认识AI和大模型
AI: 人工智能(Artificial Intelligence),使机器能够像人一样思考,学习和解决问题的能力
大语言模型(LLM):
- 在自然语言处理(Natural Language Processing,NLP)中,有一项关键技术叫Transformer(encoder+decoder),这是一种先进的神经网络模型,是如今AI高速发展的最重要的原因
- 我们所熟知的大模型(Large Language Models,LLM),例如GPT,DeepSeek底层都是采用Transformer神经网络模型。
接下来我们以GPT为例讲大语言模型:

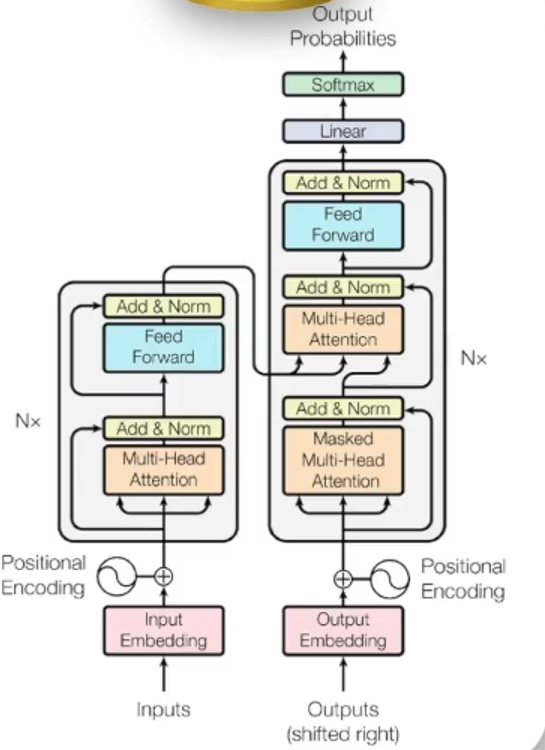
transformer由encoder和decoder组成,如下图所示:
大模型参数
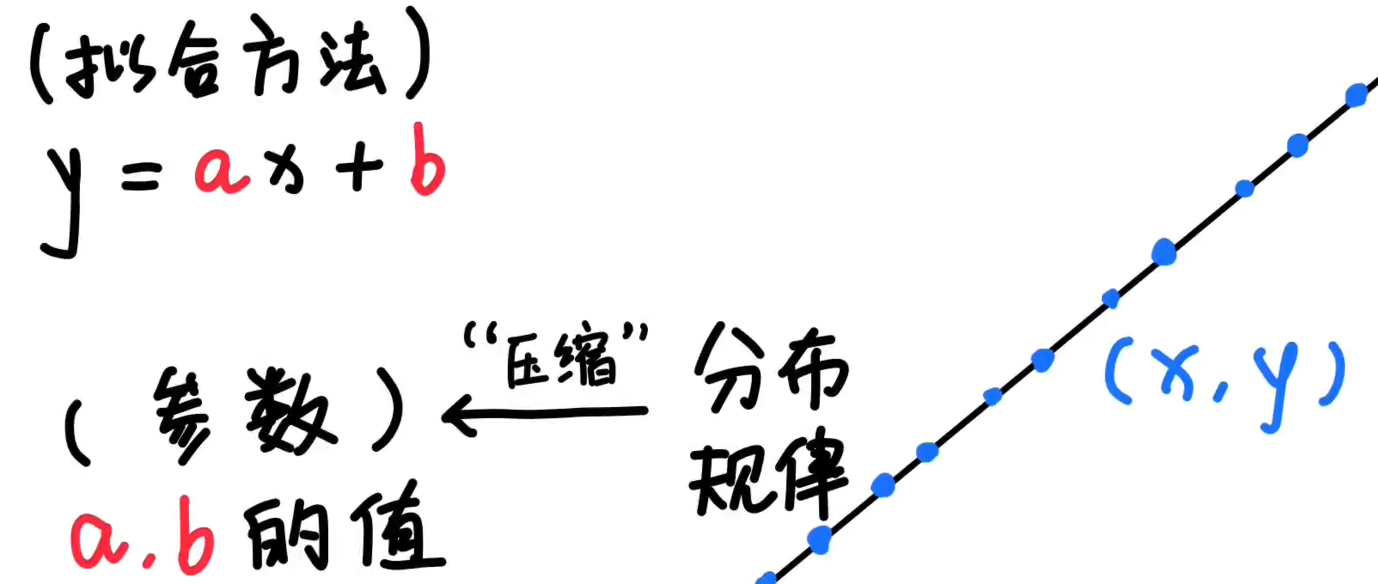
大模型参数其实是大规模机器学习模型中的核心组成部分。简单来说,参数是模型在训练过程中通过数据学习得到的数值,类似于我们拟合直线时求得的系数a和b。它们的作用是帮助模型理解和预测数据之间的关系。
举个例子,假如你想通过一条直线去拟合一组点,你只需要两个参数(比如斜率a和截距b),这就能描述这条直线的变化规律。但对于大模型,尤其是处理像文本、图片、视频这种复杂数据时,参数的数量会暴增,可能达到几百亿甚至几千亿个。每个参数对应着数据分布中的一个细节,帮助模型理解数据背后的规律。
这些参数并不是一开始就有的,而是通过"训练"逐渐调整和优化的。模型一开始的参数可能是随机的,然后它通过不断试错、计算误差并调整参数,最终让自己能够更准确地拟合真实数据的规律。
总结来说,参数是模型内部的变量,可以理解为是模型在训练过程中学到的知识,参数决定了模型如何对输入数据做出反应,从而决定模型的行为。
大模型token
啥是大模型token?比如gpt和deepseek这样的大模型,都有一个刀法精湛的小弟叫分词器;当大模型接收到一段文字,会让分词器给它切成很多个小块,这切出来的每一个小块就叫做一个token;而一个token可能包含一个字,或者多个字。当大模型输出的时候,也是一个token一个token的往外蹦。
既然分词器分出的token不一定只是一个字,那么分词器是怎么分词的呢?其中一种方法大概是这样:分词器统计了大量文字之后,发现某几个字经常一起出现,于是就把他们打包成一个token。
要算力才能产生token,而算力吃的性能,这也是为什么基本上所有公司都是按照token的数量来计费,因为token的数量对应背后的计算量。
大模型靠embedding理解文字
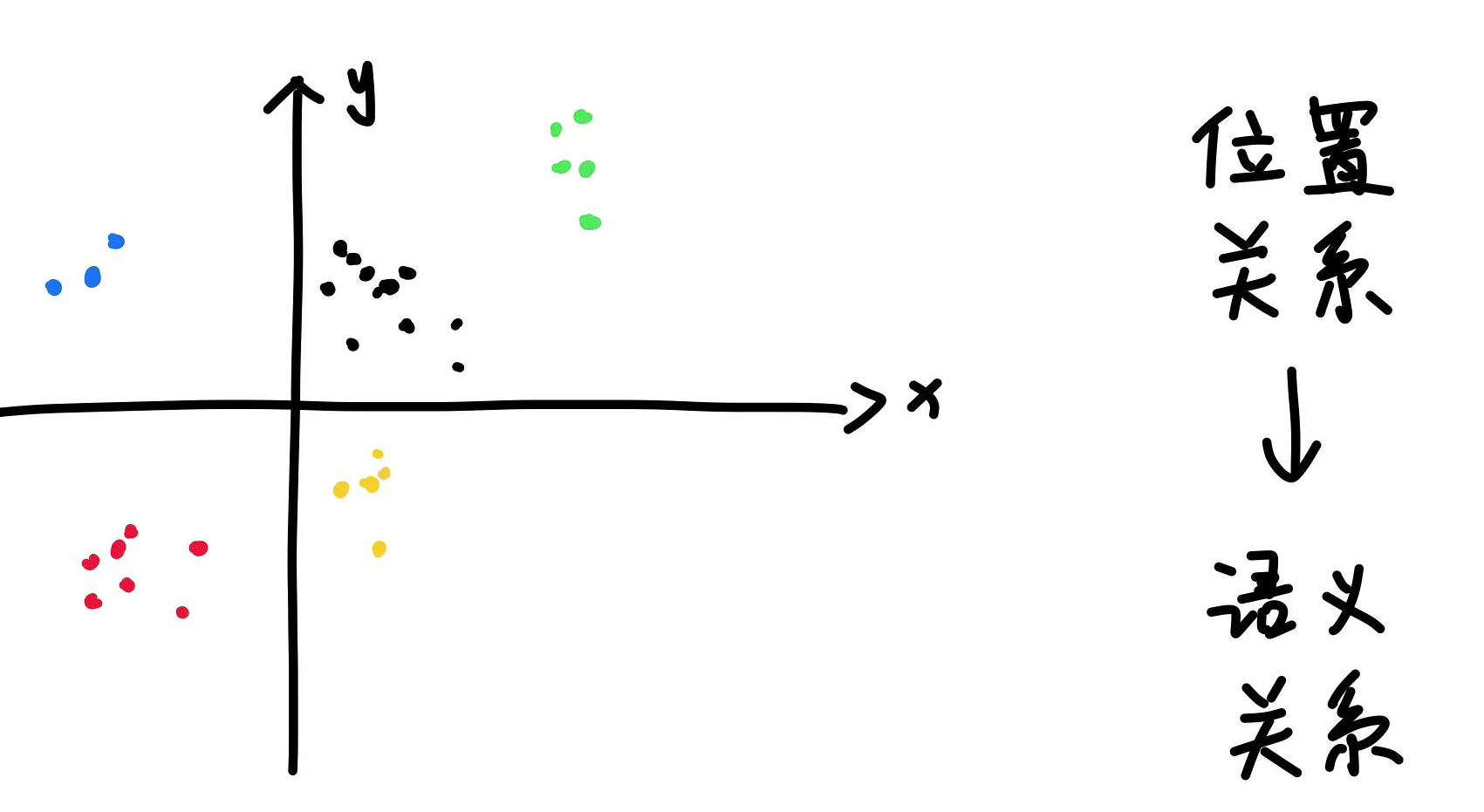
大模型主要靠embedding词嵌入来理解文字。一个词的含义就是由它和其它词的关系决定的,即Tokens with similar meaning have similar embedding.
AI核心词汇理解
AIGC
- AIGC即AI Generated Content(AI生产内容),由AI生成的东西被生成AIGC,其强调AI用于生成创造性内容的能力
generative ai
- generative ai生成式AI,从字面上来看,生成式AI和AIGC的关系很好理解,Generative主要强调的是能够自主创建内容的AI系统,其为AIGC的技术基础。所以gpt,copilot都属于生成式AI
