
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
[一、二叉搜索树的核心概念:什么是 BST?](#一、二叉搜索树的核心概念:什么是 BST?)
[三. 二叉搜索树的实战实现](#三. 二叉搜索树的实战实现)
[2、BST 类核心操作:Insert、Find、Erase](#2、BST 类核心操作:Insert、Find、Erase)
[2.1 插入操作(Insert)](#2.1 插入操作(Insert))
[2.2 查找操作(Find)](#2.2 查找操作(Find))
[2.3 删除操作(Erase):最复杂的核心操作](#2.3 删除操作(Erase):最复杂的核心操作)
[四、BST 的扩展:key/value 模型(支持映射场景)](#四、BST 的扩展:key/value 模型(支持映射场景))
[1、key-value 模型节点与类实现](#1、key-value 模型节点与类实现)
[2、key-value 模型实战场景](#2、key-value 模型实战场景)
[2.1 场景 1:简单字典(中英互译)](#2.1 场景 1:简单字典(中英互译))
[2.2 场景 2:单词统计(统计水果出现次数)](#2.2 场景 2:单词统计(统计水果出现次数))
前言
在数据结构中, 二叉搜索树(Binary Search Tree,简称 BST) 是一种兼具 "有序性" 与 "高效操作" 的树形结构,它通过特定的节点值排列规则,让增删查操作的时间复杂度在理想情况下可达到 O(log₂N) 但是最坏情况仍然是 O(N)。本文将从二叉搜索树的核心概念入手,结合实战代码,逐步拆解其插入、查找、删除并手撕这三大操作的实现代码,帮你彻底掌握这一基础数据结构。
一、二叉搜索树的核心概念:什么是 BST?
二叉搜索树 又称二叉排序树 ,它要么是空树,要么是满足以下值分布规则的二叉树:
- 若左子树不为空,则左子树中所有节点的值 ≤ 根节点的值;
- 若右子树不为空,则右子树中所有节点的值 ≥ 根节点的值;
- 左、右子树也分别是二叉搜索树,即仍然满足上述条件(递归定义)。
- 二叉搜索树可以支持插入相等的值 ,也可以不支持插入相等的值 ,具体看使用场景定义,后续我们学习 map/set/multimap/multiset 系列容器底层 就是二叉搜索树,其中 map/set 不支持插入相等值,multimap/multiset 支持插入相等值。
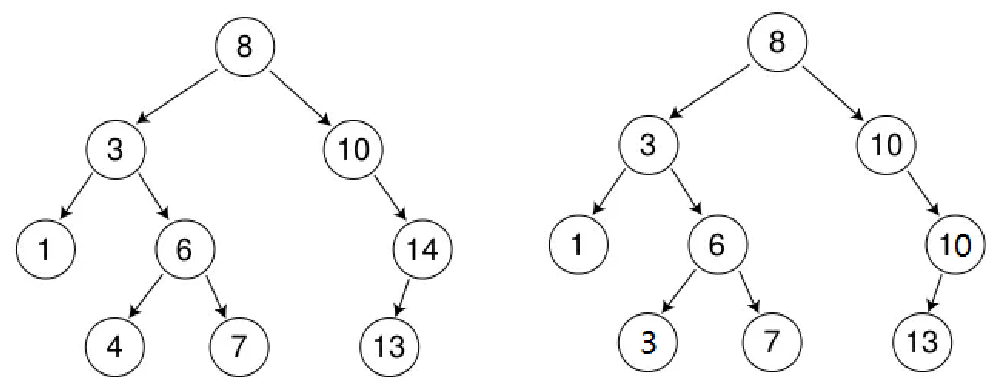
关键特性 :中序遍历为有序序列
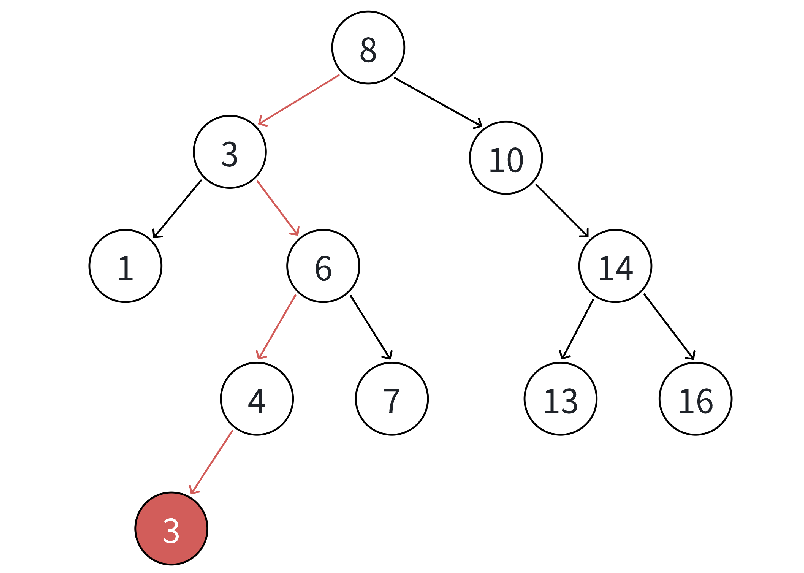
二叉搜索树的核心价值 在于 "中序遍历结果是升序序列" 。例如,上图左边 BST 的中序遍历结果为1 3 4 6 7 8 10 13 14,天然具备 "排序" 属性,这也是其 "二叉排序树" 名称的由来。
关于 "相等值" 的约定:
BST 对相等值的处理可灵活定义,具体取决于场景:
(1)不支持相等值插入(如 map/set 底层):插入时若值已存在,直接返回失败;(可用于剔除重复数据的情景)
(2)支持相等值插入(如 multimap/multiset 底层):相等值需统一插入左子树或右子树(保持逻辑一致,避免后续查找混乱)。
本文实现的 BST 默认不支持相等值插入。
二、二叉搜索树的性能分析:理想与最差情况
BST 的操作效率直接取决于树的 "高度",而 BST 的高度由节点插入顺序决定,则存在两种极端情况:
| 场景 | 树的形态 | 高度 | 增删查时间复杂度 | 典型插入顺序 | 核心影响因素 |
|---|---|---|---|---|---|
| 理想情况 | 完全二叉树(接近平衡) | log₂N | O(log₂N) | 随机插入(如8,3,10,1,6) | 插入顺序无序,节点均匀分布在左右子树 |
| 最差情况 | 单支树(退化为链表) | N | O(N) | 有序插入(如 | 插入顺序严格递增/递减,节点仅向单侧延伸 |
综合来看二叉搜索树增删查改时间复杂度为:O(N)
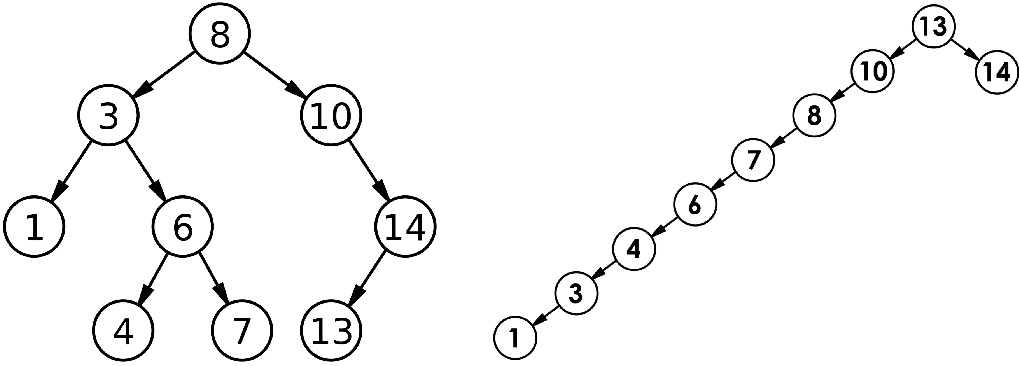
与 "二分查找" 的对比
二分查找虽也能实现 O(log₂N) 的查找效率,但存在明显缺陷:
- 依赖支持随机访问 的结构(如数组),且查找前需提前对结构内的数据进行排序;
- 二分查找只适用于查找数据,插入 / 删除数据效率低:数组中插入 / 删除元素需挪动大量数据,时间复杂度为O(N)。
而 BST 无需提前排序 ,且插入 / 删除时仅需修改对应节点指针,避免了数据挪动,这也是其在动态数据场景中更具优势的原因。
三. 二叉搜索树的实战实现
采用 C++ 模板实现,支持泛型K(可以选择存放内置类型数据或者存放自定义类型数据的二叉搜索树)(核心包含节点结构定义 与BST 类的三大操作(插入、查找、删除) ,同时提供中序遍历 接口验证有序性。
1、节点结构定义:BSTNode
BST 的节点需存储 "值" 与 "左右子树指针",模板化设计使其可适配 int、string 等多种类型:
cpp
//BinarySearch.h
#include <iostream>
using namespace std;
template<class K>
class BSTNode
{
public:
// 构造函数:初始化列表指针为空,键值为传入值
BSTNode(const K& key = 0)
:_key(key)
, _left(nullptr)
, _right(nullptr)
{
}
K _key; // 节点键值
BSTNode<K>* _left;// 左子树指针
BSTNode<K>* _right;// 右子树指针
};2、BST 类核心操作:Insert、Find、Erase
BST 类封装了树的根节点_root,并通过私有辅助函数 _Print(const Node* root) 实现成员函数 Print() 中序遍历。以下是三大核心操作的详细实现与解析:
2.1 插入操作(Insert)
插入的核心逻辑是 "按 BST 规则找到空位置,创建新节点并链接",步骤如下:
- 若树为空( _root == nullptr ),则直接新增结点,赋值给_root根节点指针;
- 树非空时,用 cur 指针遍历树找到符合要求的空位置:
- 若 cur -> _key < 插入值 :向右子树移动( cur = cur -> _right );
- 若 cu r-> _key > 插入值:向左子树移动( cur = cur -> _left );
- 若值相等(不支持插入),返回 false;
找到空位置后,通过 father 指针(记录 cur 的父亲节点)将新节点链接到树中。
代码实现:
cpp
template<class K>
class BSTree
{
public:
typedef BSTNode<K> Node;
//二叉搜索树的插入
bool Insert(const K& key)
{
//树为空,则直接新增结点,赋值给root指针
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点
//我们通过一个cur来记录要判断走哪的指针,father来记录cur的父亲结点便于找到后连接cur
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > key)
{
father = cur; //先将当前cur位置存到father
cur = cur->_left; //再移动cur
}
else if (cur->_key < key)
{
father = cur;
cur = cur->_right;
}
else //相同则则不符合插入规则,返回false
{
return false;
}
}//while循环结束则说明找到了插入位置
cur = new Node(key);
//由于cur位于father的左边还是右边不确定,所以需要判断一下
if (father->_left == cur)
{
father->_left = cur;
}
else
{
father->_right = cur;
}
return true;
}
//中序遍历
void Print()
{
_Print(_root);//类中可以访问私有成员变量_root
cout << endl;
}
private:
//因为对象调用Print(const Node* root)函数时
//无法传_root(私有无法访问),所以在类中我们套一层_Print即可
void _Print(const Node* root)
{
if (root == nullptr)
{
return;
}
_Print(root->_left);
cout << root->_key << " ";
_Print(root->_right);
}
private:
Node* _root = nullptr;
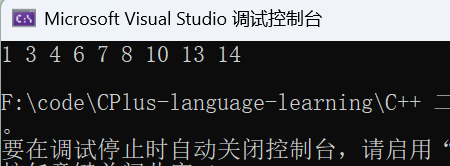
};测试代码:
cpp
//Test.cpp
#include "BinarySearch.h"
void Test1()
{
//插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print();
}
int main()
{
Test1();
return 0;
}
2.2 查找操作(Find)
查找的逻辑与插入类似,按 BST 规则遍历树,步骤如下:
- 从根节点 _root 开始,用 cur 指针遍历;
- 若 cur -> _key < 目标值:向右走;若 cur -> _key > 目标值:向左走;
- 找到目标值返回 true,遍历到空节点(未找到)返回 false。
代码实现:
cpp
//二叉搜索树的查找
bool Find(const K& x)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
{
cur = cur->_left;
}
else if (cur->_key < x)
{
cur = cur->_right;
}
else
{
return true;
}
}
return false;
}测试代码:
cpp
//Test.cpp
#include "BinarySearch.h"
void Test1()
{
//插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
//查找
cout << bst1.Find(6) << endl;
cout << bst1.Find(11) << endl;
}
int main()
{
Test1();
return 0;
}
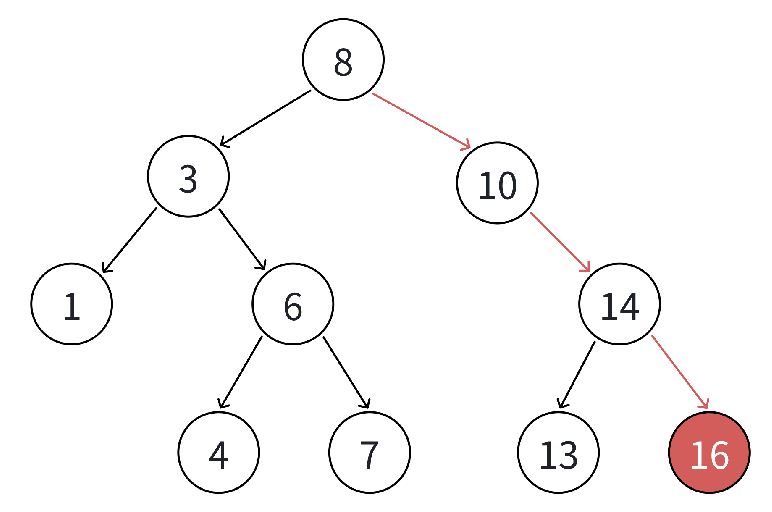
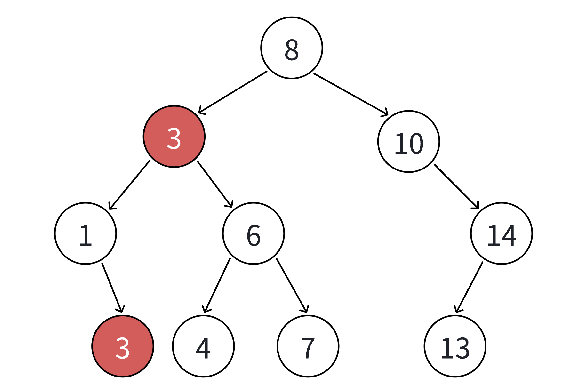
如果支持插入相等的值,意味着有多个 x 存在,一般要求查找中序的第⼀个 x。如下图,查找3,要找到1的右孩子的那个3返回:
2.3 删除操作(Erase):最复杂的核心操作
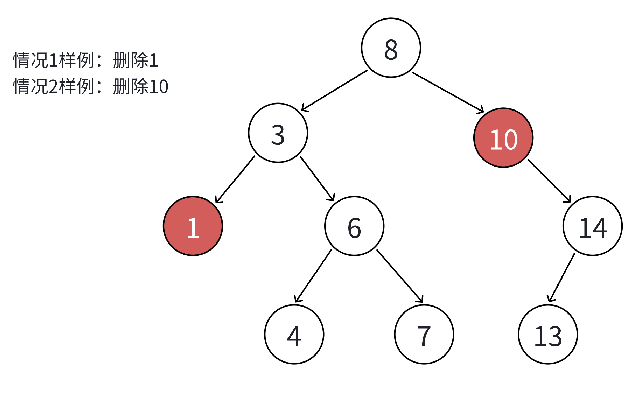
删除的难点在于 "删除节点后,需保持 BST 的规则不变"。根据删除节点(记为 cur)的子节点数量,分为 4 种情况,其中前 3 种可合并处理,第 4 种需用 "替换法" 删除:
| 情况 | 子节点状态 | 处理方案 | 关键注意事项 |
|---|---|---|---|
| 1 | 左右子树均为空(叶子节点) | 直接删除 cur 节点,将parent指向cur的孩子指针置空(可归为情况2或3统一处理) | 需判断 cur 是否为根节点(若为根,直接将 _root 置空,无需处理 parent) |
| 2 | 左子树为空,右子树非空 | 将 parent 指向 cur 的孩子指针,修改为指向 cur->_right,随后删除 cur 节点 | 若 cur 是根节点,直接让 _root = cur->_right,跳过 parent 判断 |
| 3 | 右子树为空,左子树非空 | 将 parent 指向 cur 的孩子指针,修改为指向 cur->_left,随后删除 cur 节点 | 与情况2对称,根节点处理逻辑为 _root = cur->_left |
| 4 | 左右子树均非空 | 1. 找cur右子树的"最小节点"(最左节点)或左子树的"最大节点"(最右节点); 2. 将替换节点的键值赋给cur; 3. 删除替换节点(替换节点满足情况2或3,直接处理) | 替换节点的父节点指针需正确修改(如替换节点是父节点左孩子,需将父节点左指针指向替换节点的右子树) |
代码实现:
cpp
//二叉搜索树的删除
bool Erase(const K& x)
{
//先查找删除目标结点,但需要一个father记录删除结点的父亲结点,便于连接删除结点的后续结点
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > x)
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < x)
{
father = cur;
cur = cur->_right;
}
else
{
//删除结点左为空
if (cur->_left == nullptr)
{
//如果删除根节点,由于根结点没有父亲结点,father仍为空,则需要单独讨论
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
//由于cur位于father的左边还是右边不确定,所以需要判断一下
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_right;
}
}
delete cur;
return true;
}
//删除结点右为空
else if (cur->_right == nullptr)
{
//如果删除根节点,由于根结点没有父亲结点,father仍为空,则需要单独讨论
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
if (father->_left == cur)
{
father->_left = cur->_left;
}
else
{
father->_right = cur->_left;
}
}
delete cur;
return true;
}
//删除结点左、右都不为空:替换法(找右子树最小结点,将key值赋给删除结点并删除最小结点)
else
{
Node* min_right_father = nullptr;
//min_right_father保存右子树最小结点的父亲结点
Node* min_right = cur->_right;
//min_right获取右子树最小结点
while (min_right->_left)
{
min_right_father = min_right;
min_right = min_right->_left;
}
cur->_key = min_right->_key;
//获取到右子树最小结点后有两种情况:
//如果min_right_father仍为空,说明右子树最小结点就是cur的右孩子结点,
//则cur->_right指向min_right->_right即可;
if (min_right_father == nullptr)
{
cur->_right = min_right->_right;
}
//如果min_right_father不为空,
//则min_right_father->_left指向min_right->_right即可
else
{
min_right_father->_left = min_right->_right;
}
delete min_right;
return true;
}
}
}
return false;
}关键说明:情况 4 中选择 "右子树最小节点" 作为替换节点,是因为该节点的值是 cur 右子树中最小的,替换后仍满足 BST 规则(左子树 ≤ 根 ≤ 右子树);同理,选择 "左子树最大节点" 也可,逻辑对称
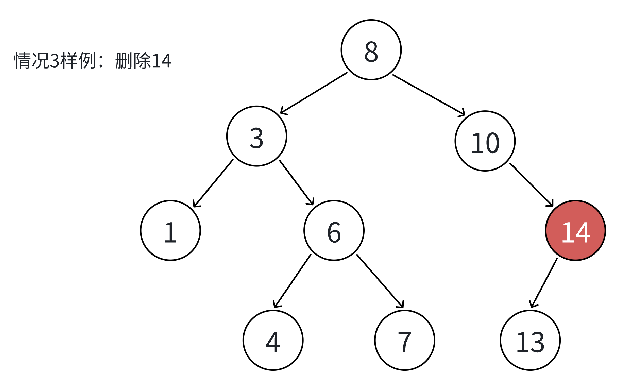
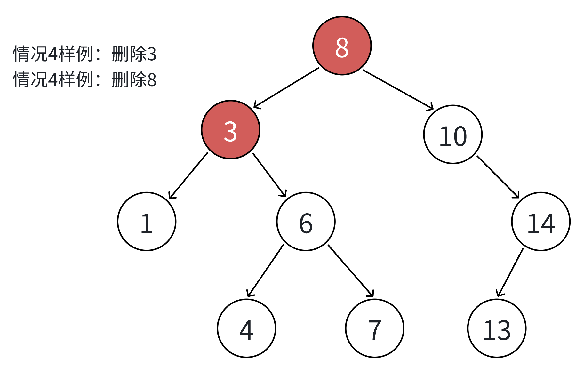
测试代码:
cpp
//Test.cpp
#include "BinarySearch.h"
void Test1()
{
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print();
//删除
for (auto e : arr)
{
bst1.Erase(e);
bst1.Print();
}
}
int main()
{
Test1();
return 0;
}值得一提的是这里有个非常简单的方法判断是否删除函数实现成功,只需要循环将二叉搜索树的所有结点全部删除一遍,如果整个循环都没有报错说明实现成功了。
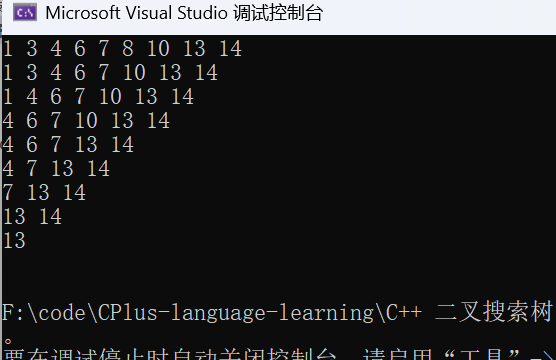
四、BST 的扩展:key/value 模型(支持映射场景)
上述实现是 "key 模型"(仅存储键值 ,用于判断 "存在性",不能修改 ),但在实际场景中比起 "key 模型" ,"key-value 模型"(键值对应数据 ,如字典、统计次数,可以修改value)更加的有用。BinarySearchTree.h 可扩展为模板 template<class K, class V>,节点同时存储 _key 和_value两个值,_key 用于做出判断,_value 则是起到实际应用的作用。
场景1:简单中英互译字典 ,树的结构中(结点)存储 key (英文)和 vlaue (中文),搜索时输入英文(key ) ,则同时查找到了英文对应的中文(value) 。
场景2:统计一篇文章中单词出现的次数 ,读取一个单词,查找单词是否存在,不存在 这个说明第一次出现,(单词,1) ,单词存在 ,则**++单词对应的次数(value)**。
1、key-value 模型节点与类实现
由于 "key-value 模型" 的二叉搜索树相关功能的实现和上面的 "key 模型" 十分类似,只是部分函数需要再考虑 value 的存放即可,所以这里就直接把类中所有函数的实现展现出来:
这里再提一句就是:由于我们的二叉搜索树是动态开辟出来的,所以我们应该手动实现析构函数,否则就会导致内存泄漏的问题;但手动实现了析构函数随之而来的就是拷贝构造,如果是编译器默认生成的则是浅拷贝,析构时就会程序崩溃,所以我们还需要手动实现深拷贝的拷贝构造函数;手动实现完拷贝构造函数后则类中就没有默认构造函数了,所以最后我们还需要手动实现一下默认构造函数。
虽然实现的东西变多了但下面的代码实现我写了详细的注释方便大家理解。
cpp
//key_value
namespace key_value
{
// key-value模型节点
template<class K, class V>
class BSTNode
{
public:
BSTNode(const K& key = 0, const V& value = 0)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{
}
K _key;
V _value;
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
};
// key-value模型BST类
template<class K, class V>
class BSTree
{
public:
typedef BSTNode<K, V> Node;
//二叉搜索树的析构(为了防止内存泄漏)
~BSTree()
{
//使用递归(后序遍历)将每个结点进行删除
//但由于递归需要传参所以我们可以再实现一个成员函数Destroy
Destroy(_root);
_root = nullptr;
}
//写了析构也就需要写深拷贝(否则就会出现同一块析构两次的情况)
BSTree(const BSTree<K, V>& bst)
{
_root = Copy(bst._root);
}
//因为实现了深拷贝,所以类中就没有默认构造了,需要手动实现
/*BSTree()
:_root(nullptr)
{ }*/
BSTree() = default; //强制生成构造
//二叉搜索树的插入
bool Insert(const K& key, const V& value)
{
//树为空,则直接新增结点,赋值给root指针
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
//树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点
//我们通过一个cur来记录要判断走哪的指针,father来记录之前的位置便于找到后连接cur
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > key)
{
father = cur; //先将当前cur位置存到father
cur = cur->_left; //再移动cur
}
else if (cur->_key < key)
{
father = cur;
cur = cur->_right;
}
else //相同则则不符合插入规则,返回false
{
return false;
}
}//while循环结束则说明找到了插入位置
cur = new Node(key, value);
//由于cur位于father的左边还是右边不确定,所以需要判断一下
if (father->_key > key)
{
father->_left = cur;
}
else
{
father->_right = cur;
}
return true;
}
//中序遍历
void Print()
{
_Print(_root);//类中可以访问_root
cout << endl;
}
//二叉搜索树的查找(有返回类型是为了查找后满足需要修改_value的情况)
Node* Find(const K& x)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
{
cur = cur->_left;
}
else if (cur->_key < x)
{
cur = cur->_right;
}
else
{
return cur;
}
}
return nullptr;
}
//二叉搜索树的删除
bool Erase(const K& x)
{
//先查找删除目标结点
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > x)
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < x)
{
father = cur;
cur = cur->_right;
}
else
{
//删除结点左为空
if (cur->_left == nullptr)
{
//如果删除根节点,则father仍为空,需要单独讨论
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
//father左右孩子结点的值和cur进行判断,
//确定father是左边还是右边
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_right;
}
}
delete cur;
return true;
}
//删除结点右为空
else if (cur->_right == nullptr)
{
//如果删除根节点,则father仍为空,需要单独讨论
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
if (father->_left == cur)
{
father->_left = cur->_left;
}
else
{
father->_right = cur->_left;
}
}
delete cur;
return true;
}
//删除结点左、右都不为空:替换法(找右子树最小结点,将值赋给删除结点并删除最小结点)
else
{
Node* min_right_father = nullptr;
//min_right_father保存右子树最小结点的父亲结点
Node* min_right = cur->_right;
//min_right获取右子树最小结点
while (min_right->_left)
{
min_right_father = min_right;
min_right = min_right->_left;
}
cur->_key = min_right->_key;
cur->_value = min_right->_value;
//获取到右子树最小结点后有两种情况:
//如果min_right_father仍为空,说明右子树最小结点就是cur的右孩子结点,
//则cur->_right指向min_right->_right即可;
if (min_right_father == nullptr)
{
cur->_right = min_right->_right;
}
//如果min_right_father不为空,
//则min_right_father->_left指向min_right->_right即可
else
{
min_right_father->_left = min_right->_right;
}
delete min_right;
return true;
}
}
}
return false;
}
private:
//因为对象调用Print()函数时无法传_root(私有无法访问),所以在类中我们套一层_Print即可
void _Print(const Node* root)
{
if (root == nullptr)
{
return;
}
_Print(root->_left);
cout << root->_key << ":" << root->_value << endl;
_Print(root->_right);
}
//后序遍历删除所有结点
void Destroy(const Node* root)
{
if (root == nullptr)
{
return;
}
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
//前序遍历深拷贝
Node* Copy(Node* root)
{
if (root == nullptr)
{
return root;
}
Node* newroot = new Node(root->_key, root->_value);
newroot->_left = Copy(root->_left);
newroot->_right = Copy(root->_right);
//深拷贝完根结点后,将根节点的左子树放入Copy函数进行深拷贝并且用newroot->_left进行连接
//再将根节点右子树放入Copy函数进行深拷贝并且用newroot->_right进行连接
//宏观角度:函数怎么将左右子树进行深拷贝我不关心,我只知道Copy能帮我完成
return newroot;
}
private:
Node* _root = nullptr;
//提供缺省值则无需再手动实现构造函数,用编译器默认生成的即可
};
}2、key-value 模型实战场景
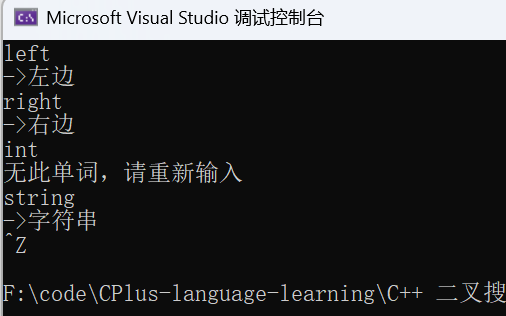
2.1 场景 1:简单字典(中英互译)
cpp
void Test2()
{
//使用key/value二叉搜索树的情况(查字典)
key_value::BSTree<string, string> dict;
//BSTree<string, string> copy = dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "输入");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
}
int main()
{
Test2();
return 0;
}
2.2 场景 2:单词统计(统计水果出现次数)
cpp
void Test3()
{
//使用key/value二叉搜索树的情况(存放数据的个数)
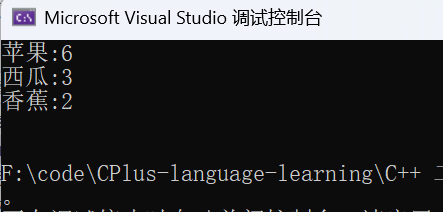
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> countTree;
//int为不同string存放的次数
for (const auto& str : arr)
{
// 先查找水果在不在搜索树中
// 1、不在,说明水果第一次出现,则插入<水果, 1>
// 2、在,则查找到的结点中水果对应的次数++
//STreeNode<string, int>* ret = countTree.Find(str);
auto ret = countTree.Find(str);
if (ret == nullptr)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;//若ret不为nullptr则已经存在,Find找到结点后直接访问_value再++即可
}
}
countTree.Print();
}
int main()
{
Test3();
return 0;
}
结束语
到此,二叉搜索树(BST)的基础概念和功能实现就讲解完了,虽然中序遍历的有序性与指针操作的灵活性是其核心优势,但其性能受插入顺序影响大,导致出现单支树退化问题。我们在这里之所以把二叉搜索树的实现讲解的这么详细也为后续平衡树(AVL、红黑树)的学习埋下伏笔。作为基础树形结构,BST 是理解复杂数据结构设计逻辑的重要基石。希望对大家学习C++能有所收获!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/