文章目录
-
- 引言:从"看"到"理解"的视觉智能层级
- 一、算法家族全景:计算机视觉的五大核心任务
-
- [1. 图像分类:识别"是什么"的基础任务](#1. 图像分类:识别"是什么"的基础任务)
- [2. 目标检测:定位"在哪里"的关键技术](#2. 目标检测:定位"在哪里"的关键技术)
- [3. 语义分割:理解"每个像素属于什么"的精细解析](#3. 语义分割:理解"每个像素属于什么"的精细解析)
- [4. 实例分割:"目标检测 + 语义分割"的融合](#4. 实例分割:"目标检测 + 语义分割"的融合)
- [5. 图像生成与合成:从"理解"到"创造"的飞跃](#5. 图像生成与合成:从"理解"到"创造"的飞跃)
- 二、核心思想与哲学对比
- 三、关键特性与应用场景横向对比
- 四、算法选择指南:如何为你的视觉问题匹配合适的工具
- [五、算法演进脉络:从卷积革命到 Transformer 时代](#五、算法演进脉络:从卷积革命到 Transformer 时代)
- 六、可视化汇总
-
- [1. 任务关系与模型分类思维导图](#1. 任务关系与模型分类思维导图)
- [2. 模型选择决策树(以目标检测为例)](#2. 模型选择决策树(以目标检测为例))
- 七、总结与启示:构建面向未来的视觉智能工具箱
引言:从"看"到"理解"的视觉智能层级
计算机视觉的发展,是一场从处理像素到理解语义的认知革命。如果说图像处理教会了计算机"如何看"(处理视觉信号),那么计算机视觉的核心任务则专注于让计算机"理解看到了什么"。这不再是简单的像素操作,而是对图像内容进行高层次语义解析、结构理解和内容创造的复杂过程。
工具箱思维在这一领域显得尤为关键:面对目标检测、图像分割、图像生成等多样化任务,没有一种"银弹"模型能解决所有问题。真正的专家不是掌握最多模型的人,而是最懂得为特定视觉任务设计和实现最优解决方案的人。
一、算法家族全景:计算机视觉的五大核心任务
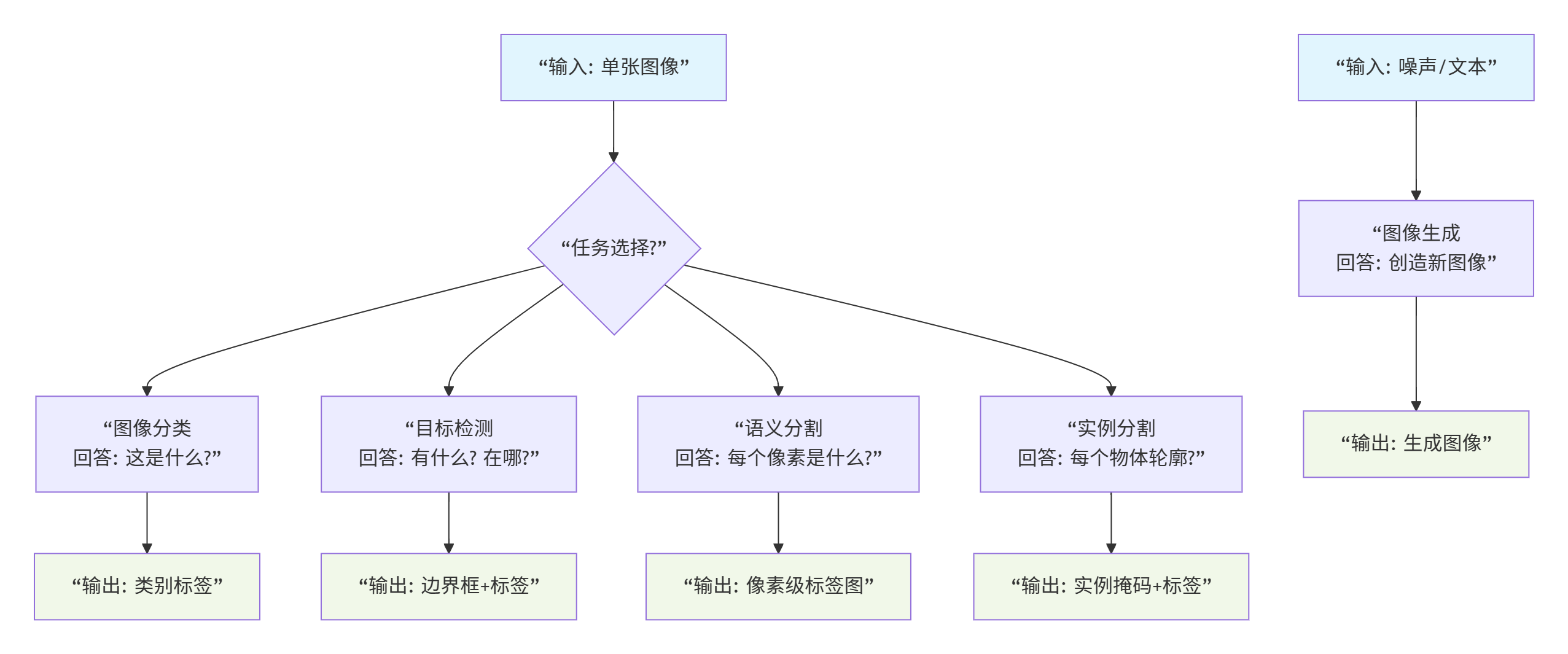
1. 图像分类:识别"是什么"的基础任务
- 核心任务:为整张图像分配一个或多个语义标签,回答"这张图片里主要是什么?"
- 输入输出:输入为图像,输出为类别标签(如"猫"、"狗")及置信度。
- 核心挑战:类内差异大,类间差异小;视角、光照、遮挡变化。
- 评估指标:Top-1 准确率、Top-5 准确率、混淆矩阵。
2. 目标检测:定位"在哪里"的关键技术
- 核心任务:识别图像中感兴趣的目标实例,并用边界框(Bounding Box)标出其位置,同时给出类别标签。
- 输入输出:输入为图像,输出为一组边界框(位置:x,y,w,h)及对应的类别标签和置信度。
- 核心挑战:多尺度、密集目标、小目标检测、实时性要求。
- 评估指标:mAP(平均精度均值)、IoU(交并比)、FPS(帧率)。
3. 语义分割:理解"每个像素属于什么"的精细解析
- 核心任务:为图像中的每个像素分配一个语义类别标签,实现像素级的分类。
- 输入输出:输入为图像,输出为与输入同尺寸的分割掩码(Mask),每个像素值为类别 ID。
- 核心挑战:边界精细度、类别不平衡、上下文信息利用。
- 评估指标:mIoU(平均交并比)、像素准确率、Dice 系数。
4. 实例分割:"目标检测 + 语义分割"的融合
- 核心任务:在语义分割的基础上,进一步区分同一类别的不同实例(个体)。
- 输入输出:输入为图像,输出为每个实例的像素级掩码及类别标签。
- 核心挑战:遮挡处理、实例区分、计算复杂度高。
- 评估指标:mAP(基于掩码)、AP@IoU 阈值。
5. 图像生成与合成:从"理解"到"创造"的飞跃
-
核心任务:从随机噪声、文本描述或其他图像生成新的、逼真的图像。
-
输入输出:输入为噪声向量/文本/图像,输出为生成的图像。
-
核心挑战:生成多样性、图像真实性、训练稳定性、可控生成。
-
评估指标:FID(弗雷歇距离)、IS(初始分数)、人类评估、CLIP 得分。
二、核心思想与哲学对比
| 任务 | 核心思想比喻 | 技术哲学核心 | 关键洞察 |
|---|---|---|---|
| 图像分类 | "全局概括者" | 将整张图像映射到一个高维特征向量,再分类到最相似的语义类别。 | 关注图像的全局特征 和主体信息,忽略细节位置。本质是图像 → 标签的映射。 |
| 目标检测 | "定位与识别者" | 在图像中搜索可能存在目标的区域(候选框),然后对每个区域进行分类和位置精修。 | 解决"定位 + 识别"的联合任务。核心挑战是如何高效、准确地生成候选区域。 |
| 语义分割 | "像素级分类器" | 为每个像素预测其类别,将分类任务从图像级别细化到像素级别,保持空间分辨率。 | 需要编码器-解码器结构,编码器提取特征,解码器恢复空间细节并预测每个像素类别。 |
| 实例分割 | "实例感知的像素分类器" | 在像素级分类的基础上,增加实例区分能力,通常通过添加实例边界预测或基于检测的方法实现。 | 比语义分割更难,需区分同一类别的不同个体。常用"先检测,后分割"的两阶段方法。 |
| 图像生成 | "数据分布学习者" | 学习真实图像数据集的分布,然后从该分布中采样生成新图像,或根据条件(如文本)从条件分布采样。 | 核心是学习分布。GAN 通过对抗博弈,扩散模型通过渐进去噪,VAE 通过编码-解码学习隐空间。 |
三、关键特性与应用场景横向对比
| 维度 | 图像分类 | 目标检测 | 语义分割 | 实例分割 | 图像生成 |
|---|---|---|---|---|---|
| 输出粒度 | 最粗(图像级标签) | 中等(框级) | 细(像素级) | 最细(实例像素级) | 图像级 |
| 核心信息 | "是什么" | "有什么,在哪" | "每个区域是什么" | "每个物体轮廓" | "创造新内容" |
| 典型算法/模型 | ResNet, ViT, EfficientNet | YOLO 系列, Faster R-CNN, DETR | FCN, U-Net, DeepLab | Mask R-CNN, SOLO, Mask2Former | GANs, 扩散模型, VAE |
| 复杂度/计算成本 | 低 | 中到高 | 高 | 最高 | 高(训练),可变(推理) |
| 数据标注成本 | 低(图像级标签) | 中(框标注) | 高(像素级标注) | 最高(实例像素标注) | 无监督/自监督 |
| 实时性潜力 | 高 | 中到高(YOLO) | 中到低 | 低到中 | 低(扩散)到中(GAN) |
| 可解释性 | 中等(CAM 可视化) | 中等(框可视化) | 高(掩码可视化) | 高(实例掩码可视化) | 低(生成过程黑盒) |
| 主要应用场景 | 图像检索、内容过滤、场景识别 | 监控安防、自动驾驶、机器人抓取 | 医疗影像分析、自动驾驶场景解析、遥感解译 | 医学细胞分析、机器人交互、视频编辑 | 艺术创作、数据增强、图像编辑修复 |
| 主流学习范式 | 监督学习 | 监督学习 | 监督学习 | 监督学习 | 无监督/自监督学习 |
| 评估侧重点 | 分类准确性 | 定位准确性 + 分类准确性 | 边界准确性与区域一致性 | 实例区分与边界准确性 | 真实性、多样性、与条件一致性 |
四、算法选择指南:如何为你的视觉问题匹配合适的工具
选择正确的视觉任务和模型,是项目成功的第一步。遵循以下决策路径:
实战选择口诀:
- 只问"是什么" → 图像分类
- 又问"是什么"又问"在哪" → 目标检测
- 问"每个像素是什么" → 语义分割
- 问"每个物体的精确轮廓" → 实例分割
- 问"创造新图像" → 图像生成
- 要快 → 选名字带"Fast"、"Lite"、"Mobile"、"Nano"、"YOLO"的模型
- 要准 → 选 ResNet、Swin Transformer、两阶段检测、U-Net、扩散模型
- 要又准又快 → 选 EfficientNet、YOLOv8、BiSeNet、实时版本的扩散模型
- 数据少 → 用预训练模型 + 微调、数据增强、半监督/自监督学习
- 没标注数据 → 考虑自监督、弱监督、无监督(生成模型)方法
五、算法演进脉络:从卷积革命到 Transformer 时代
计算机视觉核心任务的发展史,是一部模型架构、学习范式和能力边界不断突破的历史。
timeline
title 计算机视觉核心任务演进时间线
section 2012前: 传统方法时代
特征工程为主 : SIFT/HOG + 分类器
section 2012-2014: CNN革命兴起
AlexNet开启深度学习时代 : 2012
R-CNN : 目标检测新范式<br>2014
section 2015-2017: 架构创新与任务细化
FCN : 语义分割里程碑<br>2015
ResNet : 深度网络训练突破<br>2016
YOLO/SSD : 实时检测兴起<br>2016
GANs爆发 : 2014提出,2017年流行
Mask R-CNN : 实例分割标杆<br>2017
section 2018-2020: 注意力机制与效率优化
Transformer入局CV : ViT, 2020
模型轻量化 : MobileNet, EfficientNet
自监督学习兴起 : MoCo, SimCLR
section 2021-至今: 大一统与生成式AI
检测分割统一 : DETR, Mask2Former
视觉基础模型 : SAM (分割一切), 2023
扩散模型革命 : Stable Diffusion, 2022
多模态大模型 : CLIP, 图文联合学习演进主线分析:
- 从手工特征到学习特征:SIFT/HOG → CNN 特征(AlexNet) → 自监督预训练特征
- 从两阶段到单阶段:R-CNN/Fast R-CNN → YOLO/SSD(检测);Mask R-CNN → SOLO/YOLACT(实例分割)
- 从专用模型到统一架构:分类用 CNN,检测用 RPN+CNN,分割用 Encoder-Decoder → Transformer 试图统一(ViT, DETR, Mask2Former)
- 从判别式到生成式:分类/检测/分割(判别数据中的模式) → GAN/扩散模型(生成新的数据)
- 从监督学习到自监督/多模态学习:需要大量标注数据 → 从无标注数据自监督学习 → 从多模态(图文对)中学习
当前技术范式:
- **基础模型(Foundation Models)**:如 SAM(分割一切模型)、CLIP(图文对比学习),在大量数据上预训练,可零样本或少样本迁移到新任务
- 扩散模型主导生成:在图像生成质量、多样性和可控性上全面超越 GAN,成为当前主流
- Transformer 与 CNN 融合:ViT 纯 Transformer 架构与 ConvNeXT 等现代 CNN 架构并存竞争,混合架构(如 Swin Transformer)兼顾全局与局部
- 边缘计算与实时性:模型轻量化、知识蒸馏、量化压缩技术使复杂模型可部署在移动端和边缘设备
六、可视化汇总
1. 任务关系与模型分类思维导图
计算机视觉核心任务
├── 图像理解(判别式任务)
│ ├── 图像分类
│ │ ├── CNN家族: ResNet, DenseNet, MobileNet
│ │ └── Transformer家族: ViT, Swin Transformer, DeiT
│ ├── 目标检测
│ │ ├── 两阶段: R-CNN系列, Mask R-CNN (检测分支)
│ │ ├── 单阶段: YOLO系列, SSD, RetinaNet
│ │ └── Transformer-based: DETR, Deformable DETR
│ ├── 语义分割
│ │ ├── 编码器-解码器: U-Net, SegNet
│ │ ├── 空间金字塔: DeepLab系列, PSPNet
│ │ └── Transformer-based: SETR, SegFormer
│ └── 实例分割
│ ├── 基于检测: Mask R-CNN, Cascade Mask R-CNN
│ ├── 单阶段: SOLO, YOLACT
│ └── Transformer-based: Mask2Former, QueryInst
└── 图像生成(生成式任务)
├── 生成对抗网络 GANs
│ ├── 无条件生成: DCGAN, StyleGAN
│ ├── 条件生成: cGAN, Pix2Pix
│ └── 循环一致: CycleGAN, DiscoGAN
├── 变分自编码器 VAEs
└── 扩散模型
├── 去噪扩散: DDPM, DDIM
├── 文本引导: Stable Diffusion, DALL-E
└── 加速推理: LCM, SDXL-Turbo2. 模型选择决策树(以目标检测为例)
开始:需要目标检测
↓
实时性要求?
├── 是 → 部署平台?
│ ├── 服务器/云端 → YOLOv8, EfficientDet-D7
│ ├── 边缘设备/移动端 → YOLOv5s, NanoDet-plus
│ └── 嵌入式/IoT → Tiny-YOLO, MobileNet-SSD
└── 否 → 精度优先?
├── 是 → 数据集特性?
│ ├── 小目标多 → 带FPN的模型 (RetinaNet, YOLOv8-P6)
│ ├── 遮挡严重 → 带注意力机制的模型 (DETR, Deformable DETR)
│ └── 一般场景 → Faster R-CNN, Cascade R-CNN
└── 否 → 需要最新SOTA → DINO, RT-DETR
↓
考虑标注成本、训练资源、推理速度平衡七、总结与启示:构建面向未来的视觉智能工具箱
通过对计算机视觉五大核心任务的全景解析,我们可以得出以下关键启示:
-
任务驱动,而非模型驱动 :面对实际问题时,首先明确需要什么粒度的理解(分类/检测/分割/生成),再选择相应任务范式,最后挑选具体模型。不要被最新最炫的模型迷惑,适合的才是最好的。
-
理解任务间的层次关系:
- 分类是基础,检测是分类 + 定位
- 语义分割是像素级分类
- 实例分割是检测 + 语义分割
- 图像生成是另一维度的创造能力
- 这些任务可以组合使用构建复杂系统(如先检测人脸,再对人脸区域进行属性分类)
-
**平衡"三大黄金三角"**:
精度 (Accuracy) /\ / \ / \ 速度------资源 (Speed) (Resource)- 高精度模型通常计算量大、速度慢
- 轻量快速模型通常精度有妥协
- 根据应用场景(实时监控 vs.医疗诊断)做出明智权衡
-
数据是瓶颈,也是机遇:
- 监督学习需要大量标注数据,成本高
- 自监督、半监督、弱监督学习是解决标注瓶颈的关键
- 合成数据生成(用生成模型)成为数据增强的新范式
- 基础模型(如 SAM、CLIP)推动少样本/零样本学习
-
从"专用模型"到"通用基础模型"的范式转变:
- 过去:为每个任务训练一个专用模型
- 现在:使用大规模预训练基础模型,通过提示(Prompting)或微调适应下游任务
- 未来:多模态大模型统一视觉、语言等多模态任务
-
部署落地是关键检验:
- 实验室精度高 ≠ 实际应用效果好
- 考虑模型鲁棒性(光照变化、遮挡、模糊)
- 考虑计算资源、功耗、实时性约束
- 考虑模型更新维护成本
工具箱思维的核心在于:面对一个视觉问题时,能够系统性地分析任务需求,在庞大的模型生态中选择最合适的技术路径,并根据约束条件(数据、算力、时间)进行合理折衷。这不仅需要了解各种"工具"(模型算法),更需要理解它们的工作原理、适用场景和组合方式。
随着 AI 技术的快速发展,计算机视觉的工具箱正在迅速扩展和更新。保持持续学习的态度,理解技术演进的内在逻辑,构建自己系统化的知识框架,才能在这个充满机遇的领域中游刃有余,真正将视觉智能技术转化为解决实际问题的强大能力。