编译一个 CUDA 扩展,本质上是协调好几个核心组件进行一场"四方会谈",任何一个谈不拢,编译就会失败。这四方是:CUDA 版本、PyTorch 版本、编译器版本和你的 GPU 架构。
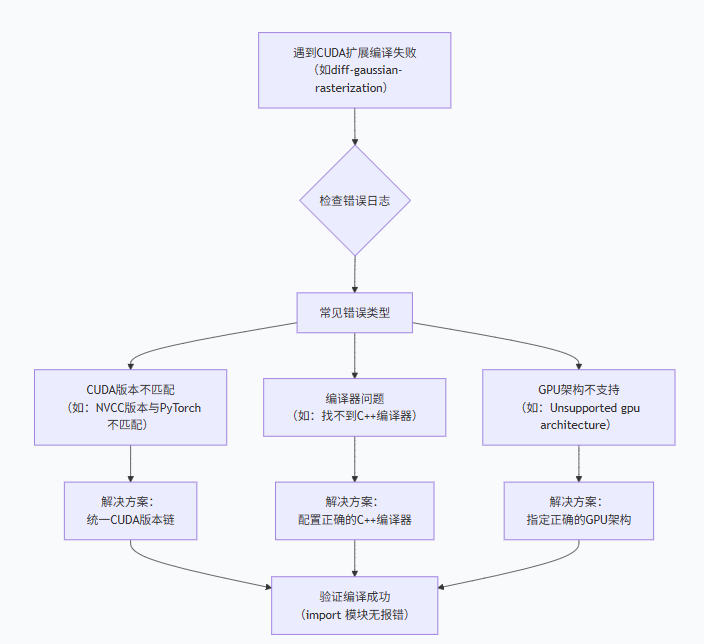
解决方案:
1. 统一版本链:CUDA, PyTorch, 驱动
这是最重要的一步,几乎 90% 的问题都源于此。你需要确保系统里的 CUDA 工具包版本和 PyTorch 所依赖的 CUDA 版本是"兼容"的,并且你的显卡驱动足够新以支持这个版本。
第一步:查看你的显卡驱动能支持的最高 CUDA 版本。
在你的服务器上运行 nvidia-smi,看右上角的 CUDA Version。根据你之前提供的信息,这个版本是 12.8,这说明你的驱动是足够新的,可以支持 CUDA 12.x 版本。
第二步:查看你当前 PyTorch 的 CUDA 版本。
在你的 gggs 环境中运行 Python,然后执行:
import torch
print(torch.version.cuda)
这会告诉你 PyTorch 是在哪个 CUDA 版本下编译的。
第三步:让版本对齐。
确保你 PyTorch 的 CUDA 版本 ≤ 你驱动支持的最高 CUDA 版本。例如,你驱动支持 12.8,那么安装 cu121(CUDA 12.1)或 cu118(CUDA 11.8)版本的 PyTorch 都是可以的。但如果你的 PyTorch 是 cu121,而你的驱动最高只支持 11.4,那就会报错。
如果发现不匹配,你需要重新安装一个兼容的 PyTorch 版本。你可以从 PyTorch 官网 找到安装历史版本或特定 CUDA 版本的命令。例如,安装 CUDA 11.8 版本的 PyTorch 可以用:
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --index-url https://download.pytorch.org/whl/cu118
2. 配置正确的 C++ 编译器
在 Linux 上,CUDA 编译器(NVCC)需要一个主机编译器来配合工作。这通常是 gcc 和 g++。NVCC 对编译器的版本有严格要求,并不是越新越好。
检查编译器版本:运行 gcc --version 查看你的 GCC 版本。
查阅兼容性表:你需要在 NVIDIA 官网查找你安装的 CUDA 版本所兼容的 GCC 版本范围。例如,CUDA 11.x 通常最高支持到 GCC 9 或 10。如果你的 GCC 版本过高(比如 13),编译就会失败。
解决方法:如果 GCC 版本过高,你需要安装一个兼容的版本,并通过 export CC=/usr/bin/gcc-9 和 export CXX=/usr/bin/g++-9 这样的命令,在编译前临时指定使用正确的编译器。
3. 设置 CUDA 架构
编译时需要告诉编译器你的显卡具体是什么型号,以便生成针对性的机器码。如果这个参数设置不对,也会报错。
查看你的 GPU 架构:运行 python -c "import torch; print(torch.cuda.get_device_capability())",它会输出类似 (8, 6) 的数字,代表你的 GPU 计算能力是 8.6(对应 sm_86 架构)。
在编译时指定架构 :对于像 diff-gaussian-rasterization 这样的包,你可以在安装前设置环境变量来指定架构:
export TORCH_CUDA_ARCH_LIST="8.6" # 将此处的数字替换为你自己GPU的计算能力
pip install submodules/diff-gaussian-rasterization --no-build-isolation
如果要支持多种架构,可以用分号分隔,如 export TORCH_CUDA_ARCH_LIST="7.5;8.0;8.6"。
4. 检查环境变量
有时编译工具找不到 CUDA 的安装路径,也会导致失败。
设置 CUDA_HOME:确保这个环境变量指向你的 CUDA 安装目录。通常是 /usr/local/cuda。可以在 ~/.bashrc 中添加以下内容:
bash
export CUDA_HOME=/usr/local/cuda
export PATH=CUDA_HOME/bin:PATH
export LD_LIBRARY_PATH=CUDA_HOME/lib64:LD_LIBRARY_PATH
然后执行 source ~/.bashrc 使其生效。