PostgreSQL MVCC 深度解析:三事务并发全流程
本文以三个并发事务为主线,逐步骤、逐字段拆解 PostgreSQL MVCC(多版本并发控制)的完整工作过程。涵盖 INSERT/UPDATE/SELECT 时页面字段的逐一变化、快照的精确比较规则、提示位写回机制、两种隔离级别的行为差异,以及与 MySQL MVCC 的本质对比。
文章目录
- [PostgreSQL MVCC 深度解析:三事务并发全流程](#PostgreSQL MVCC 深度解析:三事务并发全流程)
-
- [1. MVCC 的核心思想](#1. MVCC 的核心思想)
- [2. 场景设定:三个事务](#2. 场景设定:三个事务)
- [3. 关键数据结构:tuple 头部字段](#3. 关键数据结构:tuple 头部字段)
- [4. 步骤一:T1 执行 INSERT](#4. 步骤一:T1 执行 INSERT)
- [5. 步骤二:T1 COMMIT](#5. 步骤二:T1 COMMIT)
- [6. 步骤三:T2 执行 UPDATE](#6. 步骤三:T2 执行 UPDATE)
- [7. 步骤四:T2 COMMIT](#7. 步骤四:T2 COMMIT)
- [8. 步骤五:T3 BEGIN,获取快照](#8. 步骤五:T3 BEGIN,获取快照)
- [9. 步骤六:T3 执行 SELECT,可见性逐 tuple 判断](#9. 步骤六:T3 执行 SELECT,可见性逐 tuple 判断)
-
- [9.1 判断 Tuple (0,1):xmin=100,xmax=101](#9.1 判断 Tuple (0,1):xmin=100,xmax=101)
- [9.2 判断 Tuple (0,2):xmin=101,xmax=0](#9.2 判断 Tuple (0,2):xmin=101,xmax=0)
- [9.3 可见性判断完整伪代码](#9.3 可见性判断完整伪代码)
- [10. 提示位(Hint Bits)写回机制](#10. 提示位(Hint Bits)写回机制)
-
- [10.1 为什么需要提示位](#10.1 为什么需要提示位)
- [10.2 写回时机](#10.2 写回时机)
- [10.3 提示位写回与 WAL 的关系](#10.3 提示位写回与 WAL 的关系)
- [10.4 三种访问路径速度对比](#10.4 三种访问路径速度对比)
- [11. 两种隔离级别下 T3 的行为差异](#11. 两种隔离级别下 T3 的行为差异)
-
- [11.1 Read Committed(默认隔离级别)](#11.1 Read Committed(默认隔离级别))
- [11.2 Repeatable Read](#11.2 Repeatable Read)
- [11.3 快照获取时机对比](#11.3 快照获取时机对比)
- [12. ROLLBACK 场景:T2 回滚后 T3 看到什么](#12. ROLLBACK 场景:T2 回滚后 T3 看到什么)
- [13. 与 MySQL InnoDB MVCC 的本质对比](#13. 与 MySQL InnoDB MVCC 的本质对比)
- [14. 总结:MVCC 的代价与收益](#14. 总结:MVCC 的代价与收益)
1. MVCC 的核心思想
MVCC 要解决的核心问题是:读写操作如何互不阻塞。
传统锁方案:读加共享锁,写加排他锁,读和写之间互相等待。
MVCC 的方案:写操作产生数据的新版本,读操作读旧版本,读和写看的是不同时间点的数据,互不阻塞。
PostgreSQL 实现 MVCC 的方式叫 Append-Only(追加写):
INSERT:在页面追加一个新 tupleUPDATE:不修改旧 tuple,在旧 tuple 头部打"删除标记",再追加新 tupleDELETE:不删除数据,只在 tuple 头部打"删除标记"SELECT:根据事务的快照(Snapshot)决定看哪个版本
这与 MySQL InnoDB 不同。InnoDB 是"原地修改 + Undo Log":UPDATE 直接覆盖数据页,旧版本存入独立的 Undo Log 文件。PostgreSQL 的旧版本就地保留在堆表页面,直到 VACUUM 清理。
2. 场景设定:三个事务
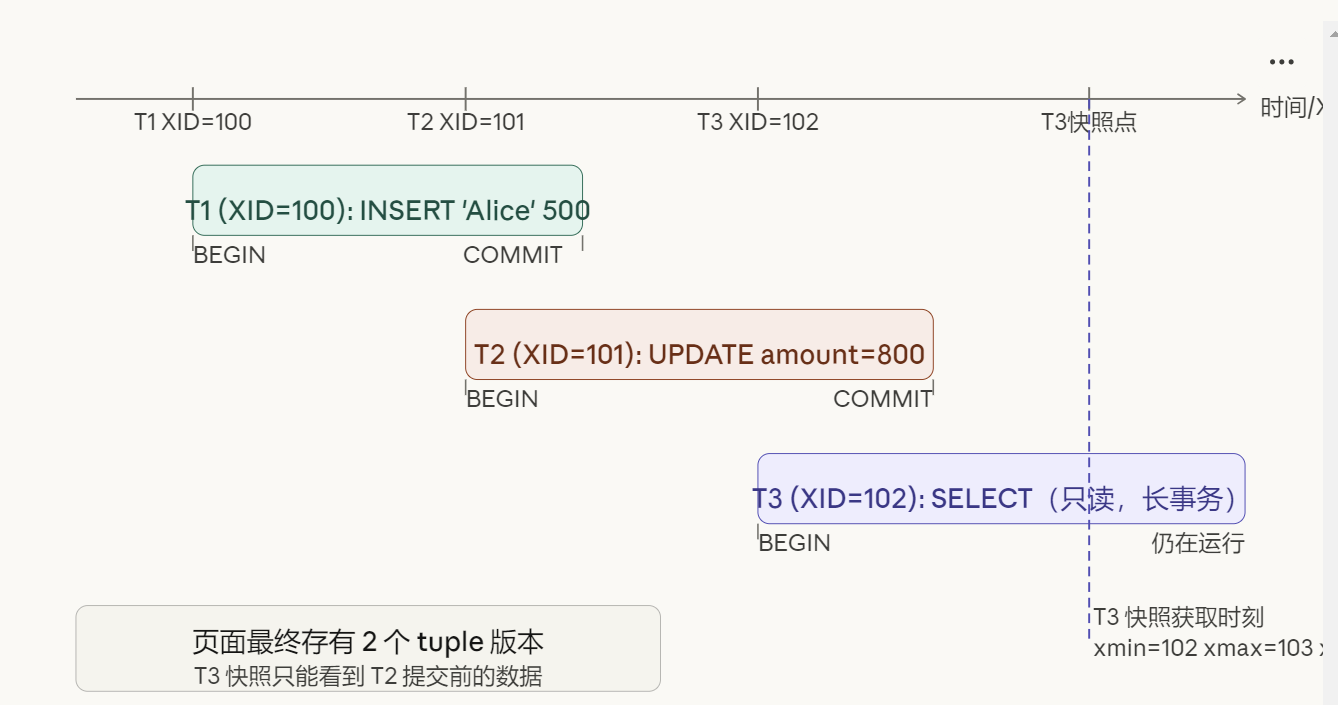
sql
-- 建表
CREATE TABLE accounts (
id integer,
name text,
balance numeric
);
-- T1:XID=100,INSERT 一行,然后提交
BEGIN; -- T1
INSERT INTO accounts VALUES (1, 'Alice', 500);
COMMIT;
-- T2:XID=101,UPDATE 这行,然后提交
BEGIN; -- T2
UPDATE accounts SET balance = 800 WHERE id = 1;
COMMIT;
-- T3:XID=102,长事务,执行 SELECT
BEGIN; -- T3,Repeatable Read 隔离级别
SELECT * FROM accounts WHERE id = 1;
-- ... T3 仍在运行 ...三个事务的 XID 分别是 100、101、102,依次递增,这是 PostgreSQL 全局单调递增的事务 ID 分配机制保证的。
3. 关键数据结构:tuple 头部字段
每个 HeapTuple(堆元组)的头部(HeapTupleHeader)包含以下 MVCC 相关字段:
HeapTupleHeader 布局(最小 23 字节):
偏移 0 4 8 14 18 19 23+
+------+------+------+-------+-----+------+--------+
|t_xmin|t_xmax|t_ctid|t_infom|t_off|nullbm| 用户数据|
+------+------+------+-------+-----+------+--------+
4字节 4字节 6字节 4字节 1字节 可变| 字段 | 大小 | 含义 |
|---|---|---|
t_xmin |
4 字节 | 创建此版本的事务 XID(INSERT/UPDATE 新版本时设置) |
t_xmax |
4 字节 | 删除此版本的事务 XID(DELETE/UPDATE 旧版本时设置);0 = 未删除 |
t_ctid |
6 字节 | (页号, 槽号) 格式;对最新版本指向自身;UPDATE 后旧版本指向新版本 |
t_infomask |
2+2 字节 | 信息位,含提示位(hint bits),缓存事务状态避免重复查 CLOG |
t_hoff |
1 字节 | 头部总长度,用户数据从此偏移开始 |
| null bitmap | 可变 | 每列一 bit,标记 NULL 列;仅当 HEAP_HASNULL 设置时存在 |
infomask 中最重要的四个提示位:
| bit 掩码 | 名称 | 含义 |
|---|---|---|
0x0100 |
XMIN_COMMITTED |
xmin 事务已提交(缓存结论,避免查 CLOG) |
0x0200 |
XMIN_INVALID |
xmin 事务已中止或为虚拟 ID |
0x0400 |
XMAX_COMMITTED |
xmax 事务已提交(此版本已被成功删除) |
0x0800 |
XMAX_INVALID |
xmax 无效(值为 0 或事务已中止),表示行未被删除 |
4. 步骤一:T1 执行 INSERT
sql
BEGIN;
INSERT INTO accounts VALUES (1, 'Alice', 500);
-- XID = 100
PostgreSQL 执行 INSERT 时,内部发生了什么:
第一步:分配事务 XID
执行第一条写操作时,从全局 XID 计数器(位于共享内存)分配一个新 XID = 100,写入当前 backend 进程的 ProcArray 条目,表示"XID=100 的事务正在运行"。
第二步:查询 FSM 找目标页
FSM(空闲空间映射文件)以近似精度记录了每个页面的可用空间。查 FSM 得到 Page 0 有足够空间,将 Page 0 载入 shared_buffers。
第三步:在页面内分配空间
pd_upper 向低地址移动 tuple_size 字节,pd_lower 向高地址移动 4 字节(一个 ItemId)。分配槽位 1,lp_flags = 1(normal),lp_off 指向 tuple 的起始偏移。
第四步:写入 tuple 字段
t_xmin = 100 // 我是 T1 创建的
t_xmax = 0 // 尚未被删除
t_ctid = (0, 1) // 指向自身((页号0, 槽号1))
infomask:
XMAX_INVALID = 1 // xmax=0 无效,表示行活跃
XMIN_COMMITTED = 0 // 提示位未设,T1 尚未提交
XMIN_INVALID = 0
HEAP_HASVARWIDTH = 1 // 有变长列(text, numeric)
t_hoff = 24 // 头部 24 字节(无 null bitmap,数据对齐后)第五步:写用户数据
从 t_hoff 偏移处开始按列顺序写入:
id = 1:int4,4 字节,4 字节对齐name = 'Alice':text,varlena 头(1 字节)+ 5 字节数据 = 6 字节balance = 500:numeric,变长,约 8~16 字节
第六步:写 WAL
将上述页面修改(新 tuple 的内容)写入 WAL(Write-Ahead Log),确保在 COMMIT 之前日志已持久化。这保证了即使在 COMMIT 后立即断电,重启时也能通过重放 WAL 恢复。
5. 步骤二:T1 COMMIT
sql
COMMIT; -- T1 提交COMMIT 的物理实现极其轻量,只做一件事:
在 CLOG 文件(PGDATA/pg_xact/ 目录,即提交日志)中,将 XID=100 对应的 2 bit 从 00(进行中)改为 01(已提交)。
CLOG 中 XID=100 的 2 bit:00 → 01(已提交)COMMIT 不修改任何数据页面。 页面中 tuple 的 XMIN_COMMITTED 提示位此时仍为 0。这是 PostgreSQL 设计上的权衡:若 COMMIT 时遍历所有被修改的页面写回提示位,代价太高(可能已不在 buffer cache 中)。
从 ProcArray 中移除 XID=100,其他事务此后不再能在 ProcArray 中找到它。
6. 步骤三:T2 执行 UPDATE
sql
BEGIN;
UPDATE accounts SET balance = 800 WHERE id = 1;
-- XID = 101T2 的 UPDATE 等价于"标记删除旧版本 + 插入新版本",在页面内产生两个 tuple。
第一步:找到目标 tuple
通过全表扫描或索引找到 tuple (0,1),发现 t_xmax = 0 且 XMAX_INVALID = 1,确认此行未被删除,是当前有效版本。
同时还要确认 t_xmin = 100 对应的 T1 已提交:检查 XMIN_COMMITTED 提示位为 0(未设),则查 CLOG,发现 XID=100 已提交,将 XMIN_COMMITTED 写回 infomask(这就是提示位的写回时机)。
第二步:修改旧 tuple (0,1)
t_xmax = 101 // T2 标记删除此版本
infomask:
XMAX_INVALID = 0 // 清除 invalid 标记,xmax 现在有意义
XMAX_COMMITTED = 0 // T2 尚未提交,先不设置
XMIN_COMMITTED = 1 // 刚才写回的提示位
t_ctid = (0, 2) // 改写!指向即将写入的新版本注意:t_ctid 从 (0,1)(指向自身)改写为 (0,2)(指向新版本),这是版本链的建立时刻。
第三步:追加新 tuple (0,2)
在同一页面(若有空间)或新页面追加新 tuple:
t_xmin = 101 // T2 创建此版本
t_xmax = 0 // 未删除
t_ctid = (0, 2) // 指向自身
infomask:
XMIN_COMMITTED = 0 // T2 尚未提交
XMAX_INVALID = 1 // xmax 无效(未删除)
HEAP_UPDATED = 1 // 标记此 tuple 由 UPDATE 产生(非首次插入)
用户数据:
id = 1, name = 'Alice', balance = 800 // balance 已更新第四步:更新索引
若 balance 列有索引,则在索引中新增条目 (800, TID=(0,2));旧条目 (500, TID=(0,1)) 暂时保留(VACUUM 清理时再删)。若 id 列有索引(balance 没变化而只是修改了 balance),且满足 HOT 条件(同页且被修改列无索引),则不需要修改任何索引,走 HOT 路径。
7. 步骤四:T2 COMMIT
sql
COMMIT; -- T2 提交同 T1 COMMIT:在 CLOG 中将 XID=101 的 2 bit 置为 01(已提交),从 ProcArray 移除,数据页面不变。
此时页面状态如下:

页面内完整状态(T2 COMMIT 后):
Page 0 页头:lower=160 upper=7980 special=8192
槽1:normal offset=8116 len=44
槽2:normal offset=8072 len=44
Tuple (0,1): Tuple (0,2):
t_xmin = 100 t_xmin = 101
t_xmax = 101 t_xmax = 0
t_ctid = (0, 2) ←版本链 t_ctid = (0, 2) ←自身
infomask: infomask:
XMIN_COMMITTED = 1 XMIN_COMMITTED = 0 ←待写回
XMAX_COMMITTED = 0 ←待写回 XMAX_INVALID = 1
data: balance=500(旧) data: balance=800(新)两个 tuple 物理共存。旧 tuple 并没有被标记 "废弃" 的特殊位,它的死活完全由 xmin/xmax 的事务状态决定,这正是 MVCC 的精髓。
8. 步骤五:T3 BEGIN,获取快照
sql
BEGIN ISOLATION LEVEL REPEATABLE READ;
-- T3 第一条语句执行时获取快照
SELECT pg_current_snapshot();
-- 输出:102:103:102快照的三个字段:
xmin = 102 最老活跃事务 XID。
所有 XID < 102 的事务:要么已提交,要么已中止,均已完成。
T1(100) 和 T2(101) 均 < 102,所以它们的结果都"有机会"可见。
xmax = 103 当前已分配的最大 XID + 1,即下一个将被分配的 XID。
所有 XID >= 103 的事务尚未开始或刚开始,对当前快照不可见。
xip_list = [102] 快照创建时所有活跃事务 XID 的列表(排除虚拟事务)。
102 是 T3 自己,虽然在 [xmin,xmax) 范围内,但在 xip_list 中,
所以 T3 自己的修改遵循特殊规则(由 cmin/cmax 控制)。快照是怎么获取的:
PostgreSQL 加一把短暂的 ProcArray 锁,读取当前所有活跃后端进程的 XID 列表,构造上述三元组,存储在当前进程的内存中。整个过程在共享内存中完成,极快。
9. 步骤六:T3 执行 SELECT,可见性逐 tuple 判断

sql
SELECT * FROM accounts WHERE id = 1;执行引擎对 Page 0 发起全表扫描(无索引时),逐个 tuple 判断可见性:
9.1 判断 Tuple (0,1):xmin=100,xmax=101
第一步:判断 xmin=100 是否可见
- 检查 infomask
XMIN_COMMITTEDbit:为 1(之前 T2 读取时写回的提示位) - 直接结论:xmin=100 已提交,跳过 CLOG 查询
第二步:将 xmin=100 与快照比较
100 < xmin(102):是,说明 T1 在快照获取之前就已经完成- 结论:T1 的修改在快照范围内
第三步:判断 xmax=101 是否可见
- 检查 infomask
XMAX_COMMITTEDbit:为 0(T2 提交了,但提示位尚未写回) - XID=101 在 xip_list 102 中?不在
- 查 CLOG:XID=101 状态为已提交
- 将
XMAX_COMMITTED = 1写回 tuple 的 infomask(提示位写回,产生脏页)
第四步:判断 xmax=101 对快照是否可见
101 < xmax(103):是101在 xip_list 102 中?不在- 结论:xmax=101(T2 的删除操作)在快照范围内,即"这行的删除"对 T3 可见
最终结论:xmin 可见 + xmax 可见 = 该 tuple 已被删除,T3 不可见
跳过 Tuple(0,1),不返回。
9.2 判断 Tuple (0,2):xmin=101,xmax=0
第一步:判断 xmin=101 是否可见
- 检查 infomask
XMIN_COMMITTEDbit:为 0(提示位未设) - XID=101 在 xip_list 102 中?不在
101 < xmax(103):是,XID=101 在快照范围内- 查 CLOG:XID=101 已提交
- 将
XMIN_COMMITTED = 1写回 infomask
第二步:判断 xmax=0 是否有效
检查 infomask XMAX_INVALID bit:为 1,表示 xmax 无效(未被删除)。
最终结论:xmin 可见 + xmax 无效(未删除)= Tuple(0,2) 对 T3 可见
返回数据:id=1, name='Alice', balance=800
9.3 可见性判断完整伪代码
python
def is_tuple_visible(tuple, snapshot):
# 步骤 1:判断 xmin
if tuple.infomask.XMIN_COMMITTED:
xmin_visible = True # 提示位已设,直接用
elif tuple.infomask.XMIN_INVALID:
return False # xmin 已中止,此版本从未存在
elif tuple.xmin in ProcArray.active_xids:
return False # xmin 仍活跃,未提交
else:
status = CLOG.get(tuple.xmin)
if status == COMMITTED:
tuple.infomask.XMIN_COMMITTED = 1 # 写回提示位
xmin_visible = True
else:
tuple.infomask.XMIN_INVALID = 1 # 写回提示位
return False
# xmin 可见,继续判断 xmax
# 步骤 2:判断 xmax
if tuple.xmax == 0 or tuple.infomask.XMAX_INVALID:
return True # 未删除,可见
if tuple.infomask.XMAX_COMMITTED:
xmax_in_snapshot = is_xid_visible_in_snapshot(tuple.xmax, snapshot)
return not xmax_in_snapshot # xmax 已提交且在快照范围内 = 已删除
else:
if tuple.xmax in ProcArray.active_xids:
return True # xmax 仍活跃,删除未提交,行仍可见
status = CLOG.get(tuple.xmax)
if status == COMMITTED:
tuple.infomask.XMAX_COMMITTED = 1
return not is_xid_visible_in_snapshot(tuple.xmax, snapshot)
else:
tuple.infomask.XMAX_INVALID = 1
return True # xmax 已中止,删除失败,行仍可见
def is_xid_visible_in_snapshot(xid, snapshot):
# xid 是否在快照的可见范围内
if xid < snapshot.xmin:
return True # 快照创建前已完成
if xid >= snapshot.xmax:
return False # 快照创建后才开始
if xid in snapshot.xip_list:
return False # 快照创建时仍活跃
return True # 在范围内且已完成10. 提示位(Hint Bits)写回机制
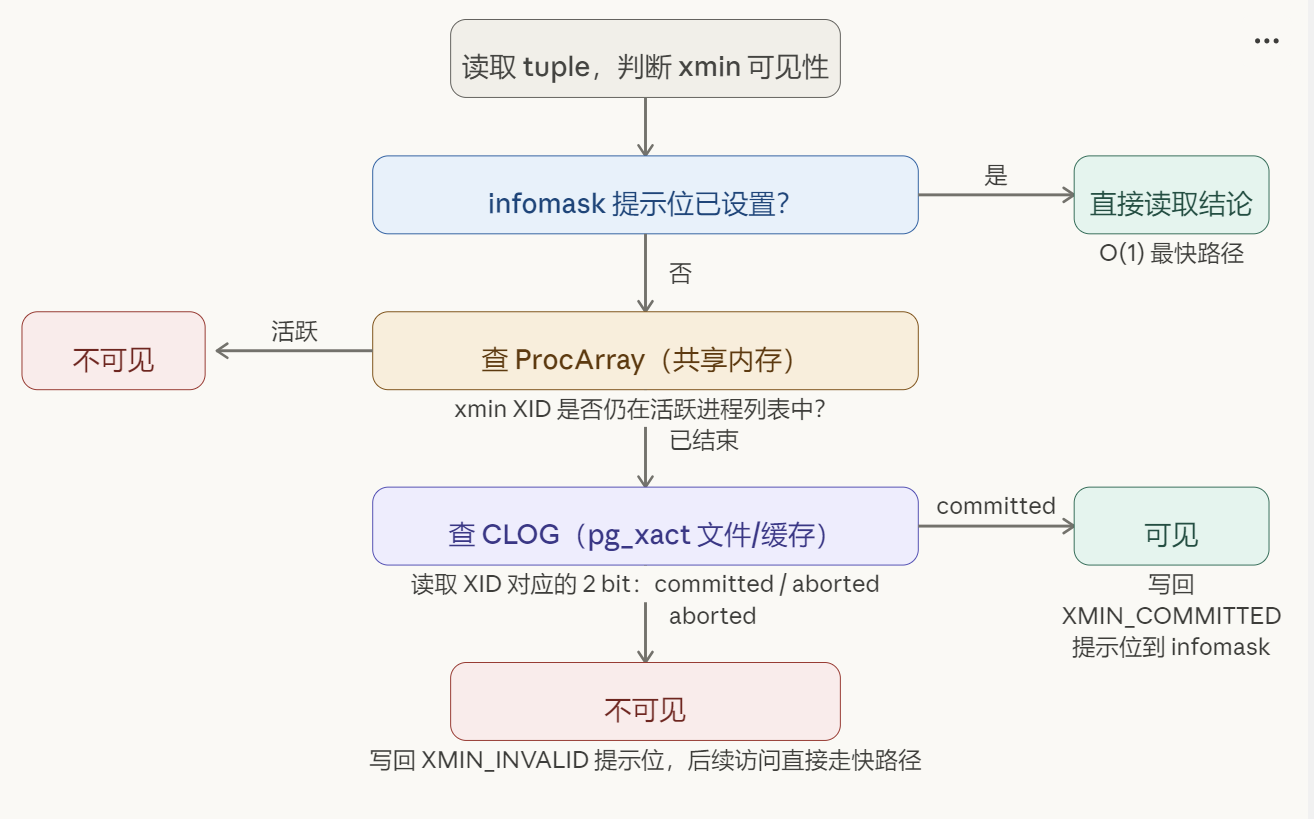
10.1 为什么需要提示位
判断 tuple 可见性时,若每次都去查 CLOG(磁盘上的文件,虽然有缓存),代价较高。提示位是将 CLOG 查询结果缓存在 tuple 头部的机制:一旦某进程确认了某 XID 的最终状态,就将结论写回 tuple 的 infomask,后续所有进程直接读 bit,无需再查 CLOG。
10.2 写回时机
提示位不在 COMMIT 时写,而在任意进程首次"发现"某事务已完成时写:
- 可以是另一个事务的 SELECT
- 可以是 autovacuum 进程
- 可以是 VACUUM
这意味着:只读 SELECT 可能产生脏页(只改了 infomask,页面内容变了),这是 PostgreSQL 特有的行为。
10.3 提示位写回与 WAL 的关系
修改提示位的页面被标记为脏页,但这个修改不保证立刻写 WAL。若此时系统崩溃,重启后页面被恢复到提示位未设置的状态,但这没有任何问题------下次访问时重新查 CLOG 即可,结果一致。
若开启了 data_checksums,提示位的改变会触发 checksum 重算,否则会检测到"损坏"(因为 checksum 对应的是旧数据)。这是 PostgreSQL 需要 full_page_writes 的原因之一。
10.4 三种访问路径速度对比
提示位已设 → 直接读 infomask O(1),最快
提示位未设 → 查 ProcArray(共享内存) O(n_active_backends)
提示位未设 → 查 CLOG(文件,有缓存) 磁盘 or 内存缓存,较慢11. 两种隔离级别下 T3 的行为差异

11.1 Read Committed(默认隔离级别)
sql
BEGIN; -- 默认 Read Committed
-- 此时 T2 尚未提交,balance 还是 500
SELECT balance FROM accounts WHERE id = 1;
-- 获取快照 S1: xmin=101, xmax=102, xip=[101]
-- T2(101) 在 xip_list 中 → 其修改不可见
-- 结果:balance = 500
-- T2 此时 COMMIT
-- 下一条 SQL 重新获取快照
SELECT balance FROM accounts WHERE id = 1;
-- 获取快照 S2: xmin=102, xmax=103, xip=[102]
-- T2(101) < xmax(103) 且不在 xip_list → 可见
-- 结果:balance = 800同一事务内两次读到不同结果------不可重复读。这是 Read Committed 允许的现象,也是它默认快照策略(每条 SQL 重新获取)的直接结果。
11.2 Repeatable Read
sql
BEGIN ISOLATION LEVEL REPEATABLE READ;
-- T3 开始执行第一条语句时,获取一次快照
-- 假设此时 T2 已提交
SELECT balance FROM accounts WHERE id = 1;
-- 获取快照: xmin=102, xmax=103, xip=[102]
-- T2(101) < xmax(103) 且不在 xip_list → 可见
-- 结果:balance = 800
-- 即使此后有其他事务 UPDATE balance=1000 并提交
SELECT balance FROM accounts WHERE id = 1;
-- 同一快照不变,新 XID >= xmax(103) → 不可见
-- 结果仍是:balance = 800(可重复读保证)整个事务共用一个快照,快照之后的任何提交对当前事务均不可见,保证了可重复读。
11.3 快照获取时机对比
| 隔离级别 | 快照获取时机 | 快照数量(每事务) |
|---|---|---|
| Read Committed | 每条 SQL 语句执行前 | 多个(每条语句一个) |
| Repeatable Read | 事务内第一条语句执行前 | 1 个(整个事务共用) |
| Serializable | 同 Repeatable Read,额外有冲突检测 | 1 个 + 序列化图追踪 |
12. ROLLBACK 场景:T2 回滚后 T3 看到什么
假设 T2 执行 UPDATE 后回滚而不是提交:
sql
BEGIN; -- T2, XID=101
UPDATE accounts SET balance = 800 WHERE id = 1;
ROLLBACK; -- 回滚ROLLBACK 的物理实现:
与 COMMIT 类似,同样只写 CLOG:将 XID=101 的 2 bit 从 00 改为 10(已中止)。不回滚任何数据页面。
此时页面状态:
Tuple (0,1): t_xmin=100 t_xmax=101 t_ctid=(0,2)
Tuple (0,2): t_xmin=101 t_xmax=0 t_ctid=(0,2)页面数据与 T2 提交时完全相同!区别只在 CLOG。
T3 此时执行 SELECT:
判断 Tuple(0,1):
- xmin=100 已提交(XMIN_COMMITTED=1)✓
- xmax=101:查 CLOG,XID=101 状态为 aborted(已中止)
- 写回提示位:
XMAX_INVALID = 1(中止的删除等同于没删) - xmax 无效 → Tuple(0,1) 对 T3 可见,返回 balance=500
判断 Tuple(0,2):
- xmin=101:查 CLOG,XID=101 已中止
- 写回提示位:
XMIN_INVALID = 1 - xmin 已中止 → Tuple(0,2) 对 T3 不可见
T3 看到:balance=500(T2 的修改如同从未发生)
13. 与 MySQL InnoDB MVCC 的本质对比
| 维度 | PostgreSQL | MySQL InnoDB |
|---|---|---|
| 旧版本存放位置 | 堆表页面(与新版本共存) | 独立的 Undo Log 文件 |
| UPDATE 操作 | Append-Only,追加新 tuple,旧 tuple 打 xmax 标记 | 原地修改数据页,旧值写入 Undo Log |
| ROLLBACK 操作 | 只改 CLOG(2 bit),数据页不变 | 从 Undo Log 还原数据页 |
| 旧版本清理 | VACUUM 定期扫描并清理 | Purge 线程从 Undo Log 头部异步清理 |
| 表膨胀风险 | 存在(UPDATE/DELETE 频繁时旧版本堆积) | 不存在(旧版本在 Undo Log,不占表空间) |
| COMMIT 代价 | 极小(只写 CLOG 2 bit) | 略大(需刷 Undo Log、redo log 等) |
| 可见性判断 | xmin/xmax 嵌在 tuple 头,结合快照三元组 | read view 结合 Undo Log 版本链回溯 |
| 版本链方向 | ctid 从旧→新(正向链) | DB_ROLL_PTR 从新→旧(反向链,需回溯 Undo) |
| 长事务影响 | 阻塞数据库视界,VACUUM 无法清理相关页面 | 持有 read view,Undo Log 无法被 Purge 清理 |
| 提示位机制 | 有(hint bits,读操作可写脏页) | 无(可见性信息在 Undo Log 版本链中) |
核心差异一句话总结:
- PostgreSQL:"数据留原地,靠快照过滤,靠 VACUUM 清扫"
- MySQL InnoDB:"数据原地改,旧版本外置,靠 Undo 回溯,靠 Purge 清扫"
14. 总结:MVCC 的代价与收益
收益
读不阻塞写,写不阻塞读:SELECT 不需要任何锁,直接读取对应版本,写操作不影响正在进行中的 SELECT。这是高并发 OLTP 场景的基础。
COMMIT/ROLLBACK 极快:无论修改多少行,COMMIT 只写 CLOG 的几个 bit;ROLLBACK 同样只写 CLOG,数据页面不变。
崩溃恢复简单:通过 WAL 重放就能恢复一致性,不需要回滚未提交事务的数据页(因为数据页中未提交事务的修改可以通过 CLOG 识别后忽略)。
代价
表膨胀(Table Bloat):UPDATE/DELETE 频繁的表,旧版本 tuple 会不断堆积,若 autovacuum 来不及清理,表文件会持续增大,影响顺序扫描性能。
长事务阻塞清理:长事务持有老快照,数据库视界(oldest xmin)无法前进,VACUUM 无法清理该视界范围内的任何死 tuple,可能引发严重膨胀。
写放大:每次 UPDATE 都产生新 tuple 和新索引条目,比原地修改消耗更多 I/O(HOT 更新可缓解部分场景)。
只读 SELECT 也可能写脏页:提示位写回机制导致 SELECT 操作修改 buffer,对某些场景(如只读副本或存储层优化)需要特别考虑。
运维建议
sql
-- 监控死元组数量,判断膨胀风险
SELECT relname, n_dead_tup, n_live_tup,
round(n_dead_tup * 100.0 / nullif(n_live_tup + n_dead_tup, 0), 2) AS dead_ratio
FROM pg_stat_user_tables
ORDER BY n_dead_tup DESC;
-- 监控长事务(阻塞 VACUUM 的主要原因)
SELECT pid, now() - pg_stat_activity.query_start AS duration, query, state
FROM pg_stat_activity
WHERE state != 'idle'
AND (now() - pg_stat_activity.query_start) > interval '5 minutes';
-- 查看数据库视界(horizon),视界越老说明 VACUUM 越受阻
SELECT datname, age(datfrozenxid) AS xid_age
FROM pg_database
ORDER BY xid_age DESC;
-- 手动触发 VACUUM 分析特定表
VACUUM ANALYZE accounts;