
- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【AlphaFold3】网络架构篇(7)| 详解Diffusion training set-up
- 每日一言🌼: "正因为我有能力跨越 这个考验才会降临"🌺
1. 整体认知
多个最新综述[1](#1),[2](#2)一致指出: Test-Time Adaptation (TTA) / Test-Time Training (TTT) 是为了解决 distribution shift(分布偏移) 问题,即:训练数据分布 ≠ 测试数据分布 → 模型性能崩溃。
核心思想:
- 传统的机器学习算法:
- 训练时:在一批数据集上进行训练,得到模型权重 θ \theta θ
- 测试时:模型权重不变,在测试集上进行推理
- TTA/TTT:测试时(Test-Time),继续"适应"模型,模型权重根据新的测试数据 θ \theta θ 改变
📌 本质:让模型在推理阶段具备"在线学习能力",以更好的在输入数据上进行推理
统一框架(来自多篇survey总结):
TTA/TTT可以统一为:
θ ∗ = arg min θ L t e s t ( θ ; x t e s t ) \theta^*=\arg\min_\theta\mathcal{L}{test}(\theta;x{test}) θ∗=argθminLtest(θ;xtest)
区别在于:
| 方法 | 是否更新模型 | 是否需要额外任务 |
|---|---|---|
| TTA | ✅ | ❌ (通常无监督) |
| TTT | ✅ | ✅ (自监督任务) |
2. 起源(2018--2020):TTT的提出
加州大学伯克利分校 发表在ICML的这篇文章 Sun, Y. et al. (2020). Test-Time Training with Self-Supervision. ICML. 是TTT的里程碑论文。它的核心思想是,在测试的时候使用一个辅助loss (这个辅助loss不涉及到label,只和输入 x x x有关,一般是一个自监督任务,也可以用到训练中),对于测试数据进行测试时,用这个任务(loss)更新模型。
它提出来了一个颠覆性的观点:❗ "模型可以在测试时继续训练"
根据这篇 https://yueatsprograms.github.io/ttt/home.html 我们再来详细讲解一下核心思路:
🪧1. Abstract
在这篇论文中,提出了测试时训练(Test-Time Training),这是一种通用的方法,用于提高预测模型在训练数据和测试数据来自不同分布时的性能。将单个未标记的测试样本转化为一个自监督学习 问题,在做出预测之前更新模型参数。这种方法也自然地扩展到在线流数据 (online stream) 。方法在各种旨在评估对分布偏移鲁棒性的图像分类基准上取得了改进。
🪧2. Introduction
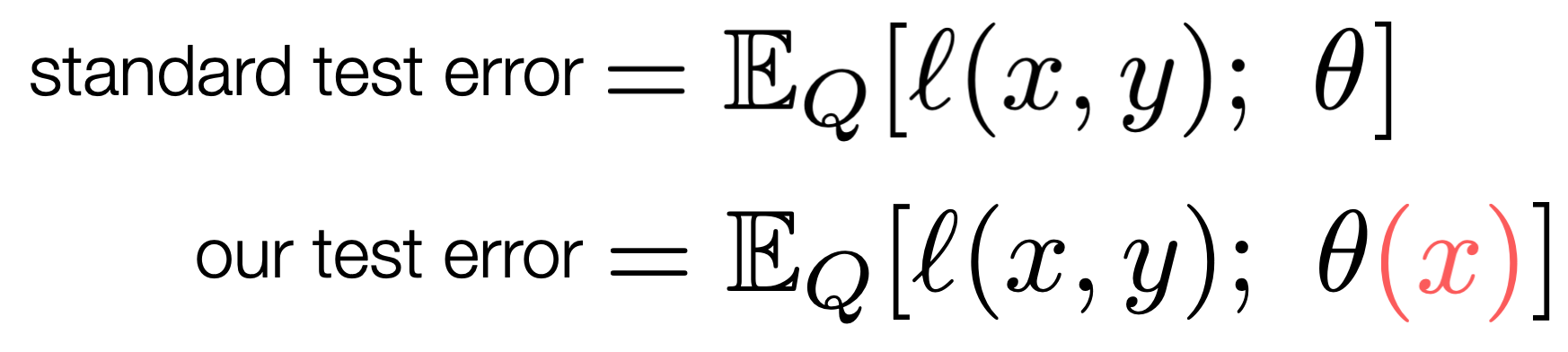
如上图,"Given model parameters θ \boldsymbol{\theta} θ and a loss function ℓ \ell ℓ, the standard test error is evaluated as the expected loss on a test distribution Q \text{Q} Q. Test-Time Training modifies the expected loss and allows θ \boldsymbol{\theta} θ to depend on the test input x x x, without looking at the label y y y.
- 标准机器学习(对照组)测试时误差 Standard test error = E Q ℓ ( x , y ) ; θ \mathbb{E}_Q\\ell(x,y);\\theta EQℓ(x,y);θ, 测试时模型权重 θ \theta θ是固定的,不会被更新
- TTT的核心突破, θ ( x ) = arg min θ ℓ s ( x ; θ ) \theta(x)=\arg\min_\theta\ell_s(x;\theta) θ(x)=argminθℓs(x;θ) , 然后: y ^ = f θ ( x ) ( x ) \hat{y}=f_{\theta(x)}(x) y^=fθ(x)(x)。 即在测时让模型权重根据输入的 x x x进行更新,更新完之后的模型权重再来预测。
🪧3. Method
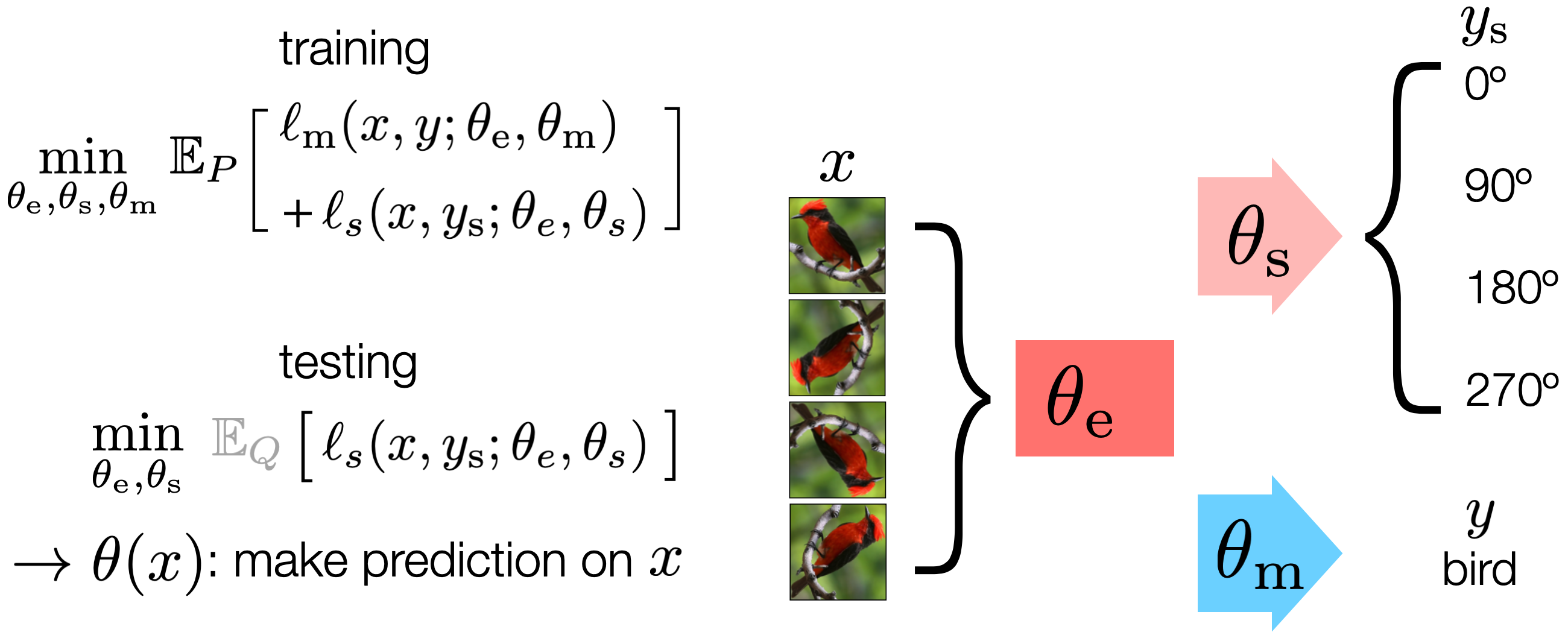
Step 1️⃣:构造"自监督任务" : 在测试的时候,自然是只有输入 x x x拿不到label y y y的,那如何构造损失函数来更新模型权重呢? 这篇论文构造了个旋转预测(rotation prediction) (Gidaris et al. 2018[3](#3))的自监督任务,将输入的图像以90°为单位进行多次旋转,然后让模型去预测4类旋转角度(0°,90°,180°,270°)。模型的 θ e \boldsymbol{\theta}{\mathbf{e}} θe负责提取公共的特征, θ s \boldsymbol{\theta}{\mathbf{s}} θs是supervised head,做角度预测, θ m \boldsymbol{\theta}_{\mathbf{m}} θm负责主任务的类别识别。
Step 2️⃣ 训练阶段公式(联合训练,joint training): 在训练时,在训练数据集的分布 P P P上,联合优化自监督任务损失 ℓ s \ell_{s} ℓs以及主任务损失 ℓ m \ell_{m} ℓm,此时是可以访问到主任务的label y y y。
Step 3️⃣ 测试时优化: 在测试时,不能获取主任务的label ,但是可以根据当前单个测试输入 (来自测试集分布 Q Q Q )得到自监督损失 ℓ s \ell_{s} ℓs, 在输出主任务预测结果前,模型会微调共享的权值 θ e \theta_{e} θe得到 θ e ∗ \theta_{e}^{*} θe∗, 最小化辅助损失的函数,再做预测: f θ ( x ) ( x ) f_{\theta(x)}(x) fθ(x)(x)。意味着 每个测试样本都有"自己的模型参数"。
Online TTT : 标准的TTT就是每个测试样本都有自己的模型参数 θ \theta θ,通过测试时微调模型权重 θ 0 \theta_{0} θ0得到 θ T \theta_{T} θT再预测,一个case预测结束后模型参数复原为 θ 0 \theta_{0} θ0。但如果测试的数据是流式,那么模型权重在一个case更新完成后继续保持当前的模型权重, θ t + 1 = θ t − η ∇ θ ℓ s ( x t ; θ t ) \theta_{t+1}=\theta_t-\eta\nabla_\theta\ell_s(x_t;\theta_t) θt+1=θt−η∇θℓs(xt;θt)。 每个样本都更新模型,模型不断适应环境 (在线学习)。

🪧4. Results
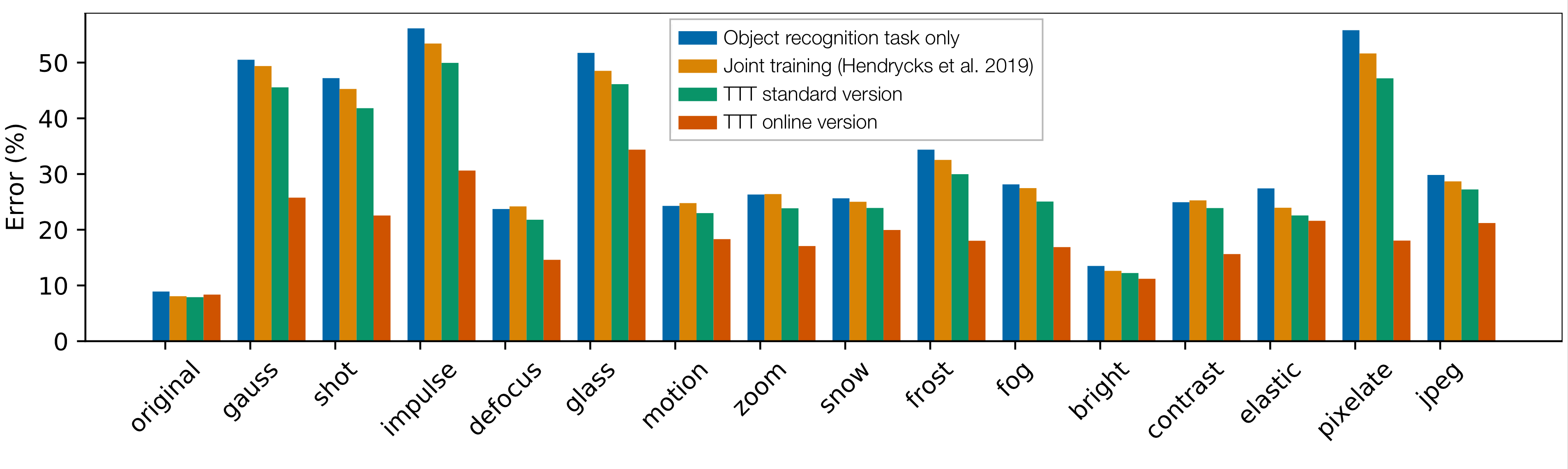
在CIFAR-10-C(Hendrycks等人,2019年)上进行了实验,这是一个标准的物体识别基准,用于评估在15种类型损坏下的泛化能力。测试时训练(TTT)标准版本在不影响原始分布的情况下,对两个基线进行了显著改进。在线版本改进得更多。
🪧5 Discussion
"最终,我们希望这篇论文能够鼓励研究人员放弃为测试而设定的固定决策边界,甚至完全放弃训练和测试之间的人为划分。我们的工作只是迈向新范式的一小步,在这个新范式中,大部分学习发生在模型部署之后。"
3. 发展阶段一(2020--2022):基础TTA方法
这一阶段重点是:❗ 不再依赖辅助任务 → 直接利用模型自己的预测信息
🪧1️⃣ Entropy Minimization^[4](#1️⃣ Entropy Minimization4(最经典))^(最经典)
📌 思想:
min θ H ( p θ ( y ∣ x ) ) \min_\theta H(p_\theta(y|x)) θminH(pθ(y∣x))
展开
H ( p ) = − ∑ c p θ ( y = c ∣ x ) log p θ ( y = c ∣ x ) H(p)=-\sum_cp_\theta(y=c|x)\log p_\theta(y=c|x) H(p)=−c∑pθ(y=c∣x)logpθ(y=c∣x)
H代表的是entropy(熵),也就是不确定性
这公式什么意思?让概率分布变"尖"。
eg:❌不确定预测(高entropy), 0.33 , 0.33 , 0.34 0.33,0.33,0.34 0.33,0.33,0.34,此时模型比较"犹豫";
✅ 确定预测(低entropy): 0.01 , 0.98 , 0.01 0.01,0.98,0.01 0.01,0.98,0.01,模型比较"自信"
所以目标是: min H ⇒ 让预测更自信 \min H\Rightarrow\text{让预测更自信} minH⇒让预测更自信
这是最关键的 insight:假设模型在新分布上仍然"基本正确"。那么:正确类别本来就应该概率高,所以"让它更自信"会更接近正确答案
🪧2️⃣ BatchNorm Adaptation(最简单)
不优化loss,只做: μ t e s t , σ t e s t \mu_{test},\sigma_{test} μtest,σtest 替换训练时的: μ t r a i n , σ t r a i n \mu_{train},\sigma_{train} μtrain,σtrain。
BN层做的是:
x ^ = x − μ σ \hat{x}=\frac{x-\mu}\sigma x^=σx−μ
方法本质不是更新模型权重,而是对齐数据分布(distribution alignment)。
3️⃣ Pseudo-label (伪标签方法)
核心公式:
y ^ = arg max p θ ( y ∣ x ) \hat{y}=\arg\max p_\theta(y|x) y^=argmaxpθ(y∣x)
然后: min θ ℓ ( f θ ( x ) , y ^ ) \min_\theta\ell(f_\theta(x),\hat{y}) θminℓ(fθ(x),y^)
用模型自己的预测当标签再训练,自举学习(self-training)。
对比:
| 方法 | 优化目标 | 是否用标签 | 风险 |
|---|---|---|---|
| TTT | 自监督loss | ❌ | 设计难 |
| Tent | entropy | ❌ | 过拟合错误 |
| Pseudo-label | CE loss | ❌(伪标签) | 错误放大 |
| BN Adapt | 无 | ❌ | 表达能力弱 |
4. 发展阶段二(2022--2025):系统化与扩展
1️⃣ 综合TTA综述 Liang, J. et al. (2025). A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts. IJCV.
👉 提出完整分类体系
-
Source-free TTA
-
Online TTA (OTTA)
-
Continual TTA
-
Test-time Prompting(新趋势)
2️⃣ 在线TTA综述 Wang, Z. et al. (2025). In Search of Lost Online Test-Time Adaptation. IJCV. 重点讲了连续数据流适应(streaming)
3️⃣ 新统一视角:Xiao, Z. & Snoek, C. (2024). Beyond Model Adaptation at Test Time.
提出TTA不仅是"改模型",还包括:数据适配、推理策略适配、memory机制
-
Liang, J. et al. (2025). A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts. IJCV. ↩︎
-
Xiao, Z. & Snoek, C. (2024). Beyond Model Adaptation at Test Time. ↩︎
-
Unsupervised Representation Learning by Predicting Image Rotations ↩︎
-
Wang, D. et al. (2021). Tent: Fully Test-Time Adaptation by Entropy Minimization. ICLR. ↩︎