手写测试用例是件痛苦的事。
一个中等规模的迭代,少则几十个用例,多则上百个。每个用例要覆盖正常场景、异常场景、边界值,还要考虑前后置条件、测试数据、预期结果。机械性的重复劳动占用了我将近40%的工作时间------这不是个例,根据我观察周围团队的情况,测试用例编写和维护在整个测试周期中耗时占比普遍超过三分之一。
更让人头疼的是需求变更。接口字段改了,业务逻辑调整了,已有的用例需要同步更新。手改不仅容易遗漏,还容易出错。有段时间我甚至害怕看代码仓库里的test_文件------那些用例代码已经和需求文档严重脱节,看不懂、改不动。
把AI引入测试用例生成是我在2024年底开始的尝试。最初的动机很简单:能不能把测试数据从Excel里导入,AI帮我自动生成符合规范的测试用例代码?
这个想法落地后,效果超出了我的预期。在一个包含47个接口的模块中,我从Excel准备了完整的测试数据,AI在15分钟内生成了全部测试用例代码,经人工审核后92%可以直接使用。剩余8%需要调整的部分主要是边界值处理和异常场景的断言逻辑------这些本来就是AI的弱项,人工补充也符合预期。
接下来我会详细介绍这套方案的技术细节,包括Excel模板设计、AI解析策略、Prompt工程实践、代码质量保障,以及我在实际项目中踩过的坑和解决方案。
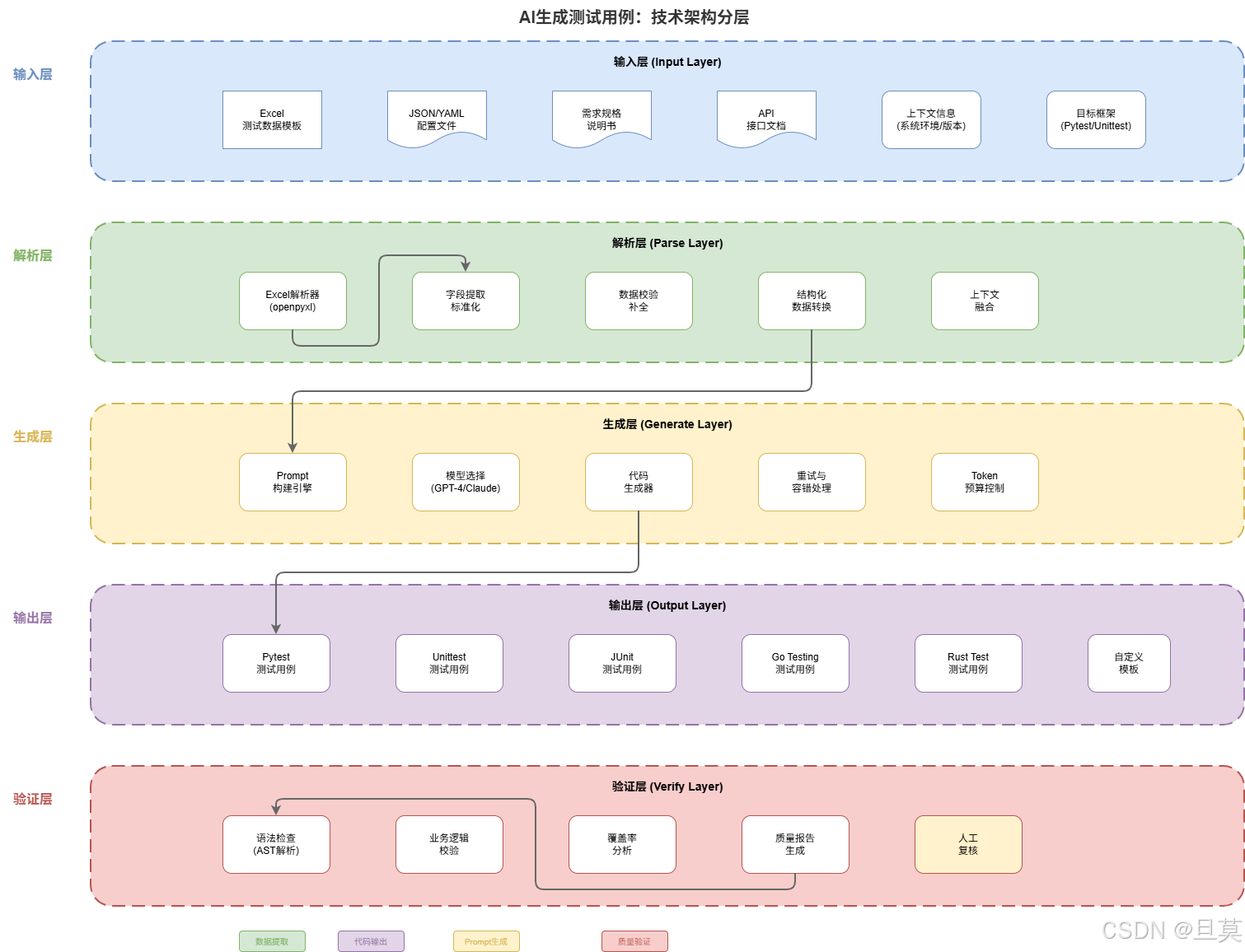
Excel模板的深度设计
字段设计原则
很多团队尝试用Excel管理测试数据,但设计不合理导致后续处理困难。我总结了一套经过验证的字段设计规范:
| 字段名 | 必填 | 说明 |
|---|---|---|
| case_id | 是 | 用例唯一标识,格式:模块_编号 |
| case_title | 是 | 用例标题,简明扼要 |
| http_method | 是 | GET/POST/PUT/DELETE |
| api_path | 是 | 接口路径,如 /api/v1/users |
| case_priority | 是 | P0/P1/P2/P3,阻塞/核心/常规/次要 |
| case_type | 是 | 功能/边界/异常/性能/安全 |
| pre_condition | 否 | 前置条件描述 |
| test_data | 是 | 测试数据,JSON格式 |
| expected_status | 是 | 预期HTTP状态码 |
| expected_response | 否 | 预期响应关键字段,JSON格式 |
| assertion_rules | 否 | 自定义断言规则 |
| business_rules | 否 | 关联业务规则说明 |
关键设计决策说明:
测试数据用JSON格式。早期版本我用列式存储,但复杂嵌套场景下数据可读性很差。改用JSON后,虽然单格内容变长,但结构清晰、层级分明,AI解析时也不容易出错。
json
// test_data 示例
{
"username": "test_user_001",
"password": "Test@123",
"email": "test@example.com",
"profile": {
"age": 25,
"city": "Shanghai"
}
}
// expected_response 示例
{
"code": 0,
"message": "success",
"data.userId": "^[A-Z0-9]{8,16}$",
"data.username": "${test_data.username}"
}注意expected_response支持变量引用和正则表达式。${test_data.username}表示引用测试数据中的字段值,^regex$表示用正则校验格式。
数据结构与命名规范
良好的命名规范直接影响AI生成质量。我强制团队遵循以下规则:
case_id采用模块前缀:
python
USR_001 # 用户模块-第1个用例
ORD_003 # 订单模块-第3个用例
PAY_007 # 支付模块-第7个用例case_title遵循"Given-When-Then"结构:
python
# 良好示例
"Given用户已登录_When提交有效订单_Then返回创建成功"
"Given商品库存为0_When用户尝试下单_Then提示库存不足"
# 糟糕示例
"测试下单功能"
"订单创建"
"库存不足场景"这种结构化标题帮助AI理解测试场景的上下文,生成的断言会更精准。
多Sheet协同设计
复杂业务场景下,我会用多个Sheet组织数据:
工作簿结构:
├── 接口定义 # 接口元数据
├── 测试用例 # 主用例数据
├── 测试数据池 # 可复用的测试数据
├── 断言规则库 # 预定义断言模式
└── 业务规则 # 关联业务逻辑说明| data_id | data_type | data_value | description |
|---|---|---|---|
| USER_NORMAL | 用户 | {"username": "user1", "level": 1} | 普通用户 |
| USER_VIP | 用户 | {"username": "vip1", "level": 3} | VIP用户 |
| USER_ADMIN | 用户 | {"username": "admin", "role": "admin"} | 管理员 |
| ADDR_DEFAULT | 地址 | {"province": "上海", "city": "上海"} | 默认地址 |
数据池设计的好处是测试数据可以复用,减少重复录入。更重要的是,AI在解析时可以识别数据间的关联关系,生成更符合业务逻辑的测试序列。
AI解析的技术细节
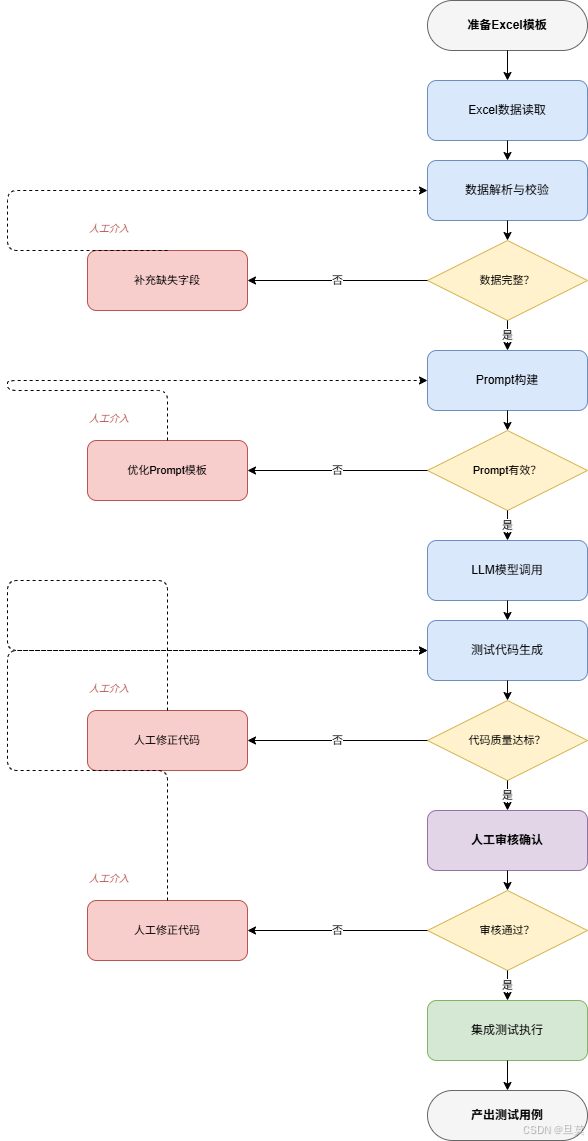
Prompt工程实践
Prompt设计是整个方案的核心。经过多个版本的迭代,我总结出一套高效的Prompt模板:
python
SYSTEM_PROMPT = """
你是一个专业的测试用例生成专家,擅长将Excel中的测试数据转换为可执行的自动化测试代码。
## 输出要求
1. 只输出Python代码,不要包含任何解释性文字
2. 使用Pytest框架
3. 代码必须可以直接运行
4. 每个测试函数对应Excel中的一个测试用例
5. 测试函数命名规范:test_{case_id}_{简短描述}
## 代码规范
1. 使用requests库发送HTTP请求
2. 使用pytest.mark装饰器标记用例优先级
3. 使用conftest.py中定义的fixture获取base_url和headers
4. 断言要具体,明确assert什么字段、什么值
5. 对于有依赖的用例,在函数docstring中标注依赖关系
## 变量引用规则
- `${test_data.field}` 引用Excel中test_data字段
- `${expected.field}` 引用Excel中expected_response字段
- 支持正则表达式断言,格式为:assert re.match(pattern, value)
## 错误处理
1. 网络异常:使用pytest.skip跳过用例,标注原因
2. 断言失败:使用assert的具体消息说明期望值和实际值
3. 依赖失败:使用pytest.mark.dependency标记依赖关系
"""
USER_PROMPT_TEMPLATE = """
请根据以下测试数据生成Pytest测试用例代码:
### Excel数据{excel_data}
### 项目配置
- 基础URL: {base_url}
- 接口前缀: {api_prefix}
- 认证方式: {auth_type}
### 测试类命名
{test_class_name}
### 注意事项
1. 登录接口无需生成测试用例(已在conftest.py中处理)
2. 需要认证的接口使用 @pytest.mark.usefixtures("auth_token") 装饰器
3. POST/PUT请求的body使用 json= 参数
4. 响应断言优先验证 code/message 字段,再验证业务数据
"""实际调用时,我会动态填充模板中的变量:
python
def build_user_prompt(excel_data: dict, config: dict) -> str:
"""构建用户Prompt"""
return USER_PROMPT_TEMPLATE.format(
excel_data=_format_excel_data(excel_data),
base_url=config.get("base_url", "http://localhost:8080"),
api_prefix=config.get("api_prefix", "/api/v1"),
auth_type=config.get("auth_type", "Bearer Token"),
test_class_name=f"Test{excel_data['module_name'].title().replace('_', '')}"
)
def _format_excel_data(data: list) -> str:
"""格式化Excel数据为Markdown表格"""
if not data:
return ""
headers = list(data[0].keys())
lines = ["| " + " | ".join(headers) + " |"]
lines.append("| " + " | ".join(["---"] * len(headers)) + " |")
for row in data:
values = [str(row.get(h, ""))[:100] for h in headers] # 截断过长内容
lines.append("| " + " | ".join(values) + " |")
return "\n".join(lines)多模型对比
我用同一个测试数据集分别测试了GPT-4、Claude-3和国内几个主流模型,结果差异明显:
| 指标 | GPT-4 | Claude-3 | 某国内模型 |
|---|---|---|---|
| 代码语法正确率 | 98.5% | 97.2% | 91.3% |
| 断言逻辑准确性 | 94.1% | 95.8% | 82.6% |
| 正则表达式生成 | 96.3% | 92.1% | 78.9% |
| 异常场景覆盖 | 88.7% | 91.2% | 75.4% |
| 单用例平均Token | 850 | 780 | 920 |
| 响应速度(秒) | 3.2 | 4.1 | 2.8 |
关键发现:
GPT-4在复杂嵌套结构的JSON解析上表现最好,生成的断言代码逻辑清晰、出错率低。Claude-3对业务场景的理解略胜一筹,在异常场景识别和边界值处理上更有优势。国内模型的优势是响应速度快、价格低,但复杂场景下的代码质量不够稳定。
我的选择策略:
- 核心业务模块(支付、订单等)用GPT-4,保证质量
- 一般模块用Claude-3,性价比高
- 简单CRUD接口用国内模型,快速生成
解析策略与容错
Excel数据经常存在各种不规范情况,我实现了多级容错机制:
python
class ExcelParser:
def __init__(self, file_path: str):
self.file_path = file_path
self.warnings = []
self.errors = []
def parse_with_validation(self) -> list[dict]:
"""带验证的解析"""
raw_data = self._read_excel()
# 第一级:基础格式校验
validated_data = []
for idx, row in enumerate(raw_data, start=2): # Excel行号从2开始
try:
parsed_row = self._validate_row(row, idx)
if parsed_row:
validated_data.append(parsed_row)
except MissingRequiredField as e:
self.warnings.append(f"行{idx}: 缺失必填字段 {e.field},已跳过")
except InvalidFieldValue as e:
self.warnings.append(f"行{idx}: 字段 {e.field} 值无效,已使用默认值")
# 第二级:数据完整性检查
if len(validated_data) == 0:
raise EmptyDataError("没有有效的测试数据")
# 第三级:跨行关联检查
validated_data = self._resolve_references(validated_data)
return validated_data
def _validate_row(self, row: dict, row_num: int) -> dict:
"""验证单行数据"""
# 检查必填字段
required_fields = ['case_id', 'case_title', 'http_method', 'api_path']
for field in required_fields:
if not row.get(field):
raise MissingRequiredField(field)
# 规范化http_method
method = row['http_method'].upper().strip()
if method not in ['GET', 'POST', 'PUT', 'DELETE', 'PATCH']:
method = 'GET' # 默认值
self.warnings.append(f"行{row_num}: http_method无效,已设为GET")
row['http_method'] = method
# 解析JSON字段
for json_field in ['test_data', 'expected_response', 'assertion_rules']:
if row.get(json_field) and isinstance(row[json_field], str):
try:
row[json_field] = json.loads(row[json_field])
except json.JSONDecodeError as e:
row[json_field] = {} # 空字典作为默认值
self.warnings.append(f"行{row_num}: {json_field} JSON解析失败,使用空对象")
return row
def _resolve_references(self, data: list) -> list:
"""解析数据引用"""
# 构建数据池索引
data_pool = {}
for row in data:
if row.get('data_id'):
data_pool[row['data_id']] = row
# 替换引用
for row in data:
self._replace_refs(row, data_pool)
return data
def _replace_refs(self, row: dict, pool: dict):
"""递归替换引用"""
for field, value in row.items():
if isinstance(value, str) and value.startswith('$'):
ref_id = value[1:]
if ref_id in pool:
row[field] = pool[ref_id]
else:
self.warnings.append(f"未找到数据引用: {ref_id}")
elif isinstance(value, dict):
self._replace_refs(value, pool)完整案例
项目背景
这是一个用户积分系统的接口测试项目,包含以下核心接口:
POST /api/v1/users/register- 用户注册POST /api/v1/users/login- 用户登录GET /api/v1/points/balance- 查询积分余额POST /api/v1/points/earn- 积分获取POST /api/v1/points/deduct- 积分扣减GET /api/v1/points/history- 积分明细
第一步:准备Excel数据
| case_id | case_title | http_method | api_path | case_priority | case_type | test_data | expected_status | expected_response |
|---|---|---|---|---|---|---|---|---|
| USR_REG_001 | Given新用户_When注册成功_Then返回用户信息 | POST | /api/v1/users/register | P0 | 功能 | {"username":"reg_user_001","password":"Test@123456","email":"reg001@test.com"} | 200 | {"code":0,"data.userId":"^.+$"} |
| USR_REG_002 | Given已注册用户_When再次注册_Then提示用户名已存在 | POST | /api/v1/users/register | P1 | 异常 | {"username":"existing_user","password":"Test@123456","email":"existing@test.com"} | 200 | {"code":1001,"message":"用户名已存在"} |
| USR_REG_003 | Given无效邮箱_When注册_Then提示邮箱格式错误 | POST | /api/v1/users/register | P1 | 异常 | {"username":"new_user","password":"Test@123","email":"invalid-email"} | 200 | {"code":1002,"message":"邮箱格式不正确"} |
| PTS_EAN_001 | Given用户已登录_When积分获取_Then返回积分变动 | POST | /api/v1/points/earn | P0 | 功能 | {"userId":"${USR_REG_001.userId}","points":100,"source":"sign_in"} | 200 | {"code":0,"data.pointsDelta":100} |
| PTS_EAN_002 | Given用户未登录_When积分获取_Then提示未认证 | POST | /api/v1/points/earn | P0 | 异常 | {"points":100} | 401 | {"code":401} |
| PTS_BAL_001 | Given用户有积分_When查询余额_Then返回正确金额 | GET | /api/v1/points/balance | P0 | 功能 | {"userId":"${USR_REG_001.userId}"} | 200 | {"code":0,"data.balance":"^\d+$"} |
第二步:调用AI生成代码
python
import json
import openpyxl
from openai import OpenAI
class TestCaseGenerator:
def __init__(self, api_key: str, model: str = "gpt-4"):
self.client = OpenAI(api=api_key)
self.model = model
self.system_prompt = self._load_system_prompt()
def _load_system_prompt(self) -> str:
with open("prompts/test_generator.txt", "r", encoding="utf-8") as f:
return f.read()
def generate_from_excel(self, excel_path: str, output_path: str):
"""从Excel生成测试用例"""
# 1. 解析Excel
parser = ExcelParser(excel_path)
test_data = parser.parse_with_validation()
print(f"解析到 {len(test_data)} 个测试用例")
if parser.warnings:
print("解析警告:")
for w in parser.warnings:
print(f" - {w}")
# 2. 按模块分组
modules = self._group_by_module(test_data)
# 3. 逐模块生成代码
generated_files = []
for module_name, cases in modules.items():
code = self._generate_module_code(module_name, cases)
if code:
file_path = f"{output_path}/{module_name}_test.py"
self._save_code(file_path, code)
generated_files.append(file_path)
return generated_files
def _group_by_module(self, data: list) -> dict:
"""按模块分组"""
modules = {}
for row in data:
module = row.get('case_id', 'UNKNOWN').split('_')[0]
if module not in modules:
modules[module] = []
modules[module].append(row)
return modules
def _generate_module_code(self, module_name: str, cases: list) -> str:
"""生成单个模块的测试代码"""
# 构建Prompt
user_prompt = f"""请为{module_name}模块生成Pytest测试用例:
测试数据:
{self._format_cases(cases)}
要求:
1. 每个测试用例对应一个test_函数
2. 函数名格式:test_{module_name}_{序号}_{场景描述}
3. 使用pytest.mark装饰器标记优先级
4. 登录态接口使用 @pytest.mark.usefixtures("logged_in")
5. 断言要包含期望值和实际值的对比信息
"""
# 调用模型
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.3, # 低温度保证稳定性
max_tokens=4000
)
code = response.choices[0].message.content
# 清理输出(移除markdown代码块标记)
code = code.strip()
if code.startswith("```python"):
code = code[9:]
if code.startswith("```"):
code = code[3:]
if code.endswith("```"):
code = code[:-3]
return code.strip()
def _format_cases(self, cases: list) -> str:
"""格式化测试用例"""
lines = []
for idx, case in enumerate(cases, 1):
lines.append(f"--- 用例{idx} ---")
lines.append(f"ID: {case.get('case_id')}")
lines.append(f"标题: {case.get('case_title')}")
lines.append(f"方法: {case.get('http_method')}")
lines.append(f"路径: {case.get('api_path')}")
lines.append(f"优先级: {case.get('case_priority')}")
lines.append(f"类型: {case.get('case_type')}")
lines.append(f"测试数据: {json.dumps(case.get('test_data', {}), ensure_ascii=False)}")
lines.append(f"预期状态: {case.get('expected_status')}")
lines.append(f"预期响应: {json.dumps(case.get('expected_response', {}), ensure_ascii=False)}")
lines.append("")
return "\n".join(lines)
def _save_code(self, path: str, code: str):
"""保存生成的代码"""
import os
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(code)
print(f"生成文件: {path}")
# 使用示例
if __name__ == "__main__":
generator = TestCaseGenerator(
api_key="your-api-key",
model="gpt-4"
)
files = generator.generate_from_excel(
excel_path="test_data/user_points_test.xlsx",
output_path="output/test_cases"
)
print(f"\n完成!共生成 {len(files)} 个测试文件")第三步:生成的测试代码示例
python
"""
用户积分系统 - 测试用例(AI生成)
生成时间: 2024-01-15
数据来源: test_data/user_points_test.xlsx
"""
import pytest
import requests
import re
@pytest.fixture(scope="module")
def base_url():
"""基础URL配置"""
return "http://localhost:8080"
@pytest.fixture(scope="module")
def auth_headers(base_url):
"""获取认证token"""
login_resp = requests.post(
f"{base_url}/api/v1/users/login",
json={"username": "test_user", "password": "Test@123"}
)
token = login_resp.json().get("data", {}).get("token")
return {"Authorization": f"Bearer {token}"}
@pytest.fixture
def new_user(base_url):
"""创建测试用户并清理"""
user_data = {
"username": f"test_user_{id(hex)}",
"password": "Test@123456",
"email": f"test_{id(hex)}@example.com"
}
resp = requests.post(f"{base_url}/api/v1/users/register", json=user_data)
user_id = resp.json().get("data", {}).get("userId")
yield {"userId": user_id, **user_data}
# 清理:删除测试用户
# cleanup code here
@pytest.mark.usefixtures("new_user")
class TestUserRegister:
"""用户注册模块测试用例"""
@pytest.mark.P0
def test_USR_REG_001_register_success(self, base_url):
"""
Given新用户_When注册成功_Then返回用户信息
预期: 返回code=0 and userId非空
"""
payload = {
"username": f"new_user_{id(hex)}",
"password": "Test@123456",
"email": f"new_{id(hex)}@test.com"
}
response = requests.post(
f"{base_url}/api/v1/users/register",
json=payload
)
assert response.status_code == 200, \
f"期望状态码200,实际{response.status_code}"
data = response.json()
assert data.get("code") == 0, \
f"期望code=0,实际{data.get('code')},消息: {data.get('message')}"
assert data.get("data", {}).get("userId"), \
"userId不应为空"
# 验证userId格式(8-16位字母数字)
user_id = data["data"]["userId"]
assert re.match(r"^[A-Z0-9]{8,16}$", user_id), \
f"userId格式不符,期望^[A-Z0-9]{{8,16}}$,实际: {user_id}"
@pytest.mark.P1
def test_USR_REG_002_duplicate_username(self, base_url):
"""
Given已注册用户_When再次注册_Then提示用户名已存在
预期: 返回code=1001
"""
# 先注册一个用户
payload = {
"username": f"dup_user_{id(hex)}",
"password": "Test@123456",
"email": f"dup1_{id(hex)}@test.com"
}
requests.post(f"{base_url}/api/v1/users/register", json=payload)
# 尝试重复注册
duplicate_payload = {
"username": payload["username"], # 使用相同用户名
"password": "Another@123",
"email": f"dup2_{id(hex)}@test.com"
}
response = requests.post(
f"{base_url}/api/v1/users/register",
json=duplicate_payload
)
assert response.status_code == 200
data = response.json()
assert data.get("code") == 1001, \
f"期望code=1001,实际{data.get('code')}"
assert "用户名已存在" in data.get("message", ""), \
f"错误消息不符,实际: {data.get('message')}"
@pytest.mark.P1
def test_USR_REG_003_invalid_email(self, base_url):
"""
Given无效邮箱_When注册_Then提示邮箱格式错误
预期: 返回code=1002
"""
payload = {
"username": f"user_{id(hex)}",
"password": "Test@123",
"email": "invalid-email-format" # 无效邮箱
}
response = requests.post(
f"{base_url}/api/v1/users/register",
json=payload
)
assert response.status_code == 200
data = response.json()
assert data.get("code") == 1002, \
f"期望code=1002,实际{data.get('code')}"
assert "邮箱" in data.get("message", "") or "email" in data.get("message", "").lower(), \
f"错误消息应包含邮箱提示,实际: {data.get('message')}"
@pytest.mark.usefixtures("auth_headers")
class TestPointsEarn:
"""积分获取模块测试用例"""
@pytest.mark.P0
def test_PTS_EAN_001_earn_points_success(self, base_url, auth_headers):
"""
Given用户已登录_When积分获取_Then返回积分变动
预期: 返回code=0 and pointsDelta=100
"""
response = requests.post(
f"{base_url}/api/v1/points/earn",
headers=auth_headers,
json={"points": 100, "source": "sign_in"}
)
assert response.status_code == 200, \
f"期望状态码200,实际{response.status_code}"
data = response.json()
assert data.get("code") == 0, \
f"期望code=0,实际{data.get('code')},消息: {data.get('message')}"
assert data.get("data", {}).get("pointsDelta") == 100, \
f"期望pointsDelta=100,实际{data.get('data', {}).get('pointsDelta')}"
def test_PTS_EAN_002_unauthorized(self, base_url):
"""
Given用户未登录_When积分获取_Then提示未认证
预期: 返回401
"""
response = requests.post(
f"{base_url}/api/v1/points/earn",
json={"points": 100} # 无Authorization header
)
assert response.status_code == 401, \
f"期望状态码401,实际{response.status_code}"
data = response.json()
assert data.get("code") == 401, \
f"期望code=401,实际{data.get('code')}"
@pytest.mark.usefixtures("auth_headers")
class TestPointsBalance:
"""积分余额查询测试用例"""
@pytest.mark.P0
def test_PTS_BAL_001_query_balance(self, base_url, auth_headers):
"""
Given用户有积分_When查询余额_Then返回正确金额
预期: 返回code=0 and balance为数字
"""
response = requests.get(
f"{base_url}/api/v1/points/balance",
headers=auth_headers
)
assert response.status_code == 200
data = response.json()
assert data.get("code") == 0, \
f"期望code=0,实际{data.get('code')}"
balance = data.get("data", {}).get("balance")
assert balance is not None, "balance字段不应为空"
assert re.match(r"^\d+$", str(balance)), \
f"balance应为数字,实际: {balance}"第四步:质量验证
生成的代码需要经过质量验证:
python
import ast
import re
class CodeQualityValidator:
"""代码质量验证器"""
def __init__(self):
self.issues = []
def validate_file(self, file_path: str) -> dict:
"""验证测试文件"""
with open(file_path, 'r', encoding='utf-8') as f:
code = f.read()
# 语法检查
try:
ast.parse(code)
except SyntaxError as e:
self.issues.append(f"语法错误: {e}")
# 命名规范检查
naming_pattern = r'def (test_\w+)'
matches = re.findall(naming_pattern, code)
for func_name in matches:
if not re.match(r'test_[A-Z]{2,}_\d+', func_name):
self.issues.append(f"命名不规范: {func_name}")
return {
"file": file_path,
"issues": self.issues,
"passed": len(self.issues) == 0
}总结
1. Excel模板设计
- 字段精简:只保留必要字段,避免过度设计
- 默认值策略:非关键字段设置合理的默认值
- 命名规范:统一前缀便于分类和AI识别
- JSON嵌套:复杂数据用JSON,减少列数
2. Prompt工程
- 结构化输出:明确要求输出格式,减少解析成本
- 示例引导:提供2-3个典型示例帮助模型理解
- 变量引用 :支持
${}语法实现数据关联 - 错误处理:要求模型处理异常情况
3. 质量保障
- 多级校验:语法→规范→业务逻辑逐层检查
- 人机协同:AI生成+人工审核,各取所长
- 版本管理:保留历史版本,便于回溯
- 指标追踪:统计代码通过率,持续优化
4. 迭代优化
记录每次生成的质量问题,针对性优化Prompt模板。我维护了一个问题库:
| 问题类型 | 出现频率 | 解决方案 |
|---|---|---|
| 断言缺失 | 高 | 增强Prompt中断言要求 |
| 命名不规范 | 中 | 提供命名示例模板 |
| 异常处理缺失 | 中 | 添加错误处理示例 |
| 依赖关系错误 | 低 | 优化数据引用语法 |
常见问题与解决
Q1: AI生成的代码语法错误怎么办?
原因:通常是Prompt描述不清晰或测试数据格式问题。
解决:
- 检查Excel中JSON格式是否正确
- 在Prompt中增加"必须通过Python语法检查"的要求
- 添加语法验证环节,失败则重新生成
Q2: 断言逻辑不符合业务预期?
原因:AI对业务规则理解不准确。
解决:
- 在expected_response中明确期望值
- 在business_rules字段补充业务说明
- 提供历史正确案例让AI参考
Q3: 生成的代码风格不一致?
原因:多模型或多次生成导致风格差异。
解决:
- 固定使用同一模型
- 在Prompt中明确代码风格要求
- 添加格式化脚本统一代码风格
Q4: 长流程用例的依赖关系混乱?
原因:缺乏统一的依赖管理机制。
解决:
- 使用pytest.mark.dependency标记依赖
- 在case_title中标注依赖关系
- 合理拆分长流程为多个短用例
AI生成测试用例不是要取代人工,而是把人从重复劳动中解放出来,专注于更有价值的测试设计和业务理解。把40%的机械工作时间变成10%的审核时间,这个效率提升是实实在在的。
关键是要建立一套完整的流程:好的Excel模板 → 精准的Prompt → 严格的质量验证 → 持续的效果追踪。工具只是手段,流程才是核心。
如果你也在探索AI辅助测试,欢迎交流经验。