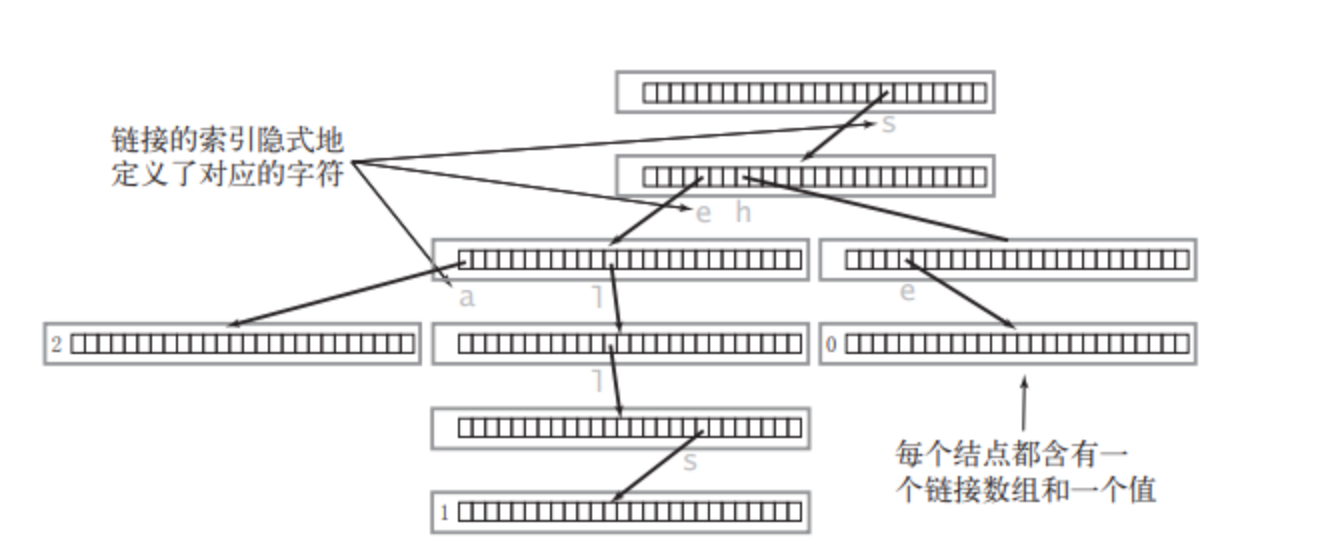
这段代码实现了一个标准且高效的 Trie(字典树/前缀树) 。它的核心逻辑是利用 数组下标 来代表字符,通过 指针跳转 来表示字符的连接。
1. 核心设计思路
-
公共前缀的共享:如果两个单词有共同的前缀(比如 "apple" 和 "apply"),它们在树中会共用前面的节点 "a"->"p"->"p"->"l",只在最后一位分叉。
-
字符不存储在节点内 :这是一个巧妙的点。字母
a-z并不存在变量里,而是隐含在next[26]数组的下标 中。如果next[0]不为空,就代表存在字符 'a'。 -
状态标记 :
isEnd就像一个终点路标,标记从根节点走到这里是否构成了一个完整的单词,而不仅仅是某个单词的前缀。
2. 代码逐行注释
C++
cpp
class Trie {
private:
bool isEnd; // 标记:当前节点是否为一个单词的结束位置
Trie* next[26]; // 指针数组:存储指向 26 个字母子节点的指针
public:
// --- 构造函数:初始化节点 ---
Trie() {
isEnd = false; // 初始化为非结尾状态
memset(next, 0, sizeof(next)); // 将 26 个子节点指针全部置为 NULL (0)
}
// --- 插入操作:向字典树添加一个单词 ---
void insert(string word) {
Trie* node = this; // 从当前根节点开始遍历
for (char c : word) { // 遍历单词的每个字符
// 如果字符对应的子节点不存在 (NULL)
if (node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie(); // 创建一个新的子节点
}
// 移动指针到对应的子节点上(相当于走到了这个字母的楼层)
node = node->next[c-'a'];
}
// 单词遍历结束后,将最后的节点标记为单词结尾
node->isEnd = true;
}
// --- 查找操作:判断一个单词是否完整存在于树中 ---
bool search(string word) {
Trie* node = this; // 从根节点开始
for (char c : word) {
node = node->next[c - 'a']; // 沿着字母路径往下跳
if (node == NULL) { // 如果中途发现路径断了,说明单词不存在
return false;
}
}
// 路径走通了,但还要检查该节点是否是一个单词的终点 (isEnd)
// 比如存了 "apple",搜 "app" 虽然路径通,但 "p" 不是终点,返回 false
return node->isEnd;
}
// --- 前缀查找:判断是否有单词以 prefix 开头 ---
bool startsWith(string prefix) {
Trie* node = this;
for (char c : prefix) {
node = node->next[c-'a']; // 沿着前缀路径往下走
if (node == NULL) { // 只要路径中途断开,说明没有以此为开头的单词
return false;
}
}
// 只要路径能全部走完,就说明前缀存在(不需要判断 isEnd)
return true;
}
};3. 运行逻辑图解
假设我们执行:insert("app"), insert("apple")
-
插入 "app":
-
创建
a->p->p三个节点。 -
在第二个
p节点打上标签isEnd = true。
-
-
插入 "apple":
-
发现
a,p,p已存在,直接沿用。 -
创建新节点
l->e。 -
在
e节点打上标签isEnd = true。
-
-
查询 "app":
- 路径走通了,且
isEnd为true,返回true。
- 路径走通了,且
-
查询 "ap":
- 路径走通了,但
isEnd为false(因为没有存过 "ap" 这个词),search返回false,但startsWith会返回true。
- 路径走通了,但
4. 复杂度分析
-
时间复杂度:
-
insert: O(L),其中 L 是单词长度。 -
search: O(L)。 -
startsWith: O(L)。 -
注:与树中存了多少个单词无关,只跟当前查的单词长度有关,这就是 Trie 强大的原因。
-
-
空间复杂度:O(N \\times 26),N 是所有单词的节点总数。每个节点都要预留 26 个指针位,比较耗内存。
-
前缀树 数据结构 next是一个数组