Claude Code学习--从搭建Nano Claude Code学习CC机制的底层原理
最近我学习了开源项目https://github.com/shareAI-lab/learn-claude-code,里面用一组从简到繁的最小示例,把 Claude Code 的核心机制拆成了 12 个章节:从最基础的 agent loop、工具调用,到 todo 计划、子 agent、skill 加载、上下文压缩,再到多 agent 团队协作。它不是那种"只讲概念"的教程,而是每一章都能直接运行、直接改、直接打日志观察行为。所以我打算按照这里面的目录来记录我是怎么通过调试,阅读代码和项目文章来深入学习的。
Agent 循环
最原始的agent:一个循环+一个bash工具
系统提示词和工具的定义:
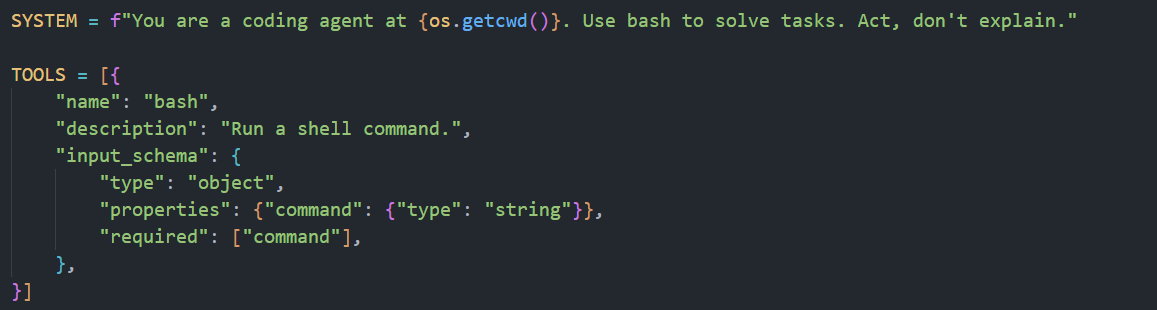
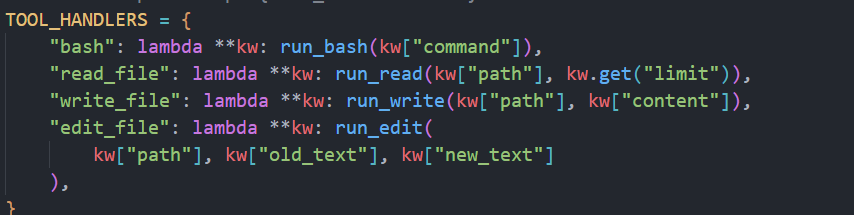
agent循环:会判断模型返回的内容有没有tool_use,如果有的话继续循环,没有退出
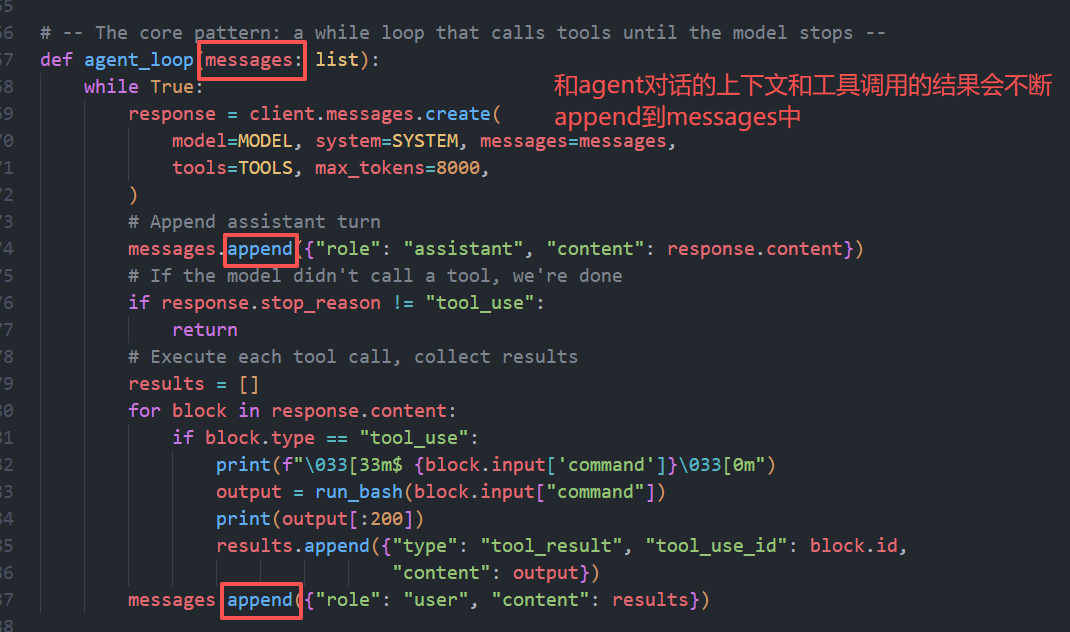
bash调用:
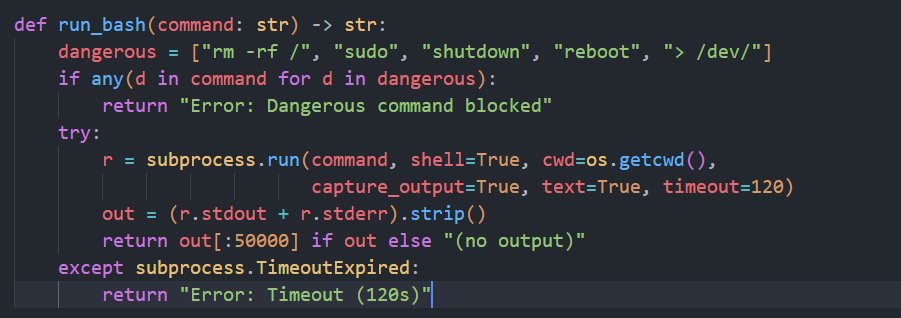
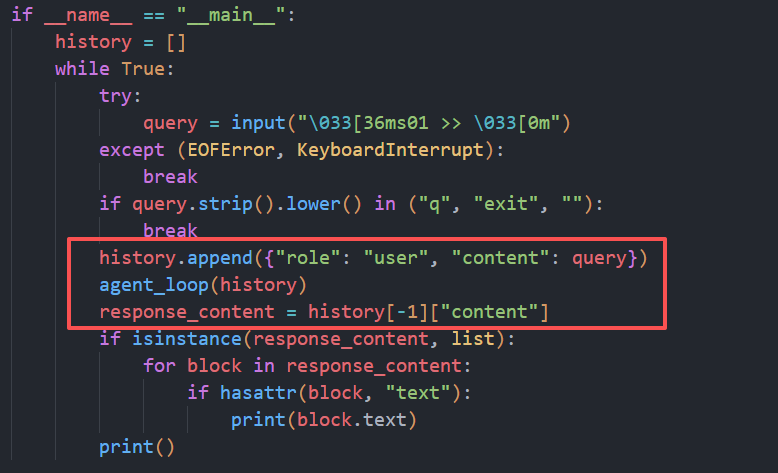
main函数:传入用户的输入
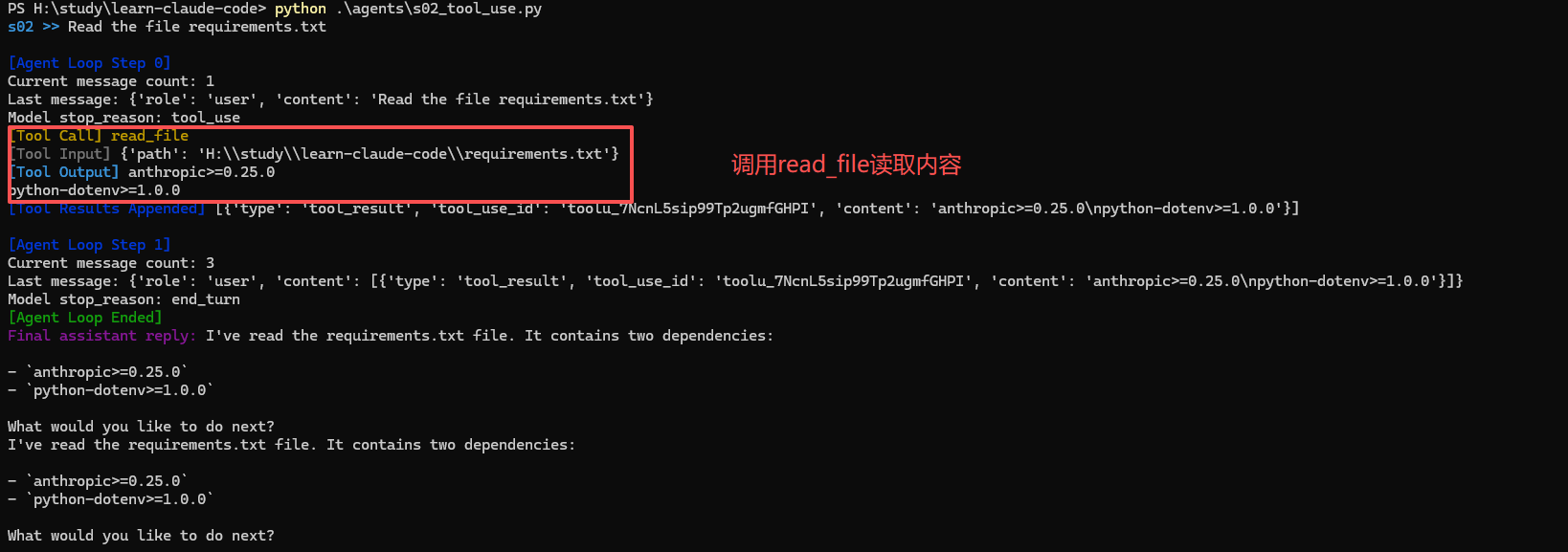
没错,一个基本的智能体就这么简单,我们可以加打印日志看看它具体是怎么运行的。
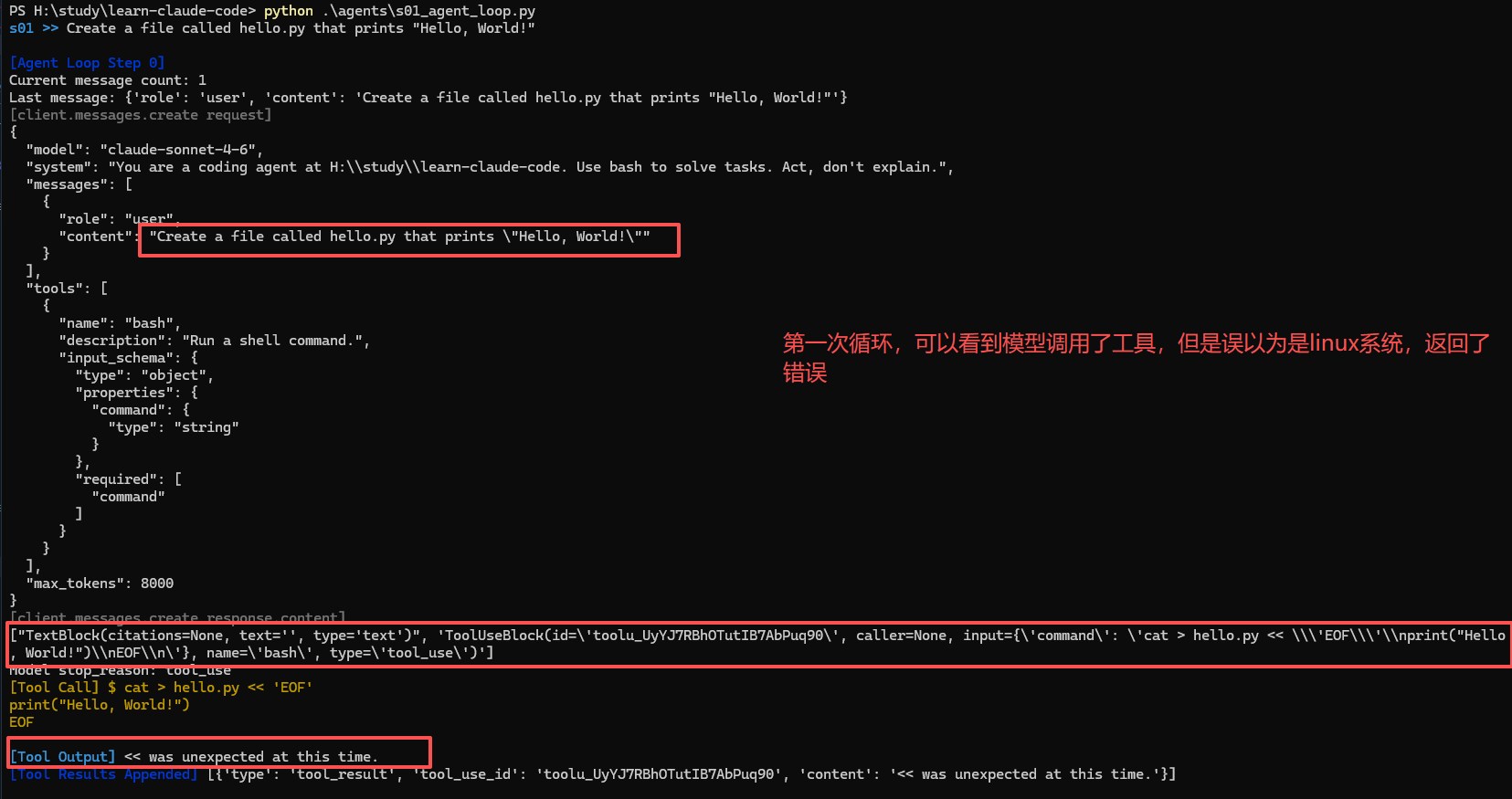
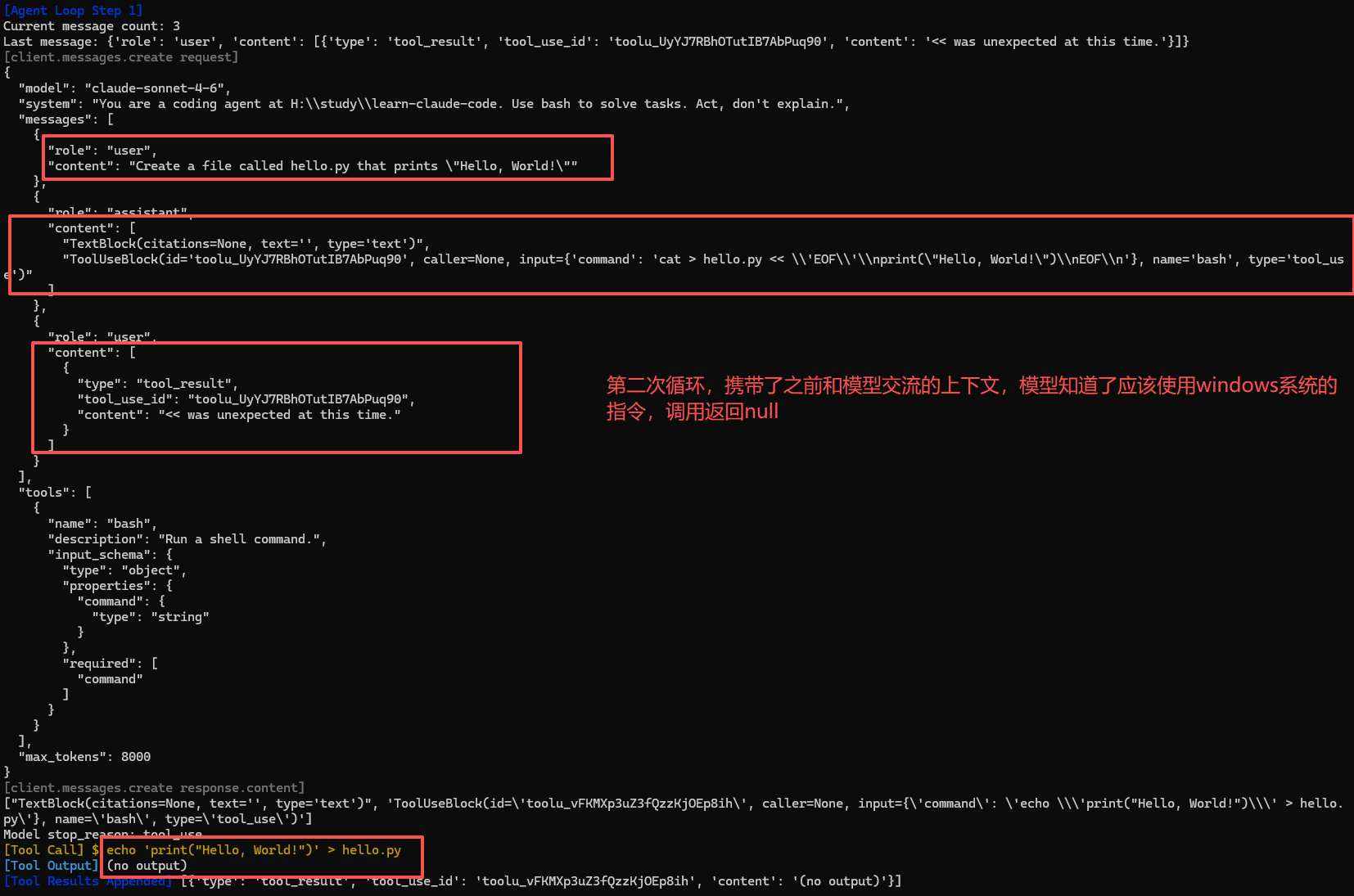
第二次循环,可以看到有类型为tool_result的content,后面在压缩一章中还会出现
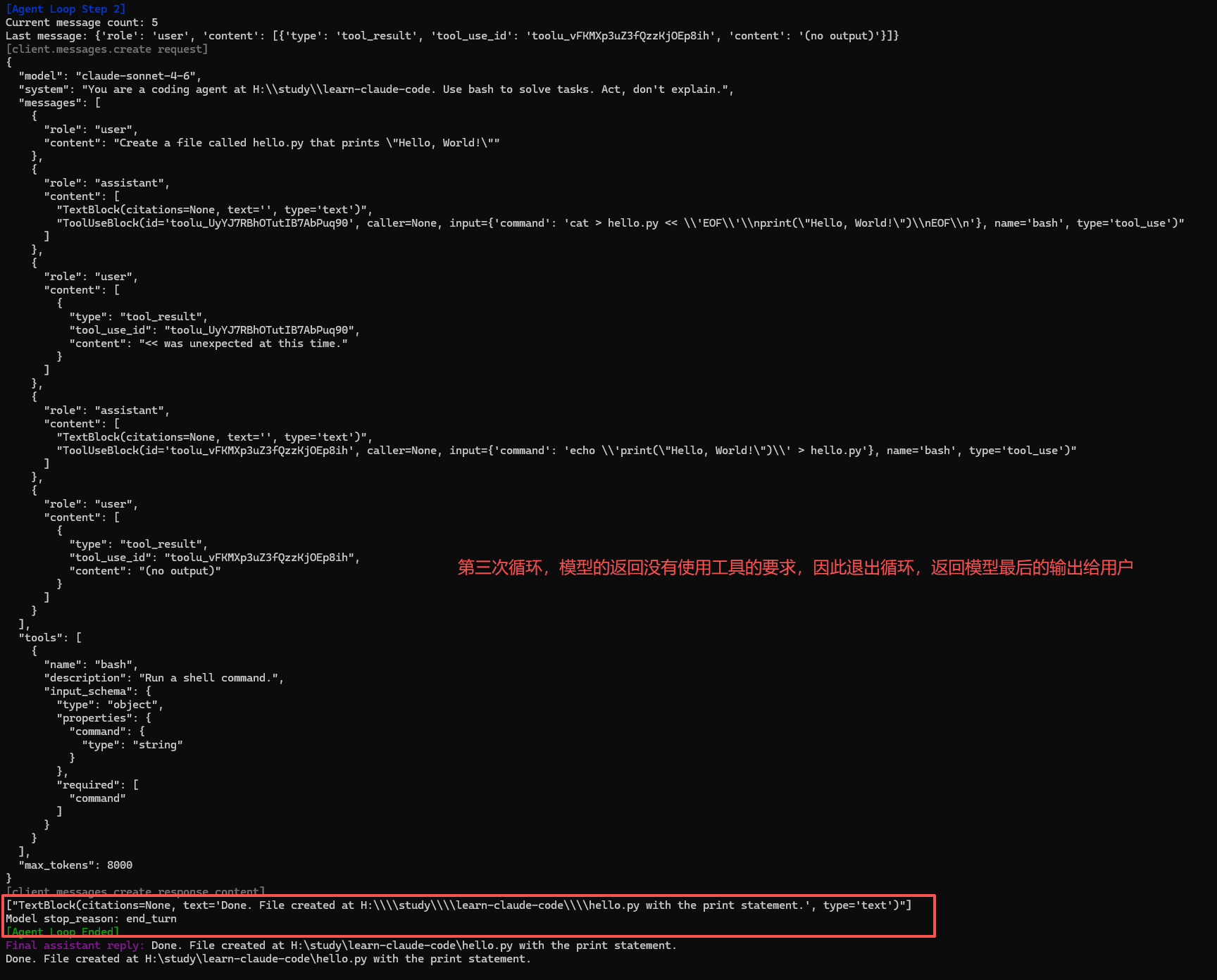
工具
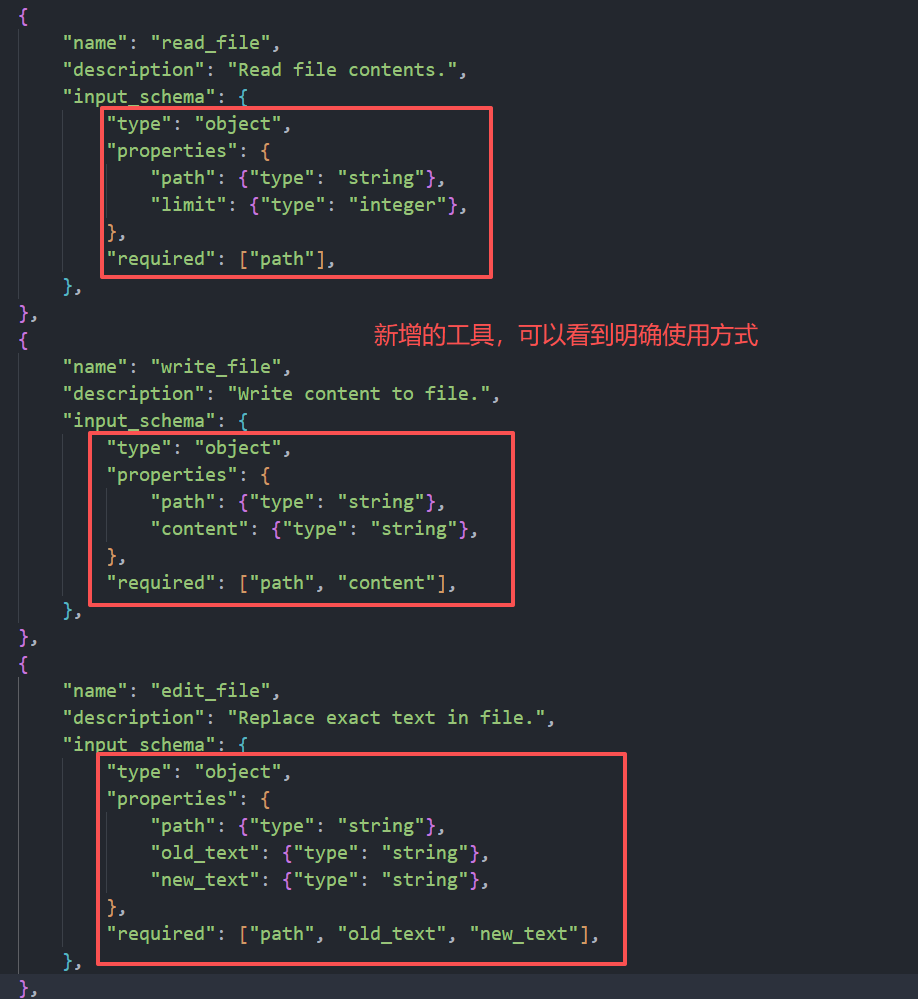
第二章也很简单,只是增加了工具的数量,在发送内容的tools(如上图)中告诉模型有哪些工具可以调用,并且明确工具的调用格式。这个"格式"其实就是每个工具都带一个 input_schema(JSON Schema 子集):先声明 type=object,再给出 properties(参数名和类型),最后用 required 规定必填项。比如 bash 要求 {"command": "string"},read_file 要求 path 必填、limit 可选,edit_file 则强制 path/old_text/new_text 三个字段都要给。模型如果少传字段、字段类型不对,或者传了 schema 以外的数据,都会在执行前被 API 拦截。这消除了一整类错误:模型无法传递格式错误的输入,因为 API 会在执行前校验 schema。这也使模型的意图变得明确------当它用特定字符串调用 edit_file 时,不存在关于它想修改什么的解析歧义。具体的工具还可以用沙箱来约束安全性,用一个dispatch map注册这些工具,再加一个handler来分派映射: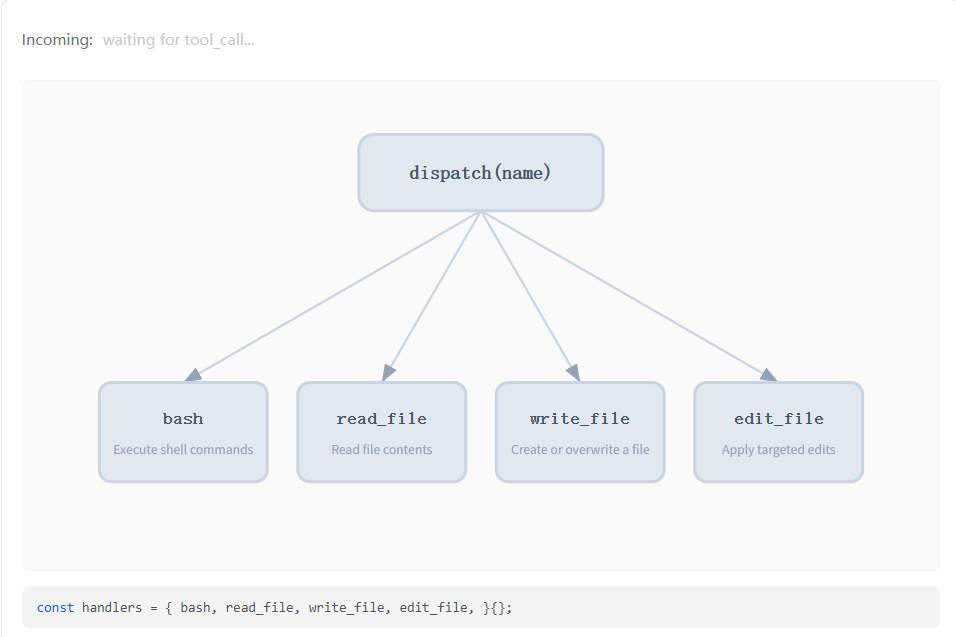
Todo清单
多步任务中, 模型会丢失进度 -- 重复做过的事、跳步、跑偏。对话越长越严重: 工具结果不断填满上下文, 系统提示的影响力逐渐被稀释。一个 10 步重构可能做完 1-3 步就开始即兴发挥, 因为 4-10 步已经被挤出注意力了。
解决方式就是多加一个工具,这个工具就是todo。
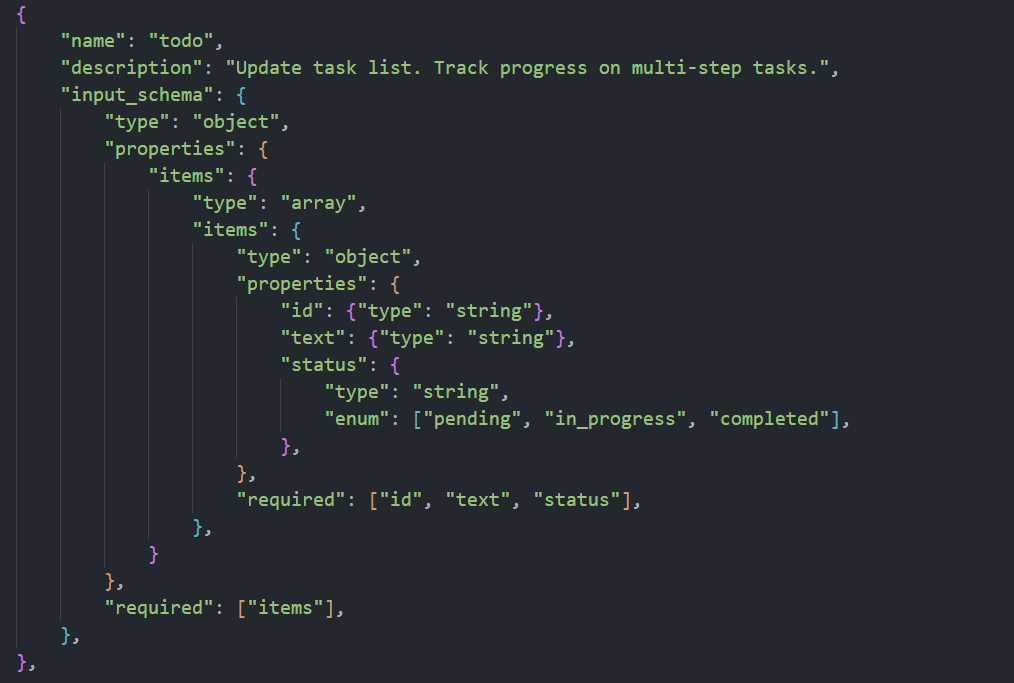
这里的 todo 工具 schema 很关键:它要求模型一次性提交 items 数组,而不是"只更新一条"。items 的每个元素必须是 object,且必须包含 id、text、status 三个字段;status 只能是 pending / in_progress / completed 三选一。也就是说,模型每次调用 todo 都是在"重写当前任务视图",而不是打补丁。这个约束让计划状态保持结构化、可校验,也方便后续做 reminder 注入和状态统计。
而agent_loop会在每次循环时检测有没有使用todo工具:
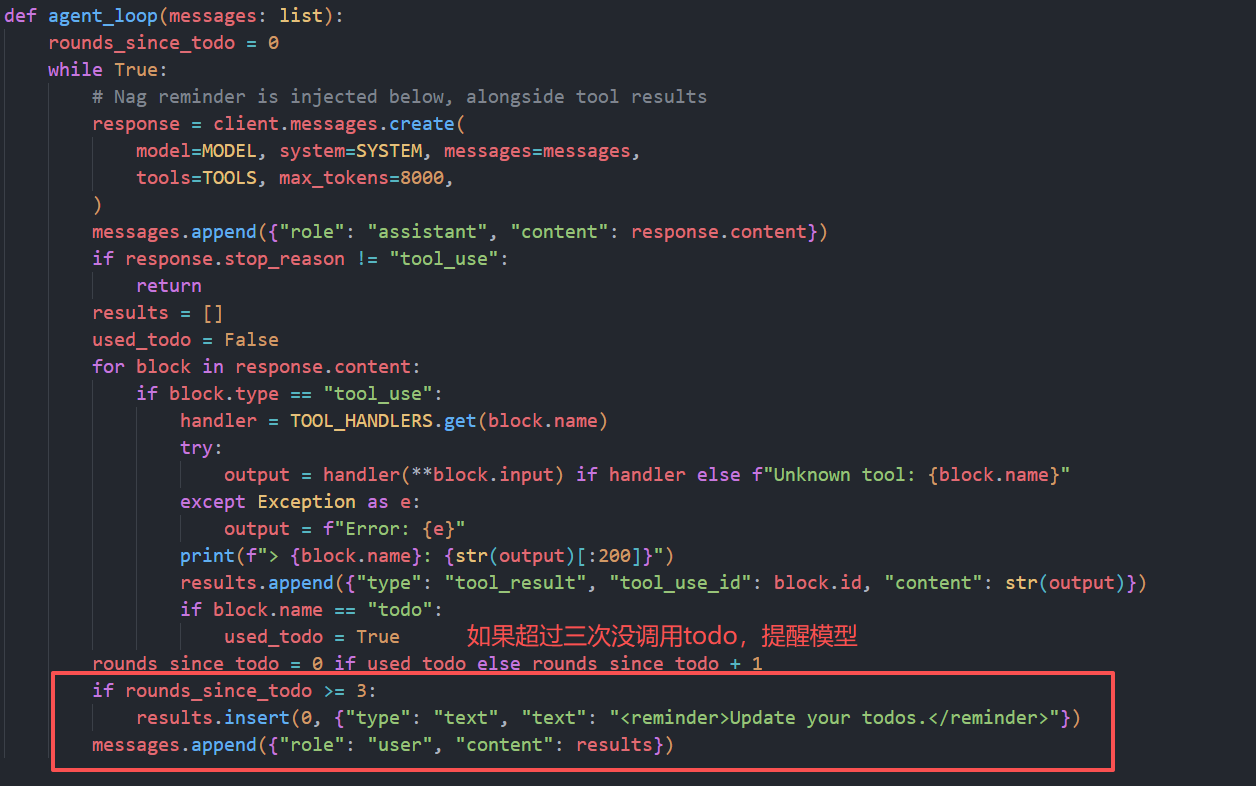
TodoManager 就是 todo 工具背后的状态机。它做了三层事:
- 校验:最多 20 条;text 不能为空;status 必须在枚举里;同一时刻最多 1 条 in_progress。
- 归一化:把 id/text/status 清洗成统一格式,覆盖写入 self.items。
- 可视化:render 时把状态映射成 / \> / x,并追加 (done/total) 统计。
在 agent_loop 里还有个很实用的"催更机制":如果连续若干轮(我这里改成了 1 轮)没有调用 todo,就自动往下一轮结果里插入 Update your todos.,强制模型回到计划驱动,而不是在长对话里自由漂移。
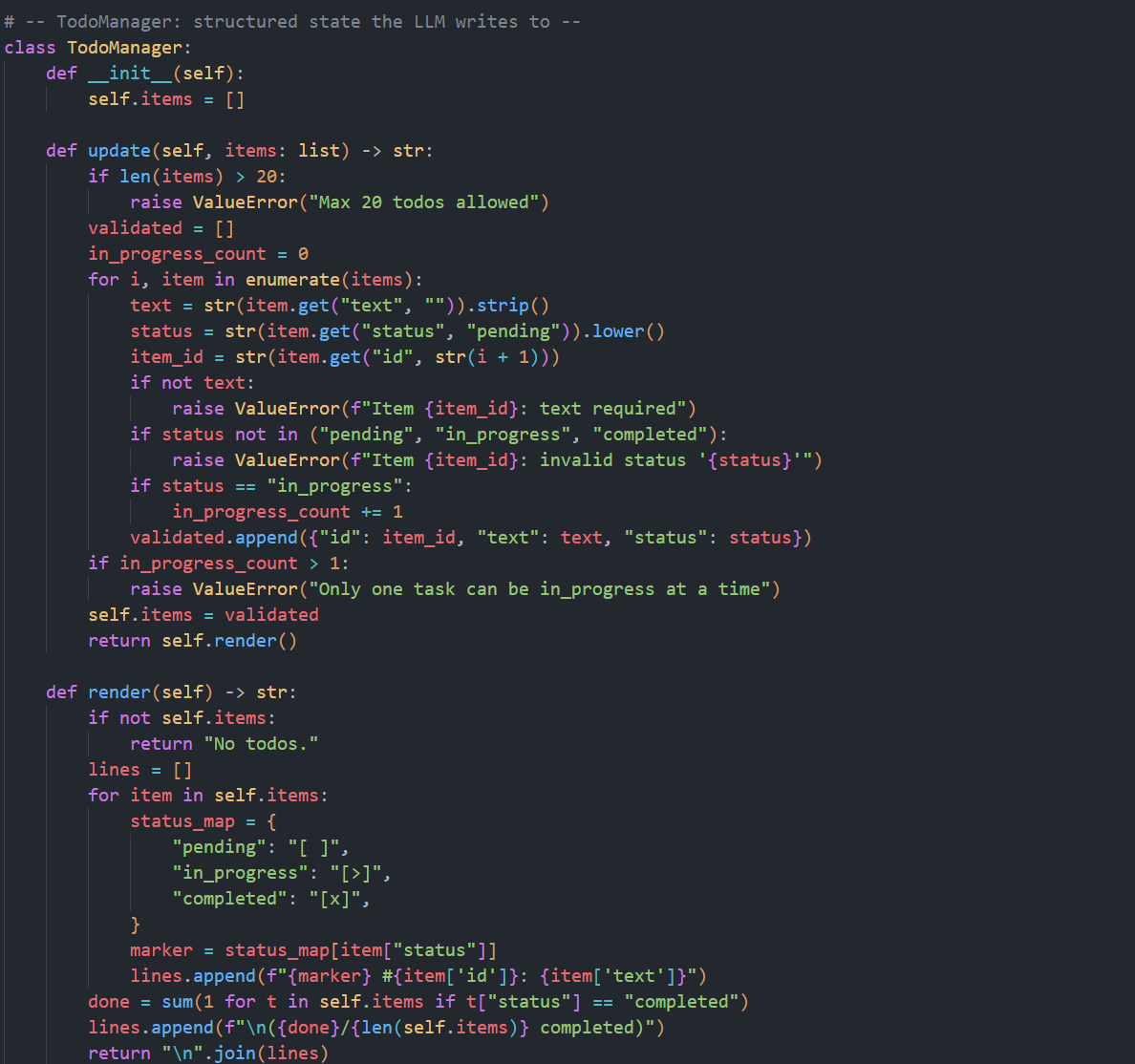
为了调试尽快输出,我把rounds_since_todo改成了>=1就触发。
当模型完成一个任务需要很多轮对话的时候,一个可持久化磁盘的文件而不是全部保存在内存就尤为重要。在使用时也是,Ralph插件就是利用清单功能,在让模型开始做之前用plan模式规划好prd文档和progress文档,每次等模型做完一个小模块后就更新progress清单并且清空上下文,这与todo大相径庭。todo清单有三个好处:(1) 用户可以在执行前看到 agent 打算做什么;(2) 开发者可以通过检查计划状态来调试 agent 行为;(3) agent 自身可以在后续轮次中引用计划,即使早期上下文已经滚出窗口。之后对于子agent的使用也可以借鉴这种方式,用一个持久化的文件来让主agent可以了解到子agent所做的更多内容,这种思想也是现在了agent团队中。
子 Agent
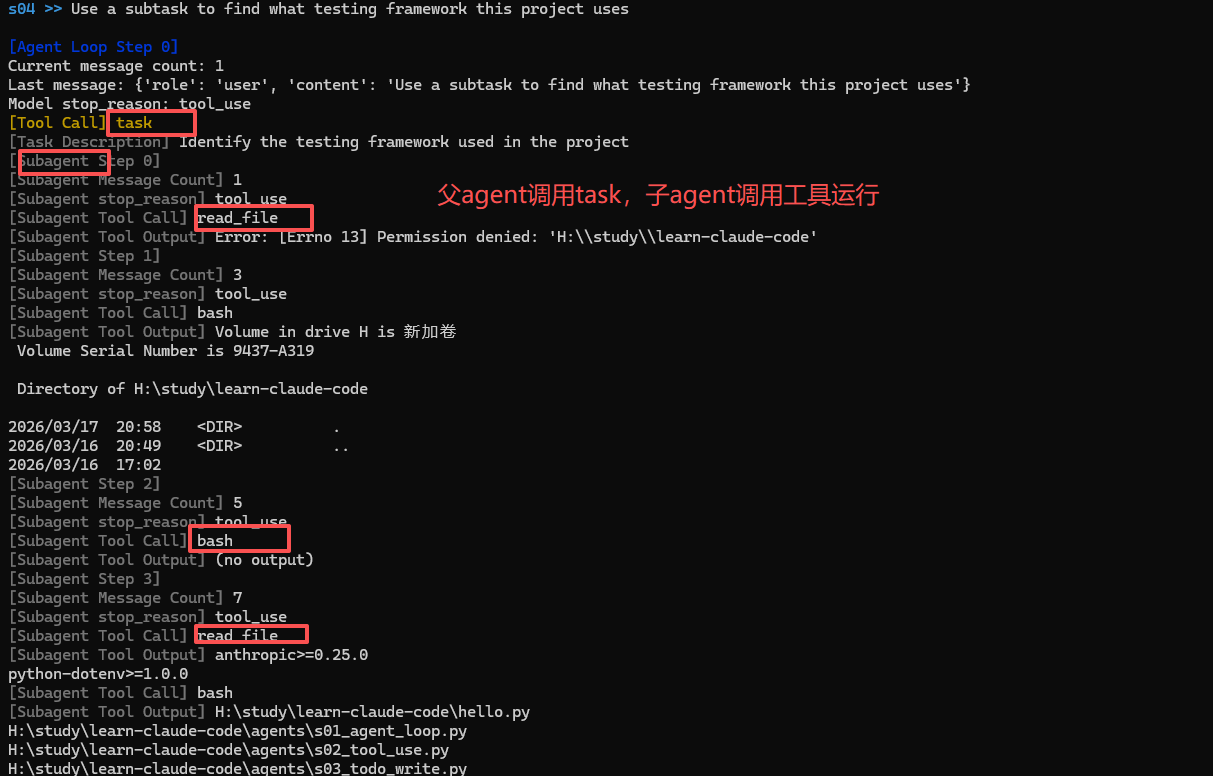
子agent就类似于函数调用,父agent给子agent一个指令,子agent完成后再把内容总结发给父agent。派生子agent同样用tools实现。

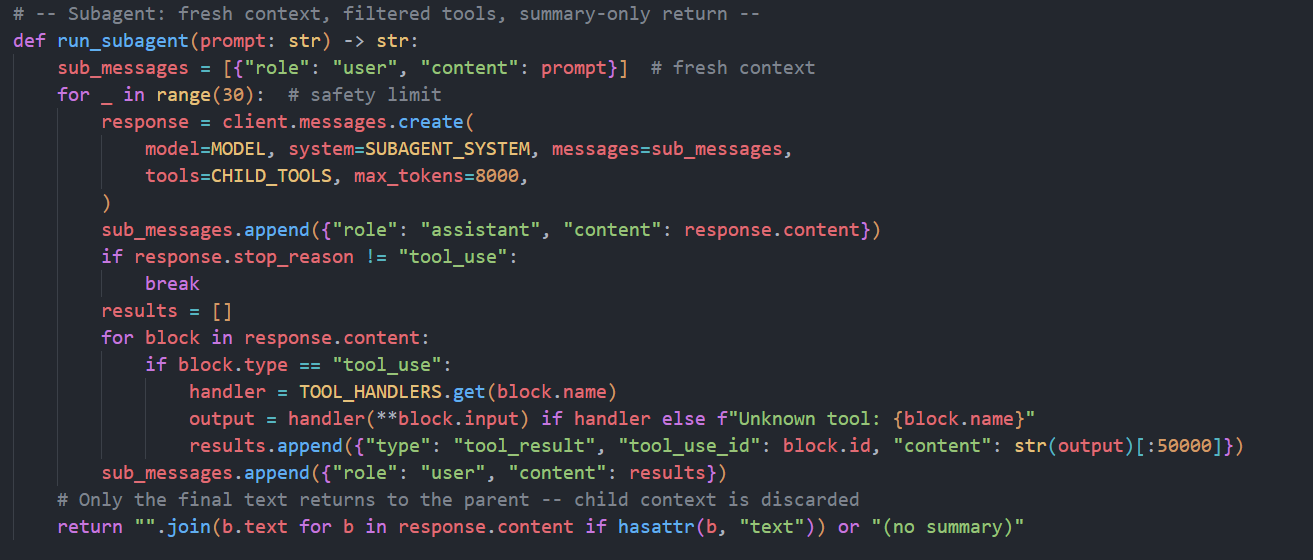
task 工具本质是一个"上下文隔离的委托调用器"。
先看 PARENT_TOOLS:它是在基础文件工具之上额外增加了 task。task 的输入有两个字段:prompt(必填,真正交给子 agent 的任务说明)和 description(可选,给父 agent/日志看的短描述)。
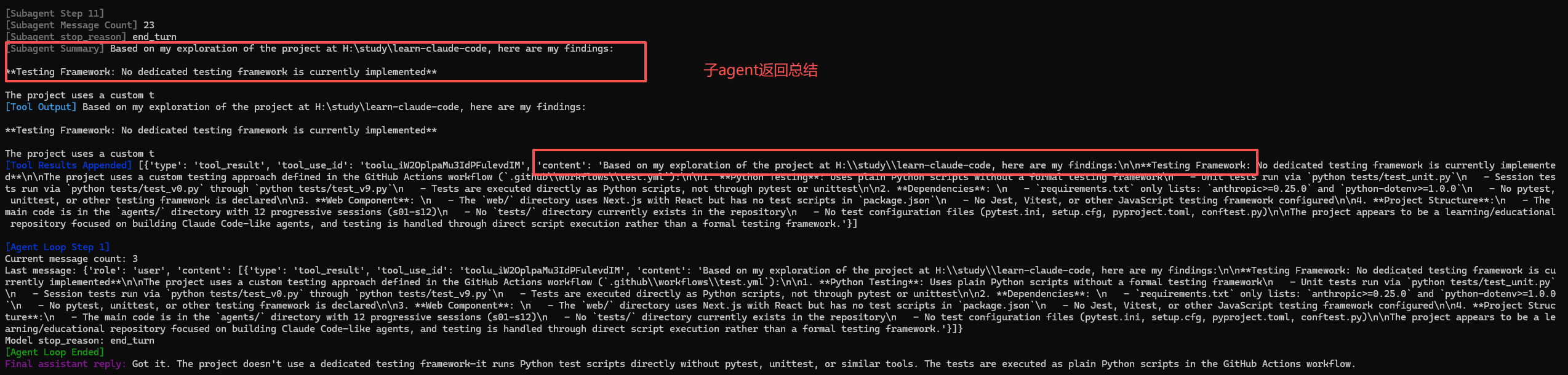
再看 run_subagent:父 agent 调用 task 后,不是在当前 messages 里继续,而是新建 sub_messages={"role": "user", "content": prompt},也就是从空上下文启动一个子循环。子 agent 只拿 CHILD_TOOLS(故意不包含 task,避免递归套娃),在自己的循环里执行工具、回填 tool_result,直到 stop_reason 不再是 tool_use。最后只把"最终文本总结"返回给父 agent。
这套机制的价值是:文件系统是共享的(子 agent 改的文件父 agent 看得到),但对话上下文不共享(父上下文不会被子过程细节污染),所以父 agent 能把复杂探索外包出去,同时保持主线程上下文干净。
Skills
这一章的核心是两层注入(two-layer injection),避免把所有知识都塞进 system prompt。
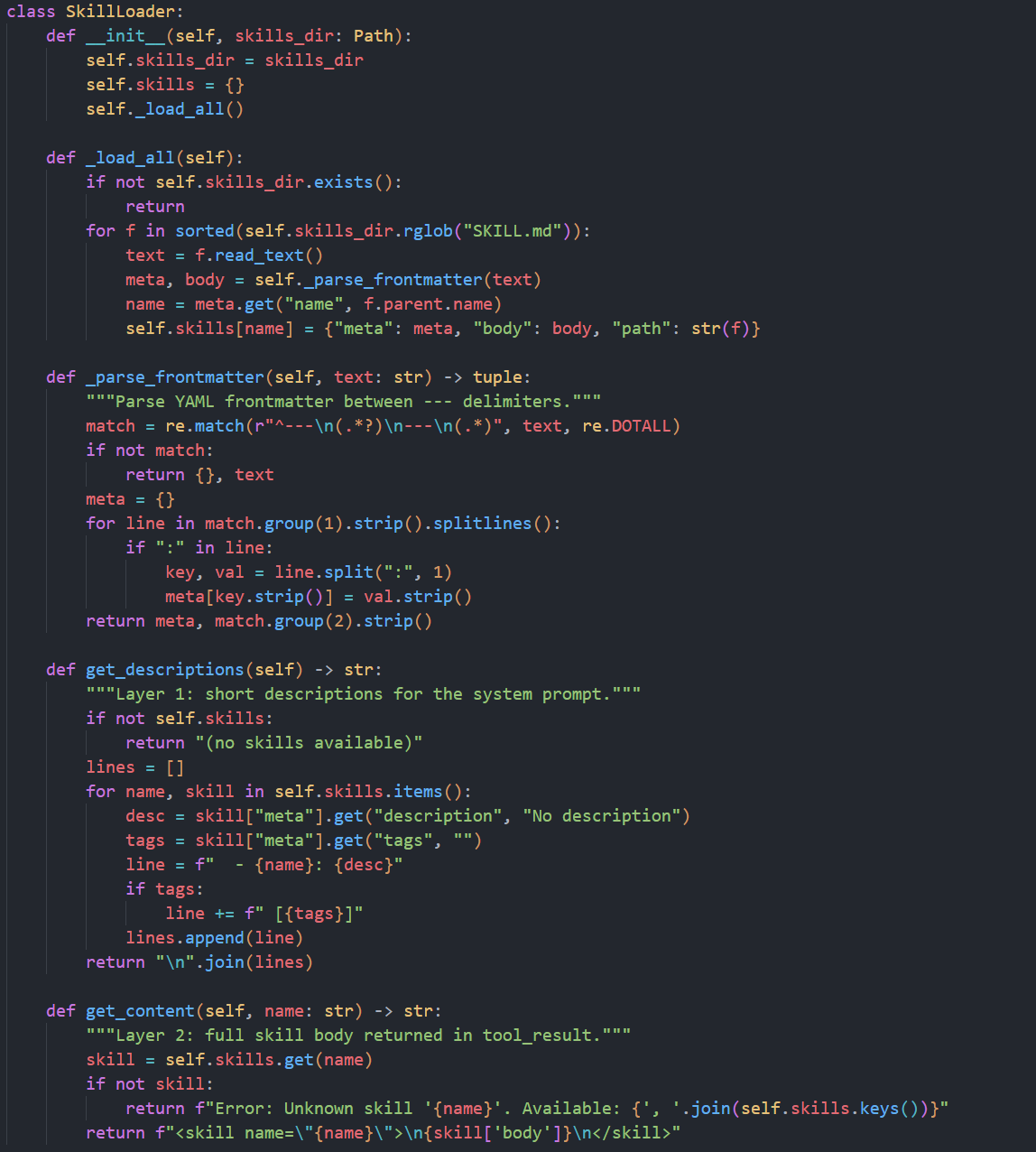
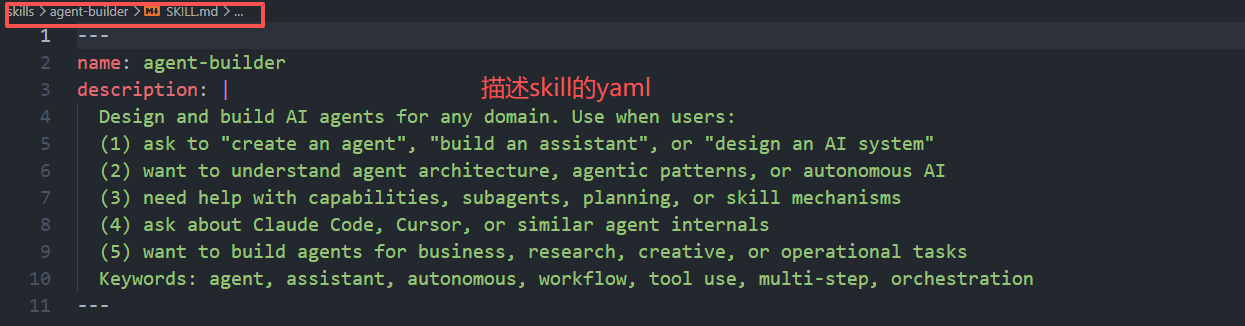
SkillLoader 会扫描 skills/SKILL.md,解析每个文件头部的 YAML frontmatter(name/description/tags),并把正文 body 分离出来。然后分两层给模型:
-
第一层(轻量元信息)
启动时把 skill 名称+描述注入到 SYSTEM 里,相当于告诉模型"有什么能力可用",成本低。
-
第二层(按需加载全文)
当模型调用 load_skill(name) 工具时,SkillLoader.get_content 会把对应 skill 正文包装成 ... 放到 tool_result 返回。模型拿到后再按这份详细步骤执行。
所以 agent 调用 skill 的过程其实是:先在 system 里"看目录",判断是否需要某个专长,再通过工具"按需读全文"。这样既保留可扩展性,也避免上下文被一次性塞爆。

来看一个skill的例子:
压缩
这里项目原文就已经解释清楚了,我直接把原文的话粘贴下来:
问题
上下文窗口是有限的。读一个 1000 行的文件就吃掉 ~4000 token; 读 30 个文件、跑 20 条命令, 轻松突破 100k token。不压缩, 智能体根本没法在大项目里干活。
解决方案
三层压缩, 激进程度递增:
Every turn:
+------------------+
| Tool call result |
+------------------+
|
v
[Layer 1: micro_compact] (silent, every turn)
Replace tool_result > 3 turns old
with "[Previous: used {tool_name}]"
|
v
[Check: tokens > 50000?]
| |
no yes
| |
v v
continue [Layer 2: auto_compact]
Save transcript to .transcripts/
LLM summarizes conversation.
Replace all messages with [summary].
|
v
[Layer 3: compact tool]
Model calls compact explicitly.
Same summarization as auto_compact.- 第一层 -- micro_compact: 每次 LLM 调用前, 将旧的 tool result 替换为占位符。
python
def micro_compact(messages: list) -> list:
tool_results = []
for i, msg in enumerate(messages):
if msg["role"] == "user" and isinstance(msg.get("content"), list):
for j, part in enumerate(msg["content"]):
if isinstance(part, dict) and part.get("type") == "tool_result":
tool_results.append((i, j, part))
if len(tool_results) <= KEEP_RECENT:
return messages
for _, _, part in tool_results[:-KEEP_RECENT]:
if len(part.get("content", "")) > 100:
part["content"] = f"[Previous: used {tool_name}]"
return messages- 第二层 -- auto_compact: token 超过阈值时, 保存完整对话到磁盘, 让 LLM 做摘要。
python
def auto_compact(messages: list) -> list:
# Save transcript for recovery
transcript_path = TRANSCRIPT_DIR / f"transcript_{int(time.time())}.jsonl"
with open(transcript_path, "w") as f:
for msg in messages:
f.write(json.dumps(msg, default=str) + "\n")
# LLM summarizes
response = client.messages.create(
model=MODEL,
messages=[{"role": "user", "content":
"Summarize this conversation for continuity..."
+ json.dumps(messages, default=str)[:80000]}],
max_tokens=2000,
)
return [
{"role": "user", "content": f"[Compressed]\n\n{response.content[0].text}"},
{"role": "assistant", "content": "Understood. Continuing."},
]- 第三层 -- manual compact :
compact工具按需触发同样的摘要机制。 - 循环整合三层:
python
def agent_loop(messages: list):
while True:
micro_compact(messages) # Layer 1
if estimate_tokens(messages) > THRESHOLD:
messages[:] = auto_compact(messages) # Layer 2
response = client.messages.create(...)
# ... tool execution ...
if manual_compact:
messages[:] = auto_compact(messages) # Layer 3完整历史通过 transcript 保存在磁盘上。信息没有真正丢失, 只是移出了活跃上下文。