目录
[3多线程 Future 的用法](#3多线程 Future 的用法)
[4 SpringMvc 的优点和缺点?](#4 SpringMvc 的优点和缺点?)
[6有没有碰到过执行计划不一致的情况,同一条 SQL 不同的执行场景用的索 引不同 ,如何强制使用某个索引](#6有没有碰到过执行计划不一致的情况,同一条 SQL 不同的执行场景用的索 引不同 ,如何强制使用某个索引)
[8当给第三方提供接口调用 ,需要注意哪些事情?](#8当给第三方提供接口调用 ,需要注意哪些事情?)
[9设计 redis 的 key 和 value ,有哪些原则?](#9设计 redis 的 key 和 value ,有哪些原则?)
[11Spring AOP 在什么场景下会失效?](#11Spring AOP 在什么场景下会失效?)
[13能否解释一下 Spring Boot 的自动配置原理?](#13能否解释一下 Spring Boot 的自动配置原理?)
[14你能说说 JVM 的垃圾回收机制吗?比如常见的垃圾收集器有哪些?](#14你能说说 JVM 的垃圾回收机制吗?比如常见的垃圾收集器有哪些?)
[15在高并发场景下,如何解决 MySQL 的性能瓶颈?](#15在高并发场景下,如何解决 MySQL 的性能瓶颈?)
[16你能解释一下 Redis 的持久化机制吗?RDB 和 AOF 有什么区别?](#16你能解释一下 Redis 的持久化机制吗?RDB 和 AOF 有什么区别?)
[17JVM 中一次完整的 GC 流程(从 ygc 到 fgc)是怎样的?](#17JVM 中一次完整的 GC 流程(从 ygc 到 fgc)是怎样的?)
[18Spring 是如何管理事务的 ,事务管理机制?](#18Spring 是如何管理事务的 ,事务管理机制?)
1缓存雪崩问题及解决方案
缓存雪崩是分布式系统中的高并发问题,其核心特征是大量key在同一时间失效或者Redis服务整体宕机,导致数据库压力激增设置崩溃
常见的缓存雪崩场景
1批量key同时过期
如定时任务批量刷新缓存,设置相同的TTL
2Redis服务故障
如主从切换,网络故障等
3冷启动未预热
新系统上线或重启时,缓存没有数据,首次请求直接压垮数据库
解决方法
1分散key的过期时间,通过随机值打散key的过期时间
javaint baseTTL=36000; int randomTTL=random.NextInt(300); redis.set(key,value,vaseTTL+randomTTL);2设置多级缓存架构:本地缓存+redis缓存+数据库构建,避免单点风险
3熔断降级与限流
当数据库压力超过阈值时,可以拒绝部分请求,直接返回错误页或默认值

2缓存穿透及解决方案
缓存穿透是指频繁查询数据库中不存在的数据,导致绕过缓存直接请求数据库
缓存穿透原因是
1恶意攻击攻击者构造大量不存在id对数据库进行请求
2业务设计缺陷:未对请求参数做合法性校验
解决方法
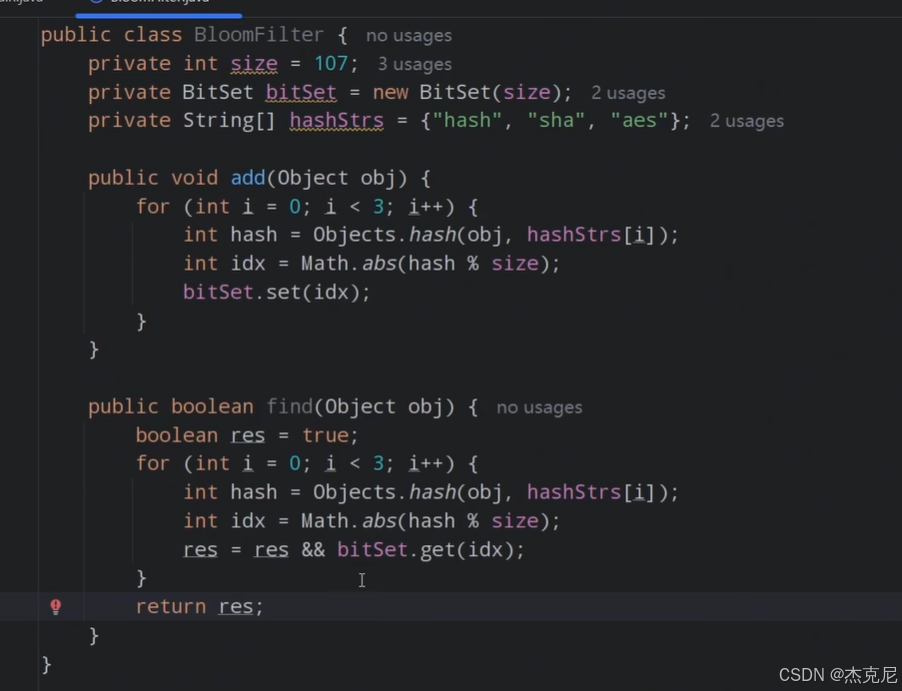
1使用布隆过滤器,利用概率型数据结快速接判断key是否存在,拦截非法请求
2空值缓存:即使数据库无数据,也缓存空值null,避免重复查询数据库
3在业务层对请求参数进行合法性校验如检验格式,范围,以及规则
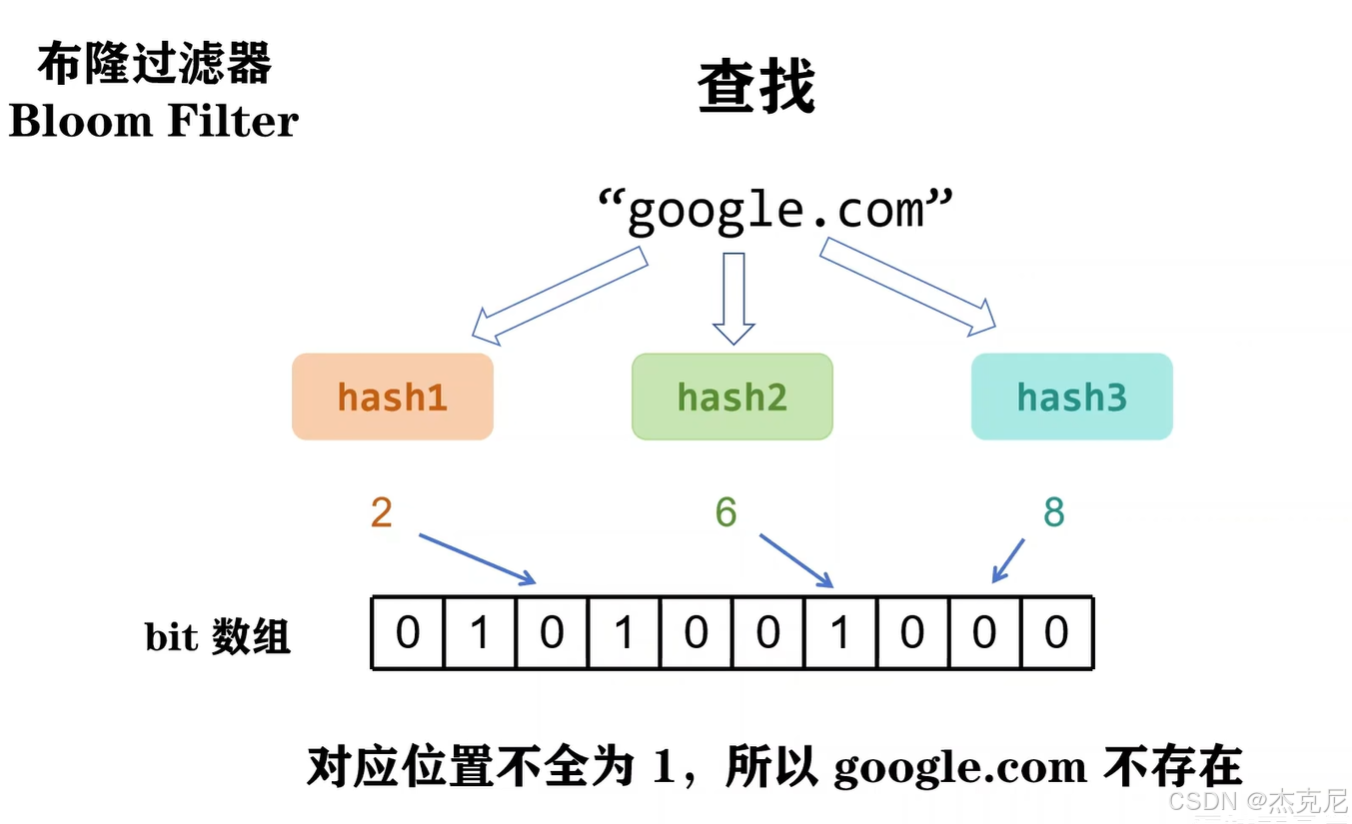
补充:布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构 ,核心作用是快速判断「一个元素是否存在于集合中」。它的特点是:不存在误判(判断 "不存在" 则一定不存在),存在可能误判(判断 "存在" 可能实际不存在),且不支持删除元素。



3多线程 Future 的用法
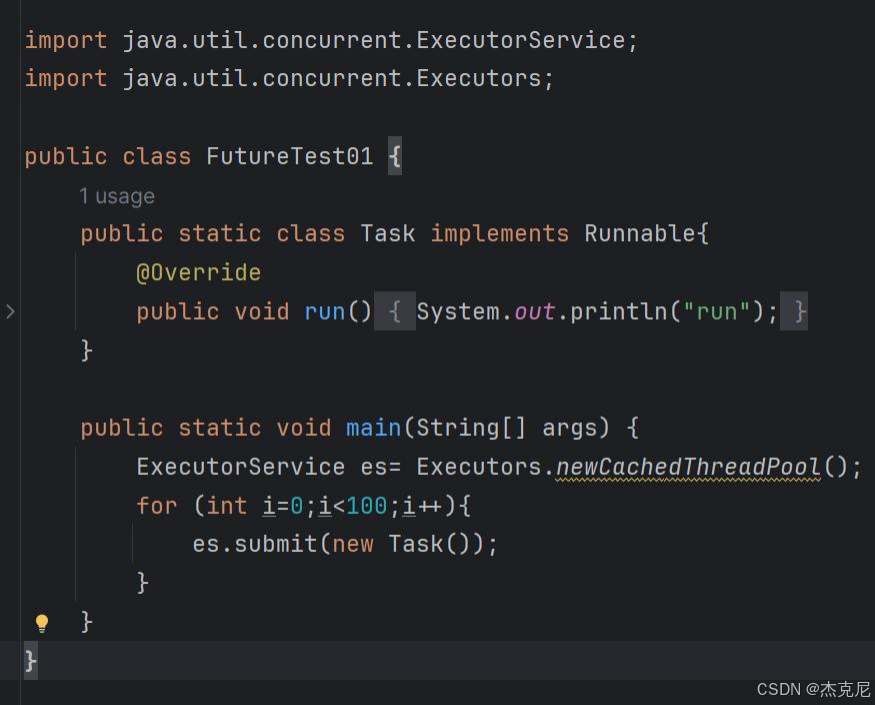
在并发编程时,一般使用runable,然后交给线程池即可,这种情况不需要返回值,所以runable是void返回类型;当需要返回值时,如多线程计算裴波那且序列,调用call()方法,该方法有一个泛型返回值类型;但是线程属于异步计算模型,不能直接从别的线程获取返回值,这时候就需要用到Future了,Future可以监视目标线程调用call的情况,当调用Future的get()方法时,当前线程就开始阻塞,直到call方法返回结果结束
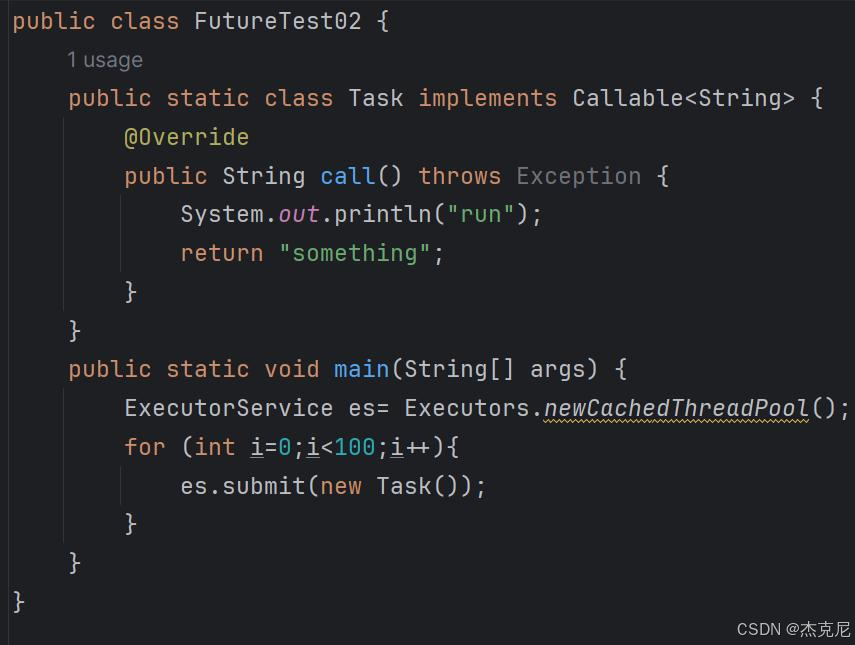
runnable 接口实现的没有返回值的并发编程
callable 实现的存在返回值的并发编程(call 的返回值 String 受泛型的影响)
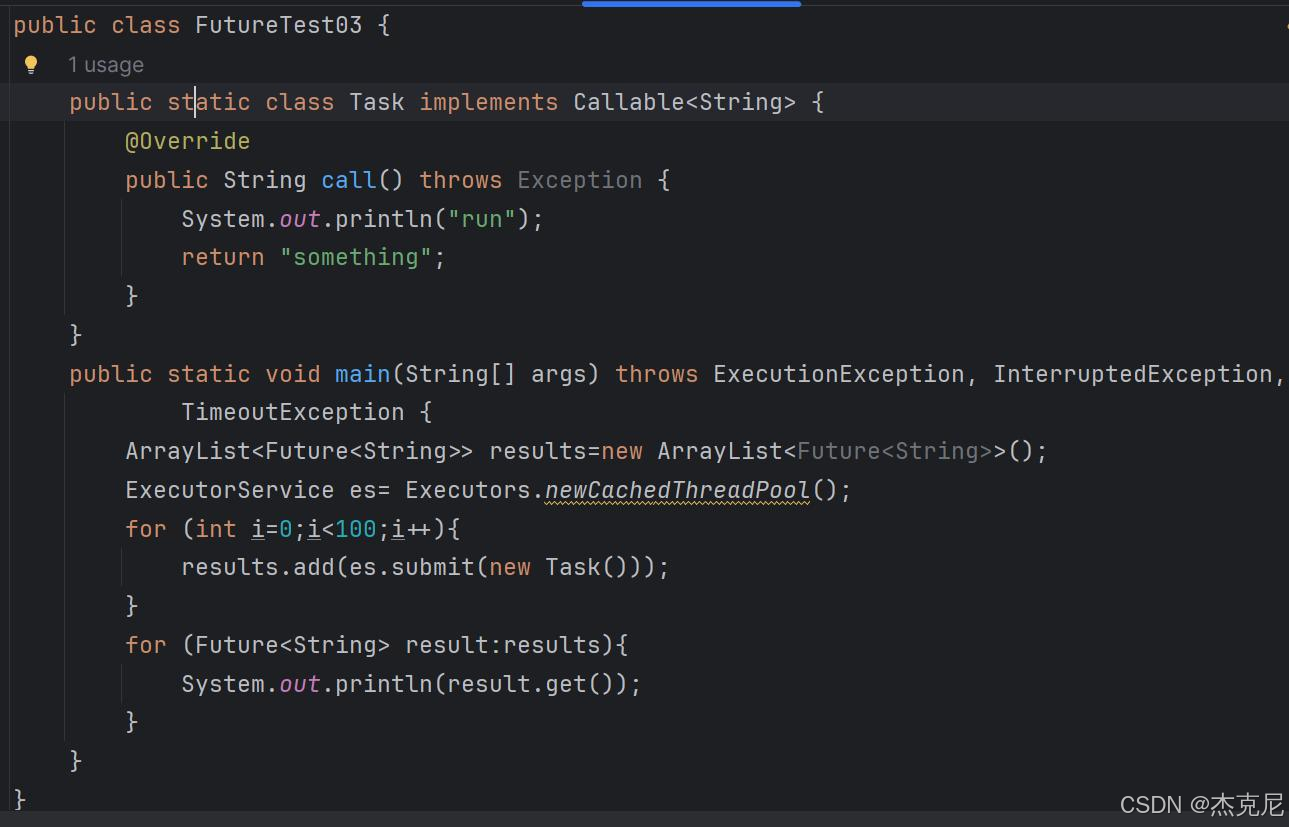
同样是 callable,使用 Future 获取返回值
4SpringMvc 的优点和缺点?
优点:
1松耦合和模块化设计:
SpringMVC将模型,视图,控制器职责分离,大大降低了代码的耦合度;
通过Spring容器管理对象的生命周期和依赖关系,降级硬编码设计,提高模块化设计
2可扩展性高:
支持各种视图技术,满足不同项目的不同需求
插件化扩展,通过拦截器,自定义数据绑定器等扩展点,可以快速集成第三方库
3配置多样:支持注解配置和xml配置,适合不同复杂程度的项目
4有强大的数据请求能力,自动将请求参数与对象进行绑定,减少手动代码
5与Spring生态无缝集成,与Spring data,security,boot等模块深度集成
6各种高级功能支持,如全局异常处理只需要使用注解@ControllerAdvice和@ExceptionHandler即可
缺点:
1学习难度高,复杂概念多,若依赖注入,AOP,拦截器等对新手不友好
2不适合小型项目的开发,过度的分层架构和模块化设计可能导致性能下降等问题
3性能开销:反射与代理机制带来一定的性能损耗,在超高并发情况下可能导致性能瓶颈
5Http和Https的区别?
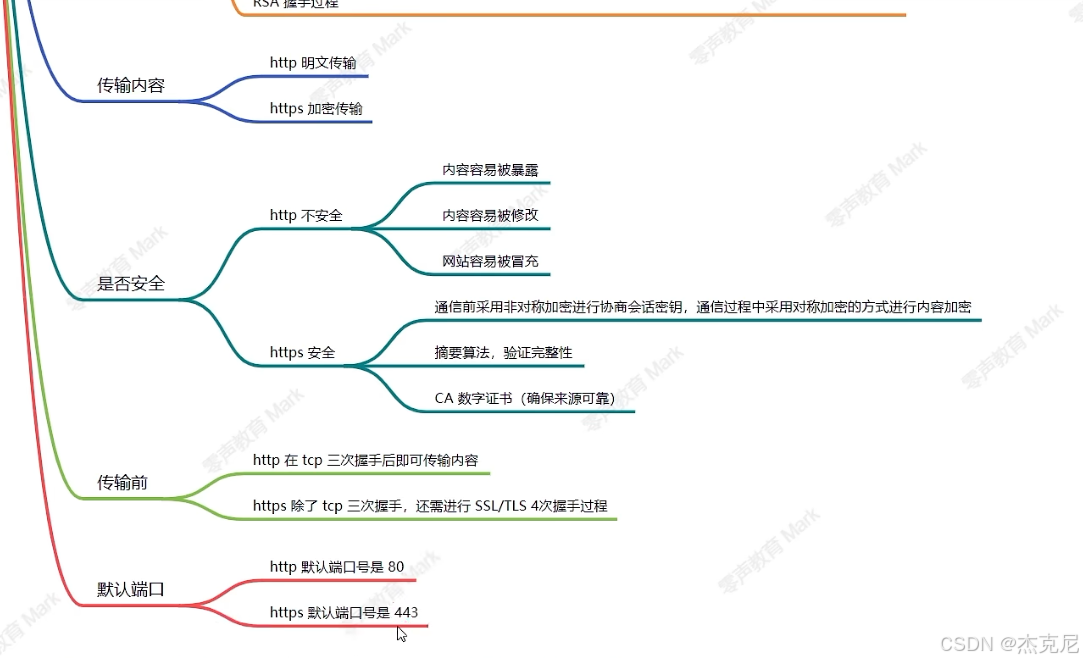
在传输内容上,http采用明文传输的方式,而https采用加密传输的方式
在安全性上,
http不安全,因为其内容容易被暴露/修改/冒充
https安全,因为通信前采用非对称加密进行协商会话秘钥,通信过程中采用对称加密的方式进行内容加密,采用摘要算法,验证完整性,使用CA数字证书(确保来源可靠)
在传输前:http在tcp三次握手后即可传输内容,https除了三次tcp握手 ,还需进行SSL/TLS4次握手过程
在默认端口上:http默认端口是80,https默认端口是443
问题:什么是非对称加密和对称加密?
问题:什么是SSL/TSL?
6有没有碰到过执行计划不一致的情********况,同一条 SQL 不同的执行场景用的索 引不同 ,如何强制使用某个索引
在实际工作中,我遇到过因为统计信息不准确和分布式变化导致同一个SQL执行使用不同的索引,这时候我们首先用explain找出产生不同的根本原因。若需要使用强制索引,我们只需要使用数据库特定的语法即可;但是我们应该优先考虑优化查询与索引,如避免对索引列使用函数操作,完善统计信息或设计覆盖索引;同时我们在测试环境应充分验证并持续性的监控生产性能,避免因数据变化导致新的性能问题;
使用强制索引:只需要在SQL语句后面跟上force index()即可
7如果查询优化器选错了索引怎么办?
在数据库优化中,查询优化器选择错索引是常见问题,尤其是在数据分布和统计信息不明确的情况下;
首先我们使用explain确认执行计划异常,确认实际使用的索引
然后使用show检查统计信息
解决方法有:
强制使用索引,当我们知道某个索引更优且需要快速修复线上问题时我们可以使用这个方法
设计覆盖索引,设计索引包含查询的所有字段,合并冗余索引
查询重写优化索引,如修改对索引使用函数操作等
8当给第三方提供接口调用 ,需要注********意哪些事情?
1首先我们需要提供的接口遵循REST ful规范,使用资源化url和HTTP方法,数据格式统一使用Json,有些接口还需要优雅降级,在高负载的情况下关闭非核心功能,确保核心功能可能,还有就是提供接口文档和SDK简化集成
2然后还要确定安全性,使用Oauth2.0,jwt等确保调用者身份合法,然后就是敏感信息脱敏,接口返回的敏感信息需要脱敏;对参数进行合法校验和防护;使用合理的限流策略限制QPS
3使用缓存和异步对性能进行保证:对高频读的数据使用Redis进行缓存,对耗时操作等通过消息队列进行异步处理
3日志记录;使用JSON的格式结构化记录日志,还需要敏感日志过滤
终极目标是为了实现安全可靠、易于集成、高效稳定的 API 服务。
9设计 redis 的 key 和 value ****,****有哪些原则?
设计key有以下三点原则:
1使用统一的命名格式
2避免key过长占用过多内存,导致查询效率降低
3避免key数量过多,导致内存碎片过多和难以管理
设计value有以下原则:
1根据需求选择合理的数据结构,如查询详情 使用Hash,排行榜使用Zset,社交关系使用SortedSet
2避免value过大,会阻塞单线程,影响性能
优化方案:分片存储将一个大Hash分割成几个小Hash进行缓存,压缩存储:对JSON/文本数据使用GZIP压缩
3合理设置过期时间,结合业务场景设置固定或随机的TTL
10进程线程协程?
进程是操作系统分配资源的最小单位,拥有独立的内存空间
线程是进程内的执行单元,共享进程的资源,是CPU调度的最小单位
协程是用户态的轻量级线程,由程序控制调度,共享线程所在的内存空间;
11Spring AOP 在什么场景下会失********效?
1当一个Bean里面的方法调用另一个方法时AOP会失效
原因:AOP代理对象增强方法,内部方法调用使用this直接调用目标对象的方法,绕过了代理
方法:使用@AopContext.currentProxy(),需开启exposeProxy()配置
2非Spring管理的对象:使用new 创建出来的对象,AOP会失效
原因:AOP只能对Spring容器中管理的Bean对象有效
方法:使用@component注解给类声明为Bean,并通过@Autowired进行注入
3异步方法在新线程中执行,可能会导致AOP拦截器无法追踪
原因:异步线程上下文与代理对象分离,导致切面逻辑失效
方法:在异步方法调用处使用AOP,在线程对象内传递上下文
4切入点表达式写法错误
12接口防刷怎么实现?
首先想到的是限流,使用令牌桶或漏桶算法,限制每个用户IP的请求频率;
然后使用验证码,特别是登录,注册接口;
其次是使用黑名单机制,对频繁违规的账户IP进行封禁处理
最后是设备指纹和用户行为分析,可以通过收集客户端的信息来识别唯一设备,分析请求模式是否异常
13能否解释一下 Spring Boot 的自动配置原理?
Spring Boot 的自动配置主要基于 @EnableAutoConfiguration 注解。它通过 SpringFactoriesLoader 加载 META-INF/spring.factories 文件中定义的自动配置类。每个自动配置类都会通过 @Conditional 系列注解来判断是否满足条件,只有满足条件时才会生效。比如 @ConditionalOnClass 会检查类路径中是否存在特定的类,@ConditionalOnMissingBean 会检查容器中是否已经存在特定的 Bean。
14你能说说 JVM 的垃圾回收机制吗?比如常见的垃圾收集器有哪些?
JVM 垃圾回收是自动内存管理机制------ 无需程序员手动释放内存,JVM 自动识别并回收 "不再被使用的对象",避免内存泄漏和 OOM,核心分 "垃圾判定→回收区域→回收算法→收集器" 四部分:
JVM 的垃圾回收主要分为新生代和老年代。常见的垃圾收集器包括:Serial GC、Parallel GC、CMS(Concurrent Mark Sweep)和 G1(Garbage First)。G1 是目前比较推荐的收集器,它将堆划分为多个 Region,可以预测停顿时间,适合大内存场景。JDK 11 后还有 ZGC,它的停顿时间可以控制在 10ms 以内,非常适合低延迟场景。
15在高并发场景下,如何解决 MySQL 的性能瓶颈?
主要有几个方向:首先是读写分离,将读操作分散到多个从库。其次是分库分表,按照业务维度或数据量进行水平拆分。然后是优化查询,包括建立合适的索引、避免全表扫描、使用 EXPLAIN 分析执行计划。另外可以引入缓存层,比如 Redis,减少数据库的直接访问。最后是连接池优化,合理配置 HikariCP 等连接池的参数。
16你能解释一下 Redis 的持久化机制吗?RDB 和 AOF 有什么区别?
Redis 把内存中的键值对数据,通过特定规则写入磁盘文件,重启时从文件恢复数据,避免数据丢失;
RDB和AOF的区别?
- 数据保存形式:RDB 存数据快照,AOF 存写命令;
- 数据安全性:AOF 更安全(默认每秒刷盘,最多丢 1 秒数据),RDB 易丢快照间隔数据;
- 性能影响:RDB 快照时会 fork 子进程,高数据量下短暂阻塞;AOF 写命令追加开销略高,需定期重写(rewrite)压缩文件。
17JVM 中一次完整的 GC 流程(从****ygc 到 fgc)是怎样的?
在年轻代中,对象创建在伊甸园中,如果伊甸园的内存不够,则会触发年轻代垃圾回收,年轻代垃圾回收采用的是标记-复制算法,将伊甸园区和幸存区s0****的对象复制到s1中,然后清空伊甸园和s0,再见s0和s1的职责互换;如果幸存区的内存仍然不够,则会进行空间分配担保,如果过担保成功,则会正常进行年轻代垃圾回收,如果担保失败则会进行全堆垃圾回收;如果老年代的内存不足,则会触发老年代垃圾回收;在全堆垃圾回收之后,若老年代的内存依旧不够,则会进行报内存耗尽的错误
18Spring 是如何管理事务的 ,事务********管理机制?
Spring 事务是基于AOP的声明式事务,有三部分组成:事务定义,事务管理器,和事务状态
首先:当方法上加上@Transactional后,Spring会通过动态代理拦截方法调用
代理先从TransactionDefinition读取事务属性:事务状态,隔离状态,回滚规则等
通过platFormTranscationManager获取数据库连接,关闭自动连接,开启事务
方法执行过程中,所有DAO操作共用同一个连接,保证在同一个事务内
当事务正常结束,事务管理器提交;抛出未捕获异常,最后回滚
最后释放连接,恢复自动提交
末尾页
本文摘要: 本文系统梳理了分布式系统与Java开发中的核心问题及解决方案。主要内容包括:1)缓存雪崩和穿透的成因及应对策略;2)多线程编程中Future的使用;3)SpringMVC的优缺点分析;4)HTTP与HTTPS的安全差异;5)SQL执行计划优化技巧;6)Redis键值设计原则;7)进程/线程/协程的区别;8)Spring AOP失效场景;9)接口防刷方案;10)JVM垃圾回收机制;11)MySQL高并发优化;12)Redis持久化机制;13)Spring事务管理原理。这些知识点涵盖了系统架构、性能优化、安全防护等多个维度,为开发高性能、高可用的分布式系统提供了实用指导。