本测试用于估算表统计信息的收集时间。
测试步骤:
1、创建测试表
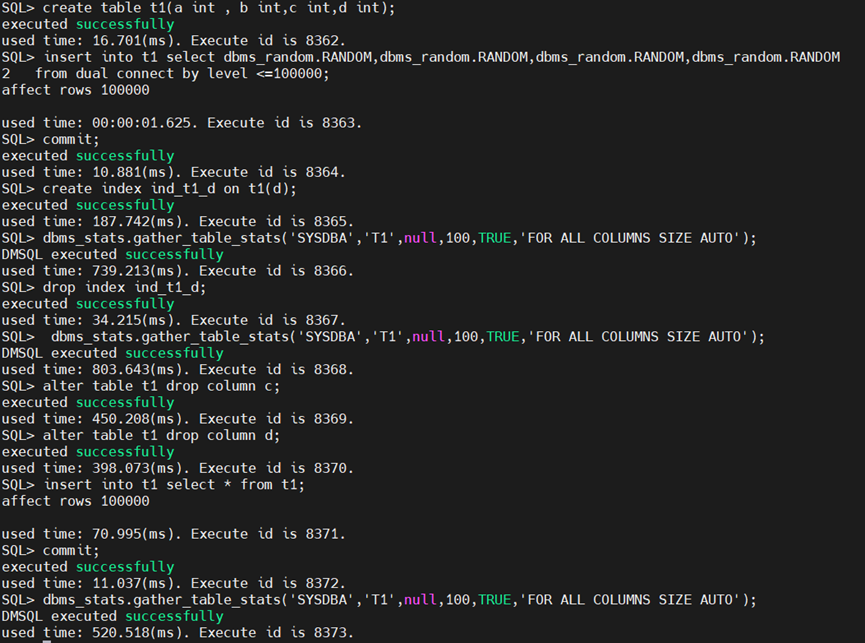
create table t1(a int , b int,c int,d int);
2、写入数据
insert into t1 select dbms_random.RANDOM,dbms_random.RANDOM,dbms_random.RANDOM,dbms_random.RANDOM
from dual connect by level <=100000;
写入10万行随机数据。
3、创建索引
create index ind_t1_d on t1(d);
在d字段上创建索引
4、收集表的统计信息,级联收集其上建立的索引统计信息
dbms_stats.gather_table_stats('SYSDBA','T1',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL executed successfully
used time: 739.213(ms). Execute id is 8366.
5、删除索引
drop index ind_t1_d;
6、再次收集表的统计信息
dbms_stats.gather_table_stats('SYSDBA','T1',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL executed successfully
used time: 803.643(ms). Execute id is 8368.
7、删除一半数量的字段
alter table t1 drop column c;
alter table t1 drop column d;
8、将表的行数增加一倍
insert into t1 select * from t1;
9、收集表的统计信息
dbms_stats.gather_table_stats('SYSDBA','T1',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL executed successfully
used time: 520.518(ms). Execute id is 8373.
结论:
1、索引并不会增加统计信息收集的时间,反之收集总时长会略微减少。
2、字段数量是表统计信息收集时间的因素。上面测试中字段减少一半,行数增加一倍,表的总字节数没有改变的情况下统计信息收集时长由803.643毫秒减少为520.518毫秒。
分析原因:
表的统计信息收集过程会拆解为三个部分:
1、统计表的行数(NUM_ROWS)
系统后台通过执行select count(*) from "T1"这样的语句收集表的统计信息。由于达梦是索引组织表,统计行数非常快。
2、统计字段的NUM_DISTINCT和数据的分布情况
系统后台通过执行select "A" , count(*), 4 from "T1" group by "A" order by 1 这样的语句收集字段的统计信息。这一步比较耗时,但如果该sql可以利用已经排好序的索引,执行时间将会显著缩短。
3、统计索引的BLEVEL、LEAF_BLOCKS
索引一半较小,这一步时间较短。
实测过程: