Prompt 工程与结构化输出:让 LLM 返回可用的 Java 对象(Java 架构师的 AI 工程笔记 04)
这是系列的第四篇,聊聊 Prompt 怎么写才能让 LLM 输出你真正能用的数据。 上一篇让 LLM 长出了"手脚"------通过 Function Calling 调用 Java 方法查真实数据。但不管是工具的 System Prompt 还是查询结果,都存在一个问题:LLM 的输出格式不可控。这一篇聚焦两件事:怎么写好 Prompt,怎么让 LLM 的输出直接变成 Java 对象。
前置知识:需要读完第三篇《Function Calling 实战:让 LLM 调用 Java 方法查真实数据》,理解工具调用的基本流程和 ToolContext 机制。
本篇速览 :这篇讲 Prompt 工程的四个设计原则、PromptTemplate 模板引擎(ST4)的源码机制、Few-shot 技巧,以及 BeanOutputConverter 如何把 LLM 的文本输出自动映射为 Java 对象。学完你能用 .entity(FlightSearchResult.class) 一行代码拿到结构化的航班数据。
最终效果预览:
bash
curl "http://localhost:8083/api/prompt/structured?q=北京到上海明天的机票"
json
{
"query": "北京到上海明天的机票",
"flights": [
{"flightNo": "MU5678", "airline": "东方航空", "departure": "北京", "arrival": "上海", "departureTime": "08:00", "arrivalTime": "10:15", "price": 520},
{"flightNo": "CA1234", "airline": "中国国航", "departure": "北京", "arrival": "上海", "departureTime": "12:30", "arrivalTime": "14:40", "price": 680}
],
"cheapest": {"flightNo": "MU5678", "price": 520},
"summary": "共找到 2 个航班,最低价 520 元(东方航空 MU5678)"
}LLM 返回的不再是一坨文本,而是可以直接用的 Java 对象。
理论篇
一、从"LLM 不听话"说起
上一篇的最后,我们用 chatClient.prompt(q).call().content() 拿到了 LLM 的回复。但你有没有发现一个问题------LLM 的回答格式完全不可控。
同样问"北京到上海的机票",它有时候给你一段话,有时候给你一个 markdown 表格,偶尔还要加一句"希望对您有帮助"。如果下游代码要解析这个结果,直接崩溃。
这引出两个现实问题:
- 怎么让 LLM "听话"------按你期望的方式回答?这就是 Prompt 工程。
- 怎么让 LLM 的输出直接变成 Java 对象------不用手动解析 JSON?这就是结构化输出。
想一想:假设你要把 LLM 返回的航班信息存到数据库,你会怎么处理 LLM 那段自由格式的文本?正则匹配?JSON.parse?如果 LLM 某次多打了一个逗号呢?
用 Java 工程师熟悉的类比------Prompt 工程就像写 SQL 查询:SQL 写得好,数据库返回的结果精准;SQL 写得烂,要么结果不对,要么全表扫描。Prompt 写得好,LLM 给你精准的结构化数据;Prompt 写得烂,LLM 给你一篇散文。
二、Prompt 设计四原则
2.1 System Message 写规则,User Message 写任务
LLM 对 system 角色的消息有特殊处理------它被视为"不可违反的指令",权重高于 user 消息。这跟 Java 里的类级别注解 vs 方法级别注解类似:类级别定义全局规则,方法级别定义具体行为。
sql
差:全部塞在 User Message
"你是票小蜜,只回答机票问题,用中文回答,查北京到上海的机票"
好:分层放置
System: "你是机票分析师「票小蜜」。只处理机票相关问题,无关问题礼貌拒绝。回答语言:中文。"
User: "查北京到上海明天的机票,按价格排序"为什么好?System 定义"不变的规则",User 传递"变化的请求" ------跟 @Configuration 配置全局行为、@RequestParam 接收请求参数一个道理。
2.2 给约束条件,不给模糊形容
LLM 按概率预测下一个 Token。模糊描述("回答要详细")会激活多种 Token 分布;具体约束("列出前 5 个最便宜的航班,包含航班号、时间、价格")会把 Token 分布收窄到你想要的模式。
| 模糊 | 具体 | 为什么好 |
|---|---|---|
| "详细回答" | "包含航班号、起飞时间、价格三个字段" | 模型知道该输出哪些字段 |
| "简短回答" | "回答限制在 50 字以内" | 模型有明确的长度目标 |
| "专业一点" | "使用 IATA 航空公司代码(如 CA=国航)" | 模型知道"专业"的具体含义 |
| "不要瞎编" | "如果数据库中没有该航线,回复:暂无此航线数据" | 模型知道"不编"时该说什么 |
2.3 注入运行时上下文
LLM 没有"当前时间"概念,也不知道用户是谁。这些运行时信息必须你来注入------就像给 PreparedStatement 填参数:
java
Map.of(
"date", LocalDate.now().toString(), // 当前日期------否则 LLM 不知道"明天"是哪天
"userId", user.getId(), // 用户身份------后续 Agent 需要
"history", recentSearches // 用户最近搜索------个性化推荐
)2.4 结构化输出配合低 temperature
BeanOutputConverter 会把 JSON Schema 拼到 Prompt 末尾------本质是一种 Prompt 级别的格式约束。但 LLM 仍然可能"跑偏"------temperature 越高,Token 采样的随机性越大,越容易生成不合格的 JSON。
💡 开发建议 :结构化输出场景把 temperature 设为 0~0.3。我实测
qwen-plus+temperature: 0.3的格式合规率在 98% 以上;temperature: 0.9时掉到 85% 左右。
三、Prompt 工程全景图
在深入细节之前,先看 Prompt 从编写到生效的完整流程:
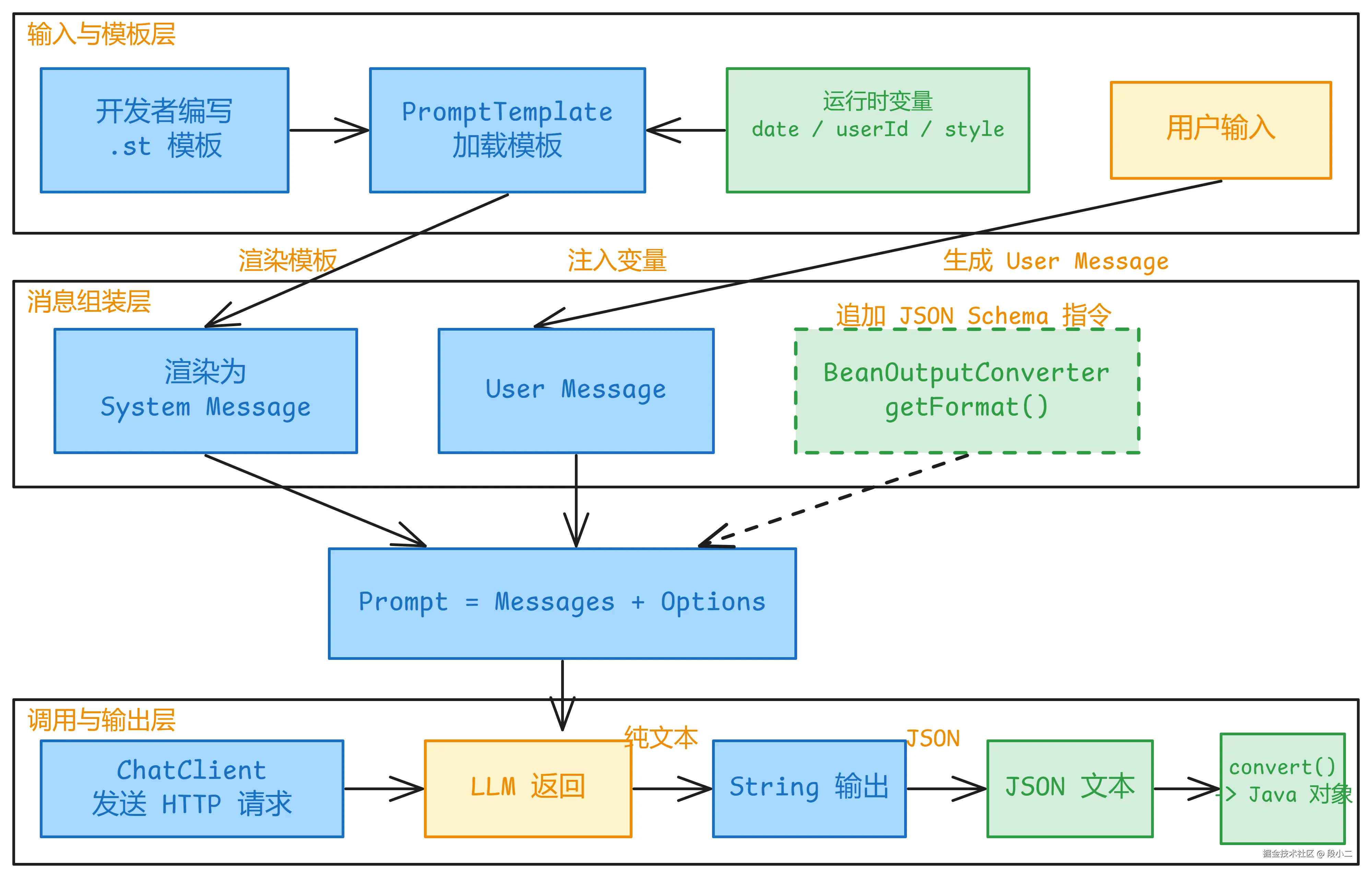
这张图串起了本章的所有知识点:模板渲染(第四节)、Few-shot(第五节)、结构化输出(第六节)。接下来逐个拆解。
四、PromptTemplate------先看怎么用,再看源码怎么实现
手动拼接 Prompt 的问题很明显:
java
// 硬编码------每次改 Prompt 都要改代码、重新部署
String prompt = "查询从" + from + "到" + to + "的" + date + "的机票";这跟直接拼 SQL 一样危险且难维护。Spring AI 的 PromptTemplate 就是 Prompt 世界的 PreparedStatement。
4.1 先看用法------三种典型场景
场景一:内联模板 + 变量替换
java
String template = """
你是一个机票查询助手。请根据以下信息查询机票:
- 出发城市:{from}
- 目的城市:{to}
- 出发日期:{date}
请列出 3 个推荐航班,包含航班号、起飞时间、价格。
""";
PromptTemplate promptTemplate = new PromptTemplate(template);
Prompt prompt = promptTemplate.create(Map.of(
"from", "北京",
"to", "上海",
"date", "2025-07-01"
));
chatClient.prompt(prompt).call().content();变量用 {from} 花括号语法,按名称替换,不怕参数顺序搞错。
场景二:从外部 .st 文件加载模板
java
// 模板文件:resources/prompts/flight-analyst.st
PromptTemplate systemTemplate = new PromptTemplate(
new ClassPathResource("prompts/flight-analyst.st")
);
String systemPrompt = systemTemplate.render(Map.of(
"style", "严谨",
"date", LocalDate.now().toString()
));模板放在文件里,改 Prompt 不用改 Java 代码。这是生产环境的常见做法。
场景三:Few-shot 模板
java
String fewShotPrompt = """
你是机票查询助手。请严格按以下示例格式回答:
【示例 1】
用户:北京到上海明天的机票
助手:为您查询到以下航班:
| 航班号 | 起飞 | 到达 | 价格 |
|--------|------|------|------|
| CA1234 | 08:00 | 10:15 | ¥680 |
【示例 2】
用户:广州到深圳的高铁
助手:抱歉,我只能查询机票信息。您是否需要查询广州到深圳的机票?
---
现在请回答:
用户:{question}
""";
PromptTemplate promptTemplate = new PromptTemplate(fewShotPrompt);
Prompt prompt = promptTemplate.create(Map.of("question", q));三个场景看下来,PromptTemplate 的用法很直觉:写模板 → 填变量 → 渲染。那它底层是怎么做到的?
4.2 再看源码------ST4 引擎
翻了下 PromptTemplate 的源码,它底层用的是 **StringTemplate 4(ST4)**引擎:
java
// PromptTemplate 源码结构(简化)
public class PromptTemplate {
private String template;
private final TemplateRenderer renderer; // 默认是 StTemplateRenderer
public String render(Map<String, Object> variables) {
return this.renderer.apply(this.template, variables); // 委托给 ST4
}
}
// StTemplateRenderer 内部用 ST4 引擎做模板渲染
public class StTemplateRenderer implements TemplateRenderer {
public String apply(String template, Map<String, Object> variables) {
ST st = createST(template); // 创建 StringTemplate 实例
variables.forEach(st::add); // 注入变量
return st.render(); // 渲染
}
}流程很清楚:PromptTemplate.render() → 委托给 StTemplateRenderer → 创建 ST4 模板实例 → 注入变量 → 渲染输出。
为什么用 ST4 而不是 String.format()?
| 能力 | String.format | PromptTemplate (ST4) |
|---|---|---|
| 变量替换 | %s 按顺序 |
{name} 按名称,不怕顺序错 |
| 条件逻辑 | 不支持 | {if(vip)}尊贵用户{endif} |
| 外部文件 | 不支持 | new PromptTemplate(new ClassPathResource("prompts/xxx.st")) |
| 模板校验 | 无 | 渲染时校验变量是否都提供了 |
| Spring 集成 | 无 | 支持 Resource、@Value 注入 |
⚠️ 踩坑提醒 :ST4 的变量语法是
{variable}(花括号,不带$)。如果你写了${variable},ST4 会把$当普通字符,变量替换静默失效------不报错、不替换,非常隐蔽。这跟 Spring 的@Value("${...}")语法不同,别搞混了。
五、Few-shot------用例子"教"LLM 输出格式
Zero-shot 是什么都不给,直接问。LLM 会回答,但格式、风格、详细程度全看它心情。
Few-shot 是在 Prompt 里给几个"示范",让 LLM 照着来。这利用了 LLM 的一个核心能力------In-Context Learning(上下文学习):LLM 能从你给的几个例子中"学会"输出模式,无需重新训练。
| 维度 | Zero-shot | Few-shot |
|---|---|---|
| Token 消耗 | 少 | 多(每个例子都占 Token) |
| 输出格式可控性 | 低,靠运气 | 高,LLM 会模仿示例格式 |
| 适用场景 | 简单问答、闲聊 | 需要固定格式、特定风格的输出 |
| 边界情况处理 | 差 | 可以用示例教 LLM 怎么拒绝 |
实用原则:
- 给 2-3 个示例就够,太多浪费 Token 且效果不会更好
- 示例要覆盖正常情况 和边界情况(比如用户问了机票以外的问题,怎么拒绝)
- 示例的格式就是你期望的输出格式------LLM 是"照猫画虎"
- 如果用了
.entity()结构化输出,JSON Schema 本身就是格式示范,通常不再需要 Few-shot
Few-shot vs .entity() 怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 输出是标准 JSON,下游代码直接消费 | .entity() |
JSON Schema 约束更严格,自动反序列化 |
| 输出是 markdown 表格/特定文本格式 | Few-shot | Schema 管不了文本格式,只有示例能教 |
| LLM 总是在 JSON 里加多余字段 | 两者混用 | Schema 定义结构,Few-shot 教"只输出这些字段" |
| 边界情况处理(拒绝、兜底话术) | Few-shot | Schema 无法表达"如果查不到该说什么" |
实际项目中两者混用的场景比想象中多------.entity() 管数据结构,Few-shot 管"语气"和"边界行为"。比如机票 Agent 中,我用 .entity(FlightSearchResult.class) 保证返回结构,同时在 System Prompt 的 Few-shot 部分教 LLM "查不到航班时返回空数组而不是编造数据"。
示例怎么维护?
Few-shot 示例本质是 Prompt 的一部分,跟 Prompt 一样有版本管理问题。我的做法是把示例放在 .st 模板文件里,跟 System Prompt 模板一起管理。好处是改示例不用改 Java 代码,坏处是示例多了模板文件会很长。如果示例超过 5 个,考虑用动态加载------根据用户输入的类型,只注入最相关的 2-3 个示例,避免浪费 Token。
六、BeanOutputConverter------先看一行代码的魔法,再拆源码
6.1 先看用法------一行代码拿到 Java 对象
结构化输出最简单的写法就一行:
java
FlightSearchResult result = chatClient.prompt()
.system("你是机票查询助手。只输出纯 JSON,不要任何额外文字。")
.user("北京到上海明天的机票")
.call()
.entity(FlightSearchResult.class); // 关键:LLM 输出的文本直接变成 Java 对象.entity(FlightSearchResult.class) 做了什么?它让 LLM 知道"你需要输出这种格式的 JSON",然后自动把 LLM 返回的 JSON 字符串反序列化成 Java 对象。不用手动解析,不用正则匹配。
如果返回的是列表,用 ParameterizedTypeReference:
java
List<FlightInfo> flights = chatClient.prompt()
.system("你是机票查询助手。只输出 JSON 数组。")
.user("列出 5 个热门航线")
.call()
.entity(new ParameterizedTypeReference<>() {});看起来像魔法------传一个 Class 进去,出来就是对象。那它底层到底怎么做到的?
6.2 再看源码------三步拆解
如果你用过 Jackson 的 ObjectMapper.readValue(json, MyClass.class),BeanOutputConverter 做的事情类似------只不过它还负责告诉 LLM 应该输出什么格式。
可以把它理解为 Jackson ObjectMapper + JSON Schema 生成器 + Prompt 注入器 三合一。
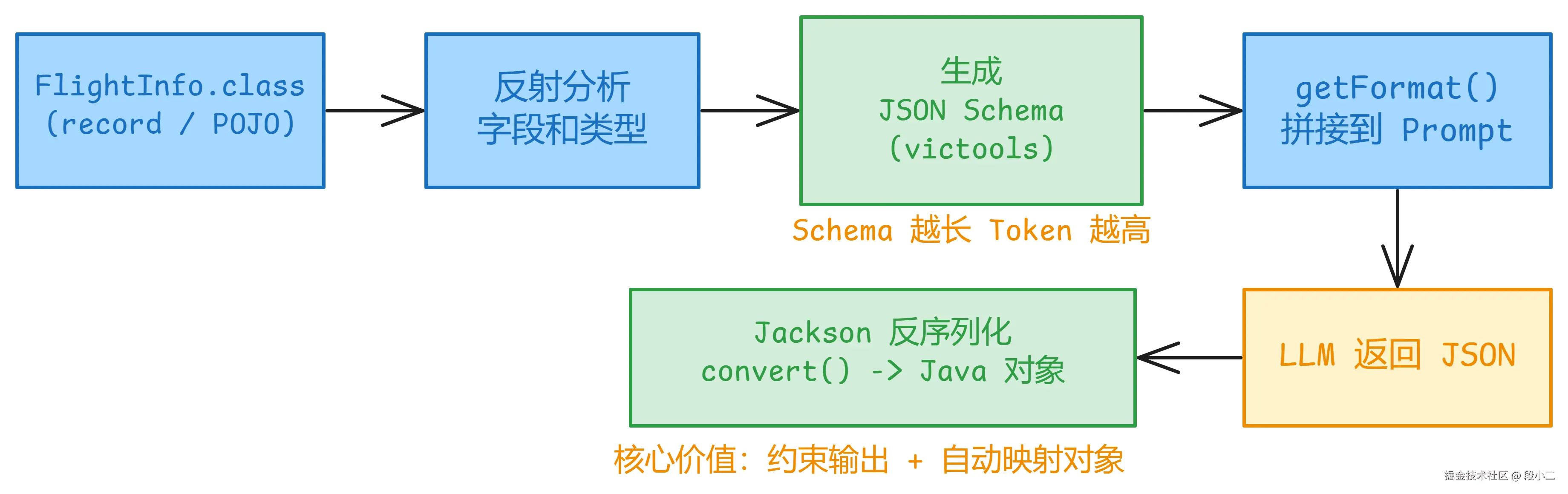 当你写
当你写 .entity(FlightInfo.class) 时,背后发生了三件事。
第一步:生成 JSON Schema
构造函数中调用 generateSchema(),用的是 victools/jsonschema-generator 库(不是 Jackson 自带的):
java
// BeanOutputConverter.generateSchema() 源码简化
private void generateSchema() {
JacksonModule jacksonModule = new JacksonModule(
RESPECT_JSONPROPERTY_REQUIRED, RESPECT_JSONPROPERTY_ORDER);
SchemaGeneratorConfig config = new SchemaGeneratorConfigBuilder(
SchemaVersion.DRAFT_2020_12, // JSON Schema 2020-12 标准
OptionPreset.PLAIN_JSON)
.with(jacksonModule)
.build();
SchemaGenerator generator = new SchemaGenerator(config);
ObjectNode schema = generator.generateSchema(this.type); // 反射分析 Java 类
this.jsonSchema = objectMapper.writeValueAsString(schema);
}对于我们的 FlightSearchResult record,生成的完整 Schema 如下(这不是简化版,就是真实生成的):
json
{
"type" : "object",
"properties" : {
"query" : { "type" : "string" },
"flights" : {
"type" : "array",
"items" : {
"type" : "object",
"properties" : {
"flightNo" : { "type" : "string" },
"airline" : { "type" : "string" },
"departure" : { "type" : "string" },
"arrival" : { "type" : "string" },
"departureTime" : { "type" : "string" },
"arrivalTime" : { "type" : "string" },
"price" : { "type" : "integer" }
}
}
},
"cheapest" : {
"type" : "object",
"properties" : {
"flightNo" : { "type" : "string" },
"airline" : { "type" : "string" },
"departure" : { "type" : "string" },
"arrival" : { "type" : "string" },
"departureTime" : { "type" : "string" },
"arrivalTime" : { "type" : "string" },
"price" : { "type" : "integer" }
}
},
"summary" : { "type" : "string" }
}
}你可能已经注意到------光这个 Schema 就有 30 多行 。这就是 BeanOutputConverter 的 Token 开销来源:嵌套越深、字段越多,Schema 越长,每次请求都要为"格式指令"付 Token 费。
第二步:拼接到 Prompt
getFormat() 方法返回一段固定的英文指令 + Schema,追加到 User Prompt 后面。我实际打印了一下,LLM 最终收到的 Prompt 长这样:
typescript
【System Message】
你是机票查询助手。根据用户需求生成模拟航班信息。
价格范围:经济舱 300-2000 元。
航班号格式:CA/MU/CZ + 4位数字。
只输出纯 JSON,不要任何额外文字。
【User Message】
北京到上海明天的机票
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON response
following this format without deviation.
Do not include markdown code blocks in your response.
Remove the ```json markdown from the output.
Here is the JSON Schema instance your output must adhere to:
```{"type":"object","properties":{"query":{"type":"string"},"flights":{"type":"array","items":{"type":"object","properties":{"flightNo":{"type":"string"},...}}},...}}```看到了吗?你写的 User Message 只有 1 行,但 LLM 实际收到了 10+ 行的格式指令 。这就是 .entity() 背后的"魔法"------也是它的 Token 成本。
💡 开发建议 :开发阶段打开
logging.level.org.springframework.ai.chat.model: DEBUG,在日志里看实际发送给 LLM 的完整 Prompt。很多"LLM 不听话"的问题,看了实际 Prompt 就明白了。
第三步:反序列化
convert() 方法用 Jackson ObjectMapper 把 LLM 返回的 JSON 字符串反序列化为 Java 对象:
java
// BeanOutputConverter.convert() 源码简化
public T convert(String text) {
// 先尝试清理 markdown 代码块标记
String trimmed = trimMarkdown(text);
try {
return objectMapper.readValue(trimmed, typeRef);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to convert to " + type.getName(), e);
}
}注意 trimMarkdown() ------Spring AI 会尝试自动去除 LLM 返回的 ```json ````标记。但它只处理最外层的代码块,如果 LLM 在 JSON 前面加了"好的,为您查询到以下结果:"这种文字,trimMarkdown` 救不了你------所以 System Prompt 里的"只输出纯 JSON"非常重要。
三种 OutputConverter 对比
Spring AI 不只有 BeanOutputConverter,还有另外两种:
| Converter | 输出类型 | 适用场景 | Token 开销 |
|---|---|---|---|
BeanOutputConverter |
Java 对象 / record | 复杂结构化数据 | 高(JSON Schema 较长) |
ListOutputConverter |
List<String> |
简单列表 | 低(逗号分隔) |
MapOutputConverter |
Map<String, Object> |
键值对,Schema 不固定 | 中 |
💡 开发建议 :能用
BeanOutputConverter就不用MapOutputConverter------有 Schema 约束比没有好。ListOutputConverter适合"列出 5 个热门航线"这种简单场景。
实战篇
七、动手编码------创建 prompt-engineering 模块
本节完整代码在
prompt-engineering子模块中。
7.1 项目结构
bash
prompt-engineering/
├── pom.xml
└── src/main/
├── java/com/ai/course/promptengineering/
│ ├── PromptEngineeringApplication.java
│ ├── config/
│ │ └── PromptManager.java ← 模板集中管理
│ ├── controller/
│ │ ├── PromptController.java ← 7 个接口:模板/角色/Few-shot/结构化/列表/重试/校验
│ │ └── ManualParseController.java ← 手动拆解 BeanOutputConverter
│ ├── model/
│ │ ├── FlightInfo.java
│ │ └── FlightSearchResult.java
│ └── service/
│ └── SafeEntityCaller.java ← 带重试的结构化输出(第八节)
└── resources/
├── application.yml
└── prompts/
└── flight-analyst.st7.2 数据模型------定义 LLM 输出结构
java
package com.ai.course.promptengineering.model;
/**
* 航班信息
* 用 record 定义------字段名就是 LLM 需要输出的 JSON key
*/
public record FlightInfo(
String flightNo, // 航班号,如 CA1234
String airline, // 航空公司
String departure, // 出发城市
String arrival, // 目的城市
String departureTime, // 起飞时间
String arrivalTime, // 到达时间
int price // 价格(元)
) {}
java
package com.ai.course.promptengineering.model;
import java.util.List;
/**
* 航班查询结果(包含多个航班)
* BeanOutputConverter 会根据这个 record 生成 JSON Schema
*/
public record FlightSearchResult(
String query, // 用户原始查询
List<FlightInfo> flights, // 航班列表
FlightInfo cheapest, // 最便宜的
String summary // 一句话摘要
) {}7.3 Prompt 模板文件
src/main/resources/prompts/flight-analyst.st:
markdown
你是一个{style}的机票分析师「票小蜜」。
你的职责:
1. 只回答与机票、航班、旅行相关的问题
2. 回答时必须包含航班号、时间、价格
3. 如果用户问了无关问题,礼貌地引导回机票话题
4. 当前日期是 {date},请基于此判断用户说的"明天""后天"是哪天
回答风格:{style}7.4 PromptManager------模板集中管理
上面的 .st 文件如果散落在各个 Controller 里加载,随着场景增多(查询/比价/推荐),会出现到处 new PromptTemplate(new ClassPathResource(...)) 的情况。抽一个 PromptManager 统一管理所有模板:
java
package com.ai.course.promptengineering.config;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* Prompt 模板管理器
* 所有模板注册在一处------改 Prompt 只需改 .st 文件,不改 Java 代码
*/
@Component
public class PromptManager {
private final Map<String, PromptTemplate> templates = new HashMap<>();
public PromptManager() {
register("flight-analyst", "prompts/flight-analyst.st");
// 后续章节会不断增加模板
// register("flight-compare", "prompts/flight-compare.st");
// register("flight-recommend", "prompts/flight-recommend.st");
}
private void register(String name, String classpath) {
templates.put(name, new PromptTemplate(new ClassPathResource(classpath)));
}
public String render(String name, Map<String, Object> variables) {
PromptTemplate template = templates.get(name);
if (template == null) {
throw new IllegalArgumentException("未知模板: " + name);
}
return template.render(variables);
}
}这样做的好处:
- 一处注册,处处使用 ------Controller 只需
promptManager.render("flight-analyst", variables)一行代码 - 改 Prompt 不改代码 ------产品经理直接改
.st文件就能调整效果 - 模板复用------多个接口可以共享同一个模板,只是参数不同
后面的 Controller 会直接注入 PromptManager 来使用。
7.5 Controller------七个接口覆盖全部知识点
java
package com.ai.course.promptengineering.controller;
import com.ai.course.promptengineering.config.PromptManager;
import com.ai.course.promptengineering.model.FlightInfo;
import com.ai.course.promptengineering.model.FlightSearchResult;
import com.ai.course.promptengineering.service.SafeEntityCaller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.StructuredOutputValidationAdvisor;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/api/prompt")
public class PromptController {
private final ChatClient chatClient;
private final PromptManager promptManager;
private final SafeEntityCaller safeEntityCaller;
public PromptController(ChatClient.Builder builder,
PromptManager promptManager,
SafeEntityCaller safeEntityCaller) {
this.chatClient = builder
.defaultSystem("你是机票查询助手。只输出纯 JSON,不要任何额外文字。")
.build();
this.promptManager = promptManager;
this.safeEntityCaller = safeEntityCaller;
}
// ---------- 接口 1:PromptTemplate 模板替换 ----------
/**
* 演示 PromptTemplate 的基础用法
* GET /api/prompt/template?from=北京&to=上海&date=2025-07-01
*/
@GetMapping("/template")
public String templateDemo(@RequestParam String from,
@RequestParam String to,
@RequestParam String date) {
// ST4 语法:{variable},不是 ${variable}
String template = """
你是一个机票查询助手。请根据以下信息查询机票:
- 出发城市:{from}
- 目的城市:{to}
- 出发日期:{date}
请列出 3 个推荐航班,包含航班号、起飞时间、价格。
按价格从低到高排序。
""";
PromptTemplate promptTemplate = new PromptTemplate(template);
Prompt prompt = promptTemplate.create(Map.of(
"from", from,
"to", to,
"date", date
));
return chatClient.prompt(prompt).call().content();
}
// ---------- 接口 2:通过 PromptManager 使用模板 ----------
/**
* 用 PromptManager 渲染 .st 模板作为 System Prompt
* GET /api/prompt/role?q=北京到上海明天的机票&style=严谨
*/
@GetMapping("/role")
public String roleTemplate(@RequestParam String q,
@RequestParam(defaultValue = "严谨") String style) {
// 一行代码渲染模板,不用每次 new PromptTemplate + new ClassPathResource
String systemPrompt = promptManager.render("flight-analyst", Map.of(
"style", style,
"date", LocalDate.now().toString()
));
return chatClient.prompt()
.system(systemPrompt)
.user(q)
.call()
.content();
}
// ---------- 接口 3:Few-shot Prompting ----------
/**
* 在 Prompt 中给出示例,让 LLM 模仿输出格式
* GET /api/prompt/few-shot?q=广州到深圳的高铁
*/
@GetMapping("/few-shot")
public String fewShot(@RequestParam String q) {
String fewShotPrompt = """
你是机票查询助手。请严格按以下示例格式回答:
【示例 1】
用户:北京到上海明天的机票
助手:为您查询到以下航班:
| 航班号 | 起飞 | 到达 | 价格 |
|--------|------|------|------|
| CA1234 | 08:00 | 10:15 | ¥680 |
| MU5678 | 12:30 | 14:45 | ¥520 |
最低价:MU5678,¥520
【示例 2】
用户:广州到深圳的高铁
助手:抱歉,我只能查询机票信息,无法查询高铁票。您是否需要查询广州到深圳的机票?
---
现在请回答:
用户:{question}
""";
PromptTemplate promptTemplate = new PromptTemplate(fewShotPrompt);
Prompt prompt = promptTemplate.create(Map.of("question", q));
return chatClient.prompt(prompt).call().content();
}
// ---------- 接口 4:结构化输出 ----------
/**
* .entity() 自动将 LLM 输出映射为 Java 对象
* GET /api/prompt/structured?q=北京到上海明天的机票
*/
@GetMapping("/structured")
public FlightSearchResult structuredOutput(@RequestParam String q) {
return chatClient.prompt()
.system("""
你是机票查询助手。根据用户需求生成模拟航班信息。
价格范围:经济舱 300-2000 元。
航班号格式:CA/MU/CZ + 4位数字。
只输出纯 JSON,不要任何额外文字。
""")
.user(q)
.call()
.entity(FlightSearchResult.class); // 关键:自动 JSON → Java 对象
}
// ---------- 接口 5:List 结构化输出 ----------
/**
* 用 ParameterizedTypeReference 获取 List
* GET /api/prompt/list?q=列出5个热门航线
*/
@GetMapping("/list")
public List<FlightInfo> listFlights(@RequestParam String q) {
return chatClient.prompt()
.system("你是机票查询助手。根据用户需求生成模拟航班信息。只输出 JSON 数组。")
.user(q)
.call()
.entity(new ParameterizedTypeReference<>() {});
}
// ---------- 接口 6:带重试的结构化输出(手动封装) ----------
@GetMapping("/safe-search")
public FlightSearchResult safeSearch(@RequestParam String q) {
return safeEntityCaller.call(q, FlightSearchResult.class, 3);
}
// ---------- 接口 7:StructuredOutputValidationAdvisor(推荐方式) ----------
@GetMapping("/validated-search")
public FlightSearchResult validatedSearch(@RequestParam String q) {
var validationAdvisor = StructuredOutputValidationAdvisor.builder()
.outputType(FlightSearchResult.class)
.maxRepeatAttempts(3)
.build();
return chatClient.prompt()
.system("""
你是机票查询助手。根据用户需求生成模拟航班信息。
价格范围:经济舱 300-2000 元。
航班号格式:CA/MU/CZ + 4位数字。
""")
.user(q)
.advisors(validationAdvisor)
.call()
.entity(FlightSearchResult.class);
}
}7.6 配置文件
src/main/resources/application.yml:
yaml
spring:
ai:
dashscope:
api-key: ${AI_DASHSCOPE_API_KEY}
chat:
options:
model: qwen-plus
temperature: 0.3 # 结构化输出场景用低 temperature
server:
port: 80837.7 启动类
java
package com.ai.course.promptengineering;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class PromptEngineeringApplication {
public static void main(String[] args) {
SpringApplication.run(PromptEngineeringApplication.class, args);
}
}验证一下------PromptTemplate 基础用法
启动项目后,测试模板替换:
bash
curl "http://localhost:8083/api/prompt/template?from=北京&to=上海&date=2025-07-01"预期输出:LLM 返回一段包含 3 个航班的文本,出发城市是北京,目的地是上海,日期是 2025-07-01。
动手试一试 :把模板里的
{from}改成${from}(加一个$),重新调用------你会发现变量没有被替换,LLM 收到的是${from}这个字面量。这就是 ST4 vs Spring 占位符语法的区别。
验证一下------System Prompt 文件化
bash
curl "http://localhost:8083/api/prompt/role?q=今天天气怎么样&style=幽默"预期输出:LLM 会以"票小蜜"身份回复,礼貌地把话题引导回机票(因为天气不是它的职责范围)。
bash
curl "http://localhost:8083/api/prompt/role?q=北京到上海明天的机票&style=幽默"预期输出:以幽默风格回答航班信息。换成 style=严谨 试试------输出风格会有明显变化。
验证一下------Few-shot 效果
bash
curl "http://localhost:8083/api/prompt/few-shot?q=广州到深圳的高铁"预期输出:LLM 会模仿示例 2 的格式,礼貌拒绝并引导到机票查询。
bash
curl "http://localhost:8083/api/prompt/few-shot?q=北京到上海明天的机票"预期输出:LLM 会模仿示例 1 的 markdown 表格格式输出航班信息。
对比实验:把 Few-shot 接口的两个示例都删掉(只保留"你是机票查询助手"),然后再问"广州到深圳的高铁"------观察 LLM 还会不会拒绝。没有示例教它怎么拒绝,它大概率会尝试回答。
验证一下------结构化输出
bash
curl "http://localhost:8083/api/prompt/structured?q=北京到上海明天的机票"预期输出:返回格式规整的 JSON,包含 query、flights、cheapest、summary 字段,可以直接被 Java 代码消费。
bash
curl "http://localhost:8083/api/prompt/list?q=列出3个从北京出发的热门航线"预期输出:返回一个 JSON 数组,每个元素是 FlightInfo 结构。
动手试一试 :在
FlightInforecord 中增加一个字段String aircraft(机型),然后重新调用/structured接口------观察 LLM 是否自动填充了新字段。BeanOutputConverter会重新生成 Schema,LLM 能"看到"新字段的要求。
结构化输出失败长什么样?
别光看成功的情况。把 application.yml 中的 temperature 改成 0.9,连续调 5 次 /structured 接口,大概率会碰到这样的错误:
vbnet
// LLM 返回了格式不合规的内容(temperature 0.9 时偶发)
org.springframework.ai.converter.ConversionException:
Failed to convert from JSON to FlightSearchResult
Caused by: com.fasterxml.jackson.core.JsonParseException:
Unexpected character ('为' (0x4E3A)): expected a valid value
at [Source: (String)"为您查询到以下航班信息:
{"query":"北京到上海明天的机票",...}"; line: 1, column: 2]问题一目了然------LLM 在 JSON 前面加了一句中文"为您查询到以下航班信息:",Jackson 解析直接挂了。trimMarkdown() 只去代码块标记,不去自然语言前缀。
解决方案的组合拳:
- System Prompt 明确说"只输出纯 JSON,不要任何额外文字"(挡住大部分情况)
- temperature 调到 0.3 以下(减少随机性)
- 代码层加重试(兜底方案)
对比实验 :分别用
temperature: 0.3和temperature: 0.9调用/structured接口,各调 10 次。记录成功次数------你会直观感受到 temperature 对结构化输出稳定性的影响。我的实测结果:0.3 成功 10/10,0.9 成功 8/10。
八、带重试的结构化输出------Spring AI 提供了什么,我们还需要什么
结构化输出不是 100% 可靠的,Spring AI 对此提供了两层重试机制:
第一层:HTTP 传输重试(内置)
Spring AI 自动配置了 RetryTemplate,处理网络层失败(限流 429、服务端 500):
yaml
spring:
ai:
retry:
max-attempts: 10 # 默认 10 次
backoff:
initial-interval: 2000 # 2 秒起步,指数退避
multiplier: 5但这层只管 HTTP 错误------LLM 返回 200 OK、JSON 解析失败时不会触发。
第二层:StructuredOutputValidationAdvisor(推荐方式)
Spring AI 1.1 引入了 StructuredOutputValidationAdvisor------一个递归 Advisor。它比简单重试聪明得多:JSON 解析失败时,把错误信息反馈给 LLM,让 LLM 看到自己哪里错了、自行纠正,而不是盲目重试。
这个 Advisor 的工作流程:
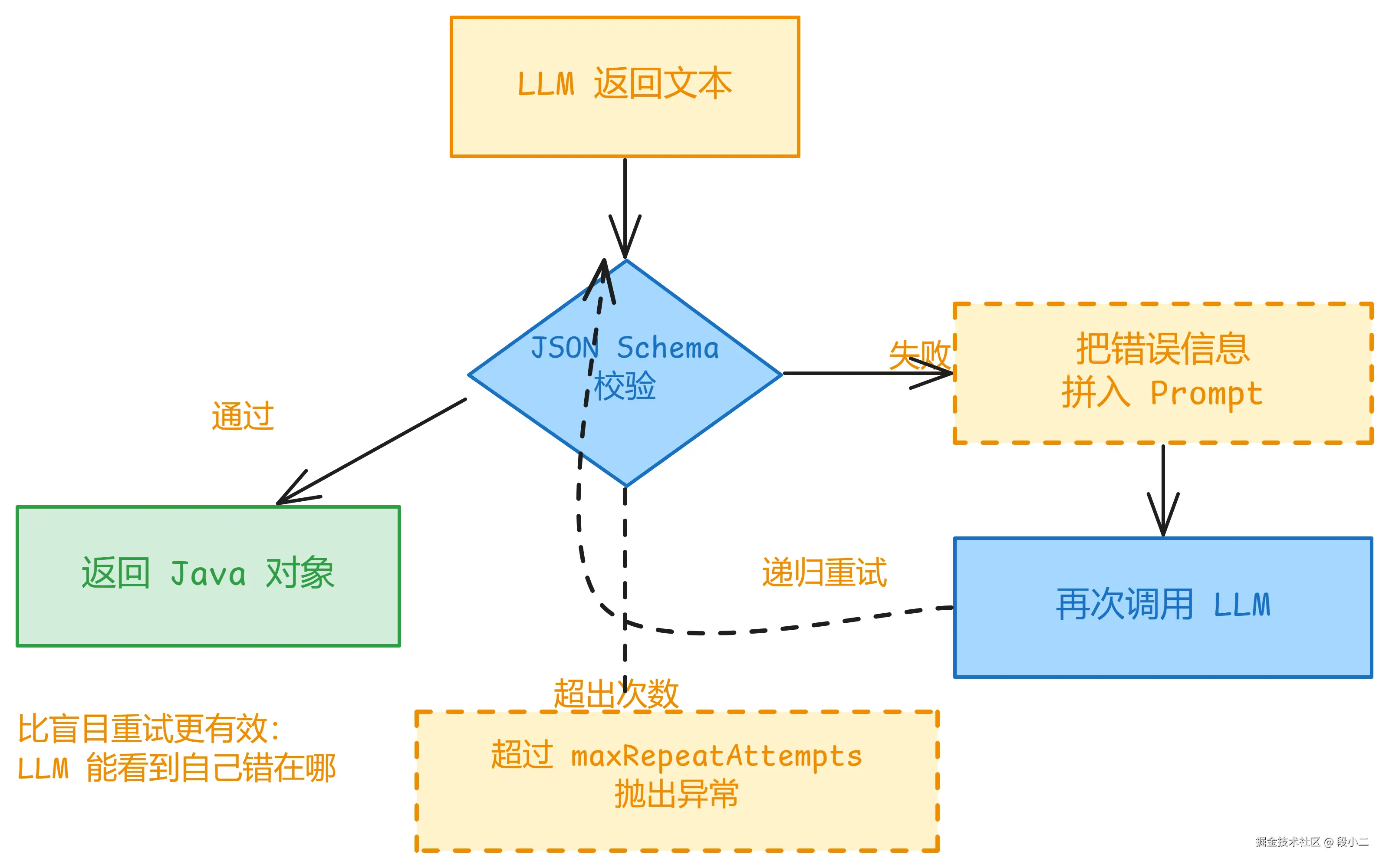 用法很简单------构建 Advisor,挂到 ChatClient 上:
用法很简单------构建 Advisor,挂到 ChatClient 上:
java
import org.springframework.ai.chat.client.advisor.StructuredOutputValidationAdvisor;
// 构建校验 Advisor
var validationAdvisor = StructuredOutputValidationAdvisor.builder()
.outputType(FlightSearchResult.class) // 用于生成 JSON Schema 并校验
.maxRepeatAttempts(3) // 最多让 LLM 修正 3 次
.build();
// 方式一:挂到 ChatClient 的默认 Advisor 链
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(validationAdvisor)
.build();
// 方式二:在单次请求中挂载(更灵活)
FlightSearchResult result = chatClient.prompt()
.user(q)
.advisors(validationAdvisor)
.call()
.entity(FlightSearchResult.class);为什么比盲目重试好?
| 对比项 | 盲目重试 (SafeEntityCaller) | StructuredOutputValidationAdvisor |
|---|---|---|
| 错误信息 | 丢弃,重发相同 Prompt | 拼入 Prompt,LLM 能看到哪里错了 |
| 纠正精度 | 纯靠运气 | LLM 定向修正错误字段 |
| 架构集成 | 独立组件 | Advisor 链的一部分,跟 Logger/Memory 等 Advisor 协同 |
| 适用版本 | 任何版本 | Spring AI 1.1+ |
💡 开发建议 :优先用
StructuredOutputValidationAdvisor------它是 Advisor 链的一部分,架构更优雅。SafeEntityCaller作为兜底方案保留,适用于需要自定义重试逻辑的场景。
SafeEntityCaller------手动封装的兜底方案
虽然有了框架内置的 Advisor,但理解手动封装的思路仍然有价值------特别是当你需要自定义重试逻辑(比如记录失败日志用于 Prompt 优化)时:
java
package com.ai.course.promptengineering.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Component;
/**
* 带重试的结构化输出封装
* 失败时记录 LLM 的原始输出------这是优化 Prompt 的最好素材
*/
@Component
public class SafeEntityCaller {
private static final Logger log = LoggerFactory.getLogger(SafeEntityCaller.class);
private final ChatClient chatClient;
public SafeEntityCaller(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("只输出纯 JSON,不要任何额外文字。")
.build();
}
public <T> T call(String userMessage, Class<T> type, int maxRetries) {
for (int i = 0; i < maxRetries; i++) {
try {
return chatClient.prompt(userMessage)
.call()
.entity(type);
} catch (Exception e) {
log.warn("结构化输出第 {} 次失败 | type={} | error={}",
i + 1, type.getSimpleName(), e.getMessage());
// 失败的原始输出是优化 Prompt 的最好素材
if (i == maxRetries - 1) {
throw new RuntimeException(
"结构化输出失败,已重试 " + maxRetries + " 次", e);
}
}
}
throw new IllegalStateException("unreachable");
}
}在 Controller 中两种方式都提供了:
java
// 方式一:SafeEntityCaller(手动重试)
@GetMapping("/safe-search")
public FlightSearchResult safeSearch(@RequestParam String q) {
return safeEntityCaller.call(q, FlightSearchResult.class, 3);
}
// 方式二:StructuredOutputValidationAdvisor(框架内置,推荐)
@GetMapping("/validated-search")
public FlightSearchResult validatedSearch(@RequestParam String q) {
var validationAdvisor = StructuredOutputValidationAdvisor.builder()
.outputType(FlightSearchResult.class)
.maxRepeatAttempts(3)
.build();
return chatClient.prompt()
.system("""
你是机票查询助手。根据用户需求生成模拟航班信息。
价格范围:经济舱 300-2000 元。
航班号格式:CA/MU/CZ + 4位数字。
""")
.user(q)
.advisors(validationAdvisor)
.call()
.entity(FlightSearchResult.class);
}验证一下------两种重试方式对比
bash
# 方式一:SafeEntityCaller 盲目重试
curl "http://localhost:8083/api/prompt/safe-search?q=北京到上海明天的机票"
# 方式二:StructuredOutputValidationAdvisor 智能纠正(推荐)
curl "http://localhost:8083/api/prompt/validated-search?q=北京到上海明天的机票"两种方式的输出结果相同------都返回结构化的 FlightSearchResult JSON。区别在失败时的行为:
/safe-search失败时,控制台输出WARN SafeEntityCaller : 结构化输出第 1 次失败,然后用相同 Prompt 盲目重试/validated-search失败时,Advisor 自动把 JSON 解析错误拼入下一轮 Prompt,LLM 能看到"你上次输出的 JSON 在第 3 行有语法错误"------定向修正比盲目重试成功率高得多
动手试一试 :把 temperature 调到 0.9,分别用两个接口各调 10 次。比较两者的成功率------
/validated-search的表现通常优于/safe-search,因为 LLM 能从错误反馈中学习。
九、手动使用 BeanOutputConverter
上面 .entity() 是 ChatClient 封装好的快捷方式。如果你想更精细地控制流程,可以手动拆开来用:
java
package com.ai.course.promptengineering.controller;
import com.ai.course.promptengineering.model.FlightInfo;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.converter.BeanOutputConverter;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ManualParseController {
private final ChatClient chatClient;
public ManualParseController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
/**
* 手动拆解 BeanOutputConverter 的三步流程
* GET /api/prompt/manual?q=北京到上海明天最便宜的航班
*/
@GetMapping("/api/prompt/manual")
public FlightInfo manualParse(@RequestParam String q) {
// 第一步:创建 Converter,内部自动生成 JSON Schema
BeanOutputConverter<FlightInfo> converter = new BeanOutputConverter<>(FlightInfo.class);
// 第二步:获取格式指令(Schema + 英文提示词)
String formatInstructions = converter.getFormat();
// 拼接到 Prompt------LLM 会收到"用户问题 + 格式要求"
String fullPrompt = q + "\n\n" + formatInstructions;
// 第三步:调用 LLM,拿到原始文本
String rawOutput = chatClient.prompt(fullPrompt).call().content();
// 第四步:用 Jackson 反序列化为 Java 对象
return converter.convert(rawOutput);
}
}验证一下
bash
curl "http://localhost:8083/api/prompt/manual?q=北京到上海明天最便宜的航班"预期输出:返回单个 FlightInfo JSON 对象。这个接口跟 /structured 效果类似,但你能清楚看到 BeanOutputConverter 的每一步。
十、与机票比价 Agent 的集成
回顾一下我们在前三章积累的能力:
| 章节 | 能力 | 在 Agent 中的作用 |
|---|---|---|
| 第 1 章 | ChatModel 基础调用 | Agent 的 LLM 底层通道 |
| 第 2 章 | ChatClient + Advisor 链 | Agent 的请求管道和拦截链 |
| 第 3 章 | Function Calling + ToolContext | Agent 的"手脚"------调用 Java 方法 |
| 第 4 章 | Prompt 模板 + 结构化输出 | Agent 的"语言"和"数据格式" |
| 第 5 章(预告) | Memory 对话记忆 | Agent 的"记忆"------跨轮次保持状态 |
这一章定义的 FlightSearchResult 就是机票比价 Agent 的核心数据结构。后续不管是 Function Calling 返回航班数据,还是 RAG 从知识库查到政策信息,最终都会走结构化输出映射成 Java 对象,让下游业务代码拿到就能用。
Prompt 模板管理在 Agent 场景更为关键------不同场景切换不同的 System Prompt(查询模式 vs 比价模式 vs 推荐模式),用模板文件管理意味着"改 Prompt 不用改代码"。
十一、FAQ、踩坑记录与 Trade-offs
Q1:.entity(FlightSearchResult.class) 抛出 JSON 解析异常?
常见原因和解决方案:
- LLM 在 JSON 前后加了 markdown 代码块标记------在 System Prompt 中明确"不要 markdown 代码块"
- LLM 返回了额外说明文字------System Prompt 中说"只输出纯 JSON"
- Java record 字段名与 LLM 输出的 JSON key 不一致------字段命名用驼峰且语义清晰
- 使用低 temperature(0~0.3)显著提高格式稳定性
Q2:PromptTemplate 的变量没被替换?
检查你写的是 {variable} 还是 ${variable}。ST4 引擎只认花括号,$ 会被当作普通字符。
Q3:ListOutputConverter 和 BeanOutputConverter<List<String>> 选哪个?
ListOutputConverter 告诉 LLM 用逗号分隔文本,然后 split------Token 消耗少,但格式不够严格。BeanOutputConverter<List<String>> 生成完整的 JSON Schema------更可靠但 Token 开销大。简单列表用前者,需要严格格式用后者。
Trade-off:Prompt 模板外部化 vs 代码内联
把 Prompt 放到 .st 文件里,好处是"改 Prompt 不用改代码、不用重新部署"。但代价也很明显:
- 调试困难 :Prompt 的效果跟模板参数强相关,光看
.st文件看不出最终发给 LLM 的完整文本。建议开发时打开org.springframework.ai.chat.model: DEBUG日志,看实际的 Prompt 内容。 - 版本管理 :
.st文件的修改历史分散在文件系统中,不像 Java 代码有严格的 code review 流程。如果 Prompt 改坏了,回滚困难。建议把.st文件纳入 Git,跟代码一样走 PR 流程。 - 跨模型兼容:一套 Prompt 模板不一定适用所有模型。qwen-plus 上跑得好的 Prompt,换到 deepseek-v3 上可能需要调整。如果项目要支持多模型,Prompt 模板管理的复杂度会翻倍。
我的做法是:开发阶段 Prompt 写在代码里,快速迭代;稳定后再抽到 .st 文件。 别一上来就过度设计。
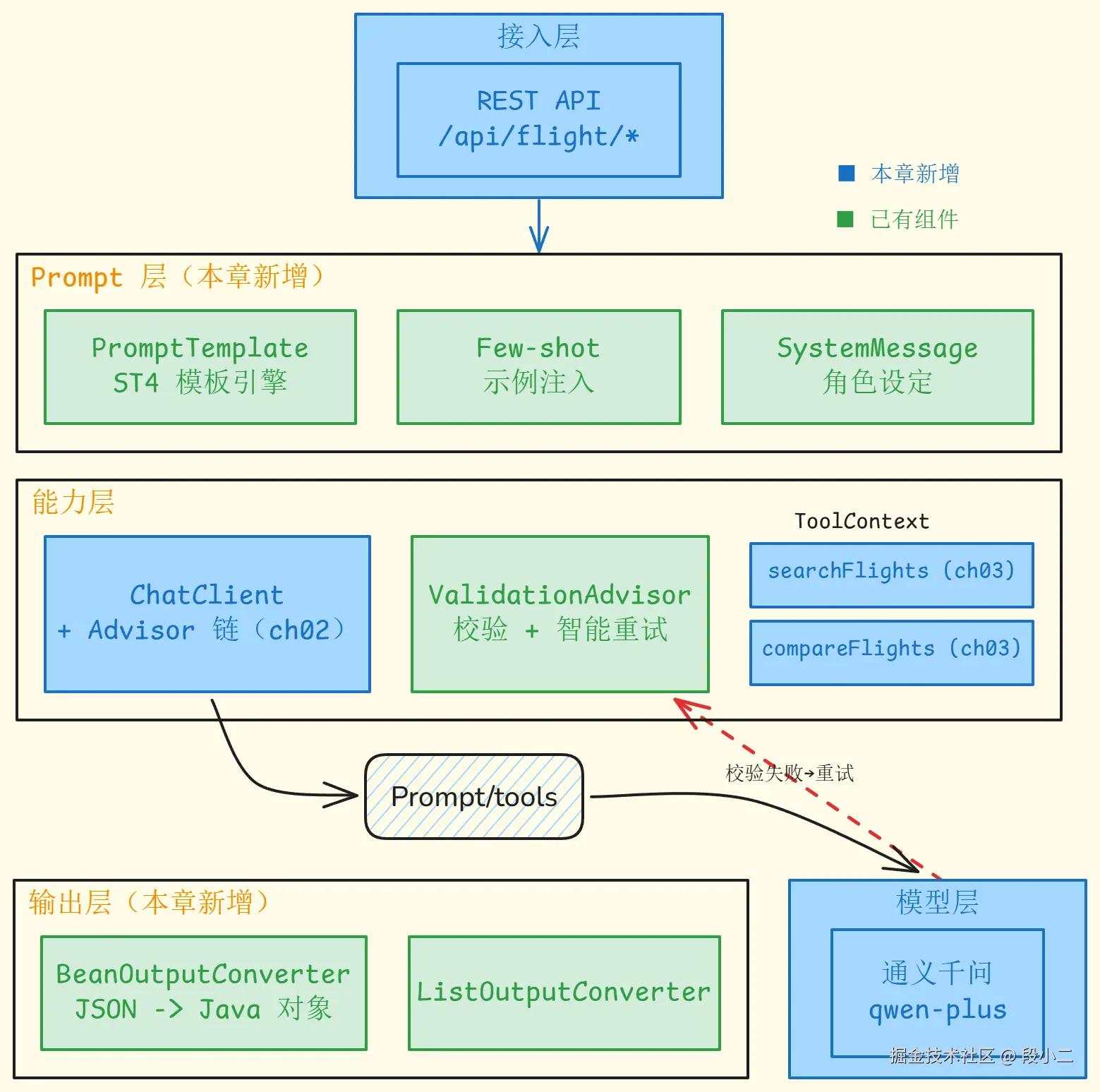
架构演进图------第 04 章后的系统
对比上一章,本章新增了 Prompt 模板层 (PromptTemplate + ST4)和 结构化输出层(BeanOutputConverter + ValidationAdvisor):
对比第 03 章:上一章加入了 Tool 层,LLM 能"做事"了。本章在输入端加了 PromptTemplate(可维护的提示词管理),在输出端加了 BeanOutputConverter(LLM 输出直接变 Java 对象)。下一章给 Agent 加上记忆------让它记住多轮对话的上下文。
本章小结 & 下一章预告
| 知识点 | 核心要点 | Java 类比 |
|---|---|---|
| Prompt 设计原则 | System 写规则、User 写任务;具体约束 > 模糊形容 | SQL 查询优化 |
| PromptTemplate | ST4 引擎,{variable} 语法,支持外部文件 |
PreparedStatement |
| Few-shot | 2-3 个示例教 LLM 输出格式 | 单元测试的 given/when/then |
| BeanOutputConverter | 反射生成 Schema → 拼入 Prompt → Jackson 反序列化 | Jackson ObjectMapper |
| 三种 Converter | Bean(复杂结构)、List(简单列表)、Map(动态键值) | 泛型容器选型 |
| StructuredOutputValidationAdvisor | 递归 Advisor,校验失败时把错误反馈给 LLM 自动纠正 | Spring Retry + 错误反馈 |
下一章预告:Memory 对话记忆 + Checkpoint
下一篇要解决一个关键问题------LLM 天生没有记忆,如何实现多轮对话?
现在的 Agent 每次对话都是独立的。用户说"我想从北京飞上海" → "明天的" → "最便宜的那个",三轮对话之间 Agent 记不住任何信息。下一篇来解决这个痛点:
- 为什么 LLM 无记忆------每次请求都是独立的 HTTP 调用
- InMemoryChatMemory------最简单的内存记忆
- MessageWindowChatMemory------滑动窗口策略,控制 Token 消耗
- 实战:多轮机票查询对话
延伸阅读
- Spring AI 官方文档 - Prompt --- PromptTemplate API 详解
- Spring AI 官方文档 - Structured Output --- BeanOutputConverter、ListOutputConverter 完整用法
- StringTemplate 4 官方文档 --- ST4 模板引擎语法参考
- victools/jsonschema-generator --- BeanOutputConverter 底层的 JSON Schema 生成库
- Prompt Engineering Guide --- Prompt 工程系统化指南(中文)
聊聊你的想法
几个开放性问题,欢迎在评论区讨论:
- 结构化输出 vs Few-shot:你更倾向哪种?
.entity()自动注入 JSON Schema,Few-shot 手动给示例。前者省事但 Token 开销大,后者灵活但要自己维护示例。你在项目中怎么选?有没有两者混用的场景? - Prompt 模板该放在哪里? 代码里、
.st文件里、还是数据库里?如果你做过 Prompt 版本管理(A/B 测试、灰度发布),聊聊你的方案。 - LLM 输出不合格时,你选择智能纠正还是后处理? 本章展示了两种重试方案------
StructuredOutputValidationAdvisor(把错误反馈给 LLM 自行纠正)和SafeEntityCaller(盲目重试)。你在项目中怎么选?有没有用正则/字符串清洗做后处理的经验? - 你踩过哪些 Prompt 的坑? 比如某个模型死活不遵守 JSON 格式、或者 Few-shot 示例"教歪"了 LLM。分享你的踩坑经验,大家少走弯路。
本文代码 :GitHub - prompt-engineering 模块
如果这篇文章对你有帮助,欢迎点赞收藏。有问题欢迎评论区交流。