DoF 是 Depth of Field
- Mobile DoF(移动端): 针对手机或低性能设备优化,通常使用Gaussian Blur(高斯模糊)来分层模糊近景和远景,以降低性能消耗。
注意:启用复杂的DoF效果会增加渲染的后处理开销,降低帧率。
在虚幻引擎(Unreal Engine)中,材质设置里的 Translucency Pass (半透明渲染阶段)并非是在设置全局后处理(Post Processing)本身,而是决定半透明物体在整个渲染流水线中的"排队顺序",特别是它相对于深度检测(Depth of Field, DOF)的位置。
之所以有这个选项,是因为半透明渲染在实时引擎中一直是个难题,Before DOF(在 DOF 之前): 如果材质在这个阶段渲染,它会被计入深度缓存。这意味着当全局后处理计算景深虚化时,这个半透明物体会像普通不透明物体一样被正确虚化。
-
After DOF(在 DOF 之后,即默认设置): 物体会跳过 DOF 计算。这通常用于 UI、光效或某些即使背景模糊也需要保持清晰的材质。如果你的角色头发被设置在
After DOF,那么即使背景被虚化得很厉害,头发边缘可能依然非常锐利,看起来会很"假"。 -
After DOF 是半透明材质的默认位置,因为它能避免很多复杂的深度排序问题。
-
但对于二次元角色(如你图中所示)的头发或皮肤 ,为了让其边缘能和背景自然融合,或者配合后期描边,通常需要手动将其调整至 Before DOF 渲染阶段。
Depth of Field(景深)通常是通过深度缓冲(Depth Buffer / Z-Buffer) 来计算虚化程度的绝大多数半透明物体默认不写入深度缓冲,因此 DOF 系统无法获得它们的准确深度信息。为了防止毛发在景深效果下出现边缘"切裂"或完全不被虚化的错误,引擎强制将其放在 After DOF 阶段渲染,即在景深处理完成后再叠加上去,以确保毛发整体视觉的稳定性,避免出现严重的渲染瑕疵。该选项的可调节性通常取决于 Blend Mode(混合模式) 的选择:只有当 Blend Mode 设置为 Translucent 、Additive 或 Modulate 且未被特定着色模型强行接管时,该选项通常才是可调的。
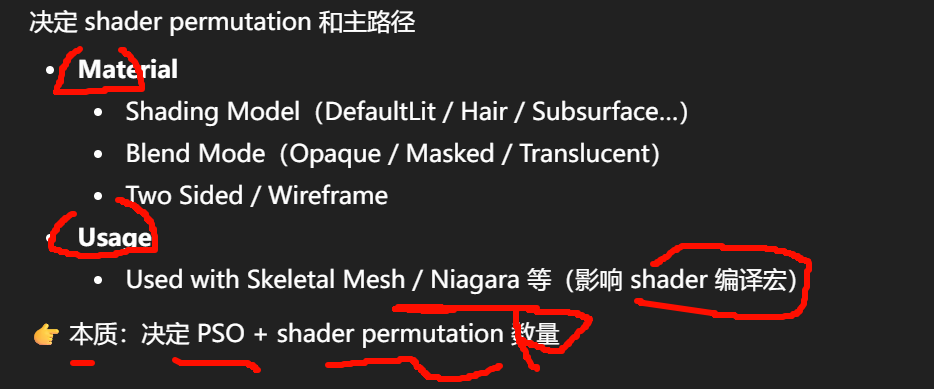

你之所以会觉得"它们应该写在 Material 节点里",是因为在材质编辑器中,我们通过连线来定义表面的属性(如粗糙度、金属度)。
但渲染引擎需要决定如何处理这些表面数据,这正是这张图讨论的核心逻辑。

- 延迟渲染 (Deferred) :材质节点里的 BRDF 信息(BaseColor, Roughness 等)会被先写入 GBuffer。等到 Lighting Pass 时,光源再读取这些数据进行统一计算。
- 前向渲染 (Forward):光照计算直接在物体绘制时完成。
- 逻辑关联 :某些复杂的 BSDF 特性(比如高质量的半透明、各向异性)在延迟渲染下很难存入有限的 GBuffer,因此往往需要回到 Forward Pass 里单独计算。图中提到的"对应关系"就是在说明这种架构上的选择。
deffered的buffer处理办法是有限的,数值就是这些,而且大多物体统一,所以,对于特例的处理会需要额外的精力,把gbuffer里的数据取出来之后,需要额外的去处理或者近似,
引擎底层会根据这些选项:
- 分发代码:决定这块材质是用 BRDF 还是完整的 BSDF 逻辑。
- 决定去向:是把数据丢进 GBuffer(延迟),还是直接进行光照运算(前向)。
- 计算能量:确保光照在反射和透射之间符合能量守恒。
如果不切换forward可以如何处理?
坚持在**延迟渲染(Deferred Shading)
架构下处理这些复杂的 BSDF 特性
增加 GBuffer 的带宽(Fat GBuffer)
最直接的方法是强行增加 GBuffer 的渲染目标(Render Target)数量或每个通道的位宽。
- 做法 :比如原本只有 4 个 MRT(Multiple Render Targets),为了支持各向异性(Anisotropy),再开一个专门存"副法线(Tangent)"或"各向异性强度"的纹理。
- 缺点:内存带宽开销极大。在移动端或高分辨率(4K)下,这会导致严重的性能瓶颈。
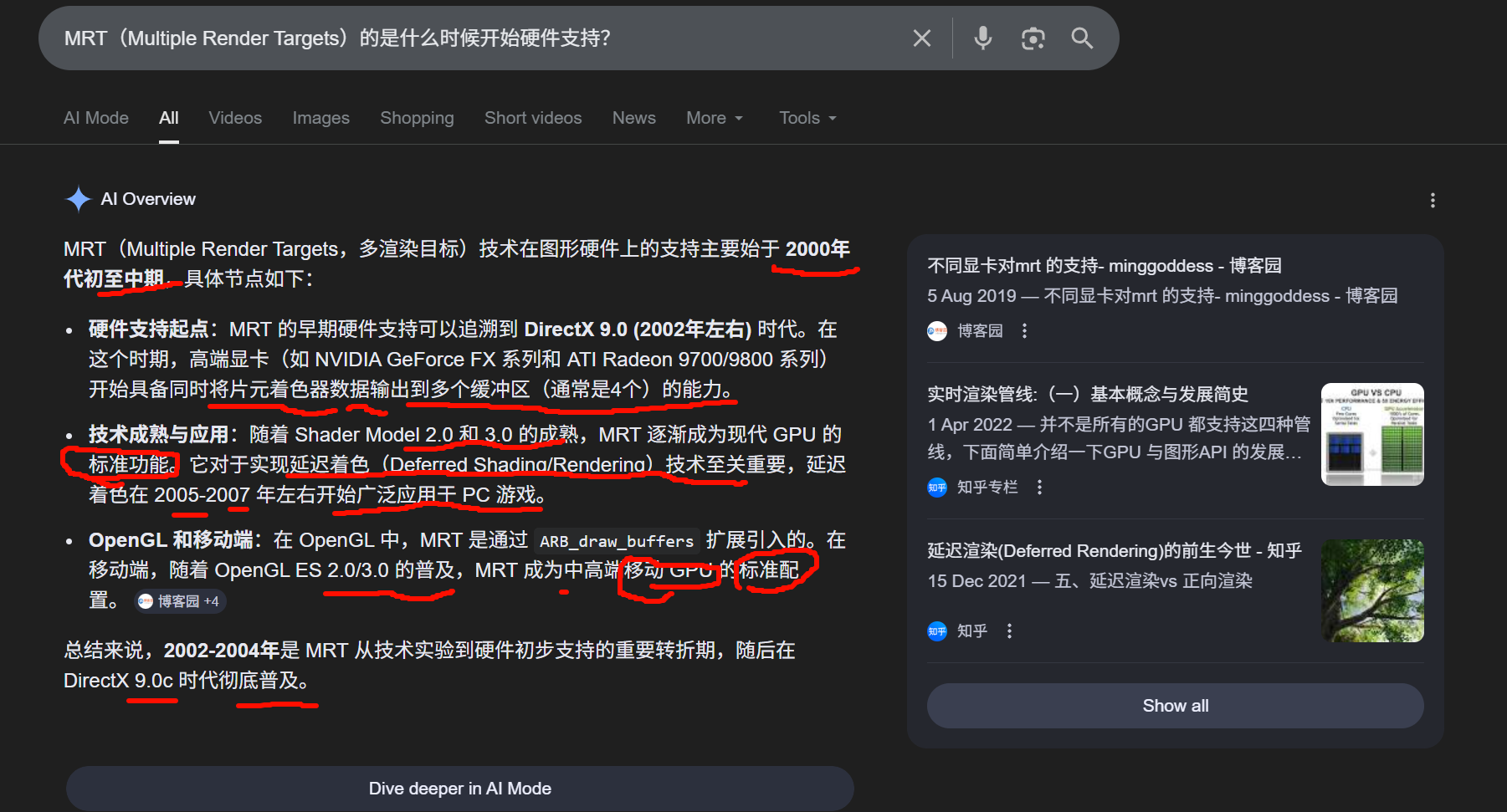
MRT(Multiple Render Targets,多渲染目标)是一种图形渲染技术,而RT(Render Target,渲染目标)是MRT所操作的基本对象。
MRT是方法,RT是对象。MRT允许在一次渲染(Draw Call)中,同时将片元着色器的输出写入多个不同的RT中。
RT (Render Target): 通常是一个纹理(Texture)或帧缓冲(Framebuffer)传统的单渲染目标模式下,所有数据都画入同一个RT(通常是屏幕后缓冲)。MRT (Multiple Render Targets): 是一种高级特性,允许在一个渲染通道(Pass)中绑定多个RT到管线上,并让片元着色器(Fragment Shader)将不同的属性(如漫反射色、法线、深度等)同时输出到这些RT中。
-
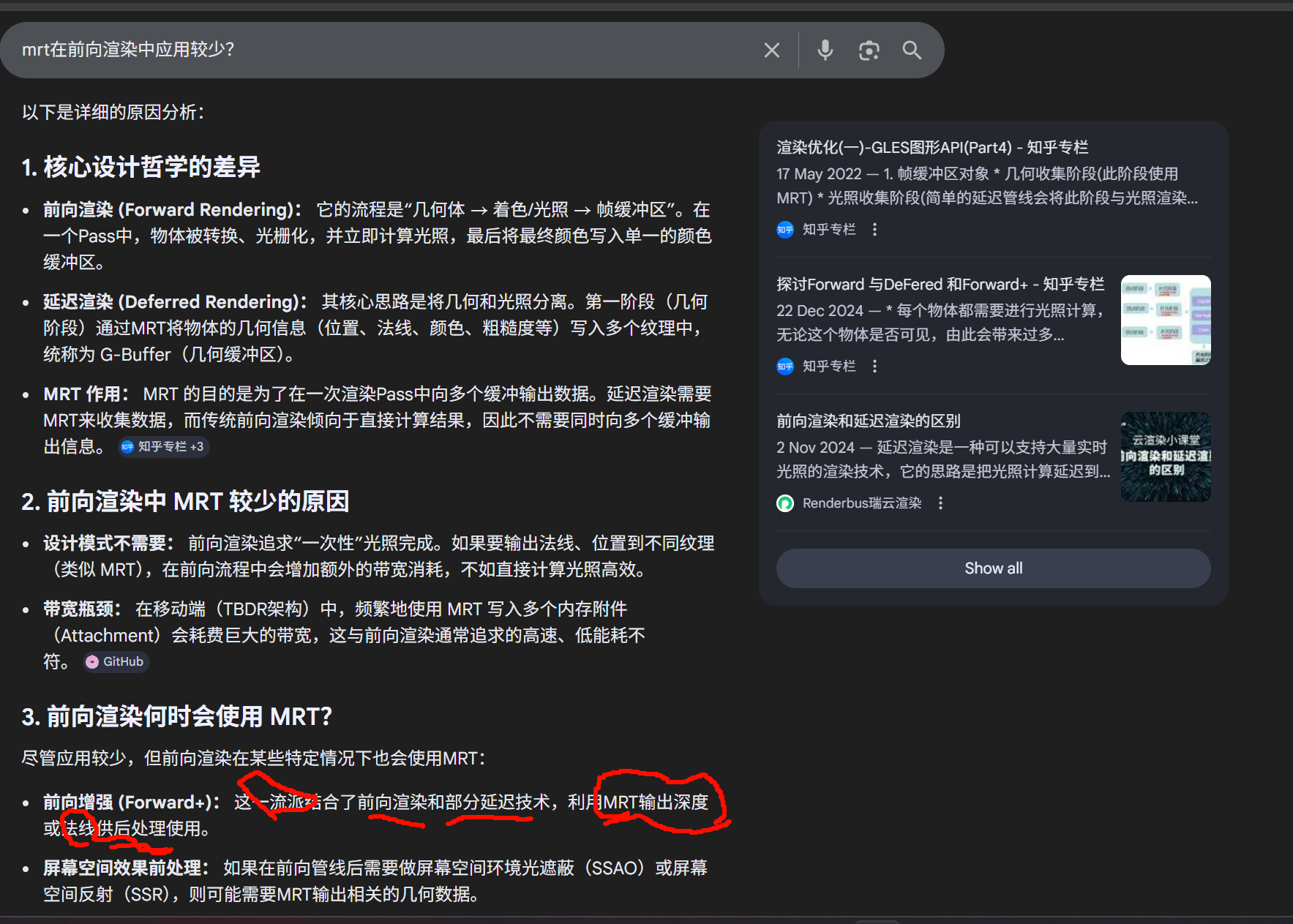
SSAO 消费数据:SSAO 算法需要在屏幕空间中,根据每个像素的深度和法线来判断其被周围几何体遮蔽的程度。
-
联系:SSAO 需要的深度贴图(Depth Texture)和法线贴图(Normal Texture)正是通过 MRT 在早期几何 Pass 中直接生成的,从而避免了多次渲染几何图形的开销。
-
几何阶段(MRT) :物体被渲染。MRT 将数据存入 G-Buffer,这通常包含:
- Target 0: 颜色 (Albedo/Diffuse)
- Target 1: 法线 (World/View Normal)
- Target 2: 位置 (World/View Position) 或 深度 (Depth)
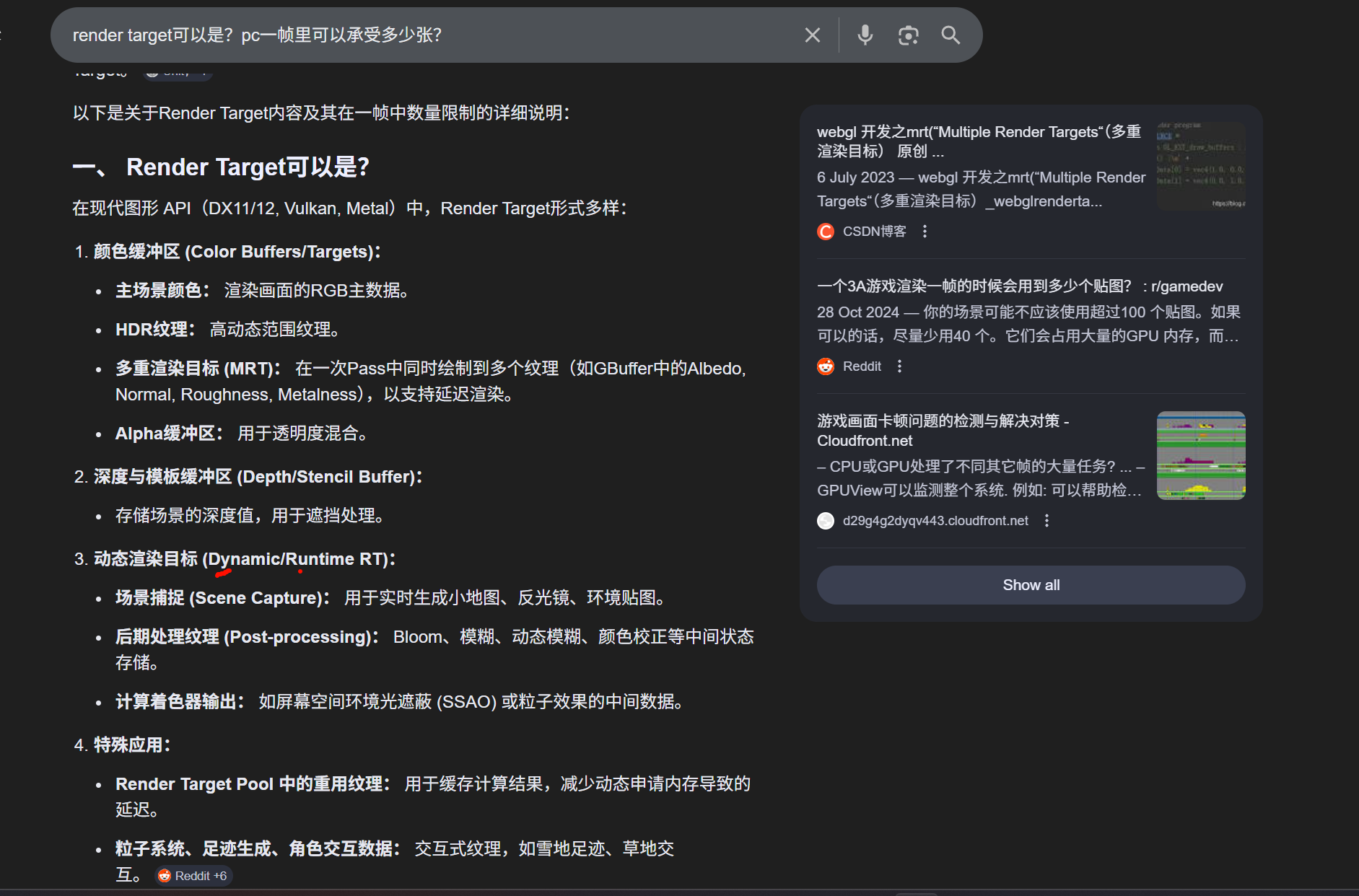
任何可以在显存中分配、具有宽度、高度和像素格式的纹理资源,几乎都可以作为Render Target。
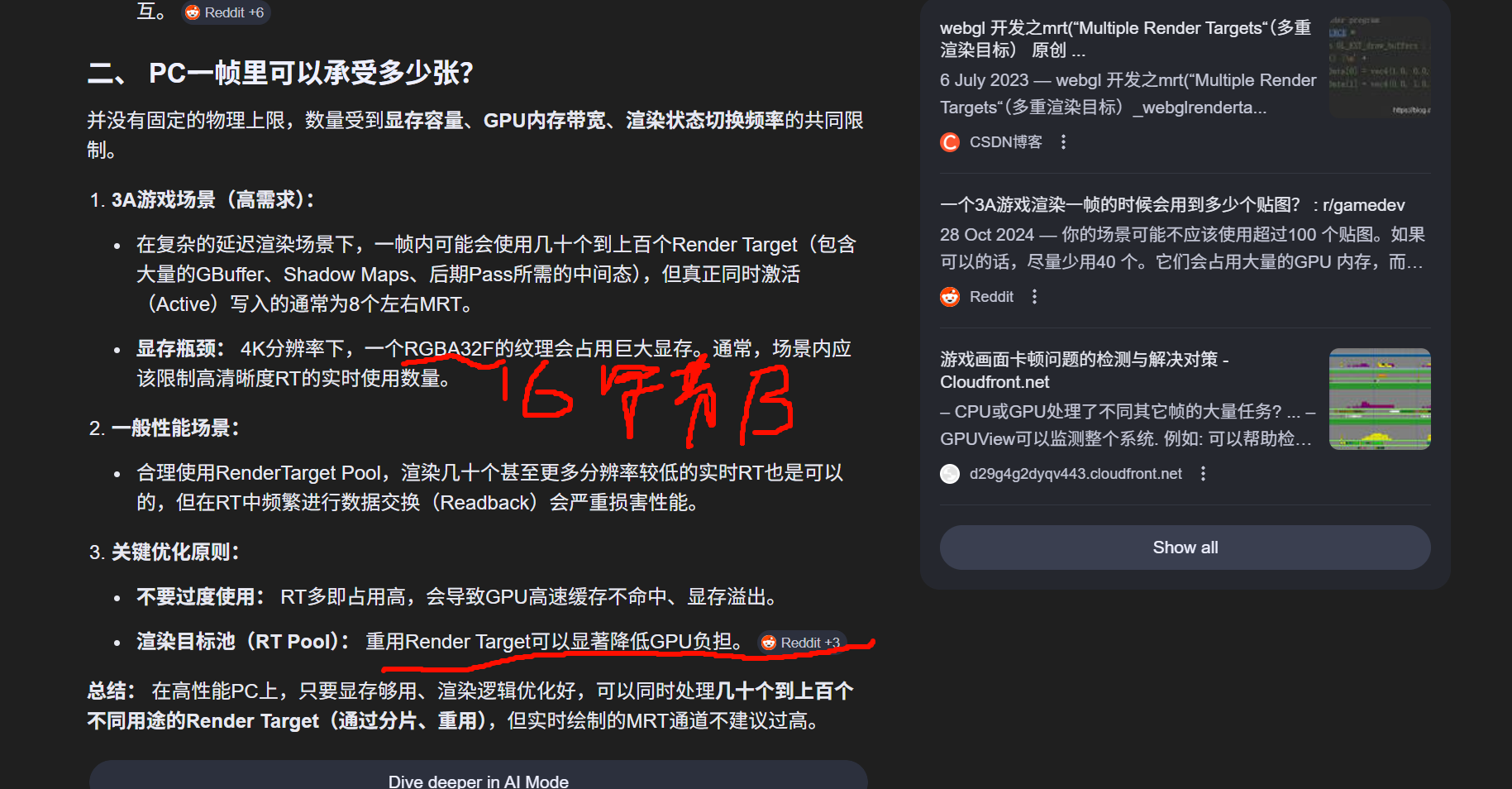
- SSSSS(屏幕空间次表面散射)。它不在 Lighting 阶段一次性算完,而是先按普通物体渲染,再对图像进行多次模糊(Blur)来模拟光线在皮肤内的散射。
商业指标驱动(核心原因)
搜索引擎优化目标不是"真理",而是:
-
CTR(点击率)
-
Session time
-
Ad revenue
现代搜索引擎在优化的是:
"用户会点击什么"
而不是:
"什么最接近真实/一手信息"
这两者在技术领域是明显冲突的
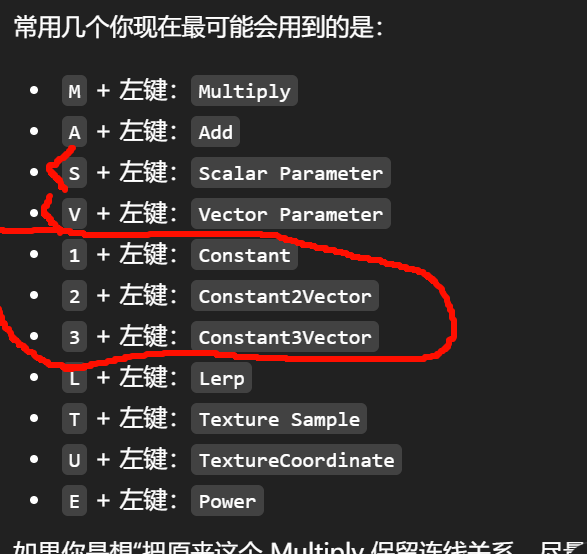
普通常量节点
比如:
-
Constant
-
Constant2Vector
-
Constant3Vector
-
Constant4Vector
这些只是写死在材质里的值,不暴露给 Material Instance。
所以它们不会出现在左边参数面板。
Parameter 节点
比如:
-
ScalarParameter
-
VectorParameter
-
TextureSampleParameter2D
-
StaticBoolParameter
-
StaticSwitchParameter
-
StaticComponentMaskParameter
Collection Parameter
这是另一类"全局参数",来自 Material Parameter Collection。
它不是给单个 MI 调的,而是给多个材质共享的全局值。
它通常不会像普通实例参数那样出现在 MI 左边给你逐项改,因为它的值来源不是这个材质实例,而是外部的 MPC 资产/蓝图/C++。
ScalarParameter
一个 float。
适合:
-
Strength
-
Contrast
-
Threshold
-
RimPower
-
SpecIntensity
VectorParameter
一个 float4。
适合:
-
颜色
-
RGBA 打包常量
-
某些四维控制值
TextureSampleParameter2D
可在 MI 里切换贴图。
适合:
-
BaseMap
-
MaskMap
-
RampTex
StaticBoolParameter
编译期开关。
适合:
-
是否启用某个功能
-
是否走某个分支
但不适合频繁连续调试。
StaticSwitchParameter
编译期分支选择。
本质也是控制 shader permutation。
开销和语义都比普通 Scalar 大。
StaticComponentMaskParameter
编译期选择 R/G/B/A 组件。
你现在这个 Channel 节点就是这一类。
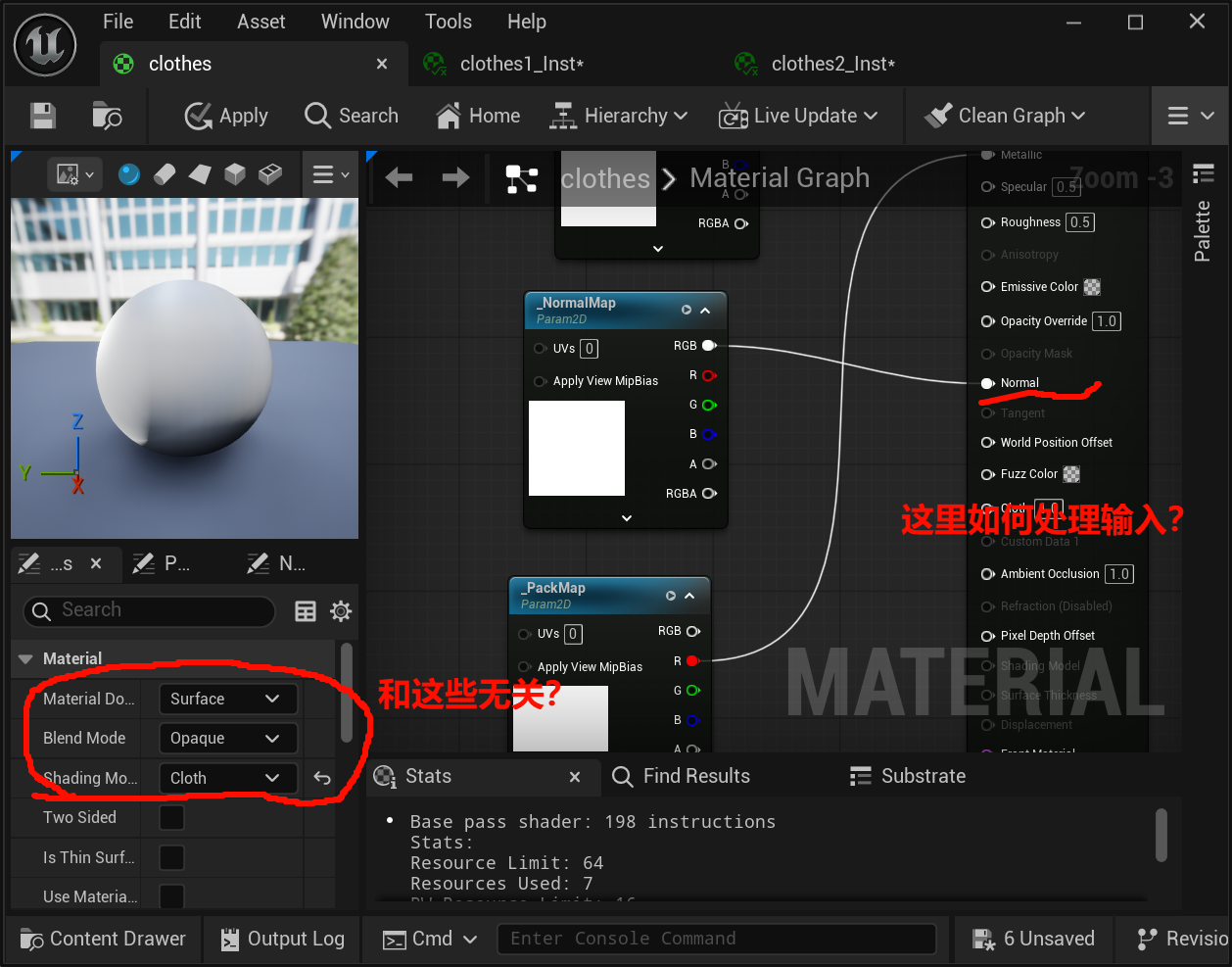
把 _NormalMap 的 RGB 直接接到 Normal,这在"贴图已经被正确导入为 Normal Map"时,通常就是对的。
similar Nodes
- BreakOutFloat3Components: A node that splits a 3-component vector into individual scalar outputs, which internally uses Component Masks.
- AppendVector: Used to re-combine individual channels after they have been split.
The name
Component Mask comes from standard graphics programming (like HLSL/GLSL). It's called a "mask" because it hides the channels you don't want and only lets the "unmasked" ones pass through a single gate.
Here is why "Split RGBA" wouldn't quite fit how this specific node works:
- It doesn't always split: A "Split" implies you are breaking one thing into four pieces. A Mask often just filters one thing. If you mask a Vector3 down to just the Red channel, you haven't split it; you've just discarded Green and Blue.
- It handles more than RGBA: In engine math, these are just numbers. A Component Mask can be used on XYZ coordinates for 3D math or UV coordinates for textures. "Mask" is a universal term for "take part of this data," whereas "RGBA" is specific only to colors.
- The Output is a single wire: If it were a "Split" node, you'd expect four output pins on the right side. Since it only has one output pin that changes its data type based on your selection, "Mask" describes the operation of filtering that single stream.
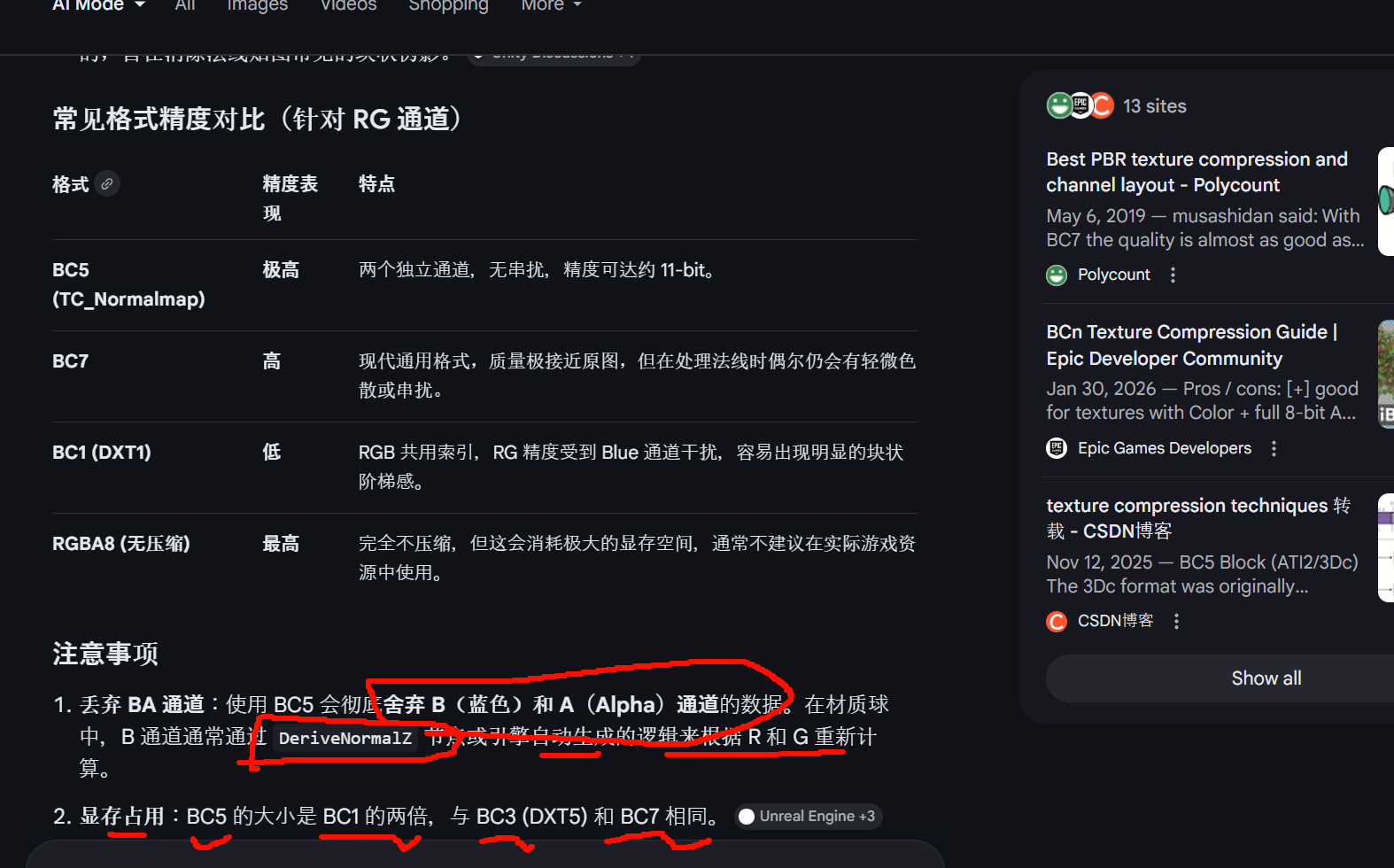
法线图一般优先用 Normalmap 压缩设置;在常见 DX11/BCn 路径下,它通常会落到 BC5,也就是只高质量保留 X/Y 两个分量,再在使用时重建 Z。Epic 的文档和教程里都把普通 normal map 对应到 TC_Normalmap,并明确提到在 DX11 上会用 BC5结合你前面那张"只有 RG 两通道法线"的情况,最合适的就是:
Compression Settings = Normalmap
而不是 BC7 Compressed。因为 BC7 更像通用高质量颜色压缩;对普通切线空间法线,UE 的标准路径还是 Normalmap/BC5,精度和体积都更合理。如果它其实是"打包贴图",只是其中 RG 恰好拿来存 normal,另外通道还要存别的数据
那就不要用 Normalmap,因为 UE 会按法线语义处理它,不适合再拿其他通道当普通数据读。这种情况才考虑 BC7、Masks 或别的压缩方案,取决于你还想保什么通道。
Unreal Engine (UE) 的
有损压缩 方式中,BC5 (TC_Normalmap) 确实是保留 RG 通道精度最高、效果最好的标准压缩格式。传统的压缩方式(如 BC1/DXT1)会将 RGB 三个通道混合在一起进行块压缩,导致通道间产生"串扰(Cross-talk)",细节会互相干扰。
而 BC5 将 R 和 G 通道完全分开存储,每个通道拥有独立的 8 字节数据块,互不影响。
BC5 实际上是两个 BC4 数据块的组合。每个块会存储该通道的最小值和最大值(端点),并使用 3-bit(8个阶级) 的索引进行精细插值。
专为法线设计:它最初就是为了存储法线贴图(Normal Map)的 X 和 Y 轴数据而开发的,旨在消除法线贴图常见的块状伪影。
如果你需要存储两张不相关的灰度图(比如粗糙度和金属度)且追求极致的清晰度,将它们放入 BC5(设置压缩模式为 Normalmap 并取消勾选 sRGB)是一个非常高端的优化方案。

BC7 对平滑梯度的处理比 BC1 好得多
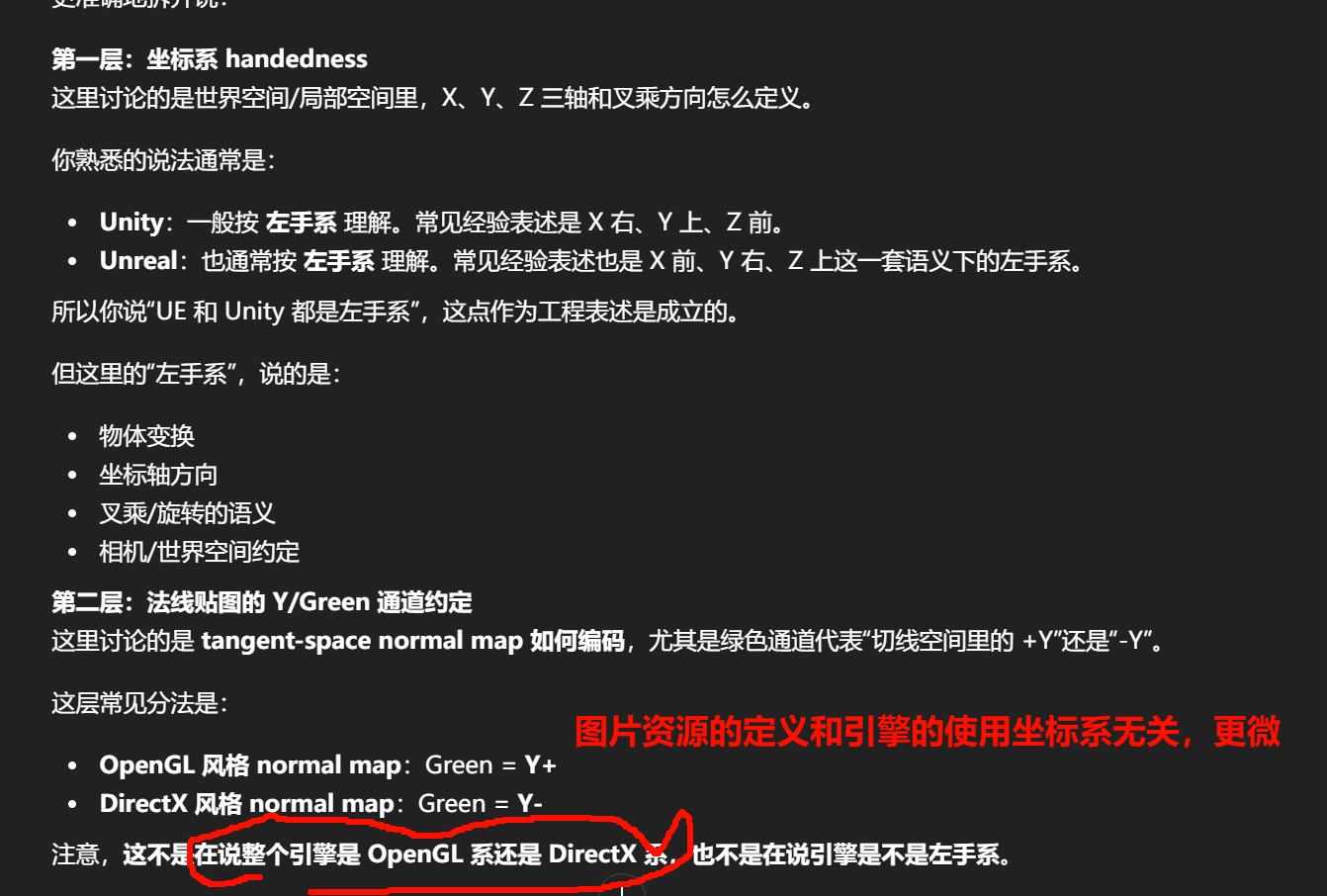
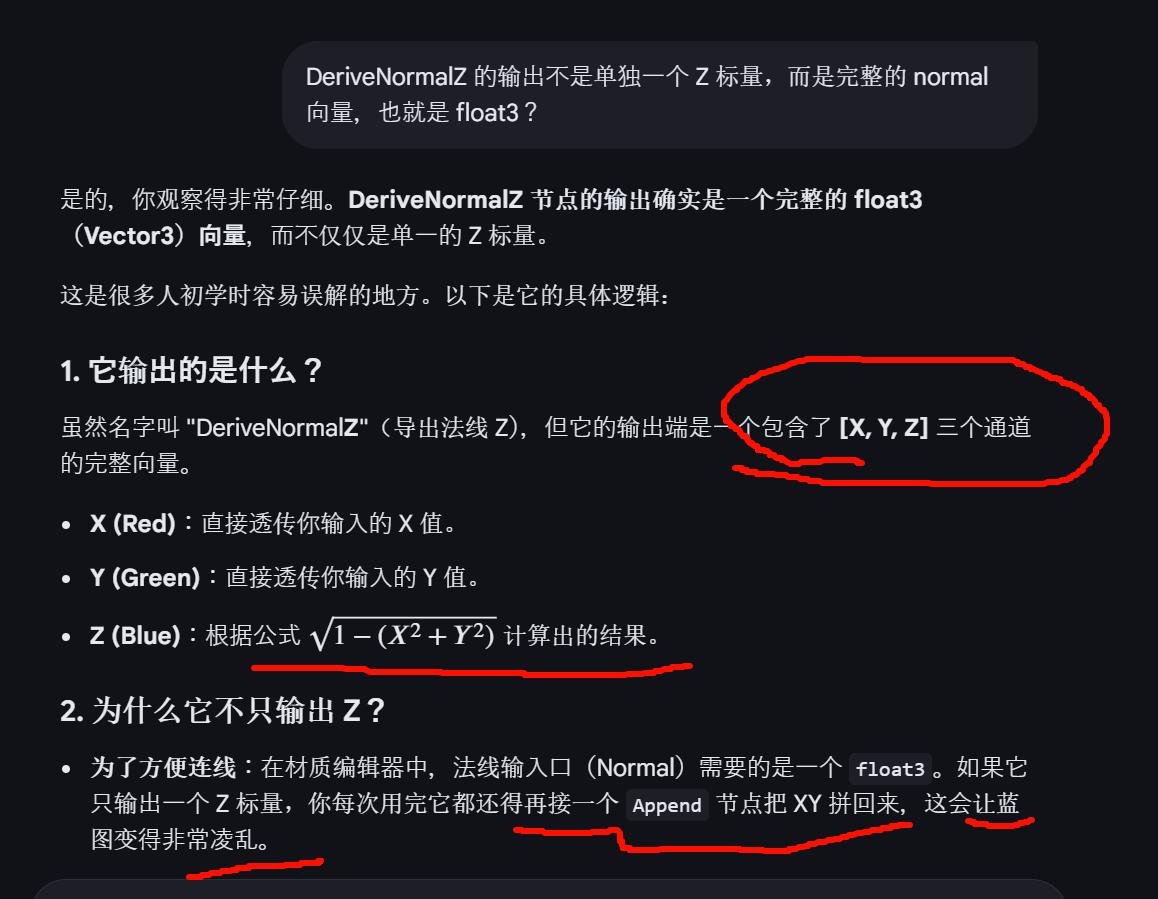
DeriveNormalZ 节点中,输入的 XY 并不是物体空间(Object Space),而是 切线空间(Tangent Space) 的坐标。
在虚幻引擎的材质系统中,坐标系的逻辑如下:
- 坐标系取决于: 纹理类型与采样设置
- 切线空间 (Tangent Space):这是 99% 法线贴图使用的空间。在这种空间下,法线方向是相对于模型表面的"垂直向外"方向(即 Z 轴,显示为蓝色)。
- X (Red) 代表切线(Tangent)方向,即表面的"左右"。
- Y (Green) 代表副切线(Bitangent)方向,即表面的"上下"。
- Z (Blue) 代表法线(Normal)方向,即垂直表面的方向。
"切线空间法线贴图里,绿色通道(Y)到底是向上还是向下"
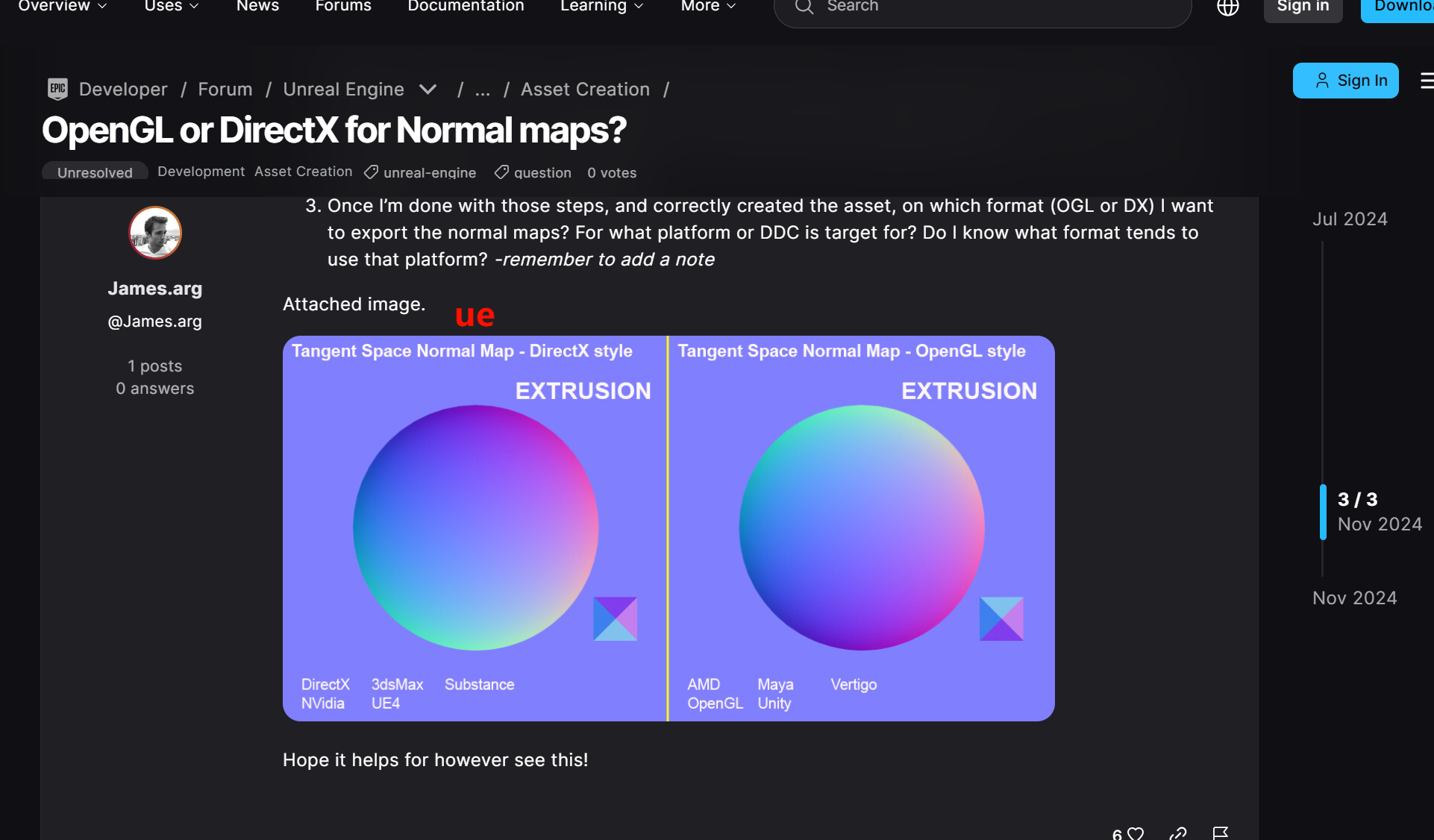
业界确实长期存在两种常见约定:OpenGL 风格通常把绿色通道解释为 Y+(up) ,DirectX 风格通常把绿色通道解释为 Y-(down)。
Blender 手册明确写了:Blender 默认使用 OpenGL convention,Y 轴在绿色通道中指向上;也可以切到 DirectX convention。Unity 2022.3 文档也明确说明了它有 flipGreenChannel 这个导入选项,用来处理"法线贴图使用了与 Unity 期望值不同的约定"的情况。Unreal 也提供了 Flip Green Channel 导入/纹理属性,说明它同样承认这类约定差异在实践中存在。Epic Games Developers+3Blender Documentation+3Unity Documentation+3
Unity 文档没有说"Unity 就是 OpenGL 法线标准",而是说如果导入的 normal map 和 Unity 预期不一致,就翻绿通道。Blender 则明确默认是 OpenGL convention。Unreal 这边也不是"因为 UE 属于 DirectX 阵营所以一定是 DX normal";更准确地说,UE 工作流里常常需要/支持对 green channel 做翻转,来匹配资产来源。
StaticComponentMaskParameter 的官方定位很明确:它是"静态分量遮罩参数",本质是一个静态参数,保存 R/G/B/A 哪些分量被启用的信息。Epic 的 API 文档直接把它描述为 "Holds the information for a static component mask parameter"。这类节点更偏"编译期材质结构选择",适合做 packed texture 的通道裁剪、决定某条材质分支最终取哪些分量。ChannelMaskParameter 的官方定位则更像"可参数化的单通道选择器"。它在 API 里是 UMaterialExpressionChannelMaskParameter,继承自 UMaterialExpressionVectorParameter,并带有 mask_channel、channel_names、default_value 这些编辑器属性。也就是说,它不是单纯保存四个静态勾选位,而是作为一个参数节点,让你围绕"选哪个通道"这件事做更明确的实例化配置和界面表达。如果按"官方使用场景"去理解,StaticComponentMaskParameter 更适合这种情况:你有一个 float4 输入,比如一张打包贴图采样结果,你想在材质实例里决定是取 R、RG、RGB 还是别的组合,而且这个选择属于静态参数,会影响材质编译结果。它在材质系统参考里也被列在 StaticBoolParameter、StaticSwitchParameter 这一类静态参数旁边,明显属于"静态 permutation / 编译期选择"家族。

shoulder robing
off the shoulder look
-
Fuzz Color没配 -
Cloth掩码基本没用 -
几何又只是个光滑球
-
没有各向异性纤维方向、没有微绒毛细节、没有合适的法线/粗糙度变化
那最后看起来就会非常接近 Default Lit。
布料专属项和 BRDF 行为。
-
掠射角更明显的柔和亮边
-
微绒毛/fuzz 的边缘提亮
-
更像织物的高光扩散,而不是塑料/漆面那种高光
-
在逆光、侧光、HDRI 下,边缘会更"绒"
-
某些实现里会对漫反射/镜面反射分布做专门处理
Cloth shading model 的"布料感"很大程度就靠这些专用输入。Fuzz Color:用于给材质加入颜色,模拟光穿过表面时产生的颜色偏移;
Cloth:用于控制 Fuzz Color 的强度,相当于一个 mask。0 表示没有 fuzz 贡献,1 表示 fuzz 完全混入到 Base Color 上。在常规 PBR 输入之外,再叠加一层"布料微纤维/绒毛感"的额外响应 。这也是为什么你只接 BaseColor / Roughness / Normal 时,视觉上会非常接近 Default Lit;因为你实际上还没真正用上 Cloth 模型最特化的部分。Shading Material Functions 里的 FuzzyShading。它明确说这个函数是在模拟类似 velvet / moss 这种"模糊纤维表面",而且效果"类似 Fresnel 计算";这已经很接近 cloth fuzz 的直觉模型了:边缘/掠射角增强、表面出现柔和的纤维散射感 。要看 pin 最终如何进入光照计算,最终还是要看 shader 源码,而不是 Material 节点页面 。官方还说明 Unreal 的 shader 源文件放在 Engine/Shaders 或插件的 Plugin/Shaders 目录下。Launcher 安装主要是预编译引擎;如果你要完整、稳定地阅读和跟踪源码,Epic 官方建议走 GitHub source code 版本,再本地编译。官方 5.7 文档也明确提供了"Downloading Source Code from GitHub"和"Building Unreal Engine from Source"的流程。
把 GitHub 作为连接器接到 ChatGPT / Codex。
那只要该产品和该会话拿到了你的 GitHub 授权,并且你的 GitHub 账号本身对仓库有权限,AI 就可以读取这些仓库的数据并基于内容回答。OpenAI 官方帮助中心明确写了:连接 GitHub 后,ChatGPT 可以拉取你仓库中的代码、README 和其他文档,并基于这些实时推理。
-
如果是
a / b通常比
a * inv_b慢,但仍比pow轻很多。 -
如果是
pow(x, 2)、pow(x, 3)、pow(x, 4)几乎总是应该手写成:
C++
x * x
x * x * x
或者更优的组合:
C++
float x2 = x * x ;
float x4 = x2 * x2 ;
这会比 pow 快很多。
-
如果是
pow(x, 0.5)通常直接写
sqrt(x)更好。 -
如果是
pow(x, -1)通常写成
1.0 / x更好。 -
如果指数是编译期常量整数
很多编译器有时会优化,但不能盲信。实际项目里最好显式改写。
编译器有时会优化不能盲信最好显式改写浮点除法通常比乘法慢几倍到十几倍不等pow 往往又比浮点除法慢很多倍
sqrt 的性能通常介于 divide 和 pow 之间,但更接近 divide,远比通用 pow 便宜。
常见关系可以粗略记成:
mul < add < sqrt ≈ divide << pow
不能把 sqrt 和 divide 绝对固定成谁一定更快,因为这很依赖:
-
CPU 还是 GPU
-
标量还是 SIMD
-
单精度还是双精度
-
编译器是否用了近似指令
-
是否允许 fast-math
-
目标架构的专用单元
不过工程上可以这么理解:
sqrt
通常是硬件支持的"特殊基础运算",比 pow 轻得多。
它不像 pow(x, y) 那样通常要走 log/exp 或复杂库实现。
ao' = pow(ao, p)
它的优点是能更温和、更可控地重分布 0~1 区间的信息:
-
p < 1:整体变亮,弱 AO 被抬起来 -
p > 1:整体变暗,强 AO 更集中 -
黑白边界通常比线性缩放更自然
-
不容易像除法那样粗暴地把大段亮部直接顶满
-
更适合"调观感"而不是"改单纯数值范围"
所以如果你说的是"调 AO 强度",并且关注:
-
视觉质量
-
细节层次
-
尽量少破坏原图信息分布
那一般结论是:
优先用 pow 做主调节。
"朝 1 回退"或"朝原图靠近":更像"调对比度 / 调响应曲线"先运行 Setup.bat/.sh 去下载二进制依赖,再 GenerateProjectFiles,最后自己编译(不是开箱即用安装包流程)。Setup.sh 脚本本身也在调用 GitDependencies.sh 去拉依赖,说明仓库不包含全部运行所需二进制内容。
OS 内核/驱动模型不同,不是"编译选项"能抹平
-
Windows(WDDM/DirectX)、Linux(Vulkan + 各发行版 libc/driver 组合)、macOS(Metal + 签名/沙箱)是不同执行生态。
-
同一套 UE 代码能跨平台,不等于同一份二进制能跨平台运行。
图形 API 和 GPU 驱动组合是乘法爆炸
-
不是"设备不同"这么简单,而是:OS × GPU 厂商 × 驱动版本 × API 路径 × 插件。
-
统一包要覆盖所有组合,QA 矩阵会大到不可维护。
平台 SDK 与法律限制
- 主机平台(PS/Xbox/Switch)本来就受厂商 NDA/授权约束,不能像 PC 一样公开统一发包。README 也写了受限平台要注册开发者账号才可开发
工具链和 ABI 现实
-
源码仓库,先
Setup拉对应依赖,再本地/CI 为目标平台编译。 -
Android 还要本地 NDK、iOS 必须 Mac,也说明"统一二进制"到不了这个层面。
UE 的渲染架构对 shading model 扩展不友好。UE 内部对材质模型类型的枚举、GBuffer 编码、各渲染路径分支、编辑器和平台兼容都绑得比较死。想"正规地新增一个 shading model"时,往往不是只改一个地方,而是要改引擎一串地方。"不改引擎就只能献祭一两个不用的 shading model 了"意思是:
如果不去深改 UE 源码,一个常见做法是"借壳"------把某个你不用的现有 shading model 魔改成你自己的用途。
例如把某个项目根本不用的 cloth、clear coat、subsurface 之类分支占掉,复用它已有的 ID、GBuffer 通道和编译路径。也就是:
不是"新增"一个 shading model,
而是"伪装成"一个现有 shading model。
把 cloth 那个 shading model 或相关槽位拿来复用了,但问题在于:
-
移动端和桌面端的 GBuffer/材质数据布局可能不同
-
Forward 和 Deferred 的实现路径不同
-
某些通道在一个平台有,在另一个平台没了,或者语义不同
-
同一个 CustomData 在不同路径里可能装的不是同样东西
所以你就会遇到:
你在桌面延迟渲染里跑得好好的,自定义数据到了移动前向路径就不对了,或者根本没有那个数据位可用。
不行。Unlit 不能从根上解决你前面说的那个问题,它只是"绕开了 lit shading model 体系",不是"给你一个稳定统一的自定义 shading model 扩展位"。
关键点在这里:
Unlit 往往意味着你不再参与那套标准的光照求值流程,因此很多情况下确实也不依赖常规 GBuffer。但这带来的代价是,你也失去了大部分"作为一个真正 shading model"想要接入的能力。
你可以把它拆成两件事看。
第一,Unlit 确实能部分绕开 GBuffer 差异问题。
如果你用的是典型 Default Lit / Subsurface / Clear Coat / Cloth 这类模型,那么在延迟路径下它们会把一堆材质属性编码进 GBuffer,后面再统一做 lighting。这里不同平台、不同路径确实会有:
-
GBuffer layout 不同
-
可用 custom data 位不同
-
某些通道是否存在不同
-
Forward/Deferred 行为不一致
而 Unlit 一般不走这套完整的 lit GBuffer-lighting 流程,更多是直接输出到最终颜色或走更简单的材质路径。
所以如果你的目标只是"我不要碰那堆 GBuffer 编码和 shading model ID",那 Unlit 确实更省事。
但第二,问题也正出在这里:
你一旦用 Unlit,本质上就不是在"扩展一个 lit shading model"了,而是在"自己手搓一套假光照效果"。
这意味着你通常会失去或要自己补下面这些东西:
-
引擎标准光照积分
-
延迟光照那套灯光兼容
-
阴影/IBL/反射/环境光的标准接入
-
与现有 BRDF、light loop、material inputs 的自然兼容
-
某些后续渲染特性的自动支持
也就是说:
如果你只是想做"自发光风格化材质""假 Lambert""卡通 ramp""屏幕空间特效式材质",Unlit 很合适。
但如果你想做的是"一个真正参与 UE 光照系统的新 BRDF / 新材质模型",Unlit 就不够了。
你前面那段讨论里的"自定义 shading model"通常指的是后者,也就是希望它:
-
还能吃灯光
-
还能有阴影
-
还能进标准渲染路径
-
还能和其他 lit 材质一样工作
这时候 Unlit 只是逃课,不是解题。
更准确地说:
Unlit 解决的是"我不想跟 UE 的 lit shading model 架构硬碰硬"。
它不能解决"我想新增一个受光、可延迟、跨路径一致的新 shading model"。
另外还有一个容易误判的点:
就算你用 Unlit,也不代表"各平台就完全一致"。
因为平台差异不只来自 GBuffer,还来自:
-
移动/桌面材质编译分支不同
-
Forward/Deferred 可用节点和语义不同
-
某些 scene textures / lighting data / feature level 支持不同
-
后处理、颜色空间、精度、MSAA 路径差异
所以 Unlit 只是把"GBuffer 编码差异"这块问题大幅减弱了,不是让所有平台渲染行为天然统一。
一个更工程化的判断标准是:
如果你的目标是这些之一,用 Unlit 很合理:
-
卡通/风格化手写光照
-
纯 emissive 表现
-
自定义 NdotL / ramp / rim
-
不依赖 UE 标准灯光模型
-
能接受自己维护不同平台分支
如果你的目标是这些之一,Unlit 就不够:
-
新的 PBR/BRDF
-
正式接入引擎光照系统
-
延迟路径下像原生 lit model 一样工作
-
复用现有灯光、阴影、反射、GI 行为
-
希望和标准材质输入保持一致
所以对你这句的直接回答是:
Unlit 可以绕开很多 GBuffer 差异带来的痛点,但代价是你也退出了"真正的 shading model 扩展问题"。
它适合"自己画效果",不适合"新增一个原生受光材质模型"。