Claude Code学习--从搭建Nano Claude Code学习CC机制的底层原理pt2
任务系统
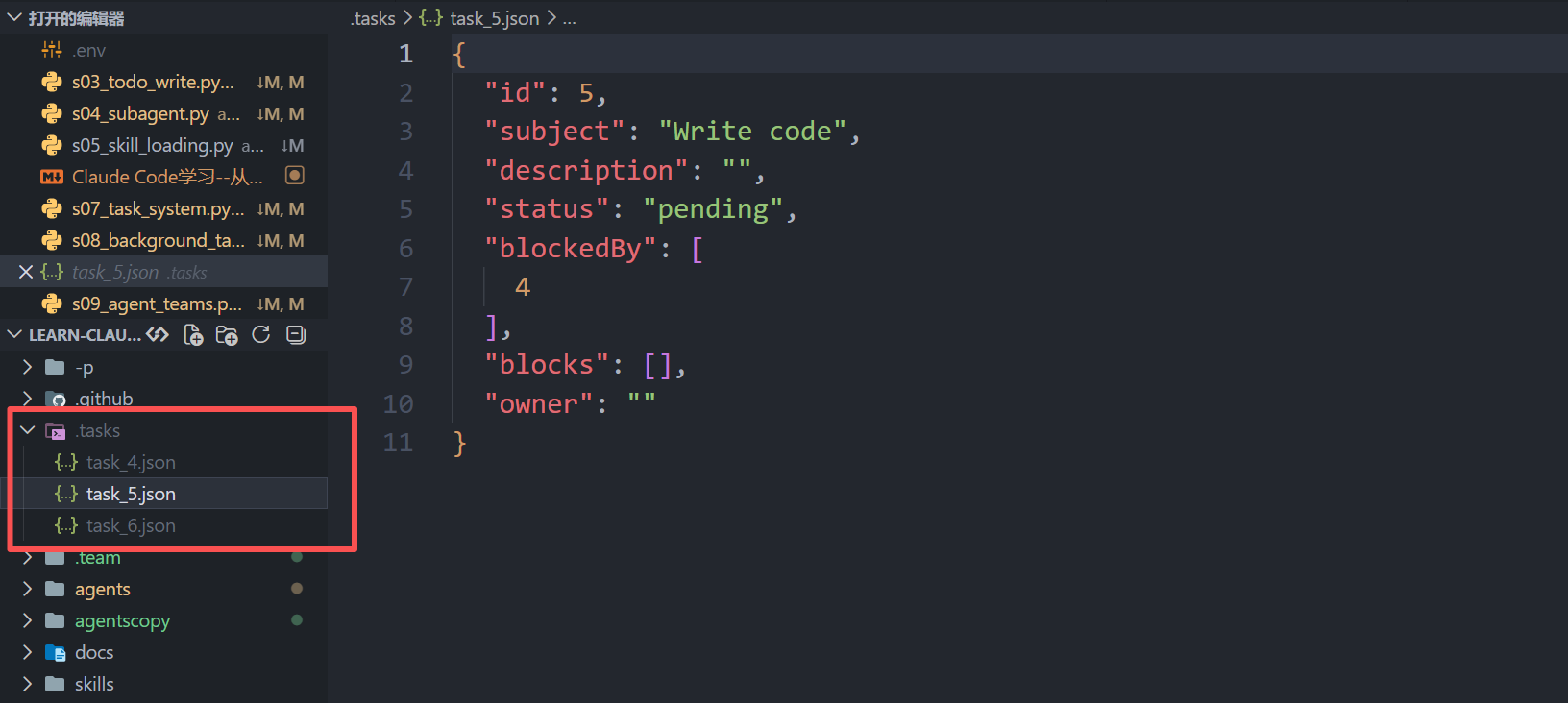
到了任务系统,在todo一章所说的一个机制在这里发挥了重要作用--持久化,每个任务是一个 JSON 文件, 有状态、前置依赖 (blockedBy) 和后置依赖 (blocks)。这有三个关键好处:(1) 任务在进程崩溃后仍然存在------如果 agent 在任务中途崩溃,重启后任务板仍在磁盘上;(2) 多个 agent 可以读写同一任务目录,无需共享内存即可实现多代理协调;(3) 人类可以查看和手动编辑任务文件来调试。文件系统就是共享数据库。
.tasks/
task_1.json {"id":1, "status":"completed"}
task_2.json {"id":2, "blockedBy":[1], "status":"pending"}
task_3.json {"id":3, "blockedBy":[1], "status":"pending"}
task_4.json {"id":4, "blockedBy":[2,3], "status":"pending"}
任务图 (DAG):
+----------+
+--> | task 2 | --+
| | pending | |
+----------+ +----------+ +--> +----------+
| task 1 | | task 4 |
| completed| --> +----------+ +--> | blocked |
+----------+ | task 3 | --+ +----------+
| pending |
+----------+
顺序: task 1 必须先完成, 才能开始 2 和 3
并行: task 2 和 3 可以同时执行
依赖: task 4 要等 2 和 3 都完成
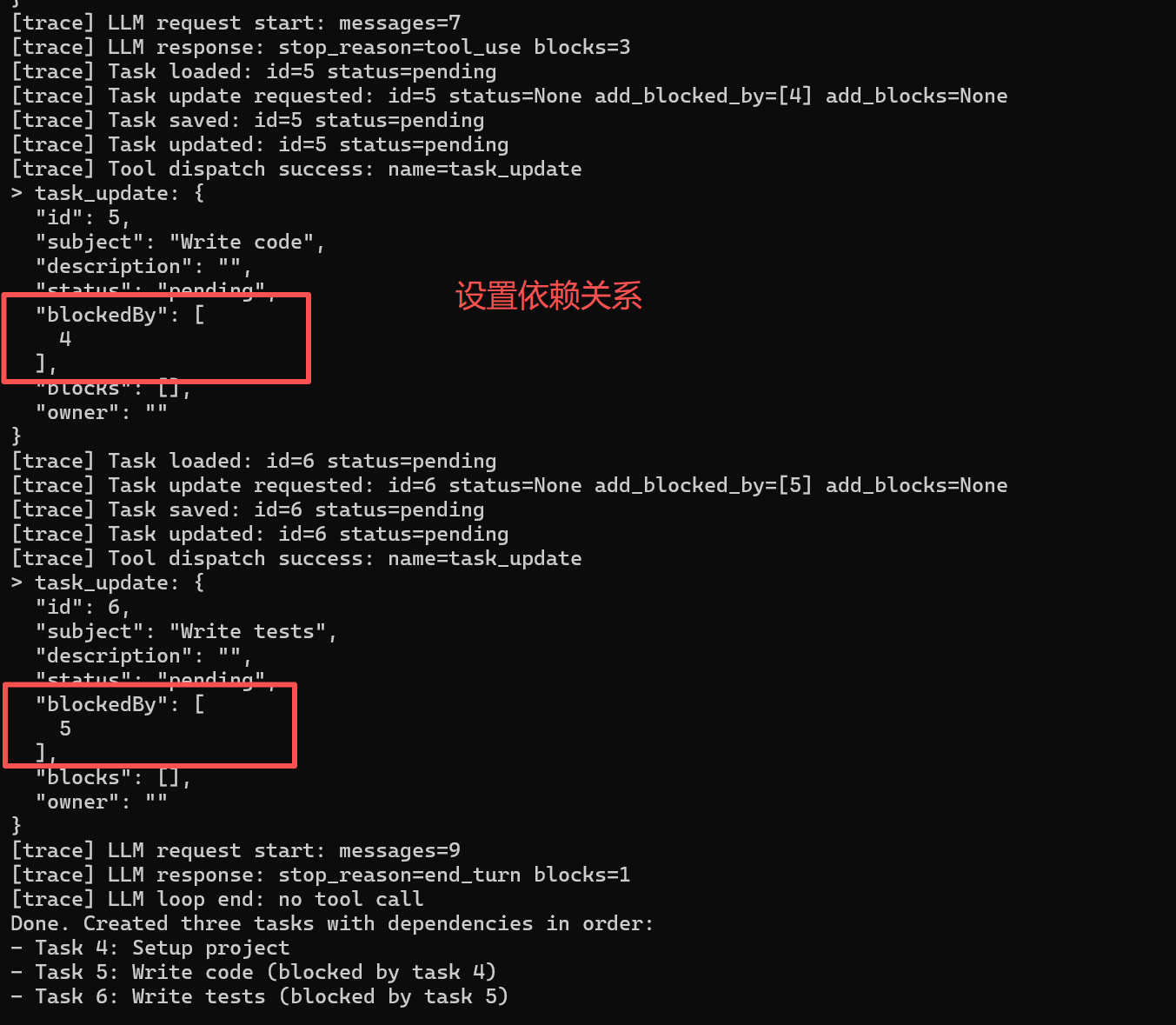
状态: pending -> in_progress -> completed这需要四个工具来实现:task_create/update/list/get:

TaskManager 基本可以理解为"任务文件仓库 + DAG 依赖维护器",每个函数都在做一件很具体的事:
init(tasks_dir)
初始化任务目录并计算 next_id。它不会把所有任务读进内存,而是通过 max_id 扫描现有 task*.json 推断下一个 ID,所以即使进程重启,也不会和历史 ID 冲突。
_max_id()
遍历 .tasks 下所有任务文件,提取文件名里的数字部分,返回最大值。空目录时返回 0。这个函数保证了 create 的 ID 分配是"单调递增"的。
_load(task_id)
读取单个任务文件并反序列化为 dict。不存在就抛错,这样上层 update/get 可以明确区分"任务不存在"和"其他错误"。
_save(task)
把任务 dict 按 task_{id}.json 落盘(带缩进,方便人工查看和调试)。这是整个任务系统持久化的核心写入口。
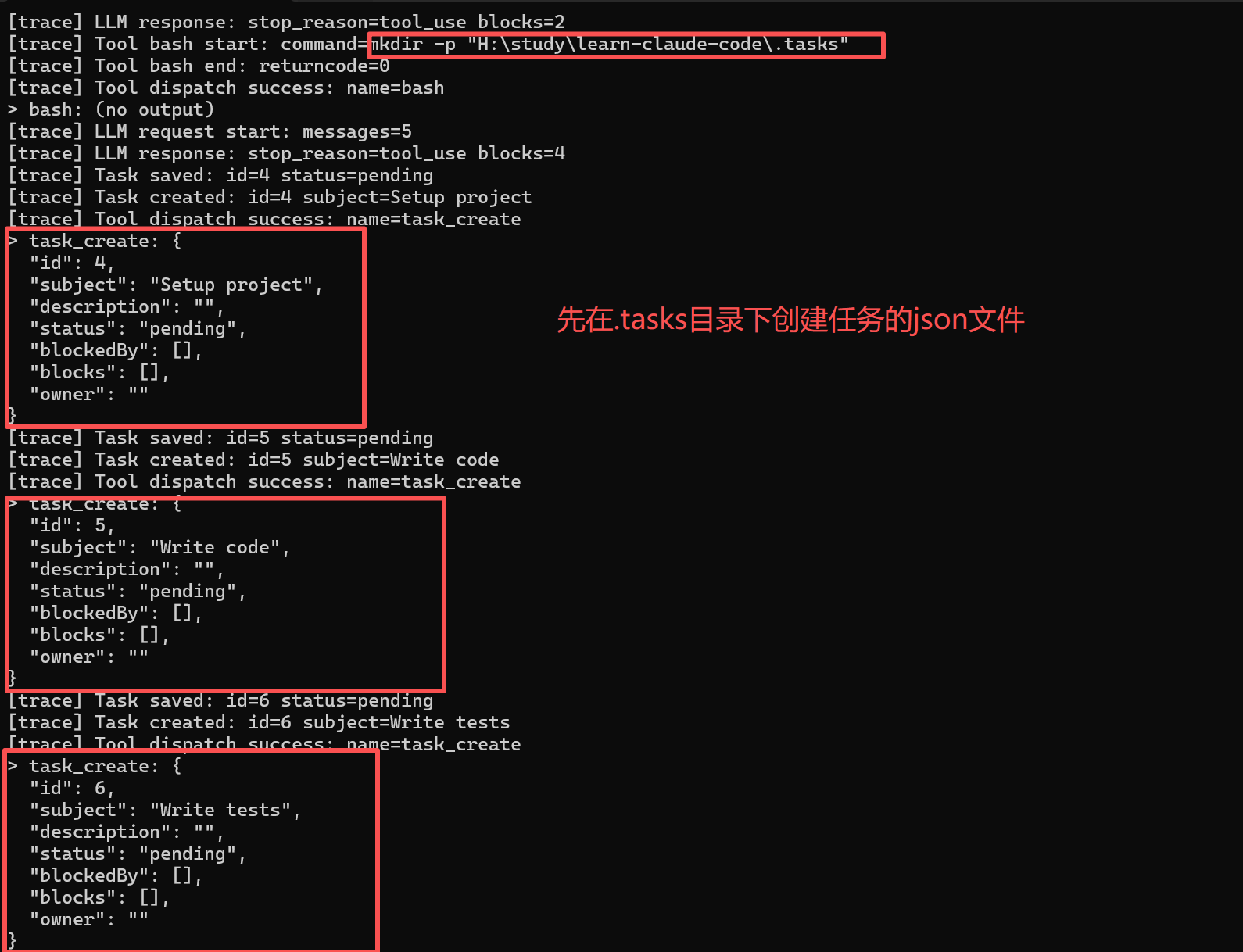
create(subject, description)
创建一个标准任务对象:id/subject/description/status/blockedBy/blocks/owner。默认 status 是 pending,依赖为空。保存后 next_id 自增,并返回任务 JSON。
get(task_id)
读取并返回单个任务详情,主要用于让模型拿到完整字段而不是摘要。
update(task_id, status, add_blocked_by, add_blocks)
这是最关键的函数,承担"状态变化 + 依赖维护"。
- 如果传了 status,先校验枚举(pending/in_progress/completed)。
- 当状态被更新为 completed 时,触发 _clear_dependency,把这个已完成任务从其他任务的 blockedBy 中批量移除。
- add_blocked_by 会把新的前置依赖并入当前任务(去重)。
- add_blocks 会把"后置任务"并入当前任务,同时反向写回被阻塞任务的 blockedBy(双向一致性维护)。
_clear_dependency(completed_id)
扫描全部任务文件,只要发现某任务 blockedBy 里含有 completed_id,就删掉它并保存。这样任务完成后,依赖链会自动松绑,后续任务可转为可执行状态。
list_all()
读取所有任务并渲染为人类可读摘要,状态映射成 / \> / x,如果任务有 blockedBy 就在行尾标出来。这个输出主要给人类和模型快速总览任务板。
事不宜迟,来跑一跑代码:
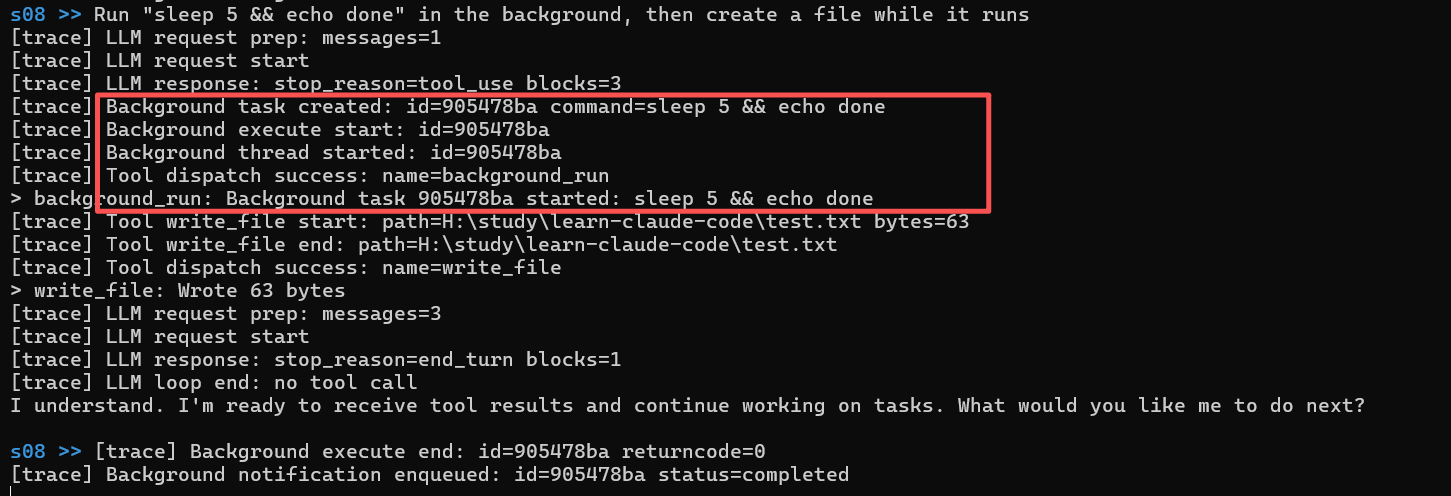
后台任务
理解后台任务最合适的方法是把代码拉下来打开项目的教程界面,有一个后台任务的动画非常直观的展示了其是怎么运作的。
它和子agent比较像,父agent分配任务给其他线程的agent,子agent一般情况下(至少我在这个项目上看到的)是同步的,后台任务是异步的,后台任务可以是子agent监听也可以是独立的处理程序,每次处理完后通过tool_result注入主agent,其实这与异步调用真感觉没什么太大区别。
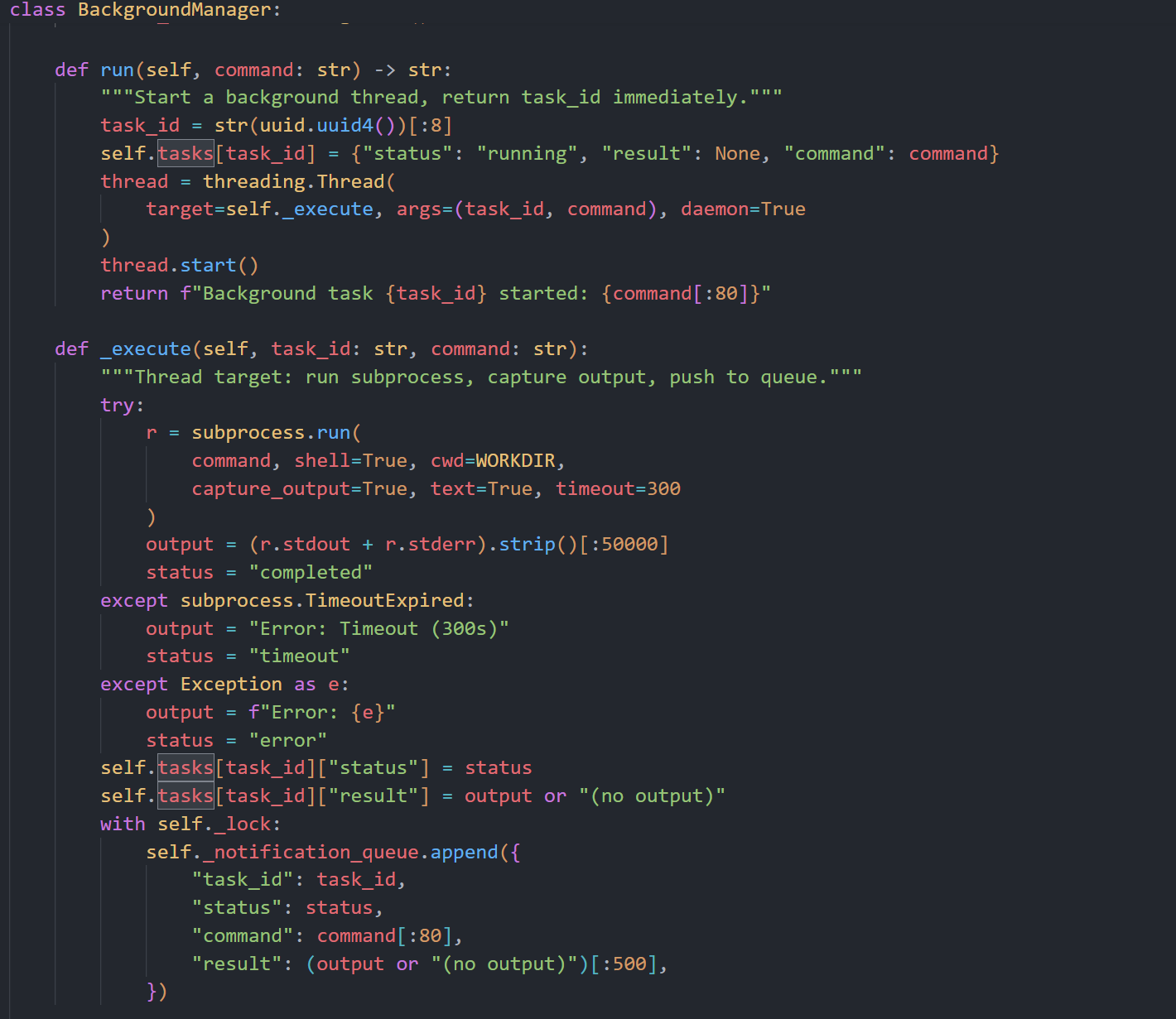
BackgroundManager 的关键就在 run 和 _execute 这对"前台发射 + 后台执行"组合:
run(command)
它做的是"立刻返回,不阻塞主循环"。流程是:
- 生成短 task_id(uuid 截断)。
- 在 tasks 字典里登记一条 running 任务(记录 command、result=None)。
- 启动一个 daemon 线程,目标函数是 _execute(task_id, command)。
- 直接把"任务已启动"的文本回给调用方。
所以 run 的语义不是执行命令,而是把命令排进一个独立线程并立刻交还控制权。
_execute(task_id, command)
它是真正跑命令的后台线程入口:
- 用 subprocess.run 执行命令,超时上限 300s。
- 根据结果把任务状态写成 completed / timeout / error。
- 把完整结果写回 taskstask_id"result"。
- 在锁保护下往 _notification_queue 追加一条简短通知(task_id、status、命令摘要、截断结果)。
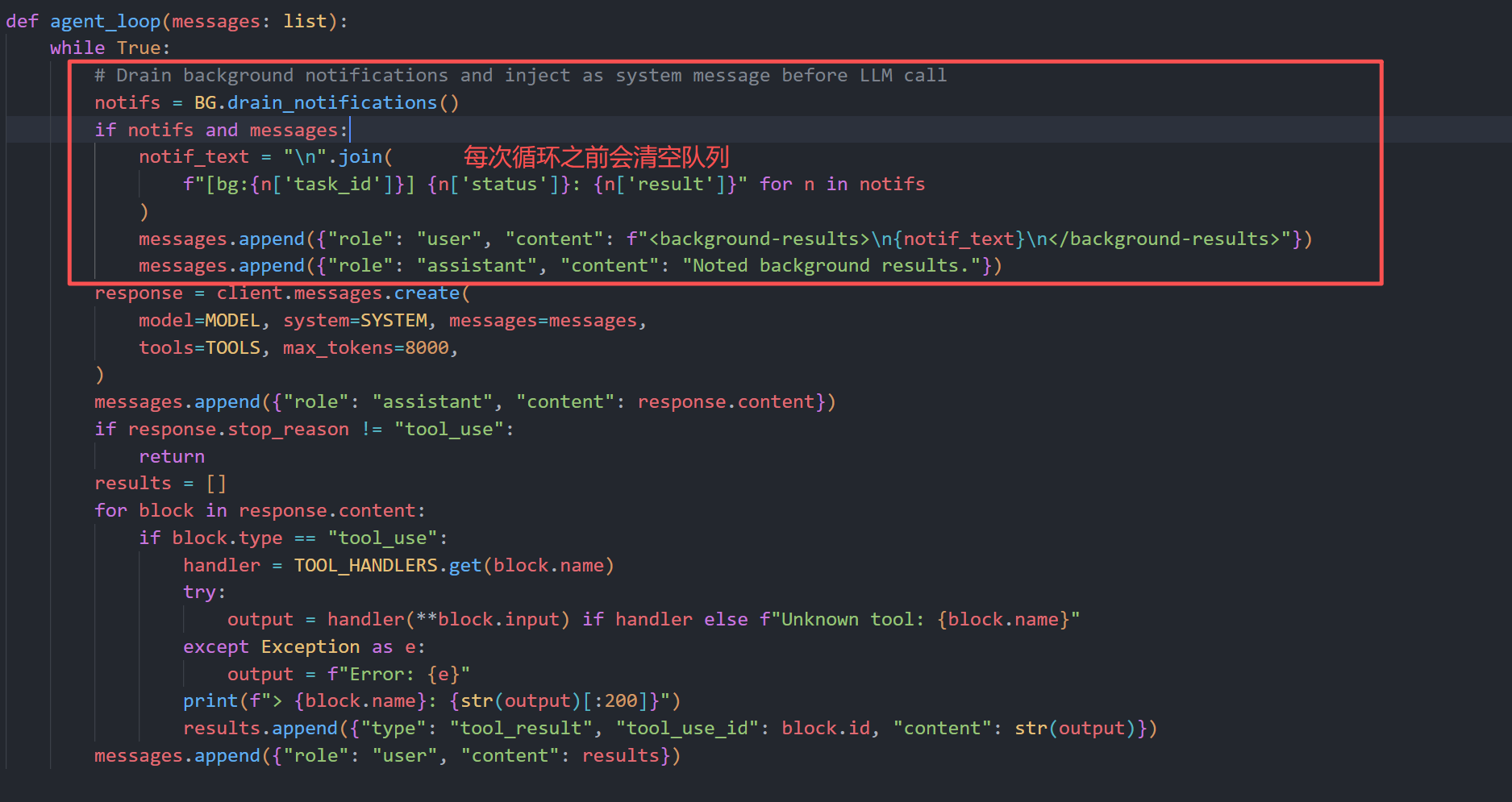
主 agent 不会主动 join 这些线程,而是在每轮 LLM 调用前 drain_notifications,把队列结果注入上下文。这就是"异步执行 + 同步回收结果"的核心机制。
agent团队
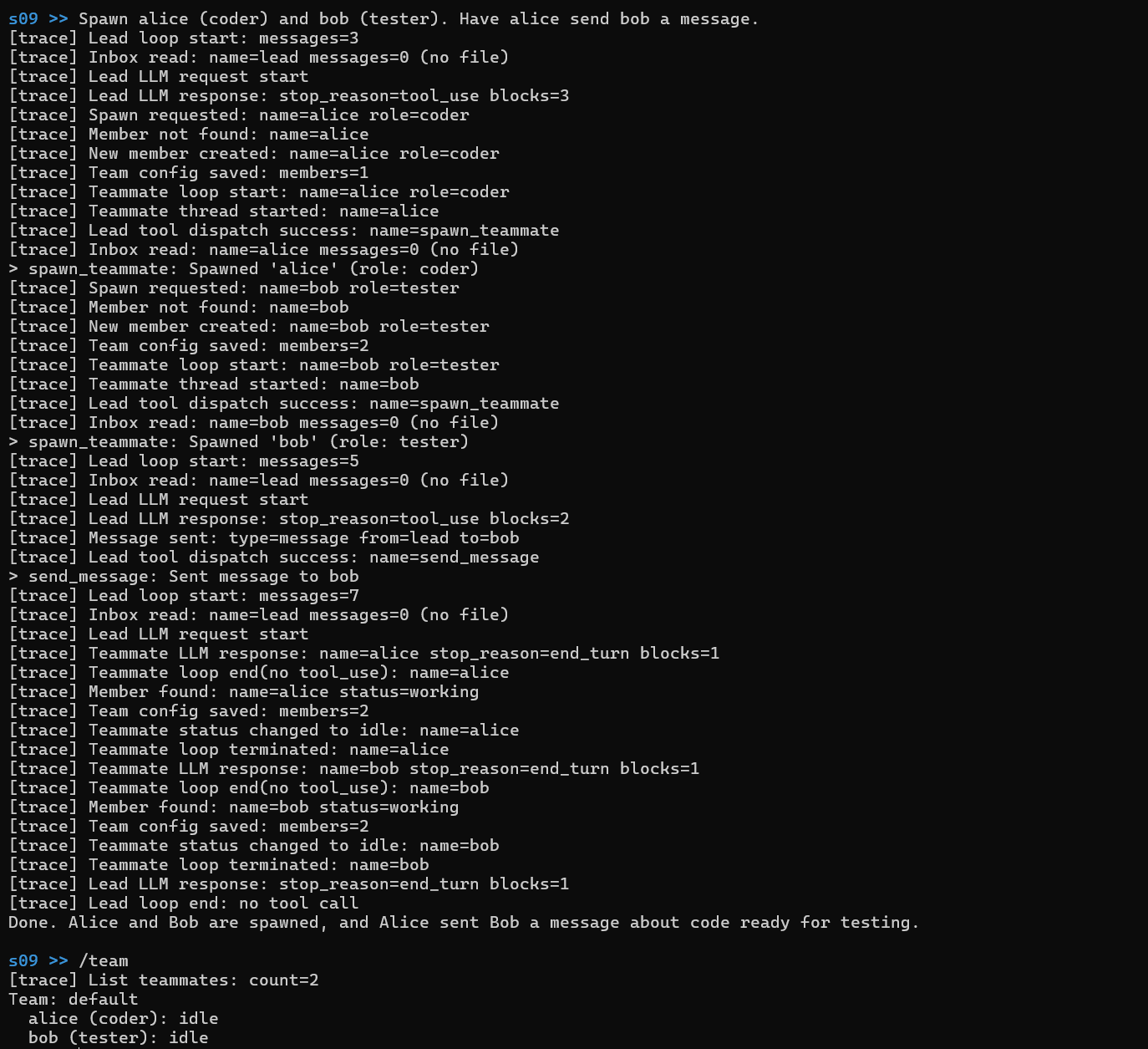
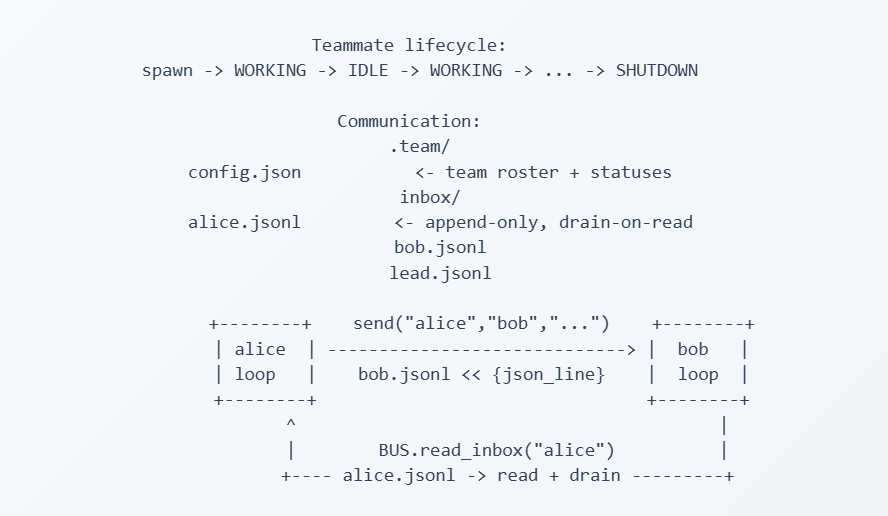
真正的团队协作需要三样东西: (1) 能跨多轮对话存活的持久智能体, (2) 身份和生命周期管理, (3) 智能体之间的通信通道。
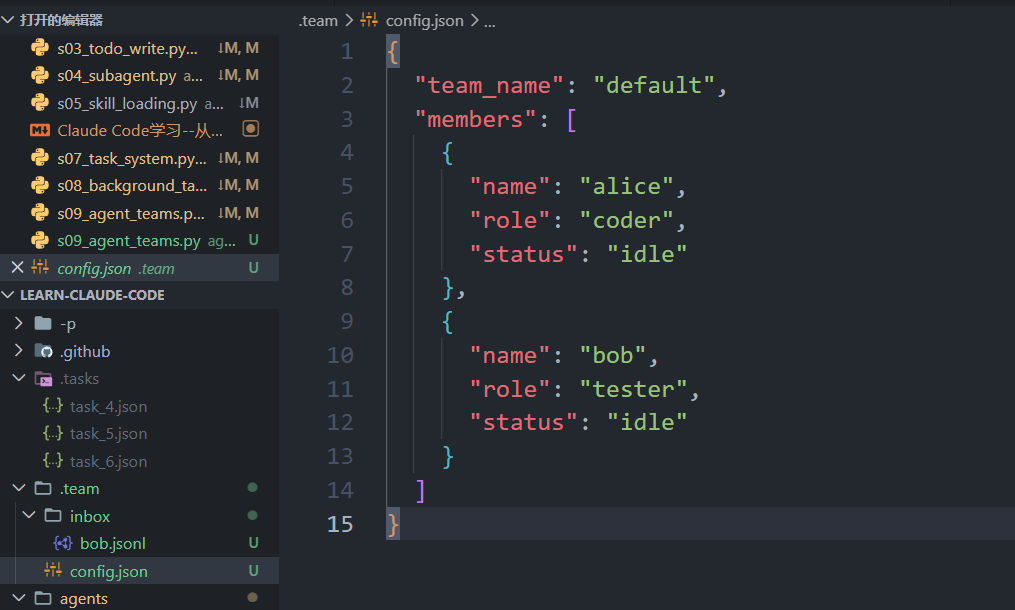
团队结构(成员名称、角色、agent ID)存储在 JSON 配置文件中,而非任何 agent 的内存中。任何 agent 都可以通过读取配置文件发现队友------无需发现服务或共享内存。如果 agent 崩溃并重启,它读取配置即可知道团队中还有谁。这与 s07 的理念一致:文件系统就是协调层。配置文件人类可读,便于手动添加或移除团队成员、调试团队配置问题。这有点像运行在单机的分布式系统,又有点像共享磁盘文件的多进程。
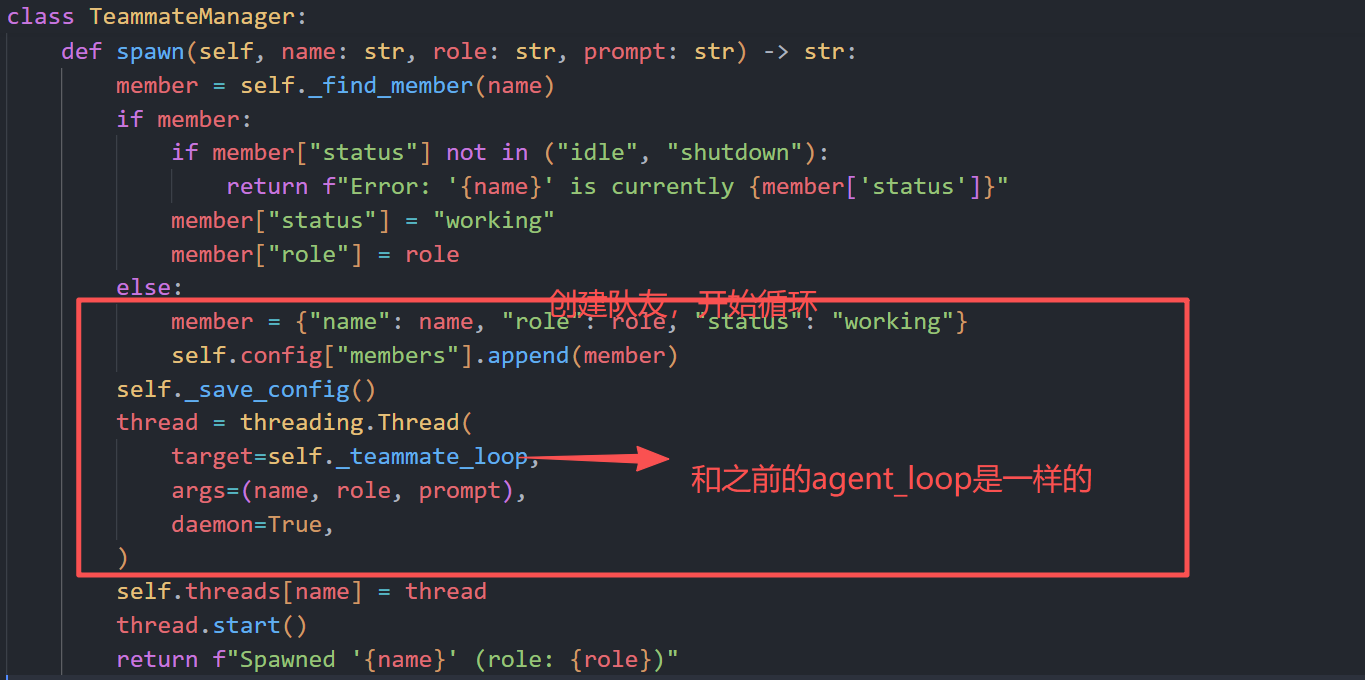
实现团队所需的几个工具:

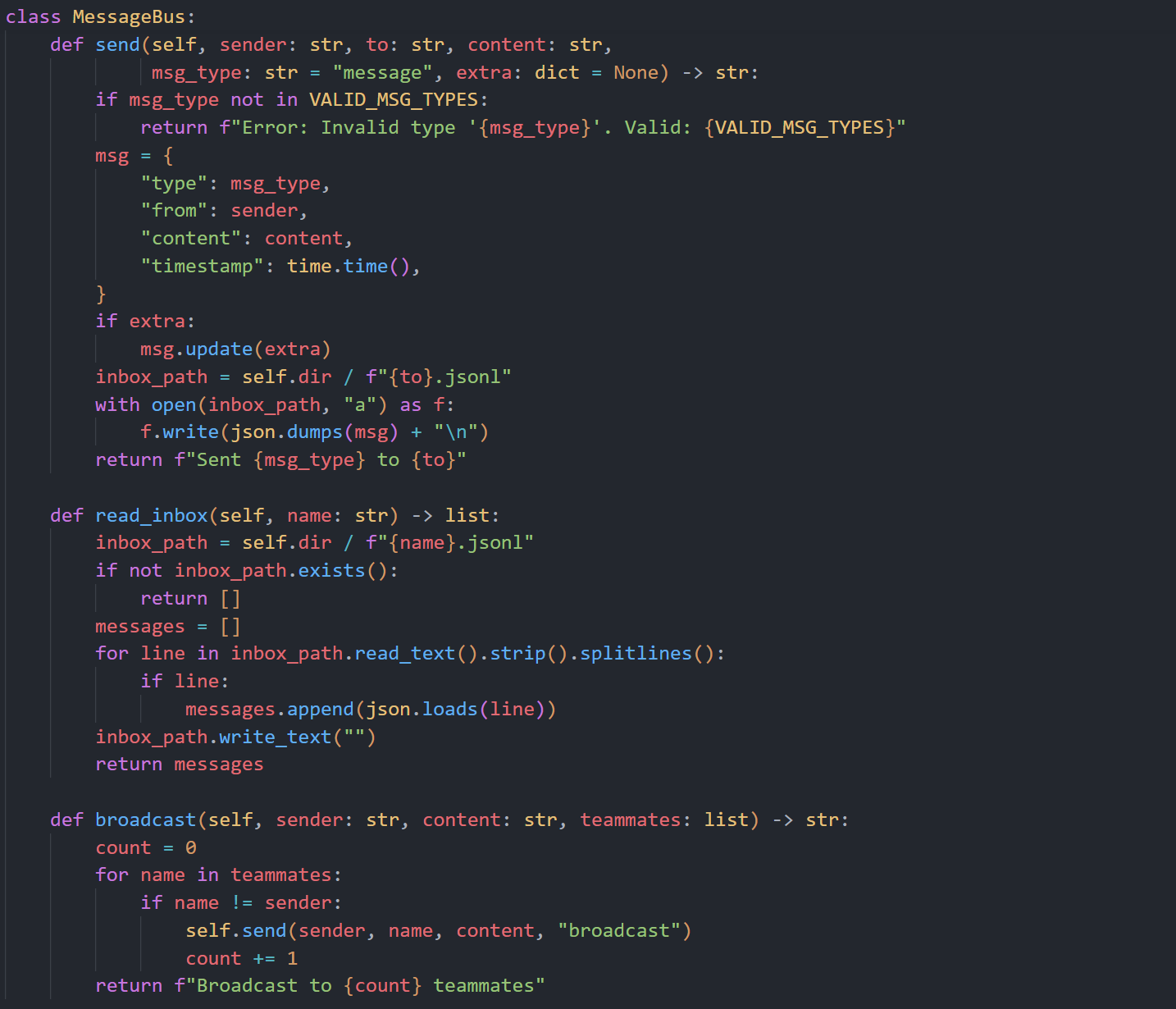
MessageBus 这三个函数构成了团队协作里的最小消息协议:
send(sender, to, content, msg_type="message", extra=None)
send 是"单播写入"。它先校验 msg_type 是否在允许集合里,然后组装消息体(type/from/content/timestamp,可选 extra),最后追加写入 .team/inbox/{to}.jsonl。这里是 append-only 语义,不会覆盖历史行,所以并发写入模型下也容易理解。
read_inbox(name)
read_inbox 是"读取并清空(drain)"。它把 {name}.jsonl 按行解析成消息数组返回,然后立刻把文件置空。这样 inbox 更像队列而不是日志:已消费消息不会被重复处理,适合 agent loop 每轮轮询后注入上下文。
broadcast(sender, content, teammates)
broadcast 是"遍历式群发"。它对 teammates 列表逐个调用 send,并跳过 sender 自己,消息类型固定为 broadcast,最后返回发送计数。实现很朴素,但足够把 lead 的指令一次性扩散给全队。