准备三张表
表一:members
每个成员都有一个ID(不保证是连续的)、基本地址信息、推荐他们的成员的引用(如果有的话),以及他们加入的时间戳。虚构的。
sql
CREATE TABLE cd.members
(
memid integer NOT NULL,
surname character varying(200) NOT NULL,
firstname character varying(200) NOT NULL,
address character varying(300) NOT NULL,
zipcode integer NOT NULL,
telephone character varying(20) NOT NULL,
recommendedby integer,
joindate timestamp NOT NULL,
CONSTRAINT members_pk PRIMARY KEY (memid),
CONSTRAINT fk_members_recommendedby FOREIGN KEY (recommendedby)
REFERENCES cd.members(memid) ON DELETE SET NULL
);表二:facilities
设施表列出了乡村俱乐部所拥有的所有可预订设施。俱乐部在其中存储了设施的ID/名称信息、会员和客人的预订费用、设施的初始建设成本以及预计的每月维护费用。
sql
CREATE TABLE cd.facilities
(
facid integer NOT NULL,
name character varying(100) NOT NULL,
membercost numeric NOT NULL,
guestcost numeric NOT NULL,
initialoutlay numeric NOT NULL,
monthlymaintenance numeric NOT NULL,
CONSTRAINT facilities_pk PRIMARY KEY (facid)
);表三:bookings
该表格存储了设施ID、进行预订的会员、预订开始时间以及预订的半小时"时段"数量。这种特殊的设计可能会使某些查询变得更加困难,但也会带来一些有趣的挑战,同时为将来处理真实世界数据库时可能遇到的复杂情况做好准备。
sql
CREATE TABLE cd.bookings
(
bookid integer NOT NULL,
facid integer NOT NULL,
memid integer NOT NULL,
starttime timestamp NOT NULL,
slots integer NOT NULL,
CONSTRAINT bookings_pk PRIMARY KEY (bookid),
CONSTRAINT fk_bookings_facid FOREIGN KEY (facid) REFERENCES cd.facilities(facid),
CONSTRAINT fk_bookings_memid FOREIGN KEY (memid) REFERENCES cd.members(memid)
);一、如何从 cd.facilities 表中检索所有信息?

问题
从表中检索所有内容
预期结果
| facid | name | membercost | guestcost | initialoutlay | monthlymaintenance |
|---|---|---|---|---|---|
| 0 | Tennis Court 1 | 5 | 25 | 10000 | 200 |
| 1 | Tennis Court 2 | 5 | 25 | 8000 | 200 |
| 2 | Badminton Court | 0 | 15.5 | 4000 | 50 |
| 3 | Table Tennis | 0 | 5 | 320 | 10 |
| 4 | Massage Room 1 | 35 | 80 | 4000 | 3000 |
| 5 | Massage Room 2 | 35 | 80 | 4000 | 3000 |
| 6 | Squash Court | 3.5 | 17.5 | 5000 | 80 |
| 7 | Snooker Table | 0 | 5 | 450 | 15 |
| 8 | Pool Table | 0 | 5 | 400 | 15 |
答案与讨论
sql
select * from cd.facilities;SELECT 语句是从数据库中读取信息的查询的基本起始块。最小的 SELECT 语句通常由 select [某些列] from [某个表或一组表] 组成。
在这种情况下,我们需要 facilities 表中的所有信息。from 部分很简单 - 我们只需要指定 cd.facilities 表。'cd' 是表的模式(schema)- 这是数据库中用于逻辑分组相关信息的术语。
接下来,我们需要指定想要所有列。方便的是,"所有列"有一个简写符号 - *。我们可以使用它来代替繁琐地指定所有列名。
二、从表中检索特定列
问题
想要打印出所有设施及其会员费用的列表。如何检索仅包含设施名称和费用的列表?
预期结果
| name | membercost |
|---|---|
| Tennis Court 1 | 5 |
| Tennis Court 2 | 5 |
| Badminton Court | 0 |
| Table Tennis | 0 |
| Massage Room 1 | 35 |
| Massage Room 2 | 35 |
| Squash Court | 3.5 |
| Snooker Table | 0 |
| Pool Table | 0 |
答案与讨论
sql
select name, membercost from cd.facilities;对于这个问题,我们需要指定想要的列。我们可以通过在 SELECT 语句中用逗号分隔的列名列表来实现。数据库只需查看 FROM 子句中可用的列,并返回我们请求的列,如下所示
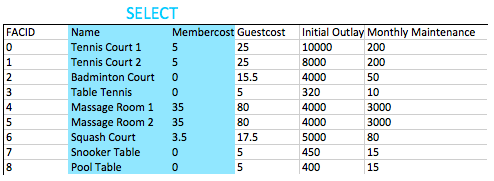
一般来说,对于非临时查询,建议在查询中指定想要的列名,而不是使用 *。这是因为如果表中添加了更多列,的应用程序可能无法处理。
三、控制检索哪些行(2)
问题
如何生成向会员收费的设施列表?
预期结果
| facid | name | membercost | guestcost | initialoutlay | monthlymaintenance |
|---|---|---|---|---|---|
| 0 | Tennis Court 1 | 5 | 25 | 10000 | 200 |
| 1 | Tennis Court 2 | 5 | 25 | 8000 | 200 |
| 4 | Massage Room 1 | 35 | 80 | 4000 | 3000 |
| 5 | Massage Room 2 | 35 | 80 | 4000 | 3000 |
| 6 | Squash Court | 3.5 | 17.5 | 5000 | 80 |
答案与讨论
sql
select * from cd.facilities where membercost > 0;FROM 子句用于构建一组候选行以读取结果。在我们目前的示例中,这组行只是表的内容。将来我们将探索连接(joining),它允许我们创建更有趣的候选集。
一旦构建了候选行集,WHERE 子句允许我们过滤感兴趣的行 - 在这种情况下,是会员费用大于零的行。正如将在后续练习中看到的那样,WHERE 子句可以有多个组件,并通过布尔逻辑组合 - 例如,可以搜索费用大于 0 且小于 10 的设施。WHERE 子句对 facilities 表的过滤作用如下图所示:
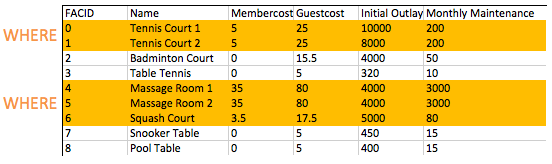
四、控制检索哪些行(2)
问题
如何生成向会员收费且费用低于月维护费1/50的设施列表?返回相关设施的facid、设施名称、会员费用和月维护费。
预期结果
| facid | name | membercost | monthlymaintenance |
|---|---|---|---|
| 4 | Massage Room 1 | 35 | 3000 |
| 5 | Massage Room 2 | 35 | 3000 |
答案与讨论
sql
select facid, name, membercost, monthlymaintenance
from cd.facilities
where
membercost > 0 and
(membercost < monthlymaintenance/50.0);WHERE 子句允许我们过滤感兴趣的行 - 在这种情况下,是会员费用大于零且低于月维护费1/50的行。如所见,由于人员成本,按摩室的运行费用非常昂贵!
当我们要测试两个或更多条件时,使用 AND 来组合它们。正如可能预期的那样,我们可以使用 OR 来测试一对条件中的任何一个是否为真。
可能已经注意到,这是我们将 WHERE子句与选择特定列相结合的第一个查询。可以在下图中看到其效果:选定列和选定行的交集为我们提供了要返回的数据。这可能现在看起来不太有趣,但当我们稍后添加更复杂的操作(如连接)时,将看到这种行为的简洁优雅之处。
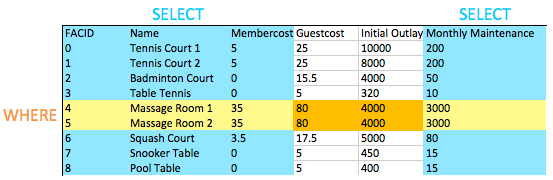
五、匹配多个可能的值
问题
如何检索ID为1和5的设施的详细信息?尝试在不使用OR运算符的情况下完成。
预期结果
| facid | name | membercost | guestcost | initialoutlay | monthlymaintenance |
|---|---|---|---|---|---|
| 1 | Tennis Court 2 | 5 | 25 | 8000 | 200 |
| 5 | Massage Room 2 | 35 | 80 | 4000 | 3000 |
答案与讨论
sql
select *
from cd.facilities
where
facid in (1,5);这个问题的明显答案是使用类似 where facid = 1 or facid = 5 的 WHERE 子句。另一种在大量可能匹配时更容易使用的是 IN 运算符。IN 运算符接受一个可能的值列表,并将它们与(在这种情况下)facid 进行匹配。如果其中一个值匹配,则该行的 WHERE 子句为真,并返回该行。
IN 运算符很好地展示了关系模型的优雅之处。它接受的参数不仅仅是一个值列表 - 它实际上是一个单列表格。由于查询也返回表格,如果创建一个返回单列的查询,可以将这些结果输入到 IN 运算符中。举一个简单的例子:
sql
select *
from cd.facilities
where
facid in (
select facid from cd.facilities
);这个示例在功能上等同于选择所有设施,但向展示了如何将一个查询的结果输入到另一个查询中。内部查询称为_子查询_。
六、将结果分类到桶中
问题
如何生成设施列表,根据月维护费用是否超过100美元,将每个设施标记为"便宜"或"昂贵"?返回相关设施的名称和月维护费。
预期结果
| name | cost |
|---|---|
| Tennis Court 1 | expensive |
| Tennis Court 2 | expensive |
| Badminton Court | cheap |
| Table Tennis | cheap |
| Massage Room 1 | expensive |
| Massage Room 2 | expensive |
| Squash Court | cheap |
| Snooker Table | cheap |
| Pool Table | cheap |
答案与讨论
sql
select name,
case when (monthlymaintenance > 100) then
'expensive'
else
'cheap'
end as cost
from cd.facilities;这个练习包含一些新概念。第一个是我们在查询的 SELECT 和 FROM 之间进行计算的事实。以前我们只使用这部分来选择想要返回的列,但可以在这里放置任何能为每行返回结果产生单个结果的内容 - 包括子查询。
第二个新概念是 CASE 语句本身。CASE 实际上类似于其他语言中的 if/switch 语句,其形式如查询中所示。要添加"中等"选项,我们只需插入另一个 when...then 部分。
最后,还有 AS 运算符。这仅用于标记列或表达式,使其显示更美观或在用作子查询的一部分时更容易引用。
七、处理日期
问题
如何生成2012年9月之后加入的会员列表?返回相关会员的memid、姓氏、名字和加入日期。
预期结果
| memid | surname | firstname | joindate |
|---|---|---|---|
| 24 | Sarwin | Ramnaresh | 2012-09-01 08:44:42 |
| 26 | Jones | Douglas | 2012-09-02 18:43:05 |
| 27 | Rumney | Henrietta | 2012-09-05 08:42:35 |
| 28 | Farrell | David | 2012-09-15 08:22:05 |
| 29 | Worthington-Smyth | Henry | 2012-09-17 12:27:15 |
| 30 | Purview | Millicent | 2012-09-18 19:04:01 |
| 33 | Tupperware | Hyacinth | 2012-09-18 19:32:05 |
| 35 | Hunt | John | 2012-09-19 11:32:45 |
| 36 | Crumpet | Erica | 2012-09-22 08:36:38 |
| 37 | Smith | Darren | 2012-09-26 18:08:45 |
答案与讨论
sql
select memid, surname, firstname, joindate
from cd.members
where joindate >= '2012-09-01';这是我们第一次了解 SQL 时间戳。它们按数量级降序排列:YYYY-MM-DD HH:MM:SS.nnnnnn。我们可以像比较 Unix 时间戳一样比较它们,尽管获取日期之间的差异稍微复杂一些(也更强大!)。在这种情况下,我们只指定了时间戳的日期部分。PostgreSQL 会自动将其转换为完整的时间戳 2012-09-01 00:00:00。
八、去除重复项并排序结果
问题
如何生成members表中前10个姓氏的有序列表?该列表不能包含重复项。
预期结果
| surname |
|---|
| Bader |
| Baker |
| Boothe |
| Butters |
| Coplin |
| Crumpet |
| Dare |
| Farrell |
| GUEST |
| Genting |
答案与讨论
sql
select distinct surname
from cd.members
order by surname
limit 10;这里有三个新概念,但它们都很简单。
- 在
SELECT后指定DISTINCT会从结果集中删除重复行。请注意,这适用于_行_:如果行 A 有多个列,则只有当所有列中的值都相同时,行 B 才等于它。作为一般规则,不要随意使用DISTINCT- 从大型查询结果集中删除重复项不是免费的,所以按需使用。 - 指定
ORDER BY(在FROM和WHERE子句之后,接近查询末尾)允许按一个列或一组列(逗号分隔)对结果进行排序。 LIMIT关键字允许限制检索的结果数量。这对于逐页获取结果很有用,并且可以与OFFSET关键字结合使用来获取后续页面。这与 MySQL 使用的方法相同,非常方便 。
九、合并多个查询的结果
问题
出于某种原因,想要一个包含所有姓氏和所有设施名称的合并列表。
预期结果
| surname |
|---|
| Tennis Court 2 |
| Worthington-Smyth |
| Badminton Court |
| Pinker |
| Dare |
| Bader |
| Mackenzie |
| Crumpet |
| Massage Room 1 |
| Squash Court |
| Tracy |
| Hunt |
| Tupperware |
| Smith |
| Butters |
| Rownam |
| Baker |
| Genting |
| Purview |
| Coplin |
| Massage Room 2 |
| Joplette |
| Stibbons |
| Rumney |
| Pool Table |
| Sarwin |
| Boothe |
| Farrell |
| Tennis Court 1 |
| Snooker Table |
| Owen |
| Table Tennis |
| GUEST |
| Jones |
答案与讨论
sql
select surname
from cd.members
union
select name
from cd.facilities;UNION 运算符执行可能期望的操作:将两个 SQL 查询的结果合并到一个表中。需要注意的是,两个查询的结果必须具有相同数量的列和兼容的数据类型。
UNION 删除重复行,而 UNION ALL 不删除。除非关心重复结果,否则默认使用 UNION ALL。
十、简单聚合
问题
想获取最后一位会员的注册日期。如何检索此信息?
预期结果
| latest |
|---|
| 2012-09-26 18:08:45 |
答案与讨论
sql
select max(joindate) as latest
from cd.members;这是首次涉足 SQL 的聚合函数。它们用于提取关于整组行的信息,并允许我们轻松提出如下问题:
- 每月维护费用最昂贵的设施是什么?
- 谁推荐的新会员最多?
- 每位会员在我们的设施中花费了多少时间?
这里的 MAX 聚合函数非常简单:它接收 joindate 的所有可能值,并输出最大的那个。聚合函数还有更多功能,将在未来的练习中遇到。
十一、更多聚合
问题
想获取最后注册成员(们)的姓和名 - 不仅仅是日期。如何做到这一点?
预期结果
| firstname | surname | joindate |
|---|---|---|
| Darren | Smith | 2012-09-26 18:08:45 |
答案与讨论
sql
select firstname, surname, joindate
from cd.members
where joindate =
(select max(joindate)
from cd.members);在上述建议的方法中,使用_子查询_来查找最近的加入日期。此子查询返回一个标量表 - 即具有单列和单行的表。由于我们只有一个值,因此可以将子查询替换为任何可能放置单个常量值的地方。在这种情况下,我们使用它来完成 WHERE 子句以查找给定会员的查询。
可能希望像下面这样做:
sql
select firstname, surname, max(joindate)
from cd.members但是,这不起作用。MAX 函数不像 WHERE 子句那样限制行 - 它只是接收一堆值并返回最大的那个。然后数据库不知道如何将一长串名称与来自 MAX 函数的单个加入日期配对,导致失败。相反,必须说"找到我加入日期与最大加入日期相同的行"。
正如提示中提到的,还有其他方法可以完成这项工作 - 下面是一个示例。在这种方法中,我们没有明确找出最后的加入日期,而是简单地按加入日期的降序对 members 表进行排序,并取第一个。请注意,这种方法没有涵盖两个人恰好在同一时间加入的极不可能发生的意外情况 😃.
sql
select firstname, surname, joindate
from cd.members
order by joindate desc
limit 1;十二、基本字符串搜索
问题
如何生成名称中包含"Tennis"一词的所有设施列表?
预期结果
| facid | name | membercost | guestcost | initialoutlay | monthlymaintenance |
|---|---|---|---|---|---|
| 0 | Tennis Court 1 | 5 | 25 | 10000 | 200 |
| 1 | Tennis Court 2 | 5 | 25 | 8000 | 200 |
| 3 | Table Tennis | 0 | 5 | 320 | 10 |
答案与讨论
sql
select *
from cd.facilities
where
name like '%Tennis%';SQL 的 LIKE 运算符提供简单的字符串模式匹配。它几乎在所有系统中都得到实现,并且使用简单 - 它只需要一个字符串,其中 % 字符匹配任何字符串,_ 匹配任何单个字符。在这种情况下,我们正在寻找包含"Tennis"一词的名称,因此在两侧放置 % 就符合要求。
还有其他方法可以完成此任务:例如,Postgres 支持使用 ~ 运算符的正则表达式。使用让感到舒适的任何方法,但请注意,LIKE 运算符在系统间的可移植性更强。