在分布式系统中,消息队列是实现高可用、高并发的核心中间件,而Kafka作为其中的"性能王者",凭借超高吞吐量、高可靠性和可扩展性,成为日志采集、实时计算、海量数据分发等场景的首选。但很多开发者初接触Kafka时,总会被Topic、Partition、Offset、消费者组等概念绕晕,甚至在实战中踩中消息丢失、重复消费、顺序错乱的坑。
一、Kafka是什么?
Kafka本质上是一个分布式流式消息平台,最初由LinkedIn开发,后来捐献给Apache基金会成为顶级开源项目。它不仅能做传统消息队列的"解耦、异步、削峰填谷",更擅长处理海量流式数据,比如日志采集、用户行为埋点、实时数据同步等场景。
简单来说,Kafka就像一个"分布式消息仓库":生产者(Producer)往仓库里存消息,消费者(Consumer)从仓库里取消息,仓库由多个节点(Broker)共同管理,保证消息不丢失、不拥堵,还能支持百万级消息的秒级处理。
二、Kafka核心体系结构
Kafka的核心架构由4大组件构成:Producer(生产者)、Broker( broker节点)、Consumer(消费者)、ZooKeeper(协调器,旧版依赖),再加上Topic、Partition、Replica等核心概念,共同组成一个高可用、高吞吐的分布式系统。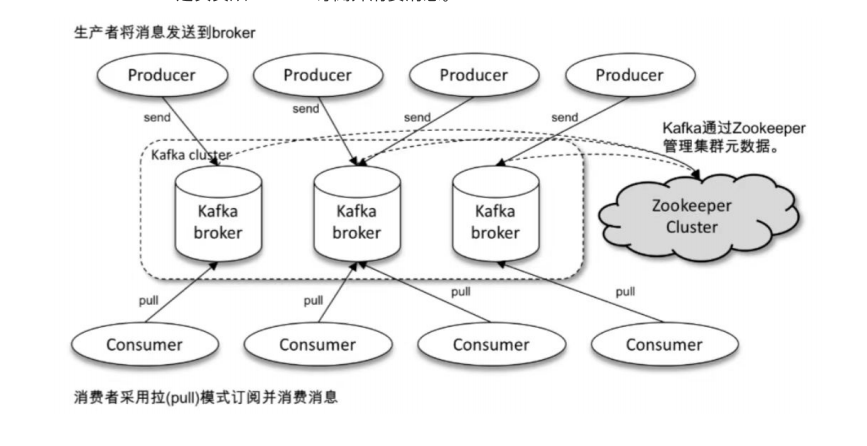
1. 四大核心组件详解
-
Producer(生产者):消息的发送方,负责将业务数据封装成消息,发送到指定的Topic中。比如电商系统中,用户下单后,订单服务作为生产者,将订单消息发送到"order_topic"。
-
Broker( broker节点):Kafka集群的核心节点,负责接收生产者发送的消息,将消息持久化到磁盘,同时响应消费者的拉取请求。一个Kafka集群通常由多个Broker组成,实现负载均衡和容错------单个Broker宕机,其他Broker能继续提供服务。
-
Consumer(消费者):消息的接收方,负责从Broker中拉取消息并处理。Kafka采用"拉模式"(消费者主动轮询),消费者可以根据自身处理能力,控制拉取消息的频率和批量大小,避免被海量消息压垮。
-
ZooKeeper(协调器):旧版Kafka的"大脑",负责管理集群元数据(比如Topic、Partition、Broker信息)、选举集群控制器(Controller)、监控Broker上下线、存储消费者偏移量(Offset)等。不过从Kafka 2.8版本开始,社区推出KIP-500方案,逐步剥离ZooKeeper依赖,实现"Kafka on Kafka"------让Kafka自身管理元数据,减少维护两套集群的成本。
2. 核心概念拆解
(1)Topic:消息的"分类文件夹"
Topic是一个逻辑概念,没有实体,相当于消息的"分类标签",用来区分不同类型的消息。比如一个电商系统中,可以创建3个Topic:
-
topic_order:存储订单相关消息(下单、支付、取消);
-
topic_user:存储用户相关消息(注册、登录、注销);
-
topic_log:存储系统日志消息(错误日志、访问日志)。
生产者发送消息时,必须指定Topic,消费者消费消息时,也必须订阅指定的Topic------这样就能实现"分类收发",避免消息混乱。需要注意的是,一个Topic中通常只存储同一类消息,且消息有固定的结构(一般是Key-Value格式)。
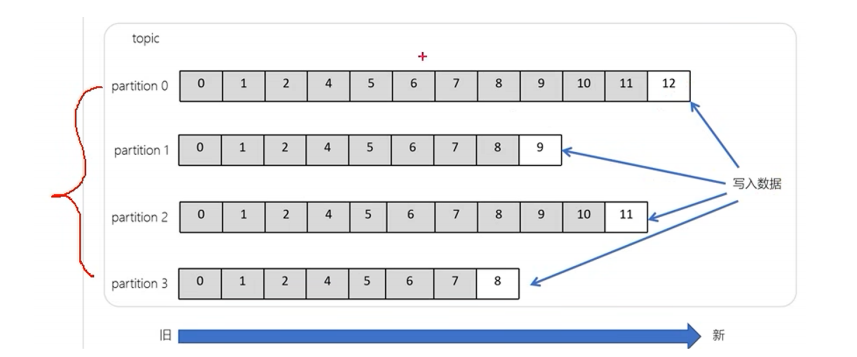
(2)Partition:消息的"实际存储单元"
Topic本身是逻辑概念,无法直接存储消息,真正存储消息的是Partition(分区)------每个Topic会被拆分成多个Partition,每个Partition是一个独立的日志文件,消息以"追加"的方式写入,不可修改。
Partition的核心作用有两个:
-
提高并发能力:多个Partition可以分布在不同的Broker上,生产者可以并行向多个Partition发送消息,消费者也可以并行从多个Partition拉取消息,突破单个Broker的IO限制。
-
实现容错:如果一个Topic的所有Partition都集中在一个Broker上,一旦该Broker宕机,整个Topic的消息都无法访问;而将Partition分散到多个Broker上,即使某个Broker宕机,其他Broker上的Partition依然可以提供服务。
补充:一个Topic的所有Partition的数据并集,就是该Topic的全量数据;单个Partition内的消息是"先进先出"(FIFO)的,但不同Partition之间的消息无序。
(3)Replica:Partition的"备份副本"
为了进一步保证消息不丢失,Kafka会为每个Partition创建多个副本(Replica),分散存储在不同的Broker上。其中,只有一个副本是"首领副本"(Leader),负责接收生产者的消息写入和消费者的消息拉取;其他副本是"跟随副本"(Follower),只负责同步Leader的数据,当Leader宕机时,跟随副本会选举成为新的Leader,保证服务不中断。
实战建议:生产环境中,副本数建议设置为2~3个(副本数越多,可靠性越高,但集群开销也越大)。
(4)Offset:消息的"唯一身份证"
Offset是一个单调递增、不可重复的数字,当一条消息写入Partition时,会被分配一个唯一的Offset,用来标识消息在Partition中的位置(从0开始,每写入一条消息,Offset加1)。即使消息过期或被删除,Offset也不会被重用。
Offset的核心作用有两个:
-
定位消息:消费者可以通过指定Offset,精准定位到Partition中的某条消息,或者从某个位置开始消费(比如重启后,从上次消费的Offset继续消费)。
-
记录消费进度:消费者消费完消息后,需要提交Offset,告诉Kafka"我已经消费到这个位置了"。如果消费者宕机重启,就能通过提交的Offset恢复消费,避免重复消费或漏消费。
补充:Kafka 0.9.0版本前,Offset存储在ZooKeeper中,但ZooKeeper不适合大量写入,因此后续版本将Offset存储在Kafka内置的"consumer_offsets"主题中(该主题默认有50个分区,可配置)。
(5)消费者组(Consumer Group):消息的"协同消费团队"
多个消费者如果指定了相同的group_id,就组成了一个消费者组。消费者组的核心作用是"协同消费"------同一个Topic的消息,会被分配给消费者组内的不同消费者,避免重复消费。
消费者组与Partition的分配规则(必记):
-
当消费者组内的消费者数量 < Partition数量:部分消费者会消费多个Partition的消息(比如3个Partition,2个消费者,其中1个消费者会消费2个Partition);
-
当消费者组内的消费者数量 = Partition数量:每个消费者对应一个Partition,实现最大并发消费;
-
当消费者组内的消费者数量 > Partition数量:多余的消费者会处于空闲状态,造成资源浪费。
另外,不同消费者组可以订阅同一个Topic ------此时Topic的同一条消息,会被每个消费者组各消费一次(实现"多播消费");而同一个消费者组内,一条消息只会被一个消费者消费(实现"单播消费")。
三、Kafka实战核心
1. 消息不丢失:三大环节层层把控
Kafka的消息可靠性,需要从生产者、Broker、消费者三个环节共同保证,对应三种消息语义(At most once、At least once、Exactly once),其中**"At least once"(最少传递一次,消息不丢失)**是生产环境的常用选择。
-
生产者端:设置acks=-1(消息写入Leader并同步到所有跟随副本后,才返回成功)、retries=3(发送失败时重试3次),并使用带回调的API,失败后将消息存入本地或数据库,避免消息丢失。
-
Broker端:设置Partition副本数>1,确保Leader宕机后有跟随副本补位;同时配置消息过期时间(避免消息被误删)。
-
消费者端:关闭自动提交Offset(enable.auto.commit=false),在业务逻辑处理完成后,手动提交Offset------避免业务未处理完,Offset已提交,导致宕机后漏消费。
2. 消息不重复消费:两端去重+幂等性
消息重复消费的核心原因是"Offset提交失败"(比如网络中断、消费者宕机),解决方案分两步:
-
生产者端:开启幂等性(enable.idempotence=true),Kafka会为每条消息分配唯一序列号,Broker端会自动去重,从源头避免重复发送。
-
消费者端:实现业务幂等性------比如用订单ID、消息ID作为唯一标识,消费前先查询数据库,判断消息是否已处理,避免重复处理对业务造成影响。
3. 消息顺序消费:单Partition+单消费者
Kafka只保证"单个Partition内的消息有序",不同Partition之间的消息无序。如果需要保证所有消息的全局顺序,解决方案是:
将Topic的Partition数量设为1,同时消费者组内只保留1个消费者------这样所有消息都写入同一个Partition,由同一个消费者单线程消费,确保顺序。但这种方式会牺牲并发能力,适合对顺序要求极高(比如订单支付、转账)的场景。
4. 消息堆积:从生产、消费、集群三端优化
消息堆积的核心原因是"生产速度>消费速度",解决方案分三端优化:
-
消费者端:优化消费逻辑(比如异步处理、批量处理);增加消费者数量(不超过Partition数量);检查Offset是否提交正常,避免消费停滞。
-
生产者端:设置限流机制,避免消息生产速度过快;合理拆分Topic,避免单个Topic消息量过大。
-
集群端:根据业务量调整Partition数量,增加并发处理能力;升级Broker硬件(提升IO、内存),优化磁盘存储。
5. Rebalance机制:避免不必要的集群抖动
Rebalance(再均衡)是Kafka协调消费者组与Partition分配的机制,当消费者组内消费者数量变化、Topic的Partition数量变化、消费者组订阅的Topic变化时,会触发Rebalance。
Rebalance的缺点是:过程中所有消费者会停止消费,直到Rebalance完成,造成消费停滞。因此,实战中要尽量避免不必要的Rebalance,比如:
-
避免频繁增减消费者;
-
合理设置session.timeout.ms(消费者超时时间),避免消费者因网络波动被误判为宕机,触发Rebalance。
四、Kafka vs 其他消息队列(选型参考)
很多开发者会纠结Kafka、RabbitMQ、RocketMQ该怎么选,结合核心差异,给出明确的选型建议(基于你提供的对比信息):
| 对比指标 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 核心优势 | 高吞吐量、海量数据处理、流式计算 | 路由灵活、支持延迟/死信队列、轻量 | 可靠性高、支持事务消息、功能全面 |
| 消费模式 | 拉模式 | 推模式 | 推/拉模式都支持 |
| 适用场景 | 日志采集、实时计算、埋点数据 | 业务通知、任务分发、低并发场景 | 电商交易、金融支付、高可靠 |
总结:海量数据、高吞吐选Kafka;业务灵活、轻量场景选RabbitMQ;高可靠、复杂业务选RocketMQ。
Kafka的核心价值,在于"高吞吐、高可靠、可扩展",它不仅是一个消息队列,更是一个分布式流式处理平台。掌握它的核心概念(Topic、Partition、Offset、消费者组),理解它的体系结构,避开实战中的常见坑,就能在分布式系统中灵活运用Kafka解决问题。
随着Kafka逐步剥离ZooKeeper依赖,自研KRaft协议管理元数据,未来它的部署和维护成本会更低,性能也会进一步提升。
五、SpringBoot 整合 Kafka 实战开发
1. 核心依赖引入
在pom.xml中添加SpringBoot Kafka官方starter,无需额外引入Kafka核心依赖,starter已自动整合:
<!-- SpringBoot Kafka 核心依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>2. 核心配置文件(application.yml)
配置生产者、消费者核心参数,开启手动提交Offset,绑定消费组、序列化方式,适配生产环境需求:
spring:
kafka:
# Kafka集群地址(单机写单个,集群用逗号分隔,如:127.0.0.1:9092,127.0.0.1:9093)
bootstrap-servers: 127.0.0.1:9092
# 生产者配置
producer:
# 消息Key/Value序列化方式(String类型,可根据需求替换为JSON序列化)
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=-1:等待所有副本同步成功,保证消息不丢失(生产环境首选)
acks: -1
# 发送失败重试次数
retries: 3
# 重试间隔时间(毫秒)
retry-backoff-ms: 1000
# 消费者配置
consumer:
# 消费组ID(核心!同组消费者协同消费,不同组独立消费)
group-id: test-consumer-group
# 消息Key/Value反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 无Offset时,从最早消息开始消费(可选:earliest/latest/none)
auto-offset-reset: earliest
# 关闭自动提交Offset(手动提交,保证消息不丢失)
enable-auto-commit: false
# 监听容器配置(手动提交Offset相关)
listener:
# 手动提交Offset(消费完成后立即提交)
ack-mode: manual_immediate
# 消费者线程数(建议不超过Partition数量)
concurrency: 13. 编写Kafka生产者(封装发送接口)
封装生产者组件,支持普通发送、带Key发送、指定分区发送,满足不同业务场景(如顺序消费需指定分区):
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* Kafka生产者组件(企业级封装,可直接复用)
*/
@Component
public class KafkaProducer {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 普通发送消息(不指定Key和分区,轮询分配分区)
* @param topic 主题名称
* @param message 消息内容
*/
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
/**
* 带Key发送消息(Key哈希路由分区,同Key消息进入同一个分区)
* @param topic 主题名称
* @param key 消息Key(用于路由分区)
* @param message 消息内容
*/
public void sendMessageWithKey(String topic, String key, String message) {
kafkaTemplate.send(topic, key, message);
}
/**
* 指定分区发送消息(保证消息顺序,需手动指定分区号)
* @param topic 主题名称
* @param partition 分区号(从0开始)
* @param key 消息Key
* @param message 消息内容
*/
public void sendMessageWithPartition(String topic, Integer partition, String key, String message) {
kafkaTemplate.send(topic, partition, key, message);
}
}4. 编写Kafka消费者(手动提交Offset)
使用@KafkaListener注解监听指定Topic,手动提交Offset,避免消息丢失,同时处理消费异常:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
/**
* Kafka消费者组件(手动提交Offset,企业级实战)
*/
@Component
public class KafkaConsumer {
/**
* 监听指定Topic:test_topic(可监听多个Topic,用逗号分隔)
* @param record 消息记录(包含Topic、分区、Offset、消息内容等信息)
* @param ack 手动提交Offset工具类
*/
@KafkaListener(topics = "test_topic")
public void consumeMessage(ConsumerRecord<String, String> record, Acknowledgment ack) {
try {
// 1. 获取消息核心信息
String topic = record.topic(); // 主题名称
int partition = record.partition(); // 分区号
long offset = record.offset(); // 消息Offset
String key = record.key(); // 消息Key
String message = record.value(); // 消息内容
// 2. 执行业务逻辑(此处替换为自己的业务代码)
System.out.println("====================消费消息====================");
System.out.println("Topic:" + topic);
System.out.println("分区:" + partition);
System.out.println("Offset:" + offset);
System.out.println("消息Key:" + key);
System.out.println("消息内容:" + message);
// 3. 业务处理成功后,手动提交Offset(关键!避免消息丢失)
ack.acknowledge();
} catch (Exception e) {
// 4. 业务处理失败,不提交Offset,重启后重新消费
System.out.println("消息消费失败,原因:" + e.getMessage());
// 可选:失败消息存入死信队列,后续人工处理
}
}
}5. 编写测试接口
编写Controller接口,测试生产者发送消息,启动项目后可直接通过浏览器访问验证:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
/**
* Kafka测试接口(快速验证生产消费功能)
*/
@RestController
public class KafkaTestController {
@Resource
private KafkaProducer kafkaProducer;
/**
* 测试普通消息发送
* 访问地址:http://localhost:8080/send/hello-kafka
*/
@GetMapping("/send/{message}")
public String sendMessage(@PathVariable String message) {
kafkaProducer.sendMessage("test_topic", message);
return "消息发送成功!发送内容:" + message;
}
/**
* 测试指定Key发送消息
* 访问地址:http://localhost:8080/send/key1/hello-kafka-key
*/
@GetMapping("/send/{key}/{message}")
public String sendMessageWithKey(@PathVariable String key, @PathVariable String message) {
kafkaProducer.sendMessageWithKey("test_topic", key, message);
return "带Key消息发送成功!Key:" + key + ",消息内容:" + message;
}
}6. 实战运行步骤
-
启动本地/远程Kafka服务(确保Broker正常运行,端口9092可访问);
-
创建测试Topic:使用Kafka命令行创建(Windows/Linux通用):
``# 创建Topic:test_topic,分区数3,副本数1(本地测试用,生产环境副本数≥2)kafka-topics.sh --create --topic test_topic --bootstrap-server 127.0.0.1:9092 --partitions 3 --replication-factor 1 -
启动SpringBoot项目(确保配置文件中的Kafka地址正确);
-
访问测试接口:http://localhost:8080/send/hello-kafka,查看项目控制台,即可看到消费者消费日志。
六、总结
Kafka的核心价值,在于"高吞吐、高可靠、可扩展",它不仅是一个消息队列,更是一个分布式流式处理平台,是大数据时代不可或缺的中间件。
对于开发者而言,掌握Kafka的关键的是:
-
理论上:吃透Topic、Partition、Offset、消费者组四大核心概念,理解Kafka的工作原理;
-
实战上:掌握消息可靠性、顺序消费、消息堆积三大痛点的解决方案,避开常见坑;
-
开发上:熟练掌握SpringBoot整合Kafka,手动提交Offset、分区指定等核心技能,能够快速落地企业级需求。
随着Kafka逐步剥离ZooKeeper依赖,自研KRaft协议管理元数据,未来它的部署和维护成本会更低,性能也会进一步提升。对于开发者而言,"理论+实战"结合,才能真正玩转Kafka,在分布式系统开发中发挥它的最大价值。