0
return result
except Exception as e:
error_msg = (
f"工具 '{tool_name}' 调用失败(第 {_RETRY_COUNT[key]+1} 次尝试)。\n"
f"工具输出的参数是:{args}"
f"错误: {str(e)}\n"
f"请检查参数格式或值是否有效,并重新调用。"
)
print(f"{tool_name} 调用失败,[RETRY] {error_msg}")
if _RETRY_COUNT[key] < max_retries:
_RETRY_COUNT[key] += 1
# 关键:返回 ToolMessage,让 Agent 看到"观察结果"
return ToolMessage(
content=error_msg,
tool_call_id=tool_call_id # 必须匹配原始调用 ID
)
else:
return ToolMessage(
content="该工具不能正常使用,结束!",
tool_call_id=tool_call_id # 必须匹配原始调用 ID
)
@after_model
def sanitize_and_track_tokens(state: AgentState, runtime: Runtime):
"""
使用模型返回的真实 Token 数据,避免估算误差
"""
# === 1. 内容脱敏(同前)===
#user_message = messages[-1].model_dump()
last_message = state["messages"][-1].model_dump()
content = last_message.get('content')
PII_PATTERNS = [
(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', '[EMAIL]'),
(r'\b1[3-9]\d{9}\b', '[PHONE]'),
(r'\b(?:\d{4}[-\s]?){3}\d{4}\b|\b\d{16,19}\b', '[CARD]'),
]
for pattern, replacement in PII_PATTERNS:
content = re.sub(pattern, replacement, content)
last_message["content"] = content
state["messages"][-1] = AIMessage(**last_message)
# === 2. 获取真实 Token 统计(关键修正!)===
token_usage = None
# 方式 1:从 response_metadata 提取(LangChain ≥ 0.2)
if 'usage_metadata' in last_message:
_SESSION_TOKENS['input_token'] += last_message['usage_metadata']['input_tokens']
_SESSION_TOKENS['output_token'] += last_message['usage_metadata']['output_tokens']
_SESSION_TOKENS['total_completion_tokens'] += last_message['usage_metadata']['total_tokens']
print(f"截止目前会话 token消耗: input_token= {_SESSION_TOKENS['input_token']}, output_token={_SESSION_TOKENS['output_token']},"
f"total_token={_SESSION_TOKENS['total_completion_tokens']}")
return state
@after_agent
def log_final_metrics(state: AgentState, runtime: Runtime):
"""
在 Agent 完全结束后记录整体性能指标
"""
start_time = runtime.context.get("start_time", time.time())
duration = time.time() - start_time
total_messages = len(state.get("messages", []))
# 统计工具调用次数
tool_calls = sum(
1 for msg in state.get("messages", [])
if isinstance(msg, ToolMessage) and msg.model_dump().get("type") == "tool"
)
metrics = {
"duration_sec": round(duration, 2),
"total_messages": total_messages,
"tool_calls": tool_calls,
"final_status": "success"
}
print("----------"*5)
print(f"[after_agent] 任务完成!指标: {metrics}")
# 清理临时资源(如临时文件、会话缓存)
cleanup_temp_resources(runtime.context.get("session_id"))
return state # 通常不修改状态,仅用于观测
def cleanup_temp_resources(session_id):
if session_id:
print(f"清理会话 {session_id} 的临时资源")
# 4. 添加记忆
checkpointer = InMemorySaver()
# 5. 创建 Agent
agent = create_agent(
model=model,
tools=[get_weather, get_location,send_email],
system_prompt=system_prompt,
checkpointer=checkpointer,
middleware=[sanitize_and_track_tokens,retry_on_tool_failure,log_final_metrics]
)
# 6. 运行对话
config = {"configurable": {"thread_id": "user-001"}}
for event in agent.stream(
{"messages": [{"role": "user", "content": "使用send_email工具 给小明发送一个邮件(12345678@qq.com)问好!,直接发送即可!"}]},
config=config,
context={'user_role':'guest',"start_time":time.time()},
stream_mode="values"
):
#print(event)
event['messages'][-1].pretty_print()
print("----------"*5)
print("token计费如下:")
print(_SESSION_TOKENS)使用场景说明:
- 生成完整的调用链路日志,用于 APM 监控;
- 释放本次请求占用的资源(避免内存泄漏);
- 上报最终业务结果(成功/失败)。
四、使用场景对比总结
| 场景 | 推荐中间件 | 理由 |
|---|---|---|
| 实时过滤模型输出中的手机号 | after_model |
需在每轮模型响应后立即处理 |
| 统计整个 Agent 会话的总耗时 | after_agent |
需等待所有步骤完成 |
| 确保最终回复不含内部系统提示 | after_agent |
只需检查最终输出 |
| 在模型生成工具调用后验证参数合法性 | after_model |
必须在工具执行前拦截错误 |
| 上报用户会话结束事件到埋点系统 | after_agent |
会话级事件,只需触发一次 |
- after_model 可能被调用多次
在多轮 Agent 循环中,每次模型调用都会触发,需注意性能开销。 - after_agent 是最终状态快照
此时所有工具已执行完毕,消息历史完整,适合做最终一致性检查。 - 不要在 after_agent 中抛出异常,通常不修改状态,仅用于观测
此阶段异常会导致整个请求失败,应仅用于日志、监控等副作用操作。
两者互补,非互斥 - 生产级应用通常同时使用二者:after_model 做实时防护,after_agent 做事后分析。