1.梦的开始------v1

YOLO(You Only Look Once) 。2015 年。Joseph Redmon 的这篇论文《You Only Look Once: Unified, Real-Time Object Detection 》彻底颠覆了计算机视觉领域。它超越了当时主流的检测器如Faster R-CNN ,以极快的检测速度与不俗的准确率著称。这里就不赘述了,我之前专门写了一篇文章介绍底层原理:yolov1底层解析
2.Better, Faster, Stronger------v2
yolo初来乍到,虽然有一个大的框架,但是在精度上还是有所欠缺。于是,原作者对yolo进行了改进。
2.1.Batch Normalization(批归一化)
yolov2 在每一个卷积层后面都添加了批归一化层,并去掉了 Dropout随机失活层。
-
底层原理 :在深层网络训练中,每层输入的分布会随参数更新而剧烈变动。BN 通过将每一小批(Batch)数据的特征映射强制归一化为均值为 0、方差为 1 的分布,使得梯度始终保持在激活函数的非饱和区。
-
改进效果 :这不仅解决了梯度消失问题,还起到了正则化作用。在 yolov2 中,这一项改进就提升了 2% 的 mAP。
2.2.High Resolution Classifier(高分辨率预训练)
-
痛点 :v1 是在 224 × 224 的 ImageNet 上练分类,直接跳到 448 × 448 练检测,网络会"不适应"突然增大的分辨率。
-
做法 :v2 在切换到检测任务前,先用 448× 448 的输入在 ImageNet 上再微调(Fine-tune )10 个 epoch。
-
底层原理:这让卷积核有时间学习更高分辨率下的特征表达,减少了分辨率切换带来的学习压力。
2.3.Anchor Boxes 与维度聚类(Dimension Clusters)
这是v2 最底层的逻辑转变:从"盲目回归"变为"基于先验的修正"。
-
K-means 聚类 :作者没有像Faster R-CNN 那样手动选 9 个固定比例的框。他跑了 COCO 和 VOC 的所有标注框,用 K-means (聚类算法)算法自动算出 5 组最具有代表性的宽和高。
-
底层原理 :手动设定的 Anchor 可能不符合数据的实际分布(比如全是细长的人,你设个正方形框就很低效)。聚类得到的先验框让模型从一开始就站在了"离终点更近"的起跑线上。
2.4.Direct Location Prediction(绝对坐标限制)
在引入 Anchor 后,v2 改进了坐标预测公式,防止模型初期训练时"乱跑"。
-
预测公式:
-
底层原理 :
是模型预测的偏移量,通过 Sigmoid 函数
-
对比 :如果不加 Sigmoid ,模型在初期可能预测出一个巨大的偏移量,导致中心点跳到图像另一头,网络极难收敛。
2.5.Pass-Through 层(细粒度特征融合)
-
做法 :v2 引入了一个类似 ResNet 但更简单的结构。它把 26 × 26 × 512 的特征图切开重排(拆成 4 份),变成 13× 13 × 2048,然后和深层特征拼接(Concat)。
-
底层原理 :浅层特征包含更多位置细节,深层特征包含更多语义信息。这种"降维堆叠"的方式让模型在处理 13 × 13 的最终检测图时,依然能利用来自浅层的细粒度空间信息,显著提升了对小目标的检测能力。这里其实有一点v3 的影子了,像是特征金字塔、U-net的缩影,结合不同维度的特征。
2.6.Multi-Scale Training(多尺度训练)
由于去掉了全连接层,yolov2 变成了全卷积网络(FCN)。
-
底层原理:作者每隔 10 个 batch 就随机改变输入的图像尺寸(从 320 到 608,步长 32)。
-
改进效果 :同一个网络被迫适应不同分辨率的输入。这让 yolov2 具有了极强的伸缩性:在低分辨率下快到飞起,在高分辨率下精度极高。
3.天才的陨落------v3
可惜由于特殊原因,导致v3 成了原作者的最后一舞。它在v2 的基础上引入了当时深度学习界最先进的几个概念:残差网络 (ResNet) 、多尺度预测 (FPN) 和 二分类交叉熵。
3.1.Backbone 的进化:Darknet-53
v2 使用的是 Darknet-19 ,而 v3 直接升级到了 Darknet-53。
-
底层原理:引入残差连接 (Shortcut Connection)。
借鉴了 ResNet 的思想,通过"跳连"让网络变得更深(53 层卷积),且不会出现梯度消失问题。
-
效果 :它比 ResNet-101 快 1.5 倍,比 ResNet-152 快 2 倍,但精度几乎一样。这让v3 在提取复杂特征时底气十足
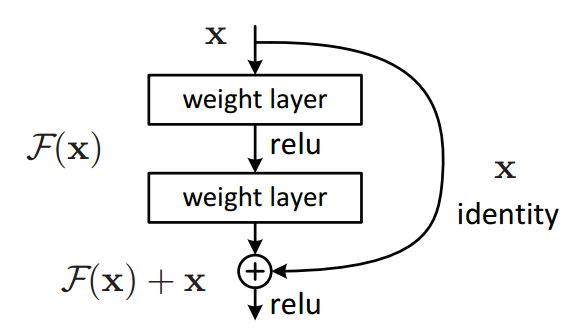
【附】残差网络简介
简单介绍残差网络吧,其实就是在模型规模打到一定程度的时候,模型的性能几乎停止,与当时人们认为的理念相悖:模型规模越大,性能应该更好。而规模再变大时,性能竟然出乎意料的下降了。这种"退化"现象说明新加入的参数甚至学不到一个"恒等映射"------也就是输入等于输出。
于是,既然这一部分发挥不了太大作用,干脆我们对它的期望就低一点,把目标值拆成两个部分:一个是原模型(性能停止前)的部分,一个是残差(目标与原模型预测值之差)的部分。也就是:
其中,是原模型的部分,
是真实标签,
是残差部分。在不影响模型运行速度的情况下,我们只需要加一个残差块,就能做到性能更高。
-
输入 x 进入第一个权重层(如卷积层),然后经过激活函数(如ReLU),再进入第二个权重层。
-
第二个权重层的输出 F(x) 计算出来之后,不会直接作为整个块的输出。
-
一个"快捷连接"将最初的输入 x 直接跳过一个或多个层,连接到第二个权重层的输出上。
-
这个快捷连接的操作就是 加法:F(x)+x。
-
最后,这个相加的结果再通过一个激活函数(如ReLU),作为整个残差块的最终输出。
3.2.核心改进:多尺度预测 (Predictions Across Scales)
这是 v3 解决"小目标检测差"的杀手锏。
-
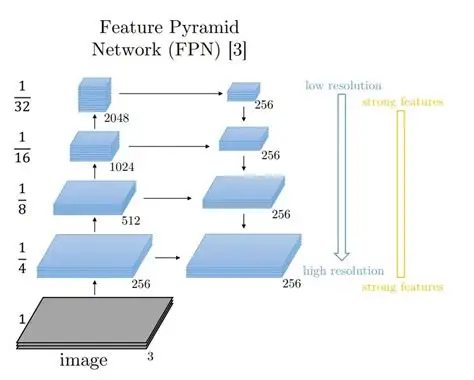
底层原理:类似 FPN (Feature Pyramid Networks)。
-
v3 不再只在最后一层做检测,而是在 3 个不同尺度 的特征图上进行检测。
-
这 3 个尺度的分辨率通常是 13 × 13(检测大物体)、26 × 26(中等物体)、52 × 52(检测小物体)。
-
-
特征融合 :深层特征经过上采样(Upsampling )后,与浅层特征进行拼接(Route),让高层语义和低层细节强强联手。
了解过U-net 的可以把这个当U-net理解。
【附】FPN简介
简单来说,在经历池化层时,图像数据的语义在下采样时被压缩。那么,在底层时,我们有高分辨率但语义不清楚的图像数据,而顶层我们有低分辨率但语义强的图像数据。为了将二者中和,我们将数据进行横向连接(通常是直接相加);为了能对各个尺度的目标都有好的检测效果,我们对每一层的数据都进行检测,这就是FPN。同时因为多层检测的原因,在进行聚类时得到的检测框也更多,提高了精准率。
3.3.分类器的改变:从 Softmax 到 Logistic
-
底层原理 :v3 放弃了 Softmax ,改用独立的 Logistic 回归(二分类交叉熵)。
-
为什么要改?
-
Softmax强制要求一个目标只能属于一个类(互斥)。
-
但在现实中,一个目标可能有多个标签,比如"女人"和"人"。使用独立的 Logistic 回归允许模型预测出多个高概率类别。
-
4.火炬的接力------v4
2020 年,在原作者退出后,AlexeyAB 接手了这一重任。yolov4 的核心逻辑不再是发明某种单一的革命性结构,而是集百家之长。
4.1.架构的铁三角:CSP + PAN + SPP
yolov4 确立了现代目标检测器的经典三段式结构:
-
Backbone: CSPDarknet53
-
原理 :在 Darknet53 的基础上引入了 CSP (Cross Stage Partial) 结构。它将特征图拆成两部分,一部分经过卷积,另一部分直接连接。以我们的yolo 检测为例,有些训练集可能就包含一两个检测目标,那么就浪费了其他的图空间。经过卷积的不用多说,提取特征;经过直接连接的部分则保留了精力,减少了计算量。
-
效果 :解决了梯度信息重复的问题,在减少计算量的同时提升了精度。这也是为什么后来的 v5 到 v8 全都在用 CSP 的原因。
-
-
Neck: SPP + PAN
-
SPP (Spatial Pyramid Pooling) :在主干网络末端加入空间金字塔池化。它通过不同尺度的池化核(如 5 × 5, 9 × 9, 13 × 13)提取特征,显著增加了感受野,让模型能"看清"更大的物体。
-
PAN (Path Aggregation Network) :v3 只用了自上而下的特征融合,v4 引入了自下而上的路径。这让底层的位置信息能更快地传到高层。
-
4.2.Bag of Freebies (BoF):不增加推理成本的优化
这是指那些只在训练时增加计算量,但不影响识别速度的技巧。
-
Mosaic 数据增强 :这是 v4 的神来之笔。它把 4 张随机图片拼成一张,强制模型在更小的尺度上识别物体。
- 底层原理 :变相增大了 Batch Size ,让模型在一个 batch 里能看到更多的上下文,对小目标极其友好。
-
Label Smoothing (标签平滑):防止模型在分类时过于"自信",提高泛化能力。公式如下:
-
-
-
效果如下,从:
猫:[1.0, 0.0, 0.0]到:
猫:[0.9, 0.05, 0.05]- CIoU Loss :相比 v2/v3 的坐标回归,CIoU 同时考虑了重叠面积、中心点距离和长宽比,让框的收敛速度飞快。公式如下:
-
-
-
-
-
4.3.Bag of Specials (BoS):微增成本换取大额收益
这是指那些稍微增加一点点计算量,但精度提升巨大的改进。
-
Mish 激活函数:替代了传统的 ReLU。
-
公式 :
-
原理:它在负值区域有微弱的梯度,且曲线更平滑。实验证明,Mish 更有利于深度网络的梯度流动。
-
-
SAM (Spatial Attention Module):引入了空间注意力机制,让模型学会"该看哪里"。如图:
输入特征图 (C=2, H=4, W=4):
通道1: [1, 1, 1, 1] 通道2: [2, 2, 2, 2]
[1, 1, 1, 1] [2, 2, 2, 2]
[1, 1, 1, 1] [2, 2, 2, 2]
[1, 1, 1, 1] [2, 2, 2, 2]Step 1: 沿着通道求平均
平均池化: [1.5, 1.5, 1.5, 1.5]
[1.5, 1.5, 1.5, 1.5]
[1.5, 1.5, 1.5, 1.5]
[1.5, 1.5, 1.5, 1.5]Step 2: 沿着通道求最大值
最大池化: [2, 2, 2, 2]
[2, 2, 2, 2]
[2, 2, 2, 2]
[2, 2, 2, 2]Step 3: 卷积学习(假设卷积核学会了关注中心区域)
注意力图: [0.1, 0.1, 0.1, 0.1]
[0.1, 0.9, 0.9, 0.1]
[0.1, 0.9, 0.9, 0.1]
[0.1, 0.1, 0.1, 0.1]最终输出: 原特征图 × 注意力权重
5.再创经典------v5
它在 2020 年由 Ultralytics 公司发布。虽然当时它没有发表正式的学术论文,但它凭借极其顺滑的 PyTorch 代码体验和工程化的高度完成度,直接统治了工业界好几年。
5.1.架构:CSP 结构的全面胜利
YOLOv5 在架构上深受 v4 的启发,但做了进一步的精简和优化:
-
Backbone: New CSP-Darknet53
-
核心模块:C3 模块 。它是 YOLOv4 中 CSP 结构的简化版。
-
底层原理 :通过将特征图分为两个分支,一个分支进行多次卷积(BottleNeck),另一个分支直接通过。最后将两者拼接。
-
效果 :这种设计极大地减少了计算量,同时保证了特征提取的深度,是 YOLOv5 跑得飞快的核心原因。
-
-
Neck: FPN + PAN
- 沿用了v4 的双向特征融合,确保了多尺度检测能力。
-
Head: 耦合检测头
- 此时依然采用分类和回归在一起的耦合头(直到 v6/v8 才分开)。
5.2.两个革命性的"自动化"改进
YOLOv5能够迅速普及,主要是因为它把以前需要"手动调参"的工作给自动化了:
-
Auto-Anchor (自适应锚框计算):
-
痛点 :在 v2/v3/v4 中,如果你换了数据集,必须手动运行 K-means 脚本来算 Anchor 大小。
-
底层原理 :v5 在训练开始前,会自动检查数据集的标签分布。如果当前的Anchor 不合适,它会利用遗传算法 (Genetic Algorithm) 自动进化出最匹配的一组 Anchor。
-
效果 :小白用户也能直接上手,完全不需要关心 Anchor 怎么设。
-
-
Adaptive Image Padding (自适应图片缩放):
-
底层原理 :在推理时,以往需要将图片补齐到固定的 640 × 640(会有很多黑边)。v5 会根据图片比例计算出最少的黑边填充量。
-
效果:减少了无效计算,推理速度提升了约 30%。
-
【附】图像补齐
YOLO有固定的下采样倍数(通常是 32倍)。这意味着:
-
网络的输出特征图尺寸 = 输入尺寸 / 32
-
如果输入尺寸不能被32整除,就会产生"小数"尺寸,导致维度不匹配或计算错误
传统解决方案(固定填充):
-
将所有图片缩放到固定尺寸(如 640x640)
-
强行拉伸或压缩图片,导致物体变形,影响检测精度
Adaptive Padding 的解决思路:
-
保持图片的原始宽高比不变
-
只对短边进行最小必要的填充,使其能被步长整除
-
而不是将所有图片都强行填充到同一个正方形
5.3.损失函数的演进
YOLOv5 默认使用了 CIoU Loss,并优化了正负样本匹配策略:
-
邻域正样本策略 :在 v3 中,一个目标只由一个网格负责。而在 v5 中,如果目标中心靠近网格边缘,相邻的网格也会被标记为正样本。
-
效果:这大大增加了正样本的数量,加速了模型的收敛。
6.再快一点------v6
YOLOv6 是由美团视觉智能部在 2022 年发布的,它标志着 YOLO 系列正式进入了"重参数化(Re-parameterization )"和"工业专用"的新阶段。它针对工业界追求的极高推理速度(尤其是 TensorRT 加速)进行了深度压榨。
6.1.核心底层逻辑:重参数化 (RepVGG 思想)
YOLOv6 最核心的改进是引入了 RepVGG 的重参数化概念。
-
训练时(复杂) :为了让模型学得更深、更准,Backbone 在训练阶段使用了包含 3 × 3 卷积、1 × 1 卷积和恒等映射(Identity)的多分支结构。
-
推理时(极简):在部署到设备上时,通过数学上的"算子融合",将所有的分支全部合并成一个单一的 3 × 3 卷积。
-
底层原理:这种"训练和推理架构不一致"的操作,既保证了训练时的多路径梯度流动(强学习能力),又保证了推理时的单路串行速度(对硬件极其友好)。
6.2.架构的大换血:从 CSP 到 EfficientRep
YOLOv6 抛弃了以往常用的 Darknet 架构,转而使用:
-
Backbone (EfficientRep) :利用刚才提到的重参数化块组成。在小模型(YOLOv6-N/S )中表现极佳,能充分利用硬件的计算密度。EfficientRep本质上是一套"硬件优先"的网络设计方案**。** 它通过将训练时的复杂结构(RepVGG Block)在推理时重参数化为高效的3x3卷积,解决了分类/回归精度与硬件运行速度之间的矛盾。说白了就是在真正考虑各种硬件算力的情况下构建的网络。
-
Neck (Rep-PAN):同样使用了重参数化思想来增强特征融合。
-
Head (Decoupled Head) :这是 YOLO 系列中较早正式引入"解耦头"的版本。
-
原理 :将分类(Classification )和定位(Regression)任务分开。分类关注哪个特征最像"狗",回归关注"狗"的边界在哪里,避免二者在预测时互相打扰。
-
效果:解决了两个任务对特征敏感度不同的冲突,显著提升了收敛速度。
-
6.3.标签分配策略:SimOTA
-
背景 :在 v5 时代,哪些网格算正样本是比较"死板"的。
-
v6 做法 :引入了 SimOTA(一种动态样本分配策略)。
-
底层原理 :它会根据当前模型对目标的预测情况(代价函数),动态地给每个目标分配最合适的"专家"网格。这让模型在处理重叠物体和复杂背景时,表现得比 v5聪明得多。
7.速度之王------v7
它被誉为"实时目标检测之王",在 5 FPS 到 160 FPS 的范围内,无论是速度还是精度,都超过了当时已知的所有检测器。其底层原理的核心在于:极其精妙的梯度路径设计。
7.1.核心底层逻辑:E-ELAN(扩展的高效层聚合网络)
这是 YOLOv7 的灵魂,也是它比v5、v6更强大的原因。
- ELAN 的进化 :之前的网络(如 v5 的 C3)主要关注减少参数量,但忽略了梯度路径的长度。
梯度路径可以理解为后面多项式的项数。梯度路径过长会导致底层梯度消失。
-
底层原理 :E-ELAN 通过"控制短路连接",让网络在不断加深、加宽的同时,依然能保持高效的梯度流动。它不是简单地堆叠层,而是通过 Shuffle (打乱) 和 Merge(合并) 策略,让不同层学习到的特征能够互补。
-
效果:模型学习能力极强,且不会因为网络变复杂而导致训练难以收敛。
7.2.策略黑科技:模型重参数化(Model Re-parameterization)
虽然 YOLOv6 也用了重参数化,但 YOLOv7 玩得更细:
-
Planned Re-param :作者发现,并不是所有地方加重参数化都有用。他通过严谨的实验,确定了在哪些残差结构(Residual )或拼接结构(Concatenate)中加入重参数化能获得最大收益。
-
底层原理 :在训练时使用多分支(带 BN 层),推理时将 BN 的参数融合进卷积权重中。这让 YOLOv7在推理阶段变成一个极其简单的卷积序列,跑得飞快。
7.3.标签分配的"师徒制":Lead Head & Auxiliary Head
这是 YOLOv7 提升训练精度的又一绝招:
-
辅助头(Auxiliary Head):在网络中间层加一个额外的检测头,负责辅助训练。
-
领先头(Lead Head):负责最终输出的检测头。
-
底层原理 :由"领先头"生成软标签(Soft Labels),指导"辅助头"去学习。这就像老师带学生,领先头负责全局把控,辅助头负责强化中间层的特征提取能力。
7.4.其它"大礼包"优化
- Scaling 策略 :v7 提出了一种新的复合缩放方法。它不是单纯地把网络变宽或变深,而是同时按比例缩放深度和宽度。这保证了模型在不同尺寸下都能保持最优的参数效率。
8.删繁就简,正本清源------v8
8.1.Backbone 的核心:从 C3 到 C2f
在 YOLOv5 中,核心模块是 C3 ;而在 YOLOv8 中,变成了 C2f (CSP Bottleneck with 2 convolutions)。
-
底层原理 :C2f 结合了 YOLOv5 的 C3 思想和 YOLOv7 的 ELAN 结构。它在保持轻量化的同时,通过更多的跨层分支连接,增加了梯度流的丰富度。
-
直观理解 :如果说 C3 是三条水管并行,C2f 就像是加了更多纵横交错的细分水管,让特征信息在网络中流动得更充分,减少了特征丢失。
8.2.彻底的革命:回归 Anchor-Free(无锚框)
这是 v8 与 v2-v7 最大区别。
-
为什么要去掉 Anchor? 预设 Anchor (先验框)需要针对不同数据集进行聚类(K-means),如果聚类不好,模型上限就很低。
-
v8 的做法 :直接预测目标的中心点以及到四个边界的距离***(LTRB)***。
-
底层原理 :它引入了 Task-Aligned Assigner ( 任务对齐分配器**)** 。它不再根据 IoU 硬性规定哪个网格负责哪个物体,而是根据"分类得分"和"定位精度"的加权结果,动态决定正样本。这让模型在处理不规则物体时灵活性极高。
-
-
-
-
这个公式深刻洞察了分类与定位的关系:一个高质量的预测框,必须同时在这两项任务上表现优异 。
8.3.Head 层:解耦头 (Decoupled Head)
YOLOv8 采用了和v6类似的解耦设计,将分类和回归任务完全拆开。
-
架构设计:模型末端分成了两个并行的分支。一个分支专门负责猜"这是什么"(分类),另一个分支专门负责猜"框在哪里"(定位)。
-
Loss 函数的精妙配合:
-
分类分支 :使用 VFL (Varifocal Loss),它能更好地处理正负样本极其不平衡的情况。
-
回归分支 :使用CIoU + DFL (Distribution Focal Loss)。
-
DFL :由于没有了预设的 Anchor 框,定位变得很模糊。DFL 不再只预测一个确切的坐标,而是预测坐标的一个概率分布。这让模型在目标边缘模糊(比如遮挡、运动模糊)的情况下,定位依然非常稳健。假设我们想预测左边界距离。传统方法直接猜一个值(如7.2)。DFL则把它分成0-15共16个"桶",模型的任务是预测一个概率分布,比如距离为7的概率是10%,距离为8的概率是80%,距离为9的概率是10% ,然后计算期望值。
-
8.4.训练策略:最后 10 个 Epoch 的魔力
你在看训练日志时可能会发现,最后阶段精度会有个小跳升。
-
原理 :YOLOv8 在训练最后 10 个 epoch 时会关闭 Mosaic 数据增强。
-
逻辑:Mosaic 虽然能增加数据多样性,但由于它把图片强行拼接,会导致真实的边界信息受到干扰。最后阶段关掉它,能让模型在真实图像分布上进行"精修",从而压榨出最后的 mAP 提升。