Chat Memory 实战:让 LLM 记住多轮对话(Java 架构师的 AI 工程笔记 05)
这是系列的第五篇,解决一个很现实的问题:LLM 天生没有记忆,多轮对话怎么办。 上一篇把 LLM 的输出从一坨文本变成了可用的 Java 对象。但不管 Prompt 写得多好、输出格式多规整,只要用户对话超过一轮,LLM 就"失忆"了------它不记得你刚才说的"北京飞上海"。这一篇来解决这个问题。
前置知识:需要读完第四篇《Prompt 工程与结构化输出:让 LLM 返回可用的 Java 对象》,理解 PromptTemplate 和结构化输出的基本用法。
先看一个真实的翻车场景:
erlang
第1轮 → 用户:我的预算是1000元以内,不坐红眼航班
第2轮 → 用户:北京飞上海,明天的
第3轮 → AI:查到3个航班...
...(聊了十几轮后)
第15轮 → 用户:再帮我查北京飞广州
第16轮 → AI:推荐 CZ3156,¥1280,凌晨01:30起飞 ← 超预算 + 红眼,两条都违反了!原因:滑动窗口只保留最近 N 条消息,第 1 轮的预算约束被裁剪丢弃了。
这不是窗口大小的问题,而是架构问题。 调大窗口只是推迟翻车时间,真正的解法是分层记忆------像人脑一样,把不同保质期的信息存在不同的地方:
sql
┌────────────────────────────────────────────┐
│ System Prompt(永久层) │ 角色设定、工具规则 → 永远不丢
├────────────────────────────────────────────┤
│ 用户档案(长期记忆) │ "预算1000、不坐红眼" → Agent 自动提取
├────────────────────────────────────────────┤
│ 历史摘要(摘要层) │ 旧对话压缩成一段话 → 装饰器自动触发
├────────────────────────────────────────────┤
│ 最近对话(短期记忆) │ 最近 20 条原始消息 → 滑动窗口
└────────────────────────────────────────────┘这就是 ChatGPT、Claude 等产品背后的记忆架构。这一篇从最简单的滑动窗口讲起,一步步走到这个生产级方案------包括压缩策略的选型(LLM 摘要 vs 实体抽取 vs 向量检索)、自动触发的装饰器模式、以及 Checkpoint 断点恢复。
本篇速览:Memory 的本质(不是模型记住了,而是每次把历史重发)→ 五种裁剪策略对比 → 三种持久化方案 → 分层记忆架构(含压缩策略对比)→ Checkpoint 机制。学完你能让机票比价 Agent 支持自然的多轮对话,并且早期的关键约束永远不会被"忘记"。
最终效果预览:
第1轮:我的预算1000以内,不坐红眼
→ 好的,已记录您的偏好。请问想查什么航线?
...(中间聊了30轮,早期对话已被窗口裁剪)
第32轮:帮我查北京飞广州
→ 为您查到 2 个航班(已排除红眼和超预算航班):
MU3210 ¥780 08:00起飞 / CZ3587 ¥920 14:30起飞
← 30轮之后,预算和红眼约束仍然生效!理论篇
一、为什么需要 Memory------LLM 天生没有记忆
1.1 每次请求都是"失忆"的
LLM 是无状态的。每次 API 调用都是独立的,模型不会"记住"上一轮对话。
arduino
第1轮
用户:我想从北京飞上海
AI:好的,请问您想哪天出发?
第2轮
用户:明天的
AI:您想查询什么航线?请提供出发地和目的地。 ← 完全忘记了"北京飞上海"1.2 "记忆"的真相:每次都把历史重发
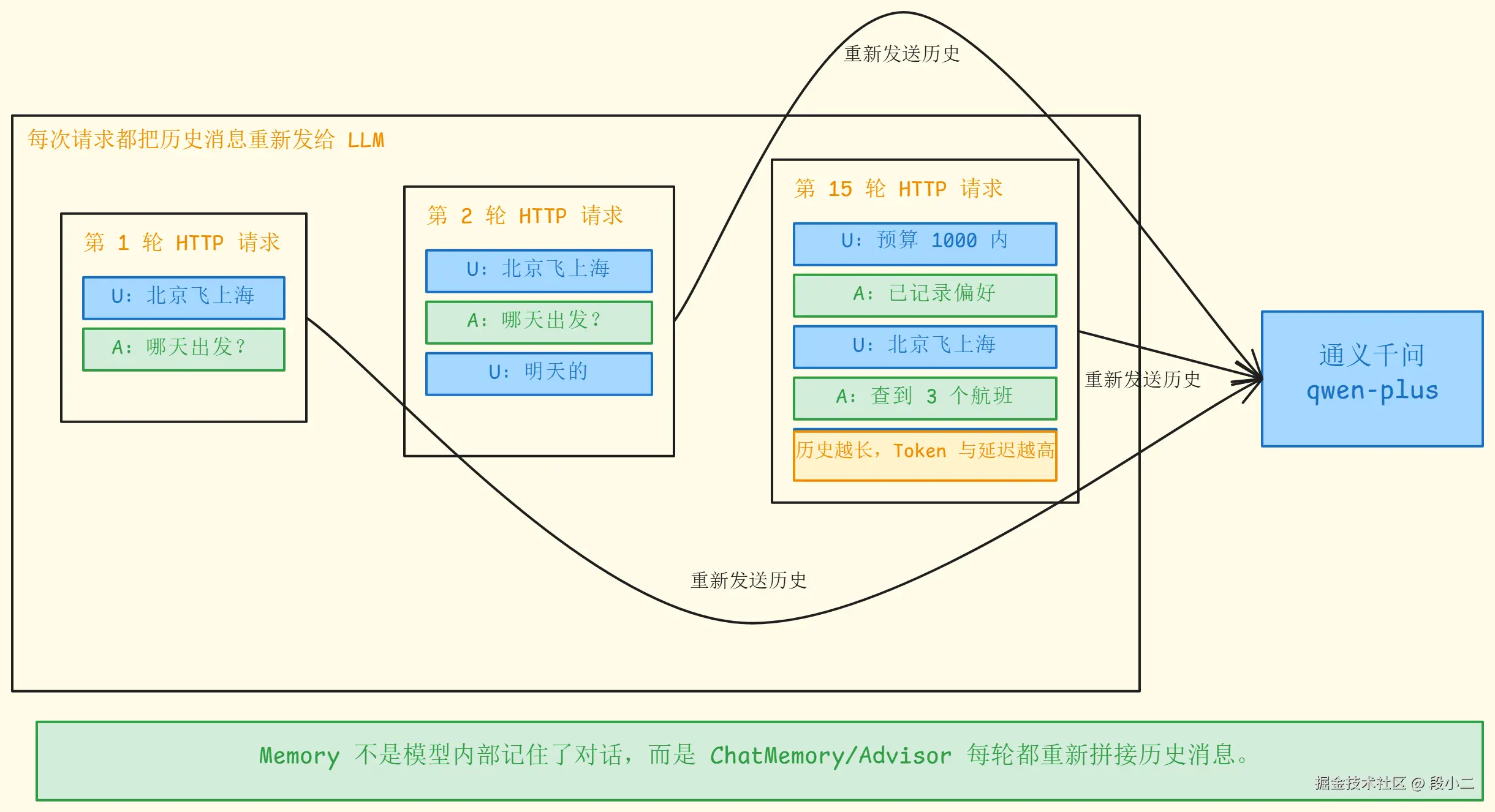 Chat Memory 的本质:不是模型记住了,而是每次都把历史对话重新发给它。
Chat Memory 的本质:不是模型记住了,而是每次都把历史对话重新发给它。
1.3 核心矛盾:Context Window 有限,对话可以无限长
| 因素 | 说明 |
|---|---|
| Context Window 限制 | qwen-turbo: 8K token,qwen-plus: 128K token,qwen-max: 128K token |
| 对话不断增长 | 用户可能连续对话几十轮 |
| 成本正比于 Token | 每轮都发全部历史 → token 消耗快速增长 → 费用暴涨 |
| 延迟正比于 Token | 输入越多 → 首 token 延迟越大 → 用户体验下降 |
所以需要"裁剪"策略:只保留最有价值的历史消息,丢弃或压缩其余部分。这就是各种 Memory 实现要解决的核心问题。
二、核心概念------Spring AI 的 Memory 体系
2.1 核心抽象
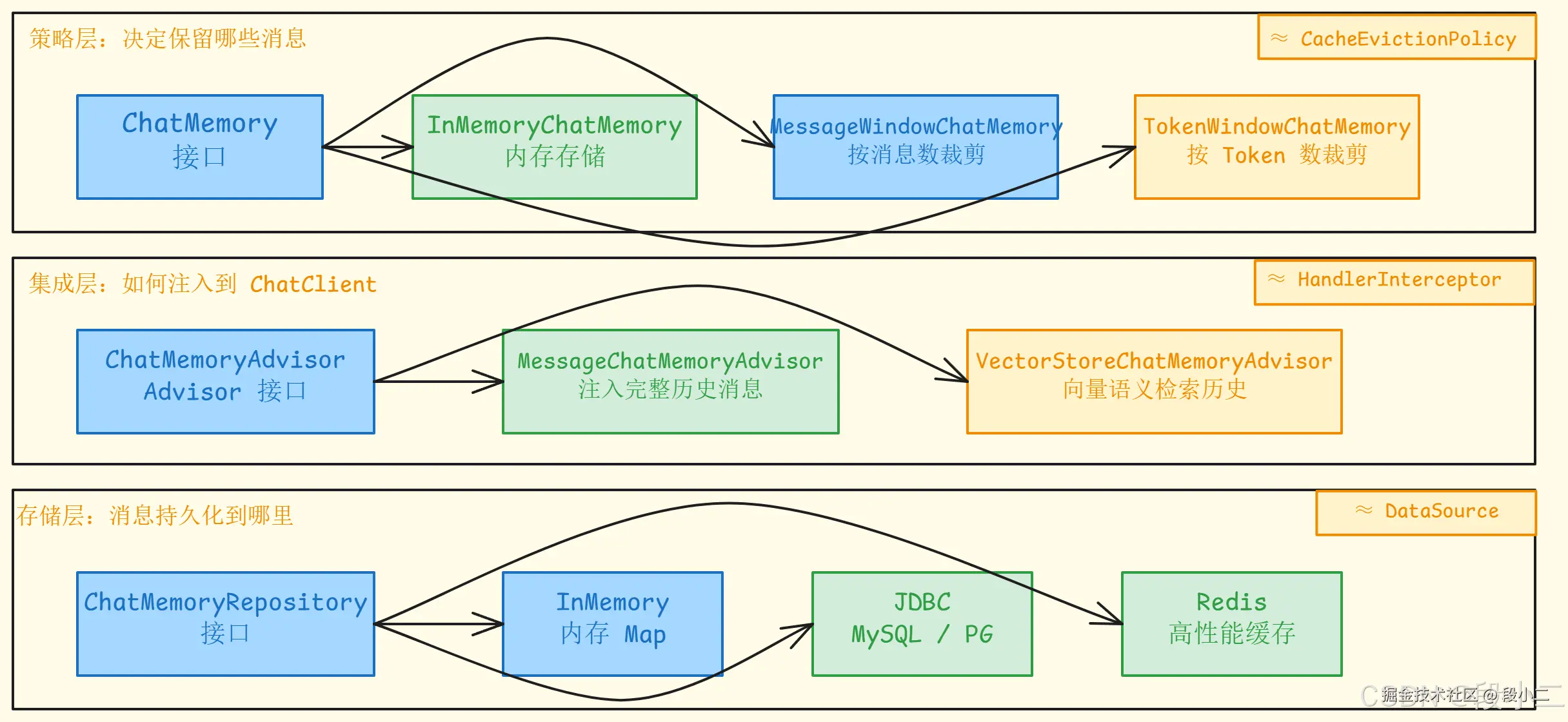
三层分离设计:
| 层 | 职责 | Java 类比 |
|---|---|---|
| 策略层 | 决定保留哪些消息 | CacheEvictionPolicy |
| 集成层 | 如何注入到 ChatClient | HandlerInterceptor |
| 存储层 | 消息存在哪里 | DataSource |
2.2 滑动窗口原理
只保留最近 N 条消息,超出后从最旧的开始丢弃。SystemMessage 永远保留,不参与计数。 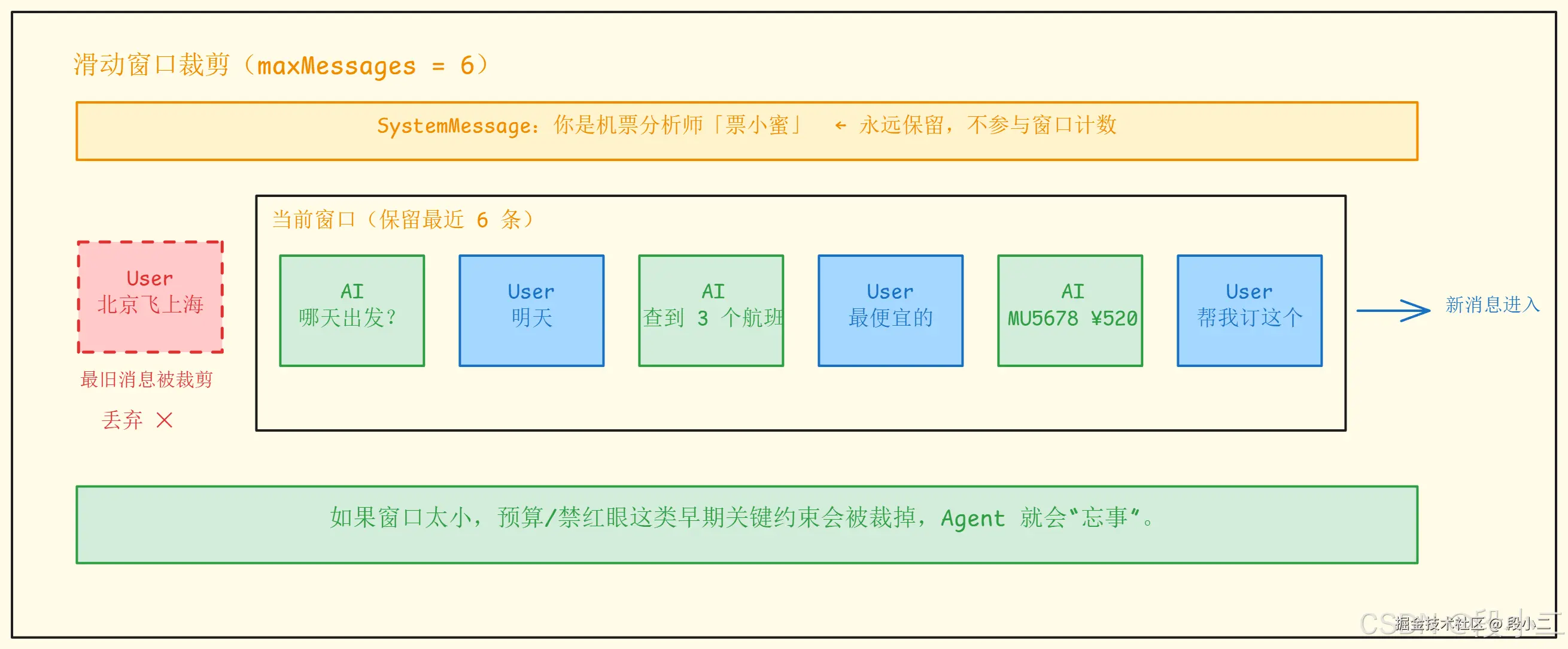
窗口大小怎么选?
sql
maxMessages 选型参考:
对话类型 建议值 理由
─────────────────────────────────────────
简单问答 10-20 上下文少,几轮就结束
机票查询 20-30 需要记住出发地/目的地/日期等多轮信息
客服对话 30-50 问题可能复杂,需要较长上下文
代码辅助 50-100 代码上下文通常很长
计算公式(粗略):
maxMessages ≈ (模型 Context Window × 0.5) / 平均每条消息 Token 数
留 50% 给 System Prompt、工具定义、当前回答生成窗口裁剪会丢失什么?
erlang
第1轮 → 用户:我的预算是1000元以内,不坐红眼航班 ← 关键约束
第2轮 → 用户:北京飞上海
第3轮 → AI:查到3个航班...
...
第12轮 → 用户:再查一下北京飞广州
如果窗口只有10条,第1轮已被裁剪:
AI 推荐了一个 ¥1200 的红眼航班 ← 违反了用户最初的约束!滑动窗口的致命弱点:早期的关键约束可能被裁剪丢失。生产环境需要配合其他策略(见进阶方案)。
2.3 五种裁剪策略对比
| 策略 | 优点 | 缺点 |
|---|---|---|
| MessageWindow(按消息数) | 简单可预测 | 长消息可能超出 Token 限制 |
| TokenBudget(按 Token 数) | 精确控制成本 | 裁剪滞后一轮(见下文) |
java
// 按消息数(简单,推荐入门)
MessageWindowChatMemory.builder().maxMessages(20).build();
// 按 Token 数(精确,推荐生产)------见 4.2 小节的 TokenBudgetAdvisor 实现Token 数从哪来? 不需要引入 Tokenizer 库估算。每次 LLM 响应里就带了精确的 token 统计:
java
Usage usage = response.chatResponse().getMetadata().getUsage();
usage.getPromptTokens(); // 本次请求的输入 token 数(精确值)
usage.getCompletionTokens(); // 本次输出 token 数
usage.getTotalTokens(); // 总计利用 promptTokens 做反馈式裁剪:第 N 轮请求后发现超预算 → 裁掉旧消息 → 第 N+1 轮回到预算内。裁剪"滞后一轮"但完全精确,无需任何估算。
完整对比:
| 方案 | 实现复杂度 | Token 成本 | 信息保留 | 适合场景 |
|---|---|---|---|---|
| 消息条数窗口 | 最低 | 不可控 | 丢弃 | 短对话、Demo |
| Token 预算窗口 | 低 | 精准控制 | 丢弃 | 生产环境基线方案 |
| 摘要压缩窗口 | 中 | 额外 LLM 调用 | 压缩保留 | 需要长期上下文的 Agent |
| 分层过期 | 高 | 多次 LLM 调用 | 分级保留 | 客服、长程任务 Agent |
| 语义相关性 | 高 | Embedding 计算 | 按需召回 | 知识密集型对话 |
选型建议:先用"消息条数窗口"跑起来。如果遇到 token 超限或费用问题,叠加"Token 预算窗口"做精确控制。如果长对话丢关键信息,再加"摘要压缩窗口"。"分层过期"和"语义相关性"是大规模生产场景的进阶选择,大部分项目前三种就够了。
2.4 Token 预算分配
ini
假设模型 Context Window = 32K token
推荐分配:
┌──────────────────────────┐
│ System Prompt ~2K │ 角色设定 + 约束
│ 工具定义 ~3K │ 所有注册工具的 JSON Schema
│ 历史消息 ~10K │ Memory 窗口
│ 当前用户输入 ~1K │ 本轮问题
│ ──────────────────────── │
│ 留给模型生成 ~16K │ 模型输出 + 安全余量
└──────────────────────────┘
所以 Memory 的 maxTokens 应该设为 ~10K2.5 成本估算
arduino
以 qwen-plus 为例(输入 ¥0.8/百万 token):
场景:客服 Agent,平均每轮对话 500 token 输入
窗口保留 20 轮 = 10,000 token/次
每次请求成本 = 10,000 / 1,000,000 × ¥0.8 = ¥0.008
每天 10,000 次请求 = ¥80/天
如果窗口从 20 轮缩小到 10 轮 = 5,000 token/次
每天成本降到 ¥40/天------省了一半!
结论:Memory 窗口大小直接影响成本,需要在"记忆质量"和"成本"间平衡三、架构解析------持久化、进阶方案与 Checkpoint
3.1 持久化方案对比
InMemoryChatMemoryRepository 的数据存在 JVM 堆内存中:
- 应用重启 → 全部丢失
- 多实例部署 → 各实例记忆不共享
- 内存占用 → 用户多了会 OOM
| 方案 | 读写性能 | 适用场景 | 运维成本 |
|---|---|---|---|
| InMemory | 极快 | 开发/测试 | 无 |
| JDBC (MySQL) | 中等 | 需要审计、复杂查询 | 低 |
| Redis | 很快 | 高频读写、生产环境 | 中 |
| Redis + MySQL 双写 | 很快 | 大规模生产系统 | 高 |
生产建议:Redis 做热存储(最近对话),MySQL 做冷存储(全量历史),通过异步双写同步。
选型决策------什么场景用 Redis,什么场景用 MySQL?
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 单体应用、用户量 <1000 | MySQL 单写 | 够用,运维简单,Spring AI JDBC 开箱即用 |
| 需要对话审计、合规留痕 | MySQL 为主 | SQL 可查询、可导出、可关联业务工单 |
| 多实例部署、QPS >100 | Redis 为主 | 每次请求都要读全量历史,MySQL 扛不住高频读 |
| 对话有 TTL(如24小时过期) | Redis | Redis 原生支持 EXPIRE,MySQL 需要定时清理 |
| 大规模生产(QPS >1000) | Redis + MySQL 双写 | Redis 扛读写,MySQL 存全量用于分析和恢复 |
| 纯开发/测试/Demo | InMemory | 零配置,重启丢失无所谓 |
Redis + MySQL 双写的典型架构:
vbnet
写入路径:
ChatMemory.save() → Redis(同步,保证实时性)
→ MySQL(异步,通过消息队列或 @Async)
读取路径:
ChatMemory.find() → Redis(命中率 >99%)
→ Redis miss → 回源 MySQL → 回写 Redis
过期策略:
Redis:SET key value EX 86400(24小时 TTL)
MySQL:保留全量,定期归档超过 30 天的数据我的实际做法:先用 MySQL 跑起来 (Spring AI JDBC 零代码),观察 QPS。如果 Memory 读取成为瓶颈(监控
spring_ai_chat_memory_find耗时),再加 Redis 缓存层。别一上来就双写------大部分项目用 MySQL 就够了。
3.2 进阶方案:解决窗口裁剪丢信息的问题
方案一:VectorStoreChatMemoryAdvisor(向量检索记忆)
不是按时间保留最近 N 条,而是根据当前问题语义检索最相关的历史消息 。 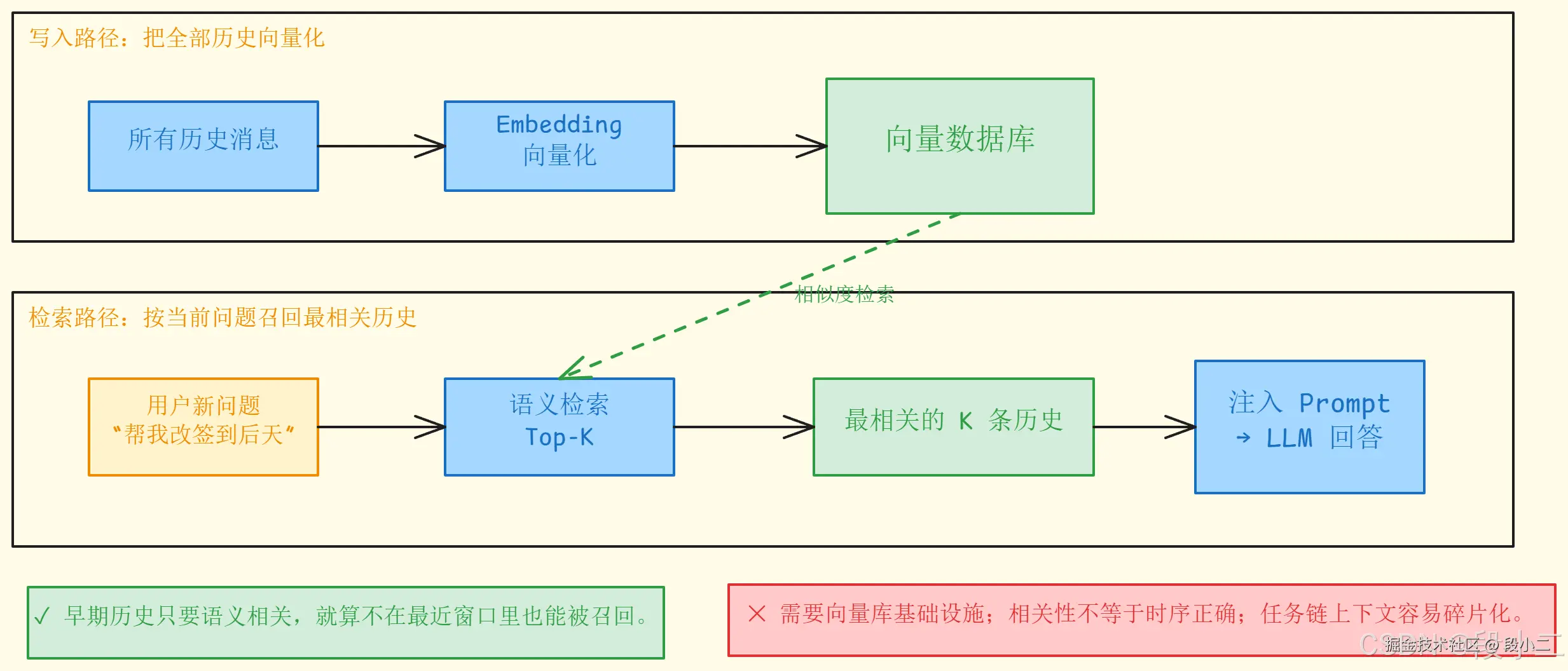
优点:即使早期对话已经很久远,只要语义相关就能被检索到。 缺点:需要向量数据库基础设施;语义相似不等于真正相关;对话的时序关系不好用向量表达。
方案二:关键信息固定在 System Prompt
把最关键的约束直接写在 System Prompt 中------System Prompt 永远不会被裁剪。 优点:简单可靠,关键约束永远不会丢失。 缺点:只能处理预先知道的固定约束,无法保留对话中动态产生的信息。
方案三:分层记忆架构(生产级)
组合多种策略,构建类似 ChatGPT 的分层记忆: 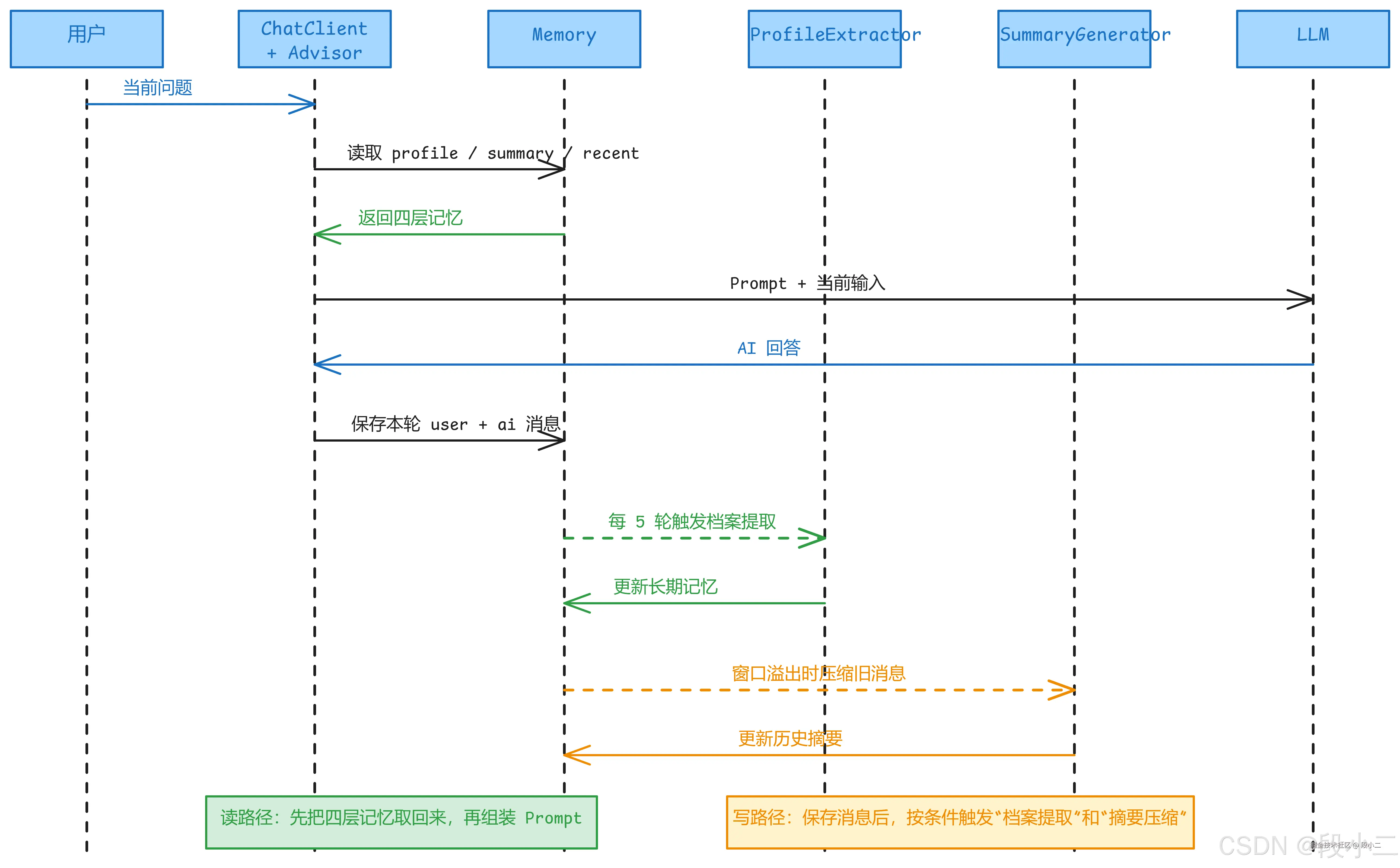
这类方案不是把全部历史消息一股脑塞进上下文,而是按稳定性和价值分层:
- 永久层:角色设定、工具规则、固定业务约束,始终保留在
System Prompt - 长期记忆:预算、排除条件、偏好航司这类跨会话偏好,持久化后每次注入
- 摘要层:被窗口淘汰的旧消息压缩成摘要,保留关键事实和对话脉络
- 短期记忆:最近
N轮完整对话,保留当前任务需要的原始细节
实际发给 LLM 的 Prompt 结构:
csharp
[System] 你是机票分析师「票小蜜」...(永久层)
[System] 【用户档案】预算1000元内,不坐红眼航班,偏好东方航空(长期记忆)
[System] 【历史摘要】用户之前查询了北京→上海的航班,选择了MU5678...(摘要层)
[User] 帮我改签到后天(短期记忆-最近对话)
[AI] 好的,为您查询后天的航班...
[User] 有没有更早的?(当前输入)这是目前最强大的方案,ChatGPT、Claude 等产品都采用类似架构。具体代码实现见 4.3 和 4.4 实战小节。
注意四层的 Token 分配比例:
sql
32K Context Window 的推荐分配:
──────────────────────────────────────
第一层 System Prompt ~2K 角色 + 工具 + 规则(固定)
第二层 用户档案 ~0.5K 3-5 个关键偏好(固定)
第三层 历史摘要 ~1K 压缩后的旧对话(缓慢增长)
第四层 短期记忆 ~10K 最近 20 条消息(滑动窗口)
留给模型生成 ~18K 输出 + 安全余量
──────────────────────────────────────
总 Token 控制在 ~14K,留 ~18K 给模型------宁可摘要压缩多一点,也别挤掉生成空间。这套架构怎么自动运转?
- 长期记忆层:定期从对话中提取结构化偏好,并做增量合并,避免后一次提取把前面的事实覆盖掉
- 摘要层:不要在 Advisor 里轮询生成摘要,而是在 Memory 层感知窗口裁剪,把即将淘汰的消息压缩后持久化
- 职责分离:Advisor 负责读取并注入,Memory 负责写入与裁剪,边界清晰后,排障和扩展都更容易
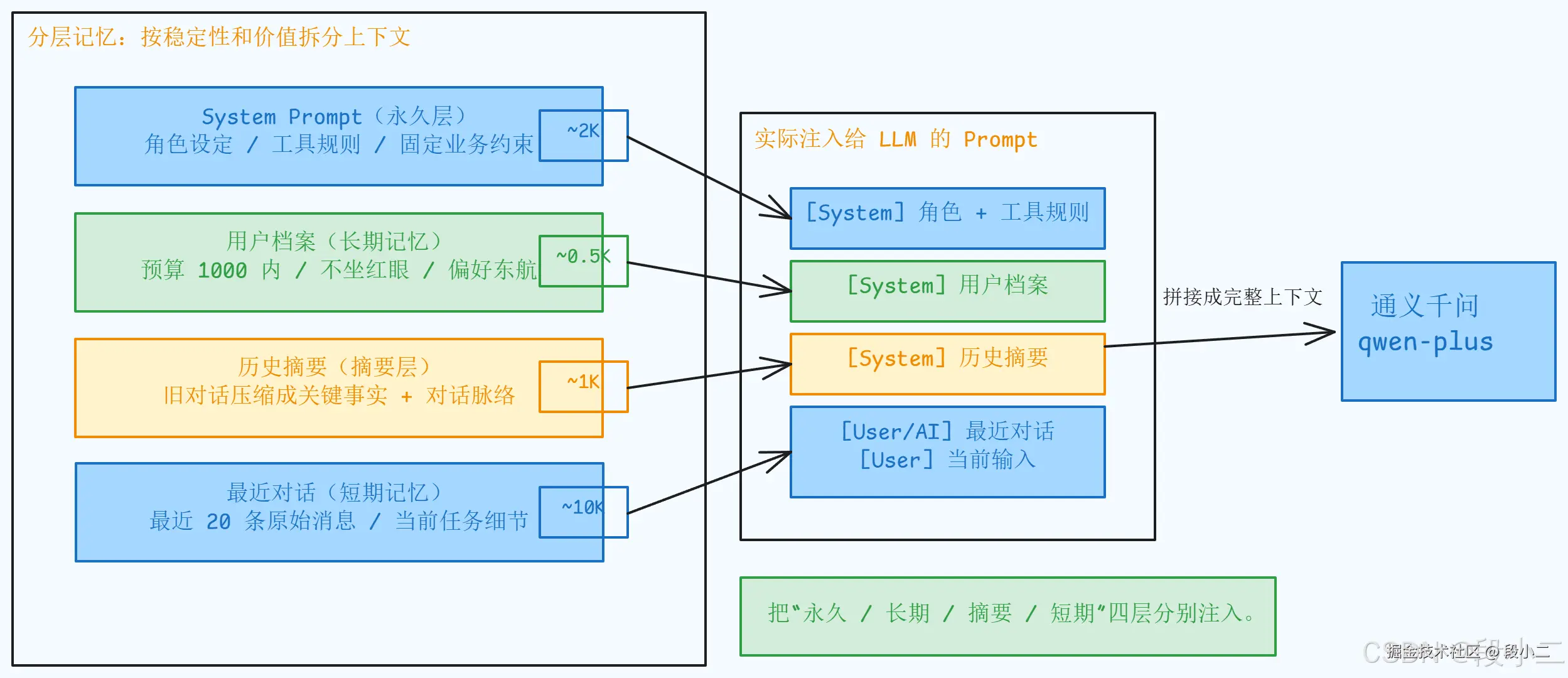
整个自动化流程的额外 LLM 调用成本并不高:每 5 轮对话多做一次档案提取,窗口裁剪时再做一次摘要压缩。一个 30 轮左右的任务型对话,额外 token 成本通常可以接受。
什么时候不值得做分层记忆? 如果你的场景对话不超过 20 轮、没有跨会话偏好记忆需求,一个 MessageWindowChatMemory 就够了。分层架构的收益在 长对话 + 跨会话 场景才能体现。
3.3 压缩策略选型------LLM 摘要不是唯一方案
用 LLM 做摘要最直觉,但也有坑。业内有四种主流策略,各有取舍:
| 策略 | 代表项目 | 原理 | 优势 | 劣势 |
|---|---|---|---|---|
| LLM 摘要 | LangChain SummaryBufferMemory |
用 LLM 压缩旧消息为自然语言 | 简单,保留语义 | 信息衰减、幻觉、每次花钱 |
| 实体抽取 | LangChain EntityMemory |
从对话中提取结构化实体 | 关键事实不丢失 | 只保留实体,丢失对话逻辑 |
| 向量检索(RAG) | MemGPT / Letta | 全量存向量库,按相关性检索 | 无损,按需召回 | 检索质量不稳定,上下文碎片化 |
| 分层混合 | 本章方案 | 实体 + 摘要 + 短期窗口 | 各层互补 | 实现复杂度高 |
纯 LLM 摘要的三个已知问题:
- 信息衰减 ------ "摘要的摘要"每压缩一轮丢一层细节。对话 100 轮后,第 1 轮的"预算 1000 元"可能被压没
- 幻觉风险 ------ LLM 压缩时可能"脑补"原文没有的信息
- LLM 不知道什么重要 ------ 压缩时不知道未来对话会问什么,可能把关键信息当噪音丢掉
我们的解法:实体抽取 + 结构化摘要,两层互补。
ProfileExtractor的职责是把预算、排除条件、偏好航司等长期偏好抽成结构化数据,写入长期记忆层,避免被后续摘要压掉SummaryGenerator的职责是把被裁剪的旧对话压成"关键事实 + 对话脉络",尽量减少自由文本摘要带来的信息衰减
完整代码见 4.4 自动提取用户档案与摘要压缩 小节。
为什么不用向量检索(RAG Memory)? 在机票这类任务型对话中,"上下文连贯性"比"检索精度"更重要。用户说"帮我改签"需要知道前面完整的决策链(查了什么航班、选了哪个、为什么选它),不是检索到几个碎片。摘要 + 实体抽取在任务型对话中比 RAG 更实用。 但如果你的场景是知识库问答(对话跨度大、话题跳跃),向量检索才是更好的选择------这是下一章 RAG 的内容。
3.4 Checkpoint 机制------Agent 状态持久化与恢复
为什么需要 Checkpoint?
Function Calling 场景下,一个请求可能涉及多次工具调用。如果中途失败怎么办?
vbnet
用户:"帮我查北京到上海的机票,找最便宜的并下单"
Agent 执行过程:
Step 1: searchFlights(北京→上海) → 成功,返回3个航班
Step 2: compareFlights([MU5678, CA1234, HU7890]) → 成功,推荐 MU5678
Step 3: bookFlight(MU5678) → 失败!支付服务超时
问题:如果用户重试,是从 Step 1 重新开始,还是从 Step 3 继续?Checkpoint 让 Agent 能够保存中间状态,故障恢复时从断点继续。
核心概念 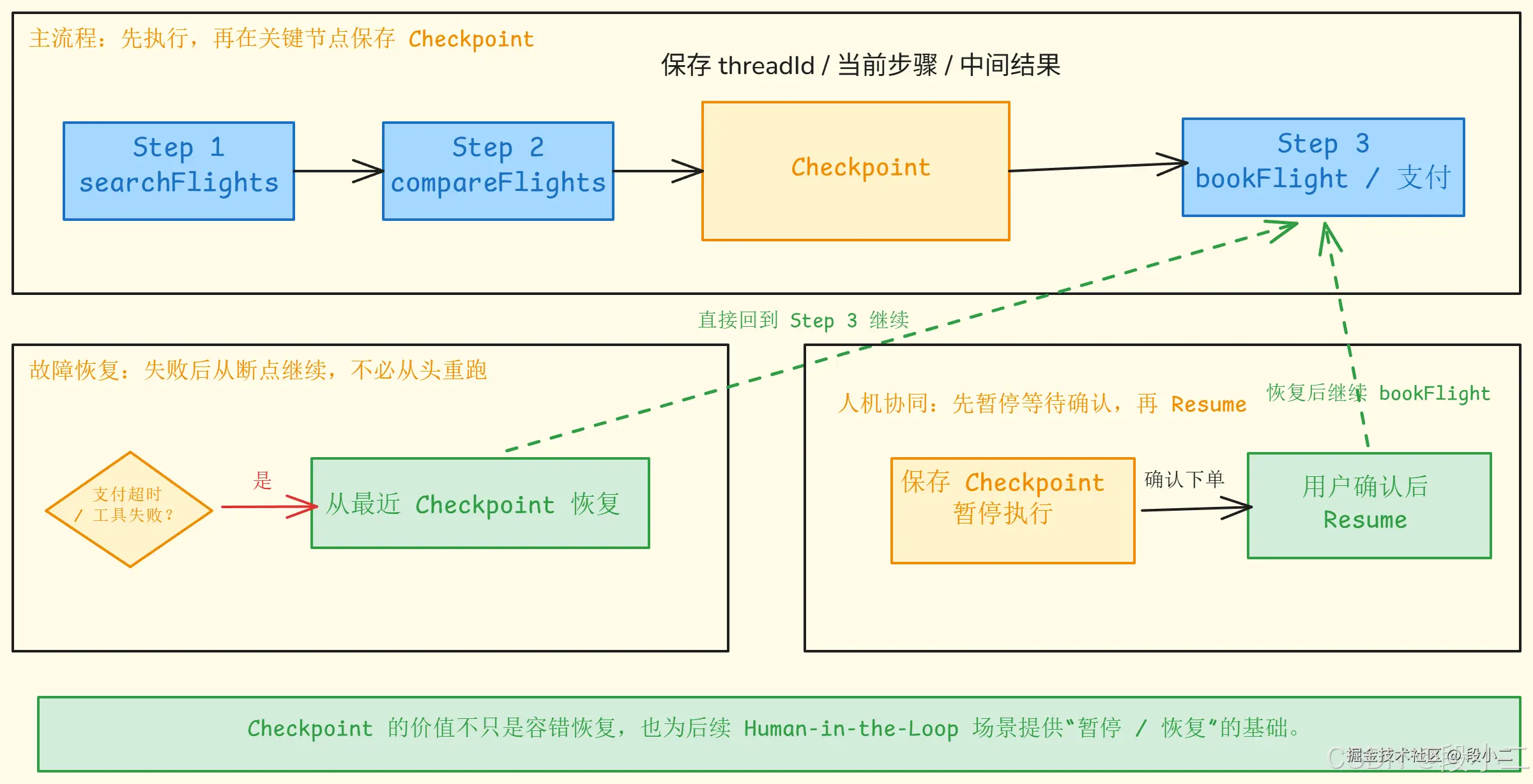
| 概念 | 说明 |
|---|---|
| State | Agent 的当前状态(已执行的步骤、中间结果、工具调用历史) |
| Checkpoint | 某一时刻的 State 快照 |
| Thread | 一次完整的 Agent 执行流程,由 threadId 标识 |
| Resume | 从某个 Checkpoint 恢复,继续执行 |
Checkpoint 与 Human-in-the-Loop
Checkpoint 的一个关键应用是支持人机协同------Agent 执行到某个步骤暂停,等待人工确认后继续:
vbnet
Agent 执行流程:
Step 1: searchFlights → 查到航班
Step 2: compareFlights → 推荐 MU5678
Step 3: → 暂停!保存 Checkpoint
→ 返回给用户:"推荐 MU5678 ¥520,确认下单吗?"
用户确认后:
Step 4: 从 Checkpoint 恢复
Step 5: bookFlight(MU5678) → 下单成功这就是下一章要详细讲的 Human-in-the-Loop 模式的基础。
实战篇
四、裁剪与记忆策略
4.1 Memory 快速上手
从零搭建一个有记忆的对话 API,一次性解决三个问题:存储后端、窗口策略、会话隔离。
配置类------InMemory + 滑动窗口
java
@Configuration
public class MemoryConfig {
// 存储后端:InMemory(开发用,生产替换为 JDBC/Redis,见第五章)
@Bean
public ChatMemoryRepository chatMemoryRepository() {
return new InMemoryChatMemoryRepository();
}
// 策略层:滑动窗口(保留最近 20 条)+ 装饰器(自动摘要压缩)
@Bean
public ChatMemory chatMemory(ChatMemoryRepository repository,
SummaryGenerator summaryGenerator) {
ChatMemory windowMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.chatMemoryRepository(repository)
.build();
return new SummarizingChatMemory(windowMemory, summaryGenerator);
}
// 集成层:通过 Advisor 自动注入历史消息
@Bean("memoryChatClient")
public ChatClient memoryChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
return builder
.defaultSystem("你是机票分析师「票小蜜」。只处理机票相关问题,无关问题礼貌拒绝。")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
new SimpleLoggerAdvisor()
)
.build();
}
}Controller------用 conversationId 隔离不同用户/会话
java
@RestController
@RequestMapping("/api/v4/chat")
public class MemoryChatController {
private final ChatClient chatClient;
private final ChatMemoryRepository repository;
public MemoryChatController(@Qualifier("memoryChatClient") ChatClient chatClient,
ChatMemoryRepository repository) {
this.chatClient = chatClient;
this.repository = repository;
}
// 关键:通过 conversationId 参数隔离不同用户的记忆
@GetMapping
public String chat(@RequestParam String q,
@RequestParam(defaultValue = "default") String sessionId) {
return chatClient.prompt(q)
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, sessionId))
.call()
.content();
}
@DeleteMapping("/memory")
public String clearMemory(@RequestParam String sessionId) {
repository.deleteByConversationId(sessionId);
return "会话 " + sessionId + " 的记忆已清除";
}
}验证------两个独立会话互不干扰:
sql
GET /chat?q=我想从北京飞上海&sessionId=user-001
→ "好的,请问您想哪天出发?"
GET /chat?q=我想从广州飞深圳&sessionId=user-002
→ "好的,请问您想哪天出发?"
GET /chat?q=明天的&sessionId=user-001
→ "为您查询北京→上海明天的航班..." 正确关联到 user-001 的上下文
GET /chat?q=明天的&sessionId=user-002
→ "为您查询广州→深圳明天的航班..." 正确关联到 user-002 的上下文如果不传 sessionId,所有用户的对话历史会混在一起------这是最常见的 Memory 踩坑点。
conversationId 的设计建议
| 场景 | conversationId 设计 | 说明 |
|---|---|---|
| 单用户单会话 | userId |
最简单,每个用户一份记忆 |
| 单用户多会话 | userId + sessionId |
类似 ChatGPT 的多对话列表 |
| 客服场景 | customerId + ticketId |
按工单隔离 |
| 匿名场景 | UUID |
浏览器端生成,Cookie 存储 |
4.2 Token 预算裁剪:用 LLM 返回的真实 token 数精确控制
MessageWindowChatMemory 按消息条数裁剪,但一条消息可能是 10 个字也可能是 2000 个字------实际 token 消耗波动很大。生产环境需要按 token 数裁剪。
核心思路 :直接用 LLM 响应中的 Usage.getPromptTokens() 做反馈式裁剪,100% 精确,零依赖。
ini
不调 LLM 就不知道精确 token 数,所以流程是:
第5轮 → promptTokens=6000 → 没超预算(8000),放过
第6轮 → promptTokens=9200 → 超预算了!记录下来
第7轮请求前 → 发现上轮超了 → 裁掉最旧的几条消息
第7轮 → promptTokens=5800 → 回到预算内 ✓代码实现------TokenBudgetAdvisor
java
public class TokenBudgetAdvisor implements CallAdvisor {
private final ChatMemoryRepository repository;
private final int maxPromptTokens;
private final ConcurrentHashMap<String, Integer> lastPromptTokens = new ConcurrentHashMap<>();
public TokenBudgetAdvisor(ChatMemoryRepository repository, int maxPromptTokens) {
this.repository = repository;
this.maxPromptTokens = maxPromptTokens;
}
@Override
public int getOrder() {
return 50; // 在 MessageChatMemoryAdvisor(默认 100)之前执行
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
String conversationId = (String) request.context()
.getOrDefault(ChatMemory.CONVERSATION_ID, "default");
// 请求前:如果上一轮超预算,先裁剪
Integer lastTokens = lastPromptTokens.get(conversationId);
if (lastTokens != null && lastTokens > maxPromptTokens) {
trimByTokenBudget(conversationId, lastTokens);
}
// 执行主链路
ChatClientResponse response = chain.nextCall(request);
// 请求后:记录本轮实际 promptTokens
if (response.chatResponse() != null) {
Usage usage = response.chatResponse().getMetadata().getUsage();
if (usage != null && usage.getPromptTokens() != null) {
lastPromptTokens.put(conversationId, usage.getPromptTokens());
}
}
return response;
}
// 根据 token 预算裁掉最旧的消息
private void trimByTokenBudget(String conversationId, int currentPromptTokens) {
List<Message> messages = repository.findByConversationId(conversationId);
if (messages.isEmpty()) return;
int fixedOverhead = 2000; // System Prompt + 工具定义的 token 开销
int messageTokens = Math.max(currentPromptTokens - fixedOverhead, 1);
int avgTokensPerMsg = messageTokens / messages.size();
int excessTokens = currentPromptTokens - maxPromptTokens;
int messagesToRemove = Math.max(1, (excessTokens / Math.max(avgTokensPerMsg, 1)) + 1);
messagesToRemove = Math.min(messagesToRemove, messages.size() - 2); // 至少保留 2 条
if (messagesToRemove <= 0) return;
List<Message> retained = messages.subList(messagesToRemove, messages.size());
repository.saveAll(conversationId, retained);
}
}使用方式------加到 Advisor 链中:
java
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
ChatMemory chatMemory,
ChatMemoryRepository repository) {
return builder
.defaultSystem("你是机票分析师「票小蜜」")
.defaultAdvisors(
new TokenBudgetAdvisor(repository, 8000), // Token 预算裁剪
MessageChatMemoryAdvisor.builder(chatMemory).build(), // 短期记忆
new SimpleLoggerAdvisor()
)
.build();
}预算设置参考:
arduino
模型 Context Window 建议 maxPromptTokens 说明
────────────────────────────────────────────────────────
qwen-turbo 8K 3000-4000 留一半给输出
qwen-plus 128K 40000-60000 对话再长也够用
qwen-max 128K 40000-60000 同上和 MessageWindowChatMemory 的配合 :两者可以叠加使用。MessageWindowChatMemory 做粗粒度保护(消息不超过 N 条),TokenBudgetAdvisor 做细粒度控制(token 不超预算)。双保险。
4.3 分层记忆架构落地:四层 Prompt 组装
3.2 节讲了分层记忆的理论,这里开始把四层真正接进 Spring AI。核心思路:用一个自定义 Advisor,在每次请求前把"用户档案 + 历史摘要"拼进 System Prompt;短期记忆继续交给 MessageWindowChatMemory。
用户档案存储(长期记忆层)
java
@Component
public class UserProfileStore {
// 生产环境替换为 JDBC / Redis
private final Map<String, UserProfile> profiles = new ConcurrentHashMap<>();
public record UserProfile(
int budgetLimit, // 预算上限
String excludeConditions, // 排除条件(如"不坐红眼航班")
String preferredAirline, // 偏好航司
String updatedAt // 最后更新时间
) {}
public UserProfile getProfile(String userId) {
return profiles.get(userId);
}
public void updateProfile(String userId, UserProfile profile) {
profiles.put(userId, profile);
}
}历史摘要存储(摘要层)
java
@Component
public class ConversationSummaryStore {
private final Map<String, String> summaries = new ConcurrentHashMap<>();
public String getSummary(String conversationId) {
return summaries.getOrDefault(conversationId, "");
}
public void updateSummary(String conversationId, String summary) {
summaries.put(conversationId, summary);
}
}分层记忆 Advisor------自动组装四层 Prompt
java
@Component
public class LayeredMemoryAdvisor implements CallAdvisor {
private final UserProfileStore profileStore;
private final ConversationSummaryStore summaryStore;
public LayeredMemoryAdvisor(UserProfileStore profileStore,
ConversationSummaryStore summaryStore) {
this.profileStore = profileStore;
this.summaryStore = summaryStore;
}
@Override
public String getName() {
return "LayeredMemoryAdvisor";
}
@Override
public int getOrder() {
return 0; // 在 MessageChatMemoryAdvisor 之前执行
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
String conversationId = (String) request.context()
.getOrDefault(ChatMemory.CONVERSATION_ID, "default");
// 从 conversationId 中解析 userId(格式:userId-sessionId)
String userId = conversationId.contains("-")
? conversationId.substring(0, conversationId.indexOf("-"))
: conversationId;
// 组装分层 System Prompt
StringBuilder layeredPrompt = new StringBuilder();
// 第二层:用户档案(长期记忆)
UserProfileStore.UserProfile profile = profileStore.getProfile(userId);
if (profile != null) {
layeredPrompt.append("\n\n【用户档案 - 必须严格遵守】\n");
layeredPrompt.append("- 预算上限:").append(profile.budgetLimit()).append(" 元\n");
layeredPrompt.append("- 排除条件:").append(profile.excludeConditions()).append("\n");
layeredPrompt.append("- 偏好航司:").append(profile.preferredAirline()).append("\n");
}
// 第三层:历史摘要
String summary = summaryStore.getSummary(conversationId);
if (!summary.isEmpty()) {
layeredPrompt.append("\n\n【历史摘要】\n").append(summary);
}
// 把分层信息追加到 System Prompt
if (!layeredPrompt.isEmpty()) {
request = request.mutate()
.prompt(request.prompt().augmentSystemMessage(layeredPrompt.toString()))
.build();
}
// 第四层:短期记忆(交给后续的 MessageChatMemoryAdvisor 处理)
return chain.nextCall(request);
}
}最终发给 LLM 的完整 Prompt(四层组装后):
csharp
[System] 你是机票分析师「票小蜜」。 ← 第一层:永久角色设定
对话规则:1. 查询需要三个信息...
当前日期:2026-03-18
【用户档案 - 必须严格遵守】 ← 第二层:长期记忆
- 预算上限:1000 元
- 排除条件:不坐红眼航班
- 偏好航司:东方航空
【历史摘要】 ← 第三层:摘要层
用户之前查询了北京→上海的航班,选择了 MU5678
[User] 帮我改签到后天 ← 第四层:短期记忆(滑动窗口)
[AI] 好的,为您查询后天的航班...
[User] 有没有更早的? ← 当前输入4.4 自动提取用户档案与摘要压缩
分层架构真正进入生产后,关键不是"手动设置两层数据",而是让 Agent 自动维护长期记忆和摘要层。
自动提取用户档案------用 LLM 从对话中抽取偏好
java
@Component
public class ProfileExtractor {
private final ChatClient.Builder clientBuilder;
private final UserProfileStore profileStore;
public void extractAndSave(String userId, String chatHistory) {
ChatClient extractClient = clientBuilder.build();
UserProfile profile = extractClient.prompt()
.system("""
你是一个信息提取助手。从对话历史中提取用户的机票偏好信息。
如果对话中没有提到某项偏好,对应字段填"未提及"。
budgetLimit 如果未提及填 0。
只输出 JSON,不要任何额外文字。
""")
.user("从以下对话中提取用户偏好:\n\n" + chatHistory)
.call()
.entity(UserProfile.class); // 结构化输出(第四章的知识)
if (profile != null) {
// 增量合并:只更新本次提到的字段,保留旧值
UserProfile existing = profileStore.getProfile(userId);
profileStore.updateProfile(userId, mergeProfiles(existing, profile));
}
}
}关键设计:提取结果是增量合并的。用户第 1 轮说了预算,第 8 轮说了偏好航司,两次提取的结果要合并成完整档案,而不是后者覆盖前者。
自动生成历史摘要------窗口裁剪时自动压缩
这里有一个关键设计决策:摘要不要靠 Advisor 轮询,而应该在 Memory 层拦截 add() 操作。窗口裁剪发生的那一刻,自动压缩被淘汰的消息。
java
/**
* 装饰器模式------在滑动窗口裁剪时自动压缩被淘汰的消息
*
* 包装原始 ChatMemory,拦截 add() 操作:
* 1. add 之前:快照当前消息
* 2. 委托给内部 ChatMemory(滑动窗口裁剪在这里发生)
* 3. add 之后:对比快照,找出被裁剪的消息
* 4. 异步调用 SummaryGenerator 压缩被裁剪的消息
*/
public class SummarizingChatMemory implements ChatMemory {
private final ChatMemory delegate; // 内部:MessageWindowChatMemory
private final SummaryGenerator summaryGenerator;
private final Executor asyncExecutor = Executors.newSingleThreadExecutor();
@Override
public void add(String conversationId, List<Message> messages) {
// 1. 快照裁剪前的消息
List<Message> before = new ArrayList<>(delegate.get(conversationId));
// 2. 委托给内部 ChatMemory(窗口裁剪在此发生)
delegate.add(conversationId, messages);
// 3. 对比找出被裁剪的消息(FIFO,被淘汰的一定在 before 头部)
List<Message> after = delegate.get(conversationId);
if (before.size() + messages.size() > after.size()) {
int evictedCount = before.size() + messages.size() - after.size();
List<Message> evicted = before.subList(0, Math.min(evictedCount, before.size()));
if (!evicted.isEmpty()) {
String evictedText = evicted.stream()
.map(m -> m.getMessageType().name() + ": " + m.getText())
.collect(Collectors.joining("\n"));
// 4. 异步压缩------不阻塞主对话
asyncExecutor.execute(() ->
summaryGenerator.summarizeAndSave(conversationId, evictedText));
}
}
}
// get() 和 clear() 直接委托给内部 ChatMemory
}配置时用装饰器包装:
java
@Bean
public ChatMemory chatMemory(ChatMemoryRepository repository, SummaryGenerator summaryGenerator) {
ChatMemory windowMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.chatMemoryRepository(repository)
.build();
// 装饰器:窗口裁剪时自动触发摘要压缩
return new SummarizingChatMemory(windowMemory, summaryGenerator);
}这样 LayeredMemoryAdvisor 只负责读取并注入用户档案和摘要,SummarizingChatMemory 负责写入时自动压缩,职责边界会更清晰。
结构化摘要生成器
java
@Component
public class SummaryGenerator {
public void summarizeAndSave(String conversationId, String oldMessages) {
String existingSummary = summaryStore.getSummary(conversationId);
// 结构化摘要 prompt------分"关键事实"和"对话脉络",防止关键信息被稀释
String systemPrompt = """
你是一个对话压缩助手。按以下格式输出,不超过 300 字:
【关键事实】(绝对不能丢失的信息,用 - 列出)
- 人名、地点、日期、金额、航班号、已做的决策
【对话脉络】(一段话概括对话走向)
用户问了什么 → 得到了什么结果 → 当前状态
规则:
1. 关键事实必须保留原始数值,不要模糊化("约500元" → "¥520")
2. 如果已有摘要和新对话有冲突,以新对话为准
3. 只输出上述格式,不要其他前缀或解释
""";
String userPrompt = existingSummary.isEmpty()
? "压缩以下对话:\n\n" + oldMessages
: "将已有摘要和新对话合并压缩:\n\n【已有摘要】\n"
+ existingSummary + "\n\n【新对话】\n" + oldMessages;
String summary = clientBuilder.build().prompt()
.system(systemPrompt)
.user(userPrompt)
.call()
.content();
summaryStore.updateSummary(conversationId, summary);
}
}在 Advisor 中自动触发档案提取
java
// LayeredMemoryAdvisor.adviseCall() 中,响应返回后:
ChatClientResponse response = chain.nextCall(request); // 先完成主对话
// 每 5 轮异步提取用户档案(不阻塞主流程)
int turnCount = turnCounters.merge(conversationId, 1, Integer::sum);
if (turnCount % 5 == 0) {
asyncExecutor.execute(() ->
profileExtractor.extractAndSave(userId, chatHistory)
);
}
// 注意:摘要压缩不在这里触发,而是由 SummarizingChatMemory 在 Memory 层自动处理
return response;五、持久化实战
5.1 JDBC 持久化(MySQL / PostgreSQL)
Spring AI 提供了开箱即用的 JDBC 实现。
Step 1:添加依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>Step 2:配置数据源
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/agent_db?useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: your_password
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always # 自动建表(首次启动用,生产环境改为 never)Step 3:自动建表的 Schema
Spring AI 会自动创建如下表结构:
sql
CREATE TABLE IF NOT EXISTS ai_chat_memory (
conversation_id VARCHAR(256) NOT NULL,
content TEXT NOT NULL,
type VARCHAR(10) NOT NULL, -- USER / ASSISTANT / SYSTEM / TOOL
`timestamp` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_conversation_id (conversation_id)
);Step 4:使用 JDBC Memory
java
@Configuration
public class PersistentMemoryConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
JdbcChatMemoryRepository jdbcRepository) {
return builder
.defaultSystem("你是机票分析师「票小蜜」")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(20)
.chatMemoryRepository(jdbcRepository) // JDBC 持久化
.build()
).build()
)
.build();
}
}现在对话记忆存在 MySQL 中,应用重启后记忆不丢失。
5.2 Redis 持久化(推荐生产环境)
Redis 读写速度远快于 MySQL,适合高频的对话记忆读写。
自定义 Redis ChatMemoryRepository:
java
@Component
public class RedisChatMemoryRepository implements ChatMemoryRepository {
private final StringRedisTemplate redisTemplate;
private final ObjectMapper objectMapper;
private static final String KEY_PREFIX = "chat:memory:";
private static final Duration TTL = Duration.ofHours(24); // 24小时过期
public RedisChatMemoryRepository(StringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
this.objectMapper = new ObjectMapper();
}
@Override
public List<Message> findByConversationId(String conversationId) {
String key = KEY_PREFIX + conversationId;
String json = redisTemplate.opsForValue().get(key);
if (json == null) return List.of();
try {
return objectMapper.readValue(json, new TypeReference<>() {});
} catch (Exception e) {
return List.of();
}
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
String key = KEY_PREFIX + conversationId;
try {
String json = objectMapper.writeValueAsString(messages);
redisTemplate.opsForValue().set(key, json, TTL);
} catch (Exception e) {
throw new RuntimeException("保存对话记忆失败", e);
}
}
@Override
public void deleteByConversationId(String conversationId) {
redisTemplate.delete(KEY_PREFIX + conversationId);
}
}
java
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
RedisChatMemoryRepository redisRepository) {
return builder
.defaultSystem("你是机票分析师「票小蜜」")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(
MessageWindowChatMemory.builder()
.maxMessages(30)
.chatMemoryRepository(redisRepository)
.build()
).build()
)
.build();
}5.3 VectorStoreChatMemoryAdvisor 实战
java
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
VectorStore vectorStore) {
return builder
.defaultSystem("你是机票分析师「票小蜜」")
.defaultAdvisors(
new VectorStoreChatMemoryAdvisor(
vectorStore,
"", // 默认 conversationId 前缀
10 // 检索最相关的 10 条历史
)
)
.build();
}5.4 关键信息固定在 System Prompt
java
@GetMapping("/chat")
public String chat(@RequestParam String q,
@RequestParam String userId) {
// 从用户配置/偏好中加载约束
UserPreference pref = userService.getPreference(userId);
String systemPrompt = """
你是机票分析师「票小蜜」。
【用户偏好 - 必须严格遵守】
- 预算上限:%d 元
- 不接受:%s
- 偏好航司:%s
- 偏好时段:%s
当前日期:%s
""".formatted(
pref.getBudget(),
pref.getExclusions(),
pref.getPreferredAirlines(),
pref.getPreferredTimeSlot(),
LocalDate.now()
);
return chatClient.prompt()
.system(systemPrompt) // 动态 System Prompt
.user(q)
.call()
.content();
}六、Checkpoint 断点恢复
说明 :Spring AI 目前没有内置
MemorySaver/Checkpoint类。但利用已有的 ChatMemory 持久化 + conversationId 机制,可以实现同样的效果------中途失败后,用同一个 threadId 恢复,Memory 中的历史消息仍在,LLM 能"接上"之前的上下文。
java
@RestController
@RequestMapping("/api/v4/agent")
public class CheckpointController {
private final ChatClient flightAgent;
public CheckpointController(@Qualifier("flightAgent") ChatClient flightAgent) {
this.flightAgent = flightAgent;
}
// 带 threadId 的对话------threadId 关联一次完整的 Agent 执行流程
@GetMapping("/chat")
public String chat(@RequestParam String q,
@RequestParam String threadId) {
return flightAgent.prompt(q)
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, threadId))
.call()
.content();
}
// 恢复执行------本质就是用同一个 threadId 继续对话
@GetMapping("/resume")
public String resume(@RequestParam String threadId,
@RequestParam(defaultValue = "请继续上次的操作") String q) {
return flightAgent.prompt(q)
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, threadId))
.call()
.content();
}
}七、与机票比价 Agent 的集成
7.1 完整配置
实际的 MemoryConfig 中,flightAgent 注入了三层 Advisor------LayeredMemoryAdvisor(用户档案 + 摘要)、MessageChatMemoryAdvisor(短期记忆)、SimpleLoggerAdvisor(日志):
java
@Configuration
public class MemoryConfig {
@Bean
public ChatMemoryRepository chatMemoryRepository() {
return new InMemoryChatMemoryRepository();
}
@Bean
public ChatMemory chatMemory(ChatMemoryRepository repository,
SummaryGenerator summaryGenerator) {
ChatMemory windowMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.chatMemoryRepository(repository)
.build();
// 装饰器:窗口裁剪时自动触发摘要压缩
return new SummarizingChatMemory(windowMemory, summaryGenerator);
}
@Bean("flightAgent")
public ChatClient flightAgent(ChatClient.Builder builder, ChatMemory chatMemory,
LayeredMemoryAdvisor layeredMemoryAdvisor) {
return builder
.defaultSystem("""
你是机票分析师「票小蜜」。
对话规则:
1. 查询机票需要三个信息:出发城市、目的城市、出发日期
2. 如果用户没有提供完整信息,主动追问
3. 用户说"明天""后天"时,基于当前日期计算
4. 记住用户之前提供的信息,不要重复追问
5. 调用工具获取真实数据,不要编造
当前日期:%s
""".formatted(LocalDate.now()))
.defaultAdvisors(
layeredMemoryAdvisor, // 第二、三层:用户档案 + 历史摘要
MessageChatMemoryAdvisor.builder(chatMemory).build(), // 第四层:短期记忆
new SimpleLoggerAdvisor()
)
.build();
}
}7.2 Controller
java
@RestController
@RequestMapping("/api/v4/flight")
public class FlightChatController {
private final ChatClient flightAgent;
private final ChatMemoryRepository repository;
public FlightChatController(@Qualifier("flightAgent") ChatClient flightAgent,
ChatMemoryRepository repository) {
this.flightAgent = flightAgent;
this.repository = repository;
}
@GetMapping("/chat")
public String chat(@RequestParam String q,
@RequestParam String sessionId) {
return flightAgent.prompt(q)
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, sessionId))
.call()
.content();
}
@GetMapping(value = "/stream", produces = "text/event-stream;charset=UTF-8")
public Flux<String> stream(@RequestParam String q,
@RequestParam String sessionId) {
return flightAgent.prompt(q)
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, sessionId))
.stream()
.content();
}
@DeleteMapping("/memory")
public String clearMemory(@RequestParam String sessionId) {
repository.deleteByConversationId(sessionId);
return "会话已清除";
}
}7.3 完整对话演示
sql
Session: user-001
第1轮
用户:我想查机票
票小蜜:好的!请告诉我以下信息:
1. 从哪个城市出发?
2. 要去哪个城市?
3. 哪天出发?
第2轮
用户:北京飞上海
票小蜜:好的,从北京飞上海。请问您想哪天出发?
第3轮
用户:明天
票小蜜:[调用 searchFlights(from=北京, to=上海, date=2026-03-14)]
为您查到 3 个北京→上海明天的航班:
| 航班号 | 航空公司 | 起飞→到达 | 价格 |
|--------|---------|----------|------|
| MU5678 | 东方航空 | 08:00→10:15 | ¥520 |
| HU7890 | 海南航空 | 17:00→19:20 | ¥550 |
| CA1234 | 中国国航 | 12:30→14:40 | ¥680 |
需要我帮您详细对比吗?
第4轮
用户:对比一下前两个
票小蜜:[调用 compareFlights([MU5678, HU7890])]
为您对比 MU5678 和 HU7890:
| 维度 | MU5678 | HU7890 |
|------|--------|--------|
| 价格 | ¥520 | ¥550 |
| 时段 | 早班 08:00 | 晚班 17:00 |
| 机型 | A320 | A330 宽体 |
推荐 MU5678,价格最低且时段合适。
第5轮
用户:那北京飞广州呢?
票小蜜:[调用 searchFlights(from=北京, to=广州, date=2026-03-14)]
为您查到 2 个北京→广州明天的航班:
...
注意:LLM 记住了"明天"这个日期,不需要用户重复说。
这就是 Memory 的作用------保持多轮对话的连贯性。7.4 架构演进图
对比上一章,本章新增了 Memory 层 (ChatMemory + 持久化)和 Checkpoint 机制 : 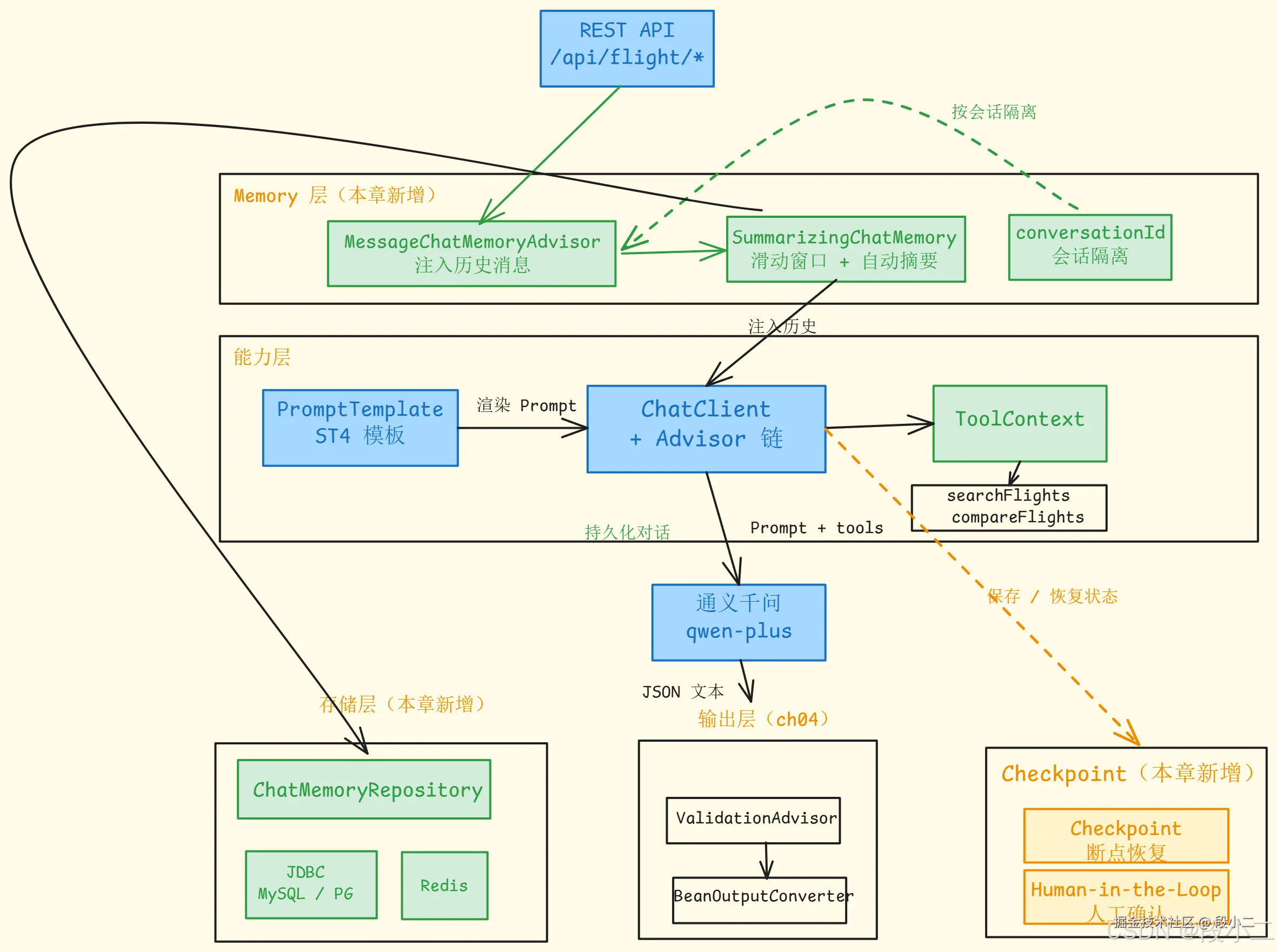
对比第 04 章:上一章在输入输出端加了 Prompt 模板和结构化输出。本章在请求管道中加入了 Memory Advisor------每次请求自动注入历史对话,让 Agent 具备了跨轮次保持状态的能力。Checkpoint 则为长链路 Agent 提供了断点恢复的基础。下一章给 Agent 接入私有知识库------RAG。
回顾一下我们到现在积累的能力:
| 章节 | 能力 | 在 Agent 中的作用 |
|---|---|---|
| 第 1 章 | ChatModel 基础调用 | Agent 的 LLM 底层通道 |
| 第 2 章 | ChatClient + Advisor 链 | Agent 的请求管道和拦截链 |
| 第 3 章 | Function Calling + ToolContext | Agent 的"手脚"------调用 Java 方法 |
| 第 4 章 | Prompt 模板 + 结构化输出 | Agent 的"语言"和"数据格式" |
| 第 5 章 | Memory + Checkpoint | Agent 的"记忆"------跨轮次保持状态 |
| 第 6 章(预告) | RAG 知识增强 | Agent 的"知识库"------基于私有数据回答 |
这一章给 Agent 加上了记忆能力。实战篇 7.2 的 FlightChatController 就是一个有记忆的机票查询 Agent------用户可以自然地分多轮提供出发地、目的地、日期,Agent 能记住前面说过的信息。下一步是让它能查阅航空公司的政策文档------这就是 RAG。
八、FAQ 与踩坑记录
Q1:使用 InMemoryChatMemory 后,不同用户的对话互相串了怎么办?
A:InMemoryChatMemory 默认所有请求共享同一个 conversationId。必须在每次请求中通过 .advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, sessionId)) 传入唯一的会话标识。常见做法是用 userId、userId + sessionId 组合、或浏览器端生成 UUID 存入 Cookie。如果不传 conversationId,所有用户的对话历史会混在一起。
Q2:应用重启后对话记忆全部丢失,如何解决?
A:InMemoryChatMemory / InMemoryChatMemoryRepository 数据存在 JVM 堆内存中,重启必然丢失。解决方案:
- 开发/测试阶段可以接受丢失,用 InMemory 即可
- 生产环境切换到 JDBC 持久化:引入
spring-ai-starter-model-chat-memory-repository-jdbc依赖,配置 MySQL/PostgreSQL 数据源 - 高频场景用 Redis:自定义
RedisChatMemoryRepository实现ChatMemoryRepository接口 - 注意:切换存储后端只需要替换
chatMemoryRepository参数,业务代码无需修改
Q3:对话轮次多了之后响应变慢、费用暴涨怎么办?
A:这是 Memory 窗口过大导致的。每轮对话都会把窗口内所有历史消息发给 LLM,历史越多 Token 消耗越大。解决方案:
- 使用
MessageWindowChatMemory设置合理的maxMessages(机票场景建议 20-30) - 使用
TokenBudgetAdvisor按实际 Token 数精确裁剪(见 4.2 小节)------不需要 Tokenizer 库,直接用 LLM 响应里的promptTokens做反馈式裁剪 - 监控每次请求的 Token 消耗(通过 TokenUsageAdvisor),发现异常及时调整窗口大小
- 对于超长对话场景,考虑分层记忆架构:短期记忆(滑动窗口)+ 历史摘要 + 关键信息固定在 System Prompt
下一章预告:RAG 三种架构
下一篇进入 Agent 的知识增强------让 LLM 基于你的私有数据回答问题:
- Two-Step RAG:经典的"检索→生成"两步架构
- Agentic RAG:LLM 自主决定何时检索、检索什么
- Hybrid RAG:查询增强 + 检索验证 + 回答验证
- Document ETL:文档加载、切分、向量化完整管道
- VectorStore 选型:SimpleVectorStore / Redis / Elasticsearch / Milvus
- 实战:航空公司政策知识库问答
聊聊你的想法
- 滑动窗口 vs Token 预算,你在项目里怎么选? MessageWindowChatMemory 简单可预测,TokenBudgetAdvisor 用 LLM 返回的 promptTokens 精确控制成本。你的场景更看重哪个?有没有窗口大小调过头导致"LLM 忘事"的经历?
- 对话记忆存哪里? InMemory 开发爽但重启丢失,JDBC 持久但慢,Redis 快但多一层运维。你的生产环境选的哪种方案?有没有用过 Redis + MySQL 双写?
- 你遇到过"LLM 忘记关键信息"的问题吗? 比如用户第一轮说了预算限制,聊了十几轮后 LLM 就忘了。你是怎么解决的------加大窗口、固定在 System Prompt、还是用向量检索?
- Checkpoint 在你的场景里有用吗? 如果 Agent 执行到一半失败了,你是让用户从头来,还是从断点恢复?实际落地过 Checkpoint 的同学聊聊体验。
本文代码 :GitHub - chat-memory 模块
如果这篇文章对你有帮助,欢迎点赞收藏。有问题欢迎评论区交流。