YOLO26改进创新 | 全网首发!VECA弹性核心注意力重塑全局建模,线性复杂度增强检测骨干,嘎嘎创新!
本文围绕 VECA 的原始论文思想与 YOLO26 检测适配策略展开

一、原文链接
-
论文标题:Elastic Attention Cores for Scalable Vision Transformers
-
论文地址:https://arxiv.org/abs/2605.12491
二、为什么这篇工作值得拿来做 YOLO26 改进
原文研究的是如何让视觉 Transformer 在高分辨率场景下摆脱二次复杂度束缚,通过少量可学习 core token 代替全量 patch 两两交互。
对目标检测研究者来说,真正值得借鉴的从来不只是"原论文在原任务上做得强不强",更关键的是:它解决的到底是不是一个我们在检测里也会频繁碰到的核心矛盾。VECA 在这一点上很典型,因为它瞄准的是 高分辨率视觉 Transformer 的全局注意力代价过大。、密集预测任务需要全局上下文,又不能放弃细粒度 token。 和 传统 cross-attention 容易形成过强的低维瓶颈。。这些问题在原论文里出现于 Elastic Attention Cores for Scalable Vision Transformers 对应的任务域,但一旦转到 YOLO26,我们会发现它们几乎都能在检测特征流中找到对应影子。

三、原文摘要翻译
原文摘要指出,视觉 Transformer 依赖全连接自注意力获得优异的可扩展性,但这种能力的代价会随着分辨率上升而呈二次增长。作者挑战了"必须存在 patch 与 patch 直接交互"这一隐含前提,提出 VECA,也就是 Visual Elastic Core Attention。它使用少量可学习 core token 作为通信接口,让所有 patch 通过 core 完成信息交换,从而把复杂度压到与 patch 数近似线性相关。更重要的是,VECA 并没有像某些压缩式 cross-attention 一样把信息彻底挤压成小瓶颈,而是完整保留了所有输入 token,并在层间持续更新它们。因此,这个结构在分类和密集预测任务上都表现出非常强的可扩展性和推理弹性。
四、原文引言翻译整理
引言部分的核心信息可以概括为三层。第一层,作者认为高分辨率视觉任务之所以难做,不只是因为分辨率高,而是因为标准自注意力把任意两个 patch 都当成潜在交互对,导致代价随 token 数暴涨。第二层,作者进一步指出,很多视觉关系并不需要每个 patch 都与所有 patch 正面相撞,一个结构良好的中介层就可以承担跨区域语义聚合。第三层,作者把这种观点落实为少量核心 token 的设计:核心 token 负责聚合和分发信息,而 patch token 保留自己原生的局部描述能力。对检测来说,这个思路很有吸引力,因为检测主干既要看局部边缘,又要理解全局语义布局。

五、原理解析:把论文的核心抓手翻成检测语言
如果只把论文名字背下来,而不知道它真正改变了哪条信息流,那改进文章通常会写得很虚。VECA 的价值并不在"换了个更复杂的块",而在于它重新定义了特征在网络内部应当如何流动。
首先,从原文角度看,作者强调的关键抓手包括:引入少量可学习 core token 作为信息中枢。;patch 只与 core 通信,core 再回流信息给 patch。;维持全量 patch 表达,兼顾效率与表示丰富度。。这些抓手如果直接照抄到检测网络里,要么接口不兼容,要么成本过高。因此,真正高质量的 YOLO26 融合写法不是整网照搬,而是抓住最能转化成 2D feature block 的那部分思想。
其次,从检测角度看,YOLO26 的优势是高效、多尺度、训练稳定,但它并不是面面俱到的通用最优器。当我们把检测任务放到复杂背景、长距离依赖、统计漂移、上采样细节损失或恶劣天气退化这些问题上时,传统 Conv + C3k2 + Neck 融合流程会暴露出比较明显的短板。VECA 恰好提供了一个足够清晰的研究方向:在不破坏 YOLO26 主流程的前提下,用一个相对克制的独立模块,把最脆弱的那条特征链路补强。
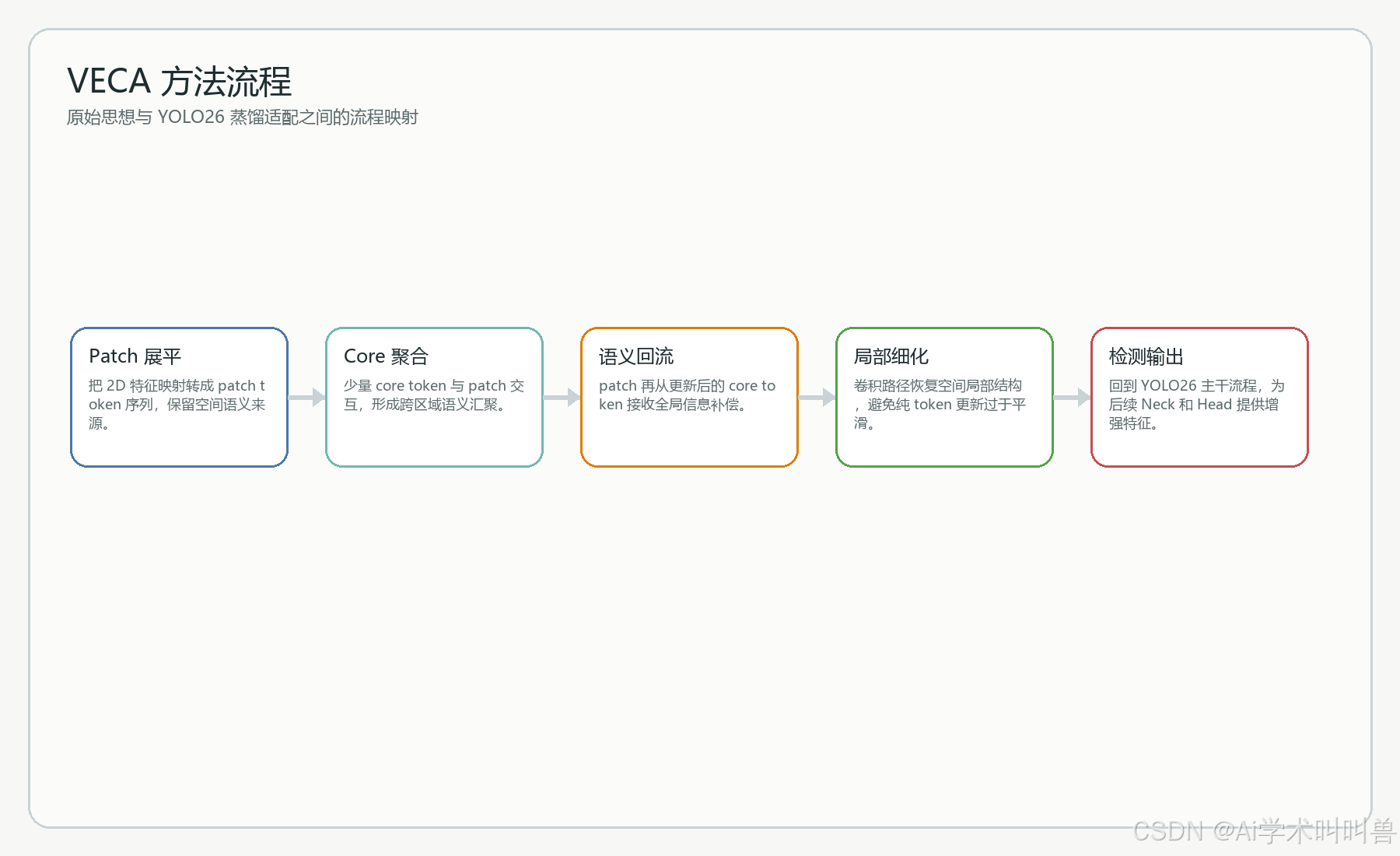
六、关键公式与数学直觉
下面只保留最值得写进专栏、也最容易帮助读者建立直觉的核心公式,而不是把原文所有符号照搬一遍。
核心交互
C^{l+1}=C^l+Attn(C^l,[C^l;P^l],[C^l;P^l])
核心 token 从自身与 patch 的拼接集合中吸收信息,承担跨区域语义汇聚。
语义回流
P^{l+1}=P^l+Attn(P^l,C^{l+1},C^{l+1})
patch token 只与更新后的 core 交互,获得全局上下文,但不与所有 patch 两两计算。
复杂度收益
O(NC),\ C\ll N
当核心 token 数远小于 patch 数时,总体复杂度接近线性,是 VECA 能服务高分辨率任务的关键。

从写作上讲,这样处理有两个好处。第一,读者能迅速抓住论文到底控制了哪个变量。第二,后面讲 YOLO26 融合时,可以自然把这些公式映射到"模块插在什么位置、改变了什么信息流、为什么这会帮助检测"这三个问题上。
七、原文方法图表解读
如果我们把原文的方法图拆开来看,它本质上都在处理同一件事:不是简单把特征算得更大,而是把特征算得更对。所谓"更对",对应的是三层含义。
第一层,是输入表征是否足够保留对任务有用的结构信息。
第二层,是中间处理过程是否在不必要的地方丢掉了边缘、层级或统计多样性。
第三层,是输出特征是否真正适合下游任务,而不是只在原论文自己的评价协议里好看。从这个角度出发,我们在专栏里解读原文图表时,重点就不该停留在"模块名字是什么",而应放在"作者到底在哪个环节发现了信息损失,又用什么机制把它救回来"。这也是把论文读懂、讲透并最终迁移到 YOLO26 的关键一步。
八、YOLO26 融合改进创新点
-
把视觉 Transformer 的线性复杂度全局建模思想蒸馏成检测友好块,而不是生硬替换整个主干。
-
在 P3/P4/P5 做语义增强,比在浅层使用更符合目标检测的特征分工。
-
用少量 core token 处理跨区域依赖,推理代价可控,且更容易和 C3k2、C2PSA 共存。
更进一步地说,这种融合写法的价值并不只是"我给 YOLO26 又加了一个新块"。真正的创新点在于,你把原论文最有信息含量的机制抽出来,重新安排到目标检测最需要它的位置上。这样形成的文章,不会流于"换模块"的流水账,而会更像一篇有研究判断力的结构创新笔记。

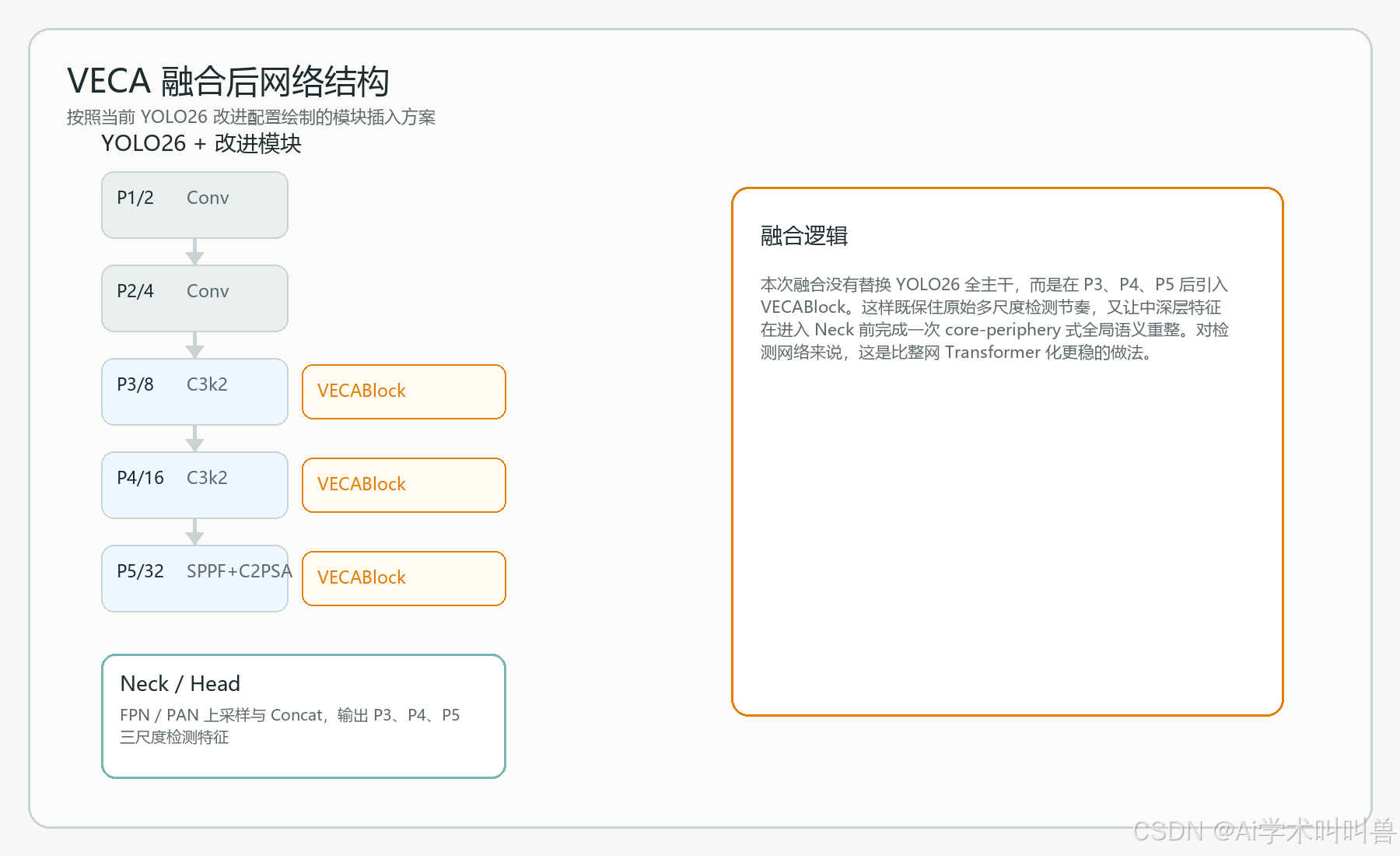
九、融合前后网络结构对比
在原始 YOLO26 中,主干和 Neck 的分工已经非常清晰:Backbone 负责逐级提炼语义,Neck 负责多尺度对齐,Head 负责检测输出。这套框架的优点是稳、快、成熟,但它默认所有节点的特征更新都遵循统一逻辑。问题恰恰出在这里:不同研究问题需要被修复的链路并不相同。
基线 YOLO26 通过 Conv、C3k2、SPPF 和 C2PSA 构成主干,语义能力主要来自卷积堆叠与轻量注意力。它足够高效,但在特别复杂的背景或中大目标语义对齐上,仍然更偏局部建模。
本次融合没有替换 YOLO26 全主干,而是在 P3、P4、P5 后引入 VECABlock。这样既保住原始多尺度检测节奏,又让中深层特征在进入 Neck 前完成一次 core-periphery 式全局语义重整。对检测网络来说,这是比整网 Transformer 化更稳的做法。
十、模块改进前后对比

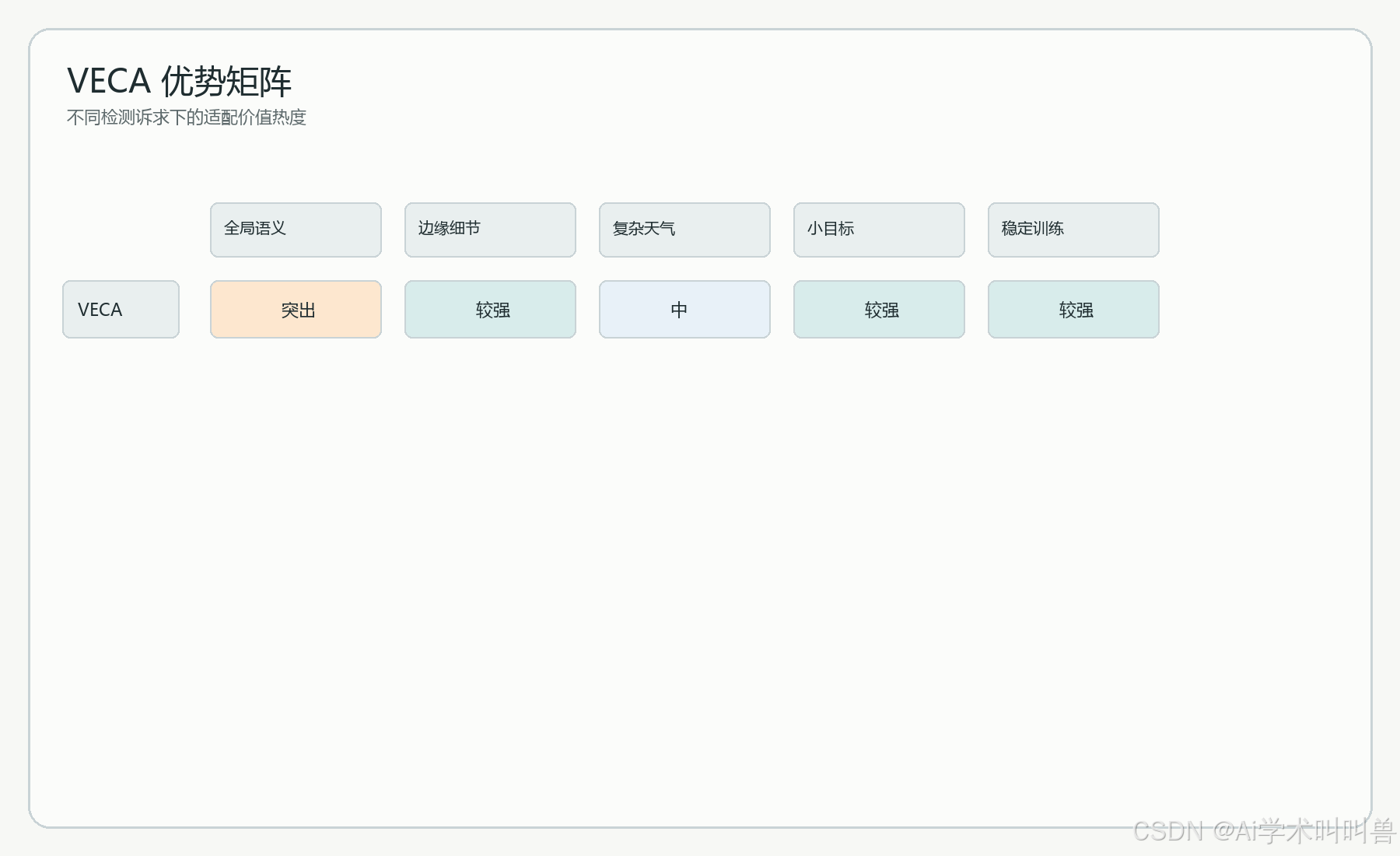
从检测视角总结,融合前后的变化至少可以从以下四个层面理解:
-
全局关系建模:融合前 主要依靠卷积层级叠加与 C2PSA;融合后 通过 core token 完成跨区域信息交换
-
复杂度增长方式:融合前 卷积稳定但远距离关系表达有限;融合后 用少量 core 近似全局上下文,复杂度更可控
-
细节保留:融合前 局部纹理保留较好;融合后 保留全 patch 后再做全局补偿,兼顾细节与语义
-
工程适配 :融合前 原始主干结构固定;融合后 作为独立块插入 P3/P4/P5,迁移成本低
十一、核心思想代码片段
如下:
```python
class VECABlock(nn.Module):
def forward(self, x):
patches = x.flatten(2).transpose(1, 2)
cores = self.core_tokens.expand(x.size(0), -1, -1)
cores = cores + self.core_attn(self.core_norm(cores), self.patch_norm(torch.cat((cores, patches), 1)), self.patch_norm(torch.cat((cores, patches), 1)), need_weights=False)[0]
patches = patches + self.patch_attn(self.patch_norm(patches), self.core_norm(cores), self.core_norm(cores), need_weights=False)[0]
return self.out(x + self.local(patches.transpose(1, 2).reshape_as(x)))
```十二、原理、创新点与写作思路如何展开
VECA 这类模块尤其适合做"原理型改进文章",因为它既有论文层面的新意,又有结构迁移上的可解释性。只要你把"为什么插这里、为什么这样蒸馏、为什么这样比直接照搬更稳"讲清楚,整篇文章的质量就会上一个台阶。
十三、总结
总体来看,VECA 融合到 YOLO26 的意义,不在于制造一个花哨的新名词,而在于为检测网络补上一条原本相对薄弱的信息链路。它可能补的是全局语义,可能补的是多层 richness,可能补的是残差统计纪律,也可能补的是上采样边缘细节或复杂天气下的结构净化。但无论具体形式如何变化,真正高阶的创新写法始终遵循同一条逻辑:先识别 YOLO26 的真实短板,再从原文中提炼最适合检测的那部分机制,最后用结构、公式、图表和对比把这件事讲透。