消息队列的解耦,就是上下游服务相互依赖,但上游服务不关心下游服务结果,同时需要降低整体响应时间,且下游即便出现问题也不需要上游来解决的场景。
解耦演示场景
一个模块A接受前端请求,收到请求之后需要调用另一个模块B,以完成后续事项。一开始需要B做完之后,才回包给前端,这是第一种流程,这种流程很明显会很依赖模块B的运作情况。
但是如果业务允许,我们还可以有第二种流程:模块A不用等模块B把事情做完,只用将信息传递到一个中转站,B从中转站感知到这件事,再自己去做就可以了,这个中转站,就是消息队列,可以起到解耦的作用。
1. CountService.java(模拟耗时业务)
java
package org.example.kafkademo1;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
@Service
public class CountService {
@Autowired
private JdbcTemplate jdbcTemplate;
public void doHeavyWork() {
// 模拟耗时操作
for (int i = 0; i < 1000000; i++) {
if (i % 100000 == 0) {
jdbcTemplate.update("UPDATE t_count SET count_value = count_value + 1 WHERE id = 1");
}
}
}
}2. DecouplingController.java(对比接口)
java
package org.example.kafkademo1;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/demo")
public class DecouplingController {
@Autowired
private CountService countService;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
// 解耦前:同步调用,用户需要等待
@GetMapping("/sync")
public String sync() {
long start = System.currentTimeMillis();
countService.doHeavyWork();
return "同步任务耗时:" + (System.currentTimeMillis() - start) + "ms";
}
// 解耦后:异步调用,秒回用户
@GetMapping("/async")
public String async() {
long start = System.currentTimeMillis();
// 丢给 Kafka 后直接返回
kafkaTemplate.send("decoupling-topic", "start-task");
return "解耦成功!用户感知耗时:" + (System.currentTimeMillis() - start) + "ms";
}
}3. KafkaConsumer.java(后台执行者)
java
package org.example.kafkademo1;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumer {
@Autowired
private CountService countService;
@KafkaListener(topics = "decoupling-topic", groupId = "my-group")
public void handle(String message) {
System.out.println(">>> Kafka 收到指令,后台开始干活...");
countService.doHeavyWork();
System.out.println(">>> 后台活干完了!");
}
}对比各自返回结果可得:
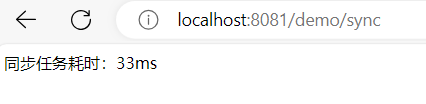
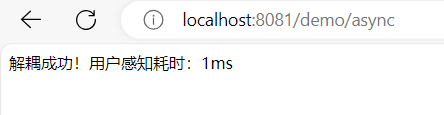
最后来抽象一下,解耦其实本质就是A不再关心B的事情,以及不再受B本身变动的影响。
但是,MQ用来解耦和用来异步,这两者该如何区分?
- 目的不一样,看业务的目的是什么
- 比如一个服务觉得他不想关心后面服务的返回,这就是解耦
- 如果一个服务,想关心结果,但是一次调用实在太久了,就是异步,回头还要轮询或者通过回调去得到结果。
Kafka的基本使用
通过上述应用场景总结,我们大概已经知道Kafka的基本用法,现在来整体做一个总结:
1.引入Maven依赖
在 pom.xml 中加入 spring-kafka。它会自动把底层的 Kafka 客户端驱动也带进来。
XML
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>2. YAML/Properties 配置
这是最基础的连接配置,让你的 Java 程序能找到 Docker 里的 Kafka。
XML
# 核心:Kafka 服务器地址
spring.kafka.bootstrap-servers=localhost:9092
# 消费者必须指定的组 ID
spring.kafka.consumer.group-id=my-group简单来说,Group-ID 就是消费者的"团队名" :它让 Kafka 记住这个团队读到了哪一页 (Offset)以保证重启不丢进度,并让同组的多个成员分工协作 (负载均衡)处理同一个 Topic,从而实现海量数据的高效并行消费。既然你在配置里写了
my-group,Spring 就默认你所有的消费者方法都属于这个组。
3.代码
在 Java 代码里,只需要记住两个核心角色:发消息的 Template 和 收消息的 Listener。
生产者:KafkaTemplate (发件人)
它是 Spring 提供的一个工具类,你只需要 @Autowired 进来,然后调用**send**方法。
- 特点 :异步执行。消息丢进缓冲区就立即返回,这就是你看到 0ms 的原因。
java
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String msg) {
// 参数:Topic名, 消息内容
kafkaTemplate.send("my-topic", msg);
}消费者:@KafkaListener (收件人)
这是一个"被动触发"的注解。你不需要写死循环去读取消息,只要 Kafka 里有了新消息,Spring 会自动调用这个方法。
- 特点:运行在独立的线程池里,不会阻塞主线程。
java
@KafkaListener(topics = "my-topic")
public void listen(String message) {
// 收到消息后的逻辑处理(比如你写的耗时计数)
System.out.println("收到消息:" + message);
}