目录
-
- 前言
- [1. Why nano-vllm?](#1. Why nano-vllm?)
- [2. 本期内容概览](#2. 本期内容概览)
- [3. nano-vllm 项目简介](#3. nano-vllm 项目简介)
- [4. nano-vllm 项目运行环境搭建](#4. nano-vllm 项目运行环境搭建)
- [5. 主线执行流程](#5. 主线执行流程)
- [6. Scheduler 细节](#6. Scheduler 细节)
- [7. Block Manager 细节](#7. Block Manager 细节)
- [8. Model Runner TP 并行系统](#8. Model Runner TP 并行系统)
- [9. Model Runner 细节](#9. Model Runner 细节)
- [10. Q & A](#10. Q & A)
- 结语
- 参考
前言
最近博主看了几个视频想来学习下 nano-vllm,记录下个人学习笔记,和大家一起分享交流😄
Note:一些基础的内容默认大家都会,我们的重点是关注 vLLM 推理框架的核心机制,而对于模型本身的知识例如 nano-vllm 使用的 Qwen 系列模型构建部分我们会跳过,不会讲得那么详细。
reference :https://github.com/GeeeekExplorer/nano-vllm
reference :https://www.bilibili.com/video/BV1xkrnBzE5R
reference :https://chatgpt.com/
1. Why nano-vllm?
nano-vllm 是 github 上的一个开源项目,是开源推理框架 vLLM 的一个精简版本,仅 1200 行的代码就完成了一个推理框架的搭建。
在正式开始之前,简单聊下博主为什么要学习 nano-vllm 这个项目,这里分享下一个 UP 主 video 的看法,博主觉得挺有道理的:
我认为学习大模型 infra 最好的方式就是从 nano project 开始,本质上来说系统追求的是简单、可扩展、稳定,那些看起来很大的项目其实究其本质,核心的概念也是非常简单的。为什么现在这么难懂的原因,主要是因为它要适配很多不同的硬件、不同的场景,导致代码变得很臃肿,所以我个人感觉学习大模型 infra 最好还是:一、先好读书,不求甚解,建立脉络;二、通过学习 nano project 梳理核心概念;三、最后再根据自己的个人兴趣和职业发展,选一个工业级别的大 project 认真研读。
博主也同感,像之前博主想学习 LLM Inference 框架时直接看的 llama.cpp,也就简单的跑了个 demo 后就放弃了,至于其中的核心设计完全不懂,因此,博主这次打算按照 UP 的建议从 nano project 开始,麻雀虽小,五脏俱全。
下面我们一起来看看 UP 推荐的几个 nano project:
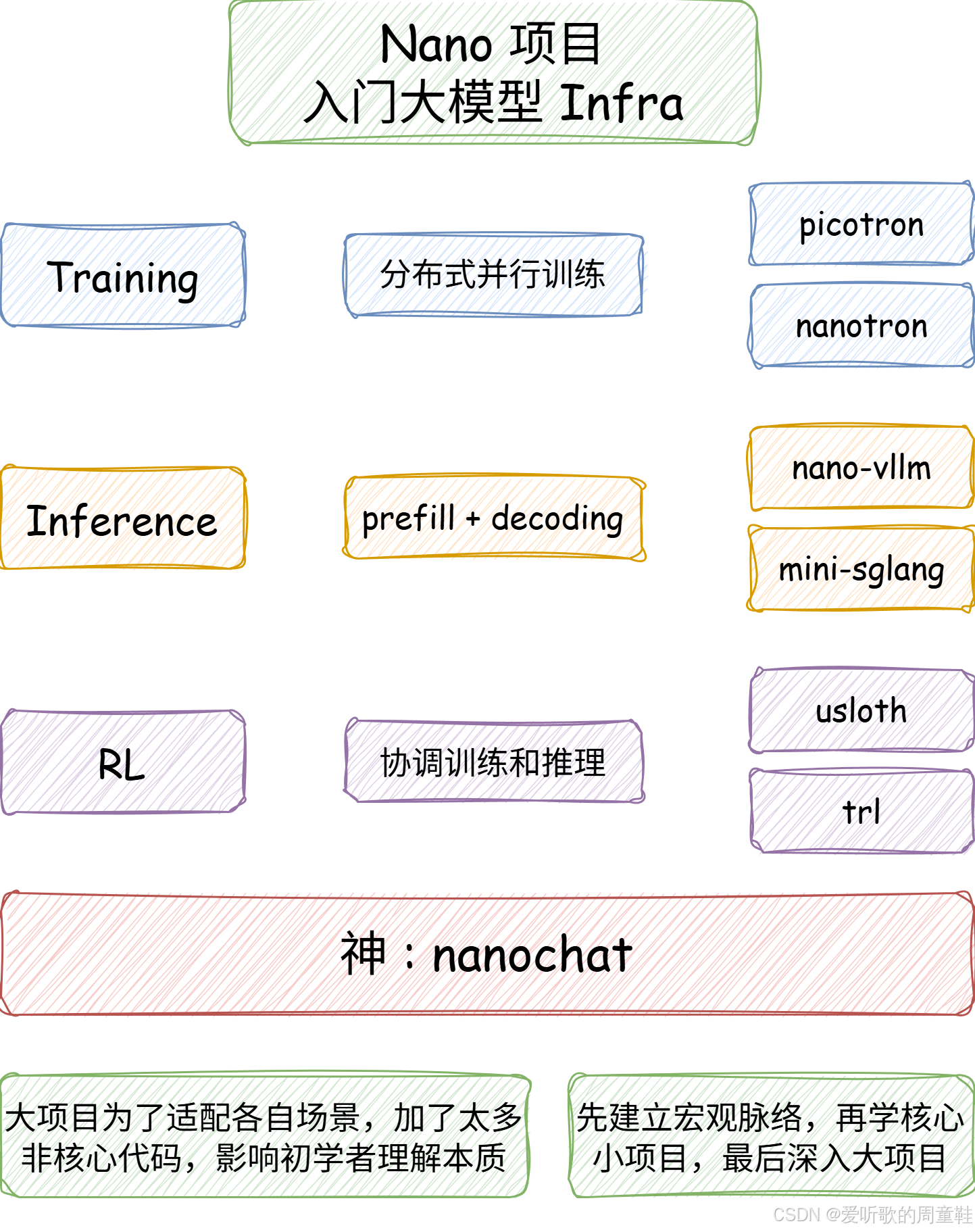
训练方面,核心概念就是分布式并行,DP、TP、EP 等等,推荐两个 nano project:picotron 和 nanotron,它们都来自于 HuggingFace,听这个名字就知道肯定是 megatron 的简化版。
第二个就是 inference 方面,inference 就是在 prefill 和 decoding 这个大框架之下,怎么更高效地利用各种各样的资源和系统技巧去提高吞吐量和降低 latency,核心的两个 nano project 必然就是 nano-vllm 和 mini-sglang。
最后一个就是强化学习,核心就是在端到端的强化学习训练当中能够更好的协调训练和推理资源以及之上的训练和推理引擎,工业界有很多 project,为了更清楚地理清细节,最好还是从 usloth 和 trl 开始。
最后再推荐一个神的 project nanochat,完整地理解大模型训练的端到端。
博主对 inference 部分比较感兴趣,选择从 nano-vllm 开始学习,大家可以根据自己的兴趣自行选择。
2. 本期内容概览
现在有两个主流的推理引擎,既适用于生产环境,也被众多推理平台所使用,一个叫做 vLLM,另外一个叫做 SGLang,但是这两个项目本身因为支持了很多很复杂的功能,所以代码量都比较庞大,不过好在这两个项目的社区都维护了两个精简的版本供学习:
vLLM 的这个精简项目叫做 nano-vllm,其 github 地址是:https://github.com/GeeeekExplorer/nano-vllm

SGLang 对应的精简项目叫做 mini-sglang,其 github 地址是:https://github.com/sgl-project/mini-sglang

nano-vllm 使用大约 1200 行 Python 代码 ,对 vLLM 推理引擎的核心实现进行了高度精简的复现 ,可以看作是一个经典的教学版实现。在此基础上,mini-sglang 进一步扩展到了 约 5000 行代码 ,对 sglang 的整体架构进行了较为完整且简化的展示 。相比 nano-vllm,mini-sglang 还额外支持了一些 在线推理(online serving)相关的场景。
因此,在本系列中,我们会先从 nano-vllm(约 1200 行代码)入手,和大家一起来理解一个 LLM 推理引擎的整体架构通常包含哪些核心组件以及 vLLM 在系统设计、算法优化和模型执行层面所做的关键优化 。在此基础上,再进一步进入 mini-sglang 的部分,对比 SGLang 和 vLLM 在架构设计上的差异 ,并分析 在线推理场景和离线推理场景在系统优化上的不同侧重点。
因此,在本系列内容中,我们会对 nano-vllm 进行系统性的讲解,并将其拆分为 上下两部分 进行解读。
在上集中,我们会重点关注 nano-vllm 的工程实现部分 ,包括整体的 系统架构设计 以及 推理请求从输入到输出的完整执行流程 。在这一部分中,对于最终执行模型计算的核心算法模块,我们会暂时将其视为一个 黑盒模块,先从系统层面理解整个推理引擎的工作方式。
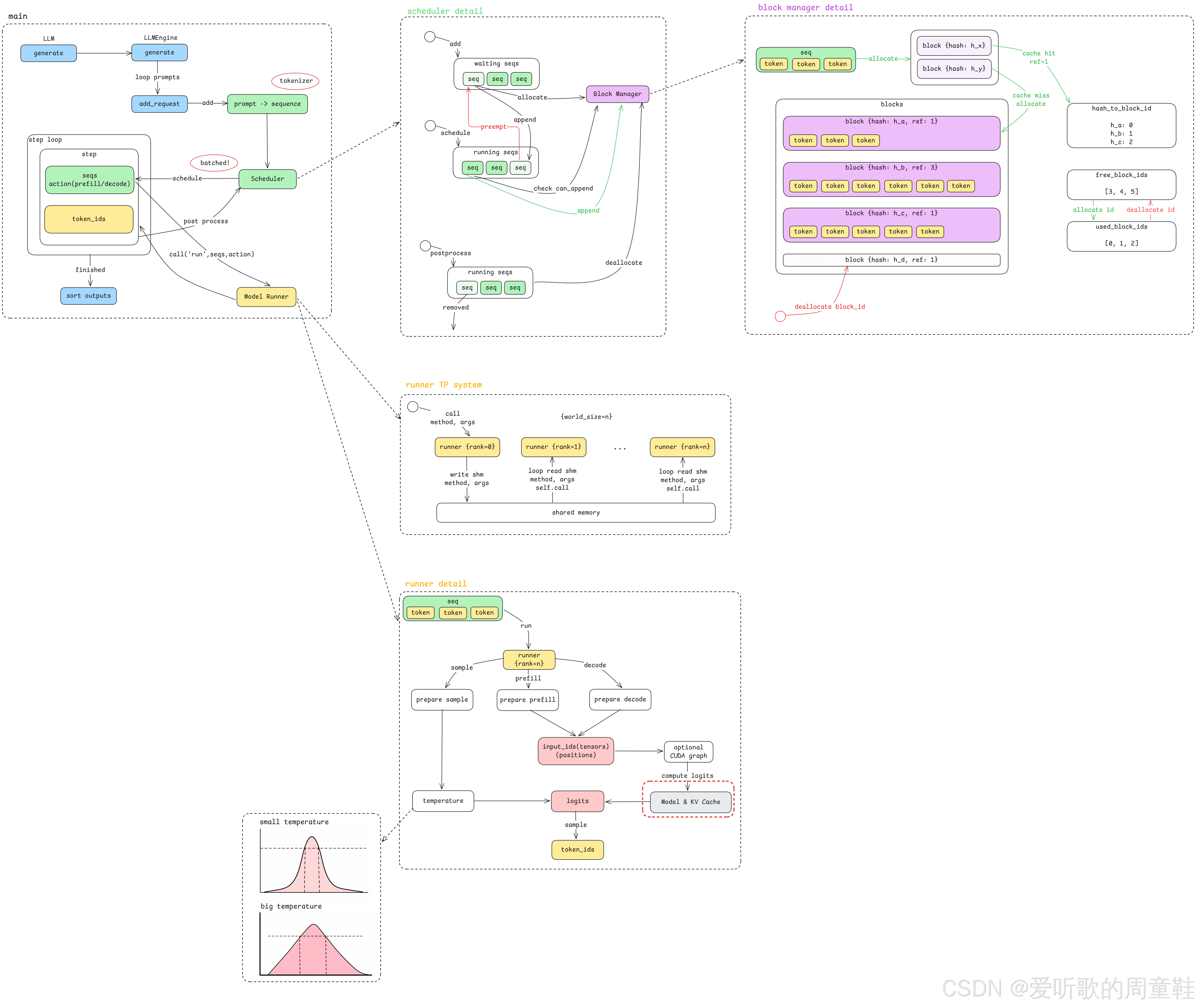
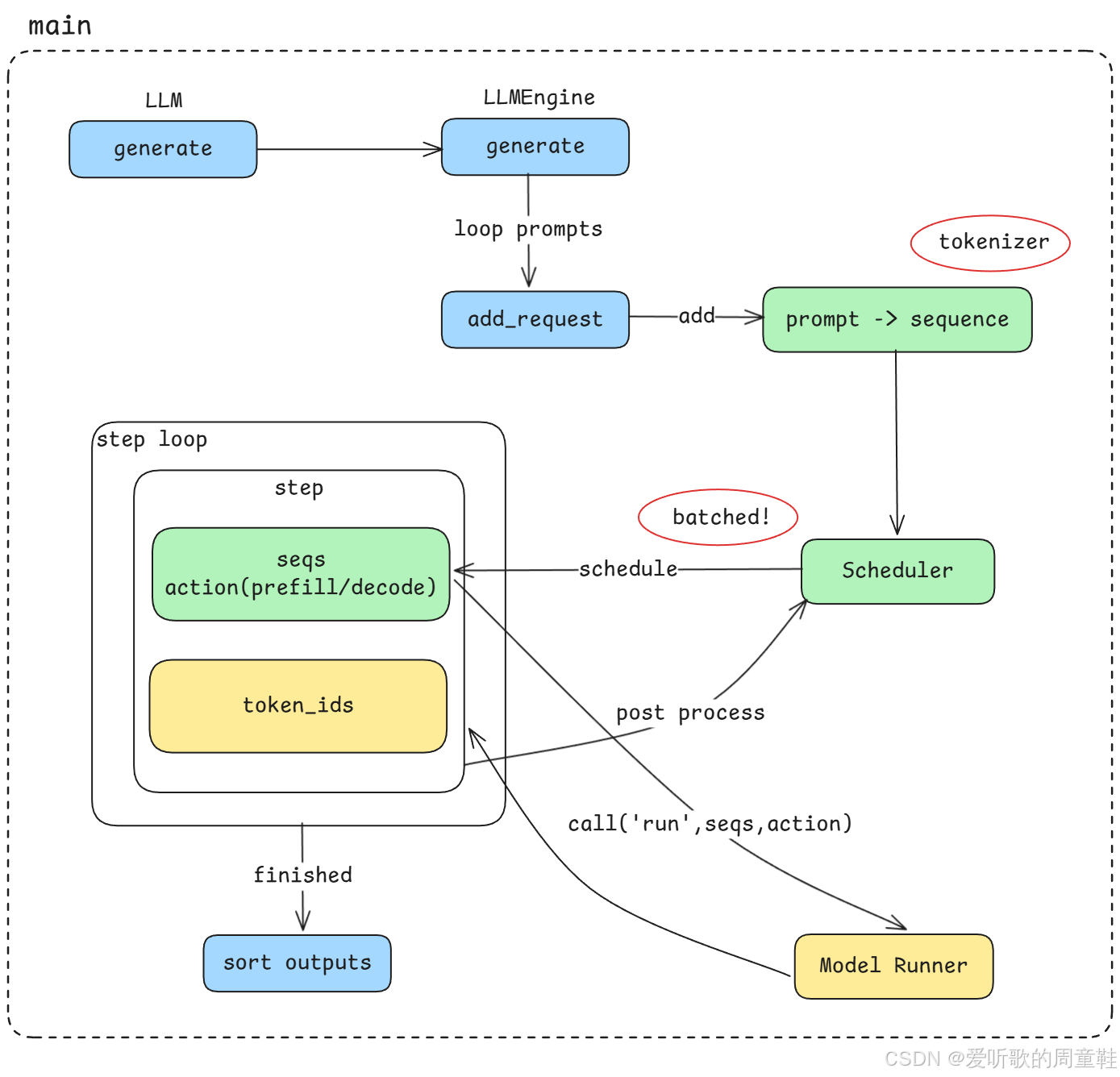
Figure 1: nano-vllm 上集整体架构图
上图展示了 上集内容将要重点分析的整体架构图 。其中,我们刚刚提到的 黑盒模块 位于右下角用红色虚线框出来的区域,即 Model & KV Cache。
可以看到,在整个推理系统架构中,模型执行模块实际上只是其中的一个组成部分。因此,在上集的讲解中,我们会暂时忽略该模块的内部实现细节,将其作为一个已经实现好的组件直接使用,从而更清晰地理解推理引擎在 调度、请求管理以及整体执行流程 方面的设计。
而在下集中,我们则会进一步深入这个 "黑盒" 的内部,实现层面的重点包括模型推理过程中涉及的一些 关键算法优化 以及推理性能提升的重要机制 - KV Cache。
通过这样的拆分方式,我们可以 先从系统架构视角理解推理引擎的整体设计,再逐步深入到模型执行层面的性能优化机制。
OK,接下来我们先来看一下本次上集内容的大纲:
- nano-vllm 简介
- 项目定位
- 作者介绍
- 上下两集内容拆分
- 架构与工程实现
- 模型优化 & KV cache
- 上集:整体架构与核心工程化实现
- 主线流程
generateprompt与sequence- 基于 scheduler 的异步 batch
- 性能优化
- 总体吞吐量(throughout)vs 单次生成延迟(latency)
step loop
- Scheduler 细节
waiting与running队列prefill与decode的含义- 与 Block Manager 的交互
- Block Manager 细节
- KV Cache 的核心控制组件
sequence与block- block 生命周期管理
- Model Runner 与 TP 并行系统
- 主线流程
首先,我们会简单介绍 nano-vllm 项目本身,包括项目的整体定位、项目的作者。
正如前面所提到的,本系列内容会拆分为上下两集进行讲解,其中上集主要关注推理引擎的整体架构与工程实现,我们会结合 架构图 与 源代码实现,逐步梳理 nano-vllm 的整体执行流程以及各个核心组件的设计思路。
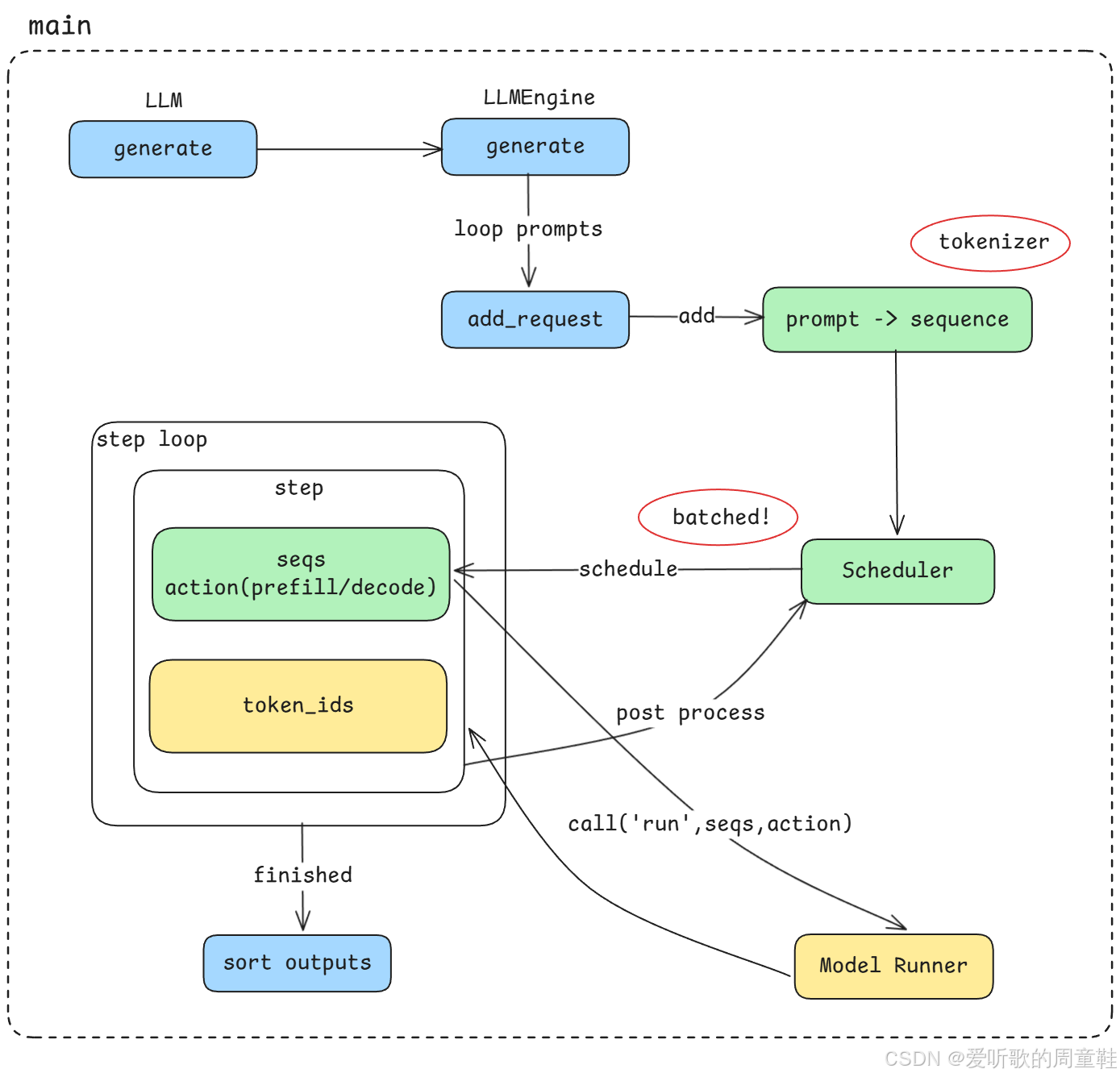
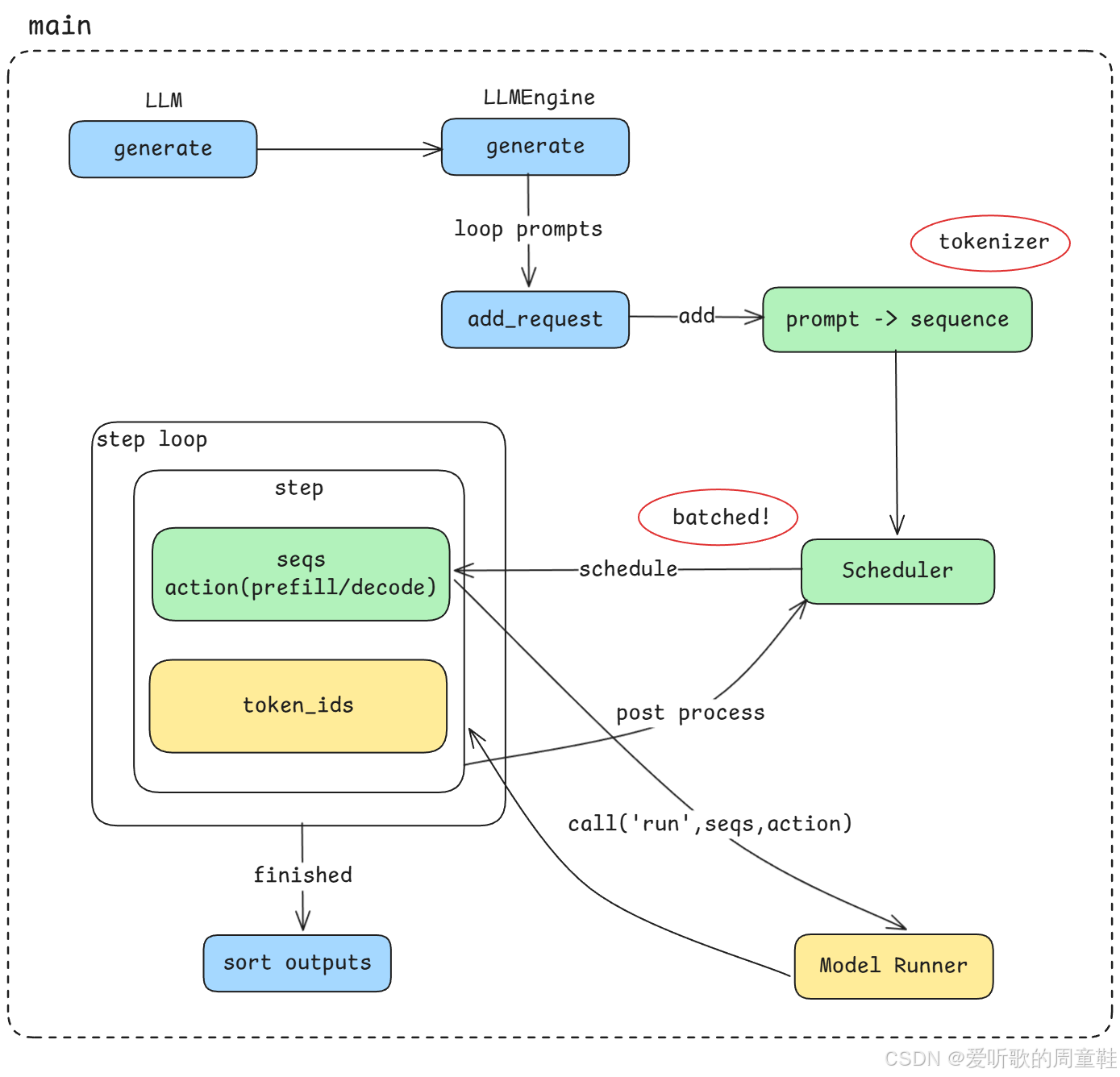
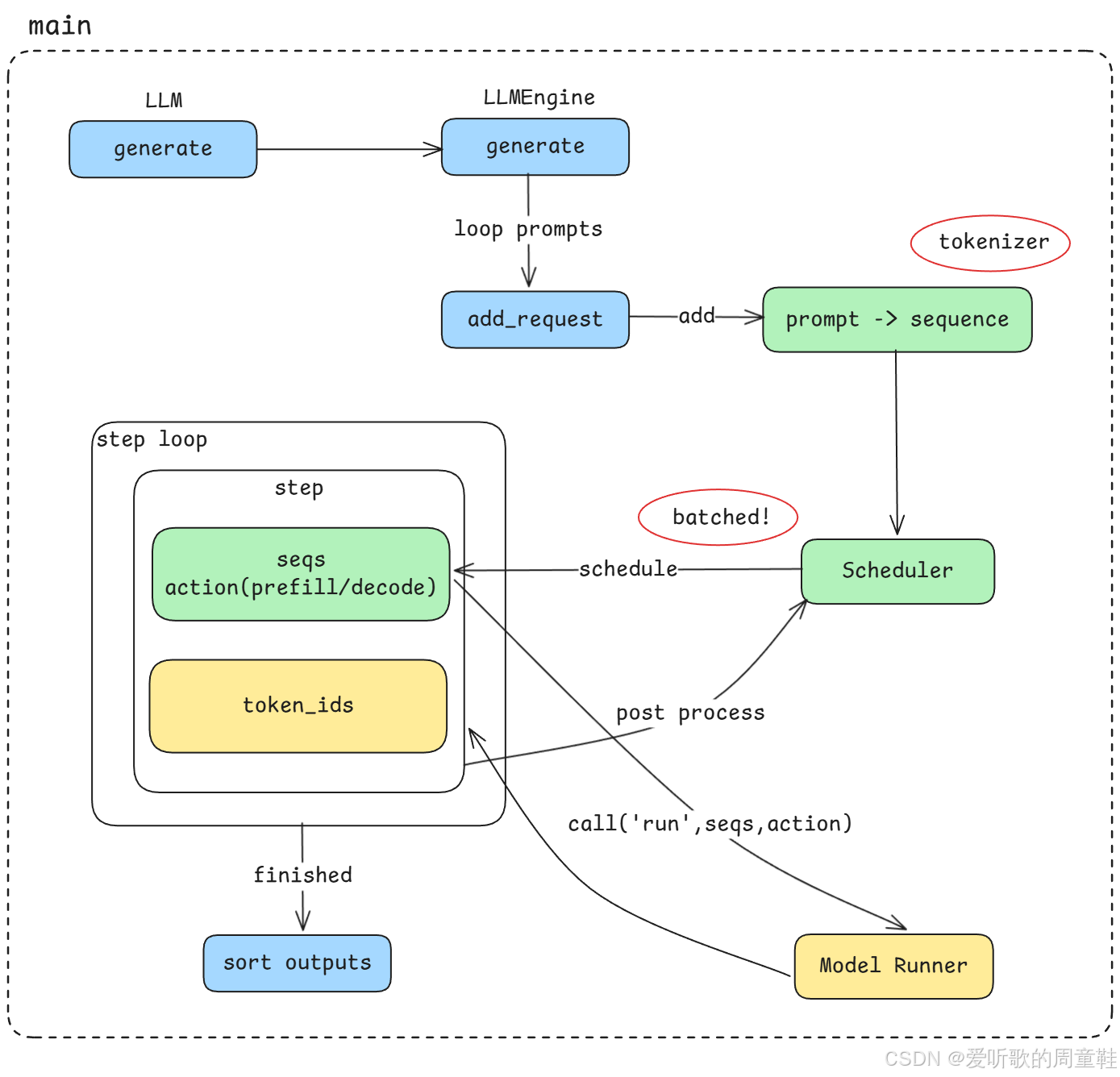
Figure 2: nano-vllm 主线执行流程
首先,我们会从整个系统的 主线执行流程(main pipeline) 开始分析,如上图所示。
这个主线流程大致分为以下几个阶段:
1. API 入口 :generate
整个推理流程从 API 调用 generate 开始,当用户发起一次文本生成请求时,请求会首先进入到推理引擎的入口模块。
2. Prompt 与 Sequence
在请求进入系统之后,首先需要处理两个非常重要的概念:
- Prompt:用户输入的文本
- Sequence:系统内部用于表示生成任务的数据结构
当输入的 prompt 被 tokenizer 处理之后,就会被转换为一个 sequence 对象,并加入到推理系统中进行调度。
3. 基于 Scheduler 的异步 Batch 调度
当多个 sequence 进入系统之后,vLLM 会通过 Scheduler(调度器) 来实现 异步批处理(asynchronous batching)。
这种调度机制是 vLLM 推理性能优化的一个核心设计,它可以:
- 动态地将多个请求组合成 batch
- 提高 GPU 地整体利用率
- 提升系统的 总体吞吐量(throughout)
不过,这种优化通常也会带来一个经典的系统设计权衡:总体吞吐量(throughout)vs 单次请求延迟(latency) 。也就是说,在提升系统整体处理能力的同时,单个请求的响应时间可能会受到一定影响。
4. Step Loop 执行循环
当 Scheduler 完成调度之后,系统会进入一个核心执行循环,也就是 step loop。
在这个循环中,系统会持续执行以下几个关键步骤:
- 根据 Scheduler 的调度策略选择需要执行的 sequence
- 决定当前 step 是 prefill 还是 decode
- 调用 Model Runner 执行模型推理
- 对生成结果进行 post process
- 更新 sequence 的状态
整个推理流程会不断重复这个 step loop,直到所有 sequence 都完成生成。
OK,以上就是我们看到的一个主线执行流程。
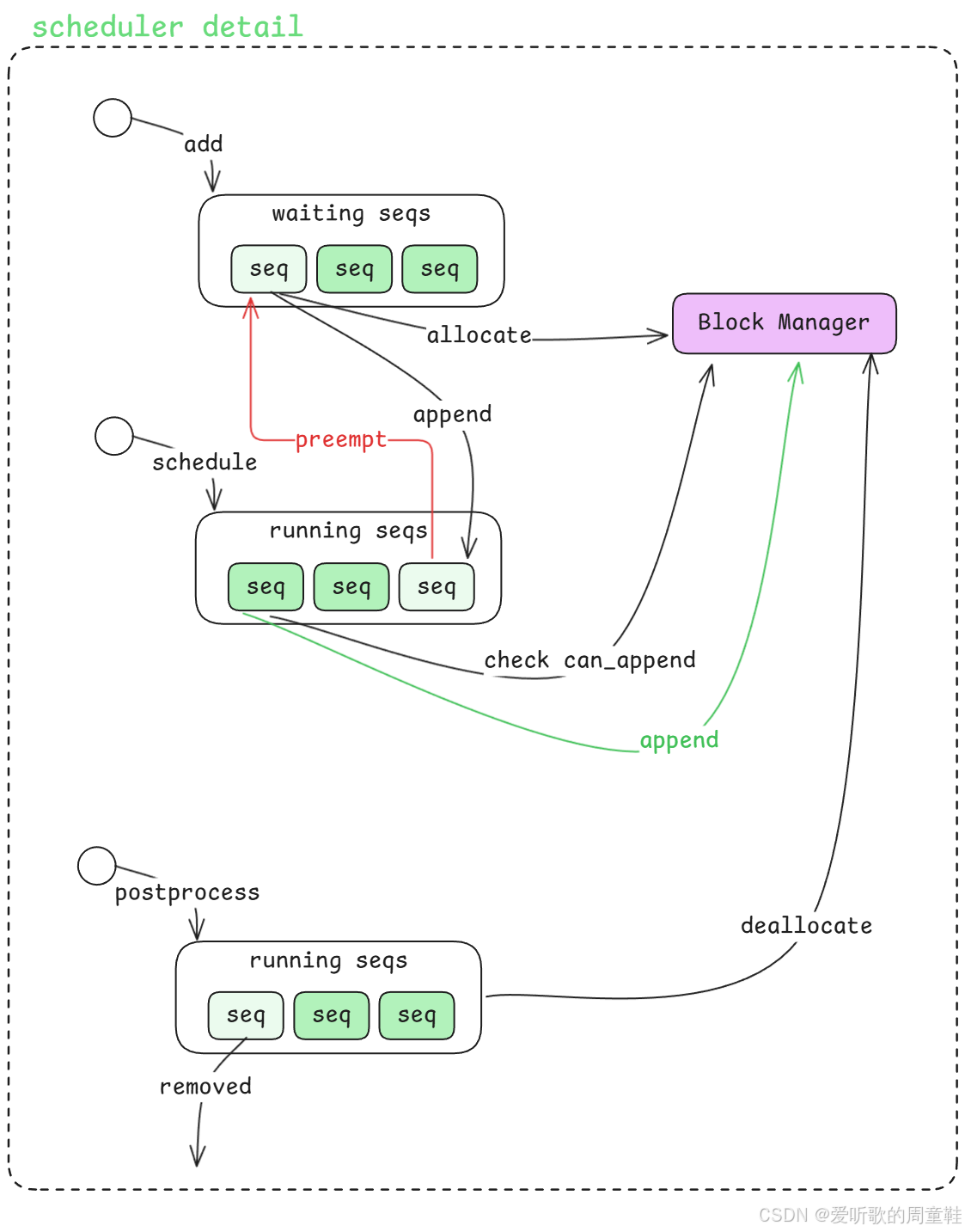
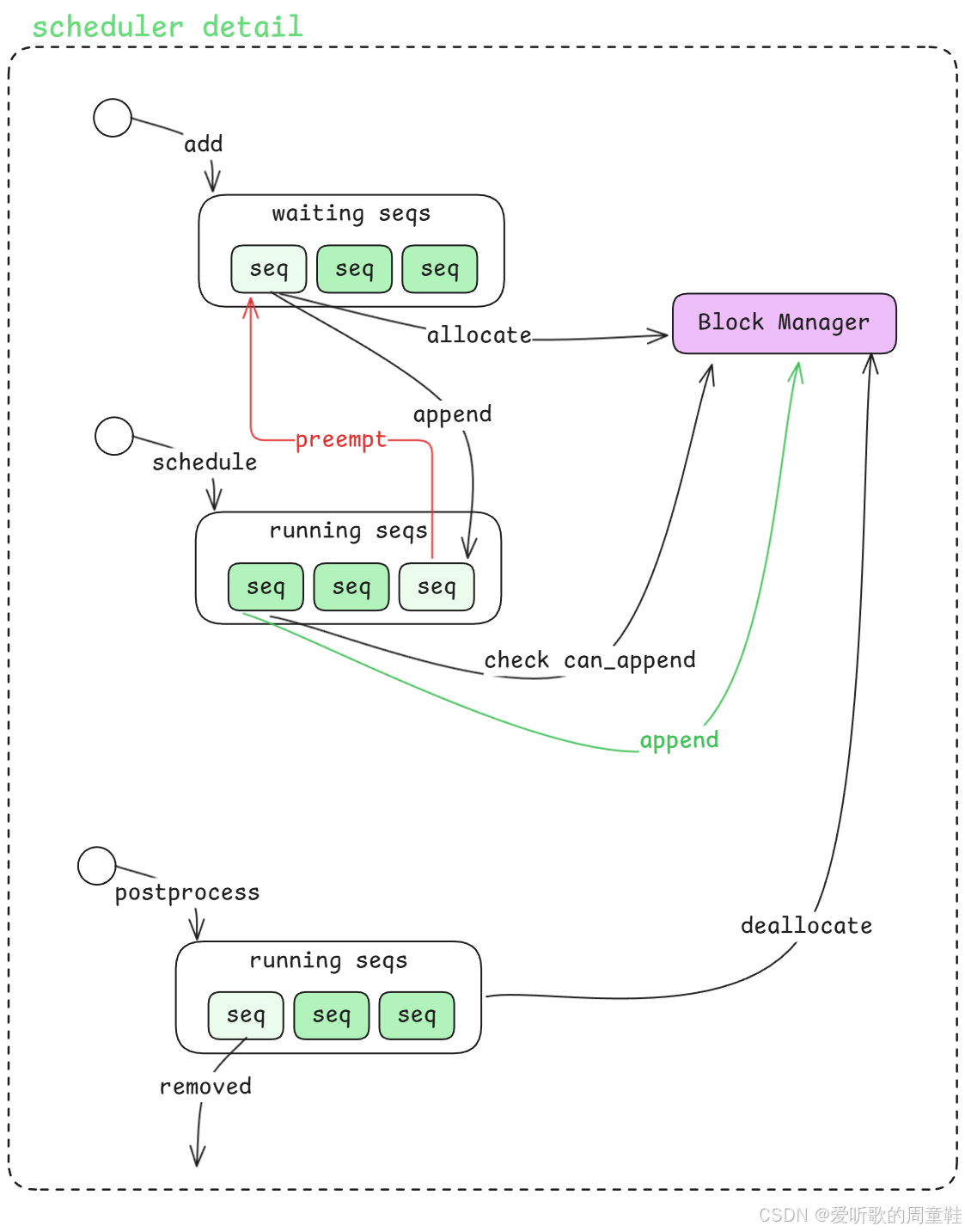
Figure 3: nano-vllm 的 Scheduler 调度器细节
在理解了整体的主线执行流程之后,接下来我们会进一步深入 Scheduler 模块 的内部实现。
从上图可以看到,在 Scheduler 中最核心的设计之一是 两类队列的管理:
- waiting queue
- running queue
当新的请求(sequence)进入系统时,会首先被加入到 waiting 队列 中;随后,Scheduler 会根据当前资源情况和调度策略,将部分 sequence 调度到 running 队列 中执行。
在这个调度过程中,还涉及两个非常重要的推理阶段,那就是 Prefill 和 Decode ,这两个阶段是当前 LLM 推理系统设计中的核心概念,其中:
- Prefill:对输入的 prompt 进行一次完整的前向计算,生成对应的 KV Cache
- Decode :在已有 KV Cache 的基础上,每一步只生成 一个新的 token,并不断更新 KV Cache
在许多 生成级推理系统 中,常常会听到一个优化策略 - PD 分离(Prefill-Decode Separation),这里的 P 和 D 正好分别对应 Prefill 和 Decode。通过将 prefill 和 decode 两个阶段拆分到不同的执行路径甚至不同的计算资源上,系统可以更好地优化 GPU 利用率与整体吞吐量。
在后续分析 nano-vllm 的 Scheduler 实现时,我们也会看到它是如何围绕 waiting / running 队列 以及 prefill / decode 执行阶段 来完成整体调度逻辑的。
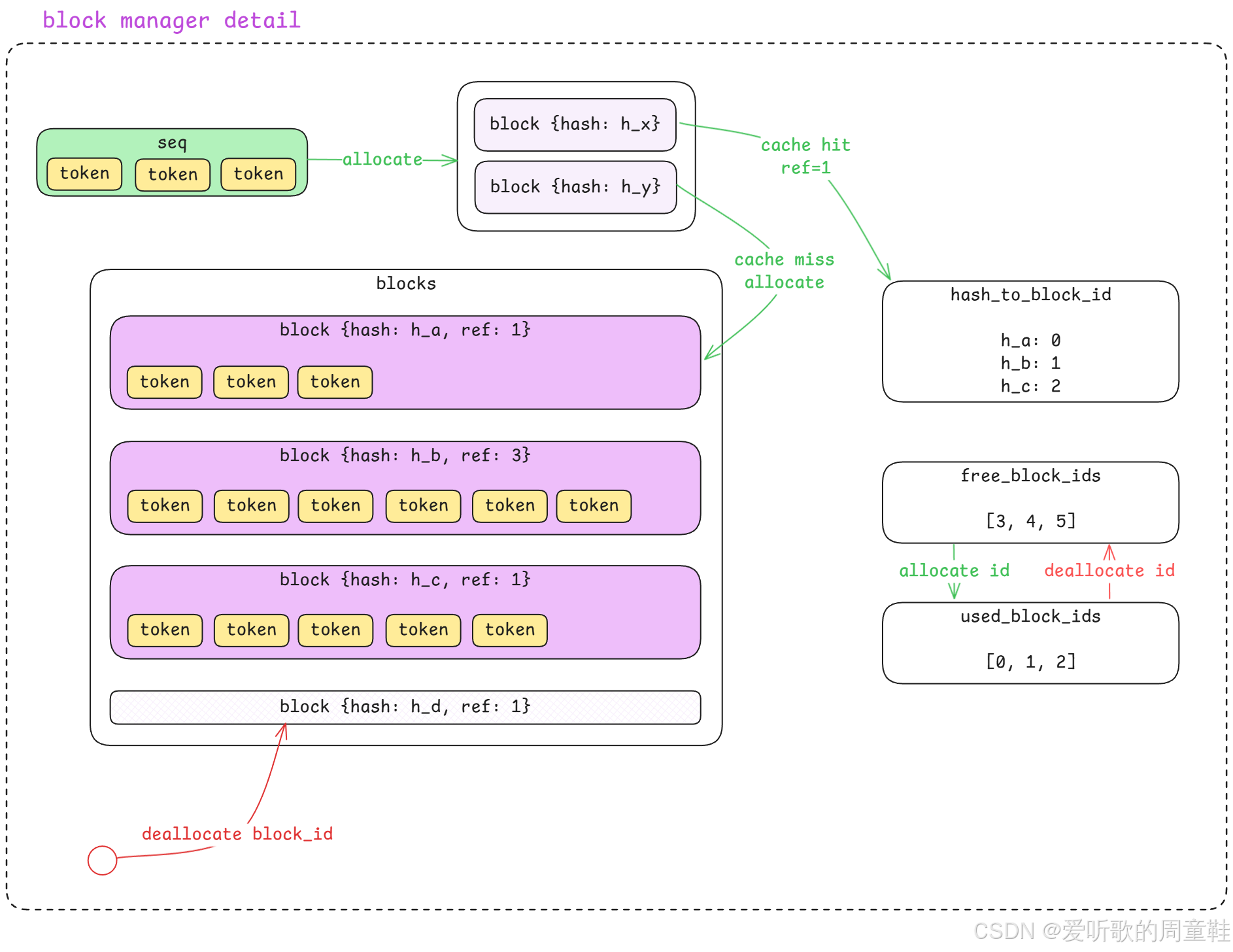
Figure 4: nano-vllm 的 Block Manager 细节
在 Scheduler 中,系统需要区分 prefill 和 decode 两种执行阶段,并维护对应的调度队列。除此之外,Scheduler 还需要与一个非常重要的组件进行交互,那就是 Block Manager ,接下来我们就来看一下 Block Manager 的整体设计。
从上图可以看到,在整个推理框架中,Block Manager 的核心作用是作为 KV Cache 的控制器 ,大家现在还不知道它是做什么的没关系,你可以先将它理解为一个 用于管理缓存的组件。
不过,在 vLLM 的设计中,KV Cache 实际上被拆分成了 控制平面(Control Plane)和数据平面(Data Plane) 两个层面,这是一种在系统设计中非常常见的设计模式。
在 控制平面 中,系统通过 Block Manager 这一 CPU 侧的数据结构来记录和管理 KV Cache 的分配状态,例如:
- 哪些 cache block 已被使用
- 哪些 block 仍然空闲
- 不同 sequence 当前使用了哪些 block
而在 数据平面 中,KV Cache 的真实数据则存储在 GPU 显存 中,用于模型推理时的高速访问。
因此,我们可以将 Block Manager 理解为 GPU 上 KV Cache 的一种 CPU 侧管理试图(metadata 管理层) 。也就是说,Block Manager 本身并不存储真正的 KV 数据,而是维护 显存中 KV Cache 的分配和引用关系。
在前面的内容中,我们已经介绍过 Sequence 这一概念了,它用于表示一个正在生成中的请求。而在 Block Manager 这一层,系统又引入了另一个重要的资源概念 - Block。
简单来说:
- Sequence:表示一个生成任务(逻辑层)
- Block:KV Cache 的最小分配单位(存储层)
当一个 sequence 在推理过程中不断生成新的 token 时,系统就需要持续为它分配新的 KV Cache block 来存储对应的 Key 和 Value。因此,在 Block Manager 内部,还需要维护 Block 的生命周期管理,例如:
- block 的 分配(allocate)
- block 的 引用计数(reference count)
- block 的 释放(deallocate)
这些机制共同保证了 KV Cache 在显存中的高效利用和复用。
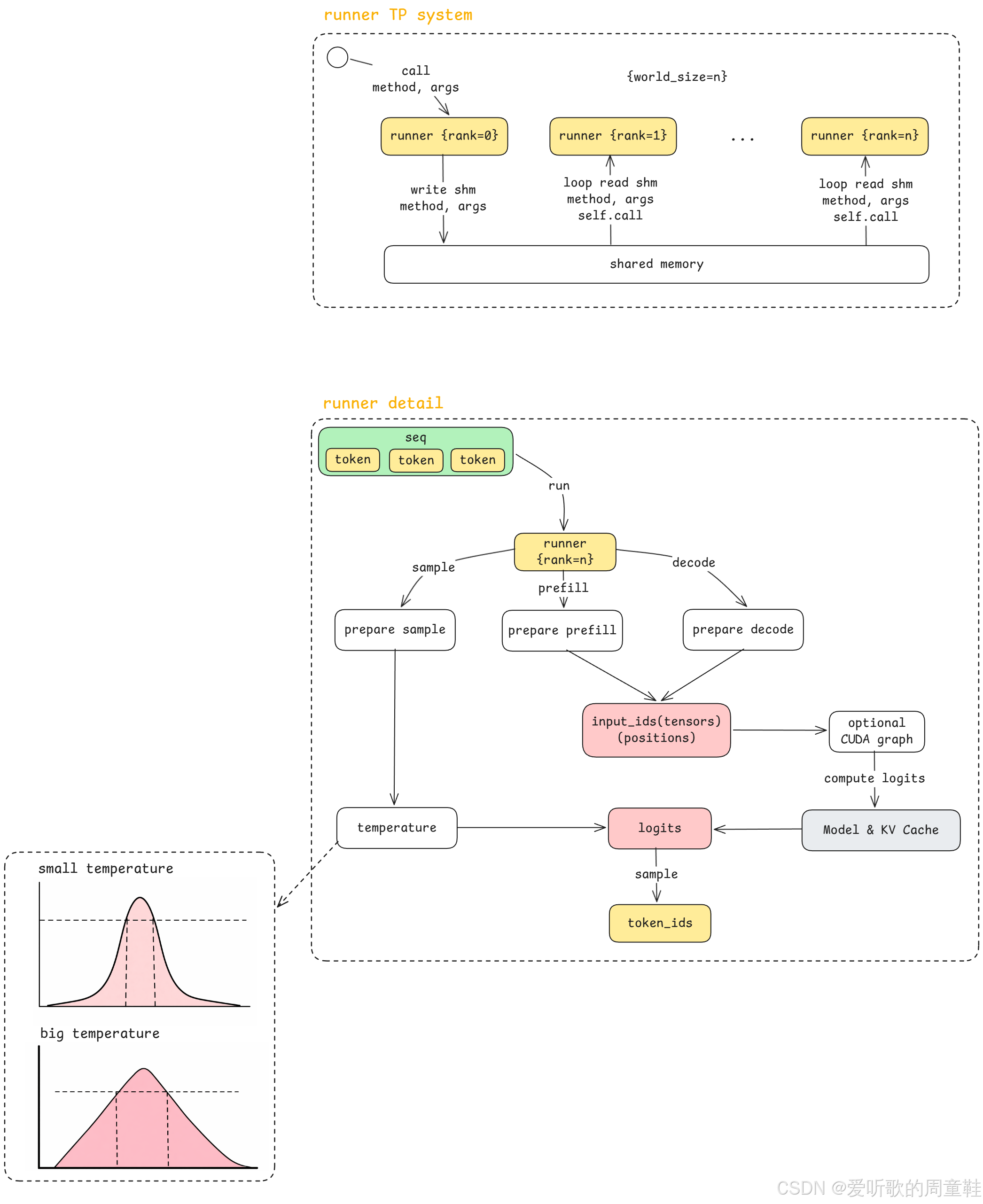
Figure 5: nano-vllm 的 Model Runner 细节
在介绍完 Block Manager 之后,接下来我们会去讲整个推理系统中的最后一个核心组件 - Model Runner 。从名字上就可以看出,Model Runner 的职责是负责执行模型推理计算,也就是最终真正运行模型前向计算的模块。
在 nano-vllm 的实现中,我们可以将 Model Runner 的内容大致拆分为两个部分:
- TP 并行系统(Tensor Parallelism)
- Runner 的具体执行流程
首先来看 TP 并行系统 ,在实际部署中,大语言模型通常规模非常庞大,而模型推理最重要的资源之一就是 GPU 显存 。当模型规模大到 单张 GPU 无法容纳完整模型权重 时,就需要通过 多 GPU 并行 的方式共同运行同一个模型,其中一种常见的并行方式就是 Tensor Parallelism(TP)。
例如,当系统使用 8 张 GPU 来运行同一个模型时,模型的计算会按照一定规则拆分到不同的 GPU 上执行,这些 GPU 需要通过通信机制进行协作,最终共同完成一次前向推理。
因此,在这一部分中,我们会重点关注:
- 在 vLLM 中 多个 GPU 的 runner 进程如何协同工作
- 不同 GPU 之间 如何进行通信与任务分发
- 各个 GPU 计算完成之后 如何汇总结果
这些内容构成了 vLLM 推理系统的并行执行基础设施。
除了并行系统之外,我们还会进一步分析 Model Runner 的执行细节 。在前面的模块中,例如 Scheduler 和 Block Manager,更多是在进行请求调度、KV Cache 管理、运行环境准备等等,而 Model Runner 则真正负责 执行一次模型推理步骤。
虽然在本篇内容中,我们仍然会将 模型内部实现以及 KV Cache 的数据层细节 视为一个黑盒,但从系统架构的角度来看,我们仍然可以观察到一些关键的执行流程。
例如,prefill 和 decode 这两个关键流程的准备工作是如何进行的;CUDA Graph 这一常见的性能优化技术发生在哪个环节,它的工作模式是怎样的;此外,使用 LLM 时常见的一些参数(如 temperature)是如何生效的,采样机制又是什么;这些我们都会在 Model Runner 里面看到。
综上所述,在本篇文章中,我们将按照以下顺序逐步解析 nano-vllm 的整体推理架构:
1. 推理系统的整体 主线流程
2. Scheduler 的调度机制
3. Block Manager 对 KV Cache 的管理
4. Model Runner 的并行系统与执行流程
通过这一系列模块的分析,我们可以从系统层面理解 一个 LLM 推理引擎是如何完成从请求输入到 token 生成的完整过程。
这就是本篇文章的一个内容的概览
3. nano-vllm 项目简介
OK,接下来,我们先简单介绍一下 nano-vllm 这个项目,nano-vllm 是 GitHub 上的一个开源项目,地址是:https://github.com/GeeeekExplorer/nano-vllm.git
该项目的目标是 从零实现一个轻量级版本的 vLLM 推理引擎,通过极简且清晰的代码结构,帮助开发者理解 vLLM 的核心设计思想:

首先,nano-vllm 是一个非常轻量级的 vLLM 实现,整个项目完全从零构建,并刻意保持了简洁、干净的代码结构。与生产级推理框架不同,nano-vllm 并不是一个持续演进、用于长期部署的系统,而是一个以学习和理解为主要目标的教学型实现。因此,大家可以看到该项目在发布之后更新并不频繁,其设计目标本身就是保持极简和稳定的代码结构,方便阅读与学习。
然后 nano-vllm 的代码规模非常小,整个核心实现仅约 1200 行 Python 代码,但代码结构却非常清晰,可读性也很高。虽然代码量不大,但如果大家此前并不熟悉大模型推理系统的整体架构,或者更多来自传统软件开发背景,那么在阅读代码时仍然会遇到不少新的概念,例如 KV Cache、Prefill / Decode、Tensor Parallelism 等等,因此,在本系列内容中,我们将分上下两篇文章对 nano-vllm 进行详细解读,和大家一起来逐步理解推理引擎的整体设计。
另外想说的是虽然 nano-vllm 是一个极简实现,但其核心功能依然非常完整,包括:
- Prefix Cache(前缀缓存机制)
- Tensor Parallelism(TP 并行)
- Torch Compile
- CUDA Graph 优化
也就是说 nano-vllm 并不是一个过度简化的 "伪实现",而是在保留关键机制的前提下,对生产级 vLLM 进行了合理的裁剪。那如果大家读过完整版的 vLLM 的一些代码,会发现他这个精简的方向还是比较得当的,因为完整的 vLLM 里面会有大量的对于不同硬件的一些支持逻辑,但是 nano-vllm 就把它裁剪成只支持特定的 NVIDIA GPU 的硬件,这样就缩减了很多的代码。
此外在完整版 vLLM 里面它还会有针对不同模型的一些优化,比如说 DeepSeek 家族模型的优化、Qwen 家族模型的优化、Llama 家族模型的优化,那在这个 nano 版本里面它只对 Qwen 这一个模型做了适配,所以它精简了非常多的代码,所以它整体的实现、裁剪的方向都是对于我们学习这个框架是不太有影响的。
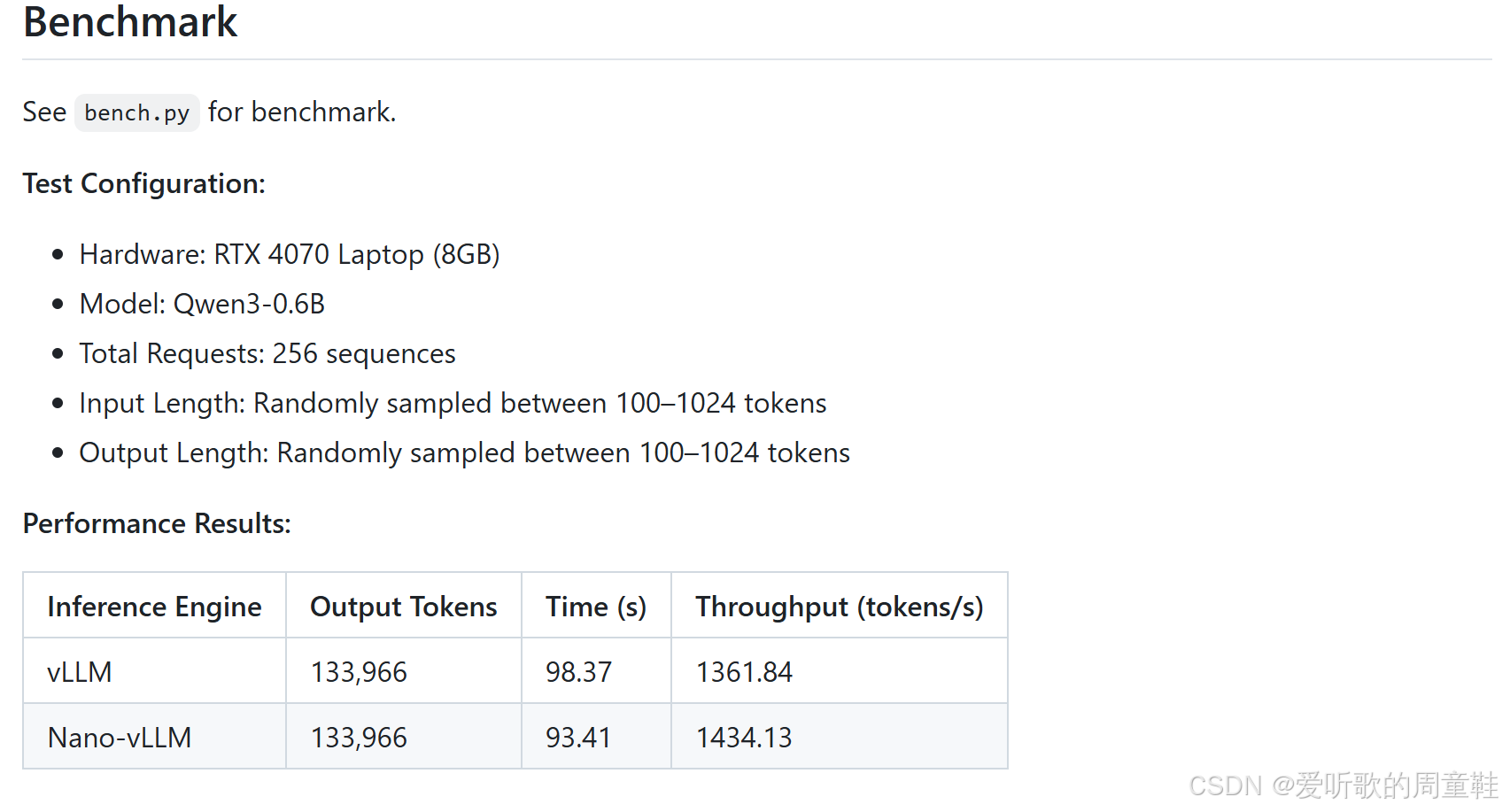
在 benchmark 部分可以看到他还做了一个基本的性能测试,然后他想证明的是说对于性能测试来看 nano-vllm 它的性能是不弱于 vLLM 的,因为 vllm 的吞吐量仅每秒 1300 多个 token,而 nano-vllm 可以跑到 1400 多个 token。
这种现象其实是符合预期的。因为 nano-vllm 去除了大量生产级系统中的通用功能与兼容逻辑,从而减少了部分额外开销。在模型规模较小、硬件资源充足的情况下,这种极简实现反而可能获得略高的吞吐表现。
当然,在真实生产环境中,完整版本的 vLLM 由于具备更完善的功能支持与更复杂的优化策略,整体表现仍然更加稳定和通用。
OK,以上就是 nano-vllm 这个项目的一些基本介绍
最后来看一下该项目的作者,从 GitHub 上可以看到这个作者他目前应该是 DeepSeek 公司的一员,而且我们其实也可以在 DeepSeek-V3、DeepSeek-R1 等重要模型的论文上看到这个作者的名字。
DeepSeek 在模型推理侧广泛采用了 vLLM 和 SGLang 等开源推理引擎,并在此基础上进行了深度优化,那所以他对于 vLLM 这个项目的理解,整个模型推理领域的理解应该都是很顶尖的,所以我们一起来学习这个项目是比较合适的。
以上就是我们对于整个项目的一个概览,接下来我们将正式进入到具体的架构还有代码的解读上去。
4. nano-vllm 项目运行环境搭建
大家可以按照 nano-vllm 的 README 文档介绍的方式通过如下指令安装:
shell
pip install git+https://github.com/GeeeekExplorer/nano-vllm.git这里博主通过 uv 工具来构建整个项目,整个流程如下:
shell
# 1. git clone project
git clone https://github.com/GeeeekExplorer/nano-vllm.git
cd nano-vllm
# 2. install uv (via pip)
conda activate base
pip install uv
# 3. build environment
uv sync
# set url (you might use it)
# uv sync --index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 4. download model
uv pip install huggingface_hub
huggingface-cli download --resume-download Qwen/Qwen3-0.6B \
--local-dir ~/huggingface/Qwen3-0.6B/ \
--local-dir-use-symlinks False
# 5. run example
uv run example.pyNote :大家如果遇到模型下载缓慢的情况,也可以从 ModelScope 下载,下载指令如下:
shell
pip install modelscope
modelscope download --model Qwen/Qwen3-0.6B --local_dir ~/huggingface/Qwen3-0.6B/由于博主显卡驱动不是最新的,无法安装最新的 flash-attn,因此简单修改了下 pyproject.toml 文件,如下所示:
shell
[build-system]
requires = ["setuptools>=61"]
build-backend = "setuptools.build_meta"
[project]
name = "nano-vllm"
version = "0.2.0"
authors = [{ name = "Xingkai Yu" }]
license = "MIT"
license-files = ["LICENSE"]
readme = "README.md"
description = "a lightweight vLLM implementation built from scratch"
requires-python = ">=3.10,<3.13"
dependencies = [
"torch==2.5.1",
"triton>=3.0.0",
"transformers>=4.51.0",
"flash-attn==2.7.4.post1",
"vllm==0.7.2",
"xxhash",
]
[project.urls]
Homepage="https://github.com/GeeeekExplorer/nano-vllm"
[tool.setuptools.packages.find]
where = ["."]
include = ["nanovllm*"]
[tool.uv]
package = true
no-build-isolation-package = ["flash-attn"]
[[tool.uv.dependency-metadata]]
name = "flash-attn"
version = "2.7.4.post1"
requires-dist = ["torch"]Note:大家可以根据自己的硬件、显卡驱动等软件环境自行修改。
大家在执行示例脚本的过程中可能会出现 TypeError: unhashable type: 'dict' 的问题,如下图所示:
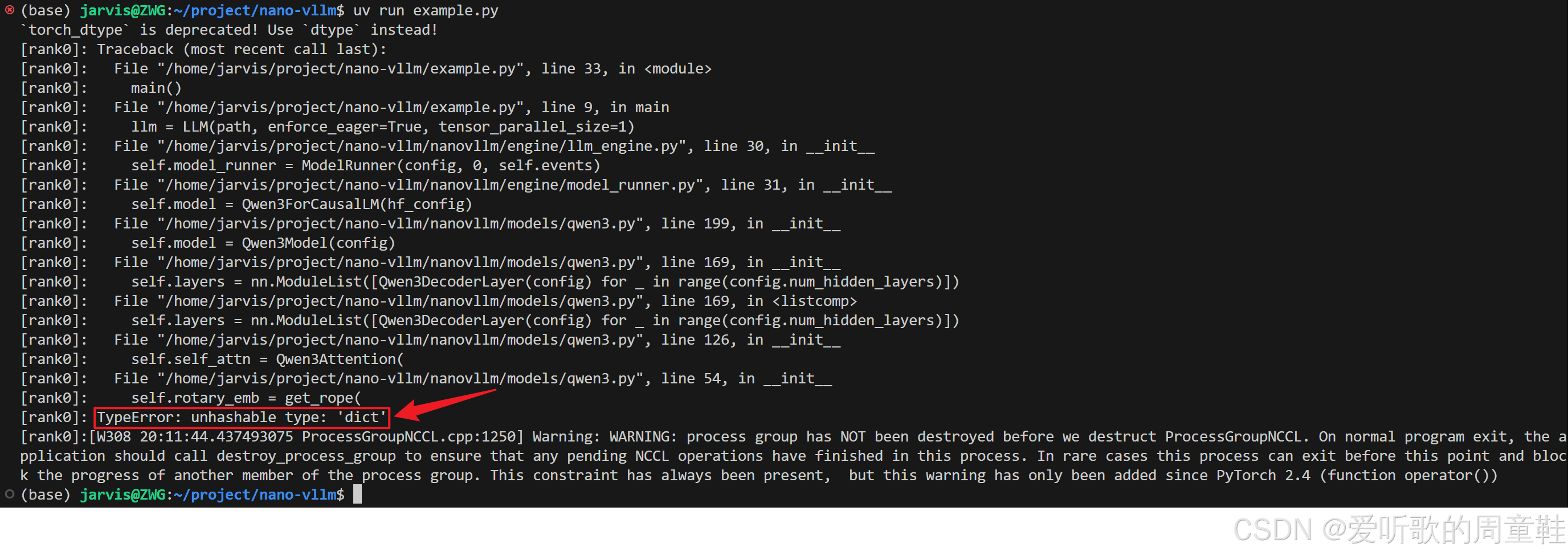
这个问题的解决办法在 nano-vllm 项目的 Issues 中有提到,具体可参考:https://github.com/GeeeekExplorer/nano-vllm/issues/167
我们只要将 nanovllm/models/qwen3.py 脚本的第 59 行修改为 rope_scaling=None 即可:
python
class Qwen3Attention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
num_kv_heads: int,
max_position: int = 4096 * 32,
head_dim: int | None = None,
rms_norm_eps: float = 1e-06,
qkv_bias: bool = False,
rope_theta: float = 10000,
rope_scaling: tuple | None = None,
) -> None:
...
self.rotary_emb = get_rope(
self.head_dim,
rotary_dim=self.head_dim,
max_position=max_position,
base=rope_theta,
rope_scaling=None, # 此处修改为 None
)修改后再次执行 uv run example.py 即可得到正确输出:
OK,环境配置完成之后接下来我们就正式来解读 nano-vllm 这个项目
5. 主线执行流程
接下来,我们正式进入 nano-vllm 源码的解读部分。
在这一部分中,我们会结合 前面绘制的系统架构图 和 对应的源码实现,逐步分析整个推理流程的执行逻辑。
首先来看主线执行流程的部分,也就是架构图中 main 虚线框内的逻辑 。在 nano-vllm 中,对外暴露的推理接口是 LLM 类中的 generate 方法,这是整个推理系统最外层的 API 入口。
在项目的 example.py 文件中,可以看到一个最简单的使用示例:
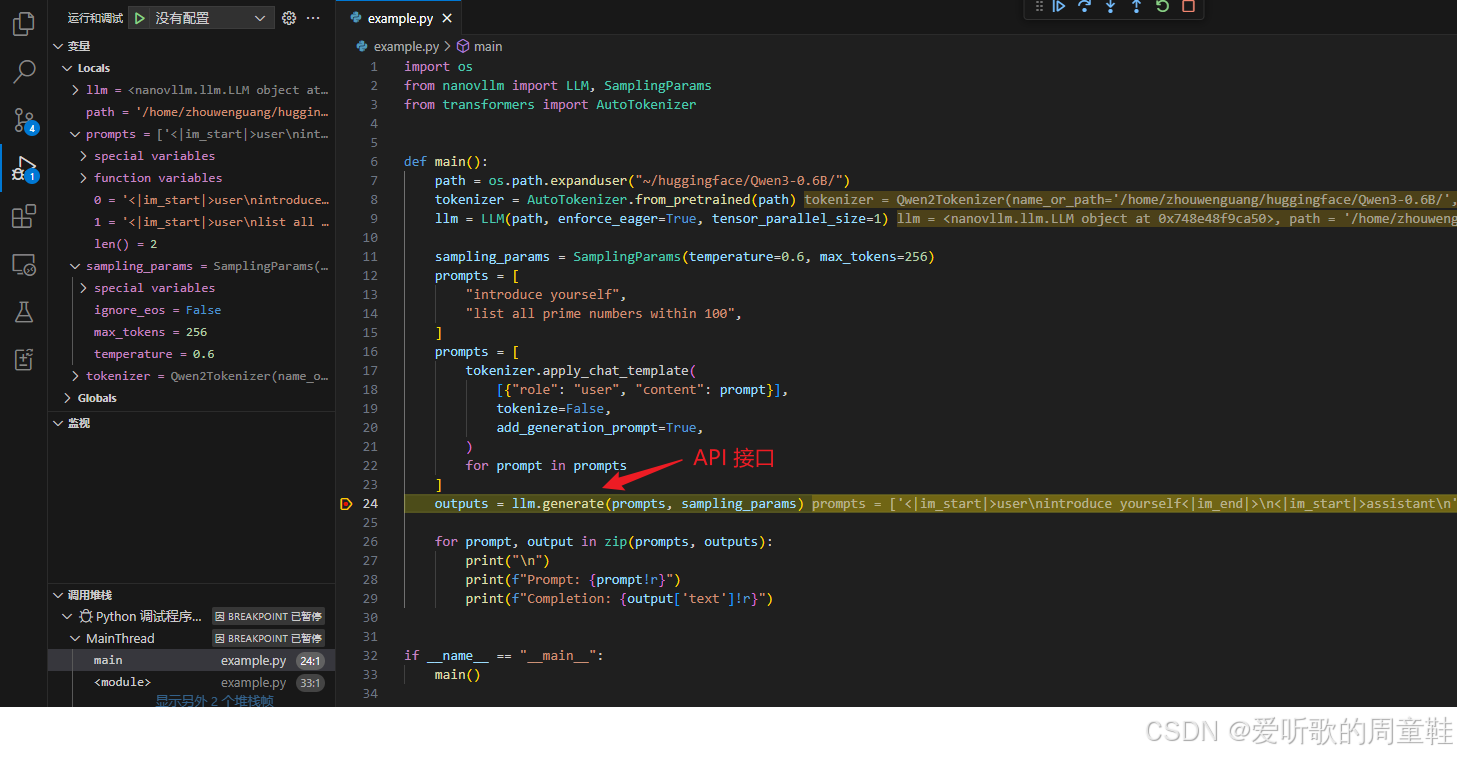
在这个示例中,首先构造了一组 prompts:
python
prompts = [
"introduce yourself",
"list all prime numbers within 100",
]这里的 prompts 是一个 字符串数组,表示一批需要进行推理的输入请求。
这种设计允许系统 同时处理多个 prompt ,而不是逐条进行推理,在后续分析中我们会看到,vLLM 的一个重点性能优化正是 通过批量处理(batching)多个请求来提升 GPU 利用率。
在构造好 prompts 之后,推理请求通过如下方式提交:
python
outputs = llm.generate(prompts, sampling_params)其中:
prompts:输入的 prompt 列表sampling_params:采样参数,例如 temperature、max_tokens 等
需要注意的是,sampling 参数并不会在推理流程的最开始阶段立即使用,在主流程的前半部分,系统主要关注的是:
- 请求解析
- prompt 处理
- sequence 构建
- 调度与批处理
而 sampling 参数通常会在 模型实际执行推理(model runner)阶段 才会发挥作用。
接下来我们来看 LLM 类的源码实现:
python
# nanovllm/llm.py
from nanovllm.engine.llm_engine import LLMEngine
class LLM(LLMEngine):
pass可以看到,这个文件的实现非常简单,LLM 类实际上只是 直接继承了 LLMEngine,并没有额外的实现逻辑。换句话说,在 nano-vllm 中 LLM 本质上就是 LLMEngine 的一个别名。
因此,当调用 LLM.generate() 时,最终执行的实际上是 LLMEngine.generate() 方法 。那大家可能会困惑为什么需要这一层抽象呢?直接用 LLMEngine 实例化不就行了吗,那其实在完整版的 vLLM 项目中,LLM 这一层并不是空的,而是承担的一些额外的职责,例如:
- 提供 同步 / 异步 engine 的封装
- 适配 OpenAI API 风格接口
- 提供更高层的用户接口
但是在 nano-vllm 中,这些工程层面的复杂逻辑都被裁剪掉了,只保留了最核心的推理流程。因此我们可以在代码中看到 LLM 类依然被保留下来,但具体实现被简化为空。
接下来,我们进入 engine 目录下 llm_engine.py 文件 ,重点来看 LLMEngine.generate() 的整体执行逻辑:
python
# nanovllm/engine/llm_engine.py
import atexit
from dataclasses import fields
from time import perf_counter
from tqdm.auto import tqdm
from transformers import AutoTokenizer
import torch.multiprocessing as mp
from nanovllm.config import Config
from nanovllm.sampling_params import SamplingParams
from nanovllm.engine.sequence import Sequence
from nanovllm.engine.scheduler import Scheduler
from nanovllm.engine.model_runner import ModelRunner
class LLMEngine:
def __init__(self, model, **kwargs):
config_fields = {field.name for field in fields(Config)}
config_kwargs = {k: v for k, v in kwargs.items() if k in config_fields}
config = Config(model, **config_kwargs)
self.ps = []
self.events = []
ctx = mp.get_context("spawn")
for i in range(1, config.tensor_parallel_size):
event = ctx.Event()
process = ctx.Process(target=ModelRunner, args=(config, i, event))
process.start()
self.ps.append(process)
self.events.append(event)
self.model_runner = ModelRunner(config, 0, self.events)
self.tokenizer = AutoTokenizer.from_pretrained(config.model, use_fast=True)
config.eos = self.tokenizer.eos_token_id
self.scheduler = Scheduler(config)
atexit.register(self.exit)
def exit(self):
self.model_runner.call("exit")
del self.model_runner
for p in self.ps:
p.join()
def add_request(self, prompt: str | list[int], sampling_params: SamplingParams):
if isinstance(prompt, str):
prompt = self.tokenizer.encode(prompt)
seq = Sequence(prompt, sampling_params)
self.scheduler.add(seq)
def step(self):
seqs, is_prefill = self.scheduler.schedule()
token_ids = self.model_runner.call("run", seqs, is_prefill)
self.scheduler.postprocess(seqs, token_ids)
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished]
num_tokens = sum(len(seq) for seq in seqs) if is_prefill else -len(seqs)
return outputs, num_tokens
def is_finished(self):
return self.scheduler.is_finished()
def generate(
self,
prompts: list[str] | list[list[int]],
sampling_params: SamplingParams | list[SamplingParams],
use_tqdm: bool = True,
) -> list[str]:
if use_tqdm:
pbar = tqdm(total=len(prompts), desc="Generating", dynamic_ncols=True)
if not isinstance(sampling_params, list):
sampling_params = [sampling_params] * len(prompts)
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp)
outputs = {}
prefill_throughput = decode_throughput = 0.
while not self.is_finished():
t = perf_counter()
output, num_tokens = self.step()
if use_tqdm:
if num_tokens > 0:
prefill_throughput = num_tokens / (perf_counter() - t)
else:
decode_throughput = -num_tokens / (perf_counter() - t)
pbar.set_postfix({
"Prefill": f"{int(prefill_throughput)}tok/s",
"Decode": f"{int(decode_throughput)}tok/s",
})
for seq_id, token_ids in output:
outputs[seq_id] = token_ids
if use_tqdm:
pbar.update(1)
outputs = [outputs[seq_id] for seq_id in sorted(outputs.keys())]
outputs = [{"text": self.tokenizer.decode(token_ids), "token_ids": token_ids} for token_ids in outputs]
if use_tqdm:
pbar.close()
return outputs需要说明的是,这里我们不会对代码进行 逐行讲解。在前面的架构图中,我们已经对核心流程做了整体说明,而源码中还包含一些与推理逻辑无关的辅助代码,例如进度条、日志等。这些部分不会影响推理系统的核心逻辑,因此这里会进行适当的简化说明。
例如,在代码中可以看到类似 tqdm 以及 pbar(process bar)相关的逻辑,这些代码主要用于在命令行中显示生成进度,并不是推理系统本身的关键部分,因此在源码分析时可以先忽略。
在 generate() 方法内部,与推理流程最直接相关的代码是下面这一部分:
python
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp)这里可以看到,系统会 遍历所有输入的 prompts ,并依次调用 add_request() 方法。
这一逻辑与我们在主线流程架构图 Figure 2 中看到的流程完全一致:
shell
LLM.generate
↓
LLMEngine.generate
↓
loop prompts
↓
add_request也就是说,generate() 方法的主要职责其实非常简单:将一批 prompt 转换为系统内部的请求,并交给调度系统进行处理。
OK,那真正与推理流程相关的第一个关键步骤,发生在 add_request() 方法中:
python
def add_request(self, prompt: str | list[int], sampling_params: SamplingParams):
if isinstance(prompt, str):
prompt = self.tokenizer.encode(prompt)
seq = Sequence(prompt, sampling_params)
self.scheduler.add(seq)在主线流程架构图 Figure 2 中我们会用不同的颜色表示当前步骤所操作的资源的一个种类,那在前三个步骤中我们使用的颜色都是蓝色,表示操作的都是提示词,也就是文本这个级别的内容。
但在这个函数中,系统会完成一个非常重要的转换:
shell
prompt (文本)
↓
token ids
↓
Sequence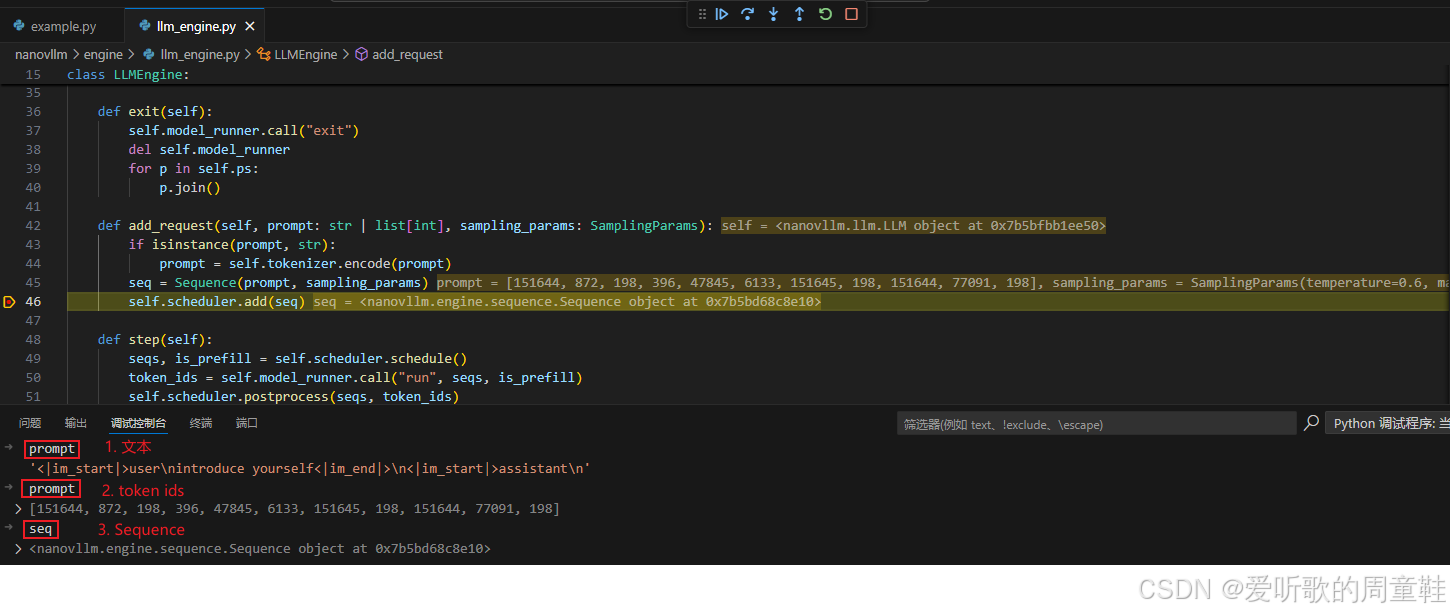
也就是说,系统会将 用户输入的自然语言 prompt 转换为 vLLM 内部使用的 Sequence 对象。
在这一步转换过程中,一个关键组件是 Tokenizer(分词器):
python
prompt = self.tokenizer.encode(prompt)Tokenizer 的作用是将 自然语言文本 转换为 模型可以理解的 token 序列。
在大语言模型中,模型真正处理的基本单位其实并不是字符,而是 token 。一个 token 可能对应一个字符、一个词、一个子词(subword)甚至是一个完整的中文词语,具体的切分方式取决于 模型所使用的 tokenizer 。因此,不同模型家族通常会使用 不同的 tokenizer,例如 Qwen tokenizer、LLaMA tokenizer、DeepSeek tokenizer、Claude / Gemini 等商业模型的专用 tokenizer。
在 nano-vllm 中,tokenizer 通过 transformers.AutoTokenizer 加载:
python
self.tokenizer = AutoTokenizer.from_pretrained(config.model, use_fast=True)当 prompt 被 tokenizer 转换为 token id 序列 之后,系统会创建一个 Sequence 对象:
python
seq = Sequence(prompt, sampling_params)在 vLLM 的推理系统中,Sequence 是一个非常重要的内部资源概念 ,一个 sequence 通常包含输入 token、已生成 token、sampling 参数、当前生成状态,后面所有推理调度都会以 sequence 为基本单位 进行管理。
这里顺便补充一下 Sequence 这个数据结构本身的定义:
python
# nanovllm/engine/sequence.py
from copy import copy
from enum import Enum, auto
from itertools import count
from nanovllm.sampling_params import SamplingParams
class SequenceStatus(Enum):
WAITING = auto()
RUNNING = auto()
FINISHED = auto()
class Sequence:
block_size = 256
counter = count()
def __init__(self, token_ids: list[int], sampling_params = SamplingParams()):
self.seq_id = next(Sequence.counter)
self.status = SequenceStatus.WAITING
self.token_ids = copy(token_ids)
self.last_token = token_ids[-1]
self.num_tokens = len(self.token_ids)
self.num_prompt_tokens = len(token_ids)
self.num_cached_tokens = 0
self.block_table = []
self.temperature = sampling_params.temperature
self.max_tokens = sampling_params.max_tokens
self.ignore_eos = sampling_params.ignore_eos
def __len__(self):
return self.num_tokens
def __getitem__(self, key):
return self.token_ids[key]
@property
def is_finished(self):
return self.status == SequenceStatus.FINISHED
@property
def num_completion_tokens(self):
return self.num_tokens - self.num_prompt_tokens
@property
def prompt_token_ids(self):
return self.token_ids[:self.num_prompt_tokens]
@property
def completion_token_ids(self):
return self.token_ids[self.num_prompt_tokens:]
@property
def num_cached_blocks(self):
return self.num_cached_tokens // self.block_size
@property
def num_blocks(self):
return (self.num_tokens + self.block_size - 1) // self.block_size
@property
def last_block_num_tokens(self):
return self.num_tokens - (self.num_blocks - 1) * self.block_size
def block(self, i):
assert 0 <= i < self.num_blocks
return self.token_ids[i*self.block_size: (i+1)*self.block_size]
def append_token(self, token_id: int):
self.token_ids.append(token_id)
self.last_token = token_id
self.num_tokens += 1
def __getstate__(self):
return (self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table,
self.token_ids if self.num_completion_tokens == 0 else self.last_token)
def __setstate__(self, state):
self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table = state[:-1]
if self.num_completion_tokens == 0:
self.token_ids = state[-1]
else:
self.last_token = state[-1]从源码上看,Sequence 本质上是 推理引擎内部对一次生成请求的运行时封装 。它并不只是保存一串 token,而是同时维护了这次请求的 唯一编号、调度状态、完整 token 序列、prompt/completion 的边界、采样参数,以及 KV Cache 对应的 block_table 信息。
因此我们可以把它理解为:在 nano-vllm 里,用户输入的 prompt 经过 tokenizer 之后,并不会直接以 "文本" 或 "裸 token 列表" 的形式继续流转,而是会被包装成一个 Sequence 对象,随后由 scheduler、block manager 和 model runner 围绕这个对象继续完成后续的调度与执行。
完成 sequence 构建之后,系统会执行:
python
self.scheduler.add(seq)这一步意味着 该生成请求正式进入推理调度系统(Scheduler) ,当前这里我们还没有看 Scheduler 具体的实现细节,那我们简单把它当成一个组件就行,我们知道在 add_request 内部做完数据转换之后把 Sequence 传给 Scheduler 就结束了。
因此,在这里,generate() 方法本身并不会立即执行模型推理,而是完成:
shell
prompt → sequence
↓
加入 scheduler随后,Scheduler 会根据系统当前的运行状态,对所有 sequence 进行调度,并在后续的 step loop 中逐步执行推理。
接下来我们继续回到主线执行流程图中:
在前面的部分中,我们已经介绍了以下几个关键步骤:
generate():推理系统的 API 入口prompt:用户输入的文本sequence:系统内部表示生成任务的数据结构
在 generate() 中,每个 prompt 都会通过 add_request() 被转换为一个 Sequence 对象,并被加入到 Scheduler 中。需要注意的是,add_request() 本身的职责其实非常简单,那就是 只负责将 sequence 提交给 scheduler ,一旦 sequence 被加入到 scheduler,add_request() 的任务就结束了。
接下来真正推动推理执行的,是 LLMEngine 内部的 step loop:
python
def step(self):
seqs, is_prefill = self.scheduler.schedule()
token_ids = self.model_runner.call("run", seqs, is_prefill)
self.scheduler.postprocess(seqs, token_ids)
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished]
num_tokens = sum(len(seq) for seq in seqs) if is_prefill else -len(seqs)
return outputs, num_tokens在这个循环中,系统会不断从 Scheduler 中取出当前被调度的 sequence,然后执行下一步推理计算。从架构角度来看,这里实际上形成了一个 典型的生产者--消费者模型:
shell
generate / add_request
↓
Scheduler
↓
step loop其中:
生产者(Producer)
LLMEngine.generate()- 负责接收用户请求
- 将 prompt 转换为 sequence
- 将 sequence 提交给 scheduler
消费者(Consumer)
step loop- 持续从 scheduler 中取出 sequence
- 执行模型推理步骤
也就是说,前端 API 接收到请求之后,并不会立即执行推理,而是 先把任务提交给调度系统 ,接着由 LLMEngine 中的另一个方法 step 去消费。
虽然 step loop 仍然由 LLMEngine 管理,但它在逻辑上可以看作是一个 独立的后台执行循环,它的职责包括:
1. 从 scheduler 中获取当前需要执行的 sequence
2. 将这些 sequence 组织成 batch
3. 调用 ModelRunner 执行模型推理
4. 将生成结果返回给 scheduler 进行后处理
因此,step loop 处理的 sequence 很可能来自 多个 generate 调用 ,而不一定与某一次 API 调用一一对应。换句话说:一次 generate 调用并不一定对应一次 step loop 执行。
如果用更直观的方式理解,可以把 scheduler 想象成一个 消息队列(message queue):
shell
Producer (generate)
↓
Scheduler
↓
Consumer (step loop)在这种模型中生产者只负责 提交任务 ,而消费者只负责 处理任务,二者之间并不需要严格的一一对应关系。例如有时 scheduler 中可能暂时没有任务,step loop 会空转;有时 scheduler 中积累了大量 sequence,step loop 会一次处理一个较大的 batch,这种行为在消息队列系统中是非常常见的。
那为什么要做这种前后台的拆分呢?🤔这种设计的核心原因,其实就是图中红框标出的关键能力:Scheduler 的批处理能力(batching)。
在实际运行中,可能会出现以下情况:
- 一次
generate()调用传入 多个 prompt - 多个用户同时调用
generate() - 系统短时间内积累了多个请求
这些请求最终都会被转换为多个 sequence ,并统一进入 scheduler。随后,scheduler 会根据当前系统资源情况,例如 GPU 可容纳的 batch size、当前运行的 sequence 数量,尽可能将多个 sequence 合并为一个 batch ,然后交给后续的 step 执行。也就是说,scheduler 会尽可能地将多个请求 聚合在一起统一执行,以提升 GPU 的利用率。
这里还有一个点值得大家注意,那就是 scheduler 的 batch 与请求内容的语义完全无关。也就是说,被组合在同一个 batch 中的 sequence 可能来自不同用户,可能对应完全不同的问题,甚至可能来自不同时间的请求,例如:
shell
sequence 1 → "介绍一下你自己"
sequence 2 → "列出 100 以内的质数"
sequence 3 → "解释 Transformer 模型"这些请求在语义上完全没有关联,但在推理系统内部,它们仍然可以被 合并到同一个 batch 中执行 。原因很简单:GPU 只关心计算效率,而不关心文本语义 ,因此,在 vLLM 的设计中,调度与 batching 的逻辑完全是 以计算效率为中心,而不是以请求语义为中心。
接下来我们继续分析 step loop 的执行过程:
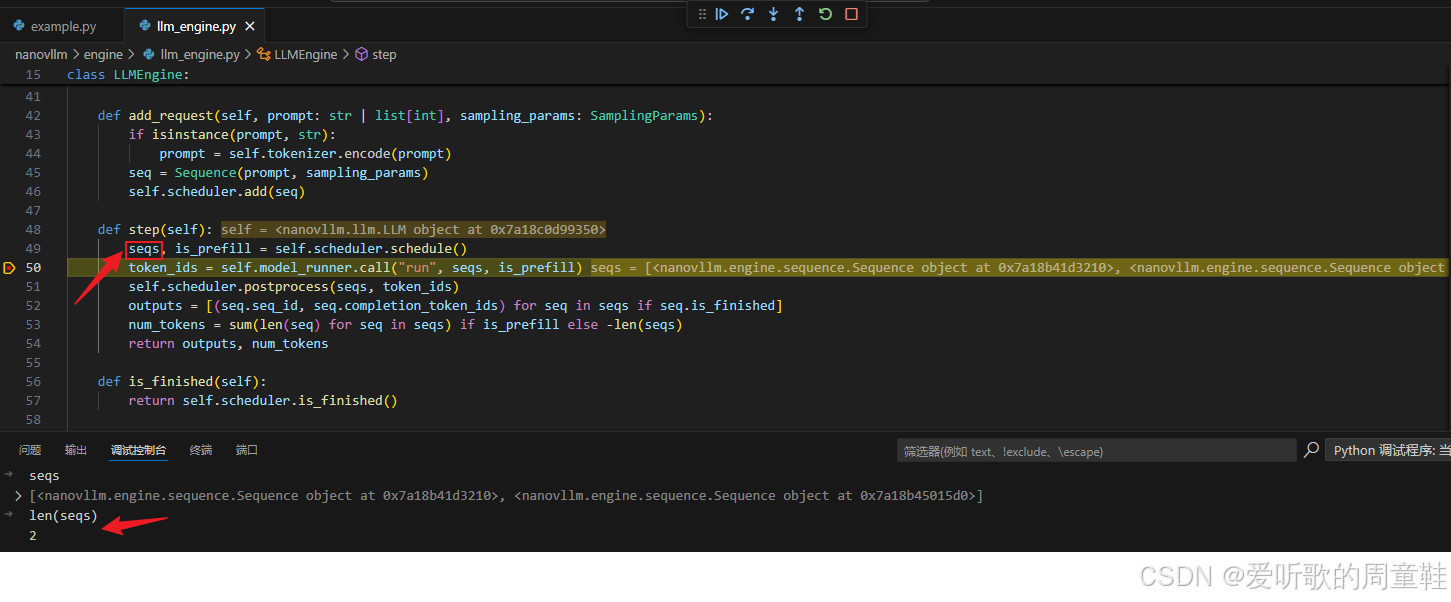
在前面的部分中已经提到,generate() 会不断将 Sequence 提交到 Scheduler 中,而 step loop 则负责从 Scheduler 中 消费这些 sequence 并执行推理计算。
需要注意的是,Scheduler 返回的并不是 单个 sequence ,而是 一组 sequence 。这一点在架构图和代码中都有所体现:我们使用的是 seqs ,这里使用复数形式,表示系统每次调度处理的是 一个 batch 的 sequence。
因此,在整个流程中可以看到一个明显的差异:
shell
add_request → 单个 sequence
step loop → 一批 sequence也就是说请求进入系统时是 逐个加入 ,实际执行推理时是 批量处理,这正是 vLLM 能够提高 GPU 利用率的重要原因。
除了返回一组 sequence 之外,Scheduler 还会返回一个非常关键的信息:
python
seqs, is_prefill = self.scheduler.schedule()这里的 is_prefill 表示当前 batch 需要执行的动作类型,包括 Prefill 和 Decode,这是大模型推理中非常核心的两个阶段。
前面我们也提到过,Prefill 指的是模型在处理 输入 prompt 时的计算阶段。在这一阶段中,模型会将输入的 prompt token 一次性送入模型,计算对应的 KV Cache。可以理解为:
shell
prompt tokens
↓
模型前向计算
↓
生成 KV Cache这个过程通常发生在 一次生成任务刚开始时,从用户视角来看,在 Prefill 阶段模型正在计算但还没有任何 token 输出。
当 Prefill 完成之后,推理就会进入 Decode 阶段 。在 Decode 阶段中,模型会 逐步生成新的 token 。每一次 Decode 通常只生成 一个 token,然后再将这个 token 加入 sequence,并继续下一轮计算。
因此,对于一个 sequence 来说,推理流程通常是:1 次 Prefill + N 次 Decode。
当 Scheduler 返回一组 sequence 和一个执行动作(prefill / decode)之后,step loop 会将这些信息传递给下一个核心组件 Model Runner:
python
token_ids = self.model_runner.call("run", seqs, is_prefill)在这一阶段中,Model Runner 负责真正执行模型的前向计算,并最终返回 GPU 计算得到的 token id ,也就是模型预测出的下一个 token。那 Model Runner 的细节我们也还没看,这里暂时把它当成一个黑盒就行。随后,step loop 会将这些 token 交回给 Scheduler 进行后处理,例如:更新 sequence、追加新 token、判断是否结束等等。
这里之所以称为 step loop,是因为这个过程会不断循环执行,只要 Scheduler 中仍然存在未完成的 sequence,系统就会持续执行:
shell
schedule
↓
model_runner.run
↓
postprocess
↓
repeat直到所有 sequence 都进入 FINISHED 状态。
当所有 sequence 都完成生成之后,系统会将生成结果重新整理为最终输出:
python
outputs = [outputs[seq_id] for seq_id in sorted(outputs.keys())]
outputs = [{"text": self.tokenizer.decode(token_ids), "token_ids": token_ids} for token_ids in outputs]这里有个排序的过程,那为什么需要排序呢?原因在于 推理过程是并行执行的 ,在 step loop 中,一批 sequence 会同时进入 model_runner.run() 执行模型推理,而不同 sequence 的执行时间可能不同。因此输入顺序并不等于输出顺序,为了保证最终返回结果与输入 prompt 的顺序一致,系统会根据 seq_id 对结果进行重新排序,这样用户最终看到的输出仍然能够正确对应,从而避免并行执行带来的 乱序问题。
Q & A
Q:这里博主其实有一个疑问:如果两个请求的 sequence 难度不同,那么在 batch 推理时,简单的问题是否必须等待复杂的问题一起完成才能返回结果?
举个简单的例子,假设有两个用户 A 和 B,用户 A 的 prompt 是 "你好!",用户 B 的 prompt 是 "请列出 1~1000 之间所有的素数"。
对于 LLM 来说,A 的问题可能只需要生成一句简单的问候语,例如 "你好,请问今天有什么可以帮助你的?",而 B 的问题则需要先理解素数的定义,然后逐个枚举 1~1000 之间的整数并判断是否为素数。显然,两者的 推理复杂度和生成长度差异非常大。
如果这两个请求被放在同一个 batch 中执行,并且必须等到整个 batch 完成之后才能返回结果,那么用户 A 是否需要一直等待用户 B 的生成完成?如果 B 的回答非常长,这是否会影响系统的响应速度?
A :这个问题其实非常关键,它涉及到 批处理(batching)在推理系统中的取舍 。在后续分析 scheduler 的实现时,我们会看到 vLLM 是如何在 吞吐量和响应延迟之间进行权衡 的。
回到主线流程图中:
我们已经看到 Scheduler 会尽可能将多个 sequence 合并成一个 batch 进行处理,主要是因为 batch 批处理能够带来一定的性能提升,那大家可以来思考下 批处理为什么能够带来性能提升呢?
其实原因在于 GPU 推理过程本身存在一定的固定开销 ,例如在 model_runner.run() 执行时,通常会涉及 CUDA kernel 启动、CPU → GPU 数据拷贝、Tensor 构建与调度、GPU kernel 调度等等,这些步骤都存在 固定开销(fixed overhead) 。因此,推理的总成本可以粗略理解为:总成本 = 固定开销 + token 计算开销
如果系统每次只处理 一个 sequence 或一个 token ,那么这些固定开销就会被频繁触发,而当系统将多个 sequence 合并成一个 batch 一起处理时 :总成本 = 一次固定开销 + 多个 sequence 的 token 计算。
这样一来,固定开销就被多个请求共同摊销,从而提高 GPU 的利用率,这也是 batch 推理能够提升性能的核心原因。
不过这里需要注意一个非常重要的事实,那就是 Batch 提升的是系统吞吐量,而不是单请求延迟 ,也就是说 吞吐量(Throughput)会上升,但单个请求的延迟(Latency)可能反而会增加。
原因很简单,假设 generate() 一次传入三个 prompt,如果 Scheduler 将它们组成一个 batch 进行推理,那么三个 sequence 会同时开始执行并且在全部完成之后一起返回。因此,对于任意一个请求来说,它都需要等待整个 batch 推理完成,也就是说三个请求 → 一起开始 → 一起结束,如果其中某一个 sequence 的生成时间特别长,那么其他 sequence 也需要等待它完成。
反过来,如果系统 每次只处理一个 prompt ,虽然这样做会带来更多 GPU 启动开销,从而降低总体吞吐量,但每一个请求都可以 更快地得到返回结果。
换句话说:大 batch 情况下,吞吐量高,但单请求延迟增加;小 batch 情况下,延迟更低,但 GPU 利用率下降。因此,在推理系统中通常需要在两者之间做出权衡。
在实际系统中,通常可以通过 调整 batch 大小 来平衡这两种指标:
- batch size ↑ → GPU 利用率 ↑ 系统吞吐 ↑ 单请求延迟 ↑
- batch size ↓ → GPU 利用率 ↓ 系统吞吐 ↓ 单请求延迟 ↓
因此,在推理服务中并不存在一种 同时最优 的配置,系统设计者需要根据具体场景进行取舍,例如在线推理服务更关注 延迟 ,离线批处理更关注 吞吐量。
那这里呢,你就需要在总体吞吐和单次生成之间做一下取舍,然后取舍的方式是什么呢,就是通过把 batch 的数量调大或者调小,batch 越大总体吞吐越好,batch 越小单次生成的等待时间越短,所以这就是要取舍的一个点,它是没有一个两个都能够兼顾的这样的一个方法的
至此,我们已经理解了主线流程中的核心逻辑:
1. generate() 将 prompt 转换为 Sequence 并提交到 Scheduler
2. Scheduler 将多个 sequence 批量调度
3. step loop 持续消费 scheduler 中的任务
4. 调用 model_runner.run() 执行 GPU 推理
5. 直到所有 sequence 完成为止
之所以这个流程比较容易理解,是因为在这里我们暂时把两个关键组件当作 黑盒 来看待:
- Scheduler:负责调度与批处理
- Model Runner:负责执行模型推理
接下来,我们就会分别深入分析这两个组件的内部实现,看看它们是如何支撑整个推理系统运行的。
6. Scheduler 细节
接下来我们沿着主线流程继续深入,来看第一个相对复杂的组件 Scheduler:
python
# nanovllm/engine/scheduler.py
from collections import deque
from nanovllm.config import Config
from nanovllm.engine.sequence import Sequence, SequenceStatus
from nanovllm.engine.block_manager import BlockManager
class Scheduler:
def __init__(self, config: Config):
self.max_num_seqs = config.max_num_seqs
self.max_num_batched_tokens = config.max_num_batched_tokens
self.eos = config.eos
self.block_manager = BlockManager(config.num_kvcache_blocks, config.kvcache_block_size)
self.waiting: deque[Sequence] = deque()
self.running: deque[Sequence] = deque()
def is_finished(self):
return not self.waiting and not self.running
def add(self, seq: Sequence):
self.waiting.append(seq)
def schedule(self) -> tuple[list[Sequence], bool]:
# prefill
scheduled_seqs = []
num_seqs = 0
num_batched_tokens = 0
while self.waiting and num_seqs < self.max_num_seqs:
seq = self.waiting[0]
if num_batched_tokens + len(seq) > self.max_num_batched_tokens or not self.block_manager.can_allocate(seq):
break
num_seqs += 1
self.block_manager.allocate(seq)
num_batched_tokens += len(seq) - seq.num_cached_tokens
seq.status = SequenceStatus.RUNNING
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)
if scheduled_seqs:
return scheduled_seqs, True
# decode
while self.running and num_seqs < self.max_num_seqs:
seq = self.running.popleft()
while not self.block_manager.can_append(seq):
if self.running:
self.preempt(self.running.pop())
else:
self.preempt(seq)
break
else:
num_seqs += 1
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, False
def preempt(self, seq: Sequence):
seq.status = SequenceStatus.WAITING
self.block_manager.deallocate(seq)
self.waiting.appendleft(seq)
def postprocess(self, seqs: list[Sequence], token_ids: list[int]) -> list[bool]:
for seq, token_id in zip(seqs, token_ids):
seq.append_token(token_id)
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens:
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
self.running.remove(seq)我们先从代码看起,在 Scheduler 的内部,我们会看到两个非常核心的数据结构:waiting sequences 和 running sequences,在代码中,它们分别被实现为两个队列:
python
self.waiting: deque[Sequence] = deque()
self.running: deque[Sequence] = deque()因此,我们在架构图中画出的 waiting seqs 和 running seqs,实际上与代码结构是一一对应的。
当一个新的请求进入系统时,对应的 Sequence 会首先进入 waiting 队列 ,这一过程在代码中由 add() 方法完成:
python
def add(self, seq: Sequence):
self.waiting.append(seq)因此整个流程可以简单理解为:
shell
LLMEngine.add_request
↓
Scheduler.add
↓
waiting queue此时 sequence 只是进入了调度器,还没有真正开始执行推理计算,真正的调度发生在 schedule() 方法中:
python
def schedule(self) -> tuple[list[Sequence], bool]这个函数会返回两个信息,其中:
scheduled_seqs:当前 step 要执行的一批 sequenceis_prefill:这一批 sequence 需要执行 prefill 还是 decode
整个调度逻辑可以分为 Prefill 调度和 Decode 调度两个阶段,Scheduler 会 优先调度 prefill:
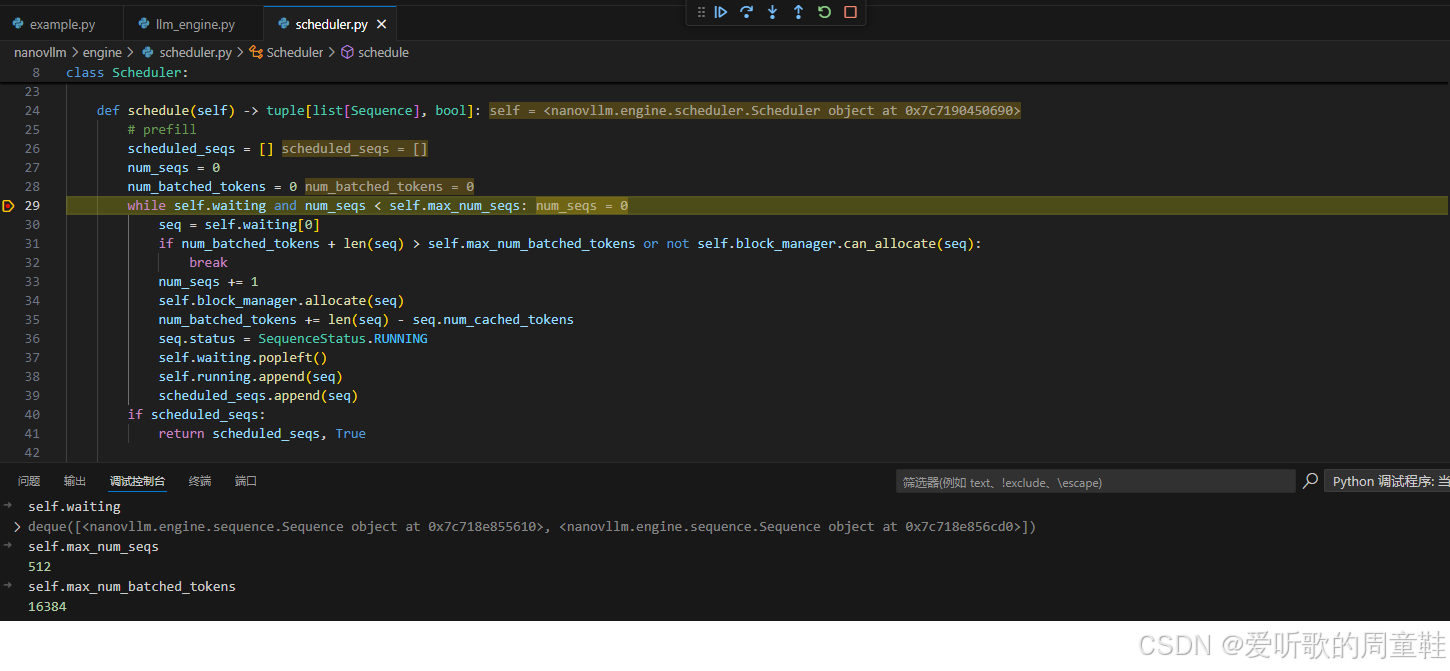
首先 Scheduler 会尝试从 waiting 队列中取出 sequence:
python
while self.waiting and num_seqs < self.max_num_seqs:在这个过程中,会有两个关键限制条件:
- Batch size 限制 :
num_seqs < self.max_num_seqs,这限制了一个 batch 中最多可以处理多少个 sequence。 - Token 数量限制 :
num_batched_tokens + len(seq) > self.max_num_batched_tokens,由于 Prefill 阶段通常需要一次性计算 整个 prompt 的 token ,如果 batch 中 token 总数过多,就可能导致显存不足、GPU 计算压力过大,因此 Scheduler 需要限制 一个 batch 的最大 token 数量。
在 Prefill 调度过程中,还有一个关键步骤:
python
self.block_manager.allocate(seq)这里就引入了一个非常重要的组件 Block Manager ,Block Manager 的职责是 管理 KV Cache 的内存分配 。如果从宏观角度来看,可以把它理解为 GPU KV Cache 的 CPU 侧管理器。
Scheduler 在调度 sequence 时,需要先向 Block Manager 申请 KV Cache 空间,代码中也会先检查:
python
self.block_manager.can_allocate(seq)只有当 GPU KV Cache 有足够空间时,Scheduler 才会允许这个 sequence 进入执行阶段,如果空间不足,调度就会停止。
当一个 sequence 成功通过 Prefill 调度之后,它会经历以下几个变化:
python
seq.status = SequenceStatus.RUNNING并且从 waiting 队列移动到 running 队列:
python
self.waiting.popleft()
self.running.append(seq)因此 sequence 的生命周期可以理解为:
shell
WAITING
↓
RUNNING
↓
FINISHEDOK,这就是关于 Prefill 调度的逻辑。
我们接着看 Decode 调度的逻辑:
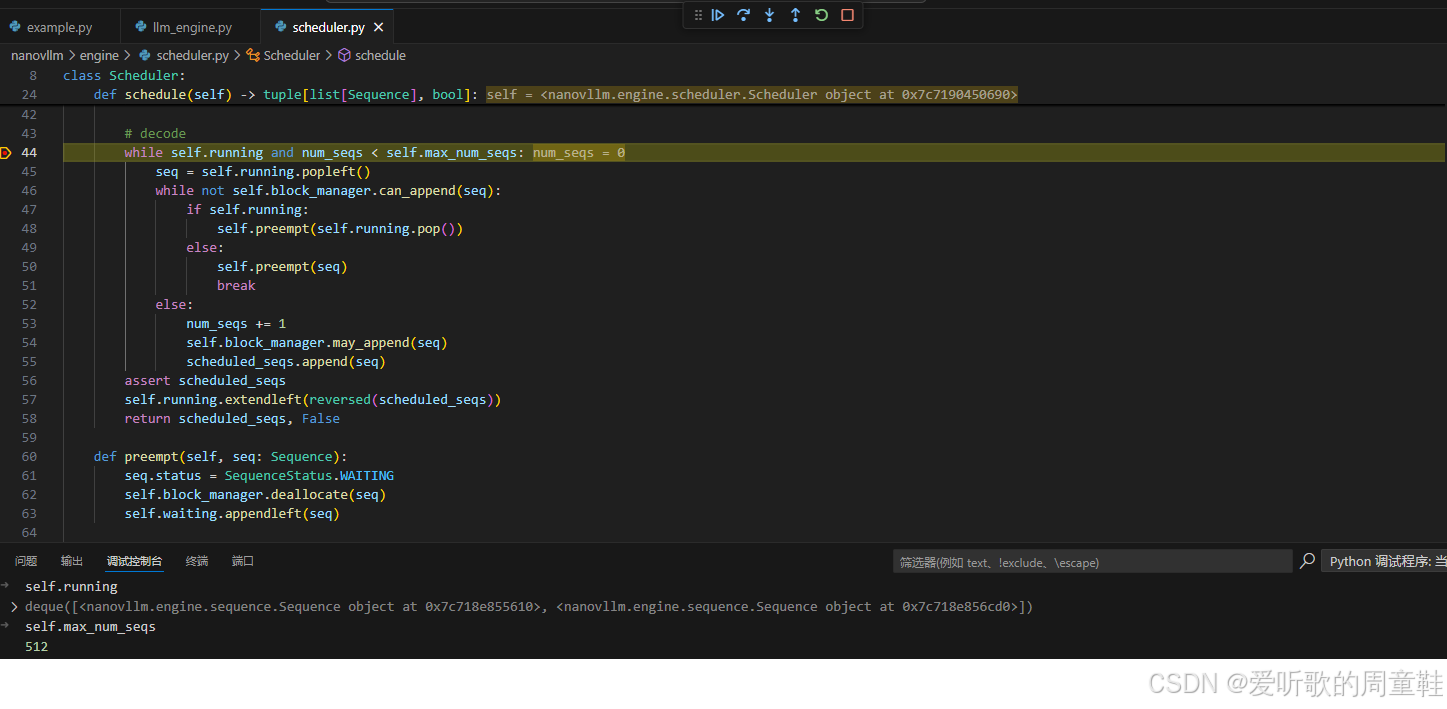
如果当前没有新的 prefill 请求需要执行,Scheduler 就会进入 decode 调度阶段,对应代码:
python
while self.running and num_seqs < self.max_num_seqs:Decode 阶段的特点是:每个 sequence 只生成一个 token,因此 decode 的计算量相对较小,但 需要频繁执行,在这个过程中 Scheduler 仍然需要检查 KV Cache 是否能够继续扩展:
shell
self.block_manager.can_append(seq)因为每生成一个新的 token,都需要分配新的 KV Cache。如果 KV Cache 空间不足,就会触发一个非常重要的机制 Preemption(抢占)。
当 KV Cache 不足时,Scheduler 会选择 暂停某些 sequence:
shell
RUNNING sequence
↓
释放 KV Cache
↓
重新进入 waiting queue这就是所谓的 抢占式调度(preemption),通过这种方式,系统可以动态调整 GPU KV Cache 的使用情况。
OK,这就是关于 Decode 调度的逻辑。
我们接着看 Scheduler 的最后一个方法 postprocess:
当 Model Runner 完成一次推理之后,Scheduler 还需要进行 后处理,在这里主要会完成三个操作:
1. 追加生成 token
python
seq.append_token(token_id)2. 判断是否结束
如果出现 生成 EOS 或者达到 max_tokens,则 sequence 会被标记为完成:
python
seq.status = SequenceStatus.FINISHED3. 释放 KV Cache
当 sequence 结束时,其对应的 KV Cache 也会被释放:
shell
self.block_manager.deallocate(seq)同时从 running 队列中移除。
综合来看,Scheduler 的核心职责主要包括:
1. 请求排队(waiting queue)
2. Batch 调度
3. Prefill / Decode 切换
4. KV Cache 资源管理
5. Sequence 生命周期管理
在整个推理系统中,Scheduler 相当于 GPU 计算任务的调度中心。
OK,前面我们已经从代码的角度把 Scheduler 的几个核心流程梳理过一遍了,接下来我们再对照着下面这张架构图,重新看看它整个流程具体是怎么运转起来的:
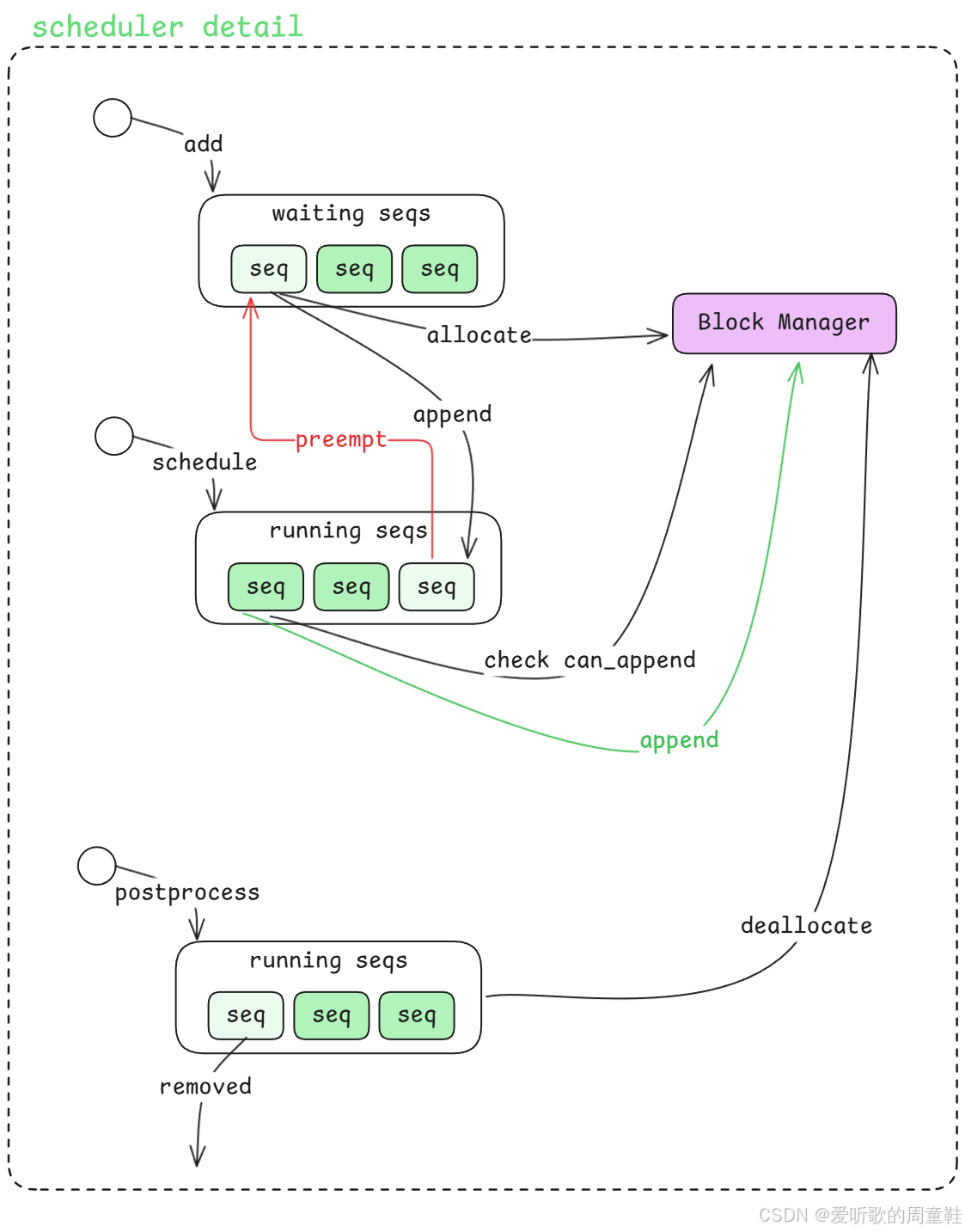
好,那从上面这张图里边我们可以看到,Scheduler 内部其实主要围绕着两个队列在运转:
- 一个是 waiting seqs
- 一个是 running seqs
同时它还会和右侧的 Block Manager 持续交互,所以整个 Scheduler 的核心逻辑,其实就是围绕着这两个队列和一个 Block Manager 展开的。
首先从最上面的 add 开始看,当前台逻辑(add_request)把一个 prompt 转换成 sequence 之后,这个 sequence 并不会直接进入推理执行,而是会先被放到 waiting queue 里边。也就是说,所有新进入系统的 sequence,都会先进入 waiting 这个队列等待调度。
那 waiting 这个阶段在做什么呢?
从图上也可以看到,waiting queue 中排在最前面的 sequence,会先去和右侧的 Block Manager 发生一次交互,这个动作就是图中标出来的 allocate。也就是说,一个 sequence 在真正进入运行状态之前,Scheduler 会先让它去做一次 allocate。你可以把这个过程理解成:在 sequence 正式开始执行 prefill 之前,先去 Block Manager 那里确认一下它对应的缓存和空间分配情况。
OK,那当 allocate 这个动作完成之后,接下来 Scheduler 会做什么呢?
下一步它就会把这个已经完成 allocate 的 sequence,从 waiting queue 里边取出来,然后放到下方的 running queue 里边。所以这个过程其实就是 waiting → allocate → running,这是一个非常典型的队列推进过程。
也就是说,waiting 队列里谁排在最前面,谁就优先去做 allocate;它做完之后被移到 running 队列,原来排在第二位的 sequence 就会自动顶上来,成为新的队首,然后继续重复这个流程。
所以从这个角度来看,waiting queue 更多承担的是一个 "等待进入正式运行状态"的角色。
接着再往下看图中间的 schedule 这个部分。
这里就对应到我们前面讲过的 step loop 。也就是说,当前台不断地把 sequence 放进 waiting queue 之后,后台的 step loop 就会持续地调用 Scheduler 的 schedule() 方法,从 running queue 里边取出当前能够继续执行的 sequence 去往下推进。
那 running 里的 sequence 在这个阶段会做什么呢?
从图上可以看到,它会先去做一次检查 check can_append,这个检查同样是和 Block Manager 交互的。不过这里和上面的 allocate 不一样,上面的 allocate 更像是在 sequence 进入运行阶段之前,先完成一次初始分配;而这里的 can_append,检查的是这个 sequence 在当前阶段还能不能继续往下追加新的 token。
也就是说,这里已经进入到了我们前面提到的 decode 过程。因为 decode 的特点就是:模型每次只会新生成一个 token,而每新生成一个 token,sequence 的长度就会往后增长一位,所以对应地也需要去更新 Block Manager 里边和它相关的缓存记录。也正因为这样,这里的动作就叫做 append。
如果检查之后发现当前空间还是够的,也就是 can_append ,那么系统就会沿着图里的这条 绿色路径 继续往下走。也就是说当前 sequence 可以继续生成新的 token,同时 Block Manager 里对应的记录也可以继续 append,然后这个 sequence 就继续保留在 running queue 里边,等待下一轮调度。
所以绿色这条线代表的是一种最理想的情况:空间够,推理就可以顺利继续往下推进。
但另一种情况是,检查之后发现 不能 append ,也就是说 Block Manager 这边已经没有足够的空间了。这个时候就会触发图里的这条 红色路径 即 preempt,这也是 Scheduler 里一个非常关键的动作。
所谓 preempt,你可以简单理解成当前这个正在 running 的 sequence 暂时没办法继续往下推了,因为空间不够,所以它需要先被 "挪出去"。于是 Scheduler 会把它从 running queue 里边拿出来,再重新放回到上面的 waiting queue 里边。
这里有一个很重要的细节,就是它并不是被放回 waiting 的末尾,而是会被尽可能优先地放回去。因为这个 sequence 其实已经执行过一部分了,它不是一个全新的请求,它只是因为当前空间不足,所以暂时中断了一下。那等后面 Block Manager 有空间释放出来的时候,它就应该能够尽快重新被调度回来继续执行。
所以你可以把这个过程理解成:running → 空间不足 → preempt → 回到 waiting,这也就是图里红线所表达的逻辑。
接着再往下看最下面这个 postprocess 的部分。
当某个 sequence 整个推理都完成之后,也就是说它已经把自己该做的 decode 全部做完了,这个时候它就不需要继续留在 running queue 里边了。
于是 Scheduler 会在 postprocess 这个阶段,把这个 sequence 从 running queue 里移除掉,对应图里左下角的这个 removed,与此同时,它还会去调用 Block Manager 的 deallocate 也就是把这个 sequence 之前占用的空间彻底释放掉。
这样一来,队列里的状态和 Block Manager 里的空间状态就能够保持一致。
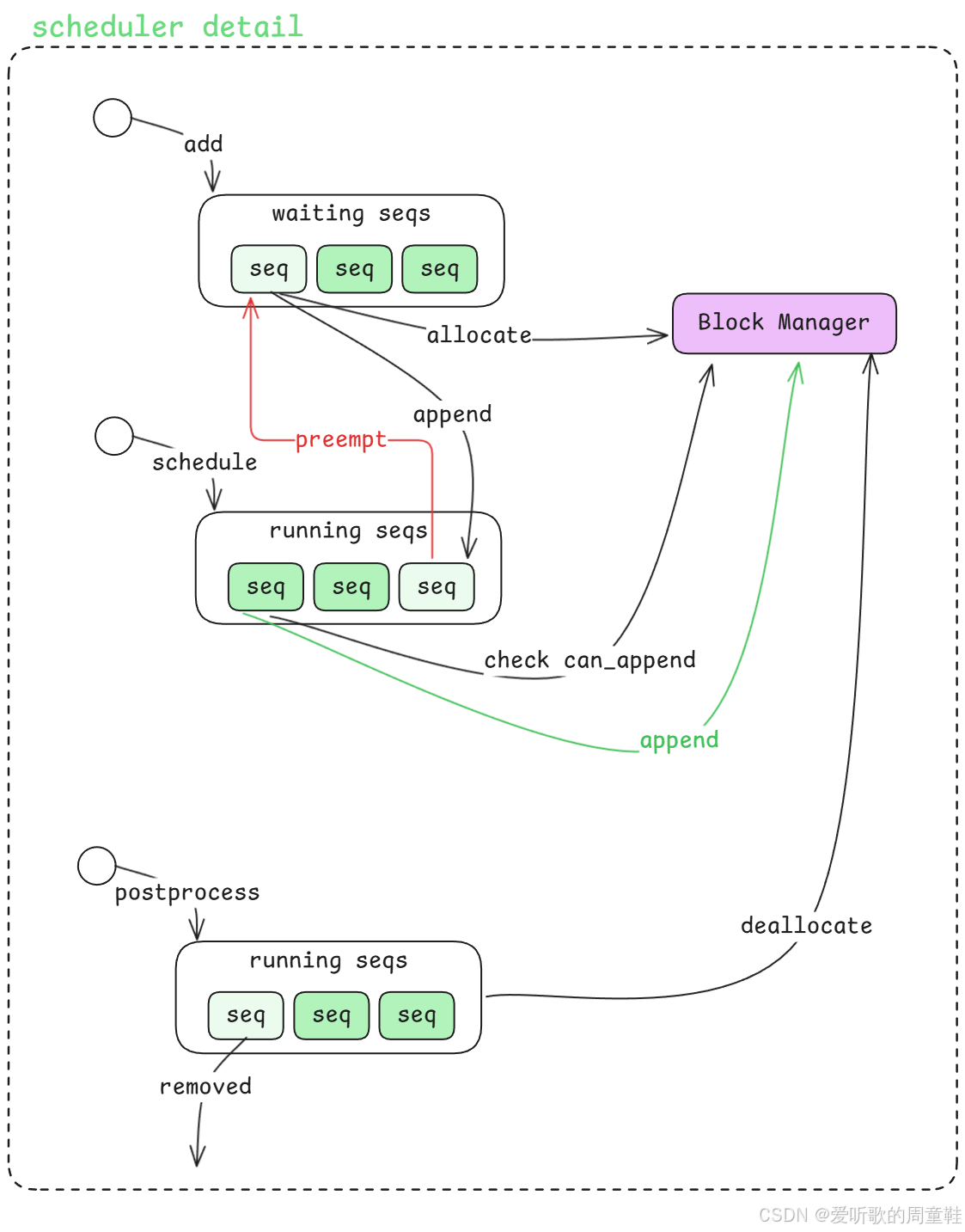
所以如果我们现在对照上面这张图,把 Scheduler 的整个过程重新串起来,其实就是下面这样一条主线:
1. 新来的 sequence 先通过 add 进入 waiting queue
2. waiting queue 里的 sequence 依次去 Block Manager 做 allocate
3. allocate 完成之后,sequence 从 waiting 移动到 running queue
4. 后台 step loop 触发 schedule(),去 running queue 中检查 sequence 是否还能 append
5. 如果可以 append,就继续往下执行 decode
6. 如果空间不够,就触发 preempt,把 sequence 暂时打回 waiting queue
7. 当 sequence 全部执行完成之后,在 postprocess 阶段把它从 running 中移除,并调用 deallocate 释放空间
这样再回过头来看上面这张图,你会发现 Scheduler 其实并不是一个特别复杂的黑盒,它本质上就是做了三件事情:
- 维护 waiting / running 两个队列
- 根据 Block Manager 的状态决定 sequence 能不能继续推进
- 在 sequence 完成之后负责把它清理掉,并把空间释放出来
所以从这个角度来看,Scheduler 本质上就是整个推理系统里负责 队列调度 + 空间协调 的那个核心组件。
OK,以上就是我们看到的关于 Scheduler 里面的所有的一个细节。
7. Block Manager 细节
OK,那我们刚刚在 Scheduler 这一节里已经看到 Scheduler 在调度 sequence 的过程中会频繁地去调用 Block Manager ,用来检查当前 KV Cache 的空间是否足够。
那接下来我们就来看一下,Block Manager 内部到底是一个什么样的结构:
python
# nanovllm/engine/block_manager.py
from collections import deque
import xxhash
import numpy as np
from nanovllm.engine.sequence import Sequence
class Block:
def __init__(self, block_id):
self.block_id = block_id
self.ref_count = 0
self.hash = -1
self.token_ids = []
def update(self, hash: int, token_ids: list[int]):
self.hash = hash
self.token_ids = token_ids
def reset(self):
self.ref_count = 1
self.hash = -1
self.token_ids = []
class BlockManager:
def __init__(self, num_blocks: int, block_size: int):
self.block_size = block_size
self.blocks: list[Block] = [Block(i) for i in range(num_blocks)]
self.hash_to_block_id: dict[int, int] = dict()
self.free_block_ids: deque[int] = deque(range(num_blocks))
self.used_block_ids: set[int] = set()
@classmethod
def compute_hash(cls, token_ids: list[int], prefix: int = -1):
h = xxhash.xxh64()
if prefix != -1:
h.update(prefix.to_bytes(8, "little"))
h.update(np.array(token_ids).tobytes())
return h.intdigest()
def _allocate_block(self, block_id: int) -> Block:
block = self.blocks[block_id]
assert block.ref_count == 0
block.reset()
self.free_block_ids.remove(block_id)
self.used_block_ids.add(block_id)
return self.blocks[block_id]
def _deallocate_block(self, block_id: int) -> Block:
assert self.blocks[block_id].ref_count == 0
self.used_block_ids.remove(block_id)
self.free_block_ids.append(block_id)
def can_allocate(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= seq.num_blocks
def allocate(self, seq: Sequence):
assert not seq.block_table
h = -1
cache_miss = False
for i in range(seq.num_blocks):
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1
block_id = self.hash_to_block_id.get(h, -1)
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss:
block_id = self.free_block_ids[0]
block = self._allocate_block(block_id)
else:
seq.num_cached_tokens += self.block_size
if block_id in self.used_block_ids:
block = self.blocks[block_id]
block.ref_count += 1
else:
block = self._allocate_block(block_id)
if h != -1:
block.update(h, token_ids)
self.hash_to_block_id[h] = block_id
seq.block_table.append(block_id)
def deallocate(self, seq: Sequence):
for block_id in reversed(seq.block_table):
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0:
self._deallocate_block(block_id)
seq.num_cached_tokens = 0
seq.block_table.clear()
def can_append(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= (len(seq) % self.block_size == 1)
def may_append(self, seq: Sequence):
block_table = seq.block_table
last_block = self.blocks[block_table[-1]]
if len(seq) % self.block_size == 1:
assert last_block.hash != -1
block_id = self.free_block_ids[0]
self._allocate_block(block_id)
block_table.append(block_id)
elif len(seq) % self.block_size == 0:
assert last_block.hash == -1
token_ids = seq.block(seq.num_blocks-1)
prefix = self.blocks[block_table[-2]].hash if len(block_table) > 1 else -1
h = self.compute_hash(token_ids, prefix)
last_block.update(h, token_ids)
self.hash_to_block_id[h] = last_block.block_id
else:
assert last_block.hash == -1首先从整体角色来看,Block Manager 本身并不会真的在显卡上去分配 KV Cache,前面我们也介绍过,它更像是 KV Cache 在 CPU 侧的一个控制器或者管理器。
也就是说底层真正的 KV Cache 是存在 GPU 显存 里的,而 Block Manager 只是用 CPU 上的数据结构 来描述和管理这些缓存的分配情况,所以我们才可以把 Block Manager 理解为 GPU KV Cache 的 CPU 侧管理结构。
它的主要作用,就是记录:
- 哪些缓存已经被使用
- 哪些缓存还可以继续分配
- 哪些缓存可以复用
从代码上来看,Block Manager 的入口其实非常简单,它始终是围绕 Sequence 来工作的。也就是说,外部在调用 Block Manager 的时候,基本都是围绕着这三种操作:
python
def allocate(self, seq: Sequence):
pass
def may_append(self, seq: Sequence):
pass
def deallocate(self, seq: Sequence):
pass也就是说一个 sequence 进入系统时会 allocate ;在 decode 过程中会不断 append ;推理结束之后会 deallocate ,所以 Block Manager 的整个生命周期,其实都是围绕 sequence 的生命周期 展开的。
而 sequence 我们前面已经讲过,本质上就是 token 的序列,所以从数据结构的角度来看,Block Manager 需要解决的核心问题就是 如何高效地管理一组 token 的缓存。
在 Block Manager 内部,我们会引入一个新的概念,叫做 Block,在图中:
- 绿色部分表示 sequence
- 黄色表示 token
- 紫色表示 block
也就是说,当一个 sequence 被 allocate 进入 Block Manager 之后,系统会把这整个 sequence 拆分成多个 block。每一个 block 都是一个新的数据结构,代码中的定义如下:
python
class Block:
def __init__(self, block_id):
self.block_id = block_id
self.ref_count = 0
self.hash = -1
self.token_ids = []可以看到,一个 block 主要包含三个信息:
1. block 的 hash
也就是对 block 内容做一次哈希计算之后得到的结果,这个 hash 主要用于判断 当前 block 是否已经在缓存中出现过。
2. block 的引用计数(ref count)
这个就是所谓的 缓存命中次数 。在多次推理中,如果不同的 sequence 中出现了 完全相同的 block 内容 ,那么系统就不会重复存储这个 block,而是会让多个 sequence 共享同一个 block。
这个时候就会通过 ref_count 来记录这个 block 被引用了多少次,例如:
- 如果某个 block 只被使用了一次,那么它的
ref_count就是 1 - 如果它被多个 sequence 复用,那么
ref_count就会大于 1
所以在 blocks 列表里,你看到的其实都是 唯一的 block ,只是它们可能会被不同的 sequence 引用多次。
3. block 的 token 内容
第三部分就是 block 中真正存储的 token 列表 。也就是说,block 本质上也是一组 token,只不过它和 sequence 的区别在于:sequence 是动态长度,block 是固定长度。
固定长度是什么意思呢?其实在 nano-vllm 中,每一个 block 的长度是固定的,之前我们在 Sequence 的定义中可以看到:
python
class Sequence:
block_size = 256也就是说,一个 block 最多可以存储 256 个 token 。因此,当一个 sequence 被拆分成 block 时,就会出现这样的情况:假设现在有一个 sequence,它的长度是 700 个 tokens 且我们设置的 block_size = 256,那么这个 sequence 就会被拆成:
shell
block 1 → 256 tokens
block 2 → 256 tokens
block 3 → 剩余 tokens前两个 block 是完整的,而第三个 block 可能只有一部分 token。所以我们从这里也能看到当一个 sequence 转换成多个 block 时,每个 block 的长度是固定的,但最后一个 block 可能不会完全填满。
这里还有一个很重要的规则需要注意,那就是 一个 block 只会属于一个 sequence 的一部分,不会混合多个 sequence 的内容。也就是说一个 sequence 可以被拆成多个 block,但一个 block 不会同时存储两个 sequence 的 token。
比如说上面提到的这个拥有 700 个 token 的 sequence,在它转换成三个 block 之后,第三个 block 中的 token 其实是没有被填满的,这时候不会说另外的一个 sequence 的 token 填入到这里,这是不会发生的,它不会去混合多个 sequence 的 token 内容的。
所以从关系上看就是 sequence → 多个 block,这是一个 一对多 的关系。
当 sequence 被拆成多个 block 之后,每一个 block 都会计算一个 hash 值:
python
def allocate(self, seq: Sequence):
assert not seq.block_table
h = -1
cache_miss = False
for i in range(seq.num_blocks):
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1
block_id = self.hash_to_block_id.get(h, -1)
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss:
block_id = self.free_block_ids[0]
block = self._allocate_block(block_id)
else:
seq.num_cached_tokens += self.block_size
if block_id in self.used_block_ids:
block = self.blocks[block_id]
block.ref_count += 1
else:
block = self._allocate_block(block_id)
if h != -1:
block.update(h, token_ids)
self.hash_to_block_id[h] = block_id
seq.block_table.append(block_id)这个 hash 会和当前 Block Manager 中已有的 block 进行比较,如果发现 完全相同的 block 已经存在 ,那么就说明 cache hit ,这时系统不会重新创建 block,而只会 ref_count += 1,也就是说多个 sequence 可以 共享一个 block。
为了让这个查找过程更加高效,Block Manager 还维护了一个额外的数据结构:
python
self.hash_to_block_id: dict[int, int] = dict()它本质上是一个 哈希表(map):
shell
key → block hash
value → block id在 Block Manager 内部,还有两个非常重要的数据结构:
python
self.free_block_ids: deque[int] = deque(range(num_blocks))
self.used_block_ids: set[int] = set()它们分别表示:
self.free_block_ids:当前还可以分配的 blockself.used_block_ids:当前已经被使用过的 block
所以当发生 cache miss 的时候,系统就需要真正去分配一个新的 block,这时就会执行如下操作:
1. 从 free_block_ids 中取出一个 block id
2. 把它加入到 used_block_ids
3. 在 blocks 列表中创建新的 block
也就是说 free → used。
而当 sequence 被释放的时候,则会发生反向过程 used → free,也就是在 deallocate 时把 block id 再放回 free_block_ids 中。
那这里还剩一个问题:Block Manager 一共会有多少个 block?
那这个数量其实是由 显存大小决定的,因为每一个 token 占用多少显存是可以计算出来的,一个 block 有固定数量的 token,那么一个 block 占用多少显存也是固定的。如果我们知道 GPU 为 KV Cache 预留的显存,那么就可以计算出 最多可以容纳多少个 block。
所以 Block Manager 在初始化时就会创建固定数量的 block id,这些 id 就代表 当前推理系统最多能同时管理多少个 KV Cache block。
最后当外部调用 deallocate 时,Block Manager 会做两件事情:
python
def deallocate(self, seq: Sequence):
for block_id in reversed(seq.block_table):
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0:
self._deallocate_block(block_id)
seq.num_cached_tokens = 0
seq.block_table.clear()第一件事情是 减少 block 的 ref_count ,如果某个 block 的引用计数变成 0,就说明它已经没有 sequence 在使用了,这时就会把这个 block id 从 used_block_ids 移回 free_block_ids;第二件事情是 清理 block 的控制信息,也就是把 Block Manager 里对应的记录清空。
这里还有一个比较有意思的细节,那就是在很多版本的 vLLM 实现中,当 block 被释放时,并不会真的去 清空 GPU 显存中的数据 。原因其实很简单:清空显存是一个额外开销 ,而对于 KV Cache 来说,其实没有必要这么做,因为下一次新的 sequence 分配到这个 block 时,只需要 直接覆盖写入 就可以了。
所以你有时候可能会看到一种情况:Block Manager 在逻辑上已经把所有 block 都释放了,但是 GPU 显存看起来仍然是 "被占用" 的状态,这其实是一个正常现象。因为在 GPU 侧,它只是等待下一次写入时 直接覆盖旧数据,而不会专门做一次清空操作。
OK,到这里我们就把 Block Manager 的代码主流程基本梳理了一遍。
总结一下,Block Manager 主要做的事情其实就是三点:
1. 把 sequence 拆分成 block
2. 通过 hash 实现 block 级缓存复用
3. 管理 block 的分配与释放
接下来,我们就可以回到下面这张 block manager detail 的架构图,再把整个流程从图的角度重新串联一遍:
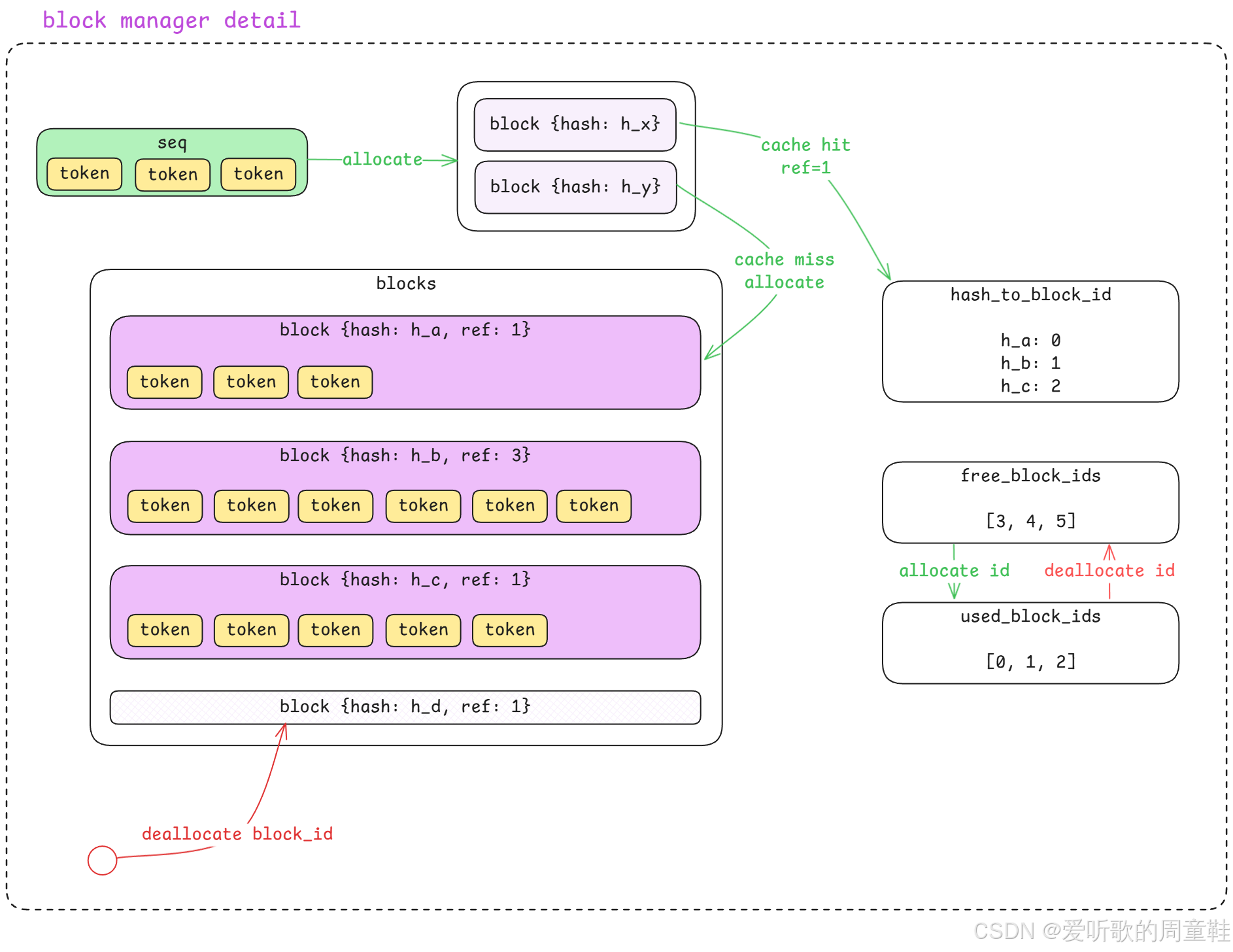
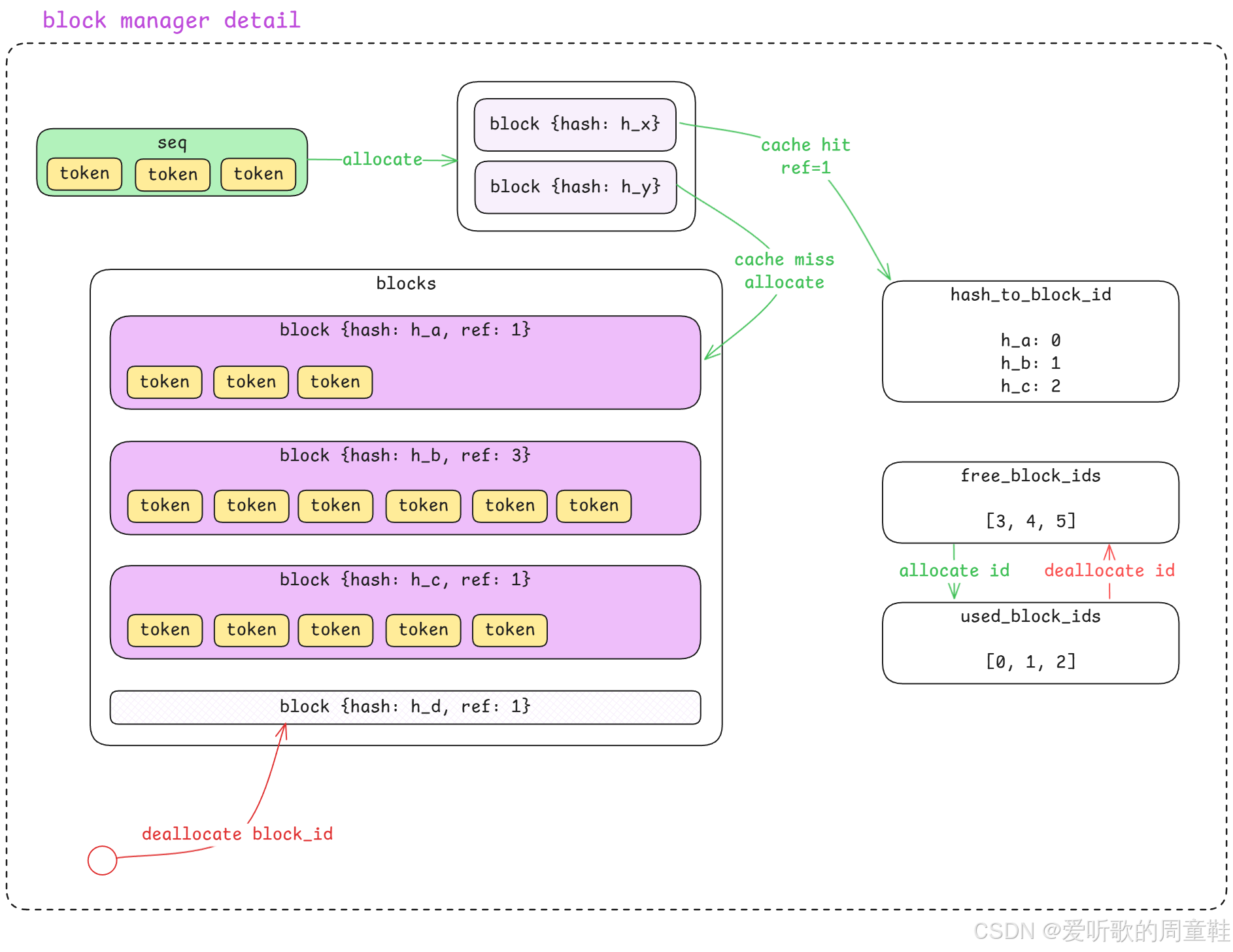
从这张图里我们可以看到,Block Manager 的整个流程其实可以分成三个主要部分:
1. sequence → block 的拆分
2. cache hit / cache miss 的判断
3. block 的分配与释放管理
首先看图的左侧:
当 Scheduler 调用 allocate(sequence) 的时候,一个 sequence 就会被送入 Block Manager。在图中:
- 绿色表示 sequence
- 黄色表示 token
所以 sequence 本质上就是一组 token 的序列。
当 sequence 进入 Block Manager 之后,它不会直接被存储,而是会先被 拆分成多个 block ,这一点其实和我们刚刚分析代码时看到的逻辑是一致的,因为在 Block Manager 的设计里,缓存管理的最小单位并不是 sequence,而是 block。
接下来可以看到图中间的这一部分:
sequence 会被拆分成多个 block,每一个 block 都是一个固定大小的 token 数组,例如 256 个 token,所以一个 sequence 如果比较长,就可能会被拆分成多个 block。
接下来每一个 block 在进入 Block Manager 之后,都会做一件事情:计算 hash ,这个 hash 是根据 block 中的 token 内容计算出来的。在代码中使用的是 xxhash,也就是说,只要 两个 block 的 token 内容完全一致 ,那么它们计算出来的 hash 就会是相同的,这个 hash 的作用其实非常关键,它是整个 KV Cache 复用机制的核心。
接下来 Block Manager 就会利用这个 hash,去查询右侧的这个数据结构 hash_to_block_id,这个结构本质上是一个 hash map 即 hash → block_id,例如图中的 h_a → 0、h_b → 1、h_c → 2,所以当一个新的 block 进入系统时,就会发生两种情况:
第一种情况:Cache Hit
如果这个 block 的 hash 已经存在于 hash_to_block_id 中 ,那就说明 cache hit ,也就是说,这个 block 的内容在系统中 已经存在一份完全相同的缓存 。这时系统就不会重新创建 block,而只会做一件事情即 ref_count += 1,也就是把这个 block 的引用计数加一,所以多个 sequence 就可以 共享同一个 block 的缓存。
图中也给出了一个例子 block {hash: h_b, ref: 3},说明这个 block 已经被 3 个 sequence 引用。
通过上面这种方式就可以避免重复存储相同的 KV Cache,大幅节省显存。
第二种情况:Cache Miss
如果 hash 在 hash_to_block_id 中 不存在 ,那么就说明 cache miss ,也就是说当前 block 是一个 从未出现过的新 block。这时 Block Manager 就需要真正去分配一个新的 block,这个过程就是图中的 cache miss allocate。
接下来我们再看图中间 blocks 这个区域,这里表示的是 Block Manager 当前维护的 所有 block 列表 。每一个 block 都包含三个信息即 block {hash, ref_count, token_ids},例如:
shell
block {hash: h_a, ref: 1}
block {hash: h_b, ref: 3}
block {hash: h_c, ref: 1}可以看到每个 block 的 hash 都不同,但 ref_count 可能相同,因为不同 sequence 可能会共享同一个 block。
接下来我们再看右侧这一部分。
Block Manager 还维护了两个非常重要的数据结构:free_block_ids 和 used_block_ids,它们分别表示:
- free_block_ids → 当前还可以分配的 block
- used_block_ids → 当前已经被占用的 block
例如图中:
shell
free_block_ids = [3,4,5]
used_block_ids = [0,1,2]这说明 block 0、1、2 已经被使用,而 block 3、4、5 还可以继续分配。
当发生 cache miss 时,系统就会:
1. 从 free_block_ids 中取出一个 block_id
2. 把这个 id 放入 used_block_ids
3. 在 blocks 中创建新的 block
这个过程就是图中绿色箭头 allocate id。
最后我们来看图的最下面这一部分。
当某个 sequence 推理结束之后,Scheduler 会调用 deallocate(sequence),这时 Block Manager 就会对这个 sequence 对应的 block 做释放操作。释放时会先减少 block 的引用计数即 ref_count -= 1,如果某个 block 的引用计数变成 0,就说明这个 block 已经没有任何 sequence 在使用,这时系统就会把这个 block_id 从 used_block_ids 中移除,同时再放回 free_block_ids
这个过程就是图中的红色箭头 deallocate id ,这样这个 block 就重新变成 可分配状态。
所以如果我们把这张图从头到尾串起来,Block Manager 的整体流程其实就是:
1. sequence 进入 Block Manager
2. sequence 被拆分成多个 block
3. 每个 block 计算 hash
4. 查询 hash_to_block_id 判断 cache hit / miss
5. cache hit → 增加 ref_count
6. cache miss → 从 free_block_ids 分配新 block
7. sequence 结束 → 减少 ref_count 并释放 block
所以 Block Manager 本质上做的事情其实就是把 KV Cache 的管理粒度从 sequence 降到 block,并通过 hash + 引用计数实现缓存复用,这样不仅可以 减少显存占用 ,同时也能 提高推理效率。
OK,以上就是我们看到的关于 Block Manager 里面的所有的一个细节。
8. Model Runner TP 并行系统
OK,那讲完 Block Manager 之后,其实 Scheduler 这一条链路我们就已经全部看完了。主流程什么时候会调用 Scheduler,Scheduler 内部如何使用 Block Manager,Block Manager 又是如何管理 KV Cache,这些部分我们都已经全部分析过了。
接下来我们来看主线流程中的 第二个核心组件 - Model Runner,在主流程图中,它就是右下角黄色标记的这个模块:
从主流程可以看到,Model Runner 是在 step loop 中被调用的,调用方式其实非常简单:
python
call("run", seqs, action)这里一共有三个参数:
"run":方法名称seqs:当前需要执行的 sequence 列表action:执行类型 prefill / decode
所以整个调用语义其实就是 让模型对这些 sequence 执行 prefill 或 decode。
在 Model Runner 内部,其实包含两个比较关键的设计:TP(Tensor Parallel)并行系统和模型执行系统 ,这一小节我们先重点看 TP 并行系统。
前面我们也提到过,TP 要解决的核心问题其实很简单:当一张显卡无法容纳整个模型时,需要多张显卡一起运行模型 。也就是说,如果模型太大,比如 32B、70B 等,那么一张显卡的显存就不够了,这时候就需要把模型 拆分到多张 GPU 上并行运行。
而这种并行方式其中一种就是 TP(Tensor Parallel) ,未来我们还会看到另一种并行方式 PP(Pipeline Parallel) ,两者的主要区别在于 TP 是将模型同一层拆分到不同 GPU 上,而 PP 是将模型不同层放在不同 GPU 上。另外还有一个比较重要的区别,那就是 TP 通常用于 单机多卡 ,这是因为单机多卡之间的通信可以通过 NVLink、PCIe、Shared Memory 等通信方式,这些方式都比 网络通信 要快很多。
下面我们来看 TP 系统的具体结构:
python
# nanovllm/engine/model_runner.py
import pickle
import torch
import torch.distributed as dist
from multiprocessing.synchronize import Event
from multiprocessing.shared_memory import SharedMemory
from nanovllm.config import Config
from nanovllm.engine.sequence import Sequence
from nanovllm.models.qwen3 import Qwen3ForCausalLM
from nanovllm.layers.sampler import Sampler
from nanovllm.utils.context import set_context, get_context, reset_context
from nanovllm.utils.loader import load_model
class ModelRunner:
def __init__(self, config: Config, rank: int, event: Event | list[Event]):
self.config = config
hf_config = config.hf_config
self.block_size = config.kvcache_block_size
self.enforce_eager = config.enforce_eager
self.world_size = config.tensor_parallel_size
self.rank = rank
self.event = event
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)
torch.cuda.set_device(rank)
default_dtype = torch.get_default_dtype()
torch.set_default_dtype(hf_config.dtype)
torch.set_default_device("cuda")
self.model = Qwen3ForCausalLM(hf_config)
load_model(self.model, config.model)
self.sampler = Sampler()
self.warmup_model()
self.allocate_kv_cache()
if not self.enforce_eager:
self.capture_cudagraph()
torch.set_default_device("cpu")
torch.set_default_dtype(default_dtype)
if self.world_size > 1:
if rank == 0:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)
dist.barrier()
else:
dist.barrier()
self.shm = SharedMemory(name="nanovllm")
self.loop()
def exit(self):
if self.world_size > 1:
self.shm.close()
dist.barrier()
if self.rank == 0:
self.shm.unlink()
if not self.enforce_eager:
del self.graphs, self.graph_pool
torch.cuda.synchronize()
dist.destroy_process_group()
def loop(self):
while True:
method_name, args = self.read_shm()
self.call(method_name, *args)
if method_name == "exit":
break
def read_shm(self):
assert self.world_size > 1 and self.rank > 0
self.event.wait()
n = int.from_bytes(self.shm.buf[0:4], "little")
method_name, *args = pickle.loads(self.shm.buf[4:n+4])
self.event.clear()
return method_name, args
def write_shm(self, method_name, *args):
assert self.world_size > 1 and self.rank == 0
data = pickle.dumps([method_name, *args])
n = len(data)
self.shm.buf[0:4] = n.to_bytes(4, "little")
self.shm.buf[4:n+4] = data
for event in self.event:
event.set()
def call(self, method_name, *args):
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args)
method = getattr(self, method_name, None)
return method(*args)
def warmup_model(self):
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
max_num_batched_tokens, max_model_len = self.config.max_num_batched_tokens, self.config.max_model_len
num_seqs = min(max_num_batched_tokens // max_model_len, self.config.max_num_seqs)
seqs = [Sequence([0] * max_model_len) for _ in range(num_seqs)]
self.run(seqs, True)
torch.cuda.empty_cache()
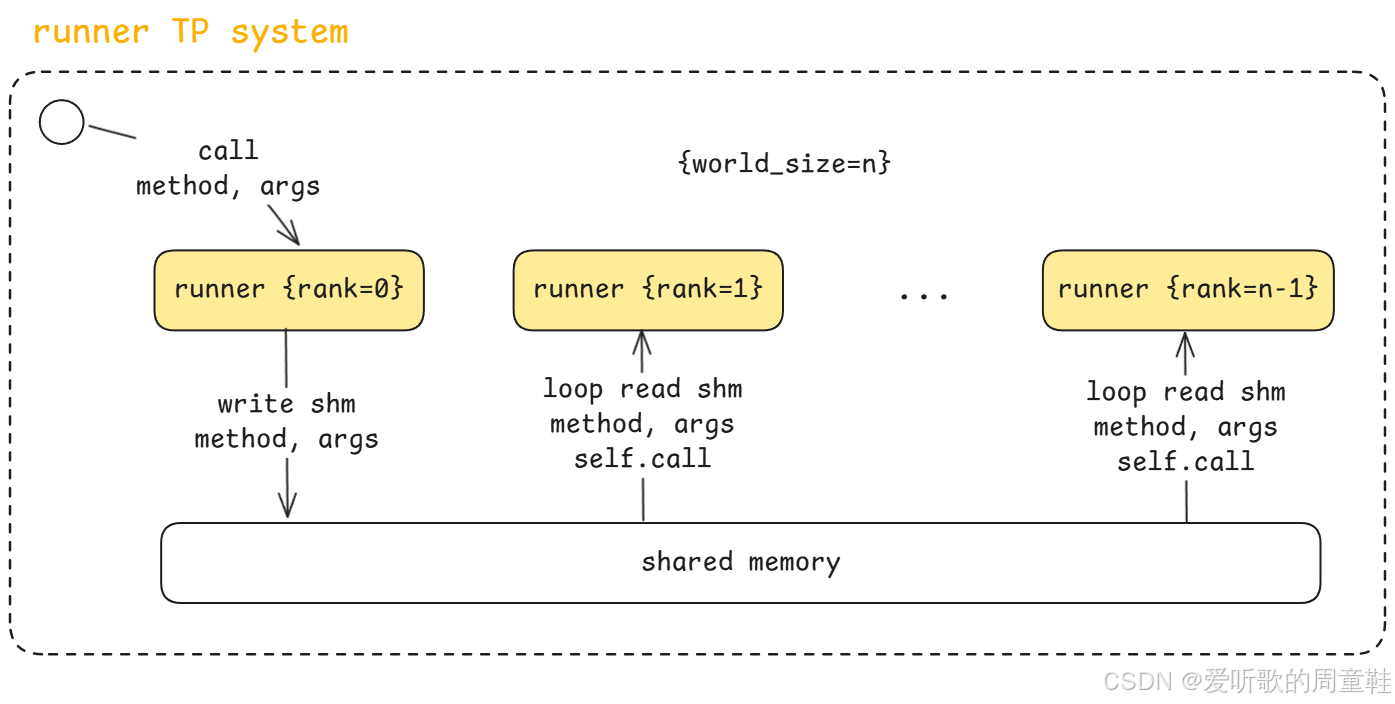
...在 nano-vllm 中,TP 系统的通信方式使用的是 Shared Memory(共享内存) ,也就是说,各个 GPU 对应的 runner 之间,通过 共享内存进行通信。
当 Model Runner 启动时,它会根据配置的 TP 数量 来决定需要启动多少个 runner:
python
self.world_size = config.tensor_parallel_size
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)这个数量在系统中有一个专门的名字叫做 world_size,也就是整个并行系统的 GPU 数量,例如 GPU 数量是 1,那 world_size = 1,如果 GPU 数量是 2,那 world_size = 2,如果 GPU 数量是 8,那 world_size = 8,依此类推。如果 world_size = 1,那就说明是单机单卡,没有并行,如果 world_size = 8,那就说明是 8 张 GPU 进行 TP 并行,所以这里的 world_size 是在初始化的时候根据你的硬件条件可以配置的一个参数。
当 TP 系统启动之后,每一张 GPU 上都会启动一个 Model Runner,这些 Runner 会被编号 rank 0、rank 1、...、rank n - 1,所以如果 world_size = n,那么系统里就会有 n 个 runner。
值得注意的是,在这些 runner 里面,并不是所有 runner 的角色完全一样。其中 rank 0 是一个 特殊的 runner ,我们通常把它叫做 leader runner,它除了执行任务之外,还承担一个额外的职责,那就是 调度和广播任务,而其他 runner(rank 1~n-1)则是纯执行者,它们只负责执行 leader 分发下来的任务。
那 runner 之间是如何通信的呢?
答案就是 Shared Memory,也就是图中最下面这一块,整个通信流程大概是下面这样:
第一步:调用 Model Runner
当上层调用 model_runner.call(method, args) 时,这个调用首先会被 rank 0 接收到
第二步:Leader 写入共享内存
rank0 在收到调用之后,会做两件事情:
python
def call(self, method_name, *args):
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args)
method = getattr(self, method_name, None)
return method(*args)第一件事就是 写入共享内存 ,把这次调用的 method name、arguments 序列化之后写入 shared memory;第二件事就是自己执行 method(args) 方法。
第三步:其他 Runner 读取共享内存
与此同时,其他 runner(rank 1 ~ rank n-1)会一直在做一件事情:
python
if self.world_size > 1:
if rank == 0:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)
dist.barrier()
else:
dist.barrier()
self.shm = SharedMemory(name="nanovllm")
self.loop()也就是不断循环读取共享内存(loop read shm),他们其实是在等待 leader 是否下达新的任务,一旦发现共享内存中出现新的 method 和 args,它们就会读取命令、调用自己的 call()、执行相同的 method。
第四步:并行执行
这样一来,系统就实现了一个非常简单但高效的效果即 leader 下达一次命令所有 runner 同时执行,所以从上层来看 model_runner.call(...) 只调用了一次,但实际上所有 GPU 上的 runner 都会执行这次操作,这就是 TP 并行系统的核心。
这里还有一个很重要的问题:既然所有 runner 执行的 method 和 arguments 都相同,那它们怎么避免互相冲突呢?答案就在 rank 中,每个 runner 都会知道自己的 rank,所以在具体执行任务的时候,可以根据 rank 去决定自己应该处理哪一部分数据。
例如,假设我们有 100 个元素需要做并行计算,如果 world_size = 4,那么就可以分配成 rank 0 处理 0~24,rank 1 处理 25~49,rank 2 处理 50~74,rank 3 处理 75~99,这样每个 runner 只处理自己负责的部分,最后再通过 reduce / gather 把结果合并。
所以整个 Runner TP 系统其实可以总结为三个关键点:
1. Runner 数量:world_size = GPU 数量,每张 GPU 启动一个 runner。
2. Leader / Worker 结构:rank0 → leader,rank1~n-1 → worker,leader 负责广播工作。
3. Shared Memory 通信:通信流程是 leader 写共享内存,worker 轮询读取,所有 runner 并行执行。
所以从整体来看,nano-vllm 的 TP 系统本质上就是一个 Leader + Shared Memory + Rank 切分 的并行执行框架。
OK,以上就是 TP 通信系统的一些介绍。
9. Model Runner 细节
OK,最后我们来看一下 Model Runner 的执行细节。
前面我们已经讲过了 TP 并行系统,也就是多个 runner 之间是如何通信、如何协同执行的。那在这之后,我们就可以继续往下看:当某一个 runner 真正开始执行的时候,它内部到底做了什么事情。
python
# nanovllm/engine/model_runner.py
import pickle
import torch
import torch.distributed as dist
from multiprocessing.synchronize import Event
from multiprocessing.shared_memory import SharedMemory
from nanovllm.config import Config
from nanovllm.engine.sequence import Sequence
from nanovllm.models.qwen3 import Qwen3ForCausalLM
from nanovllm.layers.sampler import Sampler
from nanovllm.utils.context import set_context, get_context, reset_context
from nanovllm.utils.loader import load_model
class ModelRunner:
...
def allocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
num_kv_heads = hf_config.num_key_value_heads // self.world_size
head_dim = getattr(hf_config, "head_dim", hf_config.hidden_size // hf_config.num_attention_heads)
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0
self.kv_cache = torch.empty(2, hf_config.num_hidden_layers, config.num_kvcache_blocks, self.block_size, num_kv_heads, head_dim)
layer_id = 0
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1
def prepare_block_tables(self, seqs: list[Sequence]):
max_len = max(len(seq.block_table) for seq in seqs)
block_tables = [seq.block_table + [-1] * (max_len - len(seq.block_table)) for seq in seqs]
block_tables = torch.tensor(block_tables, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
return block_tables
def prepare_prefill(self, seqs: list[Sequence]):
input_ids = []
positions = []
cu_seqlens_q = [0]
cu_seqlens_k = [0]
max_seqlen_q = 0
max_seqlen_k = 0
slot_mapping = []
block_tables = None
for seq in seqs:
seqlen = len(seq)
input_ids.extend(seq[seq.num_cached_tokens:])
positions.extend(list(range(seq.num_cached_tokens, seqlen)))
seqlen_q = seqlen - seq.num_cached_tokens
seqlen_k = seqlen
cu_seqlens_q.append(cu_seqlens_q[-1] + seqlen_q)
cu_seqlens_k.append(cu_seqlens_k[-1] + seqlen_k)
max_seqlen_q = max(seqlen_q, max_seqlen_q)
max_seqlen_k = max(seqlen_k, max_seqlen_k)
if not seq.block_table: # warmup
continue
for i in range(seq.num_cached_blocks, seq.num_blocks):
start = seq.block_table[i] * self.block_size
if i != seq.num_blocks - 1:
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end)))
if cu_seqlens_k[-1] > cu_seqlens_q[-1]: # prefix cache
block_tables = self.prepare_block_tables(seqs)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)
return input_ids, positions
def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = []
context_lens = []
for seq in seqs:
input_ids.append(seq.last_token)
positions.append(len(seq) - 1)
context_lens.append(len(seq))
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
context_lens = torch.tensor(context_lens, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
block_tables = self.prepare_block_tables(seqs)
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)
return input_ids, positions
def prepare_sample(self, seqs: list[Sequence]):
temperatures = []
for seq in seqs:
temperatures.append(seq.temperature)
temperatures = torch.tensor(temperatures, dtype=torch.float32, pin_memory=True).cuda(non_blocking=True)
return temperatures
@torch.inference_mode()
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))
else:
bs = input_ids.size(0)
context = get_context()
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)]
graph_vars = self.graph_vars
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"].fill_(-1)
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"].zero_()
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
graph.replay()
return self.model.compute_logits(graph_vars["outputs"][:bs])
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
logits = self.run_model(input_ids, positions, is_prefill)
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()
return token_ids
@torch.inference_mode()
def capture_cudagraph(self):
config = self.config
hf_config = config.hf_config
max_bs = min(self.config.max_num_seqs, 512)
max_num_blocks = (config.max_model_len + self.block_size - 1) // self.block_size
input_ids = torch.zeros(max_bs, dtype=torch.int64)
positions = torch.zeros(max_bs, dtype=torch.int64)
slot_mapping = torch.zeros(max_bs, dtype=torch.int32)
context_lens = torch.zeros(max_bs, dtype=torch.int32)
block_tables = torch.zeros(max_bs, max_num_blocks, dtype=torch.int32)
outputs = torch.zeros(max_bs, hf_config.hidden_size)
self.graph_bs = [1, 2, 4, 8] + list(range(16, max_bs + 1, 16))
self.graphs = {}
self.graph_pool = None
for bs in reversed(self.graph_bs):
graph = torch.cuda.CUDAGraph()
set_context(False, slot_mapping=slot_mapping[:bs], context_lens=context_lens[:bs], block_tables=block_tables[:bs])
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # warmup
with torch.cuda.graph(graph, self.graph_pool):
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # capture
if self.graph_pool is None:
self.graph_pool = graph.pool()
self.graphs[bs] = graph
torch.cuda.synchronize()
reset_context()
self.graph_vars = dict(
input_ids=input_ids,
positions=positions,
slot_mapping=slot_mapping,
context_lens=context_lens,
block_tables=block_tables,
outputs=outputs,
)我们先从最外层来看,当任意一个 runner,也就是任意一个 rank=n 的 runner 被执行的时候,它接收到的核心参数其实还是我们前面一直在传递的那个对象,也就是 sequence。
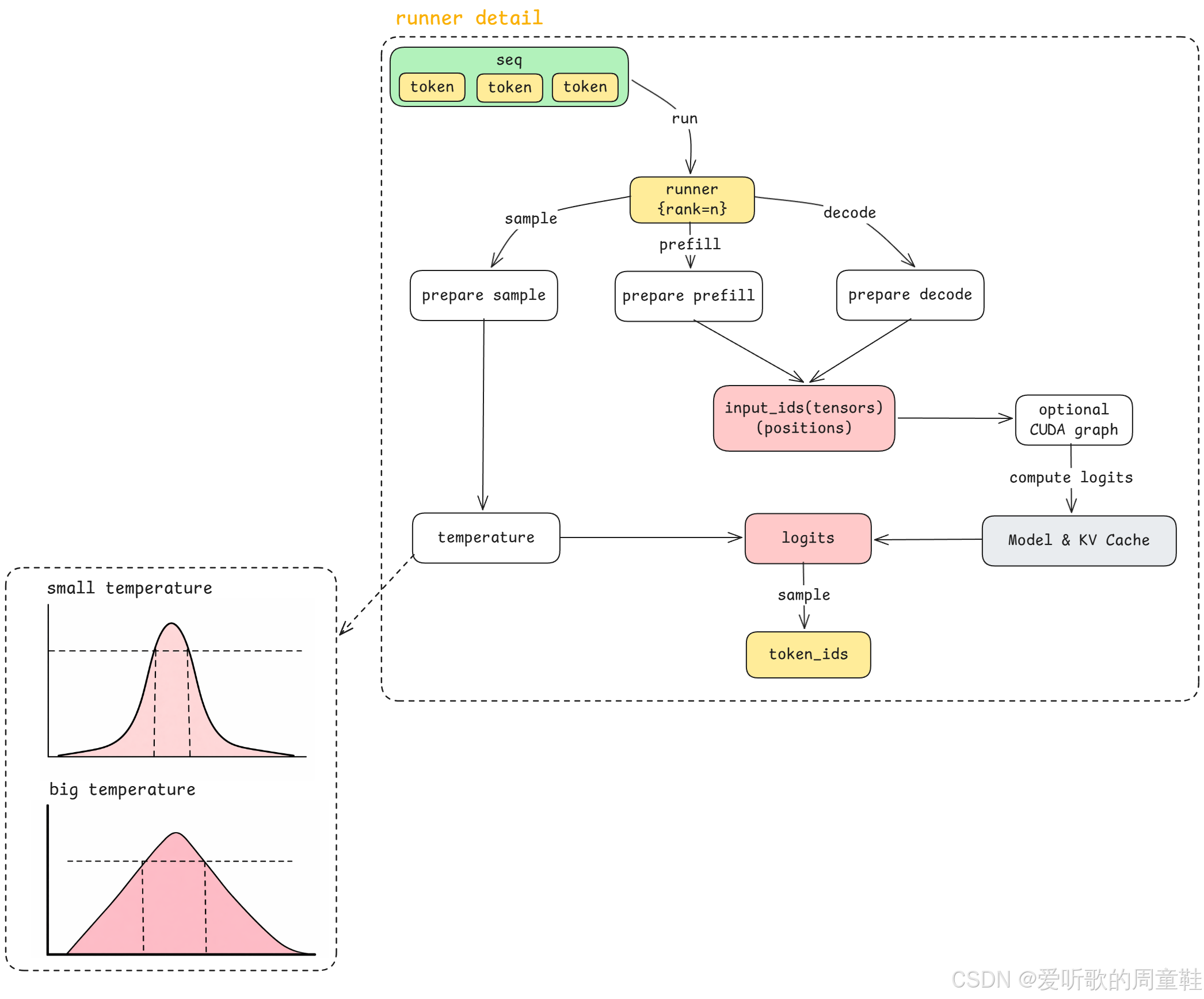
因为我们从前面的主线流程里已经看到,step loop 在调用 model runner 的时候,实际调用的是:
python
call("run", seqs, action)所以 run() 这里的两个核心参数就是:
seqsaction
这里的 seqs 仍然是一组 sequence,也就是一组 动态长度的 token 序列 ;而 action 则表示当前这一步到底是在执行 prefill 还是 decode。
OK,那当 runner 开始执行 run() 之后,它内部首先会做的第一件事情,就是根据 action 来决定接下来应该走哪一条路径。如果当前动作是 prefill 那么它就会执行 prepare_prefill(),而如果当前动作是 decode 它就会执行 prepare_decode()。
这一点在代码里其实也能直接看到:
python
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
logits = self.run_model(input_ids, positions, is_prefill)
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()
return token_ids所以 run() 内部的第一个分支,其实就是:
- prefill →
prepare_prefill - decode →
prepare_decode
再进一步展开的话,prepare_prefill 和 prepare_decode 内部都会去做两类事情,一类是一些和推理相关的 数学计算 ,另一类是 数据格式转换。
当然,在这里我们先不急着逐行展开它们内部的细节,我们先看一下它们做完之后最终产出的结果是什么。从图中可以看到,不管当前走的是 prefill 还是 decode,在执行完 prepare 之后,最终都会得到两个最关键的结果:
input_idspositions
这里的 input_ids,你可以把它理解成模型真正要吃进去的 input token ids ,而 positions,就是对应的 位置信息。
那这个位置信息在我们上集这里其实不用展开得特别细,因为它更多是和底层 Model & KV Cache 那个黑盒内部的执行方式相关。我们在这里可以先把它简单理解成:positions 是根据上面 Block Manager 维护的那些逻辑信息计算出来的,它告诉模型当前这些 token 在真正执行时应该对应到 KV Cache 里的什么位置。
因为前面 Block Manager 负责的是一个 逻辑层面的管理 ,而真正到了模型和 KV Cache 的数据面执行时,你总得有一个办法把这种逻辑管理结果和底层真实的缓存位置对应起来。这个对应关系,最终就是通过这些 positions 以及相关的 mapping 信息来完成的。
所以你可以理解为:
- Block Manager 管的是 逻辑分配
positions管的是 落到真实执行时的位置线索
带着这些位置信息,模型在真正执行的时候,才能正确地读取已经缓存好的 KV 或者把新的 KV 正确地写回去,这就是 positions 在这里的作用。
OK,那除了这些位置相关的信息之外,另一个很重要的变化就是我们前面一路传下来的 sequence,本质上还是 CPU 内存里的 Python 对象 ,里面装的是 token ids 这样的数据。但是到了 prepare_prefill() 和 prepare_decode() 这里之后,这些数据就会被进一步转换成真正可以送到 GPU 上执行的 Tensor。
例如在 prepare_prefill() 里,大家会看到这样的代码:
python
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)这里其实就发生了一件很关键的事情:把 CPU 上的 token / list / Python 对象,转换成 GPU 上真正可以参与计算的 Tensor 。所以在 Model Runner 的细节图里,我们这里用 黄色 表示 CPU 侧的对象,用 红色 表示 GPU 侧的对象。
也就是说,前面 sequence 里那些 token,本来还是 CPU 里的数据,到了 prepare 之后,它们就变成了 GPU 上的 Tensor,这一步其实就是一个非常典型的 CPU → GPU 数据准备过程。
Note :这里还有一个值得顺手提一下的小细节,那就是在构造 Tensor 的时候用了 pin_memory=True,也就是我们常说的 pinned memory(页锁定内存) ,他这样做的主要原因就是为了让 CPU 到 GPU 的数据传输更高效。。关于 pinned memory 的介绍,大家可以看下之前杜老师课上的介绍:3.3.cuda运行时API-内存的学习,pinnedmemory,内存效率问题
OK,那除了根据 action 去执行 prepare_prefill() 或者 prepare_decode() 这条主线之外,run() 里其实还有另一条分支路径,就是图里最左边的 prepare sample ,这一条路径主要是为了最后的 采样(sample) 做准备。
在代码里对应的是:
python
def prepare_sample(self, seqs: list[Sequence]):
temperatures = []
for seq in seqs:
temperatures.append(seq.temperature)
temperatures = torch.tensor(temperatures, dtype=torch.float32, pin_memory=True).cuda(non_blocking=True)
return temperatures可以看到,这里它主要做的事情其实比较简单,就是把和采样相关的参数比如说 temperature 整理好并转换成 GPU 上可用的 Tensor。
所以这条路径虽然存在,但它并不是马上就会被用到。它更多是提前把最后那一步采样所需要的参数先准备好。
好,那接下来我们再回到主线。
不管是 prepare_prefill() 还是 prepare_decode(),它们做完之后最终都会得到:
input_idspositions
然后这些内容就会被送到我们图里的这个 Model & KV Cache 黑盒,也就是我们下集要完整展开讲的那部分核心算法。所以在上集这里,我们对这个部分仍然保持一个黑盒视角,只需要知道 prepare 这一部分负责把 sequence 整理成模型真正能够执行的输入格式,然后把它送进黑盒去做计算。
不过在真正进入这个黑盒之前,中间还有一个 可选的优化环节,也就是图中这个 optional CUDA graph,这里就分成两种情况了:
第一种情况是当前推理没有开启 CUDA Graph,那么就直接进入黑盒,执行 compute_logits;第二种情况是当前推理开启了 CUDA Graph,那么就会先经过 CUDA Graph 这一层优化,然后最终还是进入 compute_logits。
也就是说,不管开没开启 CUDA Graph,我们最后都会走到 compute_logits,只是中间有没有经过 CUDA Graph 这个优化层而已。
那 CUDA Graph 到底是什么,我们该怎么来理解它呢?🤔
在这里我们仍然不展开太多实现细节,只先从一个比较宏观的角度去理解它,你可以把 CUDA Graph 理解成 NVIDIA GPU 提供的一种更高阶的软件优化能力,用来加速那些 "计算流程高度固定、重复执行很多次" 的 GPU 计算过程。
因为在推理过程中,很多时候你会反复做非常相似的一类计算:
- 输入 Tensor 的形状很接近
- 执行流程也是固定的
- 调用的 kernel 序列也差不多
在这种情况下,如果每次都从头走一遍完整的 launch 和调度流程,其实会有不少额外开销。而 CUDA Graph 做的事情,可以理解成是 把这整套 GPU 计算流程以一种更适合重复执行的方式缓存下来,从而减少重复调度带来的额外成本。
所以它并不是像 KV Cache 那样去缓存"某个具体数据",而更像是在缓存 一段可重复执行的 GPU 计算过程,这就是为什么它是一种比较高级的优化功能。
在这里我们只需要知道 vLLM / nano-vllm 在这个环节利用了 NVIDIA GPU 提供的 CUDA Graph 能力,来进一步优化这些 Tensor 在 GPU 上的执行过程。
好,那经过黑盒执行完 compute_logits 之后,最终会得到一个结果:logits,这里我们图中仍然用 红色 表示它,因为它还是一个 GPU 显存上的 Tensor 对象。
那 logits 到底是什么呢?
简单来说,logits 不是 "模型已经帮你选好了最终答案",而是 模型对 "下一个 token 可能是什么" 给出的一组分数 ,也就是说,模型会对很多候选 token 分别给出一个分数,这些分数代表它们各自作为下一个 token 的可能性高低。所以 logits 更像是 候选结果的得分表,而不是最终答案本身。
那接下来就来到了最后这一步 sample ,也就是从 logits 里边真正采样出一个 token。那 sample 的定义就是 从多个候选 token 中选出一个最终结果,这个过程本身就叫做 sample(采样)。
所以你可以这样理解:
logits给出的是 "多个可选答案的分数"sample做的是 "从这些可选答案里选出一个最终答案"
那一轮 decode 对应的是采样出 一个 token,如果你连续做很多轮 decode,最后就会得到很多个 token,拼接起来就变成最终生成的文本结果。
Note :关于采样方法的介绍,大家感兴趣的可以看看:理解llama.cpp如何进行LLM推理
那为什么最后这个采样过程不做成一个完全确定的过程,而是让它带有一定的随机性呢?🤔
原因在于如果我们总是简单地选那个 分数最高的 token,那模型当然也能工作,但是这样做的问题是每次结果都会特别固定,表达会非常死板,多样性也会很差。而真实的大语言模型之所以会有一种 "生成" 的感觉,很大程度上就是因为它并不是每次都机械地选同一个最高分答案,而是在一个合理的候选范围内带有一定随机性地进行采样。
所以你也可以理解为 采样阶段引入的随机性,本质上就是模型生成多样性的来源之一,这也是为什么同样一个输入,多次执行之后整体语义可能类似但具体表达方式往往会有细微差异。
好,那既然 sample 里有随机性,就会有一个很自然的问题:这个随机性到底要控制到什么程度,由什么来控制呢?
这里有一个最重要的参数,那就是我们在很多 LLM API 里都会看到的 temperature 温度 这个参数,它最终会影响 logits 分布的形状。
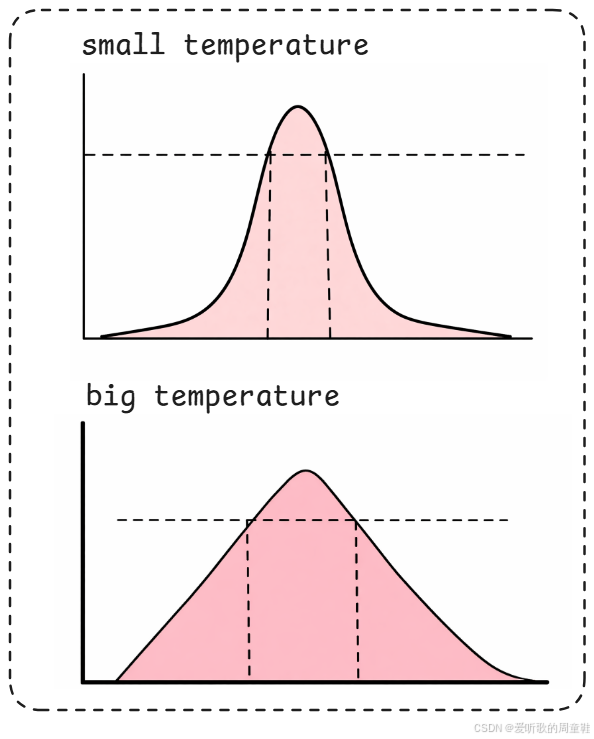
在图中我们画了两张情况:
- small temperature
- big temperature
你可以把它很直观地理解成:
- temperature 越小,logits 的分布会越 瘦高
- temperature 越大,logits 的分布会越 矮胖
这就是它最直观的效果。
那这个分布形状变化以后,会带来什么影响呢?图中画了一条横线,我们可以把它理解成一个 "合理候选分数阈值" 就可以了。也就是说,那些分数特别低的 token,往往本身就不太合理,甚至可能是完全错误的,所以它们一般不会进入最终可采样的候选范围,只有高于这个阈值的区域,才算是一个"有意义的候选区间"。
那么如果 temperature 比较小,分布更瘦高,在同样阈值下最终高于阈值的区间会更窄,也就是说可选范围更小;如果 temperature 比较大,分布更矮胖,在同样阈值下高于阈值的区间会更宽,也就是说可选范围更大。
所以最终的采样过程,就是从这个 "可选区间" 里随机挑选一个结果。那么自然就会得到一个非常直观的结论:
- temperature 越小 → 随机性越小 → 结果越稳定
- temperature 越大 → 随机性越大 → 结果越发散
所以平时我们说 temperature 控制模型的 "创造力",本质上控制的其实就是 采样范围到底是更窄还是更宽。
Q & A
Q:那其实如果大家测试过一些 LLM API 的话会发现就算将采样温度设置为 0,相同的提示词多次给到模型时输出的结果也不能保证 100% 一致,仍然存在一定的随机性,大家可以思考一下为什么?
A :那这里有一篇非常不错的文章详细解释了这个事情,强烈建议大家阅读:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/,这里博主简单解释下:
很多人会认为:temperature = 0 使用的是 greedy decoding(直接选择概率最大的 token),因此模型输出应该是完全确定的,但如果大家实际测试过就会发现,即使温度设为 0,相同 prompt 多次推理的结果仍然可能不一致。
一个比较常见的解释是:GPU 并行计算 + 浮点数误差 。由于 GPU 在执行矩阵乘法、attention 等操作时是高度并行的,而浮点数运算又不满足严格的结合律(例如 ( a + b ) + c ≠ a + ( b + c ) (a+b)+c\neq a+(b+c) (a+b)+c=a+(b+c)),因此不同线程的执行顺序可能会导致数值出现微小差异,从而让最终结果产生变化。
不过文章指出,这个解释其实 并不完全准确。在很多情况下,即使 GPU 并行执行,同一个 kernel 多次执行仍然可以得到完全一致的结果,因此单纯的并行计算并不是推理不确定性的主要来源。
根据文章的分析,更关键的原因在于:LLM 推理中的一些 GPU kernel 对 batch size 不具备不变性(batch invariance) 。在真实部署环境中,推理服务通常会把多个请求动态合并成 batch 来提高 GPU 利用率,因此同一个 prompt 在不同的时间运行时,很可能会处在 不同的 batch size 下进行计算。
而当 batch size 变化时,一些算子(例如 RMSNorm、矩阵乘法、Attention 中的 reduce 操作 )在 GPU 上执行时,其 kernel 的计算路径(例如 tile 划分、线程并行方式、reduction 顺序等)可能会发生变化 ,由于浮点数运算不满足结合律,这就会导致 logits 出现 极其微小的数值差异。
虽然这些差异非常小,但由于 LLM 是 逐 token 生成文本 的,如果某一步 logits 的最大值发生了微小变化,就可能选择不同的 token。一旦某一步生成结果不同,后续生成就会逐渐分叉,最终导致整体输出完全不同。
因此,即使 temperature = 0,在工程系统层面上模型推理仍然可能表现出一定的 非确定性(nondeterminism)。
OK,那这里我们其实就把 Model Runner 里面的一些实现细节都讲清楚了,包括 prefill / decode 的准备工作是怎么发生的、CUDA Graph 的优化是插在什么位置上的、logits 是什么、sample 是什么、temperature 又是如何影响最终采样结果的,所有这些我们都有讲解。
那到这里为止,上集里面的 整体架构 和 核心工程实现 ,我们就已经全部讲完了。而在下集,我们就会把 Model & KV Cache 这个小黑盒,也就是模型和底层 KV Cache 数据面的执行过程,完整地展开来看。
这样大家对于一个推理引擎到底需要完成哪些工作,就会有一个非常完整的理解了。
好,那本期的内容就到这里。
10. Q & A
Q :大家可能在很多 vLLM 的解析文章或视频中,经常听到一个核心优化点叫 PagedAttention。但在这一整篇文章我们似乎从头到尾都没有提到这个词,却已经把整个推理流程基本梳理完了,只剩下模型推理和 KV Cache 的部分还没有展开,那么 PagedAttention 是不是其实已经被间接讲到了呢?
A :简单来说,PagedAttention 并不是一个单独的模块名称,而是一整套围绕 KV Cache 管理与访问方式的设计思想 。它的核心目标,是解决大模型推理过程中 KV Cache 带来的显存碎片和低效利用问题。如果用一句话概括:PagedAttention = KV Cache 的分页管理机制 + 对应的 Attention 读取方式。
在传统的推理实现中,每一个 sequence 的 KV Cache 往往需要一块 连续的显存空间。但在真实的推理服务中,sequence 的长度是动态变化的,如果每个 sequence 都独占一块连续显存,就会很容易产生严重的显存碎片,同时也会导致大量空间浪费。
PagedAttention 的核心思路和操作系统中的 虚拟内存分页(Paging) 非常类似:
- 不再为每个 sequence 分配一整块连续的 KV Cache
- 而是把 KV Cache 切分成很多 固定大小的 block(页)
- sequence 只需要记录 自己使用了哪些 block
- Attention 在读取 KV Cache 时,通过 block table 来找到对应的 block
这样一来,就带来了几个重要的好处:
- KV Cache 不需要连续显存
- 可以按需分配和回收 block
- 多个 sequence 之间可以复用缓存
- 显存碎片大幅减少
而如果你回顾一下我们前面讲过的 Block Manager,就会发现它其实正是在做这件事情:
- 管理 block 的分配与回收
- 维护 block table
- 维护 引用计数
- 记录 哪些 sequence 使用了哪些 block
所以从架构上来说:
- Block Manager 是 PagedAttention 这套机制的"控制平面(CPU侧管理逻辑)"
- 而真正执行 Attention 计算、按照 block table 去读取 KV Cache 的那一部分,则是在 Model & KV Cache 的执行阶段(GPU侧的数据面)
也就是说 PagedAttention 的组成是:
- Block Manager(CPU 侧:分页管理)
- Attention Kernel + KV Cache(GPU 侧:分页访问)
因此在本篇文章中,虽然我们没有直接使用 PagedAttention 这个术语,但其实已经讲到了它的一半核心内容,也就是 Block Manager 这一部分的分页管理机制。
而在下一篇文章中,当我们继续展开 Model & KV Cache 的执行细节时,就会看到另一半内容:Attention 在计算时是如何根据 block table 去访问 KV Cache 的 。当这两部分拼在一起的时候,整个 PagedAttention 的完整实现就会非常清晰了。
结语
本篇文章我们主要从工程实现和系统架构的角度,对 nano-vllm 这个项目做了一次较为完整的梳理,重点关注了一个推理引擎从接收请求到返回生成结果,中间都需要经过哪些核心环节。
在开头部分,我们先介绍了 nano-vllm 这个项目本身的定位。它虽然代码量不大,但保留了 vLLM 中很多非常关键的设计,因此非常适合作为理解推理引擎整体架构的一个入门版本。随后我们也对整篇内容做了拆分说明:上集主要关注整体架构和工程实现,下集则会继续展开模型执行与 KV Cache 数据面的细节。
在主线流程部分,我们从 LLM.generate() 这个最外层接口开始,一路分析了 prompt 是如何经过 tokenizer 转换成 sequence,并进入 Scheduler 参与调度的。这里最核心的一个思想是:推理引擎内部真正流转的对象,不再是原始文本,而是一个个携带状态信息的 sequence;而整个系统也正是围绕 sequence 来完成后续的调度、缓存管理和模型执行。
在 Scheduler 小节中,我们重点梳理了 waiting queue 和 running queue 这两个核心队列,以及 prefill / decode 两种不同阶段对应的调度逻辑。这里可以看到,vLLM 的推理并不是简单地 "来了一个请求就立刻执行一个请求",而是通过调度器把生产和消费拆成两个相对异步的过程,并尽可能把多个 sequence 聚合起来做批处理,以提升整体吞吐。
接着我们分析了 Block Manager 的设计。这个模块本质上是 KV Cache 的 CPU 侧控制器,它通过 block、hash、引用计数以及 free/used block id 等数据结构,把底层显存中的缓存状态抽象成了一套可以高效管理的逻辑结构。通过这一层设计,我们也进一步理解了 sequence 和 block 的区别,以及 block 级缓存复用在整个推理系统中的意义。
在 Model Runner 部分,我们先讨论了 TP 并行系统,也就是在单机多卡场景下,多个 runner 如何通过 shared memory 完成指令同步,并基于各自不同的 rank 来分担模型执行任务。之后我们又继续看了 Model Runner 的执行细节,包括 prefill / decode 的准备过程、CPU 对象到 GPU Tensor 的转换、CUDA Graph 所处的优化位置,以及最终 logits、sample 和 temperature 这些生成相关概念在整个链路中的作用。
整体来看,上集的内容虽然没有真正展开模型内部每一层的计算细节,但已经从工程视角把一个推理引擎需要完成的主要工作串联了起来:请求接入、调度、批处理、缓存管理、多卡并行以及最终的模型执行与采样输出。理解了这一层之后,再去看更底层的模型执行和 KV Cache 数据面,就会顺畅很多。
下一篇文章我们就会继续把上集里一直保留为 "黑盒" 的 Model & KV Cache 彻底展开,进一步看看模型推理到底是如何在底层执行的,以及 KV Cache 在数据面上究竟是如何组织和工作的,敬请期待🤗