线程模型是Java高并发系统的核心基石,多数开发者对线程的使用停留在new Thread、Executors创建线程池的表层,对底层内核实现、调度机制、内存语义一知半解,导致线上频繁出现线程池打满、上下文切换过载、死锁、内存泄漏等疑难问题。本文从操作系统内核原理出发,逐层拆解Java线程模型的底层实现,再到生产环境的架构级选型,配合实战代码,打通从底层原理到业务落地的全链路。
一、操作系统线程模型的核心本质
进程是操作系统进行资源分配(内存、文件句柄、CPU时间片)的最小单位,线程是操作系统进行CPU调度执行的最小单位。一个进程内可包含多个线程,共享进程的内存、文件句柄等资源,线程本身仅拥有程序计数器、栈、寄存器等极少的独立资源。
操作系统主流实现了三大线程模型,直接决定了上层语言的并发能力边界:
-
用户级线程(ULT):线程的创建、调度、销毁完全在用户态完成,操作系统内核无感知,切换无需陷入内核态,开销极低。优势是切换快、支持大规模线程数量;缺陷是线程阻塞会导致整个进程阻塞,无法利用多核CPU的并行能力。
-
内核级线程(KLT):线程的创建、调度、销毁都由操作系统内核完成,内核负责线程的上下文切换,每个线程都有独立的内核态栈和用户态栈。优势是可利用多核CPU并行,单个线程阻塞不会影响整个进程;缺陷是线程切换需要用户态与内核态的切换,开销较大,大规模线程会耗尽系统资源。
-
混合线程模型:结合ULT和KLT的优势,用户态创建多个线程,映射到内核态的少量线程上,即M:N映射。用户态线程的调度由运行时完成,内核态线程负责CPU调度,既降低了切换开销,又能充分利用多核能力,Go的goroutine、JDK虚拟线程均基于此模型实现。
二、Java线程模型的底层实现与演进
2.1 Java线程模型的演进历史
-
JDK 1.2之前:采用绿色线程(Green Thread),属于用户级线程,由JVM自行调度,不依赖操作系统内核,单核时代有一定优势,但无法利用多核CPU,线程阻塞会导致整个进程挂起,JDK1.2之后正式废弃。
-
JDK 1.2及以后:在Linux x86_64、Windows等主流操作系统上,HotSpot虚拟机采用1:1的内核线程模型 ,即一个
java.lang.Thread实例,直接对应一个操作系统的内核线程,Java线程的生命周期与内核线程完全绑定。
2.2 HotSpot中Java线程的创建流程
当代码中执行new Thread()时,仅在JVM堆中创建了一个Java对象,并未创建真正的操作系统线程;只有调用Thread.start()方法时,才会通过JNI调用HotSpot的JVM_StartThread函数,完成内核线程的创建,完整流程如下:
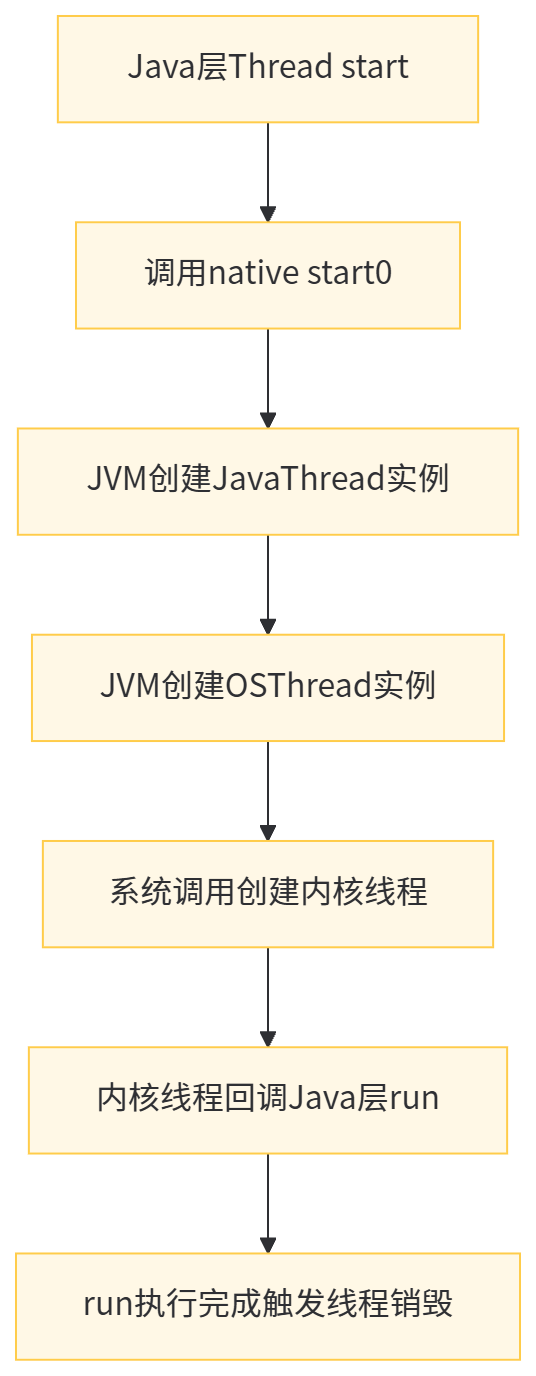
HotSpot中,JavaThread是JVM层对Java线程的抽象,存储了线程的Java对象引用、栈信息、中断状态等;OSThread是对操作系统内核线程的抽象,存储了内核线程的句柄、优先级、状态等,二者一一对应,共同完成Java线程的生命周期管理。
2.3 Java线程的调度机制
Java线程的调度完全由操作系统内核完成,主流采用时间片轮转的调度策略,内核为每个就绪的线程分配CPU时间片,时间片用完后触发上下文切换,CPU切换到其他就绪线程执行。
Java提供了Thread.setPriority(int)方法设置线程优先级,取值范围1-10,默认优先级5。但Java的优先级仅为给操作系统的调度权重提示,并非绝对的执行顺序,不同操作系统的优先级映射存在差异:
-
Linux系统:Java的1-10优先级映射到nice值(-20到19),优先级越高,nice值越低,调度权重越高
-
Windows系统:Java的1-10优先级映射到Windows的7个优先级等级,存在优先级合并的情况
核心提醒:绝对不能依赖线程优先级实现业务逻辑,不同操作系统的映射规则不同,甚至可能完全忽略优先级设置。
2.4 线程上下文切换的底层开销
线程上下文切换,是指CPU从一个线程切换到另一个线程执行的过程,必须经历用户态到内核态的切换,核心开销来自三个维度:
-
寄存器上下文保存与恢复:需要保存当前线程的程序计数器、CPU寄存器、栈指针等状态,恢复下一个线程的对应状态
-
内存缓存失效:CPU的L1/L2/L3缓存、TLB(快表)是针对当前线程的,切换后缓存失效,需要重新从内存加载数据,访问延迟大幅提升
-
内核调度开销:操作系统调度器需要遍历就绪线程队列,选择下一个要执行的线程,更新调度数据结构
根据Linux内核测试数据,一次线程上下文切换的开销约1-5微秒,看似微小,但当系统存在数千个线程时,每秒上下文切换次数可达数百万次,累计CPU开销可占到总CPU时间的30%以上,直接导致系统吞吐量大幅下降。
三、Java线程核心机制的底层原理与正确用法
3.1 Java线程的生命周期
Java线程有6个明确的状态,定义在Thread.State枚举中,状态流转规则如下:
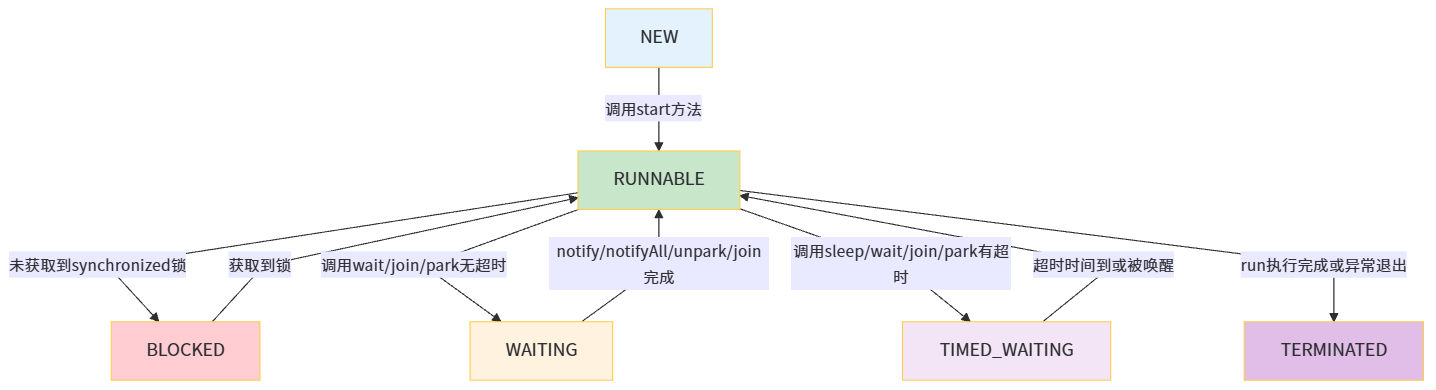
-
NEW :新建状态,
new Thread()之后,未调用start() -
RUNNABLE:可运行状态,包含正在CPU上执行的Running状态,和等待CPU调度的Ready状态
-
BLOCKED :阻塞状态,等待获取
synchronized监视器锁 -
WAITING :无限等待状态,调用无超时的
wait()、join()、park()方法,需被主动唤醒 -
TIMED_WAITING:超时等待状态,调用带超时的等待方法,超时后自动唤醒
-
TERMINATED :终止状态,
run()方法执行完成或异常退出
3.2 等待唤醒机制的底层实现与正确用法
Java提供了两套等待唤醒机制,分别是基于对象监视器的wait/notify/notifyAll,和基于Unsafe的park/unpark,二者底层实现和使用规则有本质区别,是高频混淆点。
3.2.1 wait/notify/notifyAll
基于对象监视器(Monitor)实现,底层是操作系统的条件变量与互斥锁,核心规则如下:
-
必须在
synchronized同步块或同步方法中调用,否则会抛出IllegalMonitorStateException -
调用
wait()方法后,当前线程会释放持有的监视器锁,进入对象的等待队列 -
notify()随机唤醒等待队列中的一个线程,notifyAll()唤醒所有等待线程,被唤醒的线程需重新竞争监视器锁,竞争成功后才能继续执行 -
存在虚假唤醒问题,即线程未被
notify/notifyAll唤醒就从wait()返回,因此必须在while循环中判断等待条件,而非if判断package com.jam.demo.thread;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StringUtils;/**
-
等待唤醒机制正确用法示例
-
@author ken
*/
@Slf4j
public class WaitNotifyDemo {
private static final Object LOCK = new Object();
private static String message;public static void main(String[] args) throws InterruptedException {
Thread consumerThread = new Thread(WaitNotifyDemo::consume, "consumer-thread");
consumerThread.start();Thread.sleep(1000); Thread producerThread = new Thread(WaitNotifyDemo::produce, "producer-thread"); producerThread.start();}
/**
- 消费消息
*/
private static void consume() {
synchronized (LOCK) {
// 必须用while循环判断条件,防止虚假唤醒
while (!StringUtils.hasText(message)) {
try {
log.info("消息为空,进入等待状态");
LOCK.wait();
} catch (InterruptedException e) {
log.error("消费线程被中断", e);
// 恢复中断标志位
Thread.currentThread().interrupt();
return;
}
}
log.info("消费到消息:{}", message);
}
}
/**
- 生产消息
*/
private static void produce() {
synchronized (LOCK) {
message = "Hello Java Thread Model";
log.info("消息生产完成,唤醒等待线程");
LOCK.notifyAll();
}
}
}
- 消费消息
-
3.2.2 park/unpark
基于Unsafe类实现,底层是Linux的futex(快速用户态互斥锁)系统调用,无需依赖监视器锁,使用更灵活,核心特性如下:
-
无需在同步块中调用,可在任意位置使用
-
park()方法阻塞当前线程,unpark(Thread thread)方法唤醒指定线程 -
支持「先唤醒,后阻塞」,即先调用
unpark()再调用park(),线程不会阻塞,而wait/notify不支持该特性 -
park()方法响应中断,但不会抛出InterruptedException,仅设置中断标志位,需用户自行判断package com.jam.demo.thread;
import lombok.extern.slf4j.Slf4j;
import sun.misc.Unsafe;import java.lang.reflect.Field;
/**
-
park/unpark机制示例
-
@author ken
*/
@Slf4j
public class ParkUnparkDemo {
private static final Unsafe UNSAFE;static {
try {
Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeField.setAccessible(true);
UNSAFE = (Unsafe) theUnsafeField.get(null);
} catch (Exception e) {
throw new RuntimeException("Unsafe实例获取失败", e);
}
}public static void main(String[] args) throws InterruptedException {
Thread threadA = new Thread(() -> {
log.info("线程A开始执行,准备调用park阻塞");
// 阻塞当前线程
UNSAFE.park(false, 0L);
log.info("线程A被唤醒,继续执行");
// 判断是否被中断唤醒
if (Thread.currentThread().isInterrupted()) {
log.info("线程A是被中断唤醒的");
}
}, "thread-A");
threadA.start();Thread.sleep(1000); log.info("主线程调用unpark唤醒线程A"); // 唤醒指定线程 UNSAFE.unpark(threadA); // 演示先unpark再park,不会阻塞 Thread threadB = new Thread(() -> { try { Thread.sleep(1000); log.info("线程B开始执行,调用park"); UNSAFE.park(false, 0L); log.info("线程B执行完成,没有被阻塞"); } catch (InterruptedException e) { log.error("线程B被中断", e); Thread.currentThread().interrupt(); } }, "thread-B"); threadB.start(); log.info("主线程先调用unpark唤醒线程B"); UNSAFE.unpark(threadB);}
}
-
3.3 线程中断机制的正确用法
Java线程的中断是协作式中断机制,并非强制终止线程,仅给线程设置一个中断标志位,线程需自行检查标志位,决定是否终止执行。核心方法的区别如下:
-
public void interrupt():实例方法,给目标线程设置中断标志位,不会强制终止线程。若目标线程处于WAITING/TIMED_WAITING状态,会抛出InterruptedException,同时清除中断标志位。 -
public boolean isInterrupted():实例方法,检查当前线程的中断标志位,不会清除标志位。 -
public static boolean interrupted():静态方法,检查当前线程的中断标志位,调用后会清除中断标志位 ,这是与isInterrupted()的核心区别。
Thread.stop()方法已被废弃,该方法会强制终止线程,释放所有持有的锁,导致数据不一致,绝对不能用于线程终止。正确的线程终止方式如下:
package com.jam.demo.thread;
import lombok.extern.slf4j.Slf4j;
/**
* 线程正确终止示例
*
* @author ken
*/
@Slf4j
public class ThreadInterruptDemo {
public static void main(String[] args) throws InterruptedException {
TaskRunner taskRunner = new TaskRunner();
Thread taskThread = new Thread(taskRunner, "task-thread");
taskThread.start();
// 让任务线程执行5秒
Thread.sleep(5000);
// 发送中断信号,终止线程
log.info("主线程发送中断信号");
taskThread.interrupt();
// 等待任务线程终止
taskThread.join();
log.info("任务线程已终止,程序退出");
}
/**
* 任务执行器
*/
@Slf4j
static class TaskRunner implements Runnable {
@Override
public void run() {
// 循环检查中断标志位,决定是否继续执行
while (!Thread.currentThread().isInterrupted()) {
try {
log.info("任务正在执行");
// 模拟业务处理
Thread.sleep(1000);
} catch (InterruptedException e) {
log.error("任务线程被中断,准备退出", e);
// 捕获InterruptedException后,中断标志位会被清除,需要重新设置中断标志位
Thread.currentThread().interrupt();
// 退出循环
break;
}
}
log.info("任务执行器退出");
}
}
}3.4 ThreadLocal的底层原理与内存泄漏规避
ThreadLocal是线程本地变量,每个线程都有独立的变量副本,线程之间互不影响。底层实现中,每个Thread线程都持有一个ThreadLocalMap,key是ThreadLocal实例本身(弱引用),value是线程本地的变量值。
内存泄漏的核心原因 :ThreadLocalMap的Entry继承了WeakReference,key是ThreadLocal的弱引用,当ThreadLocal没有外部强引用时,key会被GC回收,但value是强引用,只要线程一直存在(比如线程池的核心线程),value就永远不会被GC回收,最终导致内存泄漏。
正确使用规范 :每次使用完ThreadLocal后,必须在finally块中调用remove()方法,手动清除对应的Entry,避免内存泄漏。
package com.jam.demo.thread;
import lombok.extern.slf4j.Slf4j;
/**
* ThreadLocal正确用法示例
*
* @author ken
*/
@Slf4j
public class ThreadLocalDemo {
private static final ThreadLocal<String> USER_CONTEXT = new ThreadLocal<>();
public static void main(String[] args) {
try {
// 设置线程本地变量
USER_CONTEXT.set("user-123456");
log.info("当前线程用户上下文:{}", USER_CONTEXT.get());
// 执行业务逻辑
handleBusiness();
} finally {
// 必须在finally中调用remove,确保一定会执行,避免内存泄漏
USER_CONTEXT.remove();
log.info("ThreadLocal已清除,清除后的值:{}", USER_CONTEXT.get());
}
}
private static void handleBusiness() {
log.info("业务逻辑处理,获取用户上下文:{}", USER_CONTEXT.get());
}
}四、线程池的底层原理与架构级选型
线程池是Java并发编程的核心工具,通过池化技术复用线程,减少线程创建与销毁的开销,同时控制线程的最大数量,避免系统资源耗尽。
4.1 ThreadPoolExecutor的核心参数与任务提交流程
ThreadPoolExecutor是Java线程池的核心实现,包含7个核心参数:
-
corePoolSize:核心线程数,线程池中长期保留的线程数量,即使空闲也不会被回收,除非设置了allowCoreThreadTimeOut -
maximumPoolSize:最大线程数,线程池允许创建的最大线程数量 -
keepAliveTime:非核心线程的空闲存活时间,超过该时间,非核心线程会被回收 -
unit:keepAliveTime的时间单位 -
workQueue:工作队列,用于存储等待执行的任务,常用实现有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、DelayedWorkQueue -
threadFactory:线程工厂,用于创建线程,建议自定义线程工厂,设置线程名称前缀,方便线上排查问题 -
handler:拒绝策略,当线程池和工作队列都满了,无法处理新任务时的处理策略,JDK提供4种默认策略:AbortPolicy(默认,抛出异常)、CallerRunsPolicy(调用者线程执行)、DiscardPolicy(直接丢弃任务)、DiscardOldestPolicy(丢弃最旧的任务,重试提交)
线程池的任务提交流程是架构选型的核心,直接决定了线程池的行为特性,完整流程如下:
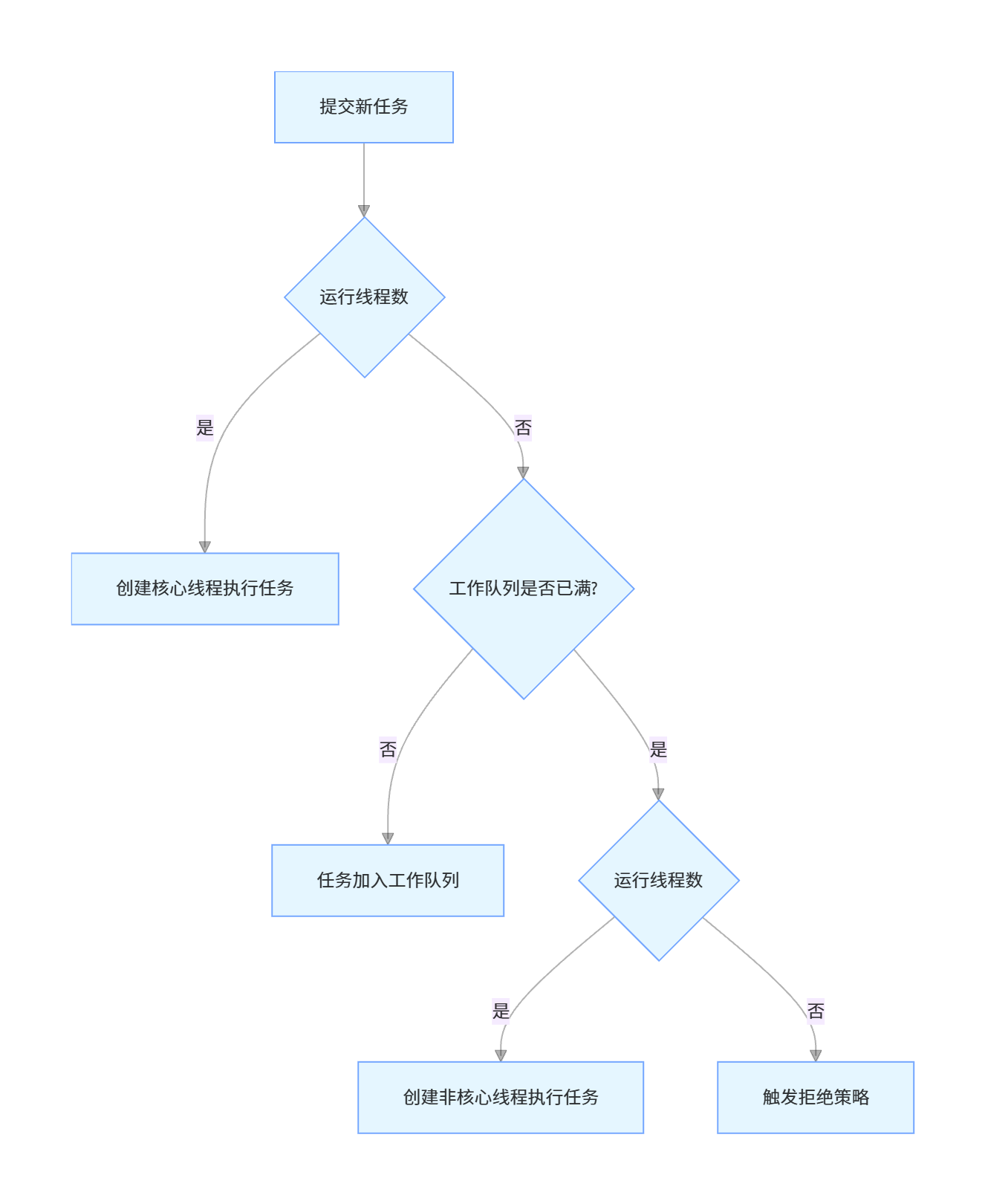
4.2 不同业务场景的线程池架构选型
线程池参数没有万能配置,必须根据任务的类型(CPU密集型、IO密集型、混合型)进行针对性选型,核心目标是平衡CPU利用率、系统吞吐量与任务延迟。
4.2.1 CPU密集型任务选型
CPU密集型任务的核心特征是任务主要执行计算操作,CPU利用率高,无IO阻塞,比如加密解密、数据计算、内存操作等。 核心选型目标 :减少上下文切换,最大化CPU利用率 核心参数配置:
-
corePoolSize= CPU核心数 + 1(+1是为了防止线程出现页缺失或其他异常时,备用线程可以顶上,保证CPU利用率) -
maximumPoolSize=corePoolSize,避免创建非核心线程,减少上下文切换 -
workQueue:使用有界队列,队列长度建议设置为corePoolSize * 2,避免队列过长导致任务延迟过高 -
拒绝策略:建议使用
CallerRunsPolicy,让调用者线程执行任务,起到背压作用,避免任务丢失
4.2.2 IO密集型任务选型
IO密集型任务的核心特征是任务大部分时间在等待IO完成,CPU利用率低,比如数据库查询、RPC调用、文件读写、网络请求等。 核心选型目标 :提高系统吞吐量,充分利用CPU资源,避免线程阻塞导致CPU空闲 核心参数配置 : 采用Brain Goetz(Java并发编程实战作者)的经典公式: corePoolSize = CPU核心数 * 目标CPU利用率 * (1 + 平均等待时间 / 平均计算时间) 示例:8核CPU,目标CPU利用率80%,任务平均等待时间100ms,平均计算时间10ms,那么corePoolSize = 8 * 0.8 * (1 + 100/10) = 70.4,约70个核心线程
-
maximumPoolSize:建议设置为corePoolSize的2倍,或根据压测结果设置,避免创建过多线程 -
workQueue:使用有界队列,队列长度建议设置为corePoolSize的50%,避免队列过长导致任务延迟 -
拒绝策略:建议自定义拒绝策略,记录日志、触发告警,或执行降级逻辑,避免任务丢失
4.2.3 混合型任务选型
核心选型策略:线程池隔离,将CPU密集型和IO密集型任务拆分到两个独立的线程池,避免互相影响。比如IO密集型任务阻塞了线程,导致CPU密集型任务无法执行,造成CPU资源浪费。
4.3 生产级线程池最佳实践与实战代码
4.3.1 强制规范
-
禁止使用
Executors创建线程池,必须通过ThreadPoolExecutor自定义线程池。Executors创建的线程池存在OOM风险:newFixedThreadPool使用无界队列,newCachedThreadPool的最大线程数为Integer.MAX_VALUE,都会在高并发下堆积任务或创建大量线程,最终导致OOM。 -
必须自定义线程工厂,设置线程名称前缀,方便线上排查问题。
-
必须使用有界队列,避免任务无限堆积导致OOM。
-
不同业务模块、不同类型的任务必须使用独立的线程池,做好隔离,避免一个模块故障影响整个应用。
-
必须开启线程池监控,监控指标包括活跃线程数、队列长度、已完成任务数、拒绝任务数等,设置告警阈值,及时发现问题。
4.3.2 项目依赖配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam.demo</groupId>
<artifactId>thread-model-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>thread-model-demo</name>
<properties>
<java.version>17</java.version>
<mybatis-plus.version>3.5.6</mybatis-plus.version>
<fastjson2.version>2.0.49</fastjson2.version>
<guava.version>33.1.0-jre</guava.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>4.3.3 线程池配置类
package com.jam.demo.config;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 线程池配置类
*
* @author ken
*/
@Configuration
@Slf4j
public class ThreadPoolConfig {
private static final int CPU_CORE_SIZE = Runtime.getRuntime().availableProcessors();
/**
* CPU密集型任务线程池
*/
@Bean("cpuIntensiveThreadPool")
public ThreadPoolExecutor cpuIntensiveThreadPool() {
return new ThreadPoolExecutor(
CPU_CORE_SIZE + 1,
CPU_CORE_SIZE + 1,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(CPU_CORE_SIZE * 2),
new ThreadFactoryBuilder().setNameFormat("cpu-intensive-pool-%d").setDaemon(false).build(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
/**
* IO密集型任务线程池
*/
@Bean("ioIntensiveThreadPool")
public ThreadPoolExecutor ioIntensiveThreadPool() {
int corePoolSize = (int) (CPU_CORE_SIZE * 0.8 * (1 + 100.0 / 10));
return new ThreadPoolExecutor(
corePoolSize,
corePoolSize * 2,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(corePoolSize / 2),
new ThreadFactoryBuilder().setNameFormat("io-intensive-pool-%d").setDaemon(false).build(),
(r, executor) -> {
// 自定义拒绝策略,记录日志,触发降级
log.error("IO密集型线程池已满,拒绝任务!活跃线程数:{},队列长度:{}",
executor.getActiveCount(), executor.getQueue().size());
throw new RuntimeException("系统繁忙,请稍后重试");
}
);
}
}4.3.4 异步业务实现
package com.jam.demo.service;
import com.jam.demo.entity.User;
import com.jam.demo.mapper.UserMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 异步用户服务
*
* @author ken
*/
@Service
@Slf4j
@RequiredArgsConstructor
public class AsyncUserService {
private final UserMapper userMapper;
private final ThreadPoolExecutor ioIntensiveThreadPool;
/**
* 异步查询用户信息
*
* @param userId 用户ID
* @return 用户信息CompletableFuture
*/
public CompletableFuture<User> queryUserByIdAsync(Long userId) {
return CompletableFuture.supplyAsync(() -> {
log.info("异步查询用户信息,userId:{}", userId);
return userMapper.selectById(userId);
}, ioIntensiveThreadPool);
}
/**
* 异步查询用户订单数
*
* @param userId 用户ID
* @return 订单数CompletableFuture
*/
public CompletableFuture<Integer> queryUserOrderCountAsync(Long userId) {
return CompletableFuture.supplyAsync(() -> {
log.info("异步查询用户订单数,userId:{}", userId);
// 模拟RPC调用查询订单系统
try {
Thread.sleep(50);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("查询订单数失败", e);
}
return 10;
}, ioIntensiveThreadPool);
}
/**
* 聚合用户信息和订单数
*
* @param userId 用户ID
* @return 聚合结果
*/
public CompletableFuture<String> aggregateUserInfoAsync(Long userId) {
CompletableFuture<User> userFuture = queryUserByIdAsync(userId);
CompletableFuture<Integer> orderCountFuture = queryUserOrderCountAsync(userId);
return userFuture.thenCombine(orderCountFuture, (user, orderCount) -> {
log.info("聚合用户信息,userId:{}", userId);
return String.format("用户名:%s,订单数:%d", user.getUserName(), orderCount);
}).exceptionally(e -> {
log.error("聚合用户信息失败,userId:{}", userId, e);
return "用户信息查询失败";
});
}
}4.3.5 接口层实现
package com.jam.demo.controller;
import com.jam.demo.service.AsyncUserService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.CompletableFuture;
/**
* 用户查询控制器
*
* @author ken
*/
@RestController
@RequestMapping("/api/user")
@Slf4j
@RequiredArgsConstructor
@Tag(name = "用户管理", description = "用户相关接口")
public class UserController {
private final AsyncUserService asyncUserService;
/**
* 异步查询用户聚合信息
*
* @param userId 用户ID
* @return 用户聚合信息
*/
@GetMapping("/{userId}/info")
@Operation(summary = "查询用户聚合信息", description = "异步查询用户信息和订单数,聚合返回")
public CompletableFuture<String> getUserInfo(
@Parameter(description = "用户ID", required = true) @PathVariable Long userId) {
log.info("收到查询用户信息请求,userId:{}", userId);
return asyncUserService.aggregateUserInfoAsync(userId);
}
}4.3.6 持久层实现
用户实体类:
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
/**
* 用户实体类
*
* @author ken
*/
@Data
@TableName("t_user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 用户ID
*/
@TableId(type = IdType.AUTO)
private Long userId;
/**
* 用户名
*/
private String userName;
/**
* 年龄
*/
private Integer age;
/**
* 邮箱
*/
private String email;
}Mapper接口:
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.User;
import org.apache.ibatis.annotations.Mapper;
/**
* 用户Mapper
*
* @author ken
*/
@Mapper
public interface UserMapper extends BaseMapper<User> {
}MySQL建表语句:
CREATE TABLE `t_user` (
`user_id` bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(64) NOT NULL COMMENT '用户名',
`age` int DEFAULT NULL COMMENT '年龄',
`email` varchar(128) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';五、高并发场景下的线程模型进阶选型
5.1 传统1:1线程模型的瓶颈
传统1:1内核线程模型在高并发IO密集型场景下存在明显瓶颈:大量线程会因为IO阻塞而挂起,操作系统需要频繁切换线程,导致上下文切换开销巨大,系统吞吐量上不去。同时,操作系统对内核线程的数量有上限,无法支持百万级别的并发连接,无法满足网关、消息推送等超高并发场景的需求。
5.2 虚拟线程的核心原理与选型建议
虚拟线程是JVM层面实现的用户级线程,采用M:N的混合线程模型,多个虚拟线程映射到少量的操作系统内核线程(载体线程)上。当虚拟线程执行IO操作阻塞时,JVM会将该虚拟线程从载体线程上卸载,载体线程可以执行其他虚拟线程;当IO操作完成后,虚拟线程会被重新挂载到载体线程上继续执行。整个过程无需操作系统的线程上下文切换,开销极低,支持百万级别的虚拟线程,不会导致系统资源耗尽。
虚拟线程的适用场景:
-
纯IO密集型业务,比如网关、接口聚合、数据库查询、RPC调用等,大部分时间线程都在阻塞等待IO完成
-
同步代码风格的异步编程,无需修改业务代码,仅需把任务提交到虚拟线程执行器,即可获得极高的吞吐量,避免回调地狱
虚拟线程的不适用场景:
-
CPU密集型任务,虚拟线程不会减少CPU的计算开销,反而会增加JVM的调度开销
-
长时间占用CPU的任务,会导致载体线程被占用,其他虚拟线程无法执行,出现线程饥饿
5.3 最终架构选型建议
-
对于JDK8/JDK17的应用,IO密集型场景优先使用自定义的动态线程池,做好线程池隔离、监控、告警,根据压测结果优化参数。
-
对于可升级JDK21+的应用,IO密集型场景优先使用虚拟线程,大幅提升系统吞吐量,简化异步编程模型。
-
CPU密集型场景,始终使用传统的内核线程池,线程数设置为CPU核心数+1,减少上下文切换。
-
混合型业务,必须做好线程池隔离,CPU密集型和IO密集型任务使用独立的线程池,避免互相影响。
-
低延迟交易场景,使用线程CPU亲和性绑定,减少上下文切换,采用无锁设计,避免线程阻塞。
5.4 高频坑点与避坑指南
-
线程泄露:线程池中的任务出现无限阻塞(死锁、无限循环、网络请求无超时),导致线程无法被回收,线程数不断上涨最终OOM。避坑方案:所有阻塞操作必须设置超时时间,线程池做好监控,设置最大线程数告警。
-
上下文切换爆炸:线程数设置过多,导致系统每秒上下文切换次数超过百万次,CPU sys占用过高,TPS上不去。避坑方案:根据任务类型设置合理的线程数,优先优化IO操作,减少线程阻塞时间。
-
死锁 :多个线程互相等待对方持有的锁,导致所有线程都无法继续执行。避坑方案:固定锁的获取顺序,避免嵌套锁,使用
tryLock设置超时时间,线上用jstack定期排查死锁。 -
ThreadLocal内存泄漏 :线程池的线程用完ThreadLocal后未调用
remove(),导致value无法被GC。避坑方案:ThreadLocal必须在finally块中调用remove(),避免在线程池中使用ThreadLocal存储大对象。 -
线程池公用导致的雪崩:多个业务模块公用一个线程池,某个模块的慢任务占满了线程池,导致其他模块的任务无法执行。避坑方案:不同业务模块、不同类型的任务必须使用独立的线程池,做好隔离。
六、总结
Java线程模型的本质,是JVM对操作系统线程模型的封装与实现,主流HotSpot虚拟机采用1:1的内核线程模型,每个Java线程对应一个操作系统内核线程,线程的调度与切换由操作系统内核完成,存在用户态到内核态的切换开销。
理解线程模型的底层原理,是高并发系统架构选型的基础。只有搞懂了线程的创建、调度、阻塞、唤醒的底层机制,才能合理设计线程池参数,选择合适的线程模型,避免线上的各种疑难问题。
生产环境的线程模型选型,核心是匹配业务场景:CPU密集型场景追求最小的上下文切换,IO密集型场景追求最高的吞吐量,混合型场景做好线程池隔离,高并发IO场景优先考虑虚拟线程方案。所有的技术选型都要落地到业务,通过压测验证选型的合理性,做好监控与告警,才能保证系统的长期稳定运行。