掌握 Agentic AI 技术:AI Agent 定制方法全景与实践路径
企业正在把自主 AI Agent 放进越来越多的工作流:物流调度、支持工单分流、代码生成、内部知识检索、数据分析,以及跨多个系统的流程编排。问题也随之变得很具体:一个通用基础模型怎样才能真正适配你的业务任务,而不是只在演示里表现不错?
答案不是简单地"换一个更大的模型"。Agent 的能力来自模型、上下文、工具、技能、数据和评估的组合。定制的目的,是让 Agent 在约束下做出正确判断,选择正确工具,生成可被系统消费的输出,并且在复杂、模糊或证据不足的情况下仍然保持可靠。
这篇文章按照原文的框架,系统梳理 AI Agent 定制的九类技术,以及如何根据任务特点、资源条件和项目成熟度选择路线。文中也补充一些开发者可直接迁移的代码和工程结构示例。
为什么需要定制 AI Agent?
基础模型具备广泛的语言理解、推理和多模态能力,但企业任务通常需要额外的上下文。这个上下文可能是内部知识库、私有 API、行业术语、业务规则、审批流程,也可能是某个团队对输出格式和风险边界的严格要求。
例如,一个通用模型可以解释"服务延迟升高"是什么意思,但生产环境中的运维 Agent 还必须知道:
- 该服务对应哪些指标和仪表盘
- 哪些 runbook 是权威来源
- 哪些操作可以自动执行,哪些必须人工确认
- 输出应该是给人读的摘要,还是给系统消费的 JSON
- 当证据不足时,应该追问、降级,还是拒绝执行
Agent 定制就是围绕这些问题重塑系统行为。它不只是让模型"知道更多",还包括让 Agent 知道如何推理、如何调用工具、如何组织输出,以及如何在真实工作流中稳定完成任务。
Agent 定制会用到哪些技术?
Agent 定制方法从轻到重可以覆盖整个光谱:最轻的是提示词和系统提示词,最重的是强化学习。它们解决的问题不同,投入成本也不同。选型时先判断你缺的是信息、能力、格式稳定性,还是更深层的行为可靠性。
Prompt engineering and system prompts
提示词工程是最容易开始的定制方式。它不改变模型权重,只在推理时通过 system prompt、开发者指令、工具说明和输出约束来塑造 Agent 行为。几乎所有 Agent 项目都应该从这里开始。
How it works
系统提示词通常定义四类信息:角色、可用工具、输出格式和行为边界。例如,下面这个提示词把一个通用模型约束成运维排障 Agent:
text
你是一个生产环境工单诊断 Agent。
你可以读取监控指标、查询 runbook、查看最近部署记录。
你必须基于证据做判断,不允许编造指标或操作结果。
输出必须是 JSON:
{
"action": "ask_for_more_context | summarize | recommend | escalate",
"confidence": 0.0,
"evidence": [],
"next_steps": []
}
如果证据不足,action 必须是 ask_for_more_context 或 escalate。开发者最好把提示词版本化,而不是直接写在代码里:
python
from pathlib import Path
def load_prompt(name: str) -> str:
return Path("prompts", f"{name}.md").read_text()
messages = [
{"role": "system", "content": load_prompt("incident_triage")},
{"role": "user", "content": "checkout 服务 p95 延迟升高,是否需要回滚?"},
]When to use
当你还在快速试验 Agent 行为、任务可以用自然语言清楚描述、或者还没准备好投入训练数据和 GPU 资源时,提示词工程是最合适的第一步。它也适合作为所有后续方法的基线。
Limitations
提示词会随着任务复杂度变脆。约束越多、推理链越长、输出格式越严格,模型越可能在边界条件下偏离要求。提示词也不能扩展模型的核心能力:如果模型不知道你的内部文档,单靠提示词无法凭空获得事实;如果模型不会稳定调用复杂工具,也可能需要训练或更强的工具编排。
此外,模型切换后提示词需要重新评估。一个在旧模型上稳定工作的 system prompt,在新模型上可能出现不同解释。
Retrieval-augmented generation
RAG 解决的是知识缺口。基础模型的参数知识可能过时,也无法包含企业私有信息。RAG 在推理时从外部知识源检索相关内容,再把检索结果放入模型上下文,让 Agent 基于证据回答。
How it works
典型 RAG 流程包括文档切分、向量化、索引、召回、重排和生成。用户提问时,系统先检索相关文档,再把文档片段与问题一起交给模型。
python
def rag_context(question, retriever, reranker=None, top_k=8):
docs = retriever.search(question, top_k=top_k * 3)
if reranker:
docs = reranker.rank(question, docs)[:top_k]
else:
docs = docs[:top_k]
return "\n\n".join(
f"[{i}] source={doc.url}\n{doc.text}"
for i, doc in enumerate(docs, start=1)
)
def build_rag_prompt(question, context):
return f"""请只基于资料回答问题,并在关键结论后标注来源编号。
资料:
{context}
问题:
{question}
"""更进一步,标准 RAG 正在演化为 agentic RAG:Agent 不只是被动接收一次检索结果,而是会自己决定查什么、是否改写查询、是否需要更多证据,以及什么时候停止检索。
When to use
当 Agent 需要访问最新信息、私有知识、内部规范或变化频繁的业务内容时,优先考虑 RAG。它也适合降低幻觉,因为回答可以锚定到权威资料。
Limitations
RAG 会增加延迟,并受检索质量和上下文窗口限制。它补的是信息,不会直接提升模型的推理能力。如果召回错了、切分不合理、文档权威性混乱,模型仍然会基于错误证据生成看似合理的答案。
Agent tool and skill injection
工具和技能注入解决的是"Agent 能做什么"。工具是可调用函数,比如搜索、读写文件、查数据库、调用 API、执行 shell。技能是完成某类任务的领域说明,通常包含指令、脚本、模板和示例。
工具让 Agent 能接触外部世界,技能让 Agent 知道如何在特定领域执行任务。二者可以在不修改模型权重的情况下,把通用模型变成专用系统。
How it works
一个工具应该有清晰的 schema、权限边界、超时策略和错误返回。下面是一个简化的工具定义:
python
from pydantic import BaseModel, Field
class MetricQuery(BaseModel):
service: str = Field(description="服务名,例如 checkout-api")
metric: str = Field(description="指标名,例如 p95_latency_ms")
window: str = Field(default="15m", description="查询时间窗口")
def query_metric(args: MetricQuery) -> dict:
# 实际项目中这里会调用 Prometheus、Datadog 或内部指标平台。
return {
"service": args.service,
"metric": args.metric,
"window": args.window,
"value": 238,
"unit": "ms",
}技能则可以组织成目录:
text
skills/
incident-triage/
SKILL.md
scripts/
collect_metrics.py
summarize_logs.py
templates/
incident_report.mdSKILL.md 不只是说明文档,而是告诉 Agent 什么时候触发这个技能、需要哪些输入、应该按什么步骤执行、输出什么文件。
When to use
当你要扩展 Agent 的行动范围,而不是改变模型推理方式时,优先使用工具和技能。连接内部 API、自动生成报告、执行诊断脚本、调用第三方系统,都属于这类场景。
Limitations
工具调用需要模型具备基础 tool-calling 能力。复杂编排可能仍不稳定,尤其是多工具、多轮、失败重试和条件分支场景。另外,技能说明会消耗上下文窗口,技能越复杂越需要良好的触发策略和压缩表示。
Supervised fine-tuning
SFT 是第一类训练时定制方法。它通过带标签样本调整模型权重,让模型模仿理想输出。与 Prompt、RAG、工具不同,SFT 改变的是模型行为本身。
How it works
你需要准备输入和理想输出。例如,把自然语言请求映射为结构化工具调用:
jsonl
{"messages":[{"role":"user","content":"查看 checkout-api 最近 15 分钟 p95 延迟"}],"response":{"tool":"query_metric","arguments":{"service":"checkout-api","metric":"p95_latency_ms","window":"15m"}}}
{"messages":[{"role":"user","content":"如果支付错误率超过 2%,升级给 oncall"}],"response":{"tool":"create_incident","arguments":{"service":"payments","condition":"error_rate > 2%","priority":"high"}}}NVIDIA NeMo Data Designer 这类合成数据工具可以帮助低资源领域扩展样本。团队可以先定义 schema 和任务分布,再用 LLM 生成多样化训练对,之后用人工抽检和规则验证控制质量。训练可通过 NeMo 框架等工具完成。
When to use
当任务边界清楚、你有可访问的数据、并且需要模型稳定生成特定格式时,SFT 很合适。它常用于结构化 JSON、工具调用、领域术语、固定报告格式等场景。
Limitations
SFT 的质量完全依赖数据质量。样本差,模型会学坏;样本太窄,模型会过拟合;训练分布和真实分布差异太大,线上效果会下降。SFT 也需要计算资源,并可能引入灾难性遗忘。
Parameter-efficient fine-tuning
全量微调大模型代价很高。PEFT 方法,尤其是 LoRA 和 QLoRA,通过冻结大部分模型参数,只训练少量可插拔参数,大幅降低训练和存储成本。
How it works
LoRA 会在注意力层或前馈层中注入小的可训练矩阵。基础模型保持不变,不同任务使用不同 adapter。源文提到,NVIDIA Nemotron 3 Nano 具有 300 亿总参数,每次前向约 35 亿活跃参数;在这种规模下,LoRA 让维护多个专业版本变得现实。
QLoRA 进一步把基础模型量化到 4-bit,使单 GPU 上微调更大的模型成为可能。
python
# 伪代码:表达 LoRA adapter 的使用方式
base_model = load_base_model("nemotron")
adapter = load_lora_adapter("customer-support-v1")
model = attach_adapter(base_model, adapter)When to use
当 GPU 资源有限、需要维护多个领域版本、希望快速迭代训练时,PEFT 通常是首选。它也是实际 Agent 微调中最常见的路径之一。
Limitations
PEFT 只训练一小部分参数,改变能力有上限。如果任务需要深层能力迁移或大规模行为重塑,LoRA 可能不够。
Direct Preference Optimization
SFT 让模型模仿好样本,DPO 则让模型学习偏好。它使用同一个输入下的成对回答:一个 preferred,一个 rejected。偏好信号可以来自人类、LLM judge、规则验证器或合成数据。
How it works
DPO 不需要单独训练 reward model。它通过成对比较,让模型提高 preferred response 的相对概率,降低 rejected response 的概率。
json
{
"prompt": "总结这个事故并给出下一步",
"chosen": "包含证据、影响范围和明确下一步的回答",
"rejected": "只有泛泛建议、没有引用指标的回答"
}When to use
当输出质量带有主观偏好时,DPO 很有用。例如语气、帮助程度、安全边界、解释风格、报告完整度。它也适合作为 SFT 后的精修步骤。
Limitations
DPO 需要高质量偏好对。合成偏好可能带有 judge bias 或错误 rubric。对于严格可验证的任务,比如代码测试、JSON 正确性或数学答案,DPO 通常不如可验证奖励直接。
Reinforcement learning
强化学习是一类通过奖励信号优化行为的技术。Agent 定制中的 RL 关注的是多步骤行为,而不是单次文本输出。
Reinforcement learning from human feedback
RLHF 通过人类偏好训练 reward model,再用强化学习让策略模型最大化 reward。它能捕捉语气、安全性、帮助程度等复杂主观标准。
How it works
人类标注者对多个输出排序,reward model 学习这些偏好。之后,Agent 在训练中生成输出,reward model 给分,策略模型根据分数更新,同时保持不要偏离原始模型太远。
When to use
当目标难以用规则表达,并且你有足够标注资源和训练基础设施时,RLHF 值得考虑。安全对齐、帮助性、伤害规避等场景常见。
Limitations
RLHF 实现复杂,需要同时管理 policy、reference、reward、critic 等模型,计算成本高,训练不稳定,还可能出现 reward hacking。
Reinforcement learning with verifiable rewards
RLVR 用确定性验证器替代 learned reward model。对于有明确对错标准的任务,它更透明、更可审计,也更适合工程自动化。
How it works
假设 Agent 要把自然语言翻译成 CLI JSON。验证器可以检查 JSON 是否有效、命令是否正确、flag 是否匹配、测试是否通过,然后返回精确奖励。
python
import json
def reward_cli(output: str, expected_cmd: str, expected_flags: dict) -> float:
try:
payload = json.loads(output)
except json.JSONDecodeError:
return -1.0
if payload.get("command") != expected_cmd:
return -1.0
flags = payload.get("flags", {})
matched = sum(flags.get(k) == v for k, v in expected_flags.items())
return matched / max(len(expected_flags), 1)NVIDIA NeMo Gym 提供这类 verifier endpoint,可在训练期间对模型输出进行评分。DeepSeek-R1 的推理能力突破也展示了可验证奖励在复杂推理中的潜力。
When to use
当任务有客观正确性标准时,RLVR 非常合适:结构化数据、CLI 命令、代码、数学推理、工具调用、单元测试等。
Limitations
RLVR 不适合创造性、主观性或开放式生成。你必须构建验证基础设施,奖励函数设计不好也会把模型带偏。
Group Relative Policy Optimization
GRPO 是一种高效策略优化算法,常与 RLVR 搭配。它为每个 prompt 生成多个候选答案,用同组候选的平均值和方差作为相对基线,而不是像 PPO 那样训练 critic network。
How it works
对于每个训练样本,当前策略生成 4 到 64 个 completion。验证器为每个 completion 打分。GRPO 计算每个 completion 相对组内均值的优势,高于平均的被强化,低于平均的被抑制。
这种方式减少了 PPO critic 带来的复杂度,也让训练更适合可验证奖励场景。
When to use
当你已经有 RLVR 奖励函数,又希望降低 RL 训练复杂度和计算开销时,GRPO 是很自然的选择。
Limitations
GRPO 需要每个 prompt 生成多个 completion,因此单步训练成本高于 SFT。组大小太小会导致 baseline 噪声大。最终效果仍然强依赖奖励函数质量。
什么是 AI Agent 定制的多阶段流水线?
实践中,最有效的 Agent 定制通常不是单一技术,而是阶段组合。
Stage 1: Prompt engineering plus tools and skills plus RAG
先用系统提示词、工具、技能和检索建立可运行基线。这一步成本最低,也能暴露真实失败模式。
Stage 2: SDG
当 Prompt、工具和 RAG 还不够时,用合成数据生成更多任务样本,覆盖低资源领域、边界情况和长尾输入。
Stage 3: SFT
用 SFT 教模型基本词汇、格式和任务结构。例如稳定输出 JSON、正确选择工具、遵守领域术语。
Stage 4: RLVR/GRPO or DPO
在 SFT 之后继续提升质量。主观偏好强的任务用 DPO 更稳定、更便宜;有客观验证标准的任务用 RLVR + GRPO 更有潜力。常见组合是 SFT → DPO → RLVR:先对齐格式和风格,再用可验证奖励推动更难的推理能力。
Stage 5: Evaluation plus iteration
每个阶段都必须评估。指标包括任务成功率、工具调用准确率、轨迹效率、输出格式合规率、延迟和成本。没有评估,定制就会变成凭感觉调参。
如何选择合适的 Agent 定制方法
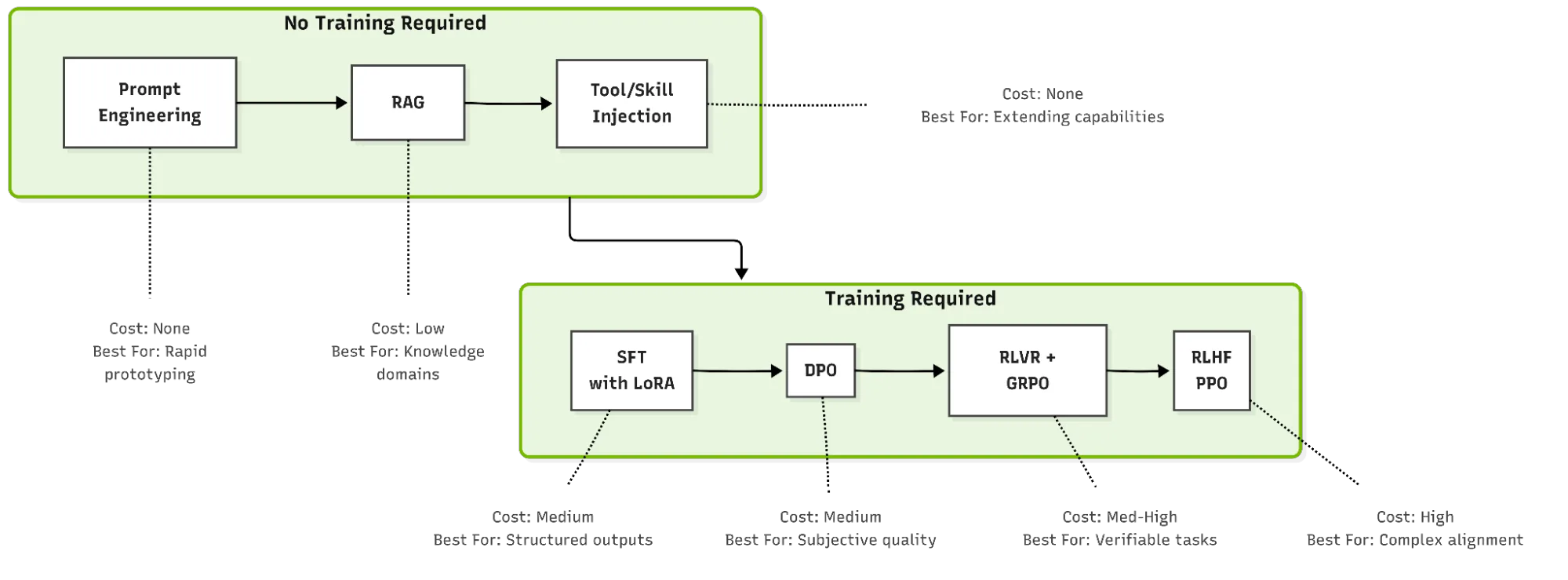
Task characteristics
如果输出可以客观验证,例如 JSON、API 调用、代码测试,RLVR + GRPO 通常价值最高。如果质量偏主观,例如语气、解释风格、帮助程度,DPO 更合适。如果任务定义清晰、模型只需要示例模仿,SFT 可能已经足够。
Available resources
Prompt engineering 几乎不需要训练资源。LoRA SFT 可以在较少 GPU 上完成。全量微调、RLHF 和大规模 RL 需要显著更多计算和数据预算。技术路线必须匹配团队现实资源。
Project maturity
早期项目应优先建设提示词、工具、RAG 和评估集。训练型定制只有在你已经知道失败模式、拥有数据、并能衡量改进时才最有价值。
开始定制你的 AI Agent
Agent 定制是一组逐层叠加的方法,而不是一次性选择。成功团队通常从轻量方法开始,尽早建立评估,然后只在数据证明需要时增加复杂度。
如果你准备进入训练阶段,NVIDIA NeMo 生态提供了覆盖多个环节的工具:NeMo Data Designer 用于合成数据,NeMo Automodel、NeMo Megatron-Bridge 和 NeMo RL 用于模型定制,NeMo Gym 用于可验证奖励,NeMo Agent Toolkit 用于 Agent 编排与评估。
最重要的原则仍然是:先测量,再定制。每一次 Prompt 修改、RAG 调整、LoRA 训练或 GRPO 训练,都应该由清晰指标驱动,并在真实任务上验证。